
深度学习 loss下降后上升在下降_Day203:学习率的设定
1、学习率目前深度学习使用的都是非常简单的一阶收敛算法,梯度下降法,不管有多少自适应的优化算法,本质上都是对梯度下降法的各种变形,所以,初始学习率对深层网络的收敛起着决定性的作用,下面就是梯度下降法的公式:α 就是学习率,如果学习率太小,会导致网络loss下降非常慢,如果学习率太大,那么参数更新的幅度就非常大,就会导致网络收敛到局部最优点,或不会收敛或者loss直接开始增加;如下图所示:学习率的选
·
1、学习率
目前深度学习使用的都是非常简单的一阶收敛算法,梯度下降法,不管有多少自适应的优化算法,本质上都是对梯度下降法的各种变形,所以,初始学习率对深层网络的收敛起着决定性的作用,下面就是梯度下降法的公式:
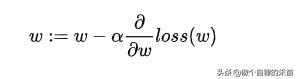
α 就是学习率,如果学习率太小,会导致网络loss下降非常慢,如果学习率太大,那么参数更新的幅度就非常大,就会导致网络收敛到局部最优点,或不会收敛或者loss直接开始增加;如下图所示:
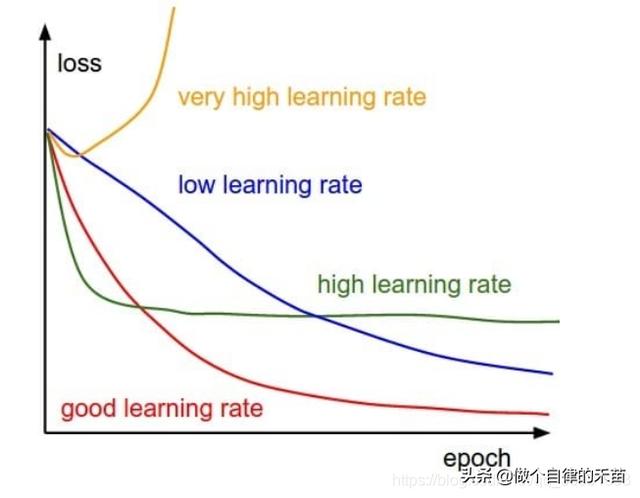
学习率的选择策略在网络的训练过程中是不断在变化的,在刚开始的时候,参数比较随机,所以我们应该选择相对较大的学习率,这样loss下降更快;当训练一段时间之后,参数的更新就应该是更小的幅度,所以学习率一般会做衰减,衰减的方式也非常多,比如到一定的步数将学习率乘上0.1,也有指数衰减等。
2、mxnet 学习率设置方法
学习率是优化器类optimizer的一个参数,设置学习率,就是给优化器传递这个参数,通常有两大类:
- 一是静态常数学习率,可以在构造optimizer的时候传入常数参数即可
- 还有一种是动态设置学习率,mxnet提供lr_scheduler模块来完成动态设置
2.1、静态常数学习率
sgd_optimizer = mx.optimizer.SGD(learning_rate=0.03, lr_scheduler=schedule) #schedule貌似没有定义trainer = mx.gluon.Trainer(params=net.collect_params(), optimizer=sgd_optimizer)2.2、动态设置
构造一个lrs,作为变量传递给优化器,当做优化器的lr_scheduler参数。
lrs # 需要自己构造学习率调整策略trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': learning_rate, 'wd': 0.00https://blog.csdn.net/qq_35091353/article/details/108925902
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)