
【汉字文本识别】:基于卷积神经网络和循环神经网络的深度学习方法:CRNN
前言之前参加深度学习比赛的时候,对计算机视觉有一些小小的积累。 虽然不足道, 但是还是记录一下, 以便以后碰到这方面的岗位问题时, 可以有一些展示的东西。 之前参加了华为赞助的一个汉字识别大赛, 要求通过神经网络,识别出图片中的汉字。 其中每张图片的汉字数量不一。 我这里先采用了 CRNN的方法, 这篇博文记叙一下。代码本文的代码全部分享于 github。已经配备了简单的训练集和验证集作为示例,
前言
之前参加深度学习比赛的时候,对计算机视觉有一些小小的积累。 虽然不足道, 但是还是记录一下, 以便以后碰到这方面的岗位问题时, 可以有一些展示的东西。 之前参加了华为赞助的一个汉字识别大赛, 要求通过神经网络,识别出图片中的汉字。 其中每张图片的汉字数量不一。 我这里先采用了 CRNN的方法, 这篇博文记叙一下。
代码
本文的代码全部分享于 github。已经配备了简单的训练集和验证集作为示例, 确保可以直接下载后使用。 读者可以用自己的数据集替代, 来实现一个自己的课堂demo。
背景
需要识别的图片大致如下: 是竖着写的, 果然是中国传统文化。 目标就是用这些图片作为输入, 输出识别的汉字结果。
CRNN介绍
CRNN, 即 CNN + RNN 的缩写 (注意不要和另一著名网络RCNN搞混)。 该网络在https://arxiv.org/pdf/1507.05717.pdf 中提出, 其核心思路在于:
- 图片中提取特征, 那显然由CNN来完成这一操作。
- 既然是文字, 往往前后有所联系,那从特征再输出文字这一节, 认为每个字都和前后的字有关联, 因此, 使用RNN来实现 特征到输出文字这一步。 (个人觉得这个古文的话,比如上面的示例图片,上下文字没什么关系, 其实RNN不太合适, 但也没什么影响。 本文重点还是介绍下CRNN的应用。)
网络模型
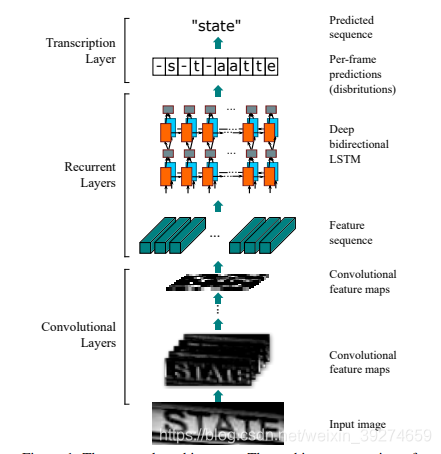
这是截取自文中的网络模型, 描述一下步骤:
- 首先用经典的CNN 卷积神经网络, 提取图片中的特征, 得到图中的 feature maps。 在我的github代码中, 我使用了 四层卷积网络,具体参数见代码。 输入的维度是 640 × 64 × 3 640\times 64\times 3 640×64×3, 即尺寸为 640 * 64, RGB颜色。 (这里我个人感觉其实可以不指定尺寸,这样就可以应用于各种不同尺寸的样本了)。 经过四层CNN网络后, 输出维度是 160 × 4 × 512 160\times4\times512 160×4×512 (经过了池化)。
- 通过全连接层(Dense层), 把提取的512个channel的特征, 整理成 维度维 32 × 64 32\times 64 32×64 的 数据, 等待输入到接下来的RNN网络中。 (可以理解为 64 64 64 个时刻的输入, 每个时刻的输入维度是 32。)
- 用BiLSTM网络, 即双向LSTM网络进行最后的处理。 用双向LSTM的意思就是每一位置的信息输出,和之前位置及之后位置的信息输出相关。 得到 32 × 512 32\times 512 32×512的输出数据。
- 最后, 用全连接层, 输出结果。
具体实现
标签
由于我们采用的是汉字, 因此,在制作标签的时候,我们要把汉字转为数字表示的标签。
思路很简单: 比如所有样本中, 我们共有9000个不同的汉字。 那么我们就以1~9000个整数, 来一一对应这每个汉字。 而由于每张图的汉字数量不一, 我们可以进行补零操作——首先,统计出样本中单张图片最大汉字数, 比如30。 那么 每张图的标签的维度就是 30 × 1 30\times1 30×1, 其中前 K K K维就对应于图片中 K K K个汉字的序号(1~9000), 而后则用0填充。 当输出再映射回汉字时, 去掉0即可。
损失函数
使用了经典的CTC损失函数, 这里有几篇讲的比较好的文章:
https://blog.csdn.net/huangyiping12345/article/details/102668605
语音识别:深入理解CTC Loss原理
简单来说, 就是使用这个损失函数, 可以解决 输出与标签之间的对齐问题。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)