
深入理解与编码大语言模型中的自注意力、多头注意力、交叉注意力与因果注意力
现在,让我们讨论一种被广泛使用的自注意力机制——缩放点积注意力 (scaled dot-product attention),它是 Transformer 体系结构的核心组成部分。在自注意力机制中,模型使用三个权重矩阵,分别称为Wq、Wk 和 Wv,这些矩阵在训练过程中作为模型参数进行调整。它们的作用是将输入投影到序列的 查询 (query)、键 (key) 和值 (value)组件中。
深入理解与编码大语言模型中的自注意力、多头注意力、交叉注意力与因果注意力
原创 NLP轻松谈 NLP轻松谈 2025年03月10日 11:11 北京
自从 Transformer 在论文 Attention Is All You Need 中首次提出以来,自注意力 (Self-Attention) 机制已成为众多先进深度学习模型的核心,特别是在自然语言处理 (NLP) 领域。如今,自注意力几乎已成为各类 AI 模型的标准组件,因此理解其工作原理至关重要。
注意力 (Attention) 机制的概念最初源于对循环神经网络 (RNN) 的改进,旨在更好地处理较长的序列或句子。例如,在进行机器翻译时,逐字翻译往往无法保证准确性,因为它忽略了复杂的语法结构和语言特有的表达方式,可能导致错误或不连贯的译文。
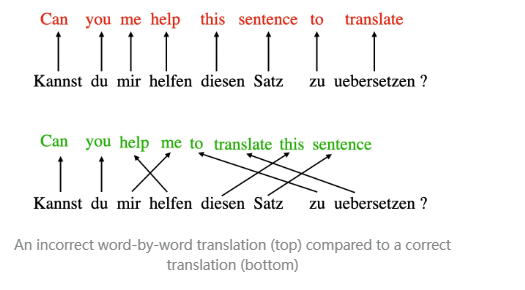
为了解决这一问题,研究者引入了注意力机制,使模型在处理每个词时都能参考整个句子的其他部分。关键在于如何选择最相关的单词,以确保上下文信息得到充分利用。2017 年,Transformer 架构提出了一种独立的自注意力机制,从而彻底摆脱了对 RNN 的依赖。
从本质上讲,自注意力是一种增强输入表示的方法,它能够结合上下文信息,提高模型对输入数据的理解能力。换句话说,自注意力使模型能够衡量输入序列中不同元素的重要性,并根据上下文动态调整它们对最终结果的影响。这一点在语言处理任务中尤为关键,因为一个词的含义往往取决于它在句子或文档中的具体位置。
因此,在本文中,我们将重点介绍最初的缩放点积注意力机制(即自注意力),因为它仍然是目前应用最广泛的注意力机制。如果你对其他类型的注意力机制感兴趣,可以参考 2020 年的 Efficient Transformers: A Survey、2023 年的 A Survey on Efficient Training of Transformers 综述文章,以及近期的 FlashAttention 和 FlashAttention-v2 论文。
输入句子的嵌入表示
首先,我们来看一个输入句子:“Life is short, eat dessert first”,并让它通过自注意力机制处理。与其他文本建模方法(如循环神经网络或卷积神经网络)类似,我们首先需要对句子进行嵌入 (Embedding)。
为了简化,我们仅使用输入句子中的单词构建词典 ( dc )。在实际应用中,通常会使用整个训练数据集中的所有单词作为词汇表,其规模通常在 30,000 到 50,000 之间。
#输入
sentence = 'Life is short, eat dessert first'
dc = {s:i for i,s
in enumerate(sorted(sentence.replace(',', '').split()))}
print(dc)
#输出
{'Life': 0, 'dessert': 1, 'eat': 2, 'first': 3, 'is': 4, 'short': 5}
接下来,我们使用这个词汇表为每个单词分配一个唯一的整数索引:
#输入
import torch
sentence_int = torch.tensor(
[dc[s] for s in sentence.replace(',', '').split()]
)
print(sentence_int)
#输出
tensor([0, 4, 5, 2, 1, 3])
现在,我们先将输入句子转换为整数向量,再通过嵌入层 (Embedding Layer) 将其映射为实数向量。在本例中,我们使用一个 3 维嵌入,因此每个单词都会被表示为一个 3 维向量。
需要注意的是,嵌入向量的维度通常在数百到数千之间。例如,Llama 2 的嵌入维度为 4,096。这里之所以使用 3 维嵌入,纯粹是为了演示,方便我们直观地查看每个向量,而不会让页面充满数字。
由于句子包含 6 个单词,因此最终的嵌入矩阵是一个 6x3 维的矩阵:
vocab_size = 50_000
torch.manual_seed(123)
embed = torch.nn.Embedding(vocab_size, 3)
embedded_sentence = embed(sentence_int).detach()
print(embedded_sentence)
print(embedded_sentence.shape)
权重矩阵的定义
现在,让我们讨论一种被广泛使用的自注意力机制——缩放点积注意力 (scaled dot-product attention),它是 Transformer 体系结构的核心组成部分。
在自注意力机制中,模型使用三个权重矩阵,分别称为 Wq、Wk 和 Wv,这些矩阵在训练过程中作为模型参数进行调整。它们的作用是将输入投影到序列的 查询 (query)、键 (key) 和值 (value)组件中。
具体来说,查询、键和值序列是通过矩阵乘法计算得到的,计算方式如下:
-
查询序列 (Query sequence): , 其中 i ∈ {1, 2, …, T}
-
键序列 (Key sequence): , 其中 i ∈ {1, 2, …, T}
-
值序列 (Value sequence): , 其中 i ∈ {1, 2, …, T}
其中,索引 i 表示输入序列中的 Token 位置,序列长度为 T。
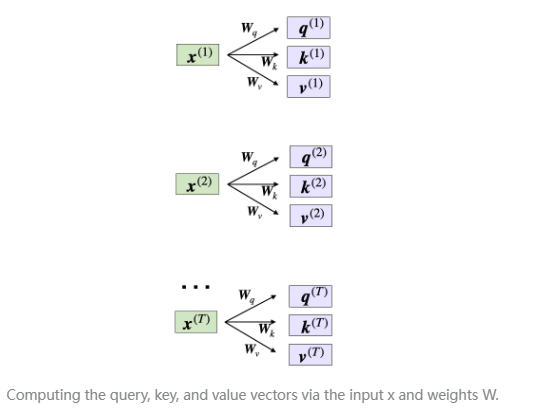
在这里, 和 均为 dk 维的向量。投影矩阵 和 的形状为 ,而 Wv 的形状为 。
(需要注意的是,d代表每个词向量 x 的维度。)
由于查询向量和键向量需要进行点积运算,它们必须具有相同的元素数量,即 。在许多大语言模型 (LLM) 中,我们通常设定值向量的大小与查询和键向量相同,因此 。不过,值向量 的元素数量可以是任意的,而它的大小决定了最终的上下文向量 (context vector) 的维度。
因此,在接下来的代码演示中,我们将设定 ,并使用 ,然后初始化投影矩阵,如下所示:
torch.manual_seed(123)
d = embedded_sentence.shape[1]
d_q, d_k, d_v = 2, 2, 4
W_query = torch.nn.Parameter(torch.rand(d, d_q))
W_key = torch.nn.Parameter(torch.rand(d, d_k))
W_value = torch.nn.Parameter(torch.rand(d, d_v))
计算未归一化的注意力权重
现在,我们希望计算第二个输入元素的注意力向量。在这里,我们将第二个输入元素作为查询 (query):
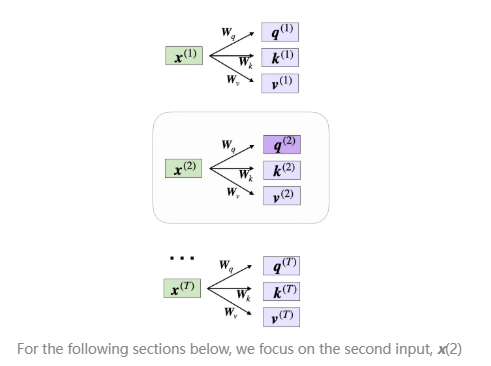
在代码中,这类似于以下方式:
x_2 = embedded_sentence[1]
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2.shape)
print(key_2.shape)
print(value_2.shape)
然后,我们可以将这一计算过程扩展到所有输入元素,以计算它们的键 (key) 和值 (value)。这些计算结果将在下一步计算未归一化的注意力权重时用到:
keys = embedded_sentence @ W_key
values = embedded_sentence @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)
在获取了所有必要的键和值后,我们可以进入下一步,计算未归一化的注意力权重 ω,如下图所示:
如上图所示,ω 是通过查询向量和键向量的点积计算得出的,即 ω。
例如,我们可以计算查询与第五个输入元素 (索引位置 4) 之间的未归一化注意力权重,具体如下:
omega_24 = query_2.dot(keys[4])
print(omega_24)
由于稍后计算实际注意力权重时需要使用 ω 值,因此我们先计算所有输入 Token 的 ω,如下图所示:
omega_2 = query_2 @ keys.T
print(omega_2)
计算注意力权重
在自注意力 (self-attention) 机制的下一步,我们需要对未归一化的注意力权重 ω进行归一化,以获得归一化后的注意力权重 ,具体操作是应用 softmax 函数。此外,在归一化之前,我们使用 进行缩放,以保证数值稳定性:
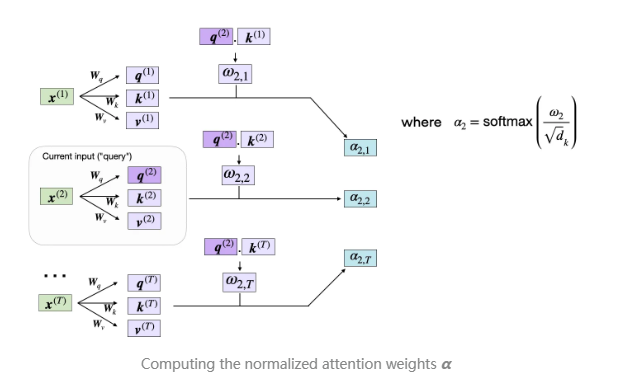
对ω进行 维度缩放的目的是确保权重向量的长度不会过大或过小。这一操作可以防止数值不稳定性,并提高模型在训练过程中的收敛性。
在代码实现中,我们可以按如下方式计算注意力权重:
import torch.nn.functional as F
attention_weights_2 = F.softmax(omega_2 / d_k**0.5, dim=0)
print(attention_weights_2)
最后一步是计算上下文向量 ,它是基于注意力权重对原始查询输入 进行加权的结果,并结合了所有其他输入元素的信息:
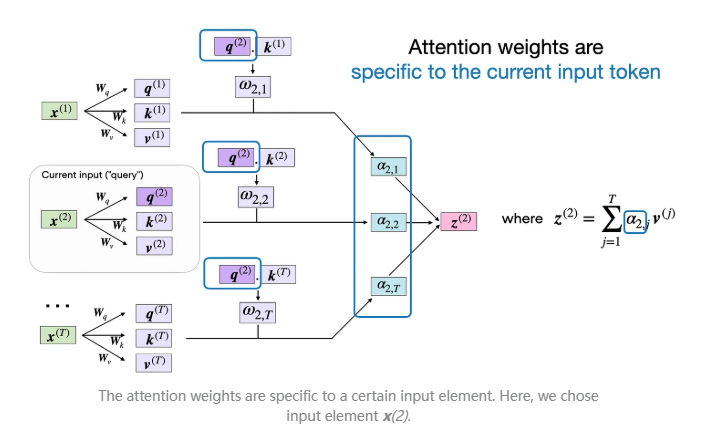
在代码中,这看起来如下:
context_vector_2 = attention_weights_2 @ values
print(context_vector_2.shape)
print(context_vector_2)
需要注意的是,该输出向量的维度 大于原始输入向量的维度 ,这是因为我们在之前设定了;然而, 的选择是任意的,并不影响核心机制。
自注意力 (Self-Attention)
为了总结前面各部分的代码实现,我们可以将自注意力机制的代码封装成一个紧凑的 SelfAttention 类:
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attn_scores = queries @ keys.T # unnormalized attention weights
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1
)
context_vec = attn_weights @ values
return context_vec
在 PyTorch 规范下,该 SelfAttention 类在 __init__ 方法中初始化自注意力参数,并在 forward 方法中计算所有输入的注意力权重及上下文向量。在实际应用中,我们可以这样使用该类:
torch.manual_seed(123)
# reduce d_out_v from 4 to 1, because we have 4 heads
d_in, d_out_kq, d_out_v = 3, 2, 4
sa = SelfAttention(d_in, d_out_kq, d_out_v)
print(sa(embedded_sentence))
多头注意力 (Multi-Head Attention)
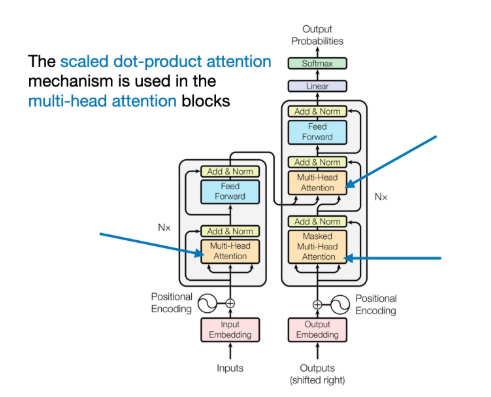
在本篇文章的第一张图(现再次展示以便参考)中,我们看到 Transformer 使用了一个名为 多头注意力 (multi-head attention) 的模块。
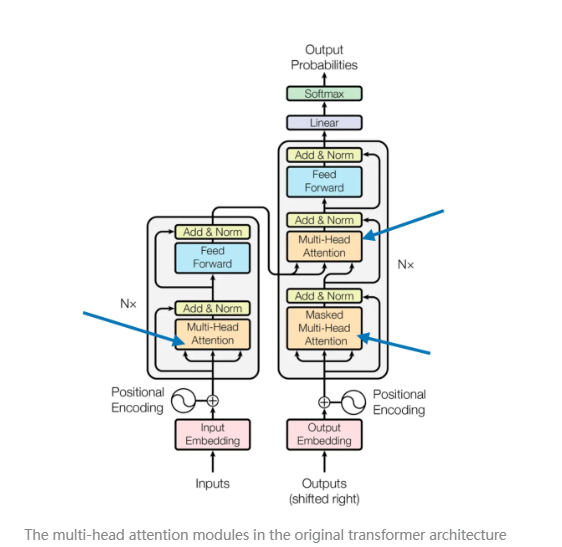
那么,这种 “多头” 注意力 与我们前面介绍的 自注意力机制(缩放点积注意力,scaled dot-product attention) 之间有什么联系呢?
在 缩放点积注意力 (scaled dot-product attention) 机制中,我们使用三个投影矩阵来计算查询 (query)、键 (key) 和值 (value)。在 多头注意力 的背景下,这三组矩阵可以看作是一个**注意力头 (attention head)**。下图总结了我们前面实现的单个注意力头:
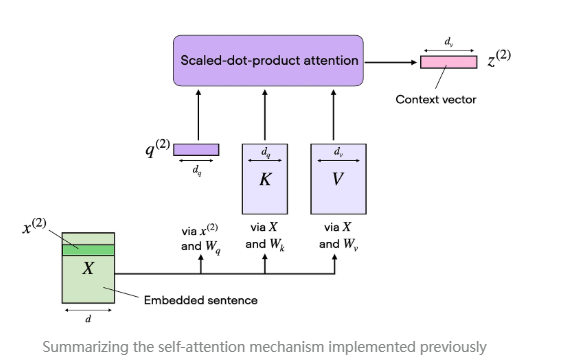
顾名思义,多头注意力 由多个这样的注意力头组成,每个头都具有独立的查询、键和值矩阵。这一概念类似于卷积神经网络 (CNN) 中的多核 (multiple kernels),每个核都会生成不同的特征映射,从而形成多个输出通道。
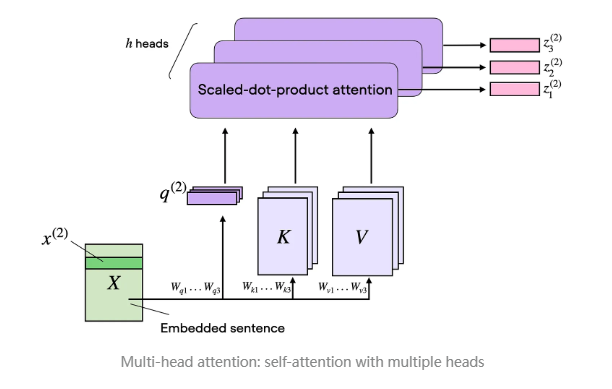
为了在代码中实现 多头注意力 (Multi-Head Attention),我们可以基于前面定义的 SelfAttention 类,封装一个 MultiHeadAttentionWrapper 类,如下所示:
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v, num_heads):
super().__init__()
self.heads = nn.ModuleList(
[SelfAttention(d_in, d_out_kq, d_out_v)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)
交叉注意力(Cross-Attention)
在上面的代码讲解中,我们设置了 ![]() 和
和![]() 。换句话说,我们为查询和键序列使用了相同的维度。虽然值矩阵
。换句话说,我们为查询和键序列使用了相同的维度。虽然值矩阵 ![]() 通常与查询和键矩阵具有相同的维度(例如在 PyTorch 的 MultiHeadAttention 类中),但我们可以为值矩阵选择任意的维度大小。
通常与查询和键矩阵具有相同的维度(例如在 PyTorch 的 MultiHeadAttention 类中),但我们可以为值矩阵选择任意的维度大小。
由于维度较难跟踪,我们在下图中总结了迄今为止的内容,该图展示了单个注意力头的不同张量尺寸。
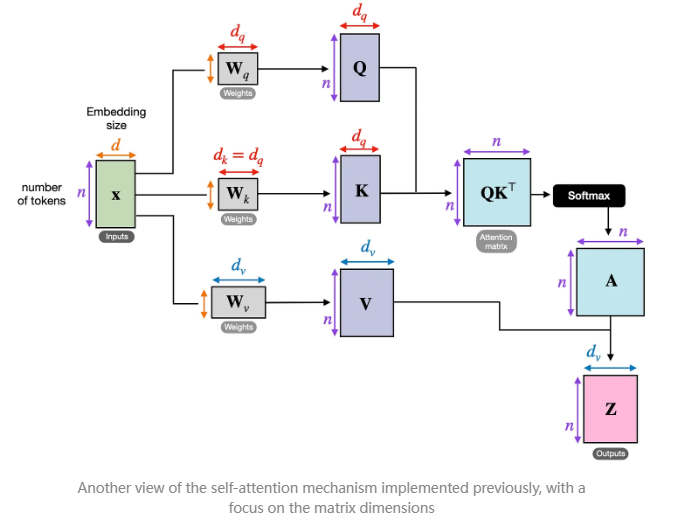
这张图展示了自注意力机制的实现,接下来我们要讨论的是自注意力的变体——交叉注意力。
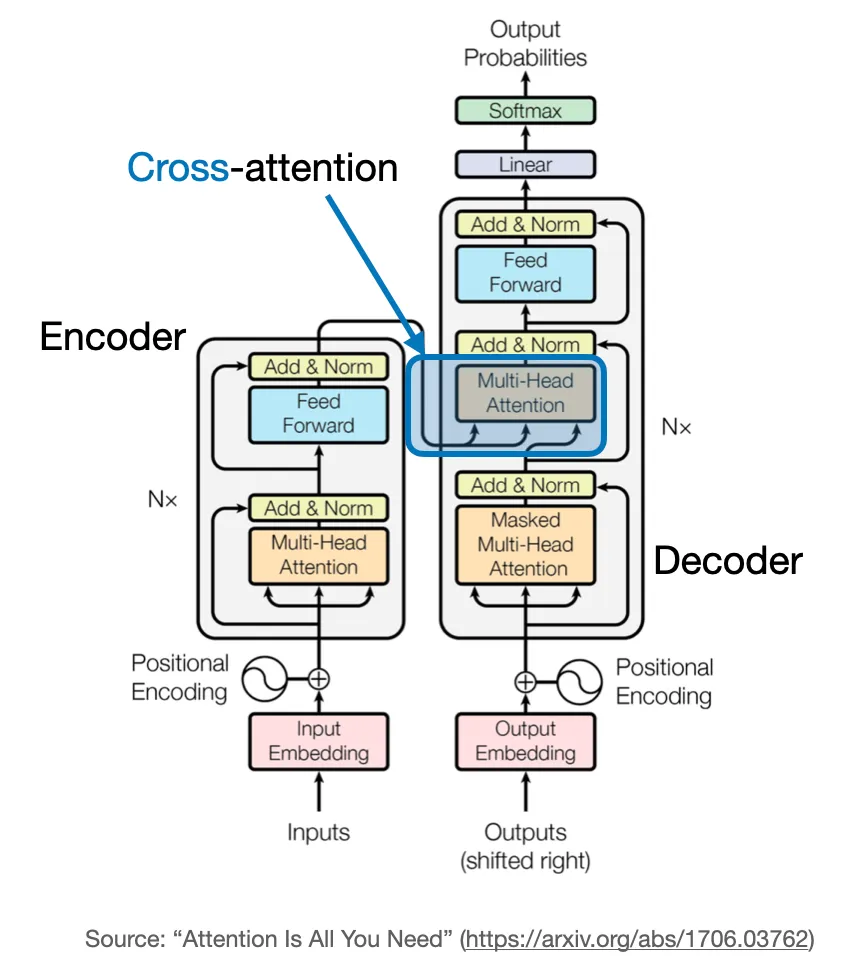
什么是交叉注意力,它与自注意力有何不同?
在自注意力中,我们处理的是相同的输入序列。而在交叉注意力中,我们将两个不同的输入序列进行混合或结合。以原始 Transformer 架构为例,交叉注意力涉及到编码器模块(位于左侧)返回的序列和解码器部分(位于右侧)正在处理的输入序列。
需要注意的是,交叉注意力中的两个输入序列 ![]() 和
和![]() 可以包含不同数量的元素,但它们的嵌入维度必须相同。
可以包含不同数量的元素,但它们的嵌入维度必须相同。
下图展示了交叉注意力的概念。如果我们将 ![]() 和
和 ![]() 设为相等,这就等同于自注意力。
设为相等,这就等同于自注意力。
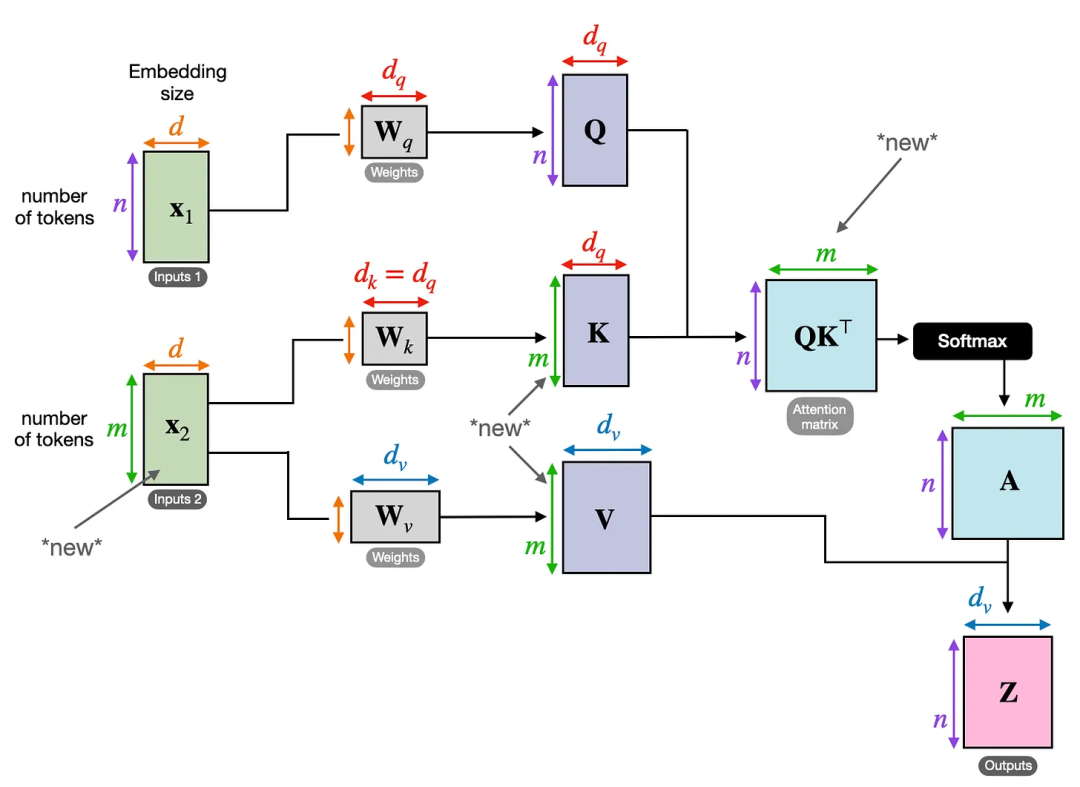
那么,在代码中如何实现交叉注意力呢?我们将基于之前在自注意力部分实现的 SelfAttention 类进行修改,主要做些小的调整:
class CrossAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x_1, x_2): # x_2 is new
queries_1 = x_1 @ self.W_query
keys_2 = x_2 @ self.W_key # new
values_2 = x_2 @ self.W_value # new
attn_scores = queries_1 @ keys_2.T # new
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1)
context_vec = attn_weights @ values_2
return context_vec
因果自注意力 (Causal Self-Attention)
在本节中,我们将前面讨论的自注意力机制转换为因果自注意力机制,特别是针对类似 GPT(解码器风格)的大语言模型(LLM),这些模型用于生成文本。因果自注意力机制也常被称为“掩蔽自注意力”。在原始 Transformer 架构中,它对应于“掩蔽多头注意力”模块——为了简化,我们将只讨论单个注意力头,但相同的概念也适用于多个注意力头。
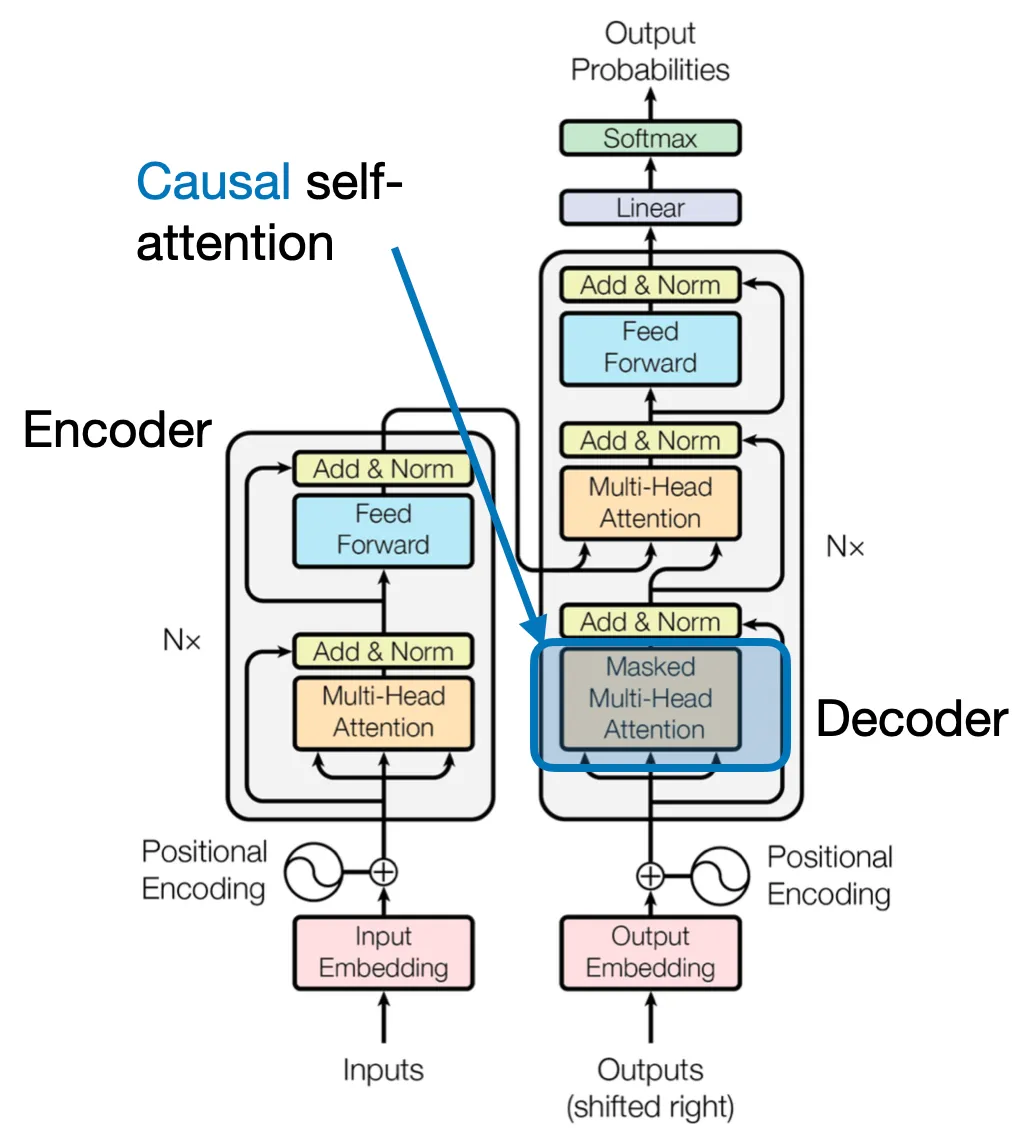
因果自注意力确保序列中某个位置的输出仅基于前面位置的已知输出,而不会依赖于后续位置的输出。简而言之,它确保每个下一个单词的预测仅依赖于之前的单词。为了在类似 GPT 的大语言模型中实现这一点,我们在处理每个 token 时,会掩蔽掉当前 token 后面的所有未来 token。
应用因果掩蔽于注意力权重的操作如下图所示,用于隐藏输入中的未来 token。
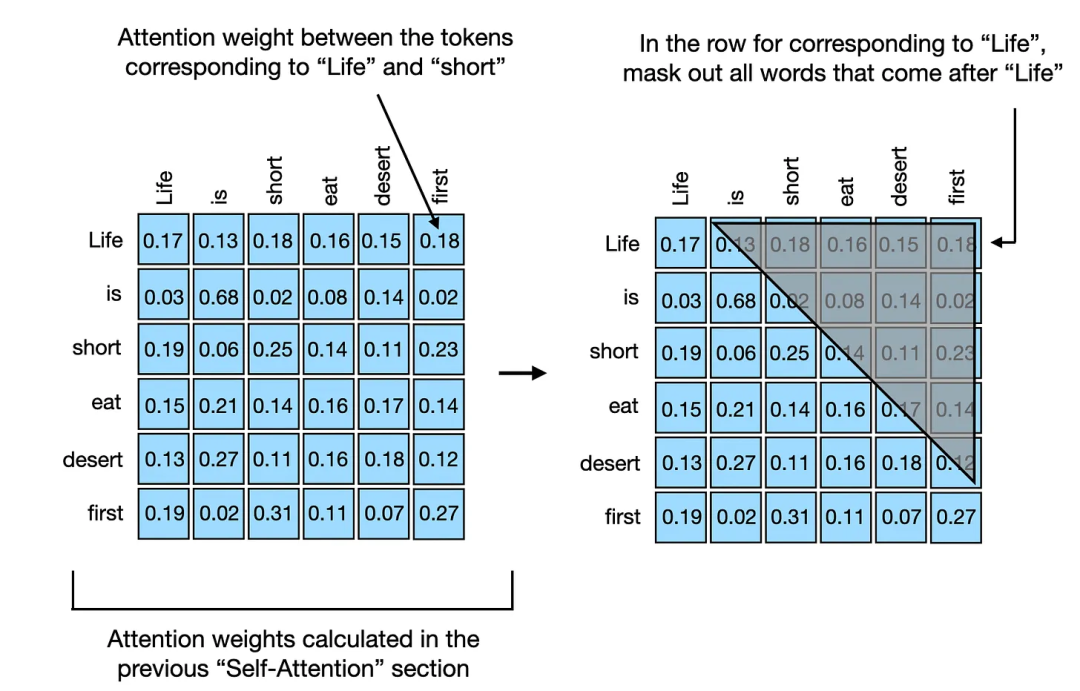
在类似 GPT 的大语言模型中,我们训练模型一次读取并生成一个 token(或单词),从左到右。如果我们有一个训练文本样本,如“Life is short eat desert first”,我们可以将其分解为如下结构,箭头右侧的单词上下文向量应该仅包括它自己和前面的单词:
"Life" → "is"
"Life is" → "short"
"Life is short" → "eat"
"Life is short eat" → "desert"
"Life is short eat desert" → "first"
要实现这一设置,最简单的方法是对注意力权重矩阵的上三角部分应用掩蔽,掩蔽掉所有未来的 token,如下图所示。这样,在创建上下文向量时,"未来"单词将不会被包含在内,上下文向量是通过对输入的注意力加权和计算得出的。
在代码中,我们可以通过 PyTorch 的 tril 函数来实现这一点,首先使用它创建一个 1 和 0 的掩蔽矩阵:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
W_value = nn.Parameter(torch.rand(d_in, d_out_v))
x = embedded_sentence
keys = x @ W_key
queries = x @ W_query
values = x @ W_value
# attn_scores are the "omegas",
# the unnormalized attention weights
attn_scores = queries @ keys.T
print(attn_scores)
print(attn_scores.shape)
attn_weights = torch.softmax(attn_scores / d_out_kq**0.5, dim=1)
print(attn_weights)
block_size = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(block_size, block_size))
print(mask_simple)
masked_simple = attn_weights*mask_simple
print(masked_simple)
row_sums = masked_simple.sum(dim=1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
print(masked_simple_norm)
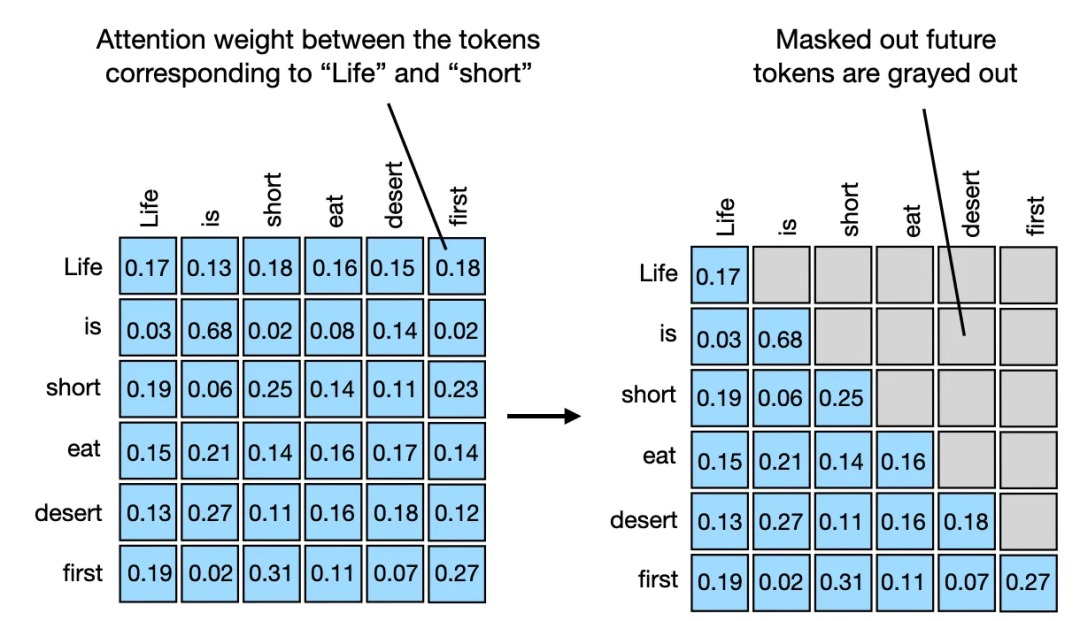
更高效的掩蔽方法,无需重新归一化
有一种更高效的方法可以实现相同的结果。在这种方法中,我们首先计算注意力分数,并在输入到 softmax 函数之前,将对角线以上的值替换为负无穷大。这个过程如下面的图所示:

我们可以通过 PyTorch 实现这个过程,首先掩蔽对角线以上的注意力分数:
mask = torch.triu(torch.ones(block_size, block_size), diagonal=1)
masked = attn_scores.masked_fill(mask.bool(), -torch.inf)
print(masked)
attn_weights = torch.softmax(masked / d_out_kq**0.5, dim=1)
print(attn_weights)
上述代码首先创建了一个掩蔽矩阵,矩阵对角线以下部分为 0,对角线以上部分为 1。torch.triu(上三角)保留矩阵的主对角线及其上方的元素,其他部分置为 0,从而保留矩阵的上三角部分;而 torch.tril(下三角)则保留主对角线及其下方的元素。
为什么这样做有效呢?在最后一步,softmax 函数将输入值转化为概率分布。当输入中有 -inf 时,softmax 会把它视为零概率。这是因为 近似为 0,因此这些位置对最终的输出概率没有任何贡献。
总结
在本文中,我们通过逐步编码的方式,探讨了自注意力机制的内部原理。在此基础上,我们进一步研究了多头注意力,它是大语言模型 Transformer 的核心组件。
接着,我们实现了交叉注意力,这是一种自注意力变体,特别适用于两个不同序列之间的应用。最后,我们编写了因果自注意力,这是生成连贯且上下文相关的序列时,在解码器风格的大语言模型(如 GPT 和 Llama)中至关重要的概念。
更多推荐
 22
22 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)