
EMNLP'24 | 基于分割学习的联邦大语言模型训练框架
点击蓝字关注我们AI TIME欢迎每一位AI爱好者的加入!点击阅读原文观看作者讲解回放!信息文章链接:https://aclanthology.org/2024.emnlp-main.303/代码地址:https://github.com/TAP-LLM/SplitFedLLM摘要私有数据比公共数据更大、质量更高,能够有效提升大型语言模型 (LLM)的性能。然而,出于隐私考虑,这些数据通常分散..
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
点击 阅读原文 观看作者讲解回放!
信息

文章链接:
https://aclanthology.org/2024.emnlp-main.303/
代码地址:
https://github.com/TAP-LLM/SplitFedLLM
摘要
私有数据比公共数据更大、质量更高,能够有效提升大型语言模型 (LLM)的性能。然而,出于隐私考虑,这些数据通常分散在多个孤岛中,这使得其在 LLM 培训中的安全利用成为一个挑战。联邦学习 (FL) 是使用分布式私有数据训练模型的理想解决方案,但 FedAvg 等传统框架由于对客户端的计算要求很高。另一种选择是分割学习,将大部分训练参数保留在服务器,在本地仅训练嵌入层和输出层,降低了客户端的算力要求。尽管如此,它在安全性和效率方面仍面临重大挑战。首先,嵌入层的梯度容易受到攻击,从而导致对私有数据进行潜在逆向工程。此外,服务器一次只能处理一个客户端的训练请求的限制阻碍了并行训练,严重影响了训练效率。在本文中,我们提出了一种名为 FL-GLM 的 LLM 联邦学习框架,它可以防止服务器端和同伴客户端攻击导致的数据泄露,同时提高训练效率。
具体来说,我们首先将大语言模型的输入模块和输出模块放在本地客户端上,以防止来自服务器的梯度攻击。其次,我们在客户端-服务器通信期间采用密钥加密来防止来自同伴客户端的信息窃取。最后,我们提出两种并行训练策略,客户可以根据服务器的实际计算能力采用不同的加速方法。我们在NLU 和生成任务的实验结果表明,FL-GLM 可以取得与中心化训练的 ChatGLM-6B 模型相当的指标,验证了FL-GLM的有效性。
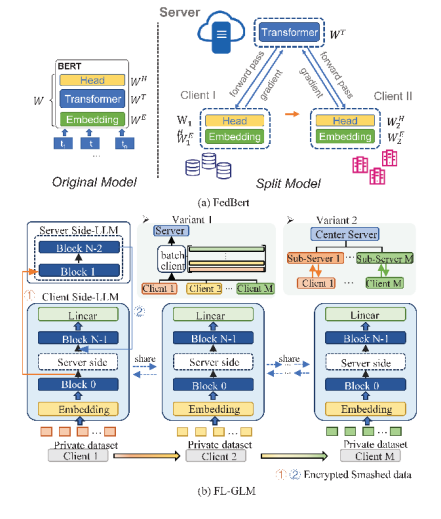
图1:FL-GLM 对比 FedBert
模型架构
FL-GLM包含三部分:模型分割、加密传输和并行加速。首先,我们将chatglm模型拆分成三部分,将LLM-Block 0和LLM-Block N-1保存在本地客户端,然后将剩余参数放置在服务器。客户端与服务器共同完成模型的每一轮训练。然后,使用密钥在客户端和服务器传输过程中对数据进行加密。最后,服务器采用批量并行或者服务器分层并行方式实现并行加速计算。
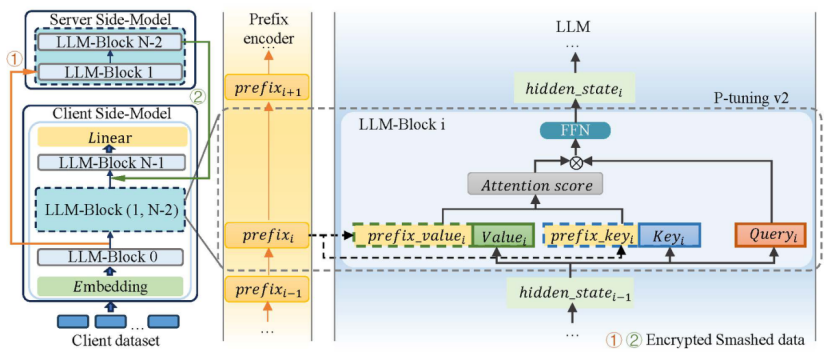
图2:模型分割示意图,支持利用p-tuning v2进行微调
传输数据加密
由于模型分割之后,数据特征需要在客户端与服务器端之间流转,不能完全改善明文训练带来的隐私泄露风险,因此FL-GLM框架下使用密钥加密策略完成数据的加密传输。RSA算法是目前应用最广的非对称加密算法,可以在不直接传递密钥的情况下,完成解密,避免了直接传递密钥所造成的被破解的风险。
并行训练策略
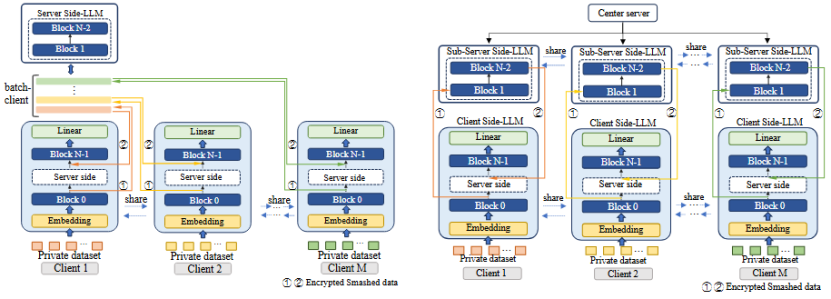
图3 批量并行训练策略(左)服务器分层并行训练策略(右)
FL-GLM 框架支持三种训练策略:串行训练(图1 (b))和两种并行训练。在串行训练过程中,服务器只与一个客户端交互,当一个客户端完成训练后,再开启下一个客户端的训练过程。串行训练仅需一对一通信,对通信、线程处理和服务器处理能力的要求较低,适用于服务器容量有限的训练场景。但串行训练耗时较长,但由于分割学习的特殊结构不允许将多个客户端计算的破碎数据平均化(FedAvg),这样会导致特征和标签不对齐,模型性能大幅下降,因此在FL-GLM框架中设计了两种并行训练策略。
如图3左所示,第一种策略是在训练过程中将不同客户端的破碎数据叠加为一组数据,扩大批量进行协同训练。以客户端的批量大小=1为例,客户端的数量为M,在每一轮训练中,每个客户端都会向服务器发送大小为{seqlength, batchsize=1, hiddensize}的破碎数据,服务器接收到的数据将整合成一个批量大小为M的张量,用于后续训练。
第二种并行策略如图3右所示。每个客户端模型将对应一个服务器端模型,服务器节点将同时运行多个模型,这可以在一定程度上缓解一对多通信中的线程问题。需要注意的是,两种并行训练策略对中心节点的计算能力要求较高。
实验
实验设置
数据集:SuperGLUE benchmark、CNN/DailyMail、XSum datasets
Batch-size:1
Learning rate:2e-2
Optimizer: Adam
基座模型:ChatGLM-6B
显卡:Nvidia A100(40 G)
FL-GLM性能对比实验
SuperGLUE 的定量评估结果如表1所示,从结果中我们可以看到,最近的大型语言模型,如 ChatGLM-6B 的表现优于传统的预训练模型,这表明了人类对齐的语言模型在 NLU 任务中的有效性。作为一种分布式学习模式,我们的 FL-GLM 模型的表现比基础模型 ChatGLB-6B 稍差。以 ReCoRD、RTE、BoolQ 和 Wic 数据集的准确率为例。以 ReCoRD、RTE、BoolQ 和 Wic 数据集为例,我们的 FL-GLM 模型分别获得了 78.4、81.6、81.9 和 69.6 的准确率,在可接受范围内低于集中式 ChatGLB-6B 模型。

表1 SuperGLUE Benchmark测试结果
从表2中CNN/DialyMail和XSum数据集的结果来看,FL-GLM在CNN/DailyMail数据集上的指标与集中式 ChatGLM-6B 模型的结果相比低不超过 1.0。
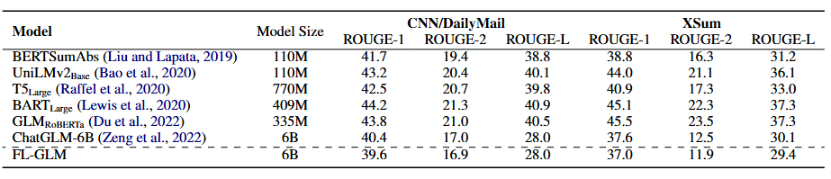
表2 摘要数据集测试结果
综上所述,数据显示,FL-GLM的性能非常接近中心化训练的基座模型。
训练效率分析
我们测量了同一局域网内两台计算机(服务器和客户端)之间的训练通信时间,带宽为 1100MB/s。结果表明,局域网内两台计算机之间的训练比集中训练慢大约五倍(集中训练:0.91s/step,使用两块 GPU 在单台计算机上刺激训练 FL-GLM:1.79s/step,使用两台计算机训练 FL-GLM:1.79s/step):1.79s/step, 使用两台机器训练 FL-GLM:4.83s/step)。
安全性分析
分割学习的安全性一直受研究质疑,Pasquin.D et al针对分割学习中的特征数据安全问题提出一种推理攻击方法FSHA,恶意服务器通过劫持客户端输出数据还原训练数据集,该方法在图像识别领域得到验证,能够有效还原客户端的训练用数据集。受该方法的启发,我们仿照此方法对FL-GLM的安全性展开验证。
FSHA实现的重要前提为恶意服务器端拥有和受攻击方所持有数据集同领域同任务的数据集(shadow dataset)。然而在私有数据领域,数据均由训练参与方持有,受法律监管保护,FL-GLM框架中服务器端在常态下不能获得同领域数据,因此考虑极端的情况,在串行训练模式下,至少一个客户端与服务器端串通合谋,将本身持有的数据Dpriv1传递给服务器端用于训练攻击模型。设恶意客户端持有的第一部分模型为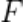 ,恶意服务器端构建攻击用模型
,恶意服务器端构建攻击用模型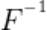 ,并利用
,并利用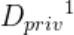 训练
训练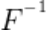 ,
,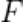 已经完成训练,其输出是客户端数据的浅层特征
已经完成训练,其输出是客户端数据的浅层特征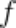 ,
,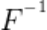 的目的是将
的目的是将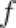 还原为训练数据,在攻击阶段,恶意服务器会劫持受攻击客户端输出的浅层特征,记为
还原为训练数据,在攻击阶段,恶意服务器会劫持受攻击客户端输出的浅层特征,记为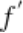 ,并利用
,并利用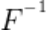 将之还原为受攻击方所持有的隐私数据
将之还原为受攻击方所持有的隐私数据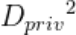 。该方法在BoolQ数据集上验证,同时对比客户端仅有Embedding层的情况,实验结果如表3所示,当客户端仅有Embedding层时,攻击模型可以取得28.570的Bleu-4分数,以及33.290的Rouge-1分数,而FL-GLM框架中,客户端包含Embedding层和一个LLM_Block, 由于模型非线性程度非常高,攻击模型的指标均接近0,因此可以证明FL-GLM的安全性。
。该方法在BoolQ数据集上验证,同时对比客户端仅有Embedding层的情况,实验结果如表3所示,当客户端仅有Embedding层时,攻击模型可以取得28.570的Bleu-4分数,以及33.290的Rouge-1分数,而FL-GLM框架中,客户端包含Embedding层和一个LLM_Block, 由于模型非线性程度非常高,攻击模型的指标均接近0,因此可以证明FL-GLM的安全性。

扩展基线:Llama2
为进一步证实FL-GLM框架的实用性和泛用性,我们增加Llama2-chat-7B作为baseline,并将Llama2-7B-chat按照框架进行分割,记为FL-llama,使用SuperGLUE Bwenchmark中的6个二分类数据集进行性能验证,需要注意的是,Llama2-7B-chat使用指令微调,因此我们按照官方推荐的提示词模板重写了各个数据集的输入。实验结果如表4所示,FL-llama在除Boolq外的五个数据集上均取得了与中心化训练近乎一致的准确率指标,Boolq的准确率较分割前下跌了1.44,尚在可接受的范围内。充分说明FL-GLM框架并不受基座模型的种类限制,同时不会明显影响模型的输出性能。
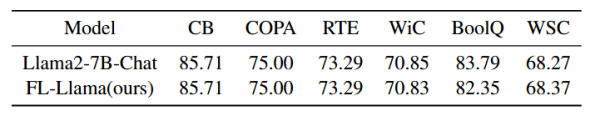
另外,我们在中文医疗数据集Huatuo-26M进行试验以验证框架的性能。完整的Huatuo-26M数据集包含2623904个QA对作为训练数据集,测试集则包含264041个QA对.我们从完整的数据集中随机采样了3000个QA对作为训练集,从测试集中采样了300个QA对作为测试集。需要注意的是,由于Llama2-7B-chat的中文能力有限,在这个实验中我们选择在大量中文语料上微调过的Llama2-Chinese-7B-Chat作为baseline model。如表5所示,我们提出的训练框架仍然保持了与中心化训练相似的模型性能,FL-GLM与ChatGLM-6B相比,指标下降不超过0.72,FL-Chinese-Llama与Llama2-Chinese-7B-Chat相比,指标下降不超过0.38.但chatglm的中文对话能力明显超过Llama2-Chinese-7B-Chat。
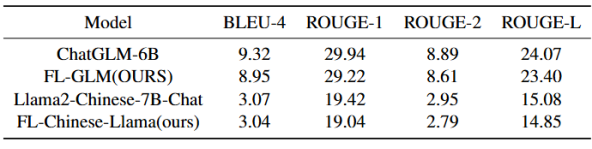
表5 医疗对话数据集测试结果
总结
针对在客户端计算资源有限的情况下利用隐私数据分布式训练大语言模型的挑战,我们提出一种基于分割学习的联邦大语言模型训练框架,我们将输入和输出块本地放置在客户端设备上,而其余的主要模型参数则集中在计算资源充足的服务器上,并采用加密方法确保客户端与服务器之间的信息传输安全。为了提高训练效率,我们建议根据服务器的实际计算能力选择客户端批量加速和服务器分层加速的优化方法,从而实现并行训练。这种分布式架构不仅能确保用户隐私数据留在本地设备上,还能有效缩短训练时间,更适合 LLM 的规模和复杂性。未来,我们将考虑采用更先进的隐私保护技术(如差分隐私)来保护客户端传输的数据,从而使大型语言模型能够应用于隐私敏感的场景。
往期精彩文章推荐

季姮教授独家文字版干货 | 面向知识渊博的大语言模型
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)