
《Tensorflow 实战Google深度学习框架》学习笔记(三)
第四章 深层神经网络
4.1 深度学习与深层神经网络
维基百科对深度学习的精确定义为:一类通过多层非线性变换对高复杂性数据建模算法的集合,可见,深度学习有两个重要的特性——多层和非线性。
深度学习具体定义可以参照维基百科:https://en.wikipedia.org/wiki/Deep_learning。
4.1.1 线性模型的局限性
在线性模型中,模型的输出为输入的加权和,假设一个模型的输出y和输入xi满足以下关系,那么这个模型就是一个线性模型。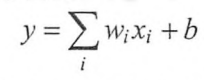
其中wi,b为模型的参数,被称之为线性模型是因为当模型的输入只有一个的时候,,x和y形成了二维坐标系上的一条直线。类似的,当模型有n个输入时,x和y形成了n+1维空间中的一个平面。而一个线性模型中通过输入得到输出的函数被称之为一个线性变换。
线性模型的最大特点是任意线性模型的组合仍然还是线性模型,以下的前向传播算法实现的就是一个线性模型。
前向传播算法的公式为: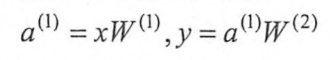
其中x为输入,W为参数,整理一下上面的公式可以得到整个模型的输出为: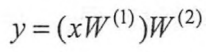
根据矩阵乘法的结合律得: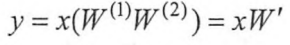

这样输入输出的关系就变为: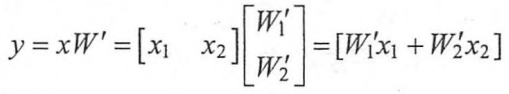
虽然这个神经网络有两层(不算输入层),但是它和单层的神经网络并没有区别。以此类推,只通过线性变换,任意层的全连接神经网络和单层神经网络模型的表达能力没有任何区别,而且它们都是线性模型。然而线性模型能够解决的问题是有限的。这就是线性模型最大的局限性,也是为什么深度学习要强调非线性。
线性可分问题是指线性模型就可以解决的问题,而所谓深度学习中的复杂问题,至少是无法通过直线或高维空间的平面划分的。然而在现实世界中,大多数问题都是无法线性分割的。
4.1.2 激活函数实现去线性化
如果将每一个神经元(也就是神经网络中的节点)的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了,这个非线性函数就是激活函数。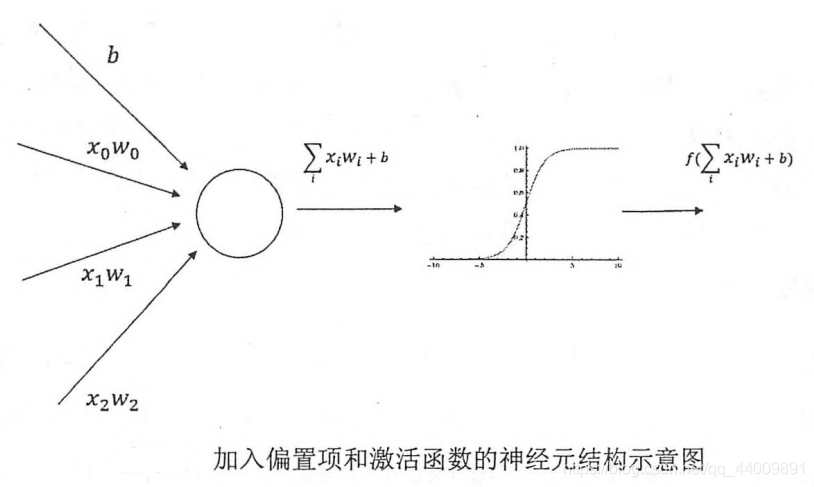
在3.4.2中前向传播算法的基础上添加偏置项和激活函数: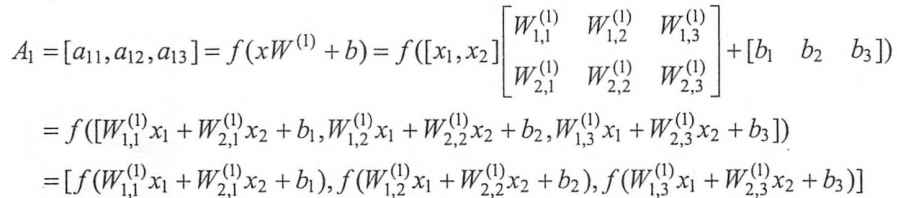
其中激活函数的作用是去线性化,而偏置项允许激活函数向左或向右移位。
目前TensorFlow提供了7种不同的非线性激活函数,tf.nn.relu,tf.sigmoid,tf.tanh是其中比较常用的几个,而且TensorFlow也支持使用自己定义的激活函数。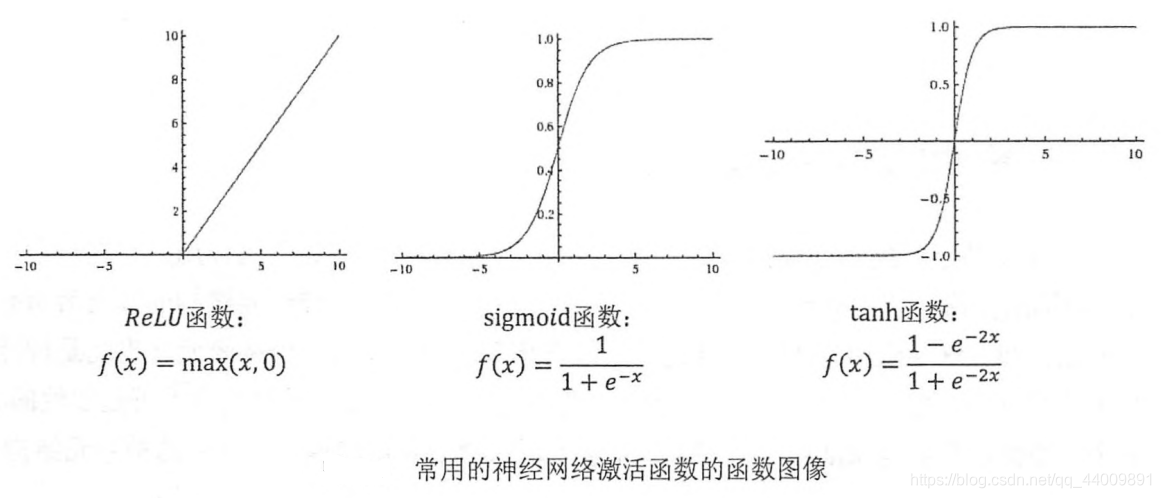
4.1.3 多层网络解决异或运算
感知机可以简单地理解为单层的神经网络,4.1.2中加入偏置项和激活函数的神经元结构就是感知机的网络结构,感知机被证明是无法模拟异或运算的,但深度学习的多层变换特性可以解决这个问题,在我的理解中,多层神经网络将每一层神经元对特征的处理能力进行堆叠,使模型的特征提取能力更加强大。
4.2 损失函数定义
神经网络模型的效果以及优化的目标是通过损失函数(loss function)来定义的。对于相同的神经网络,不同的损失函数会对训练得到的模型产生重要影响。
4.2.1 经典损失函数
分类问题和回归问题是监督学习的两大种类,分类问题希望解决的是将不同的样本分到事先定义好的类别中,回归问题希望解决的是对具体数值的预测。
4.2.1.1 分类问题的经典损失函数
通过神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。对于每一个样例,神经网络可以得到的一个n维向量作为输出结果,向量中的每一个维度(也就是每一个输出节点)对应一个类别,在理想情况下,如果一个样本属于类别k,那么这个类别所对应的输出节点的输出值应该为1,而其他节点的输出都为0。
为了描述一个输出向量和期望向量的接近程度,我们使用一种叫交叉熵(cross entropy)的损失函数,它能刻画两个概率分布之间的距离,是分类问题中使用比较广的一种损失函数。
我们先来了解一下概率分布是什么,概率分布刻画了不同事件发生的概率,当事件总数是有限的情况下,概率分布函数p(X = x)满足: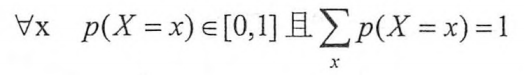
也就是说,任意事件发生的概率都在0和1之间,且总有某一个事件发生(概率的和为1),如果将分类问题中“一个样例属于某一个类别”看成一个概率事件,那么训练数据的正确答案就符合一个概率分布,因为事件“一个样例属于不正确的类别”的概率为0,而“一个样例属于正确的类别”的概率为1。
我们再来看一下交叉熵的公式,给定两个概率分布p和q,通过q来表示p的交叉熵为: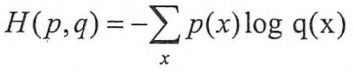
注意,交叉熵刻画的是两个概率分布之间的距离,然而神经网络的输出却不一定是一个概率分布。
为了解决这个问题,我们使用Softmax回归,它可以将神经网络前向传播得到的结果变成概率分布,Softmax回归本身可以作为一个学习算法来优化分类结果,但在TensorFlow中,Softmax回归的参数被去掉了,它只是一层额外的处理层,可以将神经网络的输出变成一个概率分布。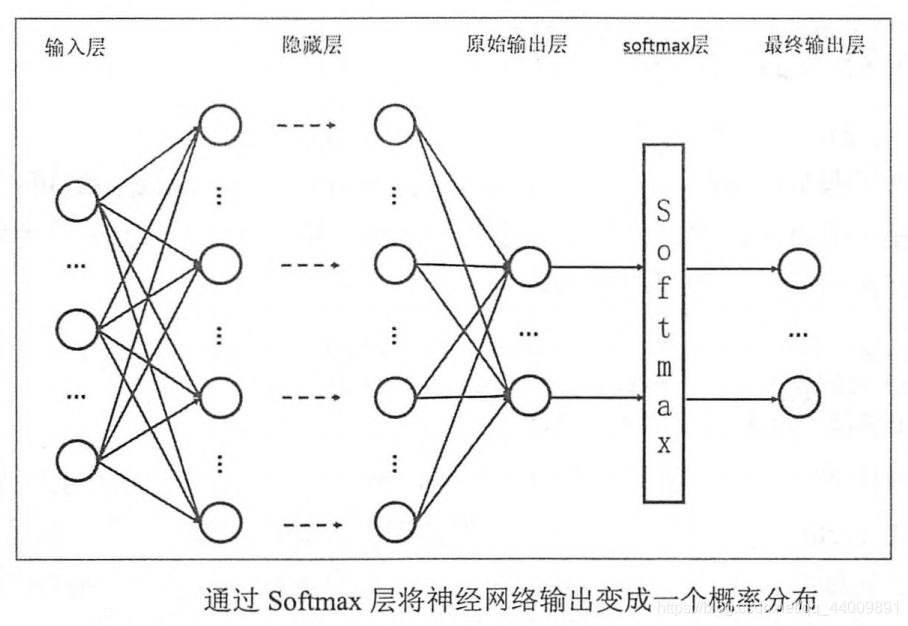
假设原始的神经网络输出为y1,y2,……,yn,那么结果Softmax回归处理后的输出为: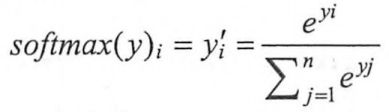
从以上公式中可以看出,原始神经网络的输出被用作置信度来生成新的输出,而新的输出满足概率分布的所有要求。这个新的输岀可以理解为经过神经网络的推导,一个样例为不同类别的概率分别是多大。这样就把神经网络的输出也变成了一个概率分布,从而可以通过交叉熵来计算预测的概率分布和真实答案的概率分布之间的距离了。
我们重新来看一下交叉熵的公式,我们可以发现交叉熵函数不是对称的(H(p,q)不等于H(q,p)),它刻画的是通过概率分布q来表达概率分布p的困难程度,因为真实值是希望得到的结果,所以当交叉嫡作为神经网络的损失函数时,p代表的是真实值,q代表的是预测值。
交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小,两个概率分布越接近。
现在我们看一下交叉熵在TensorFlow中的代码实现并对它进行解读:
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
①y_代表n个样例的真实值,y代表n个样例的最终神经网络输出的预测值,它们都是n*m的矩阵,其中n为一个batch中样例的数量,m为分类的类别数量;
②通过tf.clip_by_value(y, 1e-10, 1.0)函数可以将张量y中的的数值限制在一个范围[1e-10, 1.0]之内,小于1e-10的会被转换为1e-10,大于1.0的会被转换为1.0,这样可以避免一些运算错误(比如log0是无效的);
③tf.log函数可以完成对张量中所有元素依次求对数的功能;
④这里的“*”乘法运算并不是矩阵乘法,而是矩阵元素之间直接相乘,矩阵乘法需要使用tf.matmul函数来完成;
⑤通过上面这三个运算,得到的结果是一个n*m的二维矩阵,根据交叉熵的公式,应该将每行中的m个结果相加得到所有样例的交叉嫡,然后再对这n行取平均得到一个batch的平均交叉熵,但因为分类问题的类别数量是不变的,所以我们可以直接使用tf.reduce_mean函数对整个矩阵做平均而并不改变计算结果的意义,这样的方式可以使整个程序更加简洁。
因为交叉熵一般会与Softmax回归一起使用,所以TensorFlow对这两个功能进行了统一封装,并提供了 tf.nn.softmax_cross_entropy_with_logits函数:
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
需要注意的是,这里的y_仍然是真实值,但是y却是原始神经网络的输出值。
对交叉熵的理解请参照:
https://blog.csdn.net/qq_36931982/article/details/82998081,
https://blog.csdn.net/shwan_ma/article/details/88795940。
4.2.1.2 回归问题的经典损失函数
回归问题需要预测的不是一个事先定义好的类别,而是一个任意实数,解决回归问题的神经网络一般只有一个输出节点,这个节点的输出值就是预测值。对于回归问题,最常用的损失函数是均方误差(MSE, mean squared error),它的定义如下: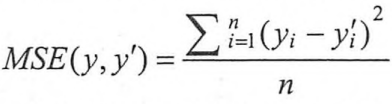
其中yi为一个batch中第i个样例的真实值,而yi’为神经网络给出的预测值。
我们来看一下均方误差在TensorFlow中的代码实现并对它进行解读:
mse = tf.reduce_mean(tf.square(y_ - y))
①其中y代表了神经网络的预测值,y_代表了真实值
②tf.square函数对张量中的值依次进行平方;
③“-”是矩阵对应元素的减法;
④tf.reduce_mean函数进行平均求值。
4.2.2 自定义损失函数
TensorFlow不仅支持经典的损失函数,还可以优化任意的自定义损失函数。
自定义损失函数在TensorFlow中的具体实例请参照:初步了解TensorFlow如何实现自定义损失函数。
4.3 神经网络优化算法
神经网络通过反向传播算法(backpropagation)和梯度下降算法(gradient decent)调整参数的取值。
梯度下降算法主要用于优化单个参数的取值,而反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,从而使神经网络模型在训练数据上的损失函数尽可能小。
反向传播算法是训练神经网络的核心算法,它可以根据定义好的损失函数优化神经网络中参数的取值,从而使神经网络模型在训练数据集上的损失函数达到一个较小值,神经网络模型中参数的优化过程直接决定了模型的质量。
神经网络的优化过程可以分为两个阶段:
第一个阶段,通过前向传播算法计算得到预测值,并将预测值和真实值做对比得出两者之间的差距;
第二个阶段,通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。
需要注意的是,梯度下降算法存在两个问题:
①梯度下降算法并不能保证被优化的函数达到全局最优解,在训练神经网络时,参数的初始值会很大程度影响最后得到的结果,只有当损失函数为凸函数时,梯度下降算法才能保证达到全局最优解。
②梯度下降算法计算时间太长,因为要在全部训练数据上最小化损失,这样在每一轮迭代中都需要计算在全部训练数据上的损失函数。在海量训练数据下,要计算所有训练数据的损失函数是非常消耗时间的。为了加速训练过程,可以使用随机梯度下降算法(stochastic gradient descent)。这个算法优化的不是在全部训练数据上的损失函数,而是在每一轮迭代中,随机优化某一条训练数据上的损失函数。这样每一轮参数更新的速度就大大加快了。因为随机梯度下降算法每次优化的只是某一条数据上的损失函数,所以它的问题也非常明显:在某一条数据上损失函数更小并不代表在全部数据上损失函数更小,于是使用随机梯度下降优化得到的神经网络甚至可能无法达到局部最优。
为了综合梯度下降算法和随机梯度下降算法的优缺点,在实际应用中一般釆用这两个算法的折中——每次计算一小部分训练数据的损失函数,这一小部分数据被称之为一个batch,通过矩阵运算,每次在一个batch上优化神经网络的参数并不会比单个数据慢太多,另一方面,每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
4.4 神经网络进一步优化
4.4.1 学习率的设置
在训练神经网络时,需要设置学习率(leaming rate)来控制参数更新的速度,学习率决定了参数每次更新的幅度,如果幅度过大,那么可能导致参数在极优值的两侧来回移动,如果幅度过小,虽然能保证收敛性,但是这会大大降低优化速度。
为了解决设定学习率的问题,TensorFlow提供了一种更加灵活的学习率设置方法——指数衰减法,通过指数衰减的学习率既可以让模型在训练的前期快速接近较优解,又可以保证模型在训练后期不会有太大的波动,从而更加接近局部最优。
指数衰减学习率在TensorFlow中的具体应用请参照:初步了解TensorFlow如何实现指数衰减学习率。
4.4.2 过拟合问题
实际上,在现实应用中我们想要的并不是让模型尽量模拟训练数据的行为,而是希望通过训练出来的模型对未知的数据给出判断,模型在训练数据上的表现并不一定代表了它在未知数据上的表现。
所谓过拟合,指的是当一个模型过为复杂之后,它可以很好地“记忆”每一个训练数据中随机噪音的部分而忘记了要去“学习”训练数据中通用的趋势,过度拟合训练数据中的随机噪音虽然可以得到非常小的损失函数,但是对于未知数据可能无法做出可靠的判断。
为了避免过拟合问题,一个非常常用的方法是正则化(regularization),正则化的思想就是在损失函数中加入刻画模型复杂程度的指标。
假设用于刻画模型在训练数据上表现的损失函数为J(θ),那么在优化时不是直接优化J(θ),而是优化J(θ) + λR(w),其中R(w)刻画的是模型的复杂程度,而λ表示模型复杂损失在总损失中的比例,需要注意的是,这里的θ表示的是一个神经网络中所有的参数,它包括边上的权重w和偏置项b,但一般来说模型复杂度只由权重w决定。
常用的刻画模型复杂度的函数R(w)有两种,一种是L1正则化,计算公式是: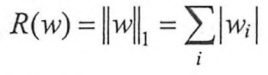
另一种是L2正则化,计算公式是: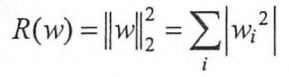
无论是哪一种正则化方式,基本的思想都是希望通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪音,但这两种正则化的方法也有很大的区别:
①L1正则化会让参数变得更稀疏,而L2正则化不会,所谓参数变得更稀疏是指会有更多的参数变为0,这样可以达到类似特征选取的功能,之所以L2正则化不会让参数变得稀疏的原因是当参数很小时,比如0.001,这个参数的平方基本上就可以忽略了,于是模型不会进一步将这个参数调整为0;
②L1正则化的计算公式不可导,而L2正则化公式可导,因为在优化时需要计算损失函数的偏导数,所以对含有L2正则化损失函数的优化要更加简洁,优化含有L1正则化的损失函数要更加复杂,而且优化方法也有很多种。
在实践中,也可以将L1正则化和L2正则化同时使用: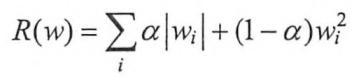
L1正则化和L2正则化在TensorFlow中的具体实现请参照:初步了解TensorFlow如何实现正则化。
4.4.3 滑动平均模型
为了使模型在测试数据上更健壮(robust),我们使用一种特殊的方法——滑动平均模型,在釆用随机梯度下降算法训练神经网络时,使用滑动平均模型在很多应用中都可以在一定程度提高最终模型在测试数据上的表现。
在TensorFlow中提供了tf.train.ExponentialMovingAverage函数来实现滑动平均模型,在初始化ExponentialMovingAverage时,需要提供一个衰减率(decay),这个衰减率将用于控制模型更新的速度,ExponentialMovingAverage对每一个变量会维护一个影子变量(shadow variable),这个影子变量的初始值就是相应变量的初始值,而每次运行变量更新时,影子变量的值会更新为: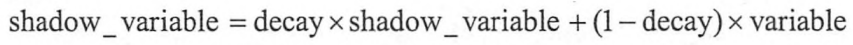
其中shadow variable为影子变量,variable为相应的变量,decay为衰减率。
从公式中可以看到,decay决定了模型更新的速度,decay越大模型越趋于稳定,在实际应用中,decay 一般会设成非常接近1的数(比如0.999或0.9999),为了使得模型在训练前期可以更新得更快,ExponentialMovingAverage还提供了num_updates参数来动态设置decay的大小,如果在ExponentialMovingAverage初始化时提供了num_updates参数,那么每次使用的衰减率将是: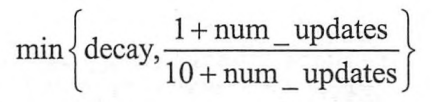
滑动平均模型的理解与使用请参照:
https://blog.csdn.net/Dongjiuqing/article/details/88049882,
https://blog.csdn.net/m0_38106113/article/details/81542863。
4.5 学习资源
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)