
毕业设计-基于深度学习的水果成熟腐烂检测系统 目标检测 算法
毕业设计选题-基于深度学习的水果蔬菜腐烂程度识别系统利用先进的计算机视觉技术和深度学习算法,能够准确地检测和识别水果蔬菜的腐烂程度,帮助农民和供应链管理者进行质量控制和食品安全监测。在各种水果蔬菜样本中展现出出色的腐烂程度识别性能,具备广泛的应用前景。为计算机科学、人工智能、图像处理等专业的毕业生提供了一个具有挑战性和创新性的研究课题。无论您对深度学习技术保持浓厚兴趣,还是对深度学习和花卉识别技术
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长人工智能专业毕设专题,本次分享的课题是
🎯基于深度学习的水果蔬菜腐烂程度识别系统
项目背景与简介
随着全球人口的增长和生活水平的提高,水果蔬菜的消费量显著增加。然而,食品安全问题日益突出,特别是水果蔬菜的腐烂和变质不仅影响食品质量,还对人们的健康构成威胁。传统的腐烂程度识别方法主要依赖人工检查,效率低下且容易出现误判。基于深度学习的图像识别技术,能够通过分析大量图像数据,自动识别水果蔬菜的腐烂程度,从而提高检测的准确性和效率。
主要设计思路
一、算法理论技术
1.1 卷积神经网络
卷积神经网络(CNN)在水果蔬菜腐烂程度识别系统中的应用具有显著优势。首先,CNN能够自动从输入图像中提取关键特征,如颜色、纹理和形状,这对于判断腐烂程度至关重要。通过对大量标注数据进行训练,CNN学习不同腐烂程度的特征模式,从而实现对新图像的准确分类,能够将水果蔬菜分为新鲜、轻微腐烂和严重腐烂等类别。此外,CNN的高效性使其适合实时处理,能够在水果蔬菜进入市场或流通环节时迅速评估腐烂程度,及时采取措施保障食品安全。在训练过程中,数据增强技术可以扩展训练集,提高模型的泛化能力,使其在不同环境下表现良好。同时,CNN的可视化技术帮助研究人员理解模型判断腐烂程度的过程,为系统改进提供依据。
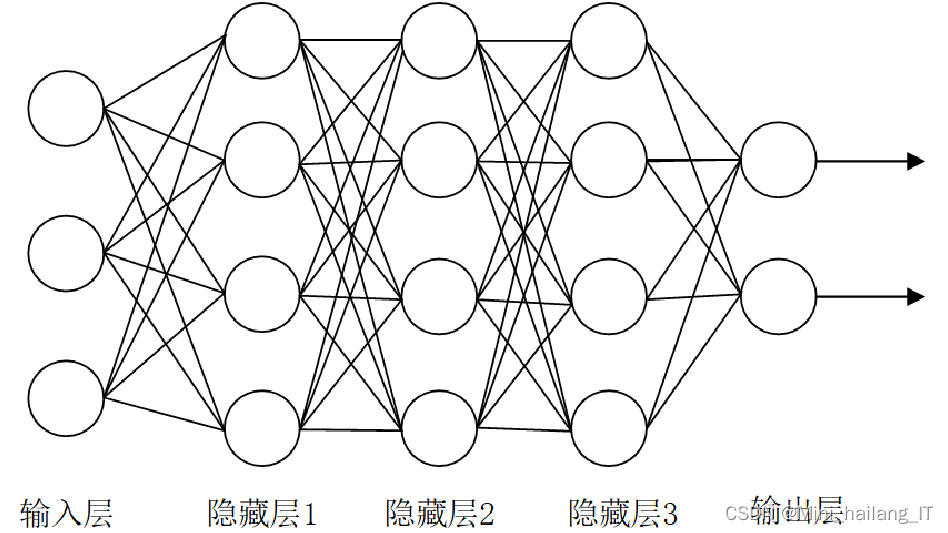
卷积神经网络(CNN)是一种深层前馈网络,主要由输入层、卷积层、池化层、全连接层和输出层组成,广泛应用于图像处理领域。在CNN中,卷积层负责图像特征提取,通过卷积核扫描原始图像以提取有效特征。每个卷积核处理单一特征,多个卷积核则同时处理多个特征。卷积时,卷积核的大小通常为A×A,通过滑动窗口的方式对输入图像进行卷积,生成新的特征图。由于卷积层处理后图像尺寸较大,因此需要经过池化层进行图像压缩,以减少数据维度并保留重要信息,最终通过全连接层进行图像识别和分类,输出层提供最终的分类结果。通过这种层次化的结构,CNN能够有效提取和识别图像中的复杂特征,实现高效的图像分类和识别任务。
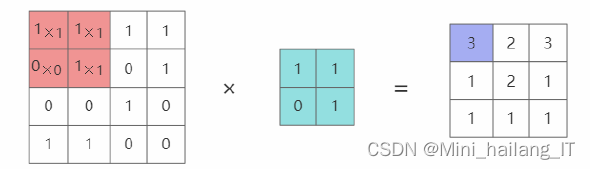
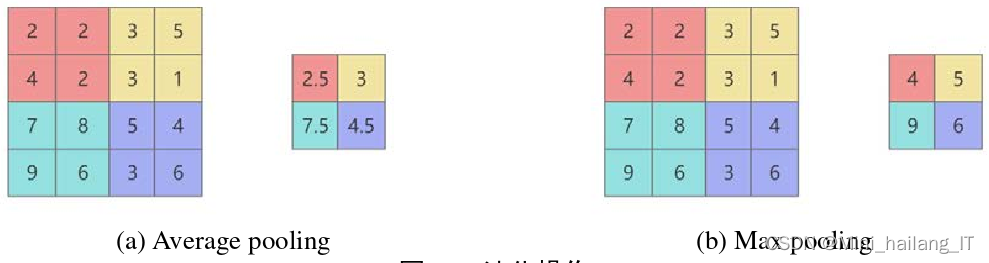
经过卷积层处理后的图像尺寸往往较大,因此需要通过池化层进行压缩和降维,以减少数据的复杂性和计算量。池化层通过对特定区域内的结果取等效值来实现这一目标,常用的策略包括最大池化和平均池化,其中最大池化选择区域内的最大值,而平均池化则计算区域内所有值的平均数。池化不仅能够有效降低特征图的尺寸,还能加快神经网络的训练速度,减少计算资源的消耗。此外,池化层在一定程度上可以防止过拟合的发生,使得模型在面对新数据时表现出更好的泛化能力,从而提高神经网络的整体性能和稳定性。这种层次化的处理方式使得卷积神经网络在图像分类和识别任务中更加高效和可靠。
1.2 目标检测算法
目标检测算法在水果蔬菜腐烂程度识别系统中的应用具有重要意义,能够精确定位每个水果和蔬菜的位置,并对其腐烂程度进行分类。这种算法可以同时识别多种类的水果和蔬菜,提高检测的全面性和准确性。此外,许多目标检测算法(如YOLO和SSD)具备较高的处理速度,能够实现实时监测,及时发现腐烂或变质的产品,从而减少损失。通过对检测结果的统计与分析,系统还可以提供数据驱动的决策支持,帮助管理者优化库存管理和销售策略。现代目标检测算法通常结合深度学习技术,通过卷积神经网络等模型进行特征提取,增强识别精度。这种技术融合使系统能够应对复杂的环境变化和背景干扰,显著提升整体性能。
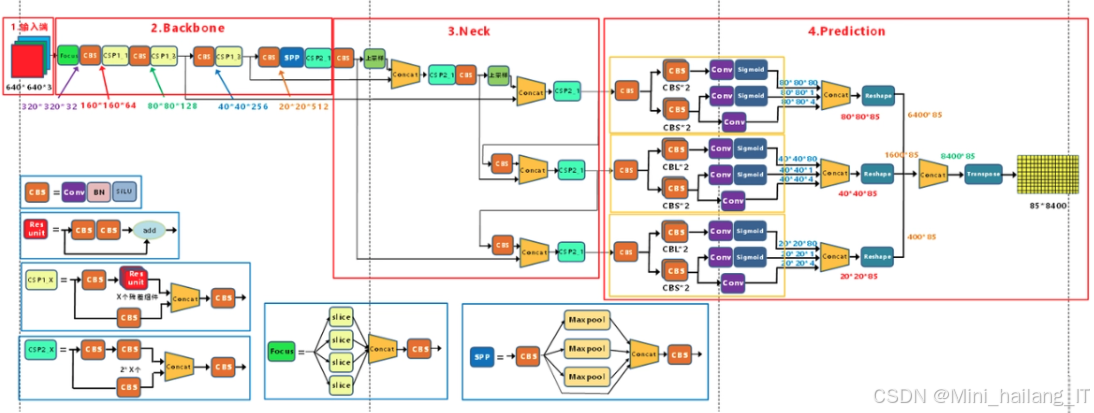
YOLOv5的网络结构主要由输入层、Backbone、Neck和Head组成,可以将其视为一个盲盒,输入大小为640×640的RGB图像经过各个模块处理后,最终生成三个特征张量,分别对应大尺度、中尺度和小尺度的目标检测。在输入层进行数据预处理后,Backbone网络负责从原始图像中提取通用特征表示,这些特征随后被传递到后续层进行更高级别的特征提取和处理。Neck网络进一步增强特征的多样性和鲁棒性,使得模型在复杂环境下仍能保持良好的性能。最后,Head输出端负责生成目标检测的最终结果,通过这一系列模块的协同作用,YOLOv5实现了高效且准确的目标检测
二、数据处理
2.1 数据集
在创建水果蔬菜腐烂程度识别系统的数据集时,我首先明确了目标和腐烂程度的分类标准,然后选择了多种类的水果和蔬菜,如香蕉,以确保数据的多样性。在不同的市场、超市和农贸市场实地拍摄,我力求捕捉真实的样本,记录每个样本的新鲜程度和腐烂情况。拍摄时,我特别注意相机设置,确保图像清晰,并从多个角度拍摄,以获取全面的信息。在后期标注时,我使用标注工具为每张图片添加详细标签,确保每个样本的种类和腐烂程度都得到准确记录。

2.2 数据处理
在为水果蔬菜腐烂程度识别系统进行数据集标注时,我选择了LabelImg这样的易用工具,确保标注过程高效且准确。每当我打开一张图片,都会仔细观察样本的整体状况和细节,依据预先设定的腐烂程度标准将每个样本标记为新鲜、轻微腐烂或严重腐烂。在这个过程中,我不仅关注样本的外观特征,如颜色、纹理和形状变化,还考虑到这些特征如何反映腐烂程度。为了确保标注的准确性,我会在完成标注后反复检查每张图片,确保每个标签都与实际情况相符,及时修正任何不准确的标记。此外,我还记录每个样本的种类和拍摄时间,以便后续的数据分析和模型训练。
三、模型训练
深度学习框架为构建、训练、优化和推理深度神经网络模型提供了必需的基础工具,使开发者能够更加高效地进行相关工作。这些框架不仅简化了复杂的计算过程,还提供了丰富的功能和灵活的接口,帮助开发者快速实现各种深度学习算法。在众多深度学习框架中,PyTorch因其高度的扩展性和可移植性受到广泛欢迎,同时拥有一个庞大的开发者社区,提供了丰富的资源和支持。其动态计算图的特性使得调试和模型修改更加容易,非常适合研究和实验。

模型训练过程中,首先需要准备和预处理数据集。这包括将采集到的图像进行标注,确保每个样本的腐烂程度被准确分类。将数据集划分为训练集、验证集和测试集,以便在不同阶段评估模型的性能。此外,针对图像数据,进行数据增强,如旋转、缩放和翻转,以提高模型的泛化能力。相关代码示例:
# 1. 数据集标注
annotations_file = 'annotations.csv' # 包含图像文件名和标签的CSV文件
annotations = pd.read_csv(annotations_file)
# 2. 数据集划分
# 将数据集划分为训练集、验证集和测试集
train_df, test_df = train_test_split(annotations, test_size=0.2, random_state=42)
val_df, test_df = train_test_split(test_df, test_size=0.5, random_state=42)
# 3. 定义数据增强和加载
transform = transforms.Compose([
transforms.Resize((640, 640)), # 调整图像大小
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])训练阶段使用选择的深度学习框架(如PyTorch)构建模型,设置合适的网络结构,通常包括卷积层、池化层和全连接层等。在训练过程中,定义损失函数和优化器,通过反向传播算法不断调整模型参数,以最小化预测结果与真实标签之间的差距。为了监控模型的训练效果,定期在验证集上评估模型性能,调整学习率和其他超参数,以提高训练效率。代码示例如下:
# 定义网络结构
class FruitVegetableModel(nn.Module):
def __init__(self, num_classes):
super(FruitVegetableModel, self).__init__()
# 使用预训练的ResNet18作为基础
self.backbone = models.resnet18(pretrained=True)
# 替换最后的全连接层
self.backbone.fc = nn.Linear(self.backbone.fc.in_features, num_classes)
def forward(self, x):
return self.backbone(x)
# 设置超参数
num_classes = 3 # 假设有三种腐烂程度
learning_rate = 0.001
num_epochs = 20
batch_size = 32
# 初始化模型、损失函数和优化器
model = FruitVegetableModel(num_classes)
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 数据加载器(假设train_loader和val_loader已经定义)
# train_loader = DataLoader(...)
# val_loader = DataLoader(...)
# 训练过程
fo epoch in range(num_epochs):
model.train() # 设置模型为训练模式
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad() # 清零梯度
outputs = model(images) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
# 每个epoch结束后评估验证集
model.eval() # 设置模型为评估模式
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算
for val_images, val_labels in val_loader:
val_outputs = model(val_images) # 前向传播
val_loss += criterion(val_outputs, val_labels).item() # 计算验证损失
_, predicted = torch.max(val_outputs.data, 1) # 获取预测结果
total += val_labels.size(0)
correct += (predicted == val_labels).sum().item()
# 输出训练和验证结果
print(f'Epoch [{epoch + 1}/{num_epochs}], '
f'Train Loss: {running_loss / len(train_loader):.4f}, '
f'Val Loss: {val_loss / len(val_loader):.4f}, '
f'Accuracy: {100 * correct / total:.2f}%')训练完成后,使用测试集对模型进行全面评估,检查其在未见数据上的表现。这一阶段将帮助我判断模型的实际应用能力,确保其能够准确识别不同腐烂程度的水果和蔬菜。根据测试结果,可能会进一步进行模型的微调和优化,以提升其整体性能和准确性,从而为后续的实际应用打下坚实基础。
更多帮助
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)