
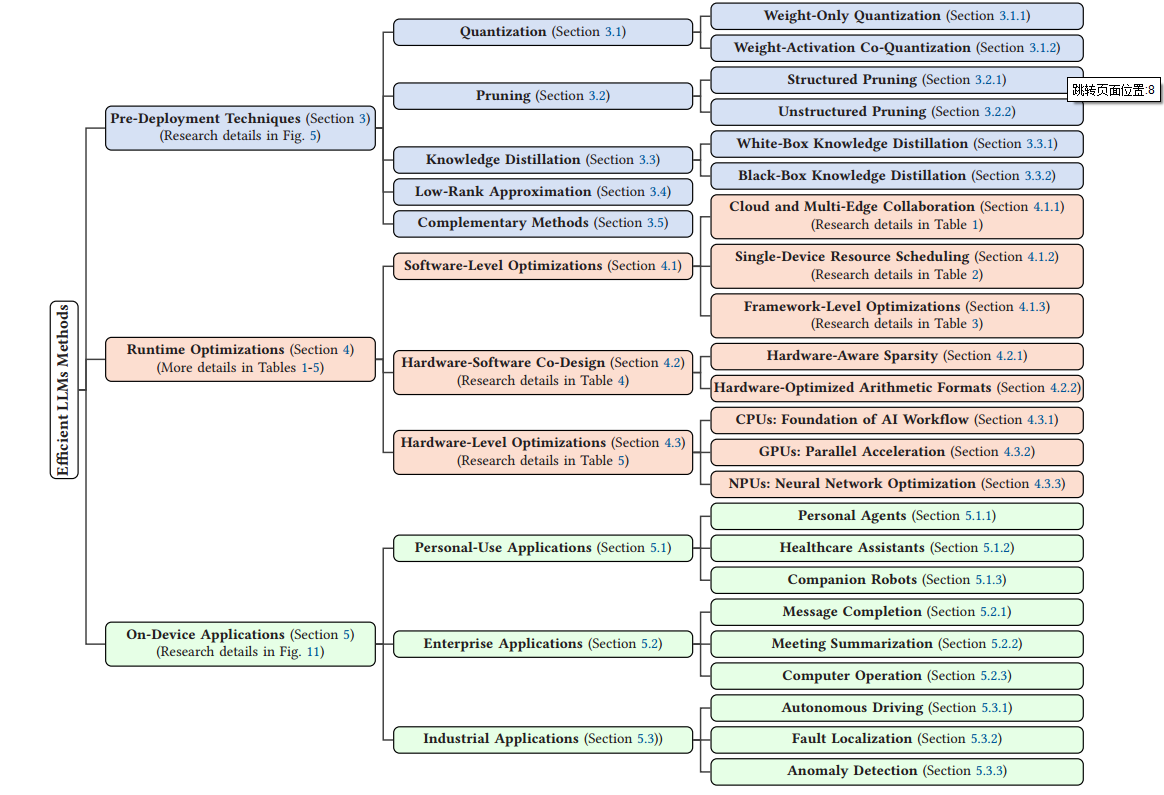
论文泛读:关于边缘大型语言模型的综述:设计、执行与应用
这种容量上的差异可能导致学生模型难以完全吸收或模仿教师模型的知识,尤其是在教师模型包含的信息过于复杂或者精细的情况下。知识蒸馏将知识从复杂的教师模型转移到简单的学生模型,以创建计算效率高的替代方案,而不会牺牲性能。但是,从大型教师模型(如LLM)中提取知识,由于转换内部表征的困难和变压器中注意力机制的复杂性,仍然具有挑战性。黑箱蒸馏还包括专注于推理跟踪的方法:这种方法试图从教师模型的推理步骤中提取
|
Title |
A Review on Edge Large Language Models: Design,Execution, and Applications |
|
Date |
23 March 2025 |
|
Link |
https://dl.acm.org/doi/10.1145/3719664 |
一、WHY
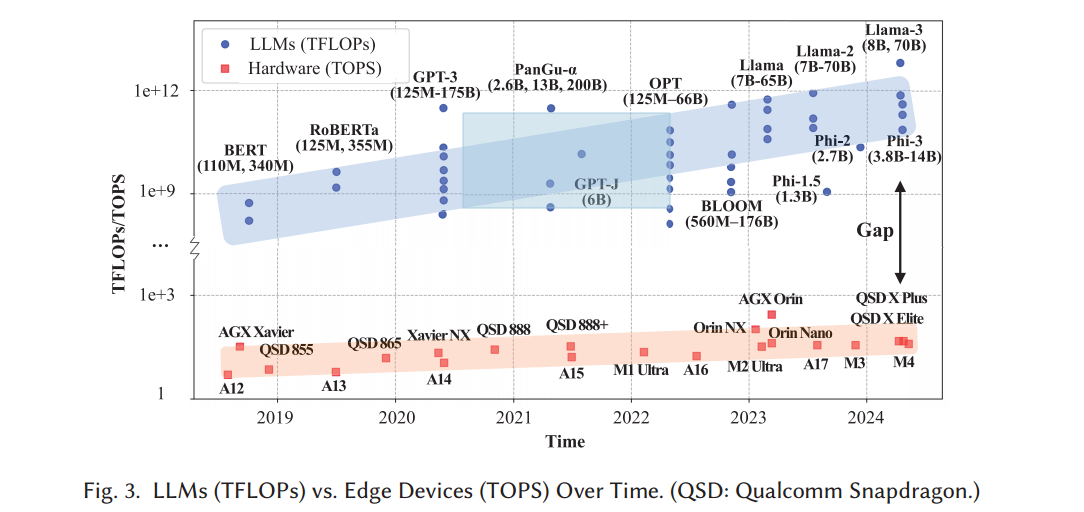
LLM计算复杂度迅速增加与边缘设备能力相对缓慢的改善之间的差距不断扩大
首先,计算和内存约束对LLM加载和推断施加了实质性限制。LLM的计算复杂度和边缘设备的能力之间的显著差异阻碍了这一努力。
其次,边缘计算设备的异构性使运行时推理优化变得复杂。
最后,开发实用的边缘应用程序仍然具有挑战性,特别是在将集中式LLM处理与分布式边缘场景连接起来方面。
二、WHAT
2.1离线预部署模型设计技术
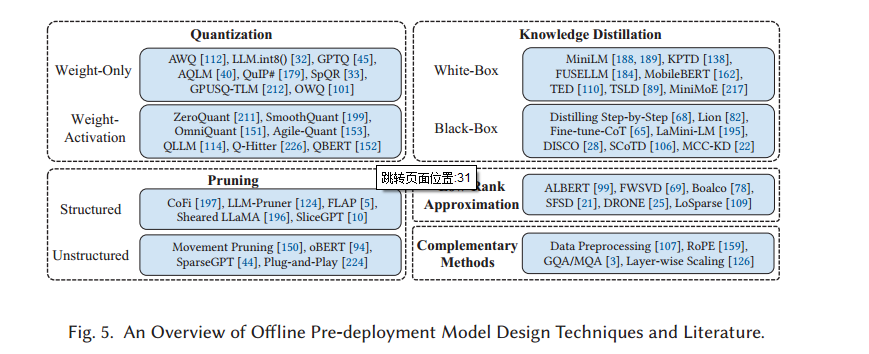
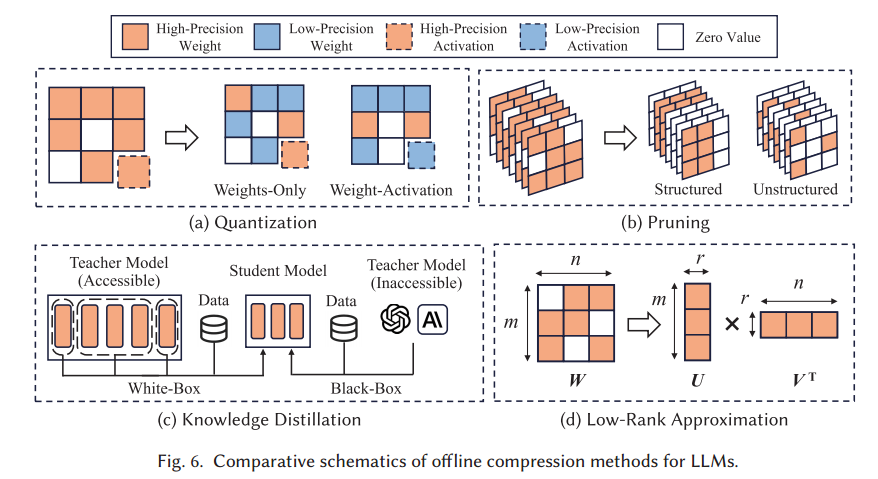
2.1.1量化
LLM模型严重依赖注意力机制和高维表示[77]。这些特性导致精度敏感的任务,并且这些模型中的高动态激活范围加剧了量化困难,常常导致性能下降。
2.1.1.1仅权重量化
仅权重量化降低了高精度数据类型的模型权重精度(例如,32位浮点)到较低精度的(例如,8位整数)
尽管有这些进步,管理离群权重中的量化误差仍然是一个挑战。
“管理离群权重”指的是处理那些在数值上显著偏离大多数其他权重的值。这些离群权重通常具有较高的重要性或者对最终输出有较大的影响,因此它们的准确表示对于保持模型性能至关重要。由于量化过程中固定使用的尺度和零点可能导致这些离群权重被不准确地表示,导致量化误差增大,这可能会影响模型的整体性能。
2.1.1.2权重-激活协同量化
在权重量化的基础上降低中间激活的精度。
尽管取得了这些进步,但在联合量化中处理离群值问题仍然是一个挑战。
2.1.2剪枝
修剪通过减少参数数量来优化LLM,从而导致更小的模型大小和更快的推理。
然而,由于其架构的复杂性和注意力头等组件的不同重要性,LLM中的修剪具有挑战性。
2.1.2.1结构化剪枝
结构化修剪通过删除整个结构组件(如神经元,通道或层)来减小神经网络的大小。
2.1.2.2非结构化剪枝
非结构化修剪删除了单个权重或神经元,导致稀疏模型更难优化。
2.1.3知识蒸馏
知识蒸馏将知识从复杂的教师模型转移到简单的学生模型,以创建计算效率高的替代方案,而不会牺牲性能。此过程减少了模型大小、计算成本和部署要求,同时增强了学生模型的多样性和稳定性。但是,从大型教师模型(如LLM)中提取知识,由于转换内部表征的困难和变压器中注意力机制的复杂性,仍然具有挑战性。
总之,白盒方法在模型内部可访问的场景中表现出色。相反,黑盒方法在无法访问模型内部的工业或专有环境中很有价值
2.1.3.1白盒知识蒸馏
白盒知识蒸馏利用对教师模型的架构和参数的访问,使用内部特征和logits(输出层的原始预测值)进行知识转移。白盒知识蒸馏需要完全访问教师模型的架构和参数。
教师和学生模型之间的容量失配:
容量失配(capacity mismatch)指的是在知识蒸馏过程中,教师模型和学生模型之间由于架构或参数量的不同而导致的表达能力差异。具体来说,教师模型通常较大、较复杂,具有更高的表达能力和性能,能够捕捉到数据中的细微模式;而学生模型则较小,设计目标是为了效率(例如更快的推理速度或更低的资源需求),因此其表达能力和性能往往低于教师模型。这种容量上的差异可能导致学生模型难以完全吸收或模仿教师模型的知识,尤其是在教师模型包含的信息过于复杂或者精细的情况下。
2.1.3.2黑盒知识蒸馏
黑盒知识蒸馏仅关注教师模型的输入和输出,而无需知道其内部结构或参数。当教师模型是专有的或通过API部署时,这种方法很有价值。
COT蒸馏
黑箱蒸馏还包括专注于推理跟踪的方法:这种方法试图从教师模型的推理步骤中提取有价值的信息,并将这些信息迁移到学生模型中,以增强学生模型的推理能力
2.1.4 低秩近似
矩阵因子分解技术,如主成分分析和正则化矩阵因子分解,在提高CNN和RNN的泛化性和互操作性方面发挥了关键作用。这些方法将高维数据减少到低维空间,提高模型性能,非常适合用于优化诸如嵌入层和注意力权重等大规模矩阵。
2.2在线运行时推理优化
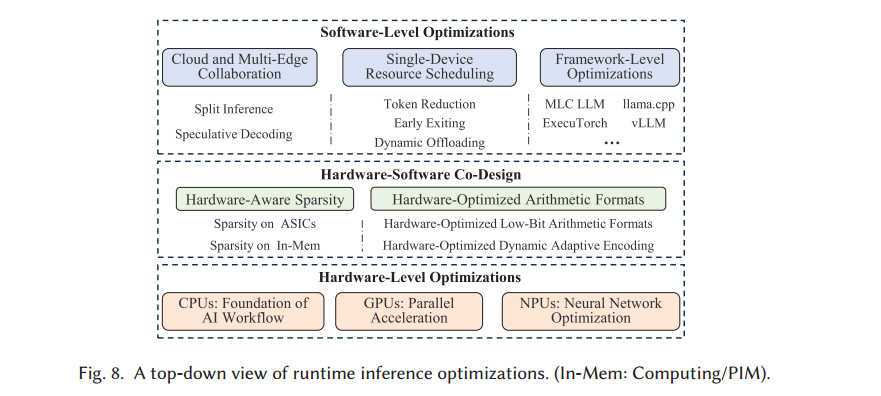
2.2.1软件级优化
2.2.1.1云和多边缘协作
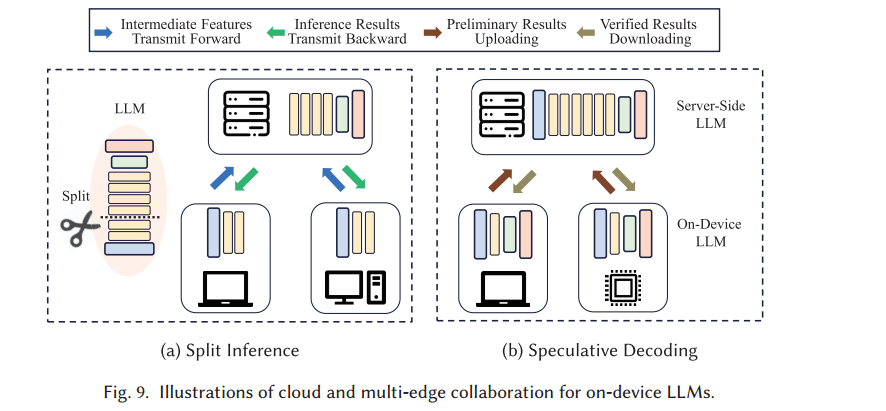
拆分推理通过跨云和边缘设备划分计算来优化资源利用率并加速推理。类似分布式计算。
关键限制:其中中间特征的传输通常会导致显著的通信开销。
推测解码从边缘设备上传初步结果并仅从云端LLM下载验证结果。这种简化的通信机制为带宽或延迟限制至关重要的场景提供了一种实用的替代方案。“并行化生成”,通过草稿模型和主模型的协作来加速序列生成。
2.2.1.2单设备资源调度
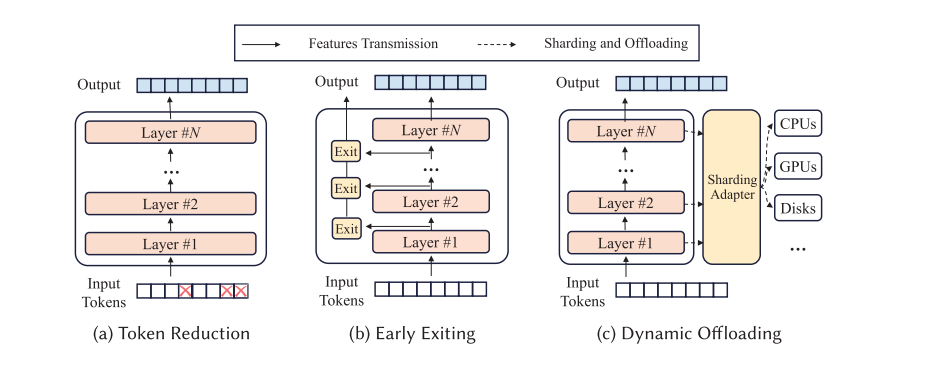
令牌缩减专注于通过选择性地消除不必要的令牌或输入来减少计算负载。
提前退出:一旦达到预定义的置信度阈值,提前退出就会终止推理,从而减少模型前向传递过程中不必要的计算。
动态卸载通过在不同的处理单元之间分配任务来进一步优化资源利用率。
2.2.1.3框架级优化
2.2.2软硬件协同设计
硬件感知稀疏性:
ASIC加速器通过细粒度稀疏性在吞吐量优化方面表现出色,而内存加速器则专注于通过基于令牌的设计减少数据移动。
硬件优化的算术格式:
低比特算术格式将模型参数的数值精度降低到固定的低比特表示,为专用硬件加速器量身定制。
动态自适应编码根据运行时要求调整数值精度,与固定的低位格式相比提供了更大的灵活性。
低比特格式提供了能效和可预测的性能,但可能会牺牲准确性,而自适应编码提供了精度灵活性,但代价是增加了复杂性。
2.2.3硬件级优化
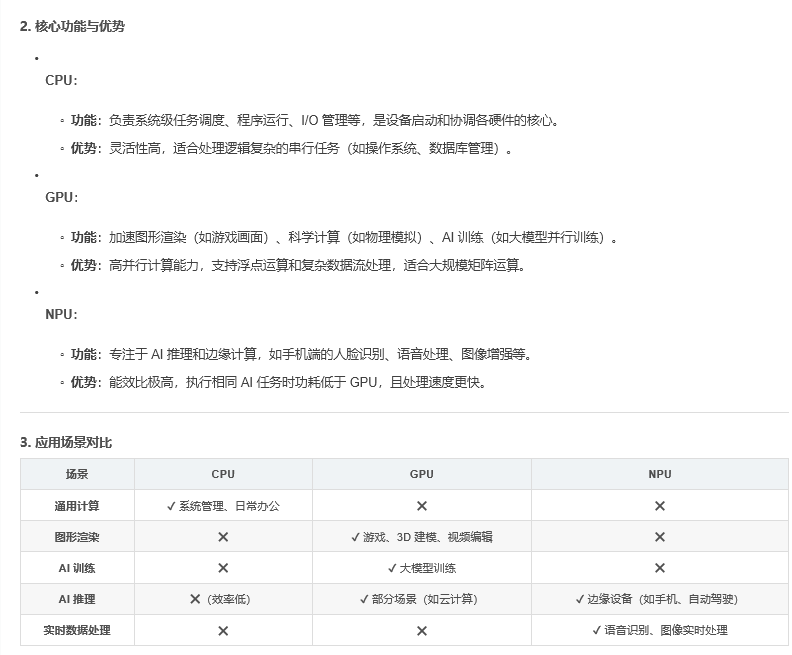
CPU的架构针对顺序任务进行了优化,难以处理LLM推理所需的并行计算
GPU:并行加速。为了解决CPU的低效率问题;然而,GPU在边缘场景中面临着巨大的功耗挑战,通常需要在云和本地资源之间分配密集计算的混合模型。
NPU:旨在优化神经网络计算,为边缘LLM推理提供性能和能效方面的实质性改进。通过采用低精度算法,(例如,INT 8)和高度并行化的架构,NPU使得能够以最小的功耗进行实时推理。然而,它们针对有限的神经网络运算符集进行了优化,使其与许多现代LLM架构不兼容。这通常会迫使诸如CPU-NPU协处理之类的回退策略,这可能会抵消性能提升。此外,因为NPU难以跟上模型的多样性和复杂性。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)