
CUDA专家手册+gpu变成权威指南 笔记(一)
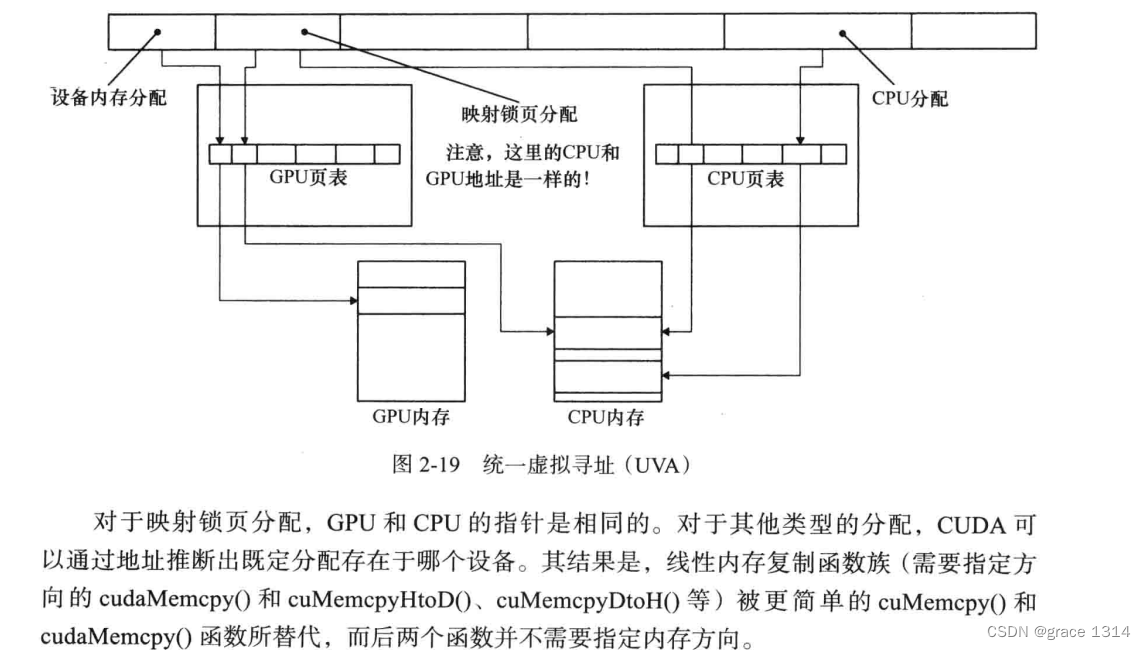
CUDA中用于映射锁页内存(mapped pinned memory)的API,把分配的主机内存映射到CUDA内核的地址空间,使得他们能够直接被访问,称作零复制,因为内存是共享的,复制操作不需要通过总线。事实上,在传输受限型的工作量上,一个集成的GPU可以超过一个更大的独立GPU。虚拟寻址,虚拟地址空间,为物理内存一个一个分配连续编号,以便进行访问,比如0~64kb内存位置是0~65535,指定内
1.硬件架构
CPU与CPU内存
GPU与GPU内存
(CPU与GPU通过PCIe连接)
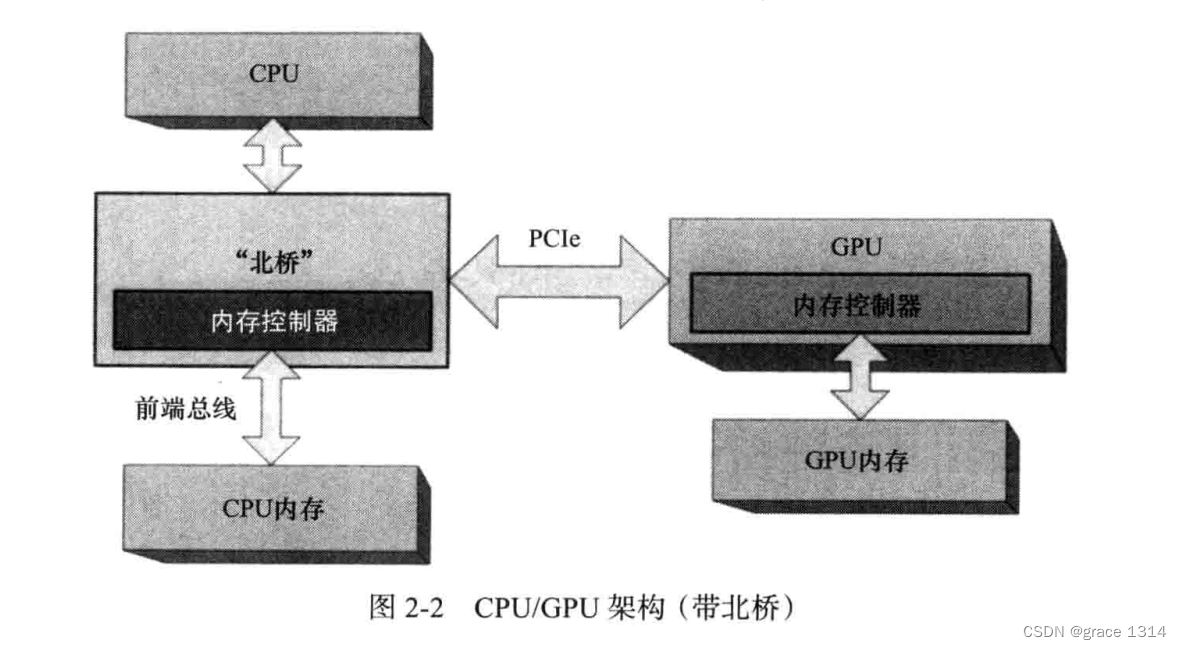
芯片组/核心逻辑:主要分为南桥和北桥。
南桥:连接外围设备和系统(芯片输入输入,外界输入输出)
北桥:包含图形总线(加速图形接口,后背PCIe接口取代)和内存控制器
其中PCIe(peripheral communications interconnect express ,外围通信互连快车)带宽很高,而GPU需要频台所有外设的最大带宽,所以一般倍插入由16通道构成的PCIe插槽。
GPU PCIe接口带宽通常指的是图形处理单元(GPU)与计算机主板之间通过PCI Express(PCIe)接口传输数据的能力。PCIe接口带宽通常以每秒传输的数据量来衡量,单位是GB/s(千兆字节每秒)。
PCIe接口的版本和通道数量是影响带宽的关键因素。目前,PCIe的版本有1.0、2.0、3.0、4.0和5.0。每个版本都有不同的理论最大传输速率。例如,PCIe 3.0的理论最大传输速率是8 GT/s(千兆传输每秒),而PCIe 4.0则是16 GT/s。
通道数量也是决定带宽的重要因素。PCIe接口通常有x1、x4、x8和x16等不同的物理大小,表示数据可以通过的通道数量。带宽可以通过将PCIe版本的理论最大传输速率与通道数量相乘来计算。
GT/s通常指的是“千兆传输每秒”(gigatransfers per second)。这是用于衡量计算机总线或其他数据传输通道速度的单位。通常用于描述处理器、内存和其他组件之间的数据传输速率。 GT/s的值越高,表示数据传输速度越快。
前端总线:
多核处理器:即具有多个CPU核心。多个CPU可以一致访问CPU内存称作一致内存访问。、
非一致内存访问(NUMA),每个CPU核心都有自己的内存,虽然当前CPU也可以访问其他CPU核心的内存,但容易出问题。
而对于CUDA程序,GPU的非本地内存复制操作对性能的影响有可能更为要命。
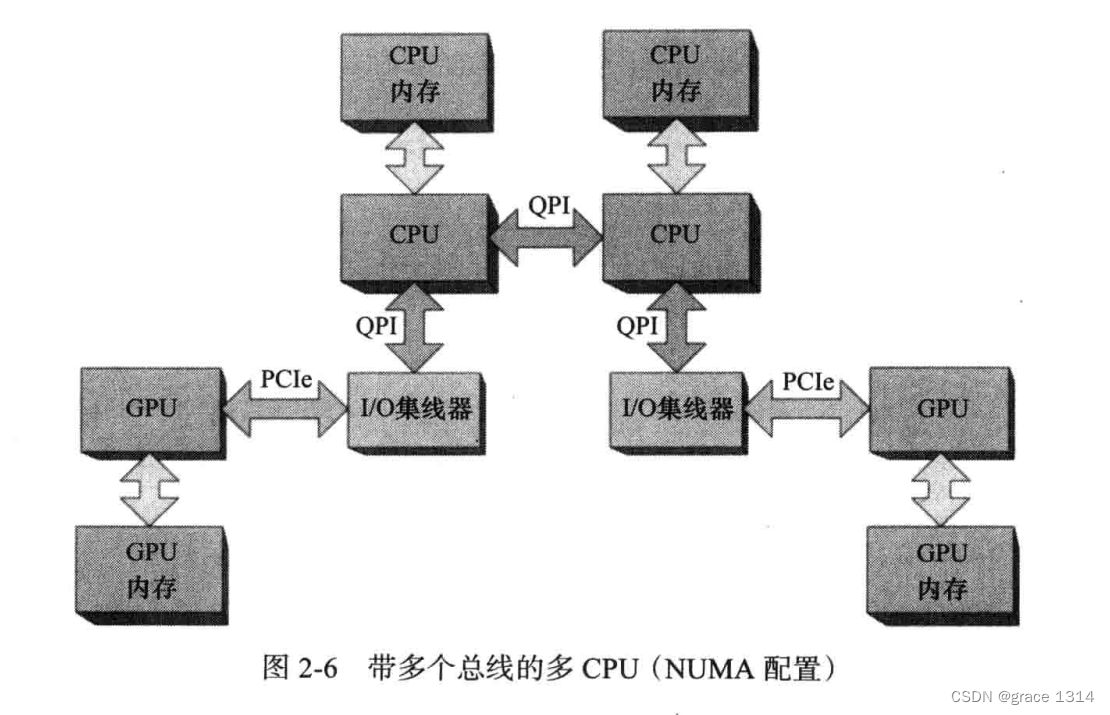
CPU上集成的PCIe,即I/O集线器,通道可多达40个,而一个GPU最多16个,这样虽然一个CPU可以访问两个GPU,但是对于多个CPU的访问就无法实现点对点操作。
集成GPU,将GPU集成到芯片组与北桥在一块。
CUDA中用于映射锁页内存(mapped pinned memory)的API,把分配的主机内存映射到CUDA内核的地址空间,使得他们能够直接被访问,称作零复制,因为内存是共享的,复制操作不需要通过总线。事实上,在传输受限型的工作量上,一个集成的GPU可以超过一个更大的独立GPU。
多GPU板,具有桥接芯片的GPU之间是可以通过PCIe交换信息,但并不能共享内存资源。
CUDA中的地址空间
CPU与GPU的地址空间是分开的,CPU不能读写GPU设备内存,同理GPU也无法读写CPU内存。
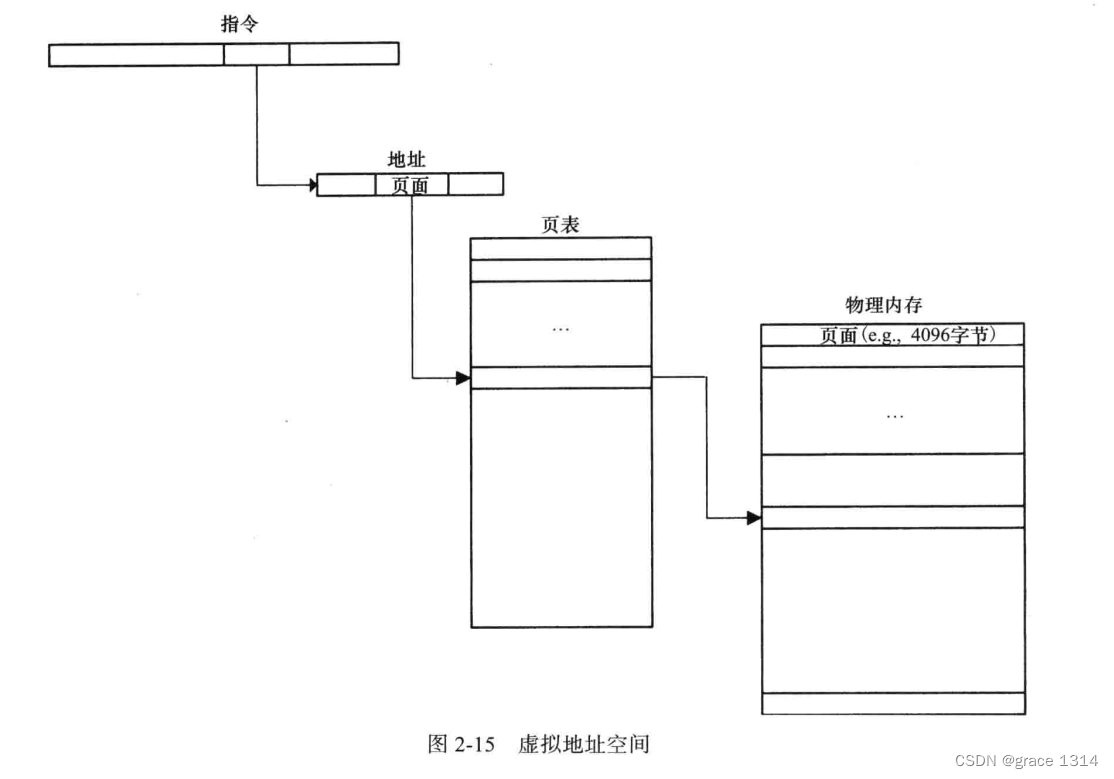
虚拟寻址,虚拟地址空间,为物理内存一个一个分配连续编号,以便进行访问,比如0~64kb内存位置是0~65535,指定内存位置的16位值成为地址,地址的计算和相应内存位置上的操作过程统称为寻址。
现代一个程序或者每个进程都有自己的地址空间,未经操作系统特别许可,它们不能读取或写入属于其他进程的内存。机器指令使用虚拟地址而不是物理地址,随后由操作系统执行一系列查找表的操作,将其翻译为一个物理地址。
在大多数系统中,虚拟地址空间被划分成许多页,他们是寻址的单位,大小至少4096字节。通常硬件查找指定页内存的页表项(PTE)来得到所在物理地址,而不直接引用物理内存的地址。
虚拟寻址可以是一个连续的虚拟地址空间映射到物理内存并不连续的一些页。当程序读写页面违背映射的物理内存的内存位置时,硬件会发送必须由操作系统处理的错误信号。
不相交的地址空间
CUDA也使用虚拟地址空间,GPU执行内存保护,CUDA程序不可以随机地读取或破坏其他CUDA程序地内存,也不可以访问还没有被内核模型驱动程序映射地内存。CUDA分配地没亿字节虚拟内存都必须对应一个字节的物理内存。
每个GPU有自己的内存和地址转换硬条件,GPU的地址空间和CUDA应用程序中的CPU地址空间是相互分开的。
CPU和GPU都有自己的地址空间,用来映射各自设备自身的页表。两者的设备都要通过显式的内存复制命令来交换数据。
GPU可以分配锁页内存,该内存式GPU为DMA映射的页面锁定的内存,只能使DMA的速度更快,却不能让CUDA内核程序访问主机内存。(DMA,直接存储访问)
CUDA驱动程序跟踪锁页内存的起止范围,并自动加速引用他们的内存复制操作,异步内存复制调用需要锁页内存气质信息,以确保在内存复制完成之前操作系统不会取消映射或移动物理内存。
映射锁页内存是被映射到CUDA地址空间的锁页主存,在CUDA内核程序里可以直接对其读取或写入,CPU和GPU的页表更新了,以便CPU和GPU中拥有只想相同主机内存缓冲区的地址区间。
可分享锁页内存,将锁页内存设置为可分享,会导致CUDA驱动程序把该内存映射给系统中的所有GPU。
统一寻址:统一虚拟寻址(UVA),CUDA可以从相同的虚拟地址空间为CPU和GPU分配内存。
点对点映射,可以使费米架构GPU读写另一个费米架构的GPU内存。点对点映射仅支持启用UVA的平台。并且支队连接到相同I/O集线器上的GPU有效。点对点内存寻址是非对称的。
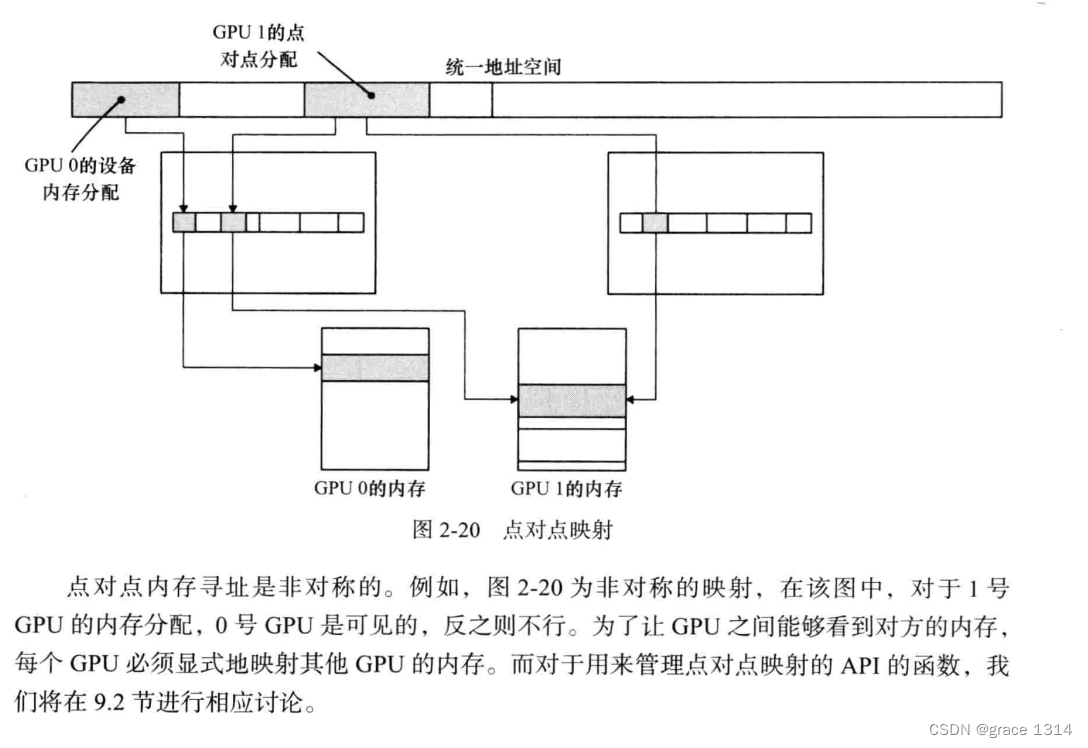
CPU与GPU的交互
锁页主机内存:GPU可以直接访问(DMA方式)的CPU的锁页内存;被锁定的页面已被操作系统标记为不可被操作系统换出的,所以设备驱动程序给这些外设编程时,可以使用页面的物理地址直接访问内存。而CPU上仍然可以访问上述锁页内存,但是此内存是不能移动或换页到磁盘上的。
DMA可以使GPU读取和写入CPU内存的操作与CPU的执行操作相互独立并且并行执行。但要注意二者的同步,以避免竞争。
命令缓冲区:由CUDA驱动程序写入命令,GPU从此缓冲区读取命令并控制其执行。
CPU/GPU同步:指的是CPU如何跟踪GPU的进度。CUDA内核程序的所有启动都是异步的:CPU通过将命令写入命令缓冲区来请求启动内核,然后直接返回,不检查GPU进度。内存复制也可以选择异步方式,这使CPU并发以及可能使内存复制与内核处理并发执行。
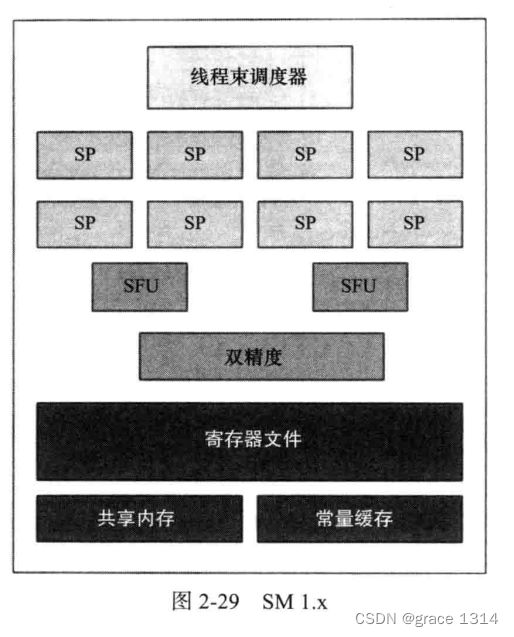
流多处理器/流处理器簇,SM,每个SM包含执行单位,特殊函数单元,线程束调度器,常量缓存,共享内存,纹理映射专用硬件。
总结:
GPU与CPU一般不能直接相互访问内存,通过CUDA程序,可以显式的将CPU内存数据复制到GPU上,或者相反也行。
而统一寻址功能,是cuda创建的虚拟地址空间,可以将GPU或者CPU的内存地址映射在虚拟地址空间中,通过DMA可以加速直接访问,不需要显示从一个到另外一个区复制。
一般是CPU将命令放到命令缓冲区就不管GPU有没有运行完或者出错,而GPU则读取命令缓冲区的命令执行。
一个GPU的主要执行硬件是SM,里面包含内存,执行核心等等。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)