
Pytorch 搭建自己的YOLO3目标检测平台-学习笔记
参考Pytorch 搭建自己的YOLO3目标检测平台文章目录1什么是yolov32yolov3整体结构3特征提取网络3.1什么是残差网络1什么是yolov3图片导入会变成416*416的尺寸,不足部分加入灰条2yolov3整体结构具体daeknet53如下参考daeknet53主干部分提取网络叫做darknet-53主要作用是提取特征,其重要特点是使用了残差网络Residual,darknet53
1什么是yolov3

图片导入会变成416*416的尺寸,不足部分加入灰条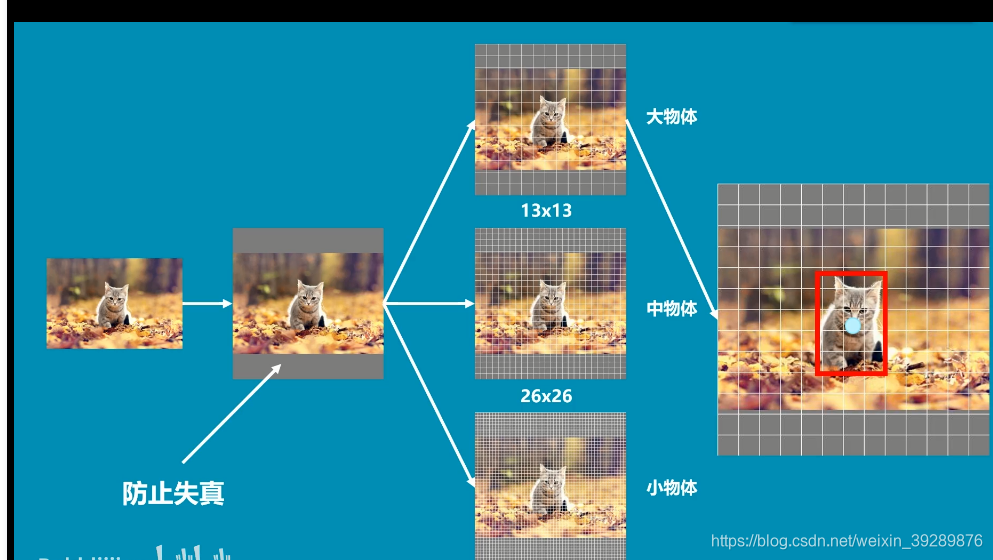
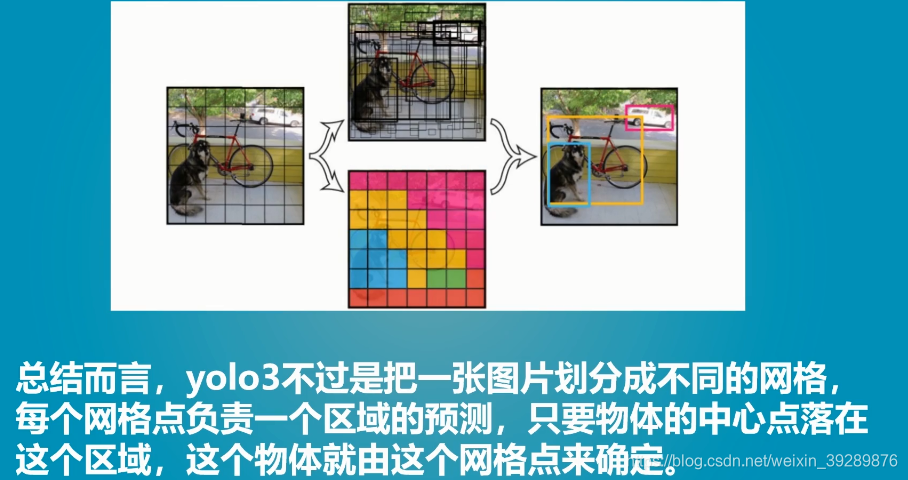
2yolov3整体结构
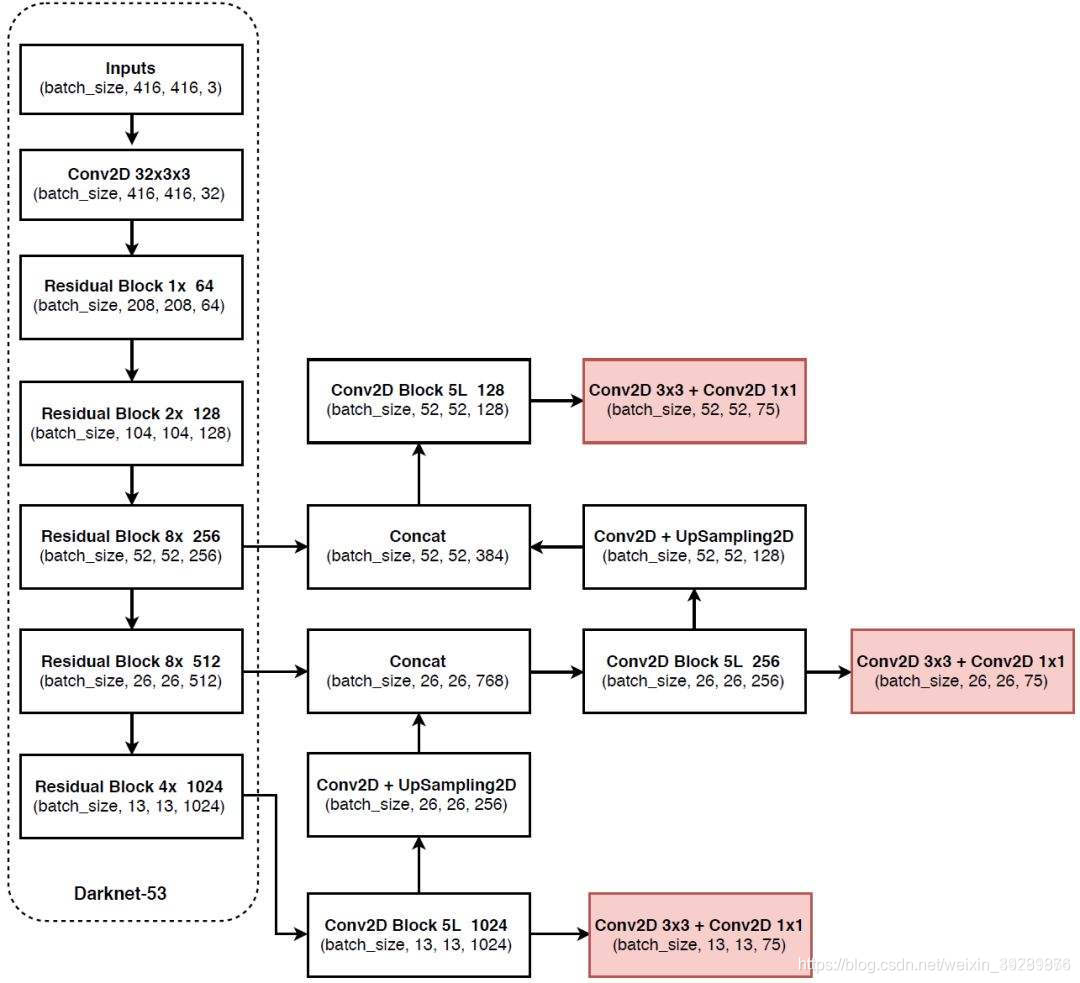
具体daeknet53如下参考daeknet53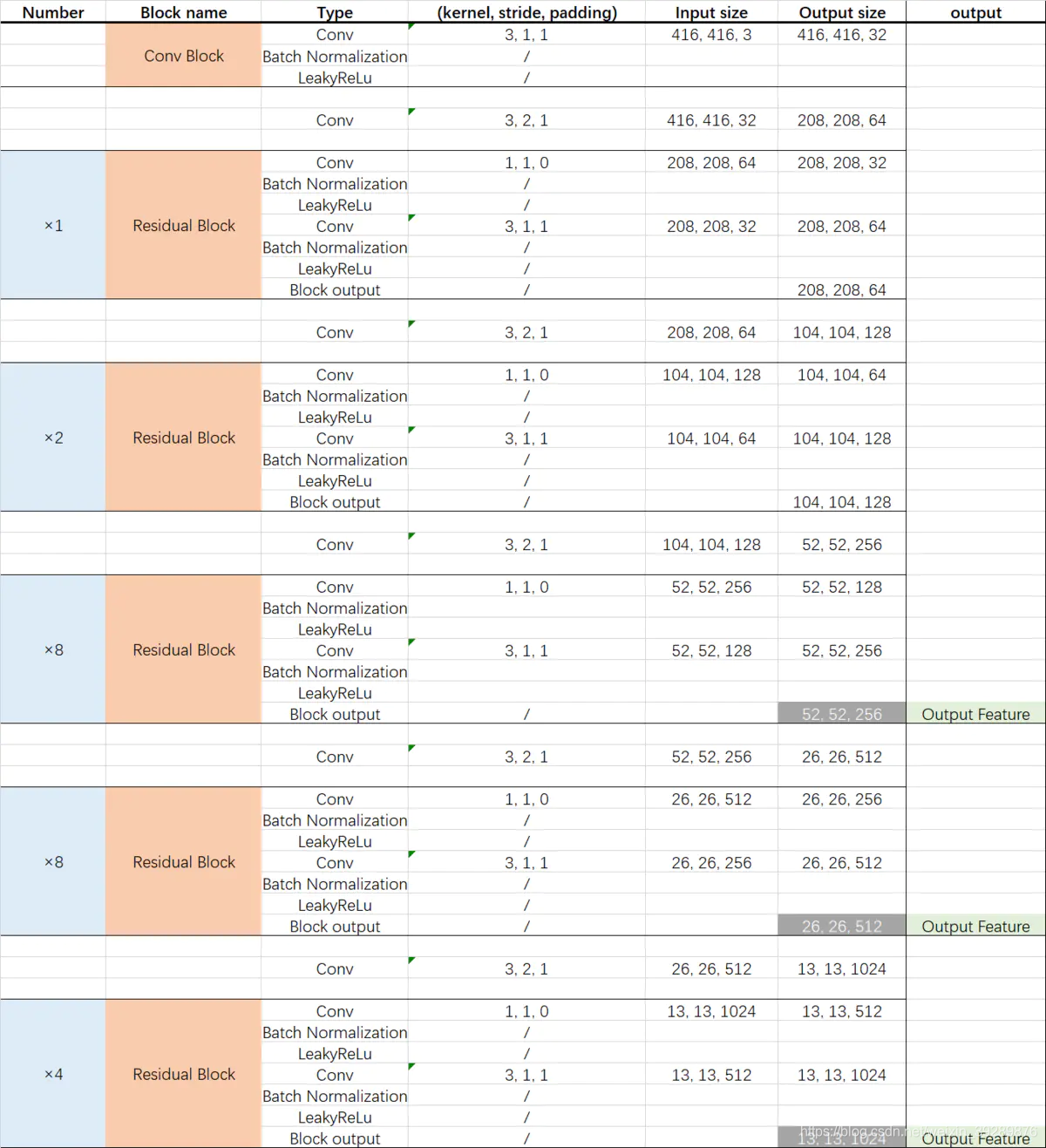

主干部分提取网络叫做darknet-53主要作用是提取特征,其重要特点是使用了残差网络Residual,darknet53中的残差卷积就是进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果与layer中权重求和作为最后的结果, 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。
3特征提取网络
3.1什么是残差网络
Residual net(残差网络):
将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
其结构如下: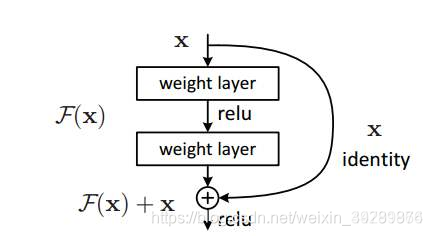
darknet的代码
import math
from collections import OrderedDict
import torch
import torch.nn as nn
#---------------------------------------------------------------------#
# 残差结构
# 利用一个1x1卷积下降通道数,然后利用一个3x3卷积提取特征并且上升通道数
# 最后接上一个残差边
#---------------------------------------------------------------------#
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1,
stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
#残差网络的实现
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
# nput channels
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#---------------------------------------------------------------------#
# 在每一个layer里面,首先利用一个步长为2的3x3卷积进行下采样
# 然后进行残差结构的堆叠
#---------------------------------------------------------------------#
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3,
stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5
def darknet53(pretrained, **kwargs):
model = DarkNet([1, 2, 8, 8, 4])
if pretrained:
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request a pretrained path. got [{}]".format(pretrained))
return model
4训练自己的模型-安全帽
首先下载yolov3模型
git clone https://github.com/bubbliiiing/yolo3-pytorch
4.1预测模型
下载权重文件
https://pan.baidu.com/s/1ncREw6Na9ycZptdxiVMApw
提取码: appk
4.2训练安全帽数据集
首先下载一个voc数据voc2028,下面有三个文件
annotation下面是xml格式标签文件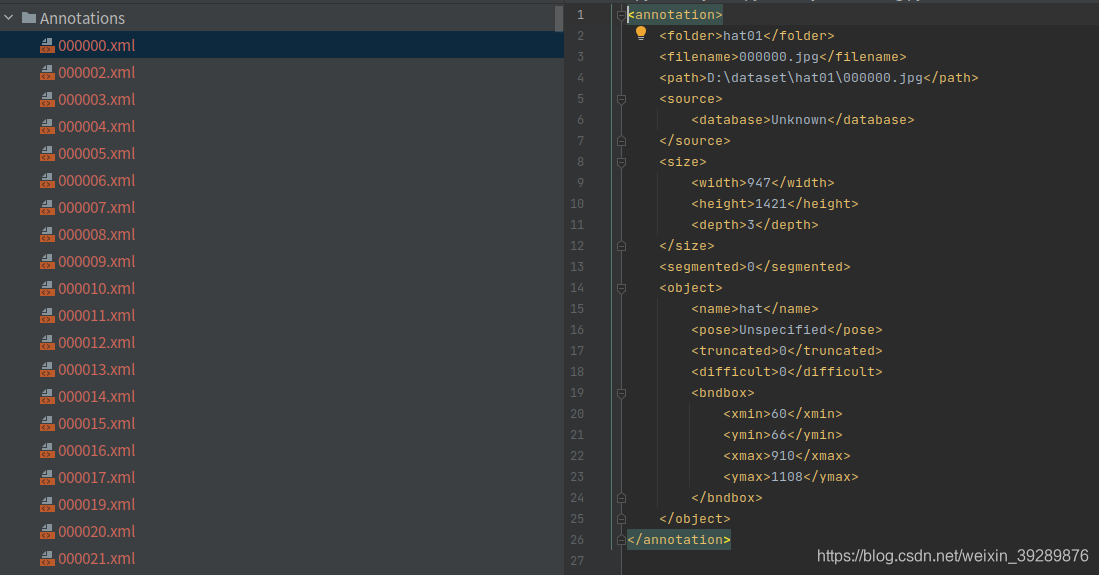
JPEGIMAGES是标签文件对应文件
imagesets 下面train.txt有非常多数字,对应标签文件和图型文件名称,这些文件可以通过voc2yolo3生成,这里要改一下名称路径
xmlfilepath=r'./VOCdevkit/VOC2028/Annotations'
saveBasePath=r"./VOCdevkit/VOC2028/ImageSets/Main/"

运行voc_annotation.py文件
修改utils下的config文件,修改classes个数,这里人和帽子选2
Config = \
{
#-------------------------------------------------------------#
# 训练前一定要修改classes参数
# anchors可以不修改,因为anchors的通用性较大
# 而且大中小的设置非常符合yolo的特征层情况
#-------------------------------------------------------------#
"yolo": {
"anchors": [[[116, 90], [156, 198], [373, 326]],
[[30, 61], [62, 45], [59, 119]],
[[10, 13], [16, 30], [33, 23]]],
#"classes": 20,
"classes": 2,
},
#-------------------------------------------------------------#
# img_h和img_w可以修改成608x608
#-------------------------------------------------------------#
"img_h": 416,
"img_w": 416,
}
修改train.py
python train.py
开始训练
更多推荐
 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)