
强化学习的数学原理-06随即近似理论和随机梯度下降
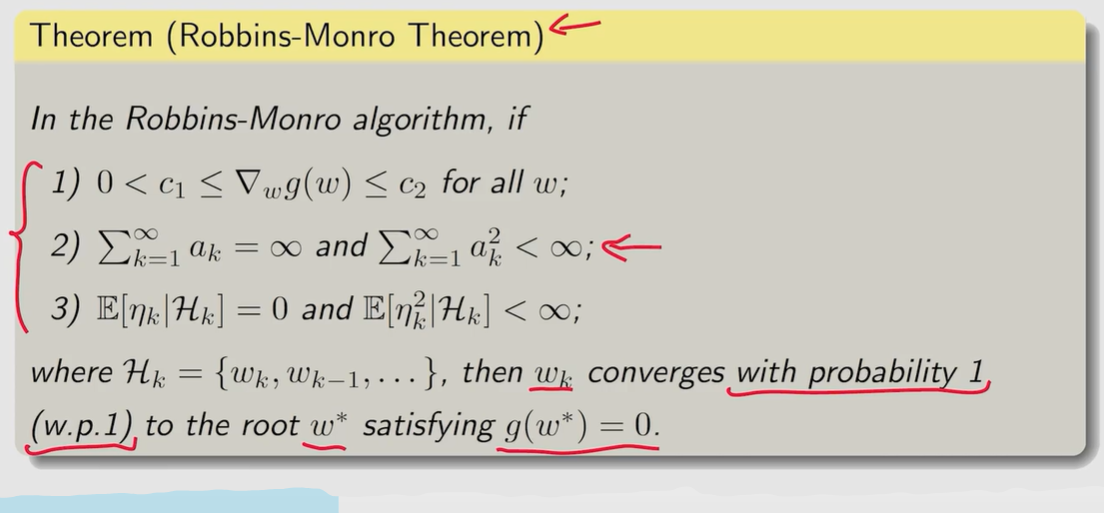
Robbins-Monro algorithm
迭代式求平均数的算法

S t o c h a s t i c a p p r o x i m a t i o n ( S A ) Stochastic \; approximation \;(SA) Stochasticapproximation(SA):是指随机迭代的一类算法,进行求解方程或者优化的问题, S A SA SA的优势是不需要知道方程或目标函数的表达式,自然也不知道导数、梯度之类的信息.
R 0 b b i n − M o n r o a l g o r i t h m R0bbin-Monro \; algorithm R0bbin−Monroalgorithm
- 是 s t o c h a s t i c a p p r o x i m a t i o n ( S A ) stochastic \; approximation(SA) stochasticapproximation(SA)领域具有开创性的工作
- 大名鼎鼎的 s t o c h a s t i c g r a d i e n t d e s c e n t stochastic \; gradient \; descent stochasticgradientdescent是 R M RM RM算法的一种特殊情况
下面看一个求解方程问题
g ( w ) = 0 , w h e r e w ∈ R i s t h e v a r i a b l e t o b e s o l v e d , g i s R → R f u n c t i o n g(w)=0, where \; w \in \mathbb{R} \; is \; the \; variable \; to \; be \; solved ,g \; is \;\mathbb{R} \rightarrow \mathbb{R} \; function g(w)=0,wherew∈Risthevariabletobesolved,gisR→Rfunction
- 如果 g g g的表达式已知,那么就有很多种算法可以求解
- 另一种是表达式未知的情况,就比如神经网络,这样的问题就可以用RM算法求解
下面就看一下RM算法如何解决上面的问题
我们的目标是求解 g ( w ) = 0 , g(w)=0, g(w)=0,最优解 w ∗ w^* w∗
w k + 1 = w k − a k g ~ ( w k , η ) , k = 1 , 2 , 3 , . . . w_{k+1}=w_k-a_k\tilde{g}(w_k,\eta),k=1,2,3,... wk+1=wk−akg~(wk,η),k=1,2,3,...
- w k w_k wk是对方程根的第 k k k次估计
- g ~ ( w k , η ) = g ( w k ) + η k \tilde{g}(w_k,\eta)=g(w_k)+\eta_k g~(wk,η)=g(wk)+ηk, g ~ \tilde{g} g~是对 g g g的一个有噪音观测, η k \eta_k ηk是一个噪音
- a k a_k ak是一个正系数
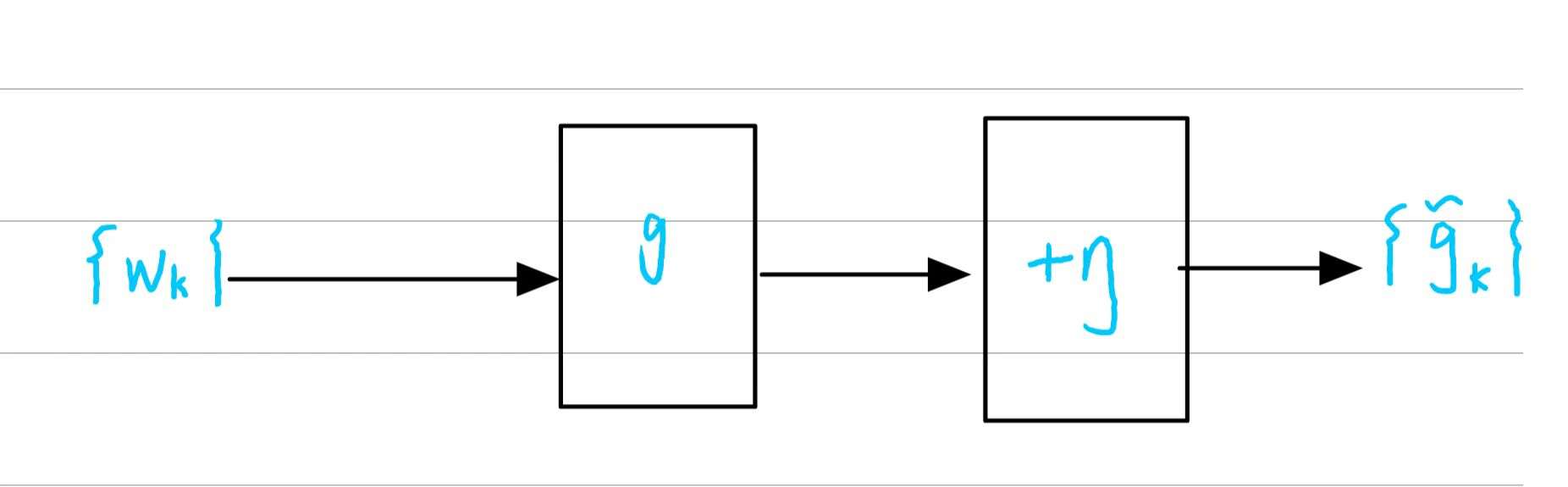
函数 g ( w ) g(w) g(w)就是作为一个黑盒 ( b l a c k b o x ) (black \; box) (blackbox),这个算法求解依赖于数据 d a t a data data
- i n p u t s e q u e n c e : w k input \;sequence:{w_k} inputsequence:wk
- N o i s y o u t p u t s e q u e n c e : g ~ ( w k , η k ) Noisy \; output \; sequence:{\tilde{g}(w_k,\eta_k)} Noisyoutputsequence:g~(wk,ηk)
下面是关于 R M RM RM算法收敛性的一些数学解释





下面看如何把 R M RM RM算法应用到 m e a n e s t i m a t i o n mean \; estimation meanestimation里面
E n = ∑ i = 1 n x i n = ∑ i = 1 n − 1 x i + x n n = ( n − 1 ) E n − 1 + x n n = E n − 1 + x n − E n − 1 n \mathbb{E}_n = \frac{\sum_{i=1}^nx_i}{n}=\frac{\sum_{i=1}^{n-1}x_i+x_n}{n}=\frac{(n-1)\mathbb{E_{n-1}} + x_n}{n}=\mathbb{E}_{n-1}+\frac{x_n-\mathbb{E}_{n-1}}{n} En=n∑i=1nxi=n∑i=1n−1xi+xn=n(n−1)En−1+xn=En−1+nxn−En−1
这是最开始介绍的 m e a n e s t i m a t i o n mean \; estimation meanestimation
w k + 1 = w k + α ( x k − w k ) w_{k+1} = w_k + \alpha(x_k-w_k) wk+1=wk+α(xk−wk)
当时 α = 1 k \alpha=\frac{1}{k} α=k1,最开始当 α = 1 k \alpha=\frac{1}{k} α=k1时,可以显示的写出 w k + 1 = 1 k ∑ i = 1 k x i w_{k+1}=\frac{1}{k}\sum_{i=1}^{k}x_i wk+1=k1∑i=1kxi,但当 α ≠ 1 k \alpha \neq \frac{1}{k} α=k1时,当时无法分析 w k + 1 w_{k+1} wk+1的收敛性,根据 R M RM RM算法可以知如果这个 m e a n e s t i m a t i o n mean \; estimation meanestimation是一种特殊的 R M RM RM算法,那么 w k + 1 w_{k+1} wk+1就会收敛
下面就看一下这个 m e a n e s t i m a t i o n mean \; estimation meanestimation是不是一个 R M RM RM算法
考虑这样一个函数 g ( w ) = w − E [ X ] g(w)=w-\mathbb{E}[X] g(w)=w−E[X],我们的目标是求 g ( w ) = 0 g(w)=0 g(w)=0,如果能解决这个问题,就能得到 E [ X ] \mathbb{E}[X] E[X]
E [ X ] \mathbb{E}[X] E[X]显示我们是不知道的(也是我们想要去求解的),但是我们可以对 X X X进行采样也就是可以获得 g ~ ( w , x ) = w − x \tilde{g}(w,x)=w-x g~(w,x)=w−x
g ~ ( w , η ) = w − x = w − x + E [ X ] − E [ X ] = ( w − E [ X ] ) + ( E [ X ] − x ) = g ( w ) + η \tilde{g}(w,\eta)=w-x=w-x+\mathbb{E}[X]-\mathbb{E}[X]=(w-\mathbb{E}[X])+(\mathbb{E}[X]-x)=g(w)+\eta g~(w,η)=w−x=w−x+E[X]−E[X]=(w−E[X])+(E[X]−x)=g(w)+η
相对应的 R M RM RM算法
w k + 1 = w k − α k g ~ ( w k , η k ) = w k − α k ( w k − x k ) w_{k+1}=w_k-\alpha_k\tilde{g}(w_k, \eta_k)=w_k-\alpha_k(w_k-x_k) wk+1=wk−αkg~(wk,ηk)=wk−αk(wk−xk)
上面的这个式子就是所给出的 m e a n e s t i m a t i o n mean \; estimation meanestimation的算法
Stochastic gradient descent
S G D SGD SGD算法主要是去解决优化问题
min w J ( w ) = E [ f ( w , X ) ] \min_w J(w)=\mathbb{E}[f(w,X)] wminJ(w)=E[f(w,X)]
- w w w是一个待优化的参数
- X X X是一个随机变量,期望 ( e x p e c t i o n ) (expection) (expection)是对 X X X求的
求解这个问题下面给出3种方法,这三种方法是逐渐递进的
M e t h o d 1 : g r a d i e n t d e s c e n t ( G D ) 梯度下降 Method \; 1:gradient \; descent(GD) \; 梯度下降 Method1:gradientdescent(GD)梯度下降
如果要最大化一个函数可以用梯度上升
w k + 1 = w k − α k ∇ w E [ f ( w k , X ) ] = w k − α k E [ ∇ w f ( w k , X ) ] w_{k+1}=w_k-\alpha_k\nabla_w\mathbb{E}[f(w_k, X)]=w_k-\alpha_k\mathbb{E}[\nabla_wf(w_k,X)] wk+1=wk−αk∇wE[f(wk,X)]=wk−αkE[∇wf(wk,X)]
- α k \alpha_k αk被称为步长,是用来控制在梯度方向下降的快还是慢的
- 这里要对梯度求期望,我们就需要模型或者数据两者其中之一
M e t h o d 2 : b a t c h g r a d i e n t d e s c e n t ( B G D ) 批量梯度下降 Method \; 2:batch \;gradient \; descent(BGD) \; 批量梯度下降 Method2:batchgradientdescent(BGD)批量梯度下降
E [ ∇ w f ( w k , X ) ] ≈ 1 n ∑ i = 1 n ∇ f ( w k , x i ) \mathbb{E}[\nabla_wf(w_k,X)] \approx \frac{1}{n}\sum_{i=1}{n}\nabla f(w_k,x_i) E[∇wf(wk,X)]≈n1i=1∑n∇f(wk,xi)
w k + 1 = w k − α k 1 n ∑ i = 1 n ∇ f ( w k , x i ) w_k+1=w_k-\alpha_k \frac{1}{n}\sum_{i=1}{n}\nabla f(w_k,x_i) wk+1=wk−αkn1i=1∑n∇f(wk,xi)
这个其实就是我们之前学习的蒙特卡洛的思想,思想比较简单,但是缺点是在每次更新 w k w_k wk时,都需要采样很多次
M e t h o d 3 : s t o c h a s t i c g r a d i e n t d e s c e n t ( S G D ) 随机梯度下降 Method \; 3:stochastic \;gradient \; descent(SGD) \; 随机梯度下降 Method3:stochasticgradientdescent(SGD)随机梯度下降
w k + 1 = w k − α k ∇ w f ( w k , x k ) w_{k+1}=w_k-\alpha_k\nabla_wf(w_k,x_k) wk+1=wk−αk∇wf(wk,xk)
注意 G D GD GD公式中的 X X X变成了对 X X X的一次采样 x k x_k xk
- 在 G D GD GD中用的是 t r u e g r a d i e n t E [ ∇ w f ( w k , X ) ] true \; gradient \; \mathbb{E}[\nabla_wf(w_k,X)] truegradientE[∇wf(wk,X)],但是这个真正的梯度是不知道的,所以就用一个 s t o c h a s t i c g r a d i e n t ∇ w f ( w k , x k ) stochastic \; gradient \; \nabla_w f(w_k, x_k) stochasticgradient∇wf(wk,xk)来代替,,之所以被称为 s t o c h a s t i c stochastic stochastic是因为这里面有一个对 X X X随机的采样
- 和 B G D BGD BGD相比, S G D SGD SGD就是把 B G D BGD BGD中的 n n n变成了 1 1 1
下面是一个用 S G D SGD SGD优化的例子
min w J ( w ) = E [ f ( w , X ) ] = E [ 1 2 ∣ ∣ ∣ w − X ∣ ∣ 2 ] \min_w J(w)=\mathbb{E}[f(w,X)]=E\left[ \frac{1}{2}\mid\mid \mid w - X \mid \mid^2 \right] wminJ(w)=E[f(w,X)]=E[21∣∣∣w−X∣∣2]
w h e r e f ( w , X ) = 1 2 ∣ ∣ ∣ w − X ∣ ∣ 2 ∇ f ( w , X ) = w − X where \; f(w,X)=\frac{1}{2}\mid\mid \mid w - X \mid \mid^2 \quad \nabla f(w,X)=w-X wheref(w,X)=21∣∣∣w−X∣∣2∇f(w,X)=w−X
这个问题的解 w ∗ = E [ X ] w^* =\mathbb{E}[X] w∗=E[X]
下面是推导:
我们知道 J ( w ) J(w) J(w)要达到最小值,有一个必要条件,就是对 J ( w ) J(w) J(w)求梯度应该等于 0 0 0,也就是
∇ J ( w ) = ∇ E [ f ( w , X ) ] = E [ ∇ f ( w , X ) ] = E [ w − X ] = w − E [ X ] = 0 \nabla J(w) = \nabla \mathbb{E}[f(w,X)]= \mathbb{E}[\nabla f(w,X)]=\mathbb{E}[w-X]=w-\mathbb{E}[X]=0 ∇J(w)=∇E[f(w,X)]=E[∇f(w,X)]=E[w−X]=w−E[X]=0
于是
w ∗ = E [ X ] w^*=\mathbb{E}[X] w∗=E[X]
G D 算法: GD算法: GD算法:
w k + 1 = w k − α k ∇ w J ( w k ) = w k − α k E [ ∇ w f ( w k , X ) ] = w k − α k E [ w k − X ] \begin{align} w_{k+1} &= w_k - \alpha_k \nabla_w J(w_k) \\ &= w_k - \alpha_k \mathbb{E}[\nabla_wf(w_k,X)] \\ &= w_k - \alpha_k\mathbb{E}[w_k-X] \end{align} wk+1=wk−αk∇wJ(wk)=wk−αkE[∇wf(wk,X)]=wk−αkE[wk−X]
S G D 算法: SGD算法: SGD算法:
w k + 1 = w k − α k ∇ w f ( w k , x k ) = w k − α ( w k − x k ) w_{k+1}=w_k-\alpha_k \nabla_wf(w_k,x_k)=w_k-\alpha (w_k - x_k) wk+1=wk−αk∇wf(wk,xk)=wk−α(wk−xk)
从 G D GD GD到 S G D SGD SGD
w k + 1 = w k − α k E [ ∇ w f ( w k ) , X ] w_{k+1}=w_k-\alpha_k \mathbb{E}[\nabla_wf(w_k),X] wk+1=wk−αkE[∇wf(wk),X]
w k + 1 = w k − α k ∇ w f ( w k ) , x k w_{k+1}=w_k-\alpha_k \nabla_wf(w_k),x_k wk+1=wk−αk∇wf(wk),xk
直接用 s t o c h a s t i c g r a d i e n t stochastic \; gradient stochasticgradient去近似 t r u e g r a d i e n t true \; gradient truegradient
既然是近似两者之间存在有误差,那么两者之间的关系如下
∇ w f ( w k , x k ) = E [ ∇ w f ( w , X ) ] + ∇ w f ( w k , x k ) − E [ ∇ w f ( w , X ) ] \nabla_w f(w_k,x_k) = \mathbb{E}[\nabla_w f(w,X)] +\nabla_w f(w_k,x_k) - \mathbb{E}[\nabla_wf(w,X)] ∇wf(wk,xk)=E[∇wf(w,X)]+∇wf(wk,xk)−E[∇wf(w,X)]
∇ w f ( w k , x k ) ≠ E [ ∇ w f ( w , X ) ] \nabla_w f(w_k,x_k) \neq \mathbb{E}[\nabla_w f(w,X)] ∇wf(wk,xk)=E[∇wf(w,X)]
那么 S G D SGD SGD能否找到最优解呢?也就是 S G D 算法 SGD算法 SGD算法能否收敛
可以通过证明 S G D 算法 SGD算法 SGD算法是 R M 算法 RM算法 RM算法解决这个问题


于是我们可以用 R M RM RM算法的收敛性来分析 S G D SGD SGD算法的收敛性




结论:当 w k w_k wk和 w ∗ w^* w∗距离比较远时, S G D SGD SGD和 G D GD GD的行为是比较类似的
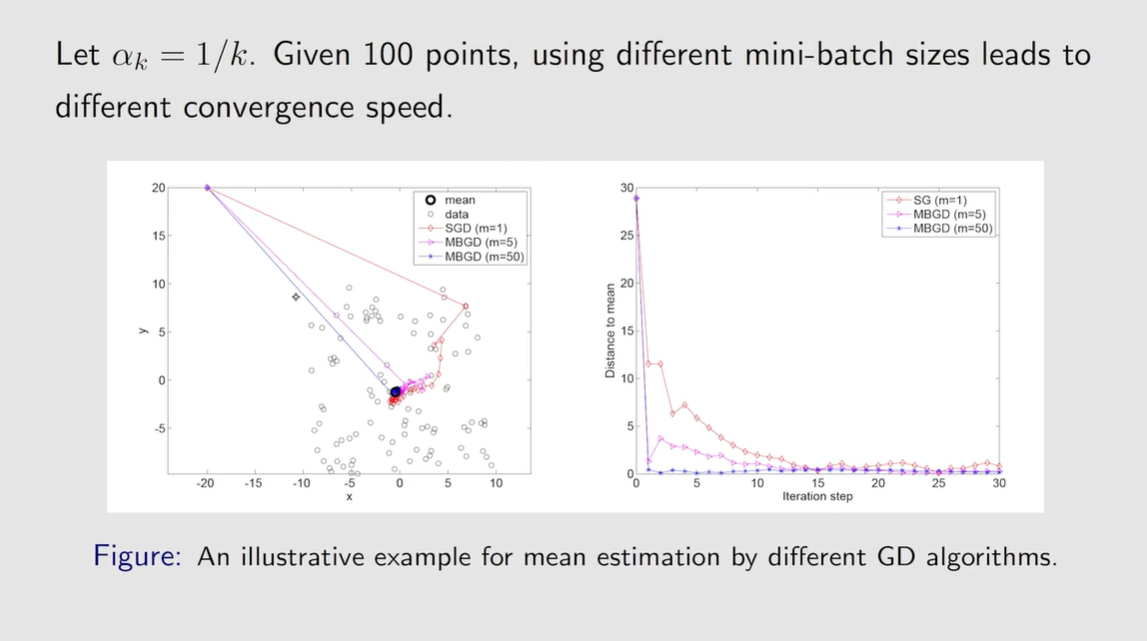
BGD、MBGD、 and SGD

可以认为 M B G D MBGD MBGD包括了 S G D SGD SGD和 B G D BGD BGD
当 m i n i − b a t c h mini-batch mini−batch为 1 1 1的时候就变成了 S G D SGD SGD
当 m i n i − b a t c h mini-batch mini−batch比较大的时候就变成了 B G D BGD BGD
相比于 S G D SGD SGD, M B G D MBGD MBGD的随机性比较小,因为用了更多的数据去代替一个数据.
相比于 B G D BGD BGD, M B G D MBGD MBGD的随机性会比较大,需要的数据又比较少,效率和性能是比较高的.


Summary
- m e a n e s t i m a t i o n : mean \; estimation: meanestimation:使用一组数 x k {x_k} xk计算 E [ X ] \mathbb{E}[X] E[X], w k + 1 = w k + 1 k ( w k − x k ) w_{k+1} = w_k + \frac{1}{k}(w_k-x_k) wk+1=wk+k1(wk−xk)
- R M 算法 RM算法 RM算法: s o l v e g ( w ) = 0 u s i n g g ~ ( w k , η k ) solve \; g(w)=0 \; using \; {\tilde{g}(w_k,\eta_k)} solveg(w)=0usingg~(wk,ηk), w k k + 1 = w k − a k g ~ ( w k , η k ) w_k{k+1}=w_k-a_k{\tilde{g}(w_k,\eta_k)} wkk+1=wk−akg~(wk,ηk)
- S G D 算法: m i n i m i z e J ( w ) = E [ f ( w k , X ) ] , u s i n g ∇ w f ( w k , x k ) , w k + 1 = w k − α k ∇ w f ( w k , x k ) SGD算法:minimize \; J(w)=\mathbb{E}[f(w_k, X)],using \; {\nabla_wf(w_k,x_k)}, \; w_{k+1}=w_k-\alpha_k \nabla_w f(w_k, x_k) SGD算法:minimizeJ(w)=E[f(wk,X)],using∇wf(wk,xk),wk+1=wk−αk∇wf(wk,xk)
更多推荐


 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)