
大语言模型逻辑一致性研究新突破:测量、评估与提升
本研究提出了一种全面的方法来测量、评估和提升大语言模型的逻辑一致性,通过定义关键的一致性属性、进行广泛的实验评估以及提出有效的数据处理方法,为提高模型的可靠性和实用性提供了重要的理论和实践指导。研究结果强调了逻辑一致性在大语言模型开发中的重要性,不仅作为评估模型可靠性的关键指标,还为改进模型在下游应用中的性能提供了新的方向。未来的研究可以进一步探索如何优化这些方法,以适应更广泛的应用场景和更复杂的
大语言模型逻辑一致性研究新突破:测量、评估与提升
原创 圈姐卡米儿 互联网持续学习圈 2025年01月06日 19:02 上海
大语言模型(LLMs)在自然语言处理领域取得了显著进展,但在可靠性和逻辑一致性方面仍面临挑战。今天为大家解读的这篇论文 “Measuring, Evaluating and Improving Logical Consistency in Large Language Models”,提出了一种创新的方法来测量和提升 LLMs 的逻辑一致性,为提高模型的可靠性和实用性提供了新的思路。
研究背景
随着大语言模型的快速发展,其在复杂自然语言任务中的应用日益广泛。然而,模型存在的一些问题,如幻觉、偏差和推理不一致等,严重影响了其可信度和可靠性,尤其在需要高度信任和精确决策的专业应用中,这些问题更为突出。逻辑一致性作为可靠系统的关键要素,对于大语言模型在结构化推理和决策任务中的表现至关重要。它不仅确保模型的决策基于对问题的稳定理解,减少输出的不确定性和矛盾性,还能增强模型的可解释性和可靠性。因此,研究大语言模型的逻辑一致性具有重要意义。
测量逻辑一致性
评估框架
论文提出了一个通用框架,通过三个基本属性来量化逻辑一致性:传递性、交换性和否定不变性。这些属性是逻辑推理的基础,对于评估模型的可靠性和推理能力至关重要。
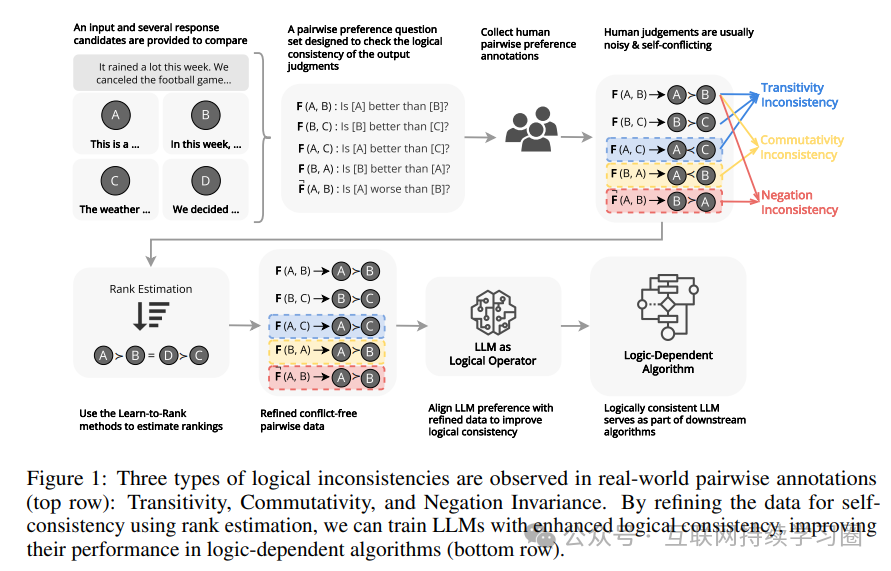
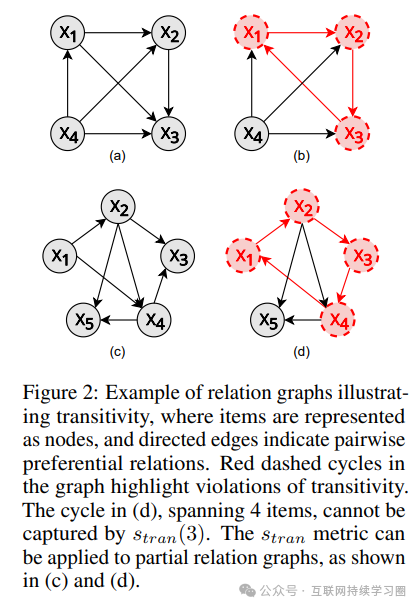
传递性
传递性确保模型在比较多个项目时,判断具有连贯性,避免逻辑矛盾。例如,如果模型判断 A 优于 B,B 优于 C,那么它应该也能判断 A 优于 C。为了衡量传递性,作者引入了度量,通过计算模型在不同项目子集上的传递性得分,来评估模型在处理复杂关系时的一致性程度。该度量的取值范围为 0 到 1,1 表示完全传递性。实验表明,随着项目数量的增加,模型保持传递性的难度增大,不同模型在传递性表现上存在差异,如 Mistral-7B 在传递性方面表现出色,但在其他一致性方面相对较弱。
交换性
交换性测试模型在比较项目顺序改变时,判断是否保持一致。作者提出了度量,通过比较模型在不同项目顺序下的判断,来评估其交换性。的取值范围也为 0 到 1,1 表示完全不受项目顺序影响。实验发现,模型在交换性方面的表现与人类偏好密切相关,缺乏交换性往往表明模型存在较强的位置偏差,不同模型对输入变化的敏感度不同,这也影响了它们在交换性方面的表现。
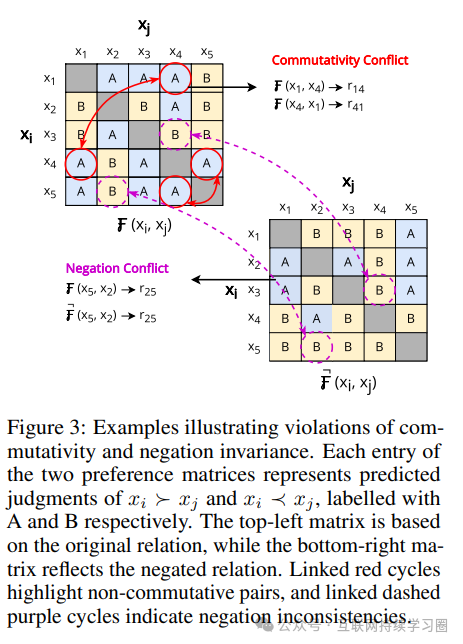
否定不变性
否定不变性检查模型在处理关系否定时是否保持一致性。为此,作者定义了度量,通过比较模型在原始关系和否定关系下的判断,来评估其否定不变性。同样取值于 0 到 1 之间,1 表示模型在处理否定关系时完全一致。研究表明,许多模型在面对关系否定时难以保持一致性,这可能导致对关系互补性质的理解和应用出现问题。
评估逻辑一致性
评估设置
- 任务和数据集
作者使用了三个具有代表性的任务来评估模型的逻辑一致性,包括抽象摘要评估(SummEval 数据集)、文档重新排序(NovelEval 数据集)和时间事件排序(CaTeRS 数据集)。这些任务涵盖了不同的主观性水平,能够全面测试模型在各种情境下的逻辑一致性。
- 指标和可靠性测量
计算每个任务测试集上的逻辑一致性指标,并报告平均值。同时,通过计算模型判断与人类注释之间的成对判断准确率,来衡量模型与人类判断的一致性程度(人类一致性率,H.)。为了评估模型的可靠性,作者采用了蒙特卡洛采样的思维链推理输出,并计算自一致性(自我一致性定义为多次采样中与多数判断一致的输出百分比)。
实验结果与分析
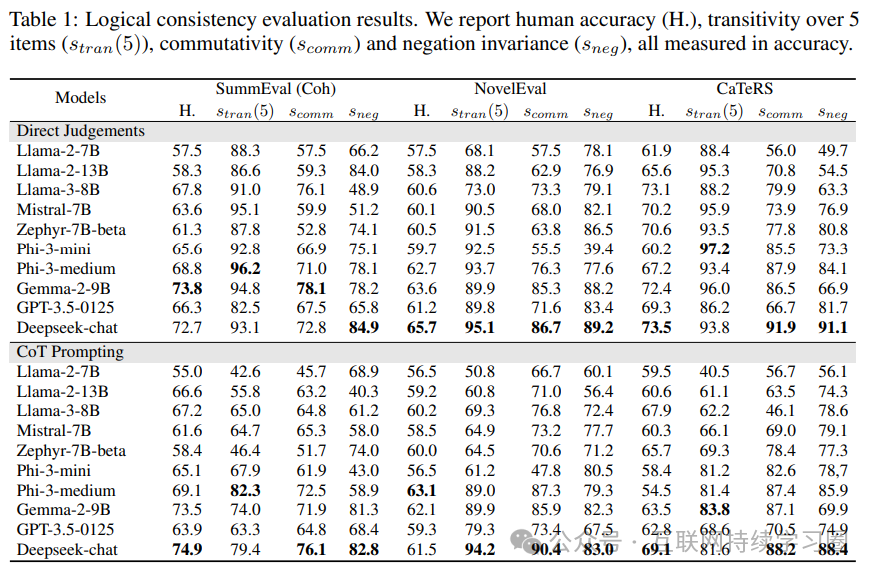
- 不同模型的表现
实验结果表明,近期的模型如 Gemma2-9B 和 Phi-3-medium 在整体一致性上表现较好,但在不同一致性维度上的表现存在差异。例如,Deepseek-chat、Phi-3-medium 和 Gemma-2-9B 在多个一致性维度上均表现出色,而 Mistral-7B 虽然在传递性方面表现突出,但在其他方面相对较弱。此外,Phi-3 家族模型由于使用了更清晰、矛盾较少的合成数据,在逻辑一致性上表现较高,但逻辑一致性与人类一致性准确率之间并未发现明显的强相关性。
- 思维链提示的影响
思维链(CoT)提示对逻辑一致性的影响并不总是积极的。在某些情况下,CoT 推理甚至导致传递性性能下降。作者推测,这可能是由于 CoT 提示在推理过程中引入了额外的变化,导致模型在比较判断时使用了不同的标准,从而产生了不一致的结果。这表明,尽管 CoT 提示在复杂推理中有益,但在某些逻辑判断任务中可能会引入意想不到的不一致性。
一致性与可靠性的关系
- 传递性与自我一致性
研究发现,传递性与模型的自我一致性之间存在强相关性。自我一致性反映了模型内部的稳定性和可靠性,较高的自我一致性表明模型在处理输入关系时具有更稳定的理解。因此,传递性可作为评估模型整体可靠性的有用指标。
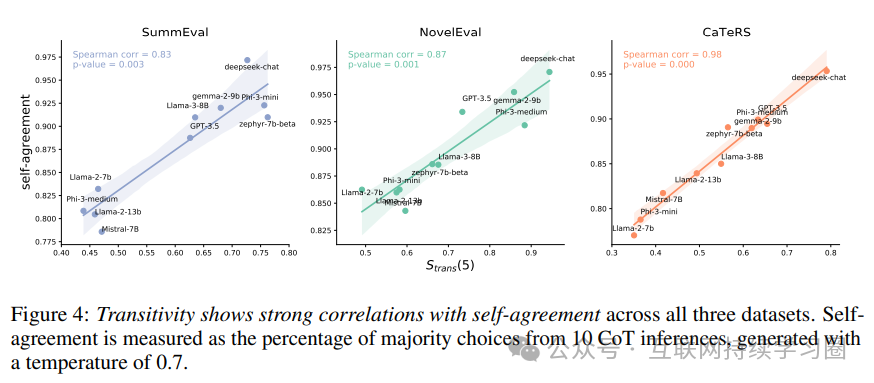
- 交换性与人类偏好
交换性与人类偏好之间也呈现出强相关性。缺乏交换性的模型往往表现出较强的位置偏差,这会影响其与人类判断的一致性。不同模型在交换性与人类偏好相关性的强度上存在差异,这可能与模型的训练方式和对输入提示的敏感度有关。
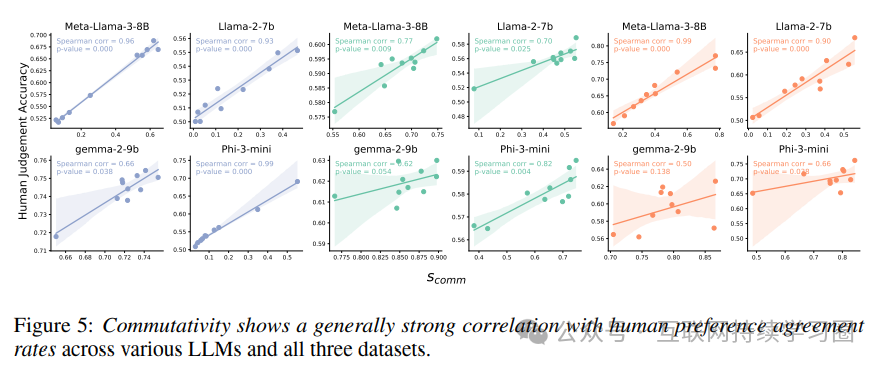
提升逻辑一致性的数据处理方法
方法动机
现实世界中的偏好数据往往存在噪声和自相矛盾的问题,这会影响模型学习偏好的效率,并导致训练出的模型逻辑不一致。为了解决这一问题,作者受强化学习人类反馈(RLHF)过程的启发,提出了一种数据精炼和增强框架,旨在从嘈杂的数据中估计出一致的排名,并通过添加无冲突的成对比较来增强数据,从而提高模型的逻辑一致性,同时保持与人类偏好的对齐。
基于胜率估计排名
作者使用胜率方法从嘈杂的成对注释中估计全局排名。该方法计算每个项目的胜率(获胜次数减去失败次数除以参与比较的次数),并根据胜率对项目进行排序。这种方法简单有效,尤其适用于处理部分和稀疏比较的实际偏好数据集,且不受比较顺序的影响。通过这种方式,可以得到一个完整或部分的排名,并将其转换为自洽的成对比较集,进一步还可以通过添加否定关系的比较来扩充数据集。
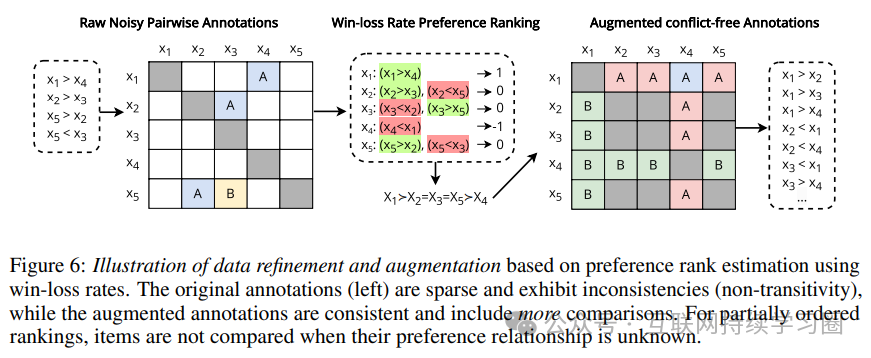
实验验证
- 实验设置
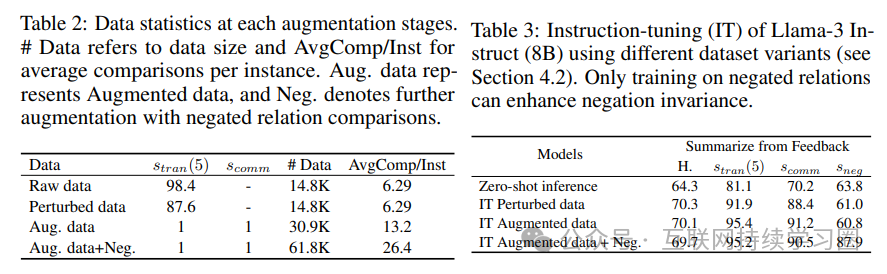
作者在 Summarize From Feedback 数据集上进行了实验,该数据集包含了人类注释者对摘要的成对比较。为了模拟数据噪声,实验随机翻转了 10% 的训练标签。然后,将数据精炼和增强技术应用于数据集,以提高成对比较的一致性和数量。作者使用三个 Meta-Llama-3-8B-Instruct 模型进行指令调整,分别在翻转 / 扰动数据、精炼和增强数据集以及进一步添加否定关系比较的数据集上进行训练,并在测试集的随机子集中评估模型性能。
- 实验结果
实验结果表明,零样本推理表现出较大的逻辑不一致性,但在扰动数据上进行训练可以显著提高模型与人类偏好的对齐和逻辑一致性。使用精炼和增强数据集进行训练进一步提高了模型的传递性和交换性,同时保持了较高的人类对齐水平。仅在否定关系上进行训练可以提高模型在否定不变性方面的性能,但添加否定关系可能会引入干扰,导致其他逻辑属性的性能略有下降。总体而言,这些结果验证了数据精炼和增强框架在提高模型逻辑一致性方面的有效性。
逻辑一致性对下游应用的影响
应用案例:偏好排名算法
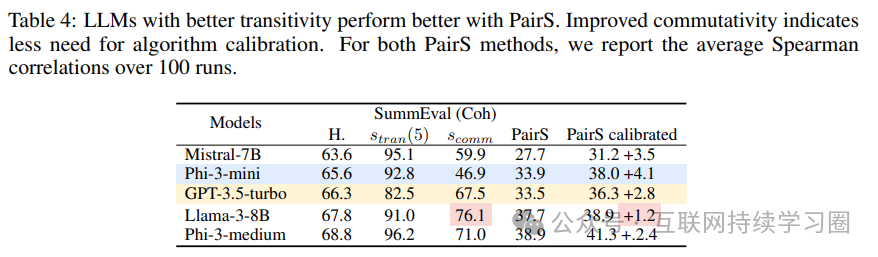
作者通过 Liu 等人提出的 Pairwise-Preference Search(PairS)算法,展示了逻辑一致性对下游应用的重要影响。PairS 是一种基于排序的偏好排名聚合算法,使用大语言模型作为成对评估器,通过比较项目的特定属性来生成排名。该算法的性能通过比较模型生成的排名与人类判断之间的斯皮尔曼相关系数来衡量。排序算法对逻辑属性如传递性和交换性依赖较高,PairS 算法假设作为评估器的大语言模型具有近乎完美的传递性和交换性,以获得最佳排名结果。
实验结果与分析
实验结果显示,模型的逻辑一致性对 PairS 算法的性能有显著影响。尽管 Phi-3-mini 在与人类判断的准确性上略低于 GPT-3.5-turbo,但其较强的传递性使其在排名性能上表现更好,无论是否进行校准。此外,模型的交换性与 PairS 算法校准后的性能提升之间存在明显的相关性,交换性较好的模型在校准过程中所需的计算资源更少,因为它们对校准的依赖程度较低。
研究总结
本研究提出了一种全面的方法来测量、评估和提升大语言模型的逻辑一致性,通过定义关键的一致性属性、进行广泛的实验评估以及提出有效的数据处理方法,为提高模型的可靠性和实用性提供了重要的理论和实践指导。研究结果强调了逻辑一致性在大语言模型开发中的重要性,不仅作为评估模型可靠性的关键指标,还为改进模型在下游应用中的性能提供了新的方向。未来的研究可以进一步探索如何优化这些方法,以适应更广泛的应用场景和更复杂的任务需求,从而推动大语言模型在实际应用中的发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)