
深度学习之全连接神经网络
在使用Torch构建网络模型时,每个网络层的参数都有默认的初始化方法,同时还可以通过以上方法来对网络参数进行初始化。# 随机初始化# 均匀分布初始化# 正态分布初始化# 参数:# mean:均值# std:标准差# xavier初始化# 原理:# 1.前向传播的方差保持一致# 2.反向传播的梯度方差保持一致# 均匀分布初始化# He初始化(kaiming初始化)# pytorch框架默认使用He初
一、神经网络
我们要学习的深度学习(Deep Learning)是神经网络的一个子领域,主要关注更深层次的神经网络结构,也就是深层神经网络(Deep Neural Networks,DNNs)。所以,我们需要先搞清楚什么是神经网络!
1. 感知神经网络
神经网络(Neural Networks)是一种模拟人脑神经元网络结构的计算模型,用于处理复杂的模式识别、分类和预测等任务。生物神经元如下图: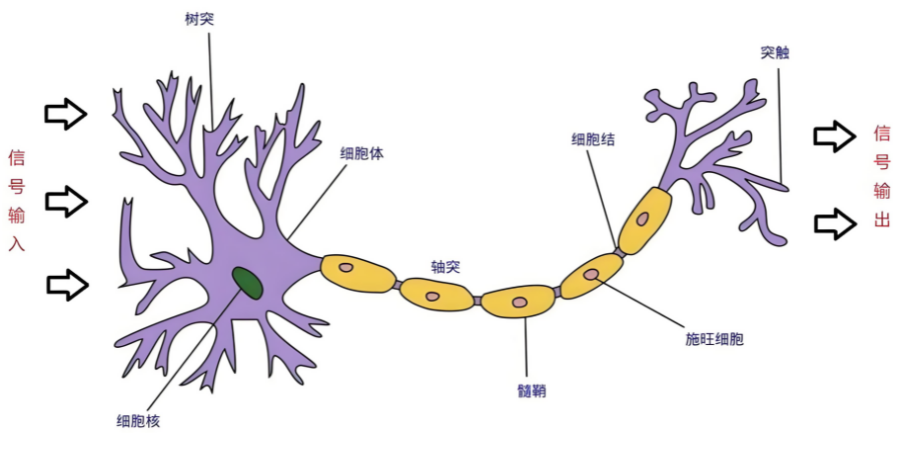
生物学:
人脑可以看做是一个生物神经网络,由众多的神经元连接而成
-
树突:从其他神经元接收信息的分支
-
细胞核:处理从树突接收到的信息
-
轴突:被神经元用来传递信息的生物电缆
-
突触:轴突和其他神经元树突之间的连接
人脑神经元处理信息的过程:
-
多个信号到达树突,然后整合到细胞体的细胞核中
-
当积累的信号超过某个阈值,细胞就会被激活
-
产生一个输出信号,由轴突传递。
神经网络由多个互相连接的节点(即人工神经元)组成。
2. 人工神经元
人工神经元(Artificial Neuron)是神经网络的基本构建单元,模仿了生物神经元的工作原理。其核心功能是接收输入信号,经过加权求和和非线性激活函数处理后,输出结果。
2.1 构建人工神经元
人工神经元接受多个输入信息,对它们进行加权求和,再经过激活函数处理,最后将这个结果输出。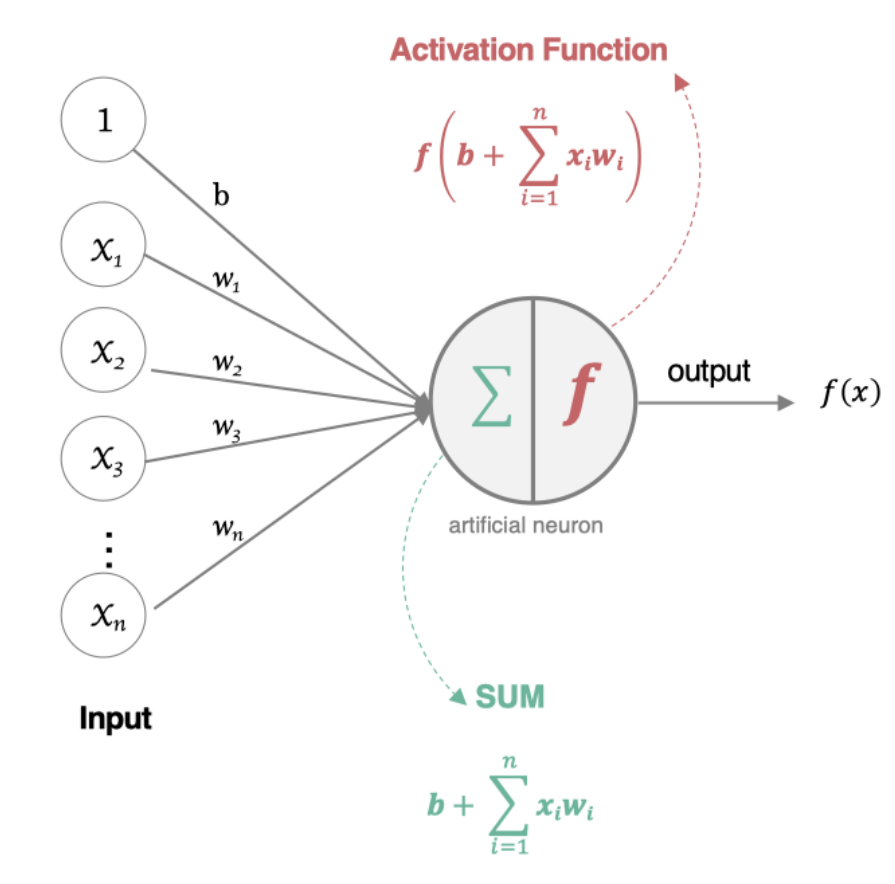
2.2 组成部分
-
输入(Inputs): 代表输入数据,通常用向量表示,每个输入值对应一个权重。
-
权重(Weights): 每个输入数据都有一个权重,表示该输入对最终结果的重要性。
-
偏置(Bias): 一个额外的可调参数,作用类似于线性方程中的截距,帮助调整模型的输出。
-
加权求和: 神经元将输入乘以对应的权重后求和,再加上偏置。
-
激活函数(Activation Function): 用于将加权求和后的结果转换为输出结果,引入非线性特性,使神经网络能够处理复杂的任务。常见的激活函数有Sigmoid、ReLU(Rectified Linear Unit)、Tanh等。
2.3 数学表示
如果有 n 个输入 x_1, x_2, \ldots, x_n,权重分别为 w_1, w_2, \ldots, w_n,偏置为 b,则神经元的输出 y 表示为:
其中, 是激活函数。
例如:
线性回归:
线性回归不需要激活函数
逻辑回归:
2.4 对比生物神经元
人工神经元和生物神经元对比如下表: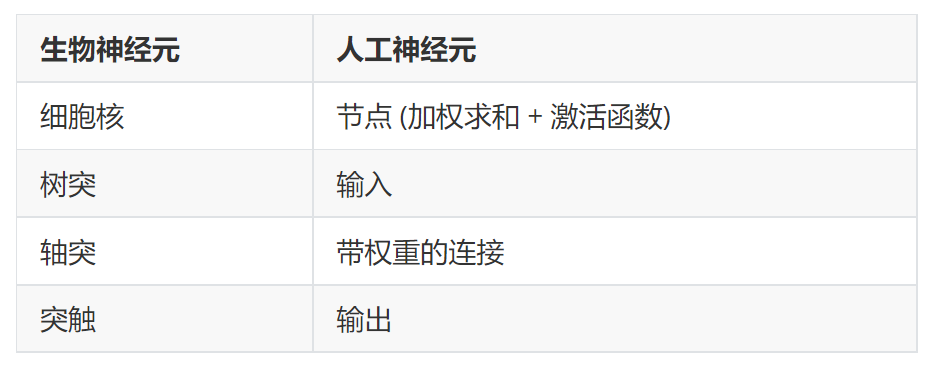
3. 深入神经网络
神经网络是由大量人工神经元按层次结构连接而成的计算模型。每一层神经元的输出作为下一层的输入,最终得到网络的输出。
3.1 基本结构
神经网络有下面三个基础层(Layer)构建而成:
-
输入层(Input): 神经网络的第一层,负责接收外部数据,不进行计算。
-
隐藏层(Hidden): 位于输入层和输出层之间,进行特征提取和转换。隐藏层一般有多层,每一层有多个神经元。
-
输出层(Output): 网络的最后一层,产生最终的预测结果或分类结果
3.2 网络构建
我们使用多个神经元来构建神经网络,相邻层之间的神经元相互连接,并给每一个连接分配一个权重,经典如下: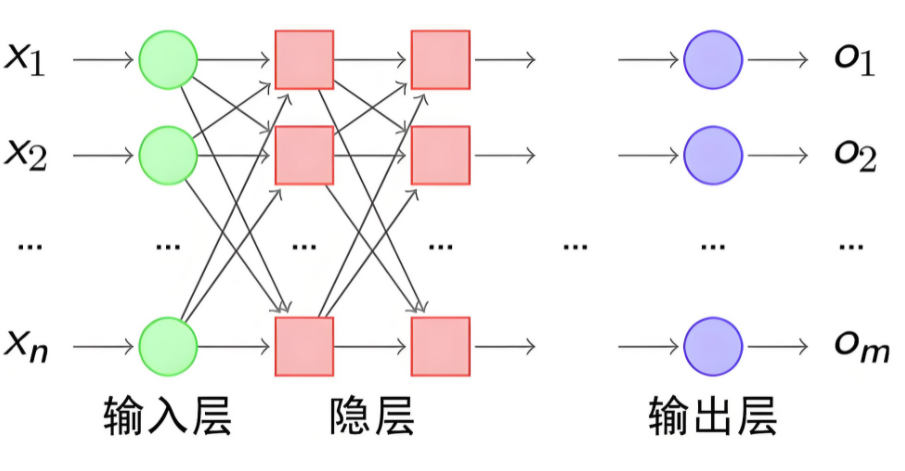
注意:同一层的各个神经元之间是没有连接的。
3.3 全连接神经网络
前馈神经网络(Feedforward Neural Network,FNN)是一种最基本的神经网络结构,其特点是信息从输入层经过隐藏层单向传递到输出层,没有反馈或循环连接。
全连接神经网络(Fully Connected Neural Network,FCNN)是前馈神经网络的一种,每一层的神经元与上一层的所有神经元全连接,常用于图像分类、文本分类等任务。
如上图,网络中每个神经元:
说明:三个等式中的w1和w2在这里只是为了方便表示对应x1和x2的权重,实际三个等式中的w值是不同的。
向量x为:
向量w:,其形状为(3,2),3是神经元节点个数,2是向量x的个数
向量z:
向量b:
所以用向量表示为:
-
x是输入数据,形状为 (batch_size, in_features)。
-
W是权重矩阵,形状为 (out_features, in_features)。
-
b是偏置项,形状为 (out_features,)。
-
z是输出数据,形状为 (batch_size, out_features)。
3.3.1 特点
-
全连接层: 层与层之间的每个神经元都与前一层的所有神经元相连。
-
权重数量: 由于全连接的特点,权重数量较大,容易导致计算量大、模型复杂度高。
-
学习能力: 能够学习输入数据的全局特征,但对于高维数据却不擅长捕捉局部特征(如图像就需要CNN)。
-
更适合单通道图,多通道图则需要将其扁平化,将其化为一维数组。
3.3.2 计算步骤
-
数据传递: 输入数据经过每一层的计算,逐层传递到输出层。
-
激活函数: 每一层的输出通过激活函数处理。
-
损失计算: 在输出层计算预测值与真实值之间的差距,即损失函数值。
-
反向传播(Back Propagation): 通过反向传播算法计算损失函数对每个权重的梯度,并更新权重以最小化损失。
3.3.3 基本组件认知
先初步认知,他们用法基本一样的,后续在学习深度神经网络和卷积神经网络的过程中会很自然的学到更多组件!
官方文档:torch.nn — PyTorch 2.7 documentation
线性层组件
nn.Linear是 PyTorch 中的一个非常重要的模块,用于实现全连接层(也称为线性层)。它是神经网络中常用的一种层类型,主要用于将输入数据通过线性变换映射到输出空间。
torch.nn.Linear(in_features,out_features,bias=True)参数说明:
in_features:
-
输入特征的数量(即输入数据的维度)。
-
例如,如果输入是一个长度为 100 的向量,则 in_features=100。
out_features:
-
输出特征的数量(即输出数据的维度)。
-
例如,如果希望输出是一个长度为 50 的向量,则 out_features=50。
bias:
-
是否使用偏置项(默认值为 True)。
-
如果设置为 False,则不会学习偏置项。
示例:构建3层全连接神经网络:在__init__方法中定义网络结构,在forward定义前向传播
如果模型中线性层按顺序叠加,也可以使用nn.Sequential构建模型。nn.Sequential 是一个顺序容器,内置了自动的前向传播逻辑,它会自动将输入数据依次传递给其中的每一层,并执行前向传播,不需要显式定义 forward() 方法。
激活函数组件
激活函数的作用是在隐藏层引入非线性,使得神经网络能够学习和表示复杂的函数关系,使网络具备非线性能力,增强其表达能力。
常见激活函数:
sigmoid函数:二分类
import torch.nn.functional as F
sigmoid = F.sigmoid()tanh函数:
tanh = F.tanh()ReLU函数:隐藏层
import torch.nn as nn
relu = nn.ReLU()LeakyReLU函数:
leaky_relu = nn.LeakyReLU(negative_slope=0.01)softmax函数:多分类
softmax = F.softmax损失函数组件
损失函数的主要作用是量化模型预测值(y^)与真实值(y)之间的差异。通常,损失函数的值越小,表示模型的预测越接近真实值。训练过程中,通过优化算法(如梯度下降)最小化损失函数,从而调整模型的参数。
PyTorch已内置多种损失函数,在构建神经网络时随用随取!
文档:torch.nn — PyTorch 2.7 documentation
根据任务类型(如回归、分类等),损失函数可以分为以下几类:
回归任务的损失函数:
1.均方误差损失(MSE Loss)
-
函数: torch.nn.MSELoss
import torch.nn as nn loss_fn = nn.MSELoss()
2.L1 损失(L1 Loss)
也叫做MAE(Mean Absolute Error,平均绝对误差)
-
函数: torch.nn.L1Loss
import torch.nn as nn
loss_fn = nn.L1Loss()分类任务的损失函数:
1.交叉熵损失(Cross-Entropy Loss)
-
函数: torch.nn.CrossEntropyLoss
cross_entropy_loss = nn.CrossEntropyLoss()-
参数:reduction:mean-平均值,sum-总和
-
适用场景: 用于多分类任务。
2.二元交叉熵损失(Binary Cross-Entropy Loss)
-
函数: torch.nn.BCELoss 或 torch.nn.BCEWithLogitsLoss
bce_loss = nn.BCELoss()
bce_with_logits_loss = nn.BCEWithLogitsLoss()-
适用场景: 用于二分类任务。
-
特点: BCEWithLogitsLoss 更稳定,因为它结合了 Sigmoid 激活函数和 BCE 损失。
-
注意:使用
nn.BCELoss时,需要确保预测值经过sigmoid函数处理。如果预测值是 logits(即未经sigmoid处理的预测值),可以使用nn.BCEWithLogitsLoss,它内部会自动应用sigmoid函数。
优化器
官方文档:torch.optim — PyTorch 2.7 documentation
在PyTorch中,优化器(Optimizer)是用于更新模型参数以最小化损失函数的核心工具。
PyTorch 在 torch.optim 模块中提供了多种优化器,常用的包括:
-
SGD(随机梯度下降)
-
Adagrad(自适应学习率)
-
RMSprop(均方根传播)
-
Adam(自适应矩估计)
核心方法有:
zero_grad():清空模型参数的梯度(将梯度置零)。必须在loss.backward()之前调用zero_grad(),避免梯度累积。
step():参数更新;是优化器的核心方法,用于根据计算得到的梯度更新模型参数。优化器会根据梯度和学习率等参数,调整模型的权重和偏置。
例子:
import torch
from torch import nn,optim
# 创建全连接神经网络步骤:
# 1.需要nn。Model抽象类:
# 2.实现__init__帆帆发,在该方法中定义网络结构
# 3.实现forward方法,定义网络结构的前向传播
class MyNet(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.fc1 = nn.Linear(in_features, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, out_features)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
def test01():
in_features = 50
out_features = 1
model = MyNet(in_features, out_features)
print(model)
# nn.Sequential快速创建神经网络
# 可以自动实现forward前向传播,默认从上到下依次加载
# 注意:在Sequential中定义网络结构时需要注意网络层的顺序
def test02():
in_features = 50
out_features = 1
model=nn.Sequential(
nn.Linear(in_features, 256),
nn.Linear(256, 128),
nn.Linear(128, out_features)
)
print(model)
# 创建单层神经网络
# 直接使用Linear创建
def test03():
in_features = 50
out_features = 1
model=nn.Linear(in_features,out_features)
print(model)
# 使用神经网络基本组件完成反向传播
def test04():
# 定义单层网络结构
model=nn.Linear(20,10)
# 定义损失函数:均方误差=((y_pred-y)**2).mean()
criterion=nn.MSELoss()
# 定义优化器,整合了梯度清零,参数更新
# 参数:
# model.parameters():模型参数-权重和偏置
# lr:学习率
opt=optim.SGD(model.parameters(),lr=0.1)
x=torch.randn(100,20)
y=torch.randn(100,10)
epochs=10
for epoch in range(epochs):
# 根据模型获取预测值
y_perd=model(x)
# 个面具预测值和真实值计算损失
loss=criterion(y_perd,y)
# 梯度清零
opt.zero_grad()
# 反向传播
loss.backward()
# 梯度下降
opt.step()
print(f'epoch:{epoch},loss:{loss.item()}')
if __name__ == "__main__":
# test01()
# test02()
# test03()
test04()二、数据准备
1. 数据加载器
分数据集和加载器2个步骤~
1.1 构建数据类
1.1.1 Dataset类
Dataset是一个抽象类,是所有自定义数据集应该继承的基类。它定义了数据集必须实现的方法。
必须实现的方法
-
__len__: 返回数据集的大小 -
__getitem__: 支持整数索引,返回对应的样本
在 PyTorch 中,构建自定义数据加载类通常需要继承 torch.utils.data.Dataset 并实现以下几个方法:
-
__init__ 方法 用于初始化数据集对象:通常在这里加载数据,或者定义如何从存储中获取数据的路径和方法。
def __init__(self, data, labels): self.data = data self.labels = labels2.__len__ 方法 返回样本数量:需要实现,以便 Dataloader加载器能够知道数据集的大小。
def __len__(self): return len(self.data)3.__getitem__ 方法 根据索引返回样本:将从数据集中提取一个样本,并可能对样本进行预处理或变换。
def __getitem__(self, index): sample = self.data[index] label = self.labels[index] return sample, label如果你需要进行更多的预处理或数据变换,可以在 __getitem__ 方法中添加额外的逻辑。
1.1.2 TensorDataset类
TensorDataset是Dataset的一个简单实现,它封装了张量数据,适用于数据已经是张量形式的情况。
特点
-
简单快捷:当数据已经是张量形式时,无需自定义Dataset类
-
多张量支持:可以接受多个张量作为输入,按顺序返回
-
索引一致:所有张量的第一个维度必须相同,表示样本数量
1.2 数据加载器
在训练或者验证的时候,需要用到数据加载器批量的加载样本。
DataLoader 是一个迭代器,用于从 Dataset 中批量加载数据。它的主要功能包括:
-
批量加载:将多个样本组合成一个批次。
-
打乱数据:在每个 epoch 中随机打乱数据顺序。
-
多线程加载:使用多线程加速数据加载。
创建DataLoader:
# 创建 DataLoader
dataloader = DataLoader(
dataset, # 数据集
batch_size=10, # 批量大小
shuffle=True, # 是否打乱数据
num_workers=2 # 使用 2 个子进程加载数据例子:
import torch
from torch.utils.data import Dataset, DataLoader, TensorDataset
from sklearn.datasets import make_regression
from torch import nn, optim
# 自定义数据集类步骤:
# 1.继承Dataset类
# 2.实现__init__方法,初始化外部的数据
# 3.实现__len__方法,用来返回数据集的长度
# 4.实现__getitem__方法,根据索引获取对应位置的数据
class MyDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample = self.data[index]
label = self.labels[index]
return sample, label
def test01():
x = torch.randn(100, 20)
y = torch.randn(100, 1)
dataset = MyDataset(x, y)
print(dataset[0])
# DataLoader:数据加载器,用来分批次加载数据,返回一个迭代器
# 参数:
# batch_size:设置每批次加载的样本数量
# shuffle:设置是否要打乱数据,True-打乱,False-不打乱
dataloader = DataLoader(
dataset=dataset,
batch_size=20,
shuffle=True
)
for sample, label in dataloader:
print(sample)
print(label)
break
# TensorDataset:pytorch提供的一个Dataset类
# 优先选择TensorDataset,如果该类不能满足需求,再考虑自定义Dataset
def test02():
x = torch.randn(100, 20)
y = torch.randn(100, 1)
dataset = TensorDataset(x, y)
dataloader = DataLoader(
dataset=dataset,
batch_size=20,
shuffle=True
)
for sample, label in dataloader:
print(sample)
print(label)
break
# pytorch实现线性回归
def build_data(in_features, out_features):
bias = 14.5
# 生成的数据需要转换为tensor
x, y, coef = make_regression(
n_samples=1000,
n_features=in_features,
n_targets=out_features,
coef=True,
bias=bias,
noise=0.1,
random_state=42
)
x = torch.tensor(x, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32).view(-1, out_features)
coef = torch.tensor(coef, dtype=torch.float32)
bias = torch.tensor(bias, dtype=torch.float32)
return x, y, coef, bias
def train():
# 数据准备
in_features = 10
out_features = 1
x, y, coef, bias = build_data(in_features, out_features)
dataset = TensorDataset(x, y)
dataloader = DataLoader(
dataset=dataset,
batch_size=100,
shuffle=True
)
# 定义网络模型
model = nn.Linear(in_features, out_features)
# 损失函数
criterion = nn.MSELoss()
# 优化器
opt = optim.SGD(model.parameters(), lr=0.1)
epochs = 20
for epoch in range(epochs):
for tx, ty in dataloader:
y_pred = model(tx)
loss = criterion(y_pred, ty)
opt.zero_grad()
loss.backward()
opt.step()
print(f'epoch:{epoch},loss:{loss.item()}')
# detach()、data:作用是将计算图中的weight参数值获取出来
print(f'真实权重:{coef.numpy()}, 训练权重:{model.weight.data.numpy()}')
print(f'真实偏置:{bias},训练偏置:{model.bias.item()}')
if __name__ == '__main__':
# test01()
# test02()
train()2. 数据集加载案例
通过一些数据集的加载案例,真正了解数据类及数据加载器。
2.1 加载csv数据集
代码参考如下
import torch
from torch import nn
from torch.utils.data import TensorDataset, DataLoader
import pandas as pd
from torchvision import datasets, transforms
def build_csv_data(filepath):
df = pd.read_csv(filepath)
df.drop(['学号', '姓名'], axis=1, inplace=True)
samples = df.iloc[..., :-1]
labels = df.iloc[..., -1]
samples = torch.tensor(samples.values)
labels = torch.tensor(labels.values)
return samples, labels
def load_csv_data():
filepath = 'datasets/大数据答辩成绩表.csv'
samples, labels = build_csv_data(filepath)
dataset = TensorDataset(samples, labels)
dataloader = DataLoader(
dataset=dataset,
batch_size=1,
shuffle=True
)
for sample, label in dataloader:
print(sample)
print(label)
break
if __name__ == '__main__':
load_csv_data()
2.2 加载图片数据集
使用ImageFolder加载图片集
ImageFolder 会根据文件夹的结构来加载图像数据。它假设每个子文件夹对应一个类别,文件夹名称即为类别名称。例如,一个典型的文件夹结构如下:
root/
class1/
img1.jpg
img2.jpg
...
class2/
img1.jpg
img2.jpg
...
...在这个结构中:
-
root是根目录。 -
class1、class2等是类别名称。 -
每个类别文件夹中的图像文件会被加载为一个样本。
ImageFolder构造函数如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)参数解释
transforms 模块提供了一系列用于图像预处理的工具,可以将多个变换组合成处理流水线。
datasets 模块提供了多种常用计算机视觉数据集的接口,可以方便地下载和加载。
参考如下:
-
root:字符串,指定图像数据集的根目录。 -
transform:可选参数,用于对图像进行预处理。通常是一个torchvision.transforms的组合。 -
target_transform:可选参数,用于对目标(标签)进行转换。 -
is_valid_file:可选参数,用于过滤无效文件。如果提供,只有返回True的文件才会被加载。import torch from torch import nn from torch.utils.data import TensorDataset, DataLoader import pandas as pd from torchvision import datasets, transforms def load_img_data(): path = 'datasets/animals' transform = transforms.Compose([ # 图片缩放,把所有图片缩放到同一个尺寸 transforms.Resize((224, 224)), # 把PIL图片或numpy数组转换为张量 transforms.ToTensor() ]) dataset = datasets.ImageFolder( root=path, transform=transform ) dataloader = DataLoader( dataset=dataset, batch_size=8, shuffle=True ) for x, y in dataloader: print(x.shape) print(x) print(y) break if __name__ == '__main__': # load_csv_data() load_img_data()2.3 加载官方数据集
在 PyTorch 中官方提供了一些经典的数据集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用这些数据集进行训练和测试。
数据集:Datasets — Torchvision 0.22 documentation
常见数据集:
-
MNIST: 手写数字数据集,包含 60,000 张训练图像和 10,000 张测试图像。
-
CIFAR10: 包含 10 个类别的 60,000 张 32x32 彩色图像,每个类别 6,000 张图像。
-
CIFAR100: 包含 100 个类别的 60,000 张 32x32 彩色图像,每个类别 600 张图像。
-
COCO: 通用对象识别数据集,包含超过 330,000 张图像,涵盖 80 个对象类别。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中处理计算机视觉任务的两个核心模块,它们为图像数据的预处理和标准数据集的加载提供了强大支持。
transforms 模块提供了一系列用于图像预处理的工具,可以将多个变换组合成处理流水线。
datasets 模块提供了多种常用计算机视觉数据集的接口,可以方便地下载和加载。
参考如下:
# 加载官方数据集
# 加载MNIST数据集
def test01():
transform=transforms.Compose([
transforms.ToTensor()
])
# MNIST数据集:0-9的手写数据图片,每张尺寸为28*28
# MNIST构造函数
# 参数:
# root:存储数据集的本地路径
# train:是否下载训练数据集,True:训练数据集,False:测试数据集
# transform:转换器,可以将图片进行预处理转换
dataset=datasets.MNIST(
root="datasets/",
train=True,
download=True,
transform=transform
)
dataloader=DataLoader(
dataset=dataset,
batch_size=4,
shuffle=True
)
for x, y in dataloader:
print(x)
print(y)
break
if __name__ == '__main__':
test01()三、 激活函数
激活函数的作用是在隐藏层引入非线性,使得神经网络能够学习和表示复杂的函数关系,使网络具备非线性能力,增强其表达能力。
1. 基础概念
通过认识线性和非线性的基础概念,深刻理解激活函数存在的价值。
1.1 线性理解
如果在隐藏层不使用激活函数,那么整个神经网络会表现为一个线性模型。我们可以通过数学推导来展示这一点。
如果在隐藏层不使用激活函数,那么整个神经网络会表现为一个线性模型。我们可以通过数学推导来展示这一点。
假设:
-
神经网络有
层,每层的输出为
。
-
每层的权重矩阵为
,偏置向量为
。
-
输入数据为
,输出为
。
一层网络的情况
对于单层网络(输入层到输出层),如果没有激活函数,输出 可以表示为:
两层网络的情况
假设我们有两层网络,且每层都没有激活函数,则:
-
第一层的输出:
-
第二层的输出:
将代入到
中,可以得到:
我们可以看到,输出是输入
的线性变换,因为:
其中
,
。
多层网络的情况
如果有层,每层都没有激活函数,则第
层的输出为:
通过递归代入,可以得到:
表达式可简化为:
其中, 是所有权重矩阵的乘积,\mathbf{b}''是所有偏置项的线性组合。
如此可以看得出来,无论网络多少层,意味着:
整个网络就是线性模型,无法捕捉数据中的非线性关系。
激活函数是引入非线性特性、使神经网络能够处理复杂问题的关键。
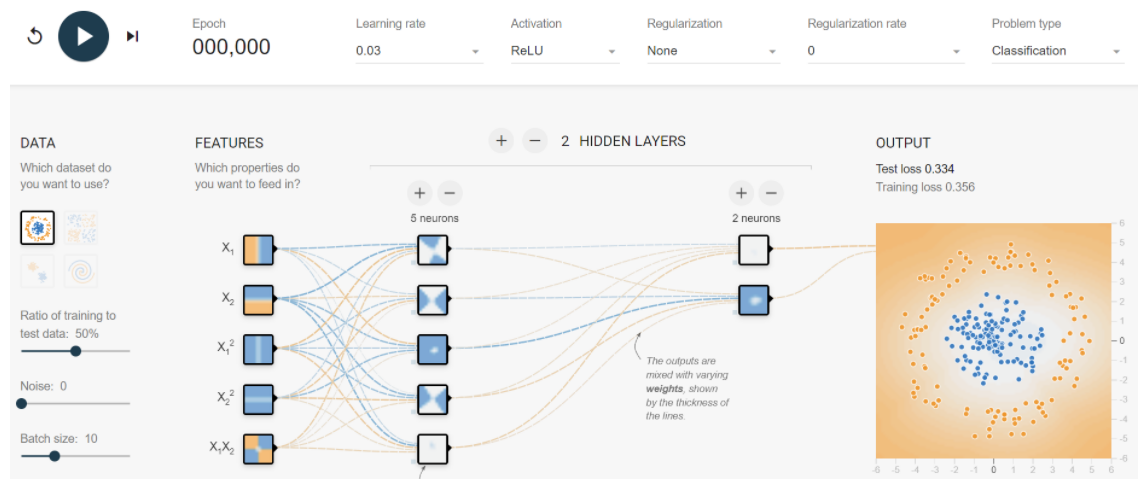
1.2 非线性可视化
我们可以通过可视化的方式去理解非线性的拟合能力:A Neural Network Playground
2. 常见激活函数
激活函数通过引入非线性来增强神经网络的表达能力,对于解决线性模型的局限性至关重要。由于反向传播算法(BP)用于更新网络参数,因此激活函数必须是可微的,也就是说能够求导的。
2.1 sigmoid
Sigmoid激活函数是一种常见的非线性激活函数,特别是在早期神经网络中应用广泛。它将输入映射到0到1之间的值,因此非常适合处理概率问题。
2.1.1 公式
Sigmoid函数的数学表达式为:
其中,e 是自然常数(约等于2.718),x 是输入。
2.1.2 特征
-
将任意实数输入映射到 (0, 1)之间,因此非常适合处理概率场景。
-
sigmoid函数一般只用于二分类的输出层。
-
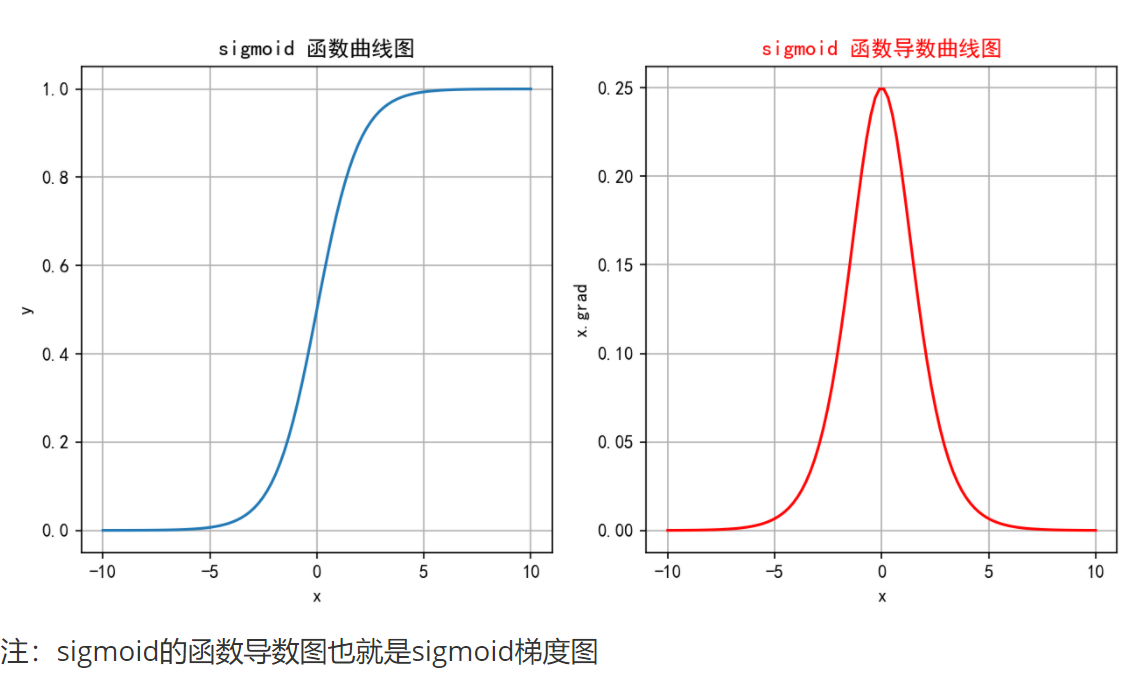
微分性质: 导数计算比较方便,可以用自身表达式来表示:
2.1.3 缺点
-
梯度消失:
-
由下面的Sigmoid梯度图可知,在输入非常大或非常小时,Sigmoid函数的梯度会变得非常小,无限趋近于0。这导致在反向传播过程中,梯度逐渐衰减。
-
最终使得早期层的权重更新非常缓慢,进而导致训练速度变慢甚至停滞。
-
-
信息丢失:有下面的Sigmoid函数图可知,输入100和输入10000经过sigmoid的激活值几乎都是等于 1 的,但是输入的数据却相差 100 倍。输入的数据相差很大,激活值却没太大的变化
-
计算成本高: 由于涉及指数运算,Sigmoid的计算比ReLU等函数更复杂,尽管差异并不显著。
2.2 tanh
tanh(双曲正切)是一种常见的非线性激活函数,常用于神经网络的隐藏层。tanh 函数也是一种S形曲线,输出范围为(−1,1)。
2.2.1 公式
tanh数学表达式为:
2.2.2 特征
-
输出范围: 将输入映射到(-1, 1)之间,因此输出是零中心的。相比于Sigmoid函数,这种零中心化的输出有助于加速收敛。
-
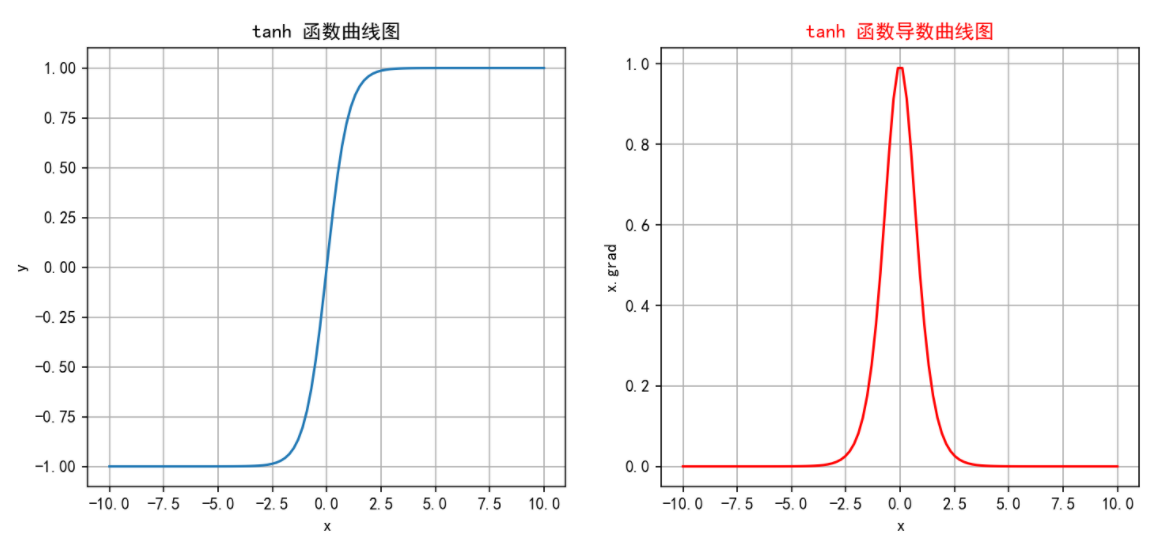
对称性: Tanh函数是关于原点对称的奇函数,因此在输入为0时,输出也为0。这种对称性有助于在训练神经网络时使数据更平衡。
-
平滑性: Tanh函数在整个输入范围内都是连续且可微的,这使其非常适合于使用梯度下降法进行优化。
2.2.3 缺点
-
梯度消失: 虽然一定程度上改善了梯度消失问题,但在输入值非常大或非常小时导数还是非常小,这在深层网络中仍然是个问题。这是因为每一层的梯度都会乘以一个小于1的值,经过多层乘积后,梯度会变得非常小,导致训练过程变得非常缓慢,甚至无法收敛。
-
计算成本: 由于涉及指数运算,Tanh的计算成本还是略高,尽管差异不大。
2.3 ReLU
ReLU(Rectified Linear Unit)是深度学习中最常用的激活函数之一,它的全称是修正线性单元。ReLU 激活函数的定义非常简单,但在实践中效果非常好。
2.3.1 公式
ReLU 函数定义如下:
即ReLU对输入x进行非线性变换:

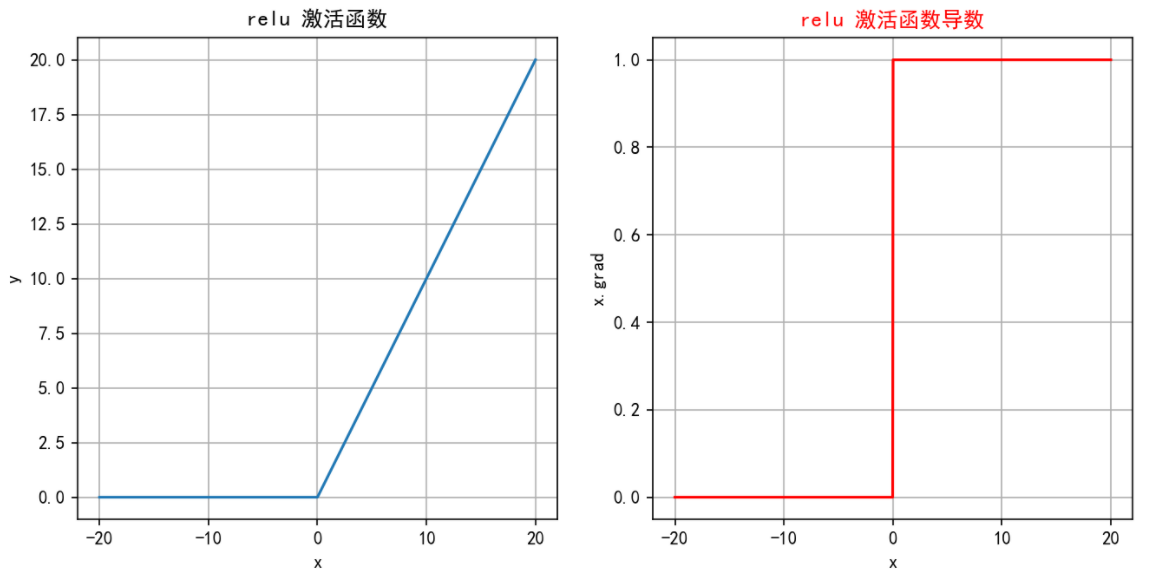
2.3.2 特征
-
计算简单:ReLU 的计算非常简单,只需要对输入进行一次比较运算,这在实际应用中大大加速了神经网络的训练。
-
ReLU 函数的导数是分段函数:
-
缓解梯度消失问题:相比于 Sigmoid 和 Tanh 激活函数,ReLU 在正半区的导数恒为 1,这使得深度神经网络在训练过程中可以更好地传播梯度,不存在饱和问题。
-
稀疏激活:ReLU在输入小于等于 0 时输出为 0,这使得 ReLU 可以在神经网络中引入稀疏性(即一些神经元不被激活),这种稀疏性可以减少网络中的冗余信息,提高网络的效率和泛化能力。
2.3.3 缺点
神经元死亡:由于ReLU在x≤0时输出为0,如果某个神经元输入值是负,那么该神经元将永远不再激活,成为“死亡”神经元。随着训练的进行,网络中可能会出现大量死亡神经元,从而会降低模型的表达能力。
2.4 LeakyReLU
Leaky ReLU是一种对 ReLU 函数的改进,旨在解决 ReLU 的一些缺点,特别是Dying ReLU 问题。Leaky ReLU 通过在输入为负时引入一个小的负斜率来改善这一问题。
2.4.1 公式
Leaky ReLU 函数的定义如下:
其中, 是一个非常小的常数(如 0.01),它控制负半轴的斜率。这个常数
是一个超参数,可以在训练过程中可自行进行调整。
2.4.2 特征
-
避免神经元死亡:通过在
区域引入一个小的负斜率,这样即使输入值小于等于零,Leaky ReLU仍然会有梯度,允许神经元继续更新权重,避免神经元在训练过程中完全“死亡”的问题。
-
计算简单:Leaky ReLU 的计算与 ReLU 相似,只需简单的比较和线性运算,计算开销低。
2.4.3 缺点
-
参数选择:
是一个需要调整的超参数,选择合适的
-
出现负激活:如果
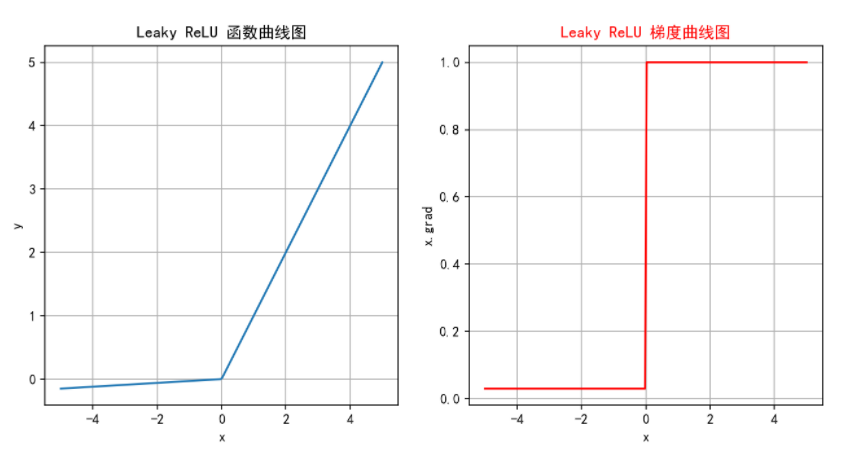
2.5 softmax
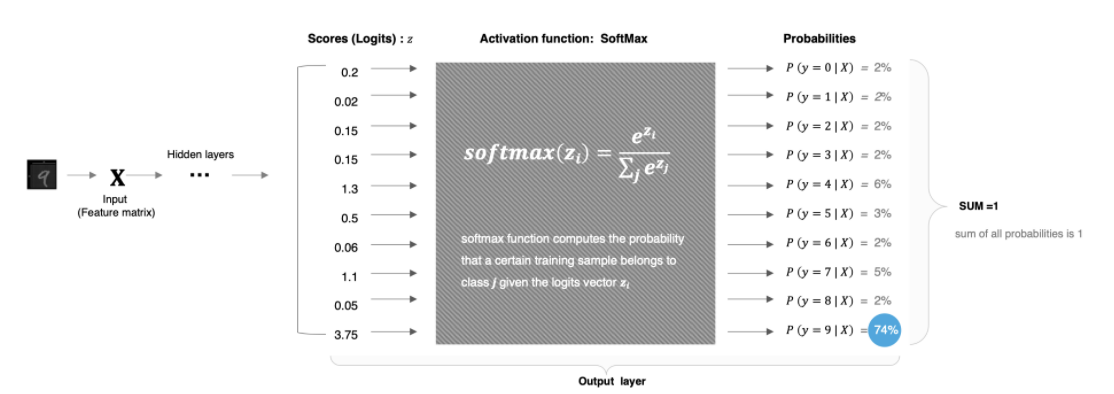
Softmax激活函数通常用于分类问题的输出层,它能够将网络的输出转换为概率分布,使得输出的各个类别的概率之和为 1。Softmax 特别适合用于多分类问题。
2.5.1 公式
假设神经网络的输出层有n个节点,每个节点的输入为,则 Softmax 函数的定义如下:
给定输入向量 z=[z_1,z_2,…,z_n]
1.指数变换:对每个 进行指数变换,得到
,使z的取值区间从
变为
2.将所有指数变换后的值求和,得到
3.将t中每个 除以归一化因子s,得到概率分布:
即:
从上述公式可以看出:
-
每个输出值在 (0,1)之间
-
Softmax()对向量的值做了改变,但其位置不变
-
所有输出值之和为1,即
2.5.2 特征
-
将输出转化为概率:通过Softmax,可以将网络的原始输出转化为各个类别的概率,从而可以根据这些概率进行分类决策。
-
概率分布:Softmax的输出是一个概率分布,即每个输出值\text{Softmax}(z_i)都是一个介于0和1之间的数,并且所有输出值的和为 1:
-
突出差异:Softmax会放大差异,使得概率最大的类别的输出值更接近1,而其他类别更接近0。
-
在实际应用中,Softmax常与交叉熵损失函数Cross-Entropy Loss结合使用,用于多分类问题。在反向传播中,Softmax的导数计算是必需的。

2.5.3 缺点
-
数值不稳定性:在计算过程中,如果z_i的数值过大,e^{z_i}可能会导致数值溢出。因此在实际应用中,经常会对z_i进行调整,如减去最大值以确保数值稳定。

在 PyTorch 中,torch.nn.functional.softmax 函数就自动处理了数值稳定性问题。
2. 难以处理大量类别:Softmax在处理类别数非常多的情况下(如大模型中的词汇表)计算开销会较大。
3. 如何选择
更多激活函数可以查看官方文档:torch.nn — PyTorch 2.7 documentation
那这么多激活函数应该如何选择呢?实际没那么纠结
3.1 隐藏层
-
优先选ReLU;
-
如果ReLU效果不好,那么尝试其他激活,如Leaky ReLU等;
-
使用ReLU时注意神经元死亡问题, 避免出现过多神经元死亡;
-
避免使用sigmoid,尝试使用tanh;
3.2 输出层
-
二分类问题选择sigmoid激活函数;
-
多分类问题选择softmax激活函数;
五、参数初始化
神经网络的参数初始化是训练深度学习模型的关键步骤之一。初始化参数(通常是权重和偏置)会对模型的训练速度、收敛性以及最终的性能产生重要影响。下面是关于神经网络参数初始化的一些常见方法及其相关知识点。
官方文档参考:torch.nn.init — PyTorch 2.7 documentation
1. 固定值初始化
固定值初始化是指在神经网络训练开始时,将所有权重或偏置初始化为一个特定的常数值。这种初始化方法虽然简单,但在实际深度学习应用中通常并不推荐。
1.1 全零初始化
将神经网络中的所有权重参数初始化为0。
方法:将所有权重初始化为零。
缺点:导致对称性破坏,每个神经元在每一层中都会执行相同的计算,模型无法学习。
应用场景:通常不用来初始化权重,但可以用来初始化偏置。
对称性问题
-
现象:同一层的所有神经元具有完全相同的初始权重和偏置。
-
后果:
-
在反向传播时,所有神经元会收到相同的梯度,导致权重更新完全一致。
-
无论训练多久,同一层的神经元本质上会保持相同的功能(相当于“一个神经元”的多个副本),极大降低模型的表达能力。
-
1.2 全1初始化
全1初始化会导致网络中每个神经元接收到相同的输入信号,进而输出相同的值,这就无法进行学习和收敛。所以全1初始化只是一个理论上的初始化方法,但在实际神经网络的训练中并不适用。
1.3 任意常数初始化
将所有参数初始化为某个非零的常数(如 0.1,-1 等)。虽然不同于全0和全1,但这种方法依然不能避免对称性破坏的问题。
2. 随机初始化
方法:将权重初始化为随机的小值,通常从正态分布或均匀分布中采样。
应用场景:这是最基本的初始化方法,通过随机初始化避免对称性破坏。
3. Xavier 初始化
前置知识:
均匀分布:
均匀分布的概率密度函数(PDF):
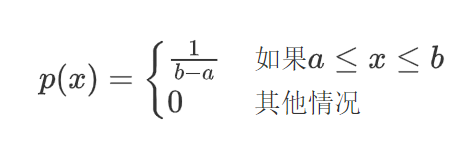
计算期望值(均值):
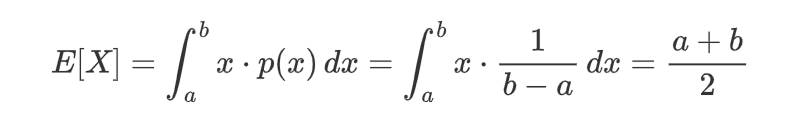
计算方差(二阶矩减去均值的平方):
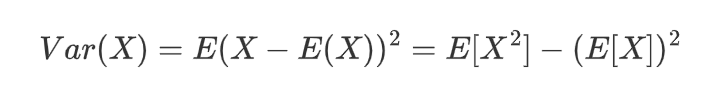
-
先计算
:
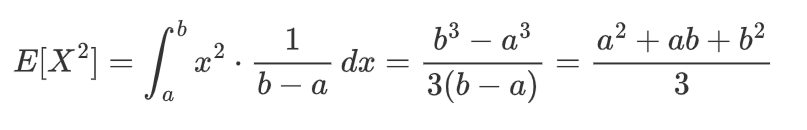
-
代入方差公式:
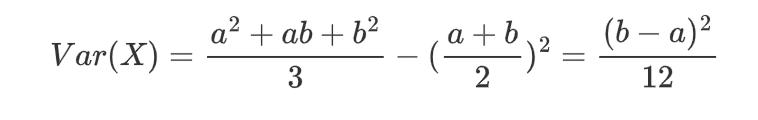
Xavier 初始化(由 Xavier Glorot 在 2010 年提出)是一种自适应权重初始化方法,专门为解决神经网络训练初期的梯度消失或爆炸问题而设计。Xavier 初始化也叫做Glorot初始化。Xavier 初始化的核心思想是根据输入和输出的维度来初始化权重,使得每一层的输出的方差保持一致。具体来说,权重的初始化范围取决于前一层的神经元数量(输入维度)和当前层的神经元数量(输出维度)。
方法:根据输入和输出神经元的数量来选择权重的初始值。
优点:平衡了输入和输出的方差,适合Sigmoid 和 Tanh 激活函数。
应用场景:常用于浅层网络或使用Sigmoid 、Tanh 激活函数的网络。
4. He初始化
也叫kaiming 初始化。He 初始化的核心思想是调整权重的初始化范围,使得每一层的输出的方差保持一致。与 Xavier 初始化不同,He 初始化专门针对 ReLU 激活函数的特性进行了优化。
优点:适用于ReLU 和 Leaky ReLU 激活函数。
应用场景:深度网络,尤其是使用 ReLU 激活函数时。
5. 总结
在使用Torch构建网络模型时,每个网络层的参数都有默认的初始化方法,同时还可以通过以上方法来对网络参数进行初始化。
import torch
from torch import nn
import torch.nn.functional as F
# 随机初始化
def test01():
model=nn.Linear(8,1)
print(model.weight)
# 均匀分布初始化
# nn.init.uniform_(model.weight)
# 正态分布初始化
# 参数:
# mean:均值
# std:标准差
nn.init.normal_(model.weight,mean=0,std=1)
print(model.weight)
# xavier初始化
# 原理:
# 1.前向传播的方差保持一致
# 2.反向传播的梯度方差保持一致
def tset02():
model=nn.Linear(8,1)
# 均匀分布初始化
nn.init.xavier_normal(model.weight)
print(model.weight)
# He初始化(kaiming初始化)
# pytorch框架默认使用He初始化
def test03():
model=nn.Linear(8,1)
# 均匀分布初始化
# mode:模式:fan_in-优先保证前向传播方差一致性,fan_out-优先保证反向传播方差一致性
# nn.init.kaiming_uniform_(model.weight,mode='fan_in')
nn.init.kaiming_uniform_(model.weight,mode="fan_out")
print(model.weight)
# 构建带有激活函数的神经网络,并作参数初始化
class MyNet(nn.Module):
def __init__(self,in_features,out_features):
super().__init__()
self.fc1=nn.Linear(in_features,64)
self.relu1=nn.ReLU()
self.fc2=nn.Linear(64,32)
self.relu2=nn.ReLU()
self.fc3=nn.Linear(32,out_features)
self.sigmoid=nn.Sigmoid()
def forward(self,x):
x=self.relu1(self.fc1(x))
x=self.relu2(self.fc2(x))
x=self.sigmoid(self.fc3(x))
return x
class MyNet1(nn.Module):
def __init__(self,in_features,out_features):
super().__init__()
nn.init.kaiming_uniform_(self.fc1.weight)
self.fc1=nn.Linear(in_features,64)
self.fc2=nn.Linear(64,32)
self.fc3=nn.Linear(32,out_features)
def forward(self,x):
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=F.sigmoid(self.fc3(x))
def test04():
model=MyNet(10,2)
nn.init.kaiming_uniform_(model.fc1.weight)
print(model)
if __name__=="__main__":
# test01()
# tset02()
# test03()
test04()六、损失函数
1. 线性回归损失函数
1.1 MAE损失
MAE(Mean Absolute Error,平均绝对误差)通常也被称为 L1-Loss,通过对预测值和真实值之间的绝对差取平均值来衡量他们之间的差异。
MAE的公式如下:
其中:
-
n 是样本的总数。
-
是第 i 个样本的真实值。
-
i 是第 i 个样本的预测值。
-
是真实值和预测值之间的绝对误差。
特点:
-
鲁棒性:与均方误差(MSE)相比,MAE对异常值(outliers)更为鲁棒,因为它不会像MSE那样对较大误差平方敏感。
-
物理意义直观:MAE以与原始数据相同的单位度量误差,使其易于解释。
应用场景: MAE通常用于需要对误差进行线性度量的情况,尤其是当数据中可能存在异常值时,MAE可以避免对异常值的过度惩罚。
1.2 MSE损失
均方差损失,也叫L2Loss。
MSE(Mean Squared Error,均方误差)通过对预测值和真实值之间的误差平方取平均值,来衡量预测值与真实值之间的差异。
MSE的公式如下:
其中:
-
n 是样本的总数。
-
-
-
是真实值和预测值之间的误差平方。
特点:
-
平方惩罚:因为误差平方,MSE 对较大误差施加更大惩罚,所以 MSE 对异常值更为敏感。
-
凸性:MSE 是一个凸函数(国际的叫法,国内叫凹函数),这意味着它具有一个唯一的全局最小值,有助于优化问题的求解。
应用场景:
MSE被广泛应用在神经网络中。
2. CrossEntropyLoss
2.1 信息量
信息量用于衡量一个事件所包含的信息的多少。信息量的定义基于事件发生的概率:事件发生的概率越低,其信息量越大。其量化公式:
对于一个事件x,其发生的概率为 P(x),信息量I(x) 定义为:
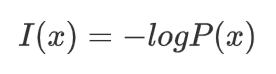
性质
-
非负性:I(x)≥0。
-
单调性:P(x)越小,I(x)越大。
2.2 信息熵
信息熵是信息量的期望值。熵越高,表示随机变量的不确定性越大;熵越低,表示随机变量的不确定性越小。
公式由数学中的期望推导而来:
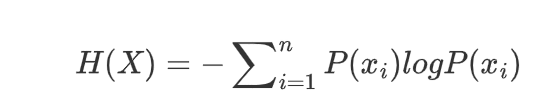
其中:
是信息量,
是信息量对应的概率
2.3 KL散度
KL散度用于衡量两个概率分布之间的差异。它描述的是用一个分布 Q来近似另一个分布 P时,所损失的信息量。KL散度越小,表示两个分布越接近。
对于两个离散概率分布 P和 Q,KL散度定义为:
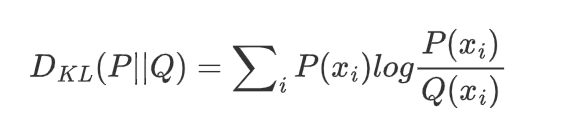
其中:P 是真实分布,Q是近似分布。
2.4 交叉熵
对KL散度公式展开: 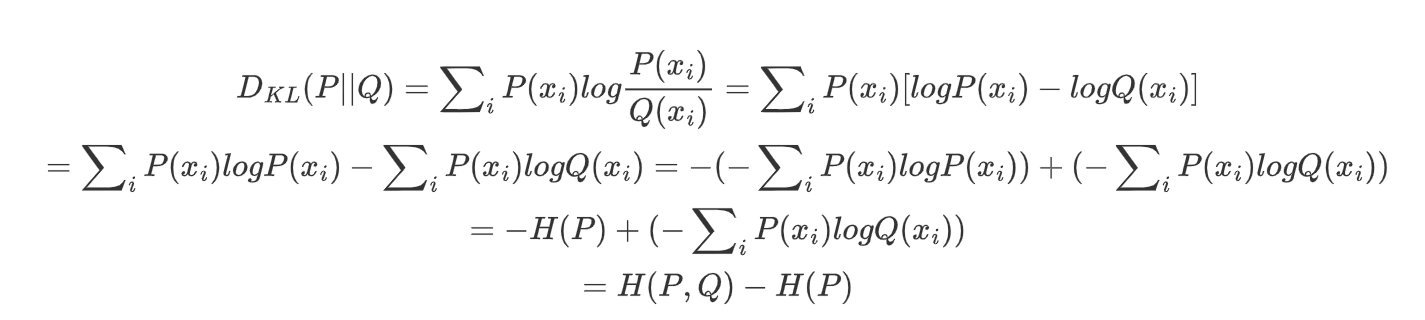
由上述公式可知,P是真实分布,H(P)是常数,所以KL散度可以用H(P,Q)来表示;H(P,Q)叫做交叉熵。
如果将P换成y,Q换成,则交叉熵公式为:
其中:
-
C 是类别的总数。
-
y 是真实标签的one-hot编码向量,表示真实类别。
-
是模型的输出(经过 softmax 后的概率分布)。
-
-
特点:
-
概率输出:CrossEntropyLoss 通常与 softmax 函数一起使用,使得模型的输出表示为一个概率分布(即所有类别的概率和为 1)。PyTorch 的 nn.CrossEntropyLoss 已经内置了 Softmax 操作。如果我们在输出层显式地添加 Softmax,会导致重复应用 Softmax,从而影响模型的训练效果。
-
惩罚错误分类:该损失函数在真实类别的预测概率较低时,会施加较大的惩罚,这样模型在训练时更注重提升正确类别的预测概率。
-
多分类问题中的标准选择:在大多数多分类问题中,CrossEntropyLoss 是首选的损失函数。
应用场景:
CrossEntropyLoss 广泛应用于各种分类任务,包括图像分类、文本分类等,尤其是在神经网络模型中。
3. BCELoss
二分类交叉熵损失函数,使用在输出层使用sigmoid激活函数进行二分类时。
由交叉熵公式:
对于二分类问题,真实标签 y的值为(0 或 1),假设模型预测为正类的概率为 \hat{y},则:

所以:
4. 总结
-
当输出层使用softmax多分类时,使用交叉熵损失函数;
-
当输出层使用sigmoid二分类时,使用二分类交叉熵损失函数, 比如在逻辑回归中使用;
-
当功能为线性回归时,使用均方差损失-L2 loss;
代码示例:
import torch
import torch.nn as nn
def test01():
# 假设有三个类别,模型输出是未经softmax的logits
logits = torch.tensor([[1.5, 2.0, 0.5], [0.5, 1.0, 1.5]])
# 真实的标签
labels = torch.tensor([1, 2]) # 第一个样本的真实类别为1,第二个样本的真实类别为2
# 初始化CrossEntropyLoss
# 参数:reduction:mean-平均值,sum-总和
criterion = nn.CrossEntropyLoss(reduction="sum")
# 计算损失
loss = criterion(logits, labels)
print(f'Cross Entropy Loss: {loss.item()}')
def test02():
# y 是模型的输出,已经被sigmoid处理过,确保其值域在(0,1)
y = torch.tensor([[0.7], [0.2], [0.9], [0.7]])
# targets 是真实的标签,0或1
t = torch.tensor([[1], [0], [1], [0]], dtype=torch.float)
criterion=nn.BCELoss()
loss=criterion(y,t)
print(loss.item())
if __name__ == "__main__":
# test01()
test02()七、反向传播算法
反向传播(Back Propagation,简称BP)算法是用于训练神经网络的核心算法之一,它通过计算损失函数(如均方误差或交叉熵)相对于每个权重参数的梯度,来优化神经网络的权重。 
1. 前向传播
前向传播(Forward Propagation)把输入数据经过各层神经元的运算并逐层向前传输,一直到输出层为止。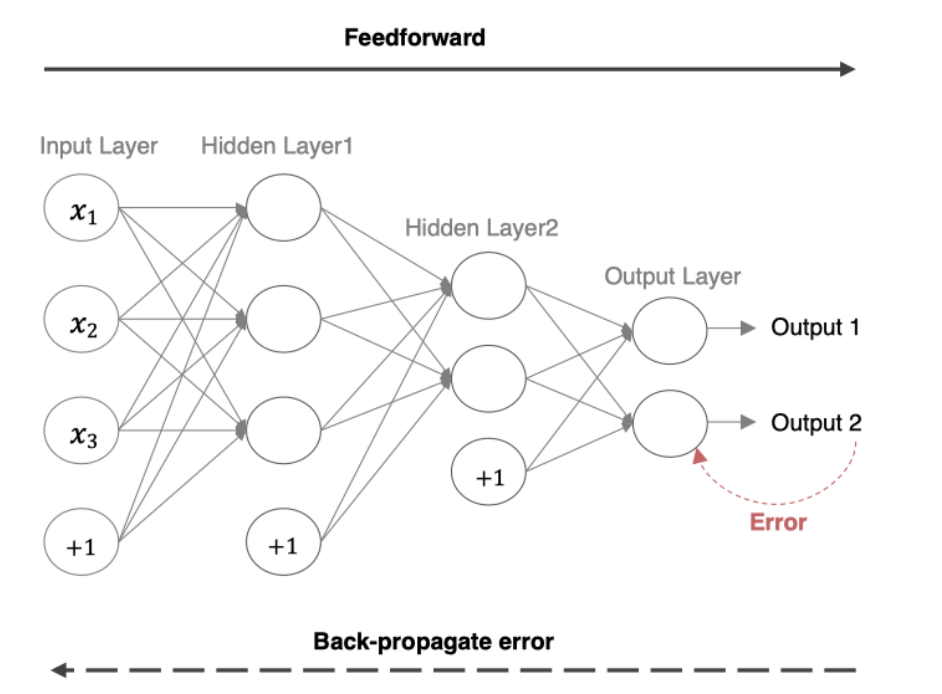
1.1 数学表达
下面是一个简单的三层神经网络(输入层、隐藏层、输出层)前向传播的基本步骤分析。
1.1.1 输入层到隐藏层
给定输入 x 和权重矩阵及偏置向量
,隐藏层的输出(激活值)计算如下:
将通过激活函数
进行激活:
1.1.2 隐藏层到输出层
隐藏层的输出通过输出层的权重矩阵
和偏置
生成最终的输出:
输出层的激活值是最终的预测结果:
1.2 作用
前向传播的主要作用是:
-
计算神经网络的输出结果,用于预测或计算损失。
-
在反向传播中使用,通过计算损失函数相对于每个参数的梯度来优化网络。
2. BP基础之梯度下降算法
梯度下降算法的目标是找到使损失函数 最小的参数
,其核心是沿着损失函数梯度的负方向更新参数,以逐步逼近局部或全局最优解,从而使模型更好地拟合训练数据。
2.1 数学描述
简单回顾下数学知识。
2.1.1 数学公式
其中,是学习率:
-
学习率太小,每次训练之后的效果太小,增加时间和算力成本。
-
学习率太大,大概率会跳过最优解,进入无限的训练和震荡中。
-
解决的方法就是,学习率也需要随着训练的进行而变化。
2.1.2 过程阐述
-
初始化参数:随机初始化模型的参数
,如权重 W和偏置 b。
-
计算梯度:损失函数
对参数
,表示损失函数在参数空间的变化率。
-
更新参数:按照梯度下降公式更新参数:
,其中,
-
迭代更新:重复【计算梯度和更新参数】步骤,直到某个终止条件(如梯度接近0、不再收敛、完成迭代次数等)。
2.2 传统下降方式
根据计算梯度时数据量不同,常见的方式有:
2. 2.1 批量梯度下降
Batch Gradient Descent BGD
-
特点:
-
每次更新参数时,使用整个训练集来计算梯度。
-
-
优点:
-
收敛稳定,能准确地沿着损失函数的真实梯度方向下降。
-
适用于小型数据集。
-
-
缺点:
-
对于大型数据集,计算量巨大,更新速度慢。
-
需要大量内存来存储整个数据集。
-
-
公式:
其中,m 是训练集样本总数,
,
是第 i 个样本及其标签,
是第 i 个样本预测值。
例如,在训练集中有100个样本,迭代50轮。
那么在每一轮迭代中,都会一起使用这100个样本,计算整个训练集的梯度,并对模型更新。
所以总共会更新50次梯度。
因为每次迭代都会使用整个训练集计算梯度,所以这种方法可以得到准确的梯度方向。
但如果数据集非常大,那么就导致每次迭代都很慢,计算成本就会很高。
2.2.3 小批量梯度下降
Mini-batch Gradient Descent MGBD
-
特点:
-
每次更新参数时,使用一小部分训练集(小批量)来计算梯度。
-
-
优点:
-
在计算效率和收敛稳定性之间取得平衡。
-
能够利用向量化加速计算,适合现代硬件(如GPU)。
-
-
缺点:
-
选择适当的批量大小比较困难;批量太小则接近SGD,批量太大则接近批量梯度下降。
-
通常会根据硬件算力设置为32\64\128\256等2的次方。
-
-
公式:
其中,b 是小批量的样本数量,也就是
。
例如,如果训练集中有100个样本,迭代50轮。
如果设置小批量的数量是20,那么在每一轮迭代中,会有5次小批量迭代。
换句话说,就是将100个样本分成5个小批量,每个小批量20个数据,每次迭代用一个小批量。
因此,按照这样的方式,会对梯度,进行50轮*5个小批量=250次更新。
2.3 存在的问题
-
收敛速度慢:BGD和MBGD使用固定学习率,太大会导致震荡,太小又收敛缓慢。
-
局部最小值和鞍点问题:SGD在遇到局部最小值或鞍点时容易停滞,导致模型难以达到全局最优。
-
训练不稳定:SGD中的噪声容易导致训练过程中不稳定,使得训练陷入震荡或不收敛。
2.4 优化下降方式
通过对标准的梯度下降进行改进,来提高收敛速度或稳定性。
2.4.1 指数加权平均
我们平时说的平均指的是将所有数加起来除以数的个数,很单纯的数学。再一个是移动平均数,指的是计算最近邻的N个数来获得平均数,感觉比纯粹的直接全部求均值高级一点。
指数加权平均:Exponential Moving Average,简称EMA,是一种平滑时间序列数据的技术,它通过对过去的值赋予不同的权重来计算平均值。与简单移动平均不同,EMA赋予最近的数据更高的权重,较远的数据则权重较低,这样可以更敏感地反映最新的变化趋势。
比如今天股市的走势,和昨天发生的国际事件关系很大,和6个月前发生的事件关系相对肯定小一些。
给定时间序列\{x_t\},EMA在每个时刻 t 的值可以通过以下递推公式计算:
当t=1时:
当t>1时:
其中:
-
是第 t 时刻的EMA值;
-
是第 t 时刻的观测值;
-
是平滑系数,取值范围为
。
公式推导:
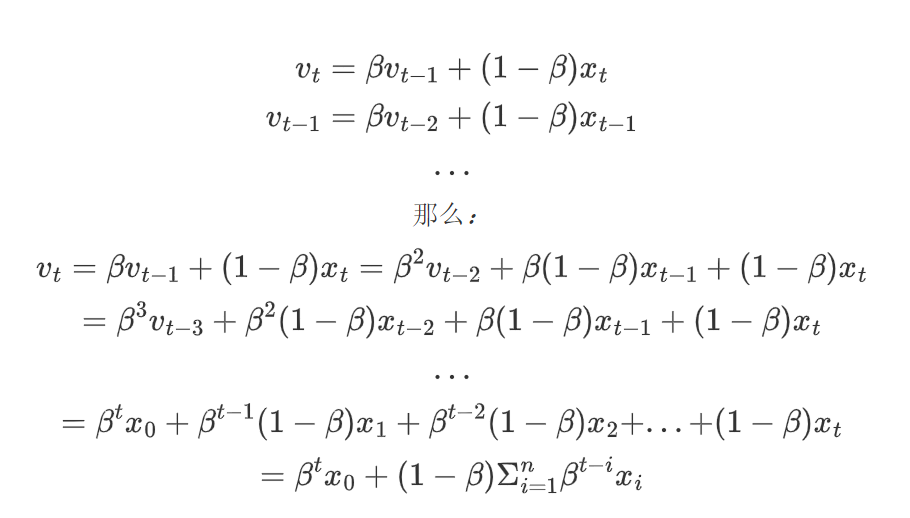
从上述公式可知:
-
当 β接近 1 时,β^k衰减较慢,因此历史数据的权重较高。
-
当 β接近 0 时,β^k衰减较快,因此历史数据的权重较低。
2.4.2 Momentum
动量(Momentum)是对梯度下降的优化方法,可以更好地应对梯度变化和梯度消失问题,从而提高训练模型的效率和稳定性。它通过引入 指数加权平均 来积累历史梯度信息,从而在更新参数时形成“动量”,帮助优化算法更快地越过局部最优或鞍点。
梯度更新算法包括两个步骤:
a. 更新动量项
首先计算当前的动量项:
其中:
-
是之前的动量项;
-
-
是当前的梯度;
b. 更新参数
利用动量项更新参数:
特点:
-
惯性效应: 该方法加入前面梯度的累积,这种惯性使得算法沿着当前的方向继续更新。如遇到鞍点,也不会因梯度逼近零而停滞。
-
减少震荡: 该方法平滑了梯度更新,减少在鞍点附近的震荡,帮助优化过程稳定向前推进。
-
加速收敛: 该方法在优化过程中持续沿着某个方向前进,能够更快地穿越鞍点区域,避免在鞍点附近长时间停留。
在方向上的作用:
(1)梯度方向一致时
-
如果梯度在多个连续时刻方向一致(例如,一直指向某个方向),Momentum 会逐渐积累动量,使更新速度加快。
-
例如,假设梯度在多个时刻都是正向的,动量
(2)梯度方向不一致时
-
如果梯度方向在不同时刻不一致(例如,来回震荡),Momentum 会通过积累的历史梯度信息部分抵消这些震荡。
-
例如,假设梯度在一个时刻是正向的,下一个时刻是负向的,动量
(3)局部最优或鞍点附近
-
在局部最优或鞍点附近,梯度可能会变得很小,导致标准梯度下降法停滞。
-
Momentum 通过积累历史梯度信息,可以帮助参数更新越过这些平坦区域。
动量方向与梯度方向一致
(1)梯度方向一致时
-
如果梯度在多个连续时刻方向一致(例如,一直指向某个方向),动量会逐渐积累,动量方向与梯度方向一致。
-
例如,假设梯度在多个时刻都是正向的,动量
(2)几何意义
-
在优化问题中,如果损失函数的几何形状是 平滑且单调 的(例如,一个狭长的山谷),梯度方向会保持一致。
-
在这种情况下,动量方向与梯度方向一致,Momentum 会加速参数更新,帮助算法更快地收敛。
动量方向与梯度方向不一致
(1)梯度方向不一致时
-
如果梯度方向在不同时刻不一致(例如,来回震荡),动量方向可能会与当前梯度方向不一致。
-
例如,假设梯度在一个时刻是正向的,下一个时刻是负向的,动量
(2)几何意义
-
在优化问题中,如果损失函数的几何形状是 复杂且非凸 的(例如,存在多个局部最优或鞍点),梯度方向可能会在不同时刻发生剧烈变化。
-
在这种情况下,动量方向与梯度方向可能不一致,Momentum 会通过积累的历史梯度信息部分抵消这些震荡,使更新路径更加平滑。
总结:
-
动量项更新:利用当前梯度和历史动量来计算新的动量项。
-
权重参数更新:利用更新后的动量项来调整权重参数。
-
梯度计算:在每个时间步计算当前的梯度,用于更新动量项和权重参数。
Momentum 算法是对梯度值的平滑调整,但是并没有对梯度下降中的学习率进行优化。
2.4.3 AdaGrad
AdaGrad(Adaptive Gradient Algorithm)为每个参数引入独立的学习率,它根据历史梯度的平方和来调整这些学习率。具体来说,对于频繁更新的参数,其学习率会逐渐减小;而对于更新频率较低的参数,学习率会相对较大。AdaGrad避免了统一学习率的不足,更多用于处理稀疏数据和梯度变化较大的问题。
AdaGrad流程:
-
初始化:
-
初始化参数
和学习率
。
-
将梯度累积平方的向量
初始化为零向量。
-
-
梯度计算:
-
在每个时间步 t,计算损失函数
对参数
。
-
-
累积梯度的平方:
-
对每个参数 i 累积梯度的平方:
其中G_{t} 是累积的梯度平方和, g_{t} 是第 i 个参数在时间步t 的梯度。
推导:
-
-
参数更新:
-
利用累积的梯度平方来更新参数:
-
其中:
-
-
是一个非常小的常数,用于避免除零操作(通常取
)。
-
是自适应调整后的学习率。
-
-
AdaGrad 为每个参数分配不同的学习率:
-
对于梯度较大的参数,Gt较大,学习率较小,从而避免更新过快。
-
对于梯度较小的参数,Gt较小,学习率较大,从而加快更新速度。
可以将 AdaGrad 类比为:
-
梯度较大的参数:类似于陡峭的山坡,需要较小的步长(学习率)以避免跨度过大。
-
梯度较小的参数:类似于平缓的山坡,可以采取较大的步长(学习率)以加快收敛。
优点:
-
自适应学习率:由于每个参数的学习率是基于其梯度的累积平方和
来动态调整的,这意味着学习率会随着时间步的增加而减少,对梯度较大且变化频繁的方向非常有用,防止了梯度过大导致的震荡。
-
适合稀疏数据:AdaGrad 在处理稀疏数据时表现很好,因为它能够自适应地为那些较少更新的参数保持较大的学习率。
缺点:
-
学习率过度衰减:随着时间的推移,累积的时间步梯度平方值越来越大,导致学习率逐渐接近零,模型会停止学习。
-
不适合非稀疏数据:在非稀疏数据的情况下,学习率过快衰减可能导致优化过程早期停滞。
AdaGrad是一种有效的自适应学习率算法,然而由于学习率衰减问题,我们会使用改 RMSProp 或 Adam 来替代。
2.4.4 RMSProp
虽然 AdaGrad 能够自适应地调整学习率,但随着训练进行,累积梯度平方会不断增大,导致学习率逐渐减小,最终可能变得过小,导致训练停滞。
RMSProp(Root Mean Square Propagation)是一种自适应学习率的优化算法,在时间步中,不是简单地累积所有梯度平方和,而是使用指数加权平均来逐步衰减过时的梯度信息。旨在解决 AdaGrad 学习率单调递减的问题。它通过引入 指数加权平均 来累积历史梯度的平方,从而动态调整学习率。
公式为:
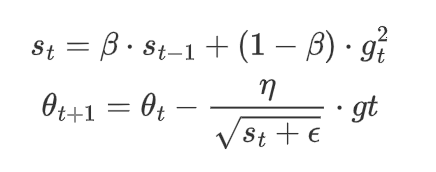
其中:
-
是当前时刻的指数加权平均梯度平方。
-
β是衰减因子,通常取 0.9。
-
η是初始学习率。
-
ϵ是一个小常数(通常取
-
是当前时刻的梯度。
优点
-
适应性强:RMSProp自适应调整每个参数的学习率,对于梯度变化较大的情况非常有效,使得优化过程更加平稳。
-
适合非稀疏数据:相比于AdaGrad,RMSProp更加适合处理非稀疏数据,因为它不会让学习率减小到几乎为零。
-
解决过度衰减问题:通过引入指数加权平均,RMSProp避免了AdaGrad中学习率过快衰减的问题,保持了学习率的稳定性
缺点
依赖于超参数的选择:RMSProp的效果对衰减率和学习率
的选择比较敏感,需要一些调参工作。
2.4.5 Adam
Adam(Adaptive Moment Estimation)算法将动量法和RMSProp的优点结合在一起:
-
动量法:通过一阶动量(即梯度的指数加权平均)来加速收敛,尤其是在有噪声或梯度稀疏的情况下。
-
RMSProp:通过二阶动量(即梯度平方的指数加权平均)来调整学习率,使得每个参数的学习率适应其梯度的变化。
Adam过程
-
初始化:
-
初始化参数
-
初始化一阶动量估计
和二阶动量估计
。
-
设定动量项的衰减率
和二阶动量项的衰减率
,通常
,
。
-
设定一个小常数
-
-
梯度计算:
-
在每个时间步 t,计算损失函数
-
-
一阶动量估计(梯度的指数加权平均):
-
更新一阶动量估计:
其中,
是当前时间步 t 的一阶动量估计,表示梯度的指数加权平均。
-
-
二阶动量估计(梯度平方的指数加权平均):
-
更新二阶动量估计:
其中,
-
-
偏差校正:
由于一阶动量和二阶动量在初始阶段可能会有偏差,以二阶动量为例:
在计算指数加权平均时,初始化
,那么
,得到
,显然得到的
会小很多,导致估计的不准确,以此类推:
根据:
,把
,导致
远小于
和
,所以
所以这个估计是有偏差的。
使用以下公式进行偏差校正:
其中,
和
是校正后的一阶和二阶动量估计。
优点
-
高效稳健:Adam结合了动量法和RMSProp的优势,在处理非静态、稀疏梯度和噪声数据时表现出色,能够快速稳定地收敛。
-
自适应学习率:Adam通过一阶和二阶动量的估计,自适应调整每个参数的学习率,避免了全局学习率设定不合适的问题。
-
适用大多数问题:Adam几乎可以在不调整超参数的情况下应用于各种深度学习模型,表现良好。
缺点
-
超参数敏感:尽管Adam通常能很好地工作,但它对初始超参数(如 \beta_1、 \beta_2 和 \eta)仍然较为敏感,有时需要仔细调参。
-
过拟合风险:由于Adam会在初始阶段快速收敛,可能导致模型陷入局部最优甚至过拟合。因此,有时会结合其他优化算法(如SGD)使用。
2.5 总结
梯度下降算法通过不断更新参数来最小化损失函数,是反向传播算法中计算权重调整的基础。在实际应用中,根据数据的规模和计算资源的情况,选择合适的梯度下降方式(批量、随机、小批量)及其变种(如动量法、Adam等)可以显著提高模型训练的效率和效果。
Adam是目前最为流行的优化算法之一,因其稳定性和高效性,广泛应用于各种深度学习模型的训练中。Adam结合了动量法和RMSProp的优点,能够在不同情况下自适应调整学习率,并提供快速且稳定的收敛表现。
代码示例:
import torch
from torch.utils.data import TensorDataset,DataLoader
from torch import nn,optim
def test01():
model=nn.Linear(10,5)
x=torch.randn(10000,10)
y=torch.rand(10000, 5)
criterion=nn.MSELoss()
# momentum:动量:根据历史梯度增加惯性
# 参数值:动量系数:一般取0.9
opt=optim.SGD(model.parameters(),lr=0.1,momentum=0.9)
dataset=TensorDataset(x,y)
# 批量梯度下降
# dataloader=DataLoader(
# dataset=dataset,
# batch_size=len(dataset),
# shuffle=True
# )
# 随机梯度下降:随机选择一条样本进行梯度更新
# dataloader=DataLoader(
# dataset=dataset,
# batch_size=1,
# shuffle=True
# )
# 小批量梯度下降
dataloader=DataLoader(
dataset=dataset,
batch_size=256,
shuffle=True
)
epochs=200
for epoch in range(epochs):
for tx,ty in dataloader:
y_pred=model(tx)
loss=criterion(y_pred,ty)
opt.zero_grad()
loss.backward()
opt.step()
print(f'epoch:{epoch},loss:{loss.item()}')
def test02():
model=nn.Linear(10,5)
x=torch.randn(1000,10)
y=torch.randn(1000,5)
criterion=nn.MSELoss()
# Adgrad:自适应学习优化率
# 原理:历史梯度平方和作为学习率的分母,动态调整学习率
# 优点:自适应动态调整学习率
# 缺点:随着训练时间的增加,历史梯度平方和越来越大,导致学习率越来越小,可能会停止参数更新
# eps:避免学习率的分母为0,是一个非常小的数字
# opt=optim.Adagrad(model.parameters(),lr=0.1,eps=1e-8)
# RESprop:自适应学习率优化器
# 原理:使用指数加权平均对历史梯度平方求和,将平方和作为分母调整学习率
# 优点:缓解历史梯度平方和快速变大,使学习率衰减更加平稳
# 缺点:需要调整alpha和lr参数,找到最优值
# opt=optim.RMSprop(model.parameters(),lr=0.1,alpha=0.9,eps=1e-8)
# Adam:自适应优化器
# 结合了动量和RMSprop,既优化了梯度,又能动态调整
# 缺点使对参数alpha和lr参数,找到最优解
# betas参数:是一个元组,第一个元素是一阶动量的参数0.9,第二个元素是二阶动量的系数0.999,两个系数是经验值
opt=optim.Adam(model.parameters(),lr=0.1,betas=(0.9,0.999),eps=1e-8)
for epoch in range(50):
y_pred = model(x)
loss = criterion(y_pred, y)
opt.zero_grad()
loss.backward()
opt.step()
print(f'loss:{loss.item()}')
if __name__=="__main__":
# test01()
test02()
八、过拟合与欠拟合
在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。
1. 概念认知
这里我们简单的回顾下过拟合和欠拟合的基本概念~
1.1 过拟合
过拟合是指模型对训练数据拟合能力很强并表现很好,但在测试数据上表现较差。
过拟合常见原因有:
-
数据量不足:当训练数据较少时,模型可能会过度学习数据中的噪声和细节。
-
模型太复杂:如果模型很复杂,也会过度学习训练数据中的细节和噪声。
-
正则化强度不足:如果正则化强度不足,可能会导致模型过度学习训练数据中的细节和噪声。
举个例子: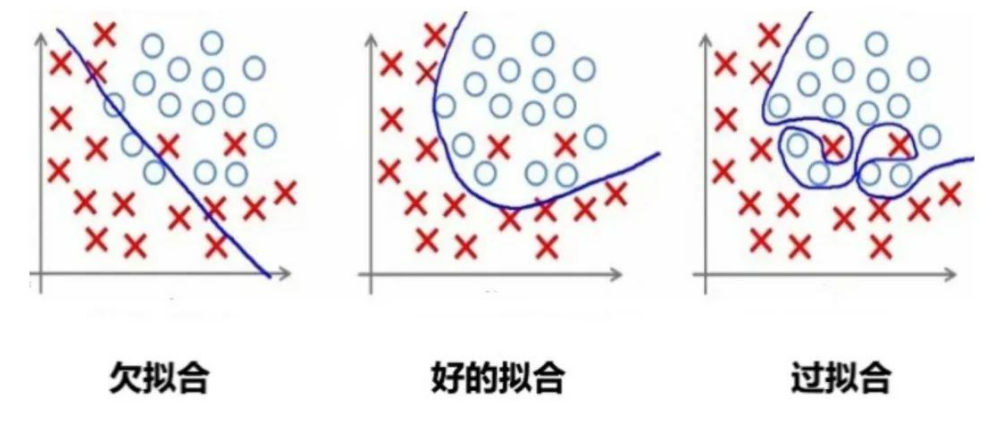
1.2 欠拟合
欠拟合是由于模型学习能力不足,无法充分捕捉数据中的复杂关系。
1.3 如何判断
那如何判断一个错误的结果是过拟合还是欠拟合呢?
过拟合
训练误差低,但验证时误差高。模型在训练数据上表现很好,但在验证数据上表现不佳,说明模型可能过度拟合了训练数据中的噪声或特定模式。
欠拟合
训练误差和测试误差都高。模型在训练数据和测试数据上的表现都不好,说明模型可能太简单,无法捕捉到数据中的复杂模式。
2. 解决欠拟合
欠拟合的解决思路比较直接:
-
增加模型复杂度:引入更多的参数、增加神经网络的层数或节点数量,使模型能够捕捉到数据中的复杂模式。
-
增加特征:通过特征工程添加更多有意义的特征,使模型能够更好地理解数据。
-
减少正则化强度:适当减小 L1、L2 正则化强度,允许模型有更多自由度来拟合数据。
-
训练更长时间:如果是因为训练不足导致的欠拟合,可以增加训练的轮数或时间.
3. 解决过拟合
避免模型参数过大是防止过拟合的关键步骤之一。
模型的复杂度主要由权重w决定,而不是偏置b。偏置只是对模型输出的平移,不会导致模型过度拟合数据。
怎么控制权重w,使w在比较小的范围内?
考虑损失函数,损失函数的目的是使预测值与真实值无限接近,如果在原来的损失函数上添加一个非0的变量
其中f(w)是关于权重w的函数,f(w)>0
要使L1变小,就要使L变小的同时,也要使f(w)变小。从而控制权重w在较小的范围内。
3.1 L2正则化
L2 正则化通过在损失函数中添加权重参数的平方和来实现,目标是惩罚过大的参数值。
3.1.1 数学表示
设损失函数为,其中 \theta 表示权重参数,加入L2正则化后的损失函数表示为:
其中:
-
-
是正则化强度,控制正则化的力度。
-
是模型的第 i 个权重参数。
-
是所有权重参数的平方和,称为 L2 正则化项。
L2 正则化会惩罚权重参数过大的情况,通过参数平方值对损失函数进行约束。
为什么是?
假设没有1/2,则对L2 正则化项的梯度为:
,会引入一个额外的系数 2,使梯度计算和更新公式变得复杂。
添加1/2后,对的梯度为:
。
3.1.2 梯度更新
在 L2 正则化下,梯度更新时,不仅要考虑原始损失函数的梯度,还要考虑正则化项的影响。更新规则为:
其中:
-
-
是损失函数关于参数
的梯度。
-
是 L2 正则化项的梯度,对应的是参数值本身的衰减。
很明显,参数越大惩罚力度就越大,从而让参数逐渐趋向于较小值,避免出现过大的参数。
3.1.3 作用
-
防止过拟合:当模型过于复杂、参数较多时,模型会倾向于记住训练数据中的噪声,导致过拟合。L2 正则化通过抑制参数的过大值,使得模型更加平滑,降低模型对训练数据噪声的敏感性。
-
限制模型复杂度:L2 正则化项强制权重参数尽量接近 0,避免模型中某些参数过大,从而限制模型的复杂度。通过引入平方和项,L2 正则化鼓励模型的权重均匀分布,避免单个权重的值过大。
-
提高模型的泛化能力:正则化项的存在使得模型在测试集上的表现更加稳健,避免在训练集上取得极高精度但在测试集上表现不佳。
-
平滑权重分布:L2 正则化不会将权重直接变为 0,而是将权重值缩小。这样模型就更加平滑的拟合数据,同时保留足够的表达能力。
3.2 L1正则化
L1 正则化通过在损失函数中添加权重参数的绝对值之和来约束模型的复杂度。
3.2.1 数学表示
设模型的原始损失函数为,其中
表示模型权重参数,则加入 L1 正则化后的损失函数表示为:
其中:
-
-
-
是模型第i 个参数的绝对值。
-
是所有权重参数的绝对值之和,这个项即为 L1 正则化项。
3.2.2 梯度更新
在 L1 正则化下,梯度更新时的公式是:
其中:
-
-
-
是参数
因为 L1 正则化依赖于参数的绝对值,其梯度更新时不是简单的线性缩小,而是通过符号函数来直接调整参数的方向。这就是为什么 L1 正则化能促使某些参数完全变为 0。
3.2.3 作用
-
稀疏性:L1 正则化的一个显著特性是它会促使许多权重参数变为 零。这是因为 L1 正则化倾向于将权重绝对值缩小到零,使得模型只保留对结果最重要的特征,而将其他不相关的特征权重设为零,从而实现 特征选择 的功能。
-
防止过拟合:通过限制权重的绝对值,L1 正则化减少了模型的复杂度,使其不容易过拟合训练数据。相比于 L2 正则化,L1 正则化更倾向于将某些权重完全移除,而不是减小它们的值。
-
简化模型:由于 L1 正则化会将一些权重变为零,因此模型最终会变得更加简单,仅依赖于少数重要特征。这对于高维度数据特别有用,尤其是在特征数量远多于样本数量的情况下。
-
特征选择:因为 L1 正则化会将部分权重置零,因此它天然具有特征选择的能力,有助于自动筛选出对模型预测最重要的特征。
3.2.4 与L2对比
-
L1 正则化 更适合用于产生稀疏模型,会让部分权重完全为零,适合做特征选择。
-
L2 正则化 更适合平滑模型的参数,避免过大参数,但不会使权重变为零,适合处理高维特征较为密集的场景。
代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 设置随机种子以保证可重复性
torch.manual_seed(42)
# 生成随机数据
n_samples = 100
n_features = 20
X = torch.randn(n_samples, n_features) # 输入数据
y = torch.randn(n_samples, 1) # 目标值
# 定义一个简单的全连接神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(n_features, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
# 训练函数
def train_model(use_l2=False, weight_decay=0.01, n_epochs=100):
# 初始化模型
model = SimpleNet()
criterion = nn.MSELoss() # 损失函数(均方误差)
# 选择优化器
if use_l2:
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=weight_decay) # 使用 L2 正则化
else:
optimizer = optim.SGD(model.parameters(), lr=0.01) # 不使用 L2 正则化
# 记录训练损失
train_losses = []
# 训练过程
for epoch in range(n_epochs):
optimizer.zero_grad() # 清空梯度
outputs = model(X) # 前向传播
loss = criterion(outputs, y) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
train_losses.append(loss.item()) # 记录损失
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{n_epochs}], Loss: {loss.item():.4f}')
return train_losses
# 训练并比较两种模型
train_losses_no_l2 = train_model(use_l2=False) # 不使用 L2 正则化
train_losses_with_l2 = train_model(use_l2=True, weight_decay=0.01) # 使用 L2 正则化
# 绘制训练损失曲线
plt.plot(train_losses_no_l2, label='Without L2 Regularization')
plt.plot(train_losses_with_l2, label='With L2 Regularization')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss: L2 Regularization vs No Regularization')
plt.legend()
plt.show()3.3 Dropout
Dropout 的工作流程如下:
-
在每次训练迭代中,随机选择一部分神经元(通常以概率 p丢弃,比如 p=0.5)。
-
被选中的神经元在当前迭代中不参与前向传播和反向传播。
-
在测试阶段,所有神经元都参与计算,但需要对权重进行缩放(通常乘以 1−p),以保持输出的期望值一致。
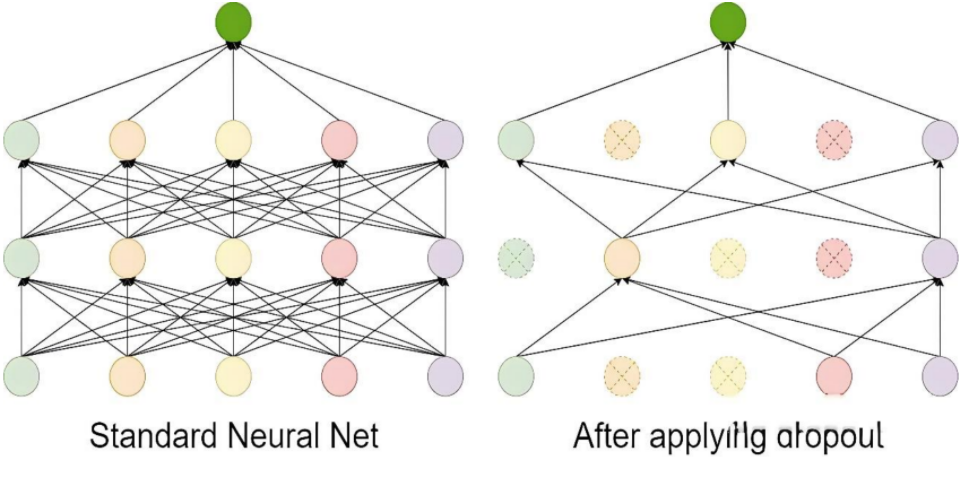
Dropout 是一种在训练过程中随机丢弃部分神经元的技术。它通过减少神经元之间的依赖来防止模型过于复杂,从而避免过拟合。
代码示例:
import torch
from torch import nn
from torch.nn.functional import dropout
def test01():
x = torch.randint(0, 10, (5, 6), dtype=torch.float)
dropout=nn.Dropout(p=0.5)
print(x)
print(dropout(x))
if __name__=="__main__":
test01()案例:
import torch
from torch import nn
from PIL import Image
from torchvision import transforms
import os
from matplotlib import pyplot as plt
torch.manual_seed(42)
def load_img(path, resize=(224, 224)):
pil_img = Image.open(path).convert('RGB')
print("Original image size:", pil_img.size) # 打印原始尺寸
transform = transforms.Compose([
transforms.Resize(resize),
transforms.ToTensor() # 转换为Tensor并自动归一化到[0,1]
])
return transform(pil_img) # 返回[C,H,W]格式的tensor
if __name__ == '__main__':
dirpath = os.path.dirname(__file__)
path = os.path.join(dirpath, 'datasets','images', '100.jpg') # 使用os.path.join更安全
# 加载图像 (已经是[0,1]范围的Tensor)
trans_img = load_img(path)
# 添加batch维度 [1, C, H, W],因为Dropout默认需要4D输入
trans_img = trans_img.unsqueeze(0)
print(trans_img.shape)
# 创建Dropout层
dropout = nn.Dropout2d(p=0.2)
drop_img = dropout(trans_img)
# 移除batch维度并转换为[H,W,C]格式供matplotlib显示
trans_img = trans_img.squeeze(0).permute(1, 2, 0).numpy()
drop_img = drop_img.squeeze(0).permute(1, 2, 0).numpy()
# 确保数据在[0,1]范围内
drop_img = drop_img.clip(0, 1)
# 显示图像
fig = plt.figure(figsize=(10, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.imshow(trans_img)
ax2 = fig.add_subplot(1, 2, 2)
ax2.imshow(drop_img)
plt.show()Dropout过程:
-
按照指定的概率把部分神经元的值设置为0;
-
为了规避该操作带来的影响,需对非 0 的元素使用缩放因子1/(1-p)进行强化。
假设某个神经元的输出为 x,Dropout 的操作可以表示为:
-
在训练阶段:

-
在测试阶段:y=x
3.5 数据增强
样本数量不足(即训练数据过少)是导致过拟合(Overfitting)的常见原因之一,可以从以下角度理解:
-
当训练数据过少时,模型容易“记住”有限的样本(包括噪声和无关细节),而非学习通用的规律。
-
简单模型更可能捕捉真实规律,但数据不足时,复杂模型会倾向于拟合训练集中的偶然性模式(噪声)。
-
样本不足时,训练集的分布可能与真实分布偏差较大,导致模型学到错误的规律。
-
小数据集中,个别样本的噪声(如标注错误、异常值)会被放大,模型可能将噪声误认为规律。
数据增强(Data Augmentation)是一种通过人工生成或修改训练数据来增加数据集多样性的技术,常用于解决过拟合问题。数据增强通过“模拟”更多训练数据,迫使模型学习泛化性更强的规律,而非训练集中的偶然性模式。其本质是一种低成本的正则化手段,尤其在数据稀缺时效果显著。
在了解计算机如何处理图像之前,需要先了解图像的构成元素。
图像是由像素点组成的,每个像素点的值范围为: [0, 255], 像素值越大意味着较亮。比如一张 200x200 的图像, 则是由 40000 个像素点组成, 如果每个像素点都是 0 的话, 意味着这是一张全黑的图像。
我们看到的彩色图一般都是多通道的图像, 所谓多通道可以理解为图像由多个不同的图像层叠加而成, 例如我们看到的彩色图像一般都是由 RGB 三个通道组成的,还有一些图像具有 RGBA 四个通道,最后一个通道为透明通道,该值越小,则图像越透明。
数据增强是提高模型泛化能力(鲁棒性)的一种有效方法,尤其在图像分类、目标检测等任务中。数据增强可以模拟更多的训练样本,从而减少过拟合风险。数据增强通过torchvision.transforms模块来实现。
数据增强的好处
大幅度降低数据采集和标注成本;
模型过拟合风险降低,提高模型泛化能力;
官方地址:
transforms:Transforming and augmenting images — Torchvision 0.22 documentation
transforms:
常用变换类
-
transforms.Compose:将多个变换操作组合成一个流水线。
-
transforms.ToTensor:将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,将图像数据从 uint8 类型 (0-255) 转换为 float32 类型 (0.0-1.0)。
-
transforms.Normalize:对张量进行标准化。
-
transforms.Resize:调整图像大小。
-
transforms.CenterCrop:从图像中心裁剪指定大小的区域。
-
transforms.RandomCrop:随机裁剪图像。
-
transforms.RandomHorizontalFlip:随机水平翻转图像。
-
transforms.RandomVerticalFlip:随机垂直翻转图像。
-
transforms.RandomRotation:随机旋转图像。
-
transforms.ColorJitter:随机调整图像的亮度、对比度、饱和度和色调。
-
transforms.RandomGrayscale:随机将图像转换为灰度图像。
-
transforms.RandomResizedCrop:随机裁剪图像并调整大小。
3.5.1 图片缩放
具体参考官方文档:Illustration of transforms — Torchvision 0.22 documentation
3.5.2 随机裁剪
3.5.3 随机水平翻转
RandomHorizontalFlip(p):随机水平翻转图像,参数p表示翻转概率(0 ≤ p ≤ 1),p=1 表示必定翻转,p=0 表示不翻转
3.5.4 调整图片颜色
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)brightness:
-
亮度调整的范围。
-
可以
float或(min, max)元组:-
如果是
float(如brightness=0.2),则亮度在[max(0, 1 - 0.2), 1 + 0.2] = [0.8, 1.2]范围内随机缩放。 -
如果是
(min, max)(如brightness=(0.5, 1.5)),则亮度在[0.5, 1.5]范围内随机缩放。
-
contrast:
-
对比度调整的范围。
-
格式与 brightness 相同。
saturation:
-
饱和度调整的范围。
-
格式与 brightness 相同。
hue:
-
色调调整的范围。
-
可以是一个浮点数(表示相对范围)或一个元组 (min, max)。
-
取值范围必须为
[-0.5, 0.5](因为色相在 HSV 色彩空间中是循环的,超出范围会导致颜色异常)。 -
例如,hue=0.1 表示色调在 [-0.1, 0.1] 之间随机调整。
3.5.5 随机旋转
RandomRotation用于对图像进行随机旋转。
transforms.RandomRotation(
degrees,
interpolation=InterpolationMode.NEAREST,
expand=False,
center=None,
fill=0
)degrees:
-
旋转角度的范围,可以是一个浮点数或元组 (min_degree, max_degree)。
-
例如,degrees=30 表示旋转角度在 [-30, 30] 之间随机选择。
-
例如,degrees=(30, 60) 表示旋转角度在 [30, 60] 之间随机选择。
interpolation:
-
插值方法,用于旋转图像。
-
默认是 InterpolationMode.NEAREST(最近邻插值)。
-
其他选项包括 InterpolationMode.BILINEAR(双线性插值)、InterpolationMode.BICUBIC(双三次插值)等。
expand:
-
是否扩展图像大小以适应旋转后的图像。如:当需要保留完整旋转后的图像时(如医学影像、文档扫描)
-
如果为 True,旋转后的图像可能会比原始图像大。
-
如果为 False,旋转后的图像大小与原始图像相同。
center:
-
旋转中心点的坐标,默认为图像中心。
-
可以是一个元组 (x, y),表示旋转中心的坐标。
fill:
-
旋转后图像边缘的填充值。
-
可以是一个浮点数(用于灰度图像)或一个元组(用于 RGB 图像)。默认填充0(黑色)
3.5.6 图片转Tensor
3.5.7 Tensor转图片
代码示例:
import torch
from torchvision import transforms
from PIL import Image
from matplotlib import pyplot as plt
def test01():
path='datasets/images/100.jpg'
img=Image.open(path)
print(img.size)
transform = transforms.Compose([
# 调整图像大小
transforms.Resize((224, 224)),
transforms.ToTensor()
])
t_img=transform(img)
print(t_img.size())
t_img=torch.permute(t_img,(1,2,0))
plt.imshow(t_img)
plt.show()
def test02():
path = 'datasets/images/100.jpg'
img = Image.open(path)
print(img.size)
transform = transforms.Compose([
# 随机裁剪
transforms.RandomCrop(size=(224, 224)),
transforms.ToTensor()
])
t_img = transform(img)
print(t_img.size())
t_img = torch.permute(t_img, (1, 2, 0))
plt.imshow(t_img)
plt.show()
def test03():
path = 'datasets/images/100.jpg'
img = Image.open(path)
print(img.size)
transform = transforms.Compose([
# 随即水平翻转
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()
])
t_img = transform(img)
print(t_img.size())
t_img = torch.permute(t_img, (1, 2, 0))
plt.imshow(t_img)
plt.show()
def test04():
path = 'datasets/images/100.jpg'
img = Image.open(path)
print(img.size)
transform = transforms.Compose([
# 随机旋转
# degree参数:degree=30,表示在(-30,30)之间随即旋转,degrees=(30, 60) 表示旋转角度在 [30, 60] 之间随机选择
transforms.RandomRotation((30,60)),
transforms.ToTensor()
])
t_img = transform(img)
print(t_img.size())
t_img = torch.permute(t_img, (1, 2, 0))
plt.imshow(t_img)
plt.show()
def test05():
t=torch.randn(3,224,224)
transform=transforms.Compose([
# 张量转PIL图片
transforms.ToPILImage()
])
img=transform(t)
print(img.size)
img.show()
def test06():
path = 'datasets/images/100.jpg'
img = Image.open(path)
print(img.size)
transform = transforms.Compose([
transforms.ToTensor(),
# Normalize:标准化
# mean:均值
# std:标准差
# 如果数据集是官方数据集,需要查看官方提供的mean和std
# 如果是自定义数据集,可以将mean和std设置为[0.5,0.5,0.5],是一个经验值
# Normalize要放在ToTensor后,否则会报错
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])
])
t_img = transform(img)
print(t_img.size())
t_img = torch.permute(t_img, (1, 2, 0))
plt.imshow(t_img)
plt.show()
if __name__=='__main__':
# test01()
# test02()
# test03()
# test04()
# test05()
test06()案例:
import matplotlib.pyplot as plt
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms, datasets, utils
def test01():
# 定义数据增强和归一化
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转 ±10 度
transforms.RandomResizedCrop(
32, scale=(0.8, 1.0)
), # 随机裁剪到 32x32,缩放比例在0.8到1.0之间
transforms.ColorJitter(
brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1
), # 随机调整亮度、对比度、饱和度、色调
transforms.ToTensor(), # 转换为 Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化,这是一种常见的经验设置,适用于数据范围 [0, 1],使其映射到 [-1, 1]
]
)
# 加载 CIFAR-10 数据集,并应用数据增强
trainset = datasets.CIFAR10(root="./datasets/cifar10", train=True, download=True, transform=transform)
dataloader = DataLoader(trainset, batch_size=4, shuffle=False)
# 获取一个批次的数据
images, labels = next(iter(dataloader))
# 还原图片并显示
plt.figure(figsize=(10, 5))
for i in range(4):
# 反归一化:将像素值从 [-1, 1] 还原到 [0, 1]
img = images[i] / 2 + 0.5
# 转换为 PIL 图像
img_pil = transforms.ToPILImage()(img)
# 显示图片
plt.subplot(1, 4, i + 1)
plt.imshow(img_pil)
plt.axis('off')
plt.title(f'Label: {labels[i]}')
plt.show()
if __name__ == "__main__":
test01()
九、批量标准化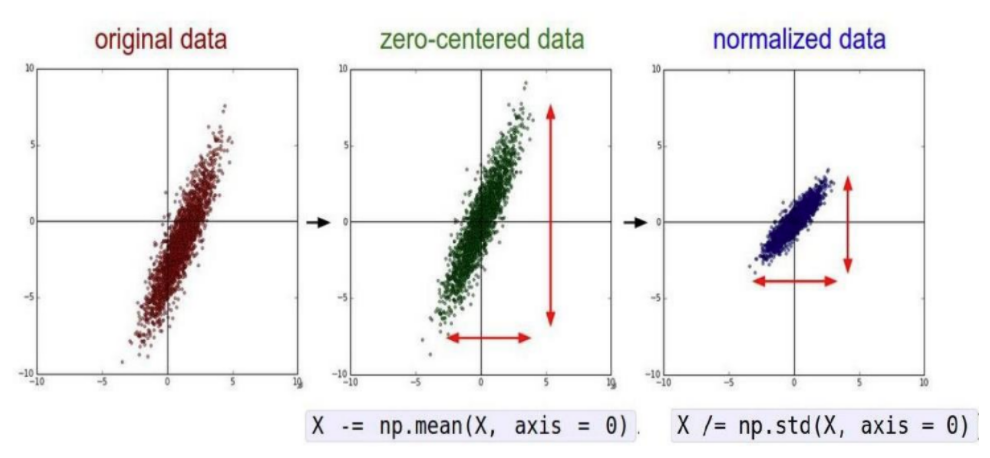
批量标准化(Batch Normalization, BN)是一种广泛使用的神经网络正则化技术,核心思想是对每一层的输入进行标准化,然后进行缩放和平移,旨在加速训练、提高模型的稳定性和泛化能力。批量标准化通常在全连接层或卷积层之后、激活函数之前应用。
核心思想
Batch Normalization(BN)通过对每一批(batch)数据的每个特征通道进行标准化,解决内部协变量偏移(Internal Covariate Shift)问题,从而:
-
加速网络训练
-
允许使用更大的学习率
-
减少对初始化的依赖
-
提供轻微的正则化效果
批量标准化的基本思路是在每一层的输入上执行标准化操作,并学习两个可训练的参数:缩放因子 \gamma 和偏移量 \beta。
在深度学习中,批量标准化(Batch Normalization)在训练阶段和测试阶段的行为是不同的。在测试阶段,由于没有 mini-batch 数据,无法直接计算当前 batch 的均值和方差,因此需要使用训练阶段计算的全局统计量(均值和方差)来进行标准化。
官网地址:torch.nn — PyTorch 2.7 documentation
1. 训练阶段的批量标准化
1.1 计算均值和方差
对于给定的神经网络层,假设输入数据为,其中 m是批次大小。我们首先计算该批次数据的均值和方差。
-
均值(Mean)
-
方差
1.2 标准化
使用计算得到的均值和方差对数据进行标准化,使得每个特征的均值为0,方差为1。
-
标准化后的值
其中,
1.3 缩放和平移
标准化后的数据通常会通过可训练的参数进行缩放和平移,以恢复模型的表达能力。
-
缩放(Gamma):
-
平移(Beta):
其中,
和
1.4 更新全局统计量
通过指数移动平均(Exponential Moving Average, EMA)更新全局均值和方差:
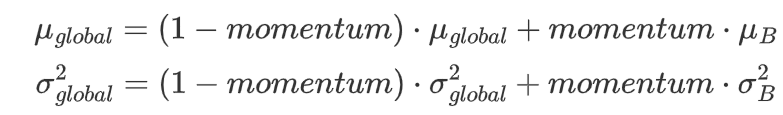
其中,momentum 是一个超参数,控制当前 mini-batch 统计量对全局统计量的贡献。
momentum 是一个介于 0 和 1 之间的值,控制当前 mini-batch 统计量的权重。PyTorch 中 momentum 的默认值是 0.1。
与优化器中的 momentum 的区别
-
批量标准化中的 momentum:
-
用于更新全局统计量(均值和方差)。
-
控制当前 mini-batch 统计量对全局统计量的贡献。
-
-
优化器中的 momentum:
-
用于加速梯度下降过程,帮助跳出局部最优。
-
例如,SGD 优化器中的 momentum 参数。
-
两者虽然名字相同,但作用完全不同,不要混淆
2. 测试阶段的批量标准化
在测试阶段,由于没有 mini-batch 数据,无法直接计算当前 batch 的均值和方差。因此,使用训练阶段通过 EMA 计算的全局统计量(均值和方差)来进行标准化。
在测试阶段,使用全局统计量对输入数据进行标准化:
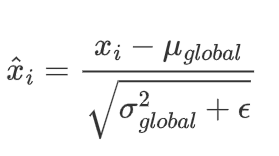
然后对标准化后的数据进行缩放和平移:
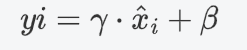
为什么使用全局统计量?
一致性:
-
在测试阶段,输入数据通常是单个样本或少量样本,无法准确计算均值和方差。
-
使用全局统计量可以确保测试阶段的行为与训练阶段一致。
稳定性:
-
全局统计量是通过训练阶段的大量 mini-batch 数据计算得到的,能够更好地反映数据的整体分布。
-
使用全局统计量可以减少测试阶段的随机性,使模型的输出更加稳定。
效率:
-
在测试阶段,使用预先计算的全局统计量可以避免重复计算,提高效率。
3. 作用
批量标准化(Batch Normalization, BN)通过以下几个方面来提高神经网络的训练稳定性、加速训练过程并减少过拟合:
3.1 缓解梯度问题
标准化处理可以防止激活值过大或过小,避免了激活函数(如 Sigmoid 或 Tanh)饱和的问题,从而缓解梯度消失或爆炸的问题。
3.2 加速训练
由于 BN 使得每层的输入数据分布更为稳定,因此模型可以使用更高的学习率进行训练。这可以加快收敛速度,并减少训练所需的时间。
3.3 减少过拟合
-
类似于正则化:虽然 BN 不是一种传统的正则化方法,但它通过对每个批次的数据进行标准化,可以起到一定的正则化作用。它通过在训练过程中引入了噪声(由于批量均值和方差的估计不完全准确),这有助于提高模型的泛化能力。
-
避免对单一数据点的过度拟合:BN 强制模型在每个批次上进行标准化处理,减少了模型对单个训练样本的依赖。这有助于模型更好地学习到数据的整体特征,而不是对特定样本的噪声进行过度拟合。
4.函数说明
torch.nn.BatchNorm1d 是 PyTorch 中用于一维数据的批量标准化(Batch Normalization)模块。
torch.nn.BatchNorm1d(
num_features, # 输入数据的特征维度
eps=1e-05, # 用于数值稳定性的小常数
momentum=0.1, # 用于计算全局统计量的动量
affine=True, # 是否启用可学习的缩放和平移参数
track_running_stats=True, # 是否跟踪全局统计量
device=None, # 设备类型(如 CPU 或 GPU)
dtype=None # 数据类型
)参数说明:
eps:用于数值稳定性的小常数,添加到方差的分母中,防止除零错误。默认值:1e-05
momentum:用于计算全局统计量(均值和方差)的动量。默认值:0.1,参考本节1.4
affine:是否启用可学习的缩放和平移参数(γ和 β)。如果 affine=True,则模块会学习两个参数;如果 affine=False,则不学习参数,直接输出标准化后的值 \hat x_i。默认值:True
track_running_stats:是否跟踪全局统计量(均值和方差)。如果 track_running_stats=True,则在训练过程中计算并更新全局统计量,并在测试阶段使用这些统计量。如果 track_running_stats=False,则不跟踪全局统计量,每次标准化都使用当前 mini-batch 的统计量。默认值:True
代码示例:
import torch
from torch import nn
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
from torch import optim
from torch.nn import CrossEntropyLoss
# 同心圆数据
def build_data():
x,y=make_circles(
n_samples=2000,
factor=0.4,
noise=0.1,
random_state=42
)
print(x[0])
print(y[0:5])
x=torch.tensor(x,dtype=torch.float)
y=torch.tensor(y,dtype=torch.long)
# plt.scatter(x[:,0],x[:,1],c=y)
# plt.show()
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=42)
return x_train,x_test,y_train,y_test
# 构建网络模型:带批量标准化
class NetWithBN(nn.Module):
def __init__(self,in_features,out_features):
super().__init__()
self.fc1=nn.Linear(in_features,128)
self.bn1=nn.BatchNorm1d(128)
self.relu1=nn.ReLU()
self.fc2=nn.Linear(128,64)
self.bn2=nn.BatchNorm1d(64)
self.relu2=nn.ReLU()
self.fc3=nn.Linear(64,out_features)
def forward(self,x):
x=self.relu1(self.bn1(self.fc1(x)))
x=self.relu2(self.bn2(self.fc2(x)))
x=self.fc3(x)
return x
# 创建网络模型,不使用标准化
class NetWithoutBN(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.fc1 = nn.Linear(in_features, 128)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(128, 64)
self.relu2 = nn.ReLU()
self.fc3 = nn.Linear(64, out_features)
def forward(self,x):
x = self.relu1(self.fc1(x))
x = self.relu2(self.fc2(x))
x = self.fc3(x)
return x
def train(model,x_train,y_train,epochs):
# 如果网络模型中使用了dropout或批量标准化,train()默认启动dropout或批量标准化的功能
model.train()
criterion=nn.CrossEntropyLoss()
opt=optim.SGD(model.parameters(),lr=0.1)
loss_list=[]
for epoch in range(epochs):
y_pred=model(x_train)
print(y_pred[0])
print(y_train.shape)
loss=criterion(y_pred,y_train)
opt.zero_grad()
loss.backward()
opt.step()
loss_list.append(loss.item())
return loss_list
def eval(model,x_test,y_test,epochs):
# 验证阶段会自动关闭dropout或批量标准化的参数更新
model.eval()
acc_list=[]
for epoch in range(epochs):
with torch.no_grad():
y_pred = model(x_test)
_, pred = torch.max(y_pred, dim=1)
correct=(pred==y_test).sum().item()
acc=correct /len(y_test)
acc_list.append(acc)
return acc_list
def plot(bn_loss_list,no_bn_loss_list,bn_acc_list,no_bn_acc_list):
fig = plt.figure(figsize=(12, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(bn_loss_list, 'b', label='BN')
ax1.plot(no_bn_loss_list, 'r', label='NoBN')
ax1.legend()
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(bn_acc_list, 'b', label='BN')
ax2.plot(no_bn_acc_list, 'r', label='NoBN')
ax2.legend()
plt.show()
if __name__=='__main__':
x_train,x_test,y_train,y_test=build_data()
bn_model=NetWithBN(2,2)
nobn_model=NetWithoutBN(2,2)
bn_loss_list=train(bn_model,x_train,y_train,100)
no_bn_loss_list=train(nobn_model,x_train,y_train,100)
bn_acc_list=eval(bn_model,x_test,y_test,epochs=100)
no_bn_acc_list=eval(nobn_model,x_test,y_test,epochs=100)
plot(bn_loss_list,no_bn_loss_list,bn_acc_list,no_bn_acc_list)
十、模型的保存和加载
训练一个模型通常需要大量的数据、时间和计算资源。通过保存训练好的模型,可以满足后续的模型部署、模型更新、迁移学习、训练恢复等各种业务需要求。
代码示例:
import torch
from torch import nn
class MyNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1=nn.Linear(10,64)
self.fc2=nn.Linear(64,5)
def forward(self,x):
x=self.fc1(x)
x=self.fc2(x)
return x
# 保存模型
def test01():
model=MyNet()
print(model)
torch.save(model,'./model/fcnn_model.pt')
# 加载模型
# 得到的是完整的模型对象
def test02():
model=torch.load('./model/fcnn_model.pt')
print(model)
# 保存模型参数
def test03():
model=MyNet()
state_dict=model.state_dict()
torch.save(state_dict,'./model/fcnn_state_dict.pt')
# 加载模型参数
# 如果保存的是模型参数,加载的是字典,内容是模型参数,并不是完整的模型
# 需要实现初始化模型,然后把模型参数导入到模型中
def test04():
model=MyNet()
state_dict=torch.load('./model/fcnn_state_dict.pt')
model.load_state_dict(state_dict)
print(model)
if __name__=='__main__':
# test01()
# test02()
# test03()
test04()十一、项目实战
1.使用全连接网络训练和验证MNIST数据集
代码:
# 使用全连接网络训练和预测MNIST数据集
# 1.数据准备:通过数据加载器加载官方MNIST数据集
# 2.构建网络结构
# 3.实现训练方法,使用交叉熵损失函数,Adam优化器
# 4.实现验证方法
# 5.通过测试图片进行预测
import torch
from torch import nn,optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from PIL import Image
def build_data():
transform=transforms.Compose([
transforms.Resize((28,28)),
transforms.ToTensor()
])
# 训练数据集
train_dataset=datasets.MNIST(
root='./datasets',
train=True,
download=True,
transform=transform
)
# 验证数据集
val_dataset=datasets.MNIST(
root='./datasets',
train=False,
download=True,
transform=transform
)
# 训练数据加载器
train_dataloader=DataLoader(
dataset=train_dataset,
batch_size=64,
shuffle=True
)
# 验证数据加载器
val_dataloader=DataLoader(
dataset=val_dataset,
batch_size=64,shuffle=True
)
return train_dataloader,val_dataloader
# 构建网络结构
class MNISTNet(nn.Module):
def __init__(self,in_features,out_features):
super().__init__()
self.fc1=nn.Linear(in_features,128)
self.bn1=nn.BatchNorm1d(128)
self.relu1=nn.ReLU()
self.fc2=nn.Linear(128,64)
self.bn2=nn.BatchNorm1d(64)
self.relu2=nn.ReLU()
self.fc3=nn.Linear(64,out_features)
def forward(self,x):
x=x.view(-1,1*28*28)
x=self.relu1(self.bn1(self.fc1(x)))
x = self.relu2(self.bn2(self.fc2(x)))
x=self.fc3(x)
return x
# 训练
def train(model,train_dataloader,lr,epochs):
model.train()
criterion=nn.CrossEntropyLoss()
opt=optim.Adam(model.parameters(),lr=lr,betas=(0.9,0.999),eps=1e-8,weight_decay=0.001)
for epoch in range(epochs):
correct=0
for tx,ty in train_dataloader:
y_pred=model(tx)
loss=criterion(y_pred,ty)
opt.zero_grad()
loss.backward()
opt.step()
_,pred=torch.max(y_pred.data,dim=1)
correct+=(pred==ty).sum().item()
acc=correct/len(train_dataloader.dataset)
print(f'epoch:{epoch},loss:{loss.item():.4f},acc:{acc:.4f}')
def eval(model,val_dataloader):
model.eval()
criterion=nn.CrossEntropyLoss()
correct=0
for vx,vy in val_dataloader:
with torch.no_grad():
y_pred=model(vx)
loss=criterion(y_pred,vy)
_,pred=torch.max(y_pred,dim=1)
correct+=(pred==vy).sum().item()
acc=correct/len(val_dataloader.dataset)
print(f'loss:{loss.item()},acc:{acc}')
def save_model(model,path):
torch.save(model.state_dict(),path)
def load_model(path):
model=MNISTNet(1*28*28,10)
model.load_state_dict(torch.load(path))
return model
def predict(test_path,model_path):
transform=transforms.Compose([
transforms.Resize((28,28)),
transforms.ToTensor()
])
img=Image.open(test_path).convert('L')
t_img=transform(img).unsqueeze(0)
model=load_model(model_path)
model.eval()
with torch.no_grad():
y_pred=model(t_img)
_,pred=torch.max(y_pred,dim=1)
print(f"预测分类:{pred.item()}")
if __name__=='__main__':
# train_dataloader,val_dataloader=build_data()
# model=MNISTNet(1*28*28,10)
# train(model,train_dataloader,lr=0.01,epochs=20)
# eval(model,val_dataloader)
# save_model(model,'./model/mnist_model.pt')
predict('./datasets/images/7.png','./model/mnist_model.pt')
2.使用全连接网络训练和验证CIFAR10数据集
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch import optim
# 数据预处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
# 数据准备
train_dataset = datasets.CIFAR10(root='./cifar10', train=True, transform=transform, download=True)
eval_dataset = datasets.CIFAR10(root='./cifar10', train=False, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
eval_loader = DataLoader(dataset=eval_dataset, batch_size=512, shuffle=True)
# 定义网络结构
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc1 = nn.Linear(32 * 32 * 3, 1024)
self.bn1 = nn.BatchNorm1d(1024)
self.dropout1 = nn.Dropout(0.3)
self.fc2 = nn.Linear(1024, 512)
self.bn2 = nn.BatchNorm1d(512)
self.dropout2 = nn.Dropout(0.3)
self.fc3 = nn.Linear(512, 256) # 增加第三层
self.bn3 = nn.BatchNorm1d(256)
self.fc4 = nn.Linear(256, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 32 * 32 * 3)
x = self.dropout1(self.bn1(self.fc1(x)))
x = self.relu(x)
x = self.dropout2(self.bn2(self.fc2(x)))
x = self.relu(x)
x = self.bn3(self.fc3(x))
x = self.relu(x)
x = self.fc4(x)
return x
model = MyNet()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(model, train_loader, epochs):
model.train()
for epoch in range(epochs):
correct = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, predicted = torch.max(output.data, 1)
correct += (predicted.eq(target)).sum().item()
correct /= len(train_loader.dataset)
print(f'Train Epoch: {epoch} , loss: {loss.item():.4f},acc:{correct:.4f}')
def eval(model, eval_loader):
model.eval()
eval_loss = 0
correct = 0
with torch.no_grad():
for data, target in eval_loader:
data, target = data.to(device), target.to(device)
output = model(data)
eval_loss += criterion(output, target).item()
_, predicted = torch.max(output.data, 1)
correct += (predicted.eq(target)).sum().item()
eval_loss /= len(eval_loader.dataset)
acc = 100.0 * correct / len(eval_loader.dataset)
print(f'loss: {eval_loss:.4f}, acc: {acc:.4f}')
epochs = 25
train(model, train_loader, epochs)
eval(model, eval_loader)更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)