
YOLO--目标检测综述、预测阶段(1)
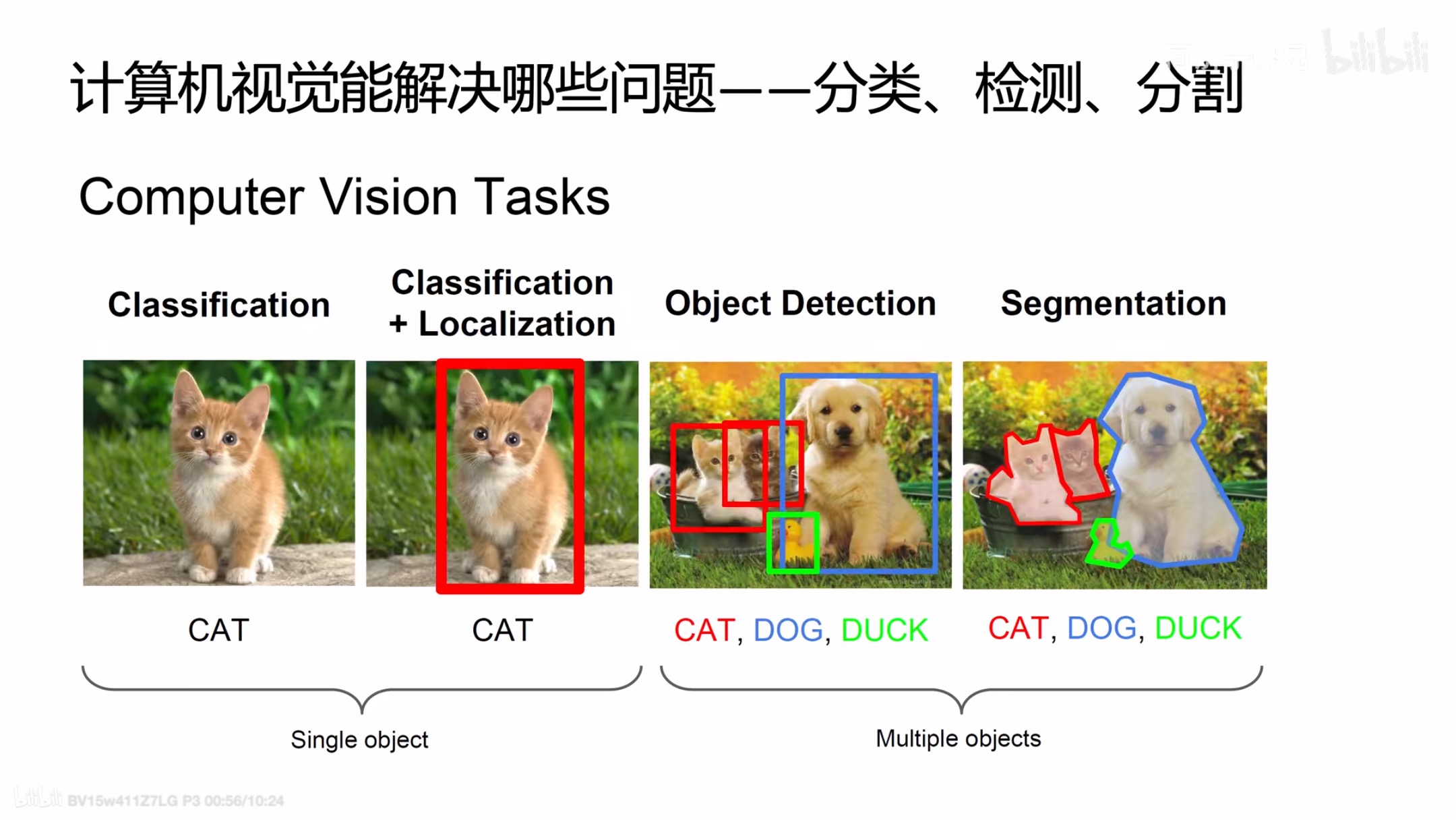
YOLO就是解决目标检测问题的计算机视觉算法。计算机视觉可以解决图像分类、图像分割、目标检测等任务。下面这张图根据加不加框、加不加文字描述,是加框还是直接把物体的边缘给勾勒出来。依次分为检测、检测+定位、目标检测、图像分割(不满足画框,想得到像素级别的)
YOLO就是解决目标检测问题的计算机视觉算法。计算机视觉可以解决图像分类、图像分割、目标检测等任务。
下面这张图根据加不加框、加不加文字描述,是加框还是直接把物体的边缘给勾勒出来。依次分为检测、检测+定位、目标检测、图像分割(不满足画框,想得到像素级别的)
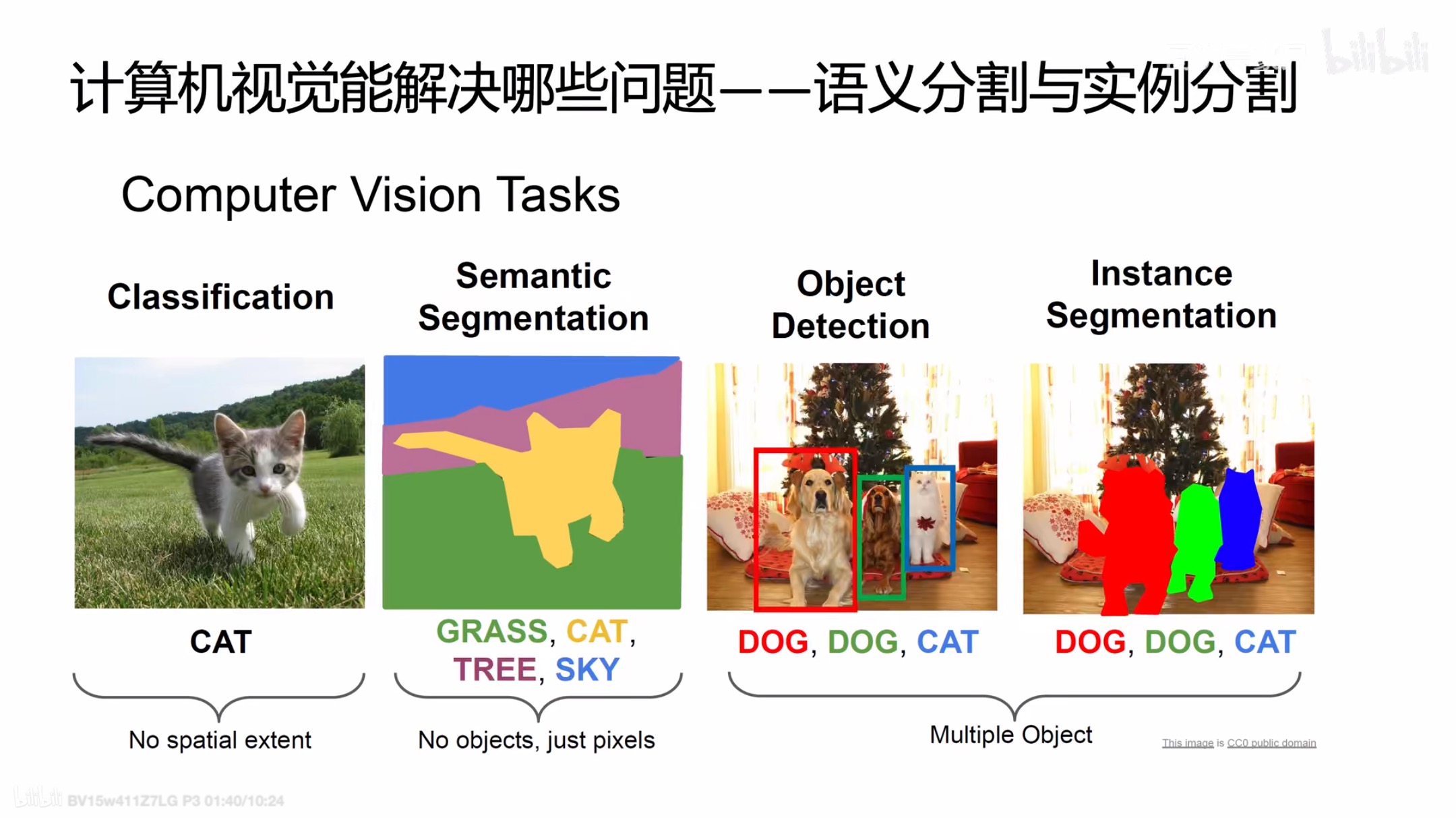
segmantic segmentation 语义分割(对每个像素分类,区分不同类别(不区分同类个体)不区分同类物体,所有的人属于同一标签,同一类别使用同一颜色进行标记) 和instance segmentation 实例分割(对每个像素分类,并区分同类别的不同个体,两个人不属于同一标签,使用不同颜色进行标记)
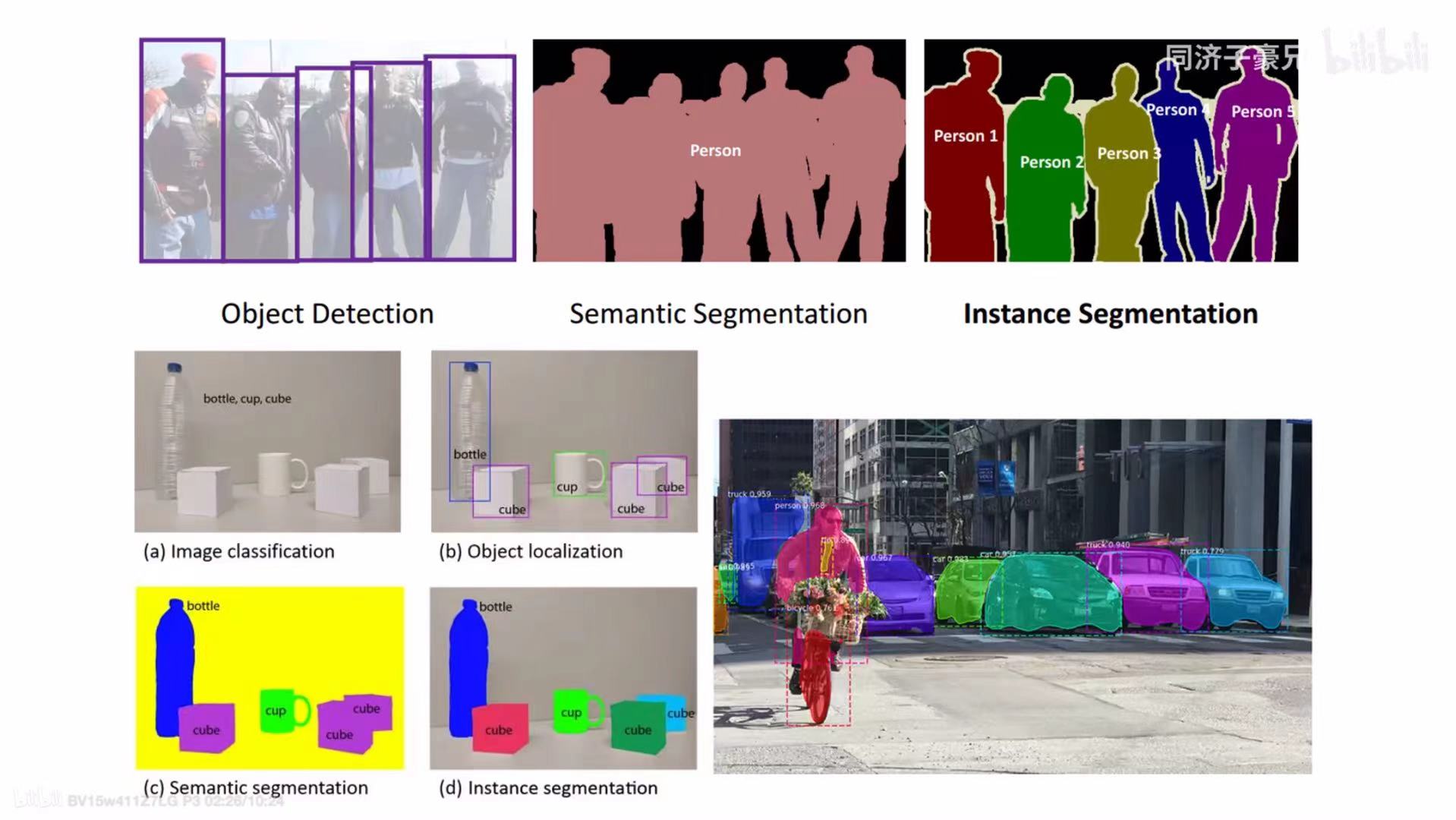
目标检测实际上分为两个流派:单阶段模型和两阶段模型。我们今天学习的YOLO就属于单阶段模型。两阶段就是先从图像中提取若干候选框,再逐一对这些候选框进行分类、调整坐标,得出结果。单阶段就是将全图喂到算法里面,算法直接输出结果。
两阶段模型的“候选框”是什么?
-
第一步:RPN(Region Proposal Network)生成 可能包含物体的区域(如1000~2000个候选框),这些框只包含粗略位置,不涉及具体类别。
-
第二步:对每个候选框进行:
-
分类:判断属于哪一类(如人、车、背景)。
-
回归:微调框的坐标(使其更贴合物体)。
-
(2) 单阶段模型如何“直接输出”?
-
YOLO的机制:将图像划分为网格(如S×S),每个网格预测固定数量的边界框(如B个)和类别概率。
-
Anchor-Based(YOLOv2-v5):预设不同尺度的Anchor框,调整偏移量。
-
Anchor-Free(YOLOv8):直接预测框中心点和宽高,无需Anchor。
-
YOLOV1 算法
之前已经算比较详细地解读了YOLO v1的架构。我们再整体说一下YOLO的优点:
YOLOv1 的革新在于 抛弃滑动窗口和候选框,直接通过网格划分和回归预测:
- 网格负责制:若物体中心落在某个网格内,则该网格负责预测该物体。
- 全局推理:模型看到整张图像,能利用上下文信息(避免像R-CNN那样局部视野受限)。
- 多任务融合:在一个网络中同时预测边界框、置信度和类别,实现端到端训练。
损失函数
YOLO V1的损失函数由三部分组成,通过加权平衡不同任务:

坐标损失,目的是优化预测框的位置和大小(x, y, w, h),使其与真实框尽可能重合。仅对正样本计算(即包含预测物体的网格和框。负样本就是即那些不包含物体或与真实框重叠度极低的预测框。区分正负样本的原因就是为了让正样本学会与预测和定位物体。负样本学会沉默,不预测无物体区域)
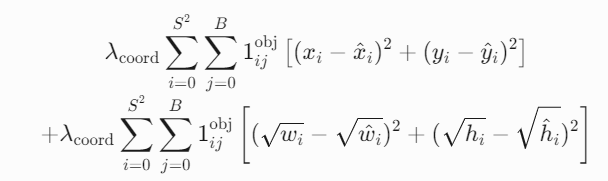
-
(x, y)损失:让框中心点靠近真实框中心。 -
(w, h)损失:调整框的宽高比例,匹配真实框大小
置信度大家应该都知道是啥。在这里的置信度包含两方面,一个是当前预测框内是否包含物体,如果包含物体,预测狂和真实框的重叠程度如何。
- 当前预测框内是否包含物体(有物体/无物体)。
- 如果包含物体,预测框与真实框的重叠程度如何(通过IoU衡量)。(真实框是人工标注的,通过计算真实框与预测框的重叠程度。后续通过损失函数使得lou尽可能大。也就是使得预测框可以尽可能地接近真实框)置信度的计算公式为:
-
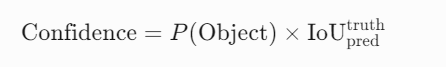
- P(Object):当前框内存在物体的概率(二分类,0或1)。
- 如果网格负责预测物体(即物体中心落在该网格内),则 P(Object)=1;否则为0。
- IoUpredtruth:预测框与真实框的交并比(Intersection over Union)。
- 所以如果有物体,那么置信度会是0~1 如果直接没有物体,那么就是0
那么其实我是有个疑问的?因为我觉得既然坐标损失就已经是去使得真实框和预测框重合。可是置信度损失不也是这样的作用吗?那这二者是否是重复的?但是其实二者是互补的。如果仔细看会发现,坐标损失并不涉及到框内是否有物体,而且坐标损失只对正样本才有用,也就是说前提是确定里面有物体,然后才可以进行坐标损失的计算。而置信度就是会首先框住物体,保证框内是有物体的。但是我又不明白的是?如果框内就是没有物体那这个框不就是没用的?置信度在这里直接就使用二分类(0表示没有物体),直接就将没物体的框设置为0,那么也就不会影响到后续计算坐标损失了。
这部分我说的很乱,我让chat给我梳理一下
1. 坐标损失(Coordinate Loss)
-
作用:坐标损失用于让预测的边界框(bounding box)尽量与真实框对齐,具体来说,计算的是预测框与真实框的偏差(位置和尺寸上的偏差)。这包括了预测框的中心坐标和宽高。
-
适用场景:坐标损失仅对正样本有效(即框内有物体)。它计算的是当预测框包含物体时,框的位置和大小与真实框的差距。
-
关键点:坐标损失并不关心框内是否有物体,它只是聚焦于如何让框更好地拟合真实物体的位置。
2. 置信度损失(Confidence Loss)
-
作用:置信度损失的目标是对每个预测框的存在性进行判断,也就是预测框内是否包含物体(前景)或背景。YOLO v1中的置信度损失是二分类问题,0表示没有物体(背景),1表示有物体(前景)。
-
适用场景:置信度损失对所有框(无论正负样本)都有影响,因为它首先要确定预测框是有物体的(置信度为1),还是没有物体的(置信度为0)。如果框内确实没有物体,模型通过置信度损失会尽量让置信度趋向0。
-
关键点:置信度损失的目标是对每个框是否包含物体做出准确判断。它帮助模型筛选掉无物体的框,因此它对整个检测过程至关重要。
3. 类别损失(Classification Loss)
-
作用:类别损失用于判断预测框内的物体属于哪个类别。对于每个正样本,YOLO会为它分配一个类别标签,然后通过交叉熵损失来计算预测类别与真实类别之间的差距。
-
适用场景:类别损失只对正样本有效,即框内有物体时才计算类别损失。它保证了模型不仅要预测物体的位置信息,还要正确分类该物体。
这三者的关系:
-
坐标损失:用于确保框内的物体位置准确,前提是已经确认框内确实有物体(正样本)。
-
置信度损失:用于判断框内是否有物体。如果框内没有物体,置信度会被拉低至0,这样模型就不需要计算这个框的坐标损失,从而避免无物体框对坐标损失的影响。
-
类别损失:在框内确实有物体时,模型需要预测物体的类别,这个损失确保类别预测的准确性。
如何互补:
-
互补关系:虽然坐标损失和置信度损失都与框的内容有关,但它们关注的点不同。坐标损失关注的是框的精准度(如何定位物体),而置信度损失则关注框内是否有物体。如果框内没有物体,置信度损失会使得置信度趋向0,避免后续坐标损失计算无效框的影响。
-
避免重复:如果置信度损失成功将无物体的框判定为0,那么就不会影响坐标损失的计算,因为坐标损失只对正样本(框内有物体)有效。因此,置信度损失和坐标损失不会重复,而是配合使用,确保模型既能准确定位物体,又能正确区分背景。
总结:
-
坐标损失:保证框的准确位置(仅对正样本有效)。
-
置信度损失:判断框内是否有物体,且在框内无物体时对后续损失计算产生屏蔽作用。
-
类别损失:确定框内物体的类别(仅对正样本有效)。
这三个损失项分别聚焦于物体的位置、存在性和类别,虽然它们的目标有些重合,但实际上它们各司其职,确保YOLO能够精准地检测并分类物体。
类别损失(以yolo v1 为例,但是现在的采用交叉熵损失,效果更好)
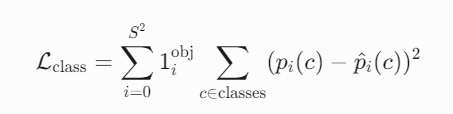
这个是如何计算的呢?我们来举个例子:
MSE类别损失:
- 筛选正样本网格:仅对包含物体中心的网格计算类别损失。
- 比较预测与真实类别:
- 预测值:模型输出的概率分布(如
[0.2, 0.8, 0.1])。 - 目标值:one-hot真实标签(如
[0, 1, 0])。
- 预测值:模型输出的概率分布(如
- 计算误差:MSE或交叉熵。
-
假设:
- 网格(3,4) 是正样本,真实类别=“狗”(对应one-hot标签
[0,1,0])。 - 模型预测的类别概率=
[0.1, 0.7, 0.2](表示“狗”的概率为0.7)。 - (0.1−0)2+(0.7−1)2+(0.2−0)2=0.14
模型会通过反向传播增大“狗”的概率(0.7→1),同时减小其他类别的概率。
需要注意的是yolo v1对这个模型预测的类别概率没有做归一化,但是v2之类的版本都是做了归一化的
这三个损失是进行协同工作的,协同工作流程:
- 置信度损失先判断哪些网格是正样本(含物体)。
- 对正样本:
- 坐标损失优化位置。
- 类别损失优化分类。
- 对负样本:仅通过置信度损失抑制(类别损失不计算)。
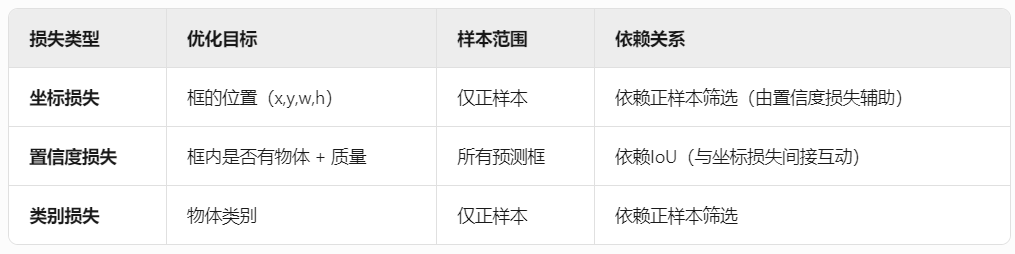
总结来说就是,置信度损失在YOLO中确实是首先发挥作用的,它的主要作用就是将负样本排除在外,为后续的坐标损失和类别损失的计算奠定基础。
YOLO 模型正向推断(测试过程)
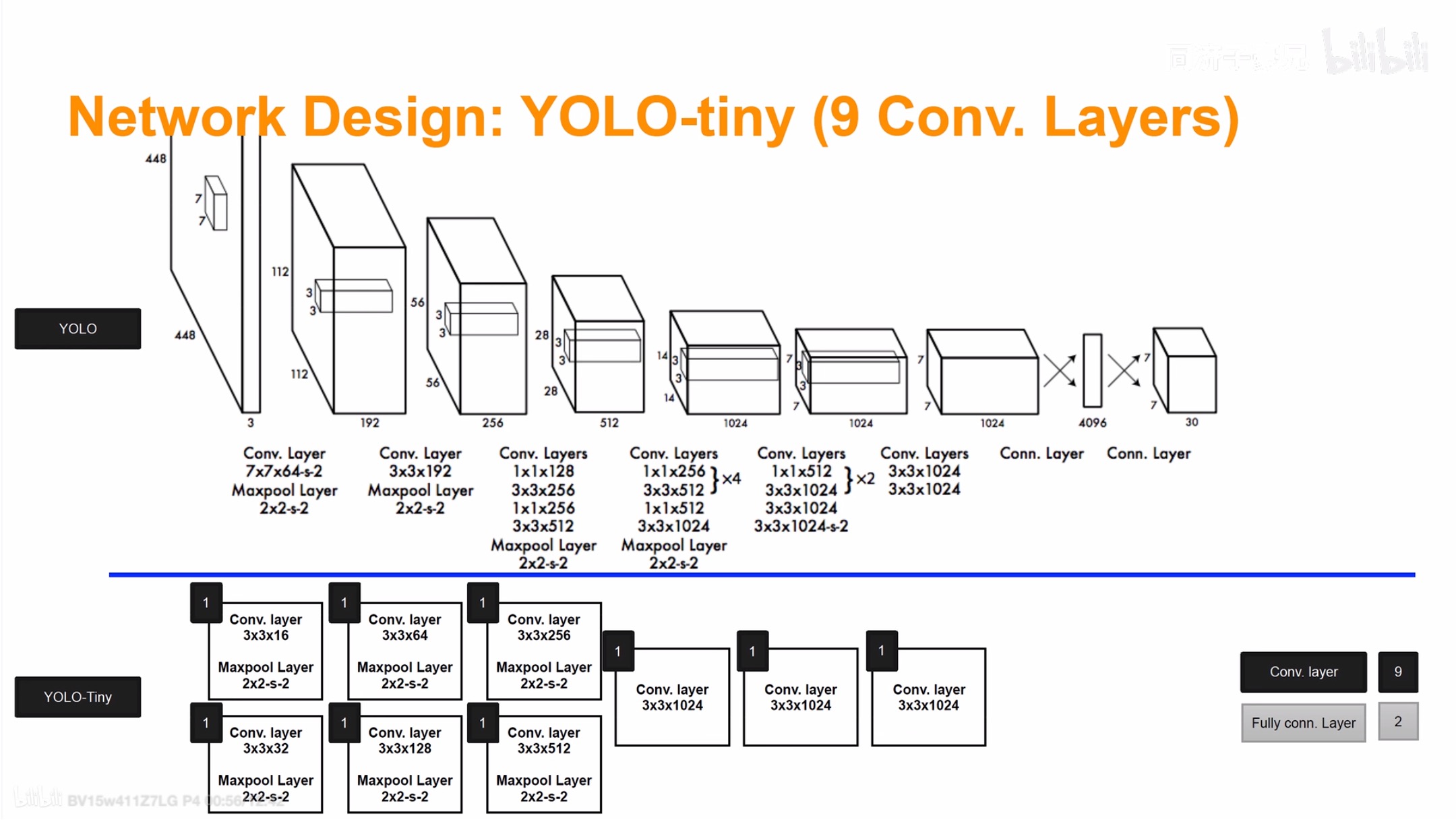
上面这个图是yolo v1的网络架构 昨天已经较为清晰地解释了 但是我还是放在这里让大家再瞅瞅
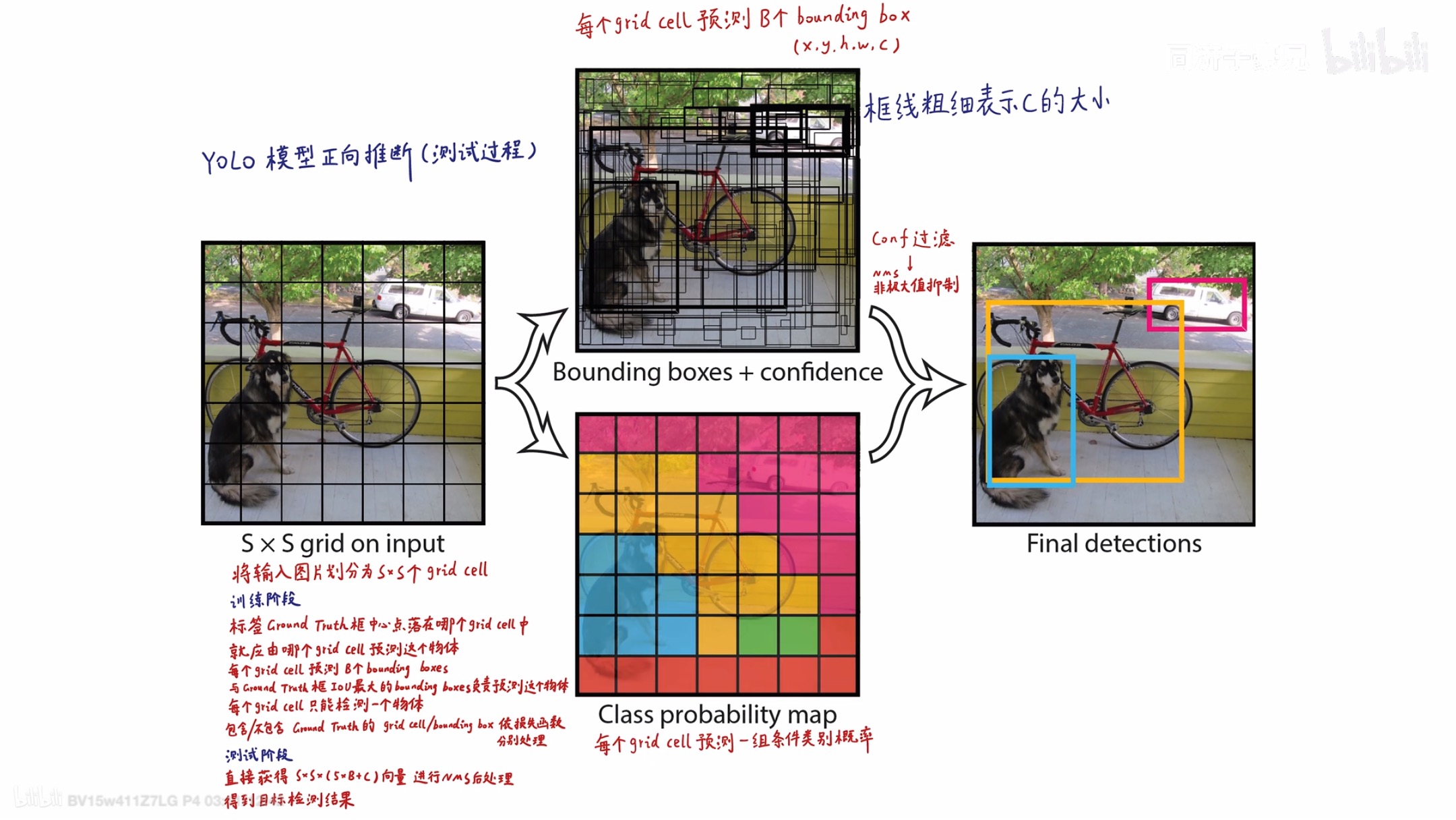
我们来解释这个图是啥意思。输入一张图,经过上述的模型架构之后,图像会被分为7*7的网格。每个网络涉及到30个数。分别是两个框的x y w h 和这个框的置信度损失 和20个类别的概率
1. 每个格子预测两个框:
-
YOLO v1 会对每个S×S网格预测两个框(即每个网格有两个bounding boxes),每个框都会预测其位置坐标(x, y, w, h),置信度(confidence)以及类别(class probability)。每个框都有自己的损失函数,具体来说:
-
坐标损失:用于衡量预测框的中心坐标和大小(宽高)与真实框之间的差异。
-
置信度损失:衡量该框是否包含物体,及其与真实物体是否匹配。如果框内有物体,置信度值接近1;如果框内没有物体,置信度值接近0。
-
类别损失:对于正样本(框内有物体),会根据类别标签计算交叉熵损失,以确保预测框的类别与真实物体类别一致。
-
2. 基于置信度进行框筛选:
-
每个框的置信度(confidence)会决定它是否包含物体。置信度高的框代表框内包含物体,而置信度低的框则可能是背景(没有物体)。在YOLO中,低置信度的框会被忽略,避免浪费计算资源。
3. 将框分配到类别:
-
对于每个正样本框,YOLO会计算出其类别概率。每个格子会输出每个类别的概率分布,因此根据最大概率的类别,框会被归类到相应的类别中。
-
每个框都可以根据预测的类别概率,选择一个最可能的类别进行分类。
4. NMS(非极大值抑制):
-
在YOLO的最终检测中,可能会有多个框检测到同一个物体。为了消除重复框,YOLO使用**NMS(非极大值抑制)**算法。具体来说,NMS会:
-
对每个类别的预测框按置信度从高到低排序。
-
然后依次选择最高置信度的框,并将与之重叠度(IoU,交并比)超过一定阈值的框删去。
-
最后保留那些没有被删掉的框,得到最终的检测框。
-
5. 最终的检测框:
-
通过以上的步骤,YOLO可以得到每个物体的最终检测框,这些框包含了物体的位置、类别和置信度。
-
最终的框是通过NMS筛选出来的,确保每个物体只有一个检测框。
我想说一下我开始的疑惑,我开始以为这个框是基于网格的,就是框的大小不可以超过网格的大小。然后我就想着如果两个框是重叠度高的?框限制在每个网格中,如果去进行重叠的。然后后来我知道了框并不局限于网格中,只不过是框的中心点是一定局限在这个网格中的。想清楚这点,就可以明白为什么要去掉重叠度高的框选择最优的那个框了。为什么重叠度低的是会被保留的,因为这个意思是这种类别的物体不仅仅是只有一个的
就像是下面这个图一样。更粗的框表示置信度比较高,较细的表示置信度很低。二者的重叠度很高,于是丢弃那个置信度低的,选择那个置信度高的。

每个cell只负责一个类别
再看下面这个图。刚刚我们说到,根据类别去选框,每个框只对应一个类别。对于yolo v1而言,每个网格cell只负责一个物体(即那个物体的中心落在这个grid cell 内) 一个cell预测两个框是为了给同一个物体提供两个候选框。训练的时候,会选择与ground truth重叠更大的那个框来负责预测。然后只计算这个框的三项损失。另外一个框就当作负样本进行处理(湖北训练为没有物体)
YOLOv1 模型原理及代码解析-云社区-华为云大家可以看看这个链接 里面包含对于代码的详细解释

这篇文章说的比较累赘 希望大家不要介意 如果喜欢的话欢迎关注收藏~
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)