
【深度强化学习】DQN与倒立摆控制问题实战(图文解释 附源码)
【深度强化学习】DQN与倒立摆控制问题实战(图文解释 附源码)
·
需要源码请点赞关注收藏后评论区留言私信~~~
神经网络来逼近值函数三种形式
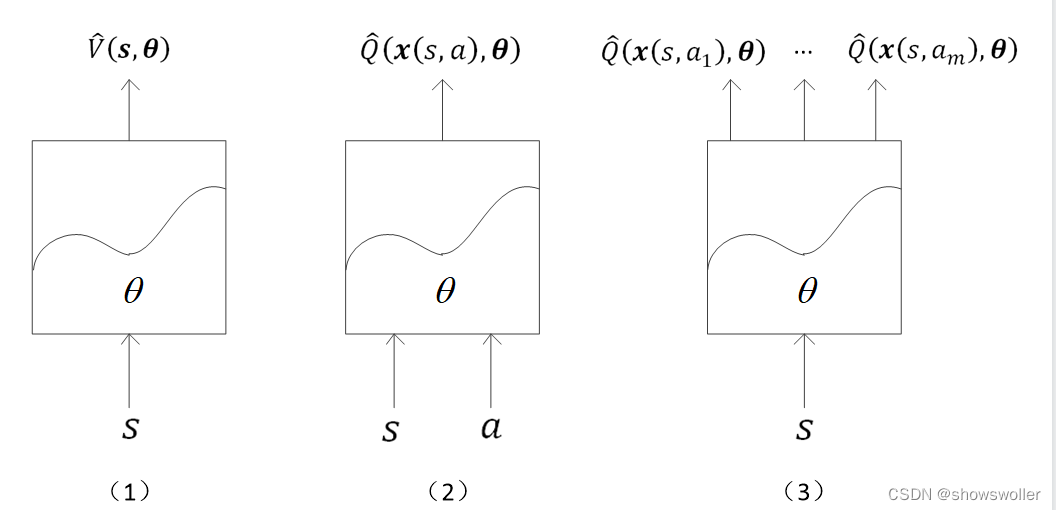
DQN
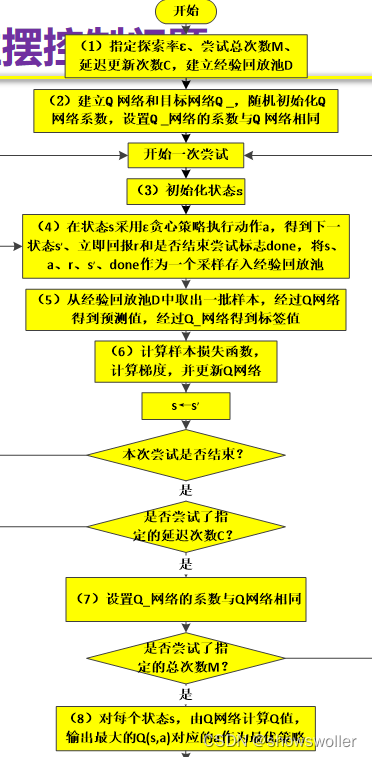
在Q-Learning算法的基础上:
1、用深度神经网络Q来逼近值函数。
2、经验回放是将每步采样都保存起来,用来成批训练Q网络。
3、目标网络Q_进一步降低样本之间的关联性。
算法流程图如下
倒立摆问题
倒立摆控制是控制系统理论教学中的典型物理模型,它也是学习强化学习的一个经典的基础实验。
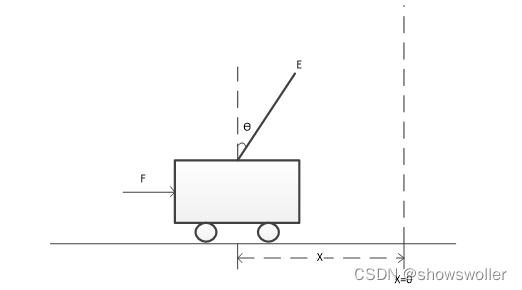
主体只能对小车施加向左或向右的大小为10N的力F。主体能够观察到4项环境状态,分别是小车的位置,小车速度,标偏离垂直线的角度,杆顶的速度。在某一步动作之后,如果杆还没倒下,主体就能得到一个值为1的回报,否则就会得到一个值为0的回报。
先看一个不对小车进行有意控制的实验
示意图如下 输入结果如下 在实验的过程中,通过图像可以实时看到小车以及杆的受控运动情况,显然采用完全随机的策略并没有实际意义
下面采用DQN算法来优化对小车进行控制的策略,从而实现较大累计回报,也就是使得小车坚持较多的步数不倒下
结果如下

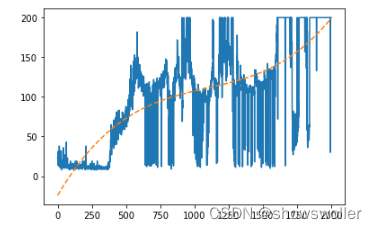
上图把每次得分都画了出来,可以看到在足够多次尝试的学习之后,最近十次尝试的平均得分已经有明显提高
部分代码如下
def DQN(env, M=2000, learning_rate=0.0002, epsilon=1.0, gamma=0.99):
# M = 2000 # 尝试次数
# learning_rate = 0.0002 # 优化器步长
# epsilon=1.0 # ε贪心策略中的ε
# gamma = 0.99 # 折扣系数
D = ReplayMemory( N=N_of_D, size_batch=size_batch ) # 经验回放池
q = Q_net() # 预测网络,Q网络
q.build(input_shape=(2, 4))
q_ = Q_net() # 目标网络
q_.build(input_shape=(2, 4))
for sv, dv in zip(q.variables, q_.variables):
dv.assign(sv) # 将目标网络系数设置为预测网络系数
C = 10 # C次采样后,更新目标网络为预测网络
score = 0.0
optimizer = optimizers.Adam(lr=learning_rate)
for i in range(M): # 训练次数
# 逐步减小ε
epsilon = update_epsilon( epsilon, epsilon_decay, epsilon_min )
s = env.reset()
episode_score = 0.0
for t in range(600): # 开始尝试,每次尝试最多走600步
a = q.epsilon_greedy_sample(s, epsilon)
next_s, r, done, _ = env.step(a)
D.push((s, a, r, next_s, done)) # 样本存入经验回放池
s = next_s # 更新状态
episode_score += r
if done: # 尝试结束
score += episode_score # 记录最近C次的总回报
episode_score_list.append(episode_score)
episode_score = 0.0
break
if D.size() > 500: # 开始更新Q网络
huber = losses.Huber()
# 从经验回放池中随机提取一批训练样本,并转换成Tensor
s_list, a_list, r_list, next_s_list, done_list = D.sample()
s_ = tf.constant(s_list, dtype=tf.float32)
a_ = tf.constant(a_list, dtype=tf.int32)
r_ = tf.constant(r_list, dtype=tf.float32)
next_s_ = tf.constant(next_s_list, dtype=tf.float32)
done_ = tf.constant(done_list, dtype=tf.float32)
with tf.GradientTape() as tape:
q_predict = q(s_) # 得到预测值Q(s_,*)
# 因为是第三种形式的网络,所以要从Q(s_,*)取对应动作的输出Q值
indices = tf.expand_dims(tf.range(a_.shape[0]), axis=1) # reshape
indices = tf.concat([indices, a_], axis=1) # 对应的动作
q_a = tf.gather_nd(q_predict, indices) # 对应动作的Q预测值
q_a = tf.expand_dims(q_a, axis=1) # reshape
# 从目标网络求下一状态s'的最大Q值,并计算样本的标签值
max_next_q = tf.reduce_max(q_(next_s_),axis=1,keepdims=True)
labels = r_ + gamma * max_next_q * (1-done_) # done_等1,说明是最终状态
# 计算预测值与标签值的误差
loss = huber(q_a, labels)
# 计算梯度,并优化网络
grads = tape.gradient(loss, q.trainable_variables)
optimizer.apply_gradients(zip(grads, q.trainable_variables))
# C次采样后,更新目标网络为预测网络,并输出中间信息
if (i+1) % C == 0:
for sv, dv in zip(q.variables, q_.variables):
dv.assign(sv) # 将目标网络系数设置为预测网络系数
print("尝试次数:{}, 最近{}次平均得分:{:.1f}, 经验回放池大小:{}, ε:{:.3f}" \
.format(i+1, C, score / C, D.size(), epsilon ))
score = 0.0
class Q_net(keras.Model):
def __init__(self, Q_net_structure=[128, 128, 2]):
# 创建Q网络
super(Q_net, self).__init__()
self.Q_net_structure = Q_net_structure
self.fc = []
self.n_actions = Q_net_structure[-1]
for i in range(len(self.Q_net_structure)):
self.fc.append( layers.Dense(self.Q_net_structure[i]) )
# 重写父类函数,实现前向输出
def call(self, x, training=None):
for i in range(len(self.Q_net_structure)-1):
x = tf.nn.relu(self.fc[i](x))
x = self.fc[ len(self.Q_net_structure)-1 ](x)
return x
# 基于ε-gredy贪心策略,根据当前状态s的所有动作值函数,采样输出动作值
def epsilon_greedy_sample(self, s, epsilon):
rand = random.random()
if rand < epsilon: # 探索
return random.randint(0, self.n_actions-1)
else: # 利用,将s经过网络前向预测,得到输出
s = tf.constant(s, dtype=tf.float32) # 转换成Tensor
s = tf.expand_dims(s, axis=0)
out = self(s)[0] # 前向预测
return int(tf.argmax(out))
import matplotlib.pyplot as plt
def plot_score(episode_score_list):
plt.plot(episode_score_list)
x = np.array(range(len(episode_score_list)))
smooth_func = np.poly1d(np.polyfit(x, episode_score_list, 3))
plt.plot(x, smooth_func(x), label='Mean', linestyle='--')
plt.show()
创作不易 觉得有帮助请点赞关注收藏~~~
更多推荐


 31
31 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)