
强化学习与 PyTorch【1.0】
其实,在本书的开头就给人工智能下定义是不合适的, 因为定义下得不好, 很可能会误导读者。但是, 对人工智能的定义没有基本的认识, 也是一件很麻烦的事情,因为很可能没过多久就会有读者开始纠结于“这种人工智能够不够智能”“这个东西配不配叫人工智能” 这样基本的而充满争议的问题了。需要注意的是,机器学习也好,人工智能也罢,这两个词汇本身就在无形中给人一种误导。它们让人们觉得, 机器是自己在学习的, 由人
第 1 章 强化学习是什么
强化学习( Reinforcement Learning) 是一个独立的机器学习研究领域。为了让大家有比较直观的感受, 本书将对强化学习和机器学习的一些研究领域进行对比讨论。请原谅我的啰唆,因为有些时候, 只有铺垫足够多, 路走起来才足够稳。
先说说监督学习( Supervised Learning)。 监督学习是一个比较传统的机器学习研究领域。简单概括, 监督学习主要希望研究映射关系𝑦𝑦 = 𝑓𝑓(𝑥𝑥|𝜃𝜃).
这其实是一个我们在中学时就见过的函数,唯一陌生的是 𝜃𝜃 ——它是待定系数。具体来说,有一个确定了系数的函数和一个确定的 𝑥𝑥, 得到一个确定的 𝑦𝑦 是顺理成章的事情。 例如, 有 𝑦𝑦 = 2𝑥𝑥 + 3, 给我一个 𝑥𝑥 的值, 让我求出对应的 𝑦𝑦 值, 当然很容易——如果 𝑥𝑥 = 2, 那么 𝑦𝑦 = 7, 这里的 𝜃𝜃 就是 𝑥𝑥 前面的系数 2 和后面的常数项 3。
如果我们实际观测到的值只有 𝑥𝑥 = 2、 𝑦𝑦 = 7, 但不知道 𝜃𝜃 的值, 希望通过一系列科学的办法“反向”推导出 𝜃𝜃 的值, 那么, 这就属于机器学习的研究范畴了。 在这个例子中, 可以在给定足够数量的样本的情况下, 也就是说, 在有足够的 𝑥𝑥 和对应的 𝑦𝑦 的值的时候, 尝试用线性回归的方法求出 𝜃𝜃 的值。 将已知输入变量 𝑥𝑥 和输出变量 𝑦𝑦 的值作为参数, 逐步求出待定系数 𝜃𝜃 的过程, 就是训练( Training) 过程。当通过这样一个过程学习到 𝜃𝜃 应该为什么值之后, 如果再有 𝑥𝑥 出现,就可以通过函数 𝑦𝑦 = 𝑓𝑓(𝑥𝑥|𝜃𝜃) 计算出 𝑦𝑦 的值。 这就是监督学习的实际工作方式, 这个例子就是典型的监督学习中的线性回归( Linear Regression) 问题。 这个过程的具体实现方法, 将在 6.3 节中详细介绍。
再说说非监督学习( Unsupervised Learning)。 非监督学习也是一个比较传统的机器学习领域。在机器学习入门阶段使用最多的算法 K-Means, 就是一个典型的非监督学习算法。例如, 在一个空间中, 有很多的空间点向量( Vector) ①,这些点在这个空间中的分布很可能是不均匀的。 是否可以通过一个算法来求出它们各自的分布究竟聚集在哪些空间区域附近? 是否可以找出这些空间区域的中心点的具体位置?答案是: 可以。在这个过程中,我们只需要告诉计算机我们要把这些空间中的点分成几个聚类( Cluster), 甚至不用告诉计算机我们要把这些点具体分成哪几个聚类,计算机就能对这些空间点向量进行聚类的划分。
如图 1-1 所示, 空间中不均匀地分布着一些点, 通过 K-Means 算法可以计算出它们分别聚集在三个点周围( 或者说“聚成了三堆”)。
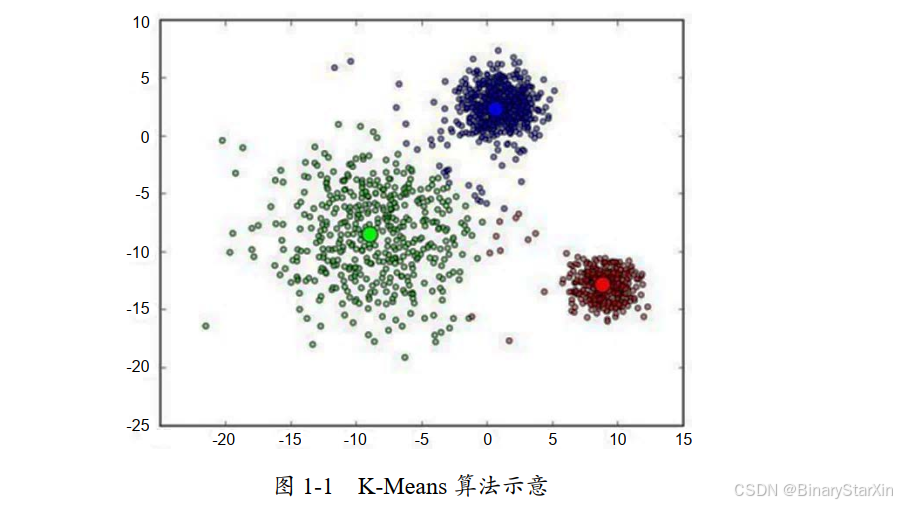
我们可以研究这三个聚类中的点都有哪些共性, 也可以研究哪些点没有在这些聚类中或远离这些聚类中心。 这样的应用场景在现实生活中是很多的。 例如,能不能把用户的年龄、收入、贷款金额等数据绘制成这样的图像,通过聚类的方式找出用户人群的分布,然后针对不同的人群尝试设计相应的产品或业务,以分别满足他们的需要? 这可比自己抱着脑袋绞尽脑汁冥思苦想要科学得多。
当然, 我们还可以通过这种方法来研究那些不属于任何类的、 飘在所有类之外的“离群点”。离群点的研究也是有价值的,因为它们太特殊了。 它们为什么特殊? 是数据收集系统本身的问题导致的特殊性,还是这个点本来就是一个“异类”(例如诈骗事件的特征点描述)? 这些都是可以研究的思路。
显然, 这个过程与研究 𝑦𝑦 = 𝑓𝑓(𝑥𝑥|𝜃𝜃) 的过程( 需要知道 𝑥𝑥 和 𝑦𝑦 的具体值, 才能完成整个训练过程)不一样。 在这个例子中, 我们只需要知道 𝑥𝑥 是什么就够了—— 𝑥𝑥 就是空间中的一个个点。还有很多机器学习的研究领域,例如迁移学习( Transfer Learning)、 生成对抗网络( Generative Adversarial Networks, GAN)等以不同建模方式或思考角度来解决问题的方法论。在这里, 我之所以不愿意称它们为“算法”, 而愿意称它们为“模型体系” 或“方法论”, 是因为它们确实已经各自拥有了一套较为完整的处理数据、 建模、 训练、 调优的套路。 它们中也包括本书的主角——强化学习。
1.1 题设
强化学习是为了解决哪些问题而设计的?在人工智能领域,我们其实一直希望机器人足够智能。这里的“智能” 是指让计算机拥有比较好的推理、判断、分析能力, 并基于这些能力自动进化, 最终胜任人类交给它们的任何任务——最理想的状态, 就像阿诺德· 施瓦辛格 ①和克里斯塔娜·洛肯 ②主演的《终结者》( The Terminator) 系列电影里的未来机器人那样。可以说,和我同龄的“80 后” 中的很多人都是在这类科幻作品的启蒙下, 对人工智能产生了懵懂的感觉。《终结者》系列电影的第一部是 1984 年在美国上映的,看这部电影时我已经上大学了,大概在 2002 年。 在那时的我看来, 电影中的机器人简直无所不能——全天候工作、刀枪不入、变形自如……在那个时候, 我脑子里对人工智能的概念是:像“终结者” 这样的高智能人形机器人, 应该是未来某个时刻的研究目标,也八成是大学或者实验室里正在研究而且没准儿哪天真的能研究出来的东西。说起来, 那时我的想法还真是天真。
我再次看到与机器人相关的电影, 已经是 2008 年了。 那也是一部极为成功的作品——《机器人总动员》( WALL-E),在豆瓣上有 9.3 分的高分评价。当时, 那部电影让我热泪盈眶。
随着年龄的增长, 虽然我不会再像第一次看《终结者》时那么“激动” 了, 但仍然免不了偷偷地想: 如果真的能造出这样的机器人, 那就太好了。同时,我也开始有意识地寻找相关资料。我真的开始好奇:在清华、哈佛这样的大学里,人工智能专业的学生都在学什么?离实现这个目标还有多远? 是不是有朝一日我们也能造出这样的机器人?
回过头来看,不得不承认, 那时自己还是太年轻。其实,在有了多年的工作经历之后,我知道, 虽然这两部科幻电影里面的机器人很难制造出来, 但它们仍然属于人形机器人的研究范畴,涉及材料学、工程力学、大规模集成电路、高精度传感器工程学等众多前沿研究领域,而算法或者机器学习在其中只占很小的一部分——很小, 很小。
在此,应该正式提出我的观点了:人形机器人不是强化学习研究的重点和难点,或者说, 当前强化学习研究和落地的领域及其擅长解决的问题并不在人形机器人这个方面。不过, 这并不会让我原本在强化学习领域积累的浓厚兴趣有一丝一毫的减弱,因为我仍然看到了基于海量样本训练的阿尔法围棋( AlphaGo) 那令人惊叹的表现。
也许有些人会说, 如今在互联网应用中已经出现了很多优秀的作品,不论是人脸识别( Face Recognition)、物体识别( Object Detective), 还是智能相机的美图、 美颜功能 ③等,不都是通过样本积累一点一点地进步, 最终满足我们对产品的要求的迭代过程吗?刚刚说过的那些问题,能够通过强化学习来解决吗?两者有本质的区别吗?我想, 在表达自己的观点之前, 有些事情还是要和大家讨论清楚,这样我们在进入这本书的主要内容之前才能有足够的共识。
1.1.1 多智能才叫智能
到目前为止, 不仅在学术界, 甚至在工业界, 仍然有不少人在争论——他们总会觉得某一种或某一类算法更为智能, 或者更贴近智能的本质。
例如, 据我所知, 有很多人对本书的主角强化学习格外痴迷, 觉得它才是实现人工智能的唯一靠谱途径( 因为它的推理过程是那么优美和自然)。 好吧, 我不反对这些人对强化学习优美和自然的推理过程的称赞,因为这是事实。
也有相当一部分人认为, 深度神经网络在形态上酷似人类的神经网络, 是仿生学对人体神经结构的顶礼膜拜在计算机领域的完美落地。 确实, 这种结构在近些年的发展给我们带来了太多的惊喜与幻想。
还有一些人认为,只有像遗传算法这样的算法才能体现大自然优胜劣汰、 适者生存的本质进化原理, 因此有了“万般皆下品,唯有遗传高”的另类思路。我在工程中使用遗传算法的经验,确实让我多次体会到了遗传算法的优势, 例如大大减少计算量、 对于 NP 问题 ①等复杂问题有着极高的提升效率的作用。
然而, 刚刚提到的这些方法论或者算法族真的都体现了不容置疑且最为本质的智能体进化的原理特性吗? 我并不这么认为。 尤其是神经网络和遗传算法, 它们仅仅是在“望文生义” 的层面从人类神经网络和 DNA 遗传的角度进行的略显生硬的模仿, 勉强做到了“形似”, 谈不上理解并复现人类智慧进化的精华。要知道,在生命科学层面的认知上,人类还有很长的路要走。人类对自己的认知和了解的过程,其难度就像自举——自己抓着自己的头把自己举起来——岂止困难,简直不可能。 现代医学对人类神经之间信号传递的了解仍是极为有限的,否则,能与人类神经嫁接的机械手臂早就问世了。 人类对遗传因子理解的局限也是这样的。 不说别的, 仅转基因这样一个已经被科学家宣布“破译” 的遗传因子应用子领域, 还是令很多人忧心忡忡。 这样一个看似被“破译”了的“上帝密码” 在被我们诵读时带来的不和谐音符, 已经让很多人看到了恶果——大家可以自己去网上找找有关孟山都 ②的新闻。我个人从来不相信“阴谋论”, 即使技术层面真的有问题,也是人类在自然面前的不自量力导致的。那么, 我们还能拍着胸脯说自己理解了智慧生物的承载本质吗?从这个角度说这些技术是“形似”, 都是客气的。
1.1.2 人工智能的定义
其实,在本书的开头就给人工智能下定义是不合适的, 因为定义下得不好, 很可能会误导读者。但是, 对人工智能的定义没有基本的认识, 也是一件很麻烦的事情,因为很可能没过多久就会有读者开始纠结于“这种人工智能够不够智能”“这个东西配不配叫人工智能” 这样基本的而充满争议的问题了。
需要注意的是,机器学习也好,人工智能也罢,这两个词汇本身就在无形中给人一种误导。它们让人们觉得, 机器是自己在学习的, 由人制造出来的这个“智能”的东西自己有分析、 思考、进化的能力。因此, 很多非业内人士会把这两个词背后的含义无限生发、 放大、 再放大。 其中的“乐观” 者觉得,在未来, 机器人会非常厉害,什么都能做,什么都能自动完成,人类可以让机器人来伺候了; 而“悲观” 者则认为, 人工智能会厉害到要么让人类“下岗”, 要么直接统治地球、统治宇宙的地步……在我看来,这真的是一种误解——就像以理解畜力生产的方式去理解内燃机的工作原理, 以理解老婆饼的方式来理解老婆……望文生义害死人。
前两年, 我参与了一个图像识别项目, 其中的一个项目组为了让一个神经网络能够认出视频中的物体, 找了一群大学生来做打标签的工作(标出图片中的物体是什么东西、 在什么位置), 然后把数以万计打了标签的图片放到网络中去训练, 从而让网络正确识别这些被标记物体的位置和分类。 在这个过程中,超过 60% 的人工数(人×天) 花在了标记样本上。当时, 业界还有几个从事相关领域研究的大型机构,在这些机构的工作人员中间流传着这样一句话: 有多少“人工”, 就有多少“智能”。 我当时说话可能更刻薄一些——这完全就是“人工”,哪儿来的“智能”。 然而,不管怎么样,这种方法被验证了,它工作起来笨拙却有效, 所有的公司和团队都可以用这种方式来复现深度神经网络应用中的监督学习过程。它让深度神经网络在迭代中不断提高自身的准确率( Accuracy),并最终在线上环境中自动工作,从而满足工程的需要。那么,这究竟算不算人工智能呢?
还是不着急回答这个问题。 我们来追思计算机界的一位前辈——艾伦·麦席森·图灵 ①。 他曾经有一个很有趣的测试假设,被称为图灵测试( The Turing Test)。 将测试者(一个人) 与被测试者( 一台机器)隔开, 由测试者通过一些装置( 例如键盘)向被测试者随意提问。进行多次测试后,如果有超过 30% 的测试者不能确定被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。
从广义上讲, 如果人类通过有限的人机交互过程后发现, 有相当比例的人无法判定与其交互的究竟是人还是机器, 这台机器就通过了图灵测试, 或者被称为具有人类智能。
乍听起来貌似没什么问题, 不过不知道大家有没有注意到, 在这里, 图灵虽然提出了很多限制条件, 但完全没有提到这台机器是否理解了交互过程的真正含义, 也没有提到这台机器是否要跟人类一样具备这种在交互中确实存在的情绪。 换句话说, 在这个由机器和人进行的自动化互动过程中, 只要人无法判断被测试者是否是机器, 就可以判定这台机器拥有人类智能, 至于什么理解含义啊、 充满智慧啊, 并不在考虑范围内。
这意味着什么呢? 这意味着: 这种人工智能仅仅是一个高质量的自动化过程, 只要它能在人类关心的范畴高质量地完成作业就够了。 没错, 现在我们研究的所有人工智能项目,无论复杂还是简单, 无论高深还是浅显,只要它能够在应用范畴提高自动化程度、 降低错误率, 或者能在错误率与人类相当的情况下极大地提高处理效率,给出的结果和我们期望中由一个人来完成工作的结果很接近, 就可以了。这些高质量的自动化过程,都应该属于人工智能的范畴。当然,这不能与我们所说的“智慧” 画等号, 因为此刻我们只是在就事论事地讨论“人工智能”。
1.2 强化学习的研究对象
我们来讨论一下强化学习的研究对象有哪些。
1.2.1 强化学习的应用场合
可能有心急的读者会问: 你说了这么半天, 该开始说说强化学习的研究对象都有哪些了吧?别急, 这就开始。
强化学习的主要目的是研究并解决机器人智能体贯序决策问题。 尽管我不喜欢直接把定义硬邦邦、 冷冰冰地扔出来让大家被动接受,可还是免不了要在这里猛然给出“贯序决策”这么专业的词汇。 好在, 很快我就能通过例子把这个词汇给大家解释清楚了。既然大家要么是程序员, 要么正走在程序员养成的路上, 要么正看着其他人走在程序员养成的路上, 那么, 按照程序员的思维来理解强化学习将会更加顺畅。
把“贯序决策”翻译成“白话”就是:强化学习希望机器人或者智能体在一个环境中,随着“时间的流逝”,不断地自我学习,并最终在这个环境中学到一套最为合理的行为策略(如图 1-2所示)。在这样一个完整的题设下,机器人应该尽可能在没有人干预的情况下,不断根据周围的环境变化学会并判断“在什么情况下怎么做才最好”,从而一步一步完成一个完整的任务。这样一系列针对不同情形的最合理的行为组合逻辑,才是一个完整的策略,而非一个简单而孤立的行为。
没错,这就是强化学习要研究并解决的问题。我想,可能已经有一些爱动脑筋的读者在心中暗暗反驳我了:这类问题一定要用强化学习来解决吗?我怎么觉得不用强化学习也能解决呢?
既然产生了这样一个争议,那我们先不去想是否一定要用人工智能这么“高大上”的工具来解决这类问题,而去想想自己以前有没有处理过类似的问题。如果一时想不起来,也没关系,请跟我看一个例子。
为了简化问题,假设我所在城市的道路是横平竖直的, 各街区的边长相等, 如图 1-3 所示。外侧的边框表示城墙,车辆无法通过。中间的方块表示街区,街区和街区之间就是道路。为了称呼方便,我们用英文字母 A~ E 来标记纵向的道路,用数字 1~ 4 来标记横向的道路,并约定 A 大街和 1 大街交汇处的坐标为 A1(也就是 START 处)。 圆圈中的数字表示我们用 GPS 或者其他手段测算出来的当前道路的拥堵程度, 1 表示通畅, 9 表示拥堵, 也可以具象地将圆圈中的数字理解为通过某段道路需要 1 分钟到 9 分钟不等——总之,怎么理解简单怎么来。
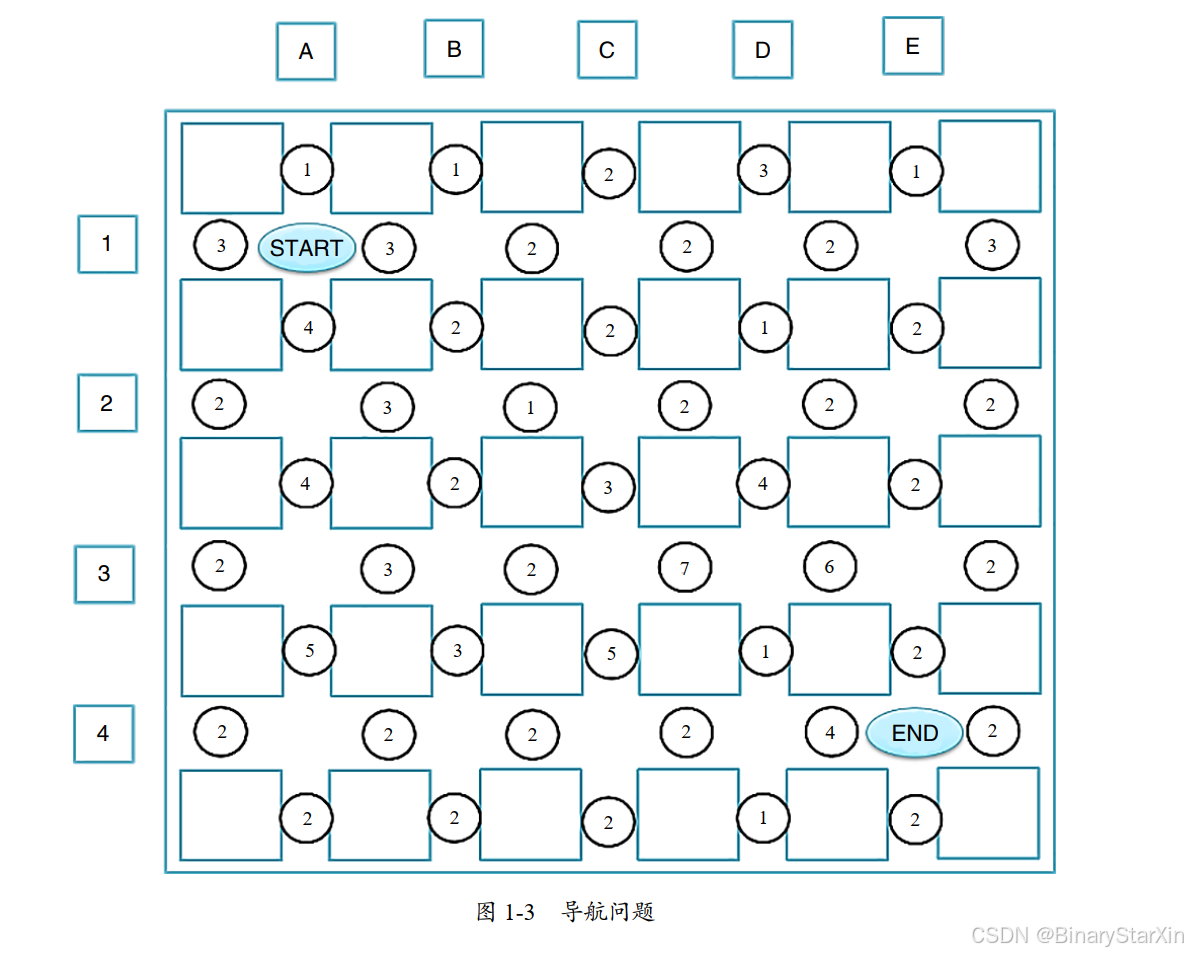
现在,我准备从 START 处去往 END 处,我需要一个“智能”的软件为我导航。这个问题难吗?如果你接触过与数据结构相关的课程,那么你一定会觉得这是一个非常简单的问题——就是图论里的图遍历问题或者树遍历问题。
该导航软件预设不会给出走回头路的方案(以免进入死循环)。以 START 处为起点,我可以向上、下、左、右各走一个街区的距离:向左和向上走会到达城墙,不能再走;向右走到 B1 处,有三条路可以走;向下走到 A2 处,还有三条路可以走。所以,如果把这个问题当作一个树遍历问题,树的前两层应该非常容易构建出来。
如图 1-4 所示: X 表示走回头路或者“撞墙”,这样的路是不能走的,其下面的树结构也就不存在了; A1、 B1 等交汇位置的节点则表示该处可以前往,并标注了该处之后的走法。这样一层一层往下标,最多能标出多少层呢?不清楚,要仔细算算才能知道。但可以确定的是,只需要 8 层就可以完成从 START 处( A1)到 END 处( E4)的行进,而且走法不止一种。
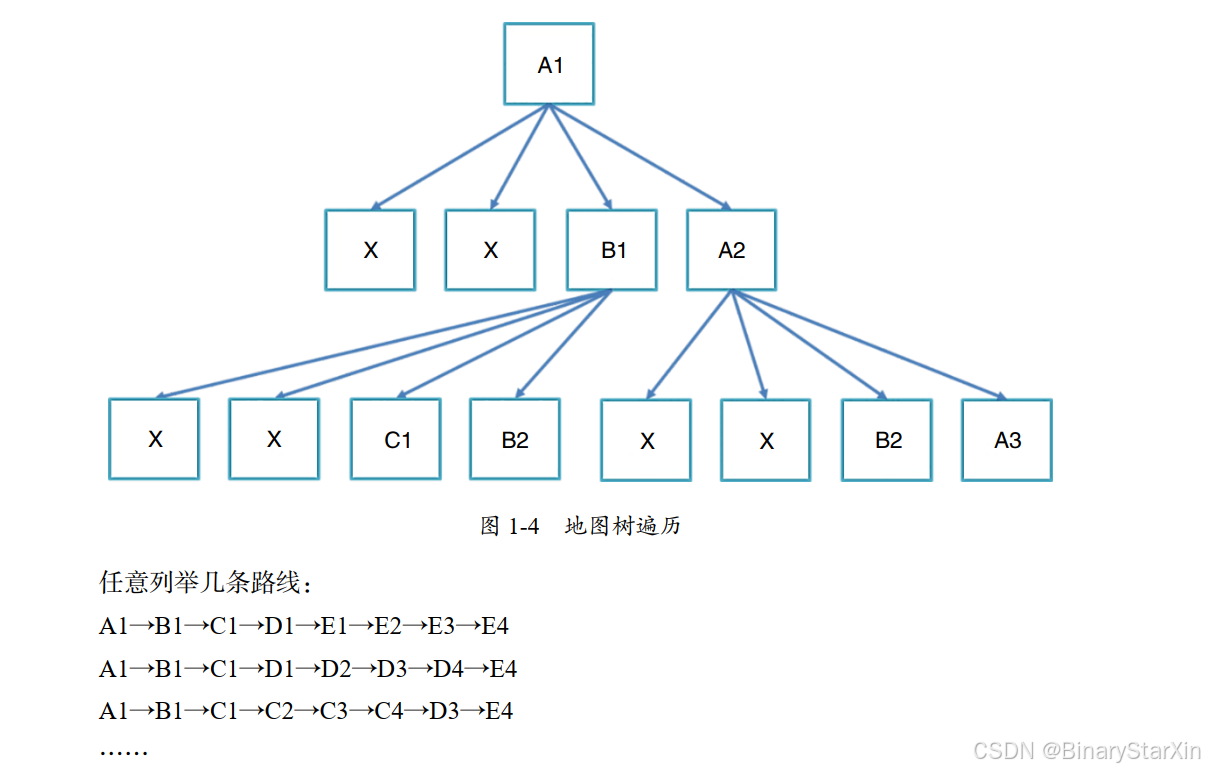
我们不仅可以把这些路线一一列举出来,还可以把经过每条路线所花费的时间算出来( 对一条路线的时间成本做一下简单的加法运算就可以了)。以路线 A1→B1→C1→D1→E1→E2→E3→ E4 为例,时间成本为 3 + 2 + 2 + 2 + 2 + 2 + 2 = 15, 也就是说, 从 START 处( A1)到 END 处( E4),走这条路线需要 15 分钟。
如果想找到最短的路径, 只要遍历路线, 计算每条路线的成本,把成本最低(或者说耗时最短)的路线挑出来就可以了。这个思路再简单不过,可以保证在当前状态下是最优解——只要不出现走到半路突然发生交通事故, 使得原本通畅的道路变得拥堵,或者原本拥堵的情况突然得到缓解。
现在,出现了两个问题。
第一, 我们很容易用一种“智能” 的方法得出这种问题的最优解,并向用户推荐这个最优解。之所以说它“智能”, 是因为它确实自动实现了路程规划和推荐,挑选的是成本最低的路径。 但是, 在这个过程中, 我没有用到任何机器学习的知识, 也没有遇到任何需要通过样本学习来生成模型、 确定待定系数的问题。 我只用计算机专业本科一年级所学的一些基础知识就已经获解了,完全没有用到人工智能的方法——好意思叫“智能” 吗?
第二,这是不是一个贯序决策问题呢?是或者不是, 这也是一个问题。我想, 可能会有两方面的意见。
认为这不是贯序决策问题的读者, 会觉得这里面根本没有决策问题, 而是纯粹的树遍历(如图 1-5 所示)问题——非常不聪明,非常不智能, 这哪里这是什么贯序决策问题!
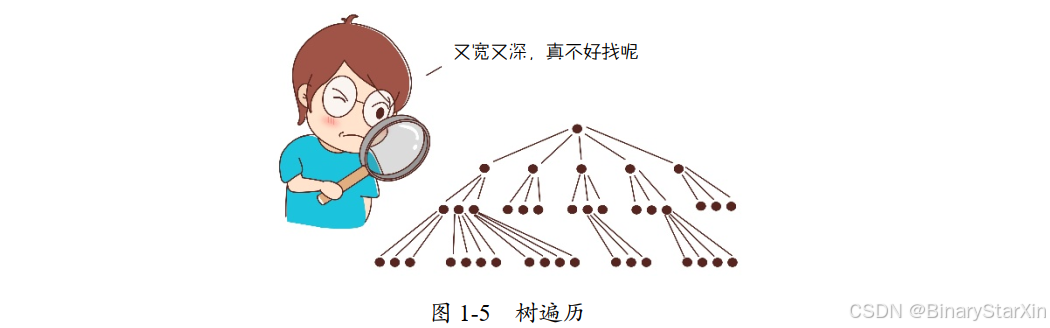
认为这是贯序决策问题的读者会觉得: 从起点前往终点,中途在任何一个可以选择路径的位置都进行了判断,而且每次都选择沿着最好的路线前进——是的, “最好”,没有“之一” ——在每个环节都进行了选择,这难道不是贯序决策问题吗?
两方的意见, 我觉得都有道理。 我不是一个喜欢咬文嚼字的人, 也不想拿着什么金科玉律去说教。问题就摆在这里, 我们要考虑的是: 用什么样的方法解决问题才是合理的。
这个导航问题,在我看来,还真可以算作贯序决策问题。第一, 它“够贯序”, 因为它是由一系列决策判断组合而成的一个完整的行车路径策略;第二, 它“有决策”, 因为在每个十字路口都有很多选择,我需要充分的理由来决定要走哪一边。这两点是事实,对不对?
或许有些读者很失望——为什么要讲这么简单的例子?我只是希望大家能通过一个简单的例子明白一个道理: 数学问题不一定非要通过极为艰深的算法和技术来解决,很多时候就是“小药治大病”, 如果能用简单的方法解决问题,确实没有必要摆弄那些复杂的算法。 反之, 为了解决一个简单的问题而引入一大堆复杂的问题, 在我看来, 不是一种值得提倡的思考和处理方式。 在解决具体的落地问题时, 要尽可能选择复杂度可控、 难度低、 理论成熟的方法。 像本节中这么特殊的贯序决策问题,在一定的限制条件下就会“退化” 成搜索问题或遍历问题。所以,别犹豫, 我们本来就应该用简单的方法去解决简单的问题。
结论已经很清晰了,刚刚这个问题就是一个贯序决策问题,只不过它是一个特例。那么, 更为普适的贯序决策场景是什么样的呢?这个问题好, 我们不妨想想看。
如果街区不是只有 A~ E 这 5 条纵向的大道和 1~ 4 这 4 条横向的大道呢?如果有 100 条横向的大道和 100 条纵向的大道,这棵遍历树会有多“高” 呢?应该最少要走 198 条路才能到达,也就是一棵 199 层的遍历树——这是非常可怕的!甚至,在很多场景中, 我们很可能无法估算具体的层数。除此之外,如果我们不清楚每条路的拥堵情况,该怎么办呢? 如果我们不能明确量化通过每条路预计需要多少分钟,该怎么办呢?
通过一系列科学的方法,对这类普适性问题进行体系性的求解方式和方法的归纳,才是这么多强化学习算法要解决的核心问题。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)