
常见GPU算力(4090&4090D,AD102-300&AD102-250)
支持的数据类型有 FP8、FP16、BF16、TF32、INT8、INT4,不支持 FP64。启用稀疏计算(2:4 模式)加速后,在神经网络权重中,强制每 4 个连续元素中至少 2 个为零,Tensor Core 硬件自动跳过零值计算,有效吞吐量翻倍。注意到,完整 AD102 核心有 12 组 GPC,每组 GPC 包含 6 组 TPC,单个 TPC 中含有两个 SM 单元,因此完整 AD102
一、硬件参数
| 4090 | 4090D | |
| 核心 | AD102-300 | AD102-250 |
| 架构 | Ada Lovelace | Ada Lovelace |
| SM | 128 | 114 |
| CUDA Cores / SM | 128 | 128 |
| CUDA Cores / GPU | 16384 | 14592 |
| Tensor Cores / SM | 4 (4th Gen) | 4 (4th Gen) |
| Tensor Cores / GPU | 512 (4th Gen) | 456 (4th Gen) |
| GPU 加速频率 | 2520 MHz | 2520 MHz |
| 显存 | 24 GB (GDDR6X) | 24 GB (GDDR6X) |
| 显存位宽 | 384 bit | 384 bit |
| 显存速率 | 21 Gbps | 21 Gbps |
| 显存带宽 | 1008 GBps | 1008 GBps |
| 一缓 | 128 KB (per SM) | 128 KB (per SM) |
| 二缓 | 72 MB | 72 MB |
| TGP | 450 W | 425 W |
| 制程 | TSMC 4N (5nm) | TSMC 4N (5nm) |
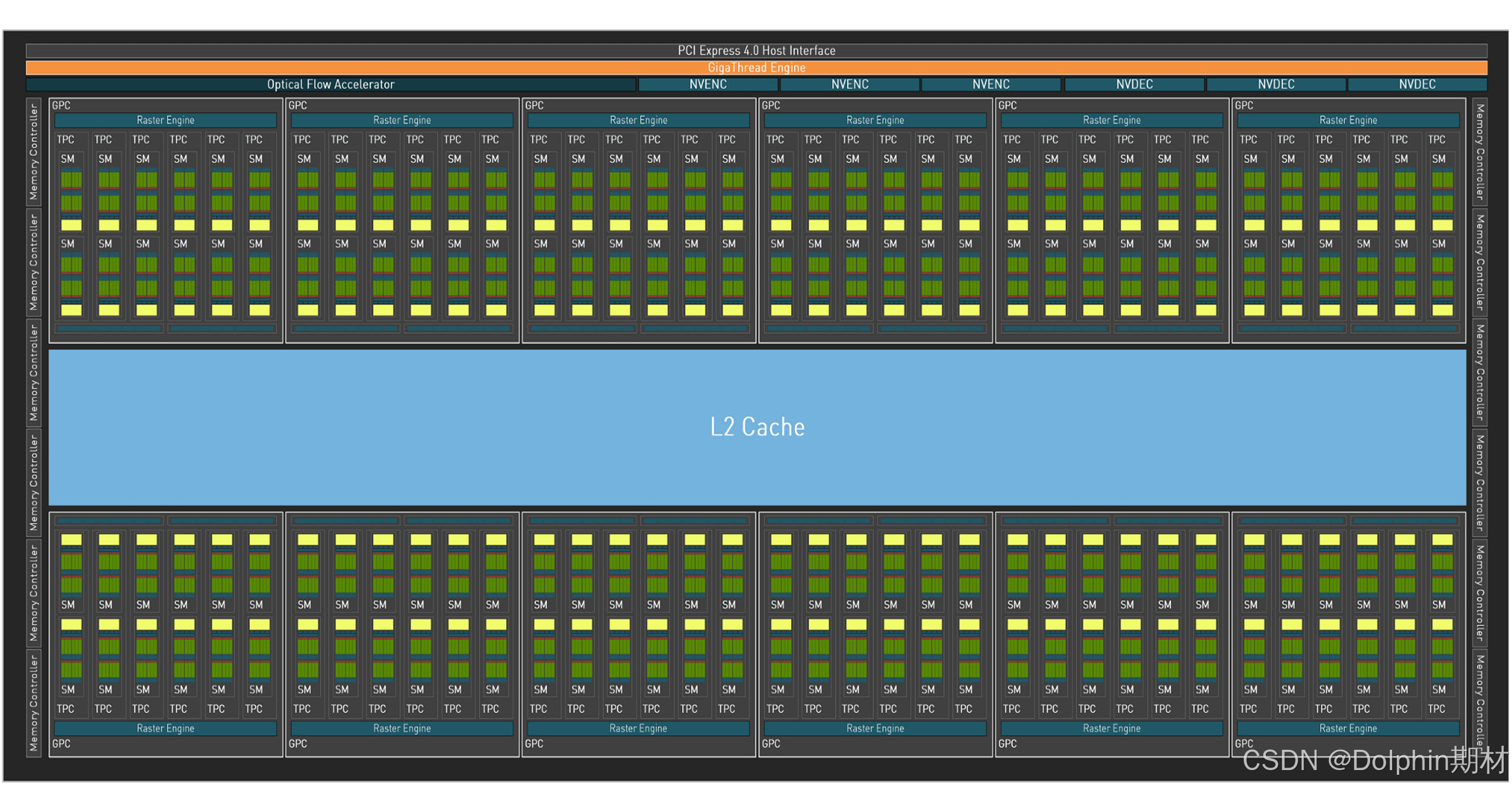
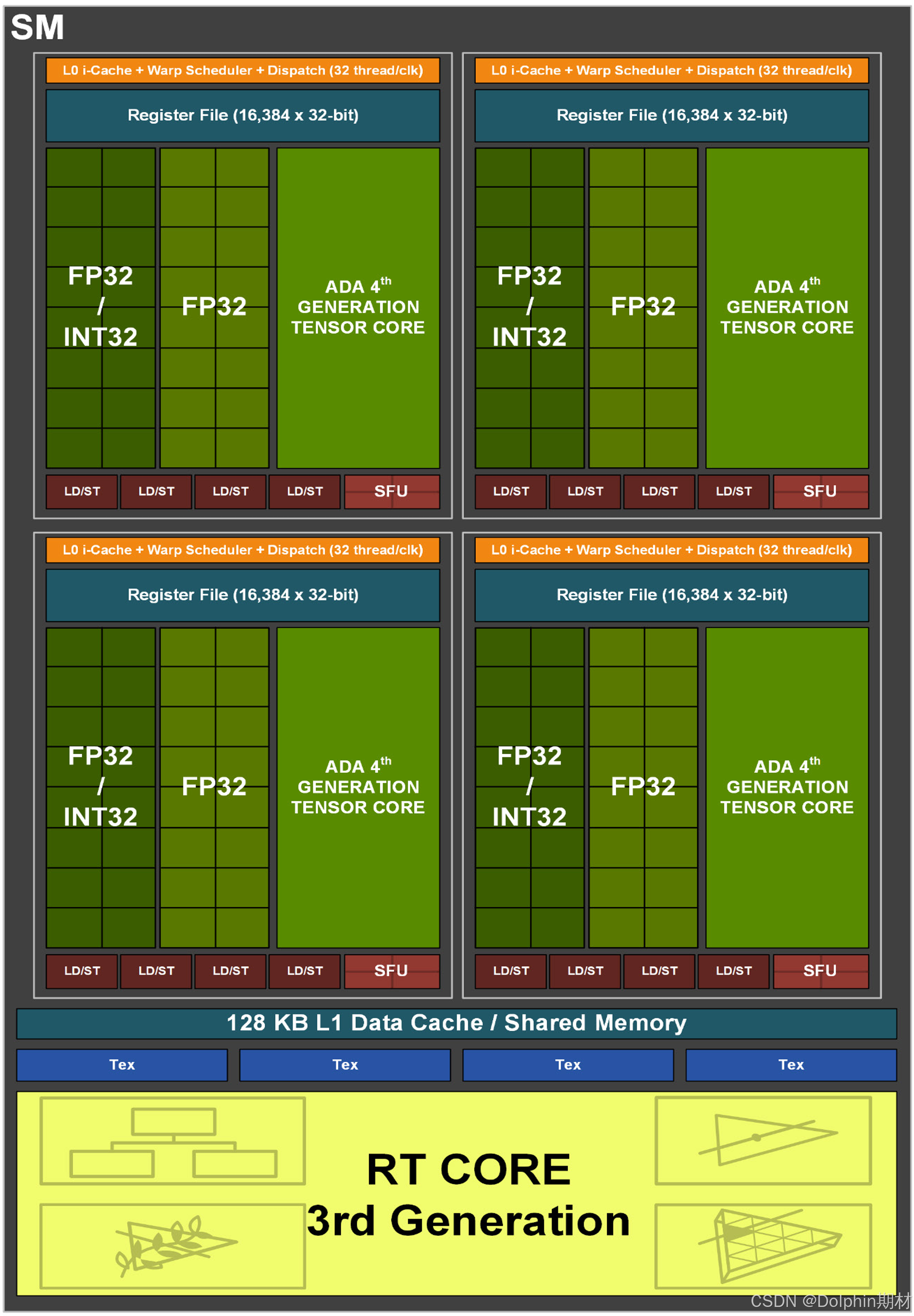
注意到,完整 AD102 核心有 12 组 GPC,每组 GPC 包含 6 组 TPC,单个 TPC 中含有两个 SM 单元,因此完整 AD102 核心共有 144 个 SM 单元,但 AD102-300 只开启其中的 128 个,AD102-250 只开启其中的 114 个。每个 SM 单元中有 128 个 CUDA 计算单元,其中 64 个 CUDA 可以计算 FP32 或 INT32,另外 64 个只能计算 INT32。
每个 SM 单元中有 4 个 Tensor Core,因此 AD102-300 总共含有 512 个 Tensor Core,AD102-250 总共含有 456 个 Tensor Core。支持的数据类型有 FP8、FP16、BF16、TF32、INT8、INT4,不支持 FP64。对于 FP16 数据,每个 Tensor Core 每周期可以完成 64 次 FMA(乘加)操作,因 FMA 算作两次浮点运算,所以相当于 128 个 FP16 FLOPs;对于 INT8 数据,每个 Tensor Core 每周期能完成 128 次运算;对于 INT4 数据,每周期则能完成 256 次运算。启用稀疏计算(2:4 模式)加速后,在神经网络权重中,强制每 4 个连续元素中至少 2 个为零,Tensor Core 硬件自动跳过零值计算,有效吞吐量翻倍。
二、算力
1、CUDA Core 算力
浮点:TFLOPS
整型:TIOPS
| 4090 | 4090D | |
| FP32 | 82.6 | 73.5 |
| FP16 | 82.6 | 73.5 |
| FP64 | 1.29 | 1.149 |
| BF16 | 82.6 | 73.5 |
| INT32 | 41.3 | 36.8 |
2、Tensor Core 算力
浮点:TFLOPS
整型:TIOPS
稠密/稀疏
| 4090 | 4090D | |
| FP8 | 660.6 / 1321.2 | 588.4 / 1176.8 |
| FP16 | 330.3 / 660.6 | 294.2 / 588.4 |
| BF16 | 165.2 / 330.4 | 147.1 / 294.2 |
| TF32 | 82.6 / 165.2 | 73.5 / 147.1 |
| INT8 | 660.6 / 1321.2 | 588.4 / 1176.8 |
| INT4 | 1321.2 / 2642.4 | 1176.8 / 2353.6 |
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)