
强化学习(PPO)
policy gradient不好确定learning rate(即step size)的问题,step size过大,policy会一直乱动,不容易收敛;反之,step size太小,完成训练的话,需要很长时间,PPO算法则是利用了新旧策略的比例,限制新策略的更新幅度,让算法对step size不那么敏感。PPO算法的核心在于更新策略梯度,主流方法有两种,一种是KL散度做penalty,另一种是
PPO——Proximal Policy Optimization近端策略优化
policy gradient不好确定learning rate(即step size)的问题,step size过大,policy会一直乱动,不容易收敛;反之,step size太小,完成训练的话,需要很长时间,PPO算法则是利用了新旧策略的比例,限制新策略的更新幅度,让算法对step size不那么敏感。
PPO算法的核心在于更新策略梯度,主流方法有两种,一种是KL散度做penalty,另一种是clip做剪裁,主要作用是限制策略梯度更新的幅度。
具体步骤
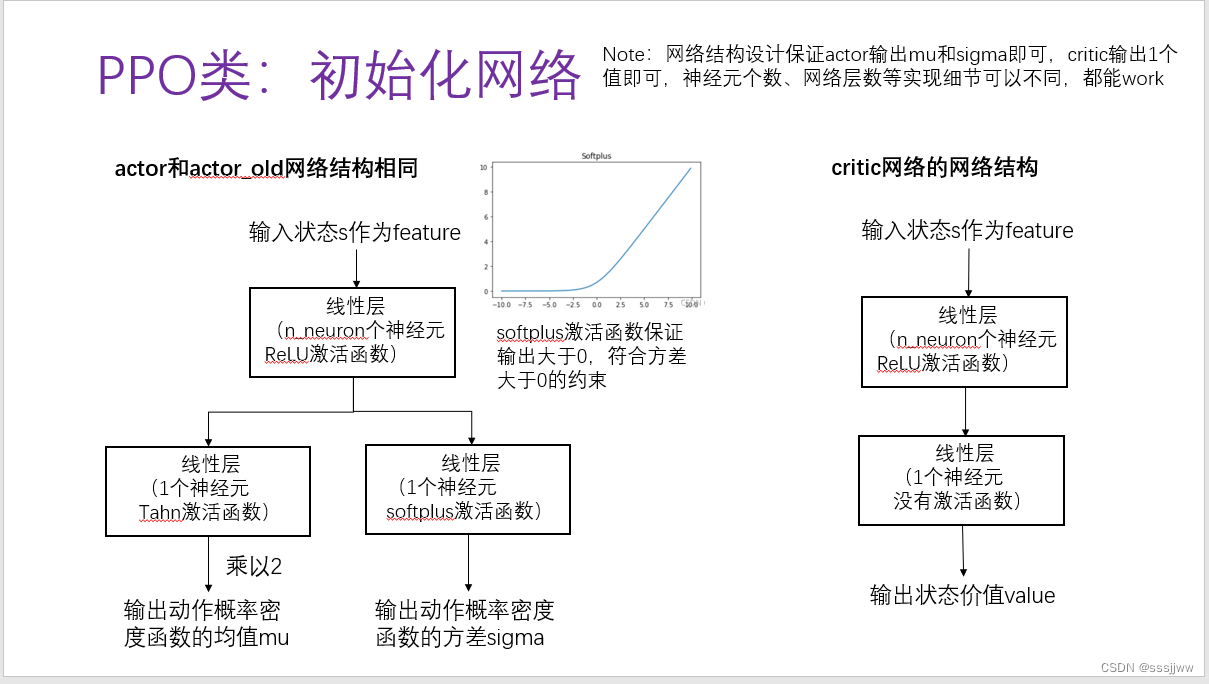
(1)初始化
初始化三个网络,分别是actor网络、actor old网络、critic网络。actor网络用于选择动作,需要训练更新、梯度反向传播,actor old网络参数复制actor的,不需要反向传播,critic网络用于计算状态价值,需要训练更新、梯度反向传播
初始化actor网络、critic网络的学习率、优化器;初始化超参数
actor网络输出两个值,一个是mu(均值)一个是sigma(方差);另一个critic网络输出一个值
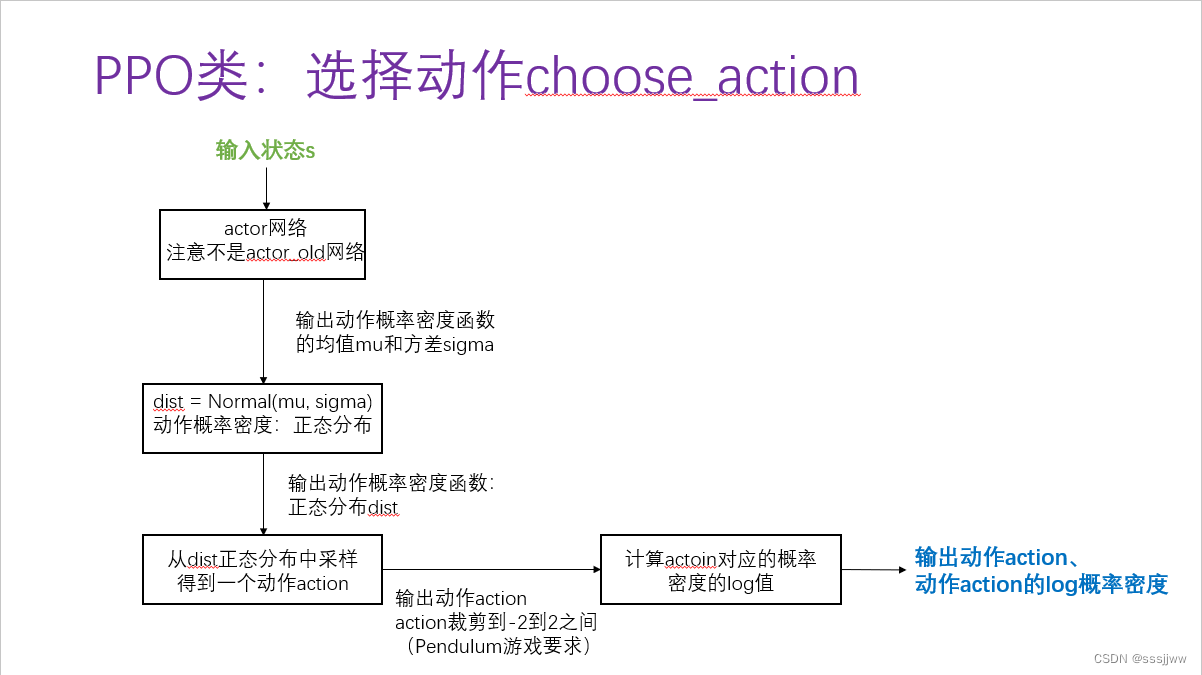
(2)动作选择
输入状态s,通过actor网络选择动作,actor网络输出动作概率密度函数中的均值和方差,假设的是概率密度函数服从的是正态分布,然后基于正态分布进行采样获得动作,该动作还需要经过裁剪到一定的范围内,之后计算动作对应的概率密度的log值。最终输出动作和该动作对应的log 概率密度
(3)计算状态价值
将状态输入到critic网络,输出状态价值value
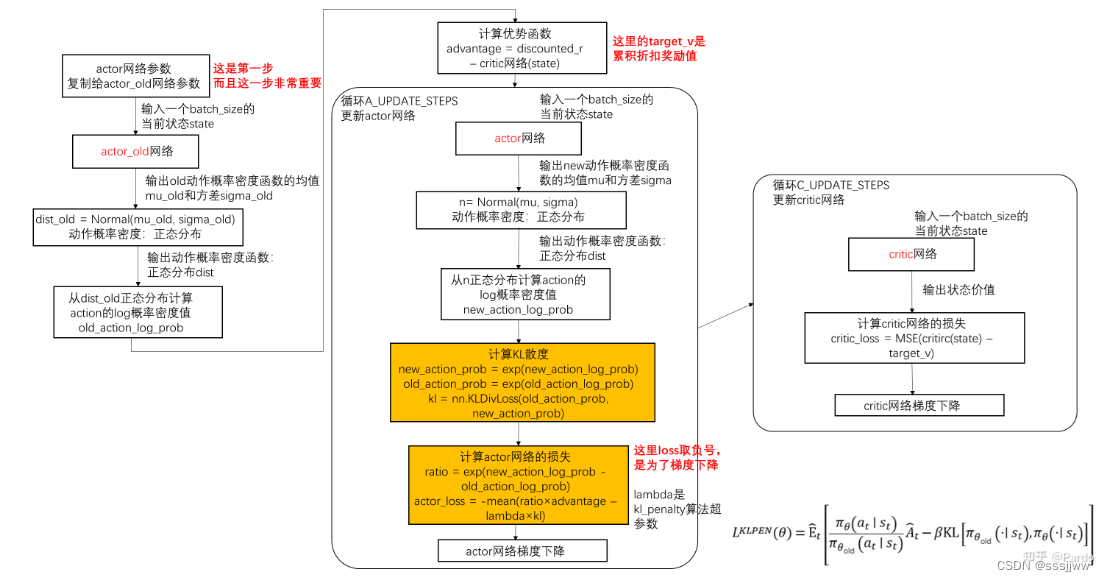
(4)更新/训练网络
采用KL penalty算法,神经网络的参数的更新方式:
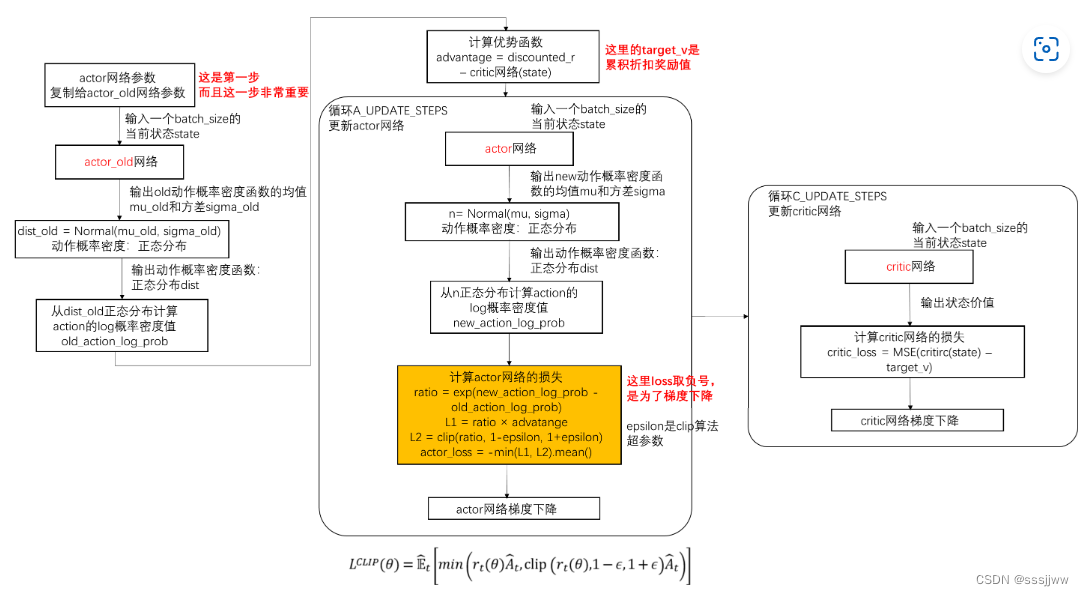
采用Clip算法,神经网络的参数的更新方式:
更多推荐
 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)