
多智能体深度强化学习 # 多智能体深度强化学习基础
前置基础:DDPG从这里开始就进入多智能体的领域了,另外到这里来说网上的教程一般也就木有了。感知智能->决策智能->群体决策智能Referenceopenai/maddpg的github在复现MADDPG的过程中遇到什么问题,是怎样解决的?张海峰 讲座-从博弈论到多智能体强化学习附介绍:...
从这里开始就进入多智能体的领域了,另外到这里来说网上的教程一般也就木有了。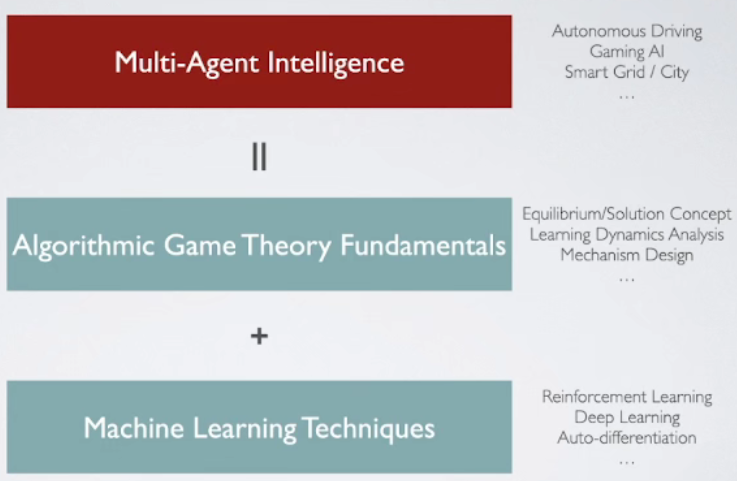
感知智能->决策智能->群体决策智能
感知智能->决策智能->认知智能
传统方法:博弈论研究多个智能体的理性决策问题,定义了动作、收益,侧重分析理性智能体的博弈结果,即均衡。实际上智能体绝对理性很难实现,智能体往往处在不断的策略学习过程中。多智能体强化学习研究智能体策略的同步学习和演化问题,在无人机群控制、智能交通系统、智能工业机器人中有重要应用。
博弈论基础
偏好 Preference、效用 Untility


游戏策略与收益矩阵 Game Strategy and Utility Matrix

矩阵博弈 Matrix Game


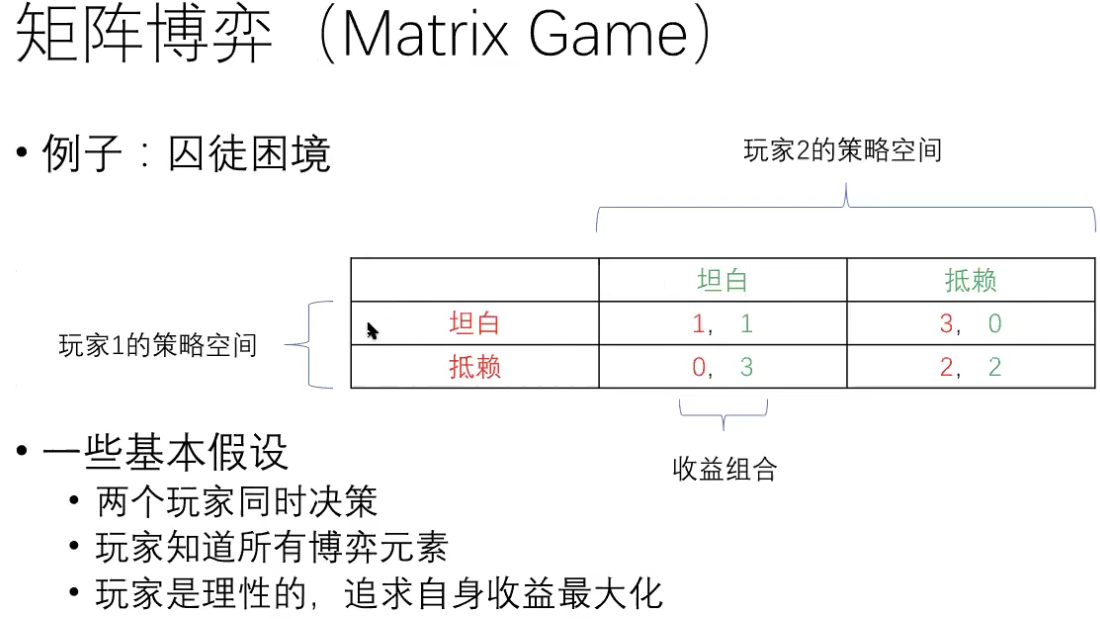
策略推理
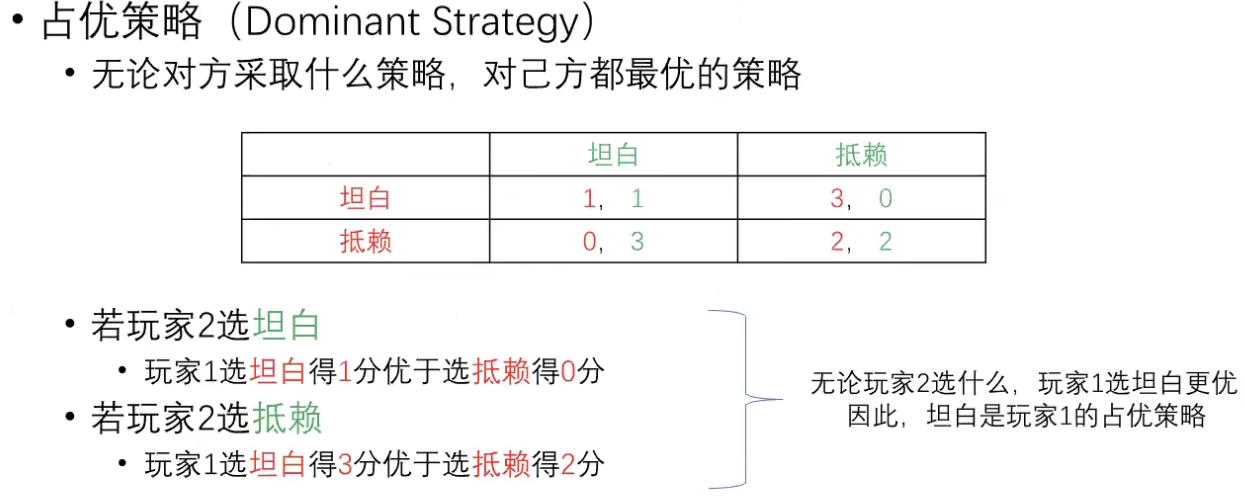

我们把数据修改成非对称的情况:

博弈的解



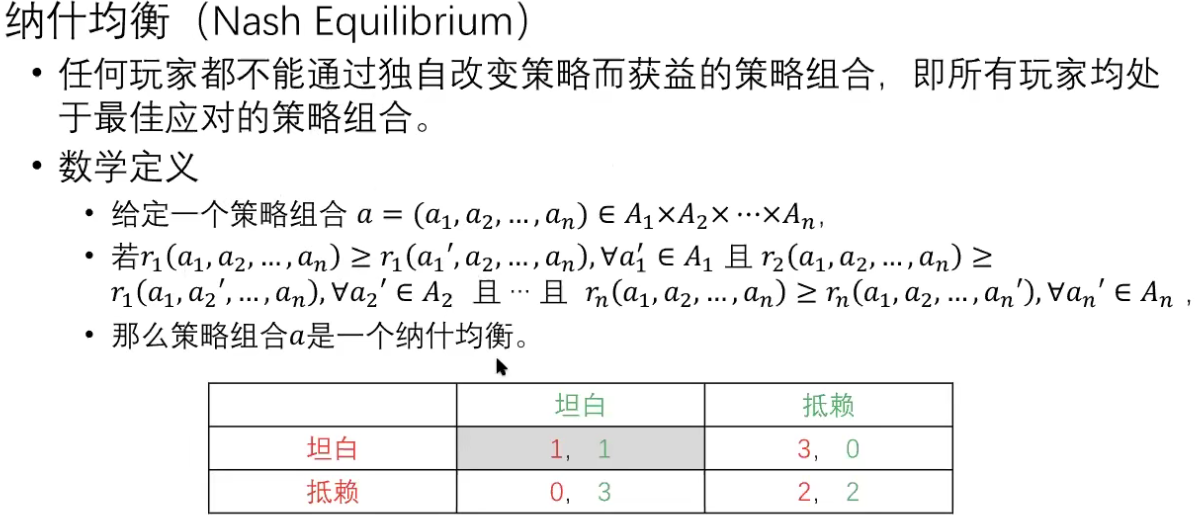




双人正则形式的零和游戏*

协同问题
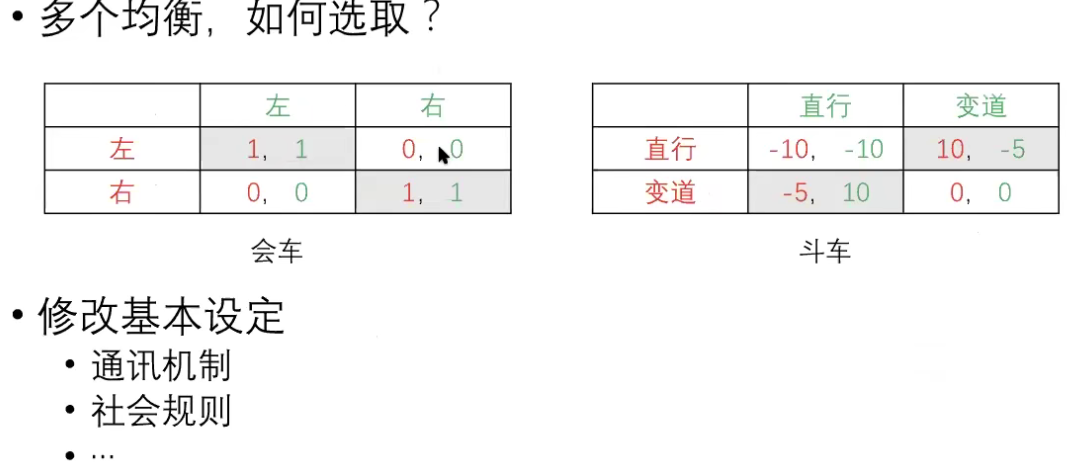
多个纳什均衡解,不知道对方选择的情况下怎么选择到合适的解?
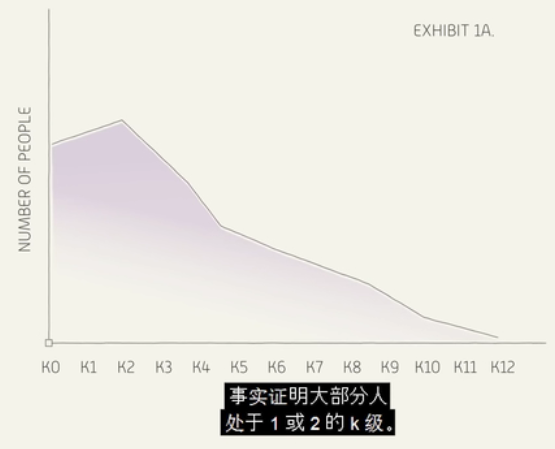
思考题:n个人从0-100中,选一个数,这个数的值接近于所有人猜的值的2/3,请问每个人猜的数是多少?平均数的2/3是多少?
答案:1、 2 3 \frac{2}{3} 32。
但现实中,参与者不一定都是绝对理智的参与者。
k-level reasoning:k means the number of times a cycle of reasoning is repeated
k-level为0的人:随机猜测
k-level为1的人:考虑k-level=0时为随机值,因此样本足够大时平均值为50,因此选取33。
k-level为2的人:考虑所有人都是k-level=1的人,因此样本足够大时平均值为33,因此选取22。
…
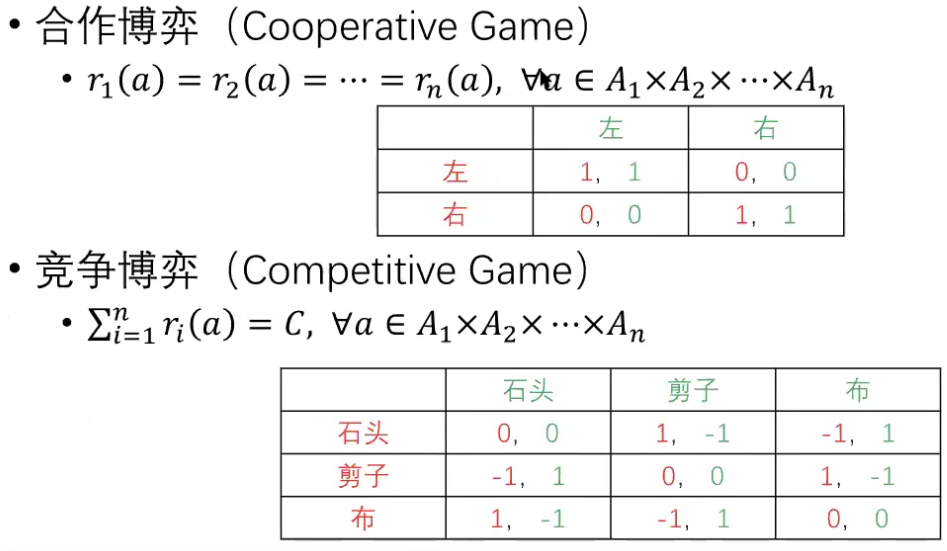
特殊的博弈:合作与竞争博弈
社会选择与社会福利

多智能体深度强化学习
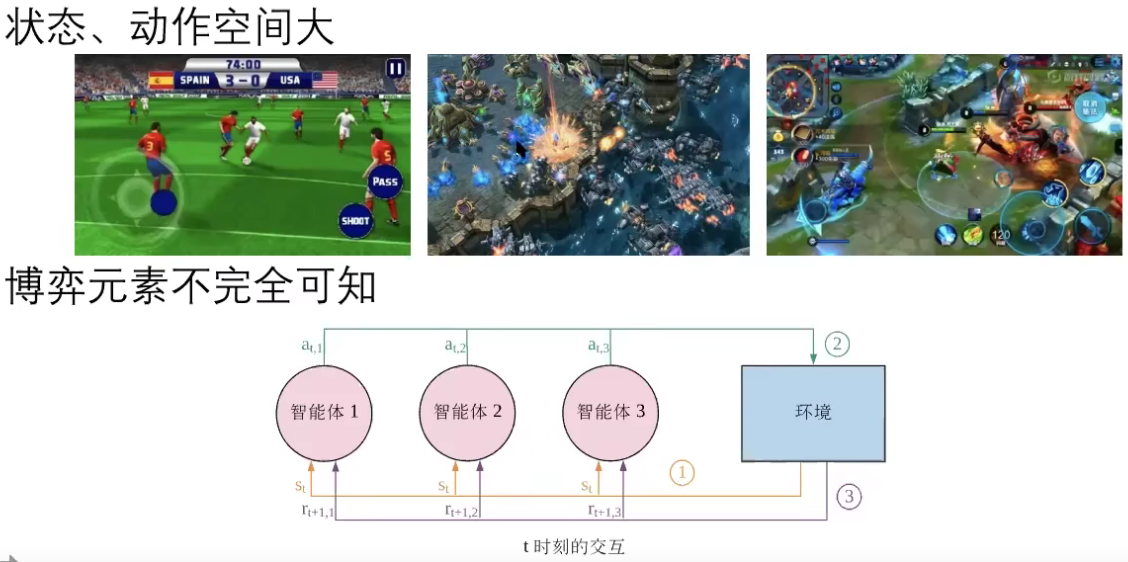
(第二种:model-free的博弈)
马尔可夫博弈
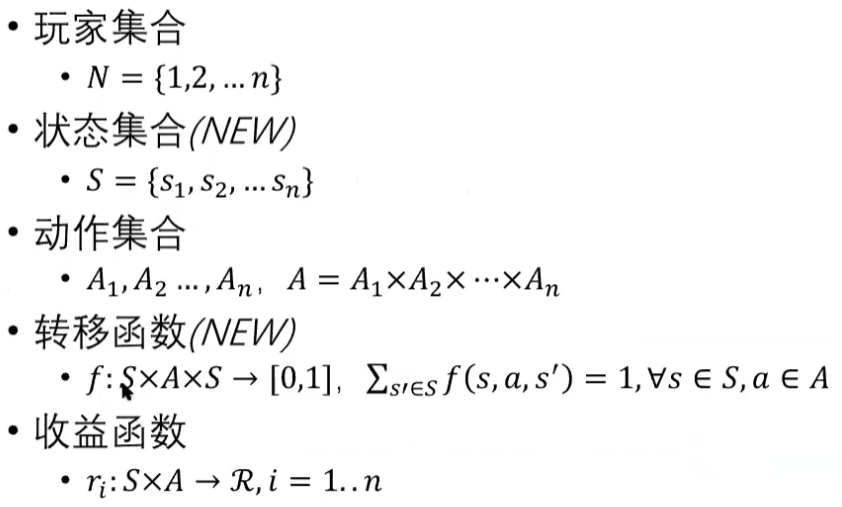

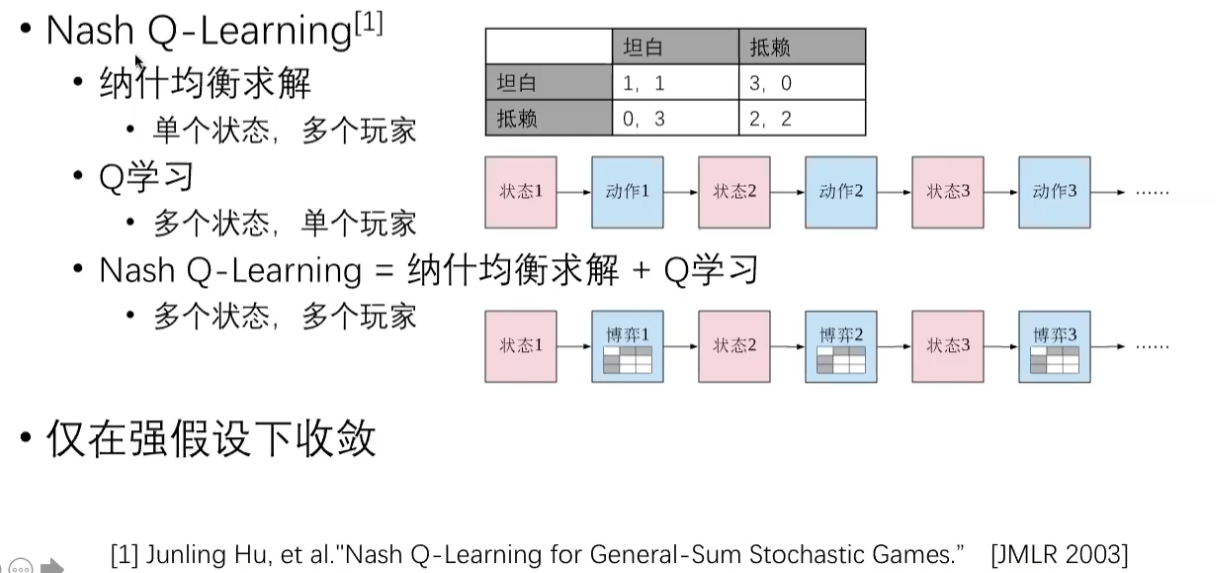
markov game的nash均衡求解算法:Nash Q-Learning
- 学习目标:均衡
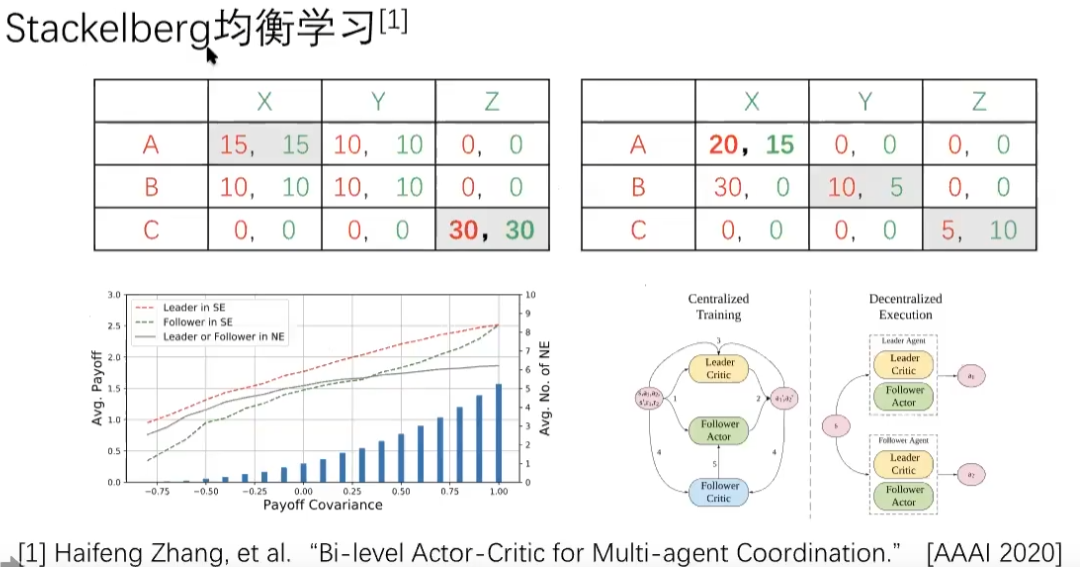
多智能体学习的处理方法有多种:协同、合作
- 学习目标:协同
PR2算法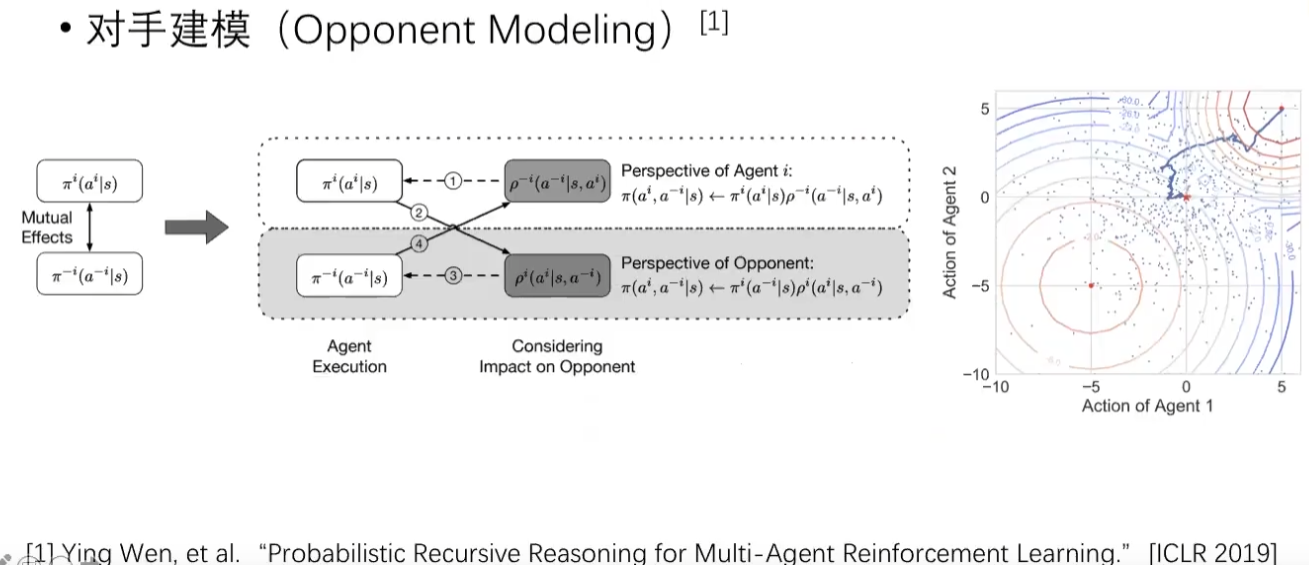
- 学习目标:合作

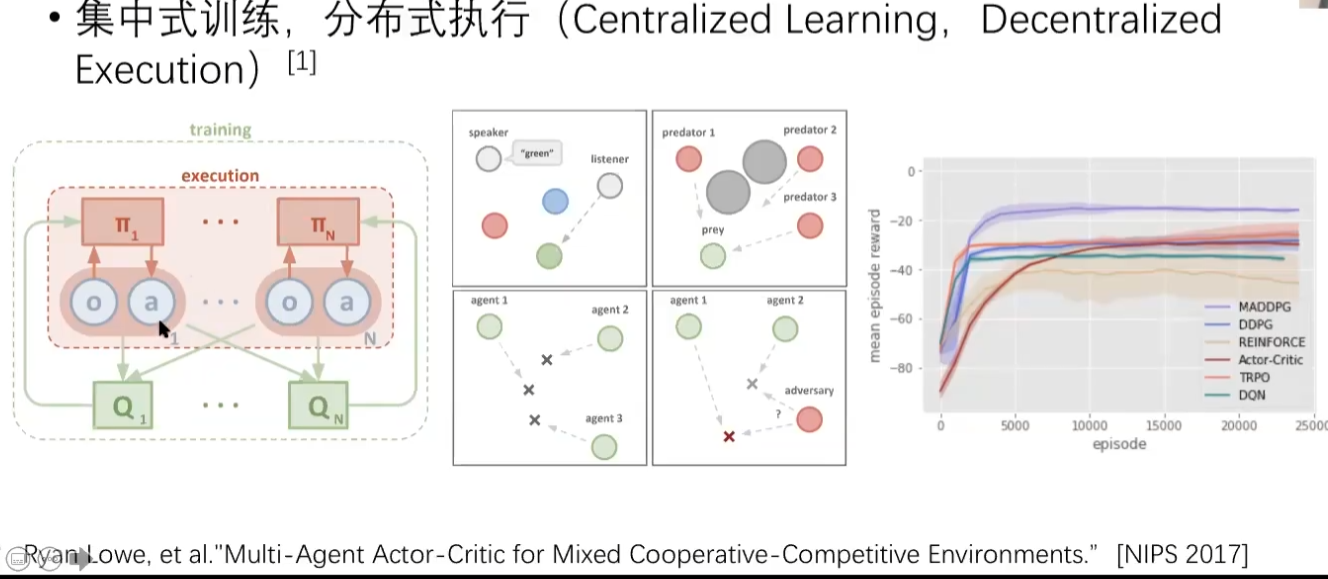
MADRL基础
- 完全合作关系 Fully cooperative
- 完全竞争关系 Fully competitive
- 合作竞争关系 Mixed Cooperative & competitive
- 利己主义 Self-interested:不会刻意帮助其他agent或者攻击其他agent,只在乎自己的收益
【这一部分可以参考Ref.7中的视频】
- 下一个状态会受所有agent动作的影响。因此Multi agent之间不是彼此独立而是相互影响。






single-agent policy learning applied to MADRL


直接应用单agent的方法到多agent的情况效果并不好: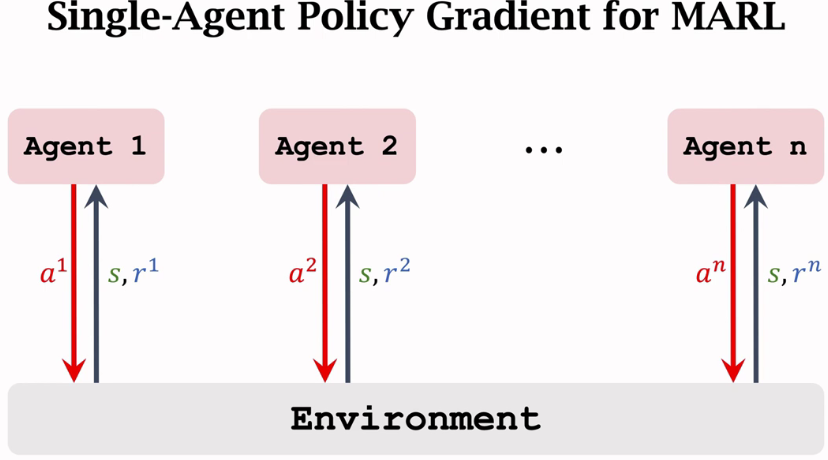



当agent A在当前环境下找到奖励最大的策略时,agent B发生了改变,对A来说,环境发生了变化,过去的最优策略未必适用。因此A会不断改变策略…这样很容易导致不收敛的问题。
当多个agent之间彼此独立时(agent的action不会影响环境对其他agent的输入)可以直接应用single agent policy gradient。
MADRL
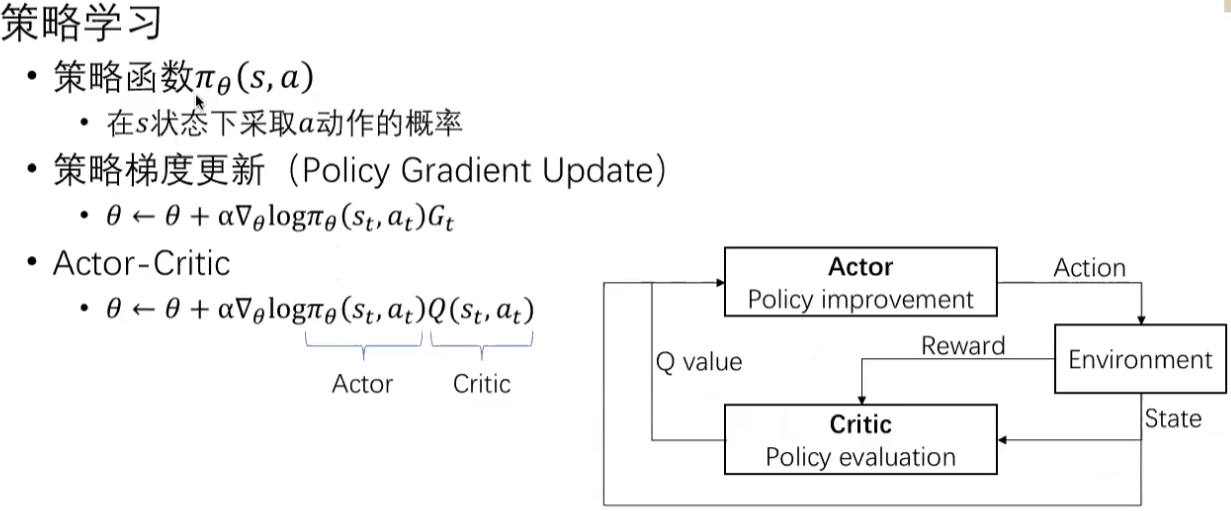
- 注意:本节需要Actor-Critic的基础。
MADRL的三种常见结构:
Multi-agent RL通常假设partial observation(不完全观测),在多智能体的情形下,MDP问题变成了POMDP问题。

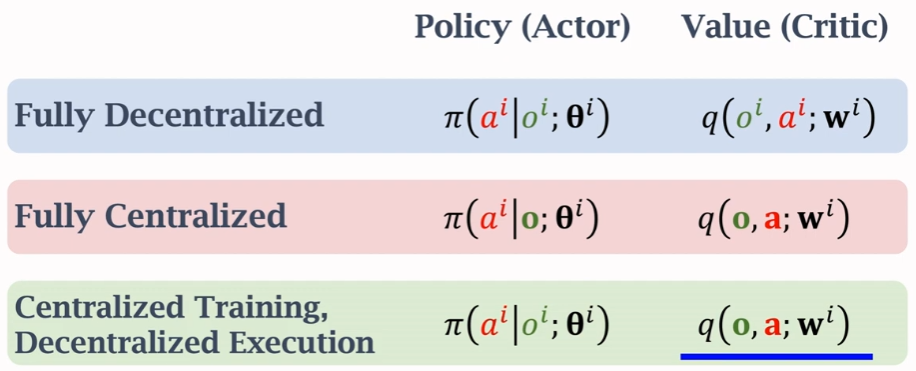
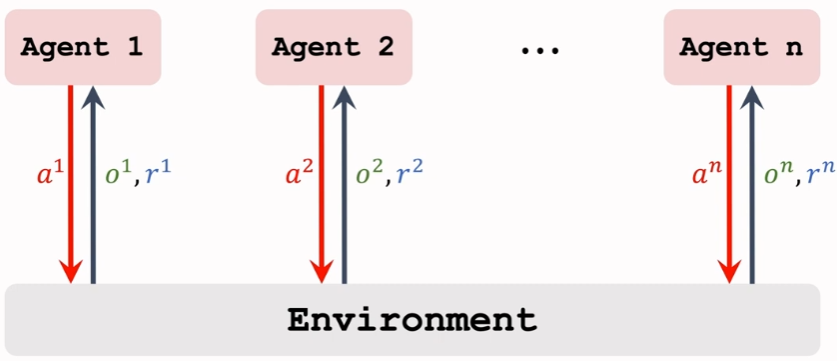
Fully Decentralized Training
这种方式是上一届介绍的single agent RL的方法处理MARL的情况。
- 训练:
- 执行:


Fully Centralized Training
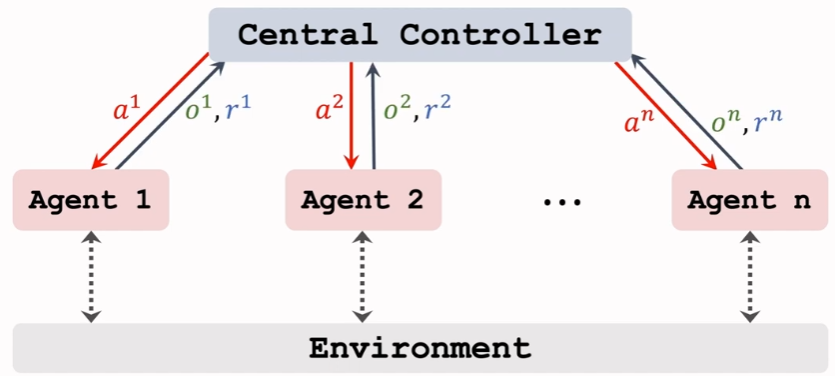
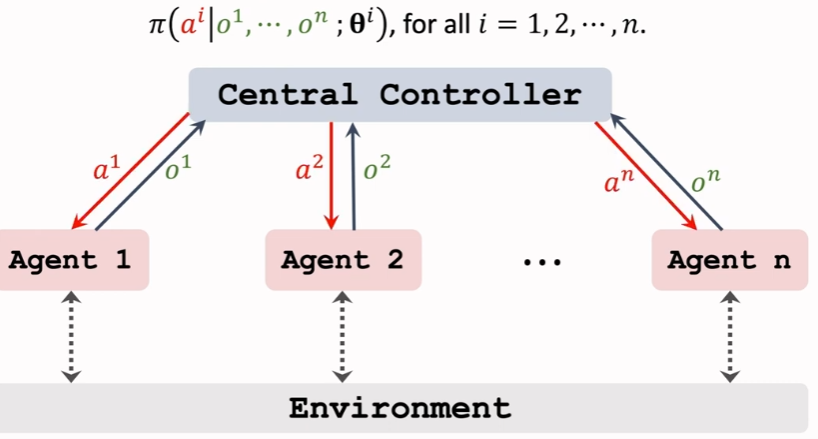


缺点:执行速度慢,边缘agent没有智能。
Centralized Training with Decentralized Execution





Parameter Sharing

展望

Reference
- openai/maddpg的github
- 在复现MADDPG的过程中遇到什么问题,是怎样解决的?
- 张海峰 讲座-从博弈论到多智能体强化学习
附介绍:
4. 博弈论入门(Game Theory)【纳什均衡、囚徒困境、纯策略纳什均衡、占优策略】
5. 博弈论入门(Game Theory)第二讲【混合策略纳什均衡、零和游戏】
6. 博弈论入门(Game Theory)第三讲【社会福利与选择函数、选举机制】
7. 多智能体强化学习(1-2):基本概念 Multi-Agent Reinforcement Learning
8. 多智能体强化学习(2_2):三种架构 Multi-Agent Reinforcement Learning

更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)