
ECCV'24 | 扩散模型&DETR 超强融合!中科大最新3D目标检测SOTA!
点击下方卡片,关注「3D视觉工坊」公众号选择星标,干货第一时间送达来源:3D视觉工坊添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研
点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0.这篇文章干了啥?
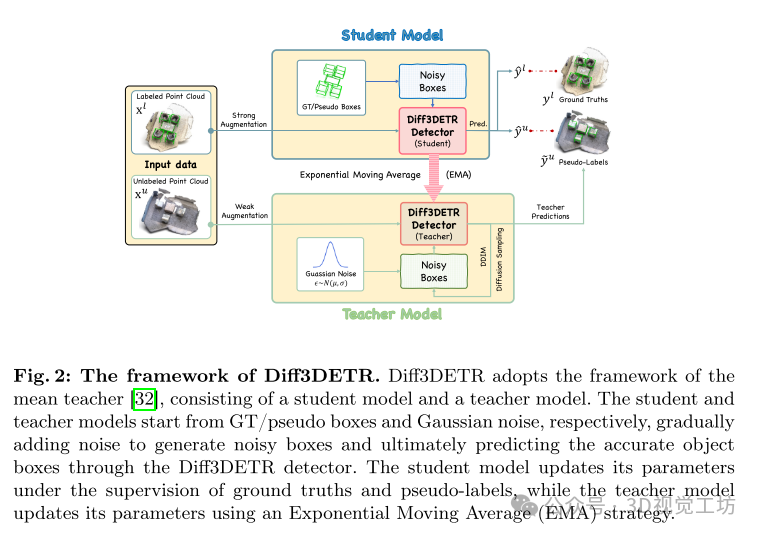
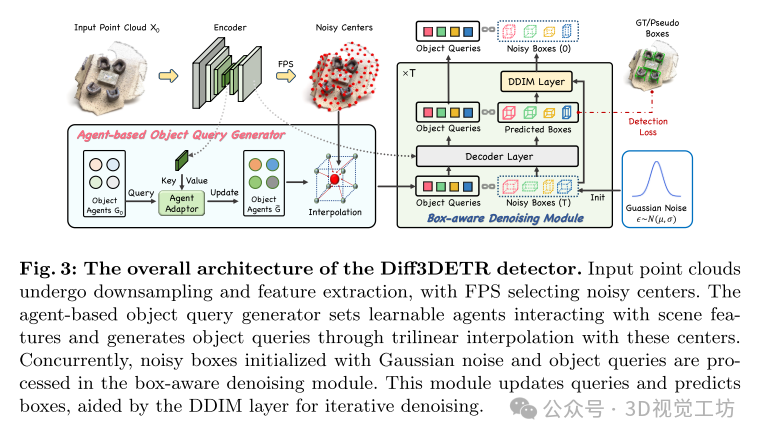
这篇文章提出了一种新的半监督 3D 目标检测方法——Diff3DETR,该方法结合了扩散模型和 DETR 框架。Diff3DETR 主要由两个部分组成:代理基础的对象查询生成器和盒子感知去噪模块。代理基础的对象查询生成器能够有效适应动态场景,平衡采样位置和内容嵌入;盒子感知去噪模块则利用 DDIM 去噪过程和长距离注意力机制,逐步精炼边界框,提升检测结果的准确性。文章通过在 ScanNet 和 SUN RGB-D 数据集上的广泛实验验证了 Diff3DETR 的优越性,尤其在低标记数据比例下表现突出。消融研究进一步证明了各个模块的有效性。尽管扩散模型的去噪过程需要较高的计算资源,这可能限制了其在实时应用和大规模场景中的应用,但总体而言,Diff3DETR 在半监督 3D 目标检测任务中展现了显著的性能提升。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:Diff3DETR: Agent-based Diffusion Model for Semi-supervised 3D Object Detection
作者:Jiacheng Deng, Jiahao Lu等
作者机构:University of Science and Technology of China等
论文链接:https://arxiv.org/pdf/2408.00286
2. 摘要
三维物体检测对于理解三维场景至关重要。当前技术通常需要大量的标注训练数据,但获取点云的逐点标注既耗时又费力。近期的半监督方法试图通过采用教师-学生框架生成无标注点云的伪标签来缓解这一问题。然而,这些伪标签往往缺乏足够的多样性和质量。为了解决这些难题,我们提出了一种基于智能体的扩散模型用于半监督三维物体检测(Diff3DETR)。具体而言,我们设计了一种基于智能体的物体查询生成器,以生成能够有效适应动态场景的物体查询,同时在采样位置和内容嵌入之间取得平衡。此外,箱体感知去噪模块利用DDIM去噪过程和变换器解码器中的长范围注意力来逐步优化边界框。我们在ScanNet和SUN RGB-D数据集上的大量实验表明,Diff3DETR优于现有的最先进半监督三维物体检测方法。
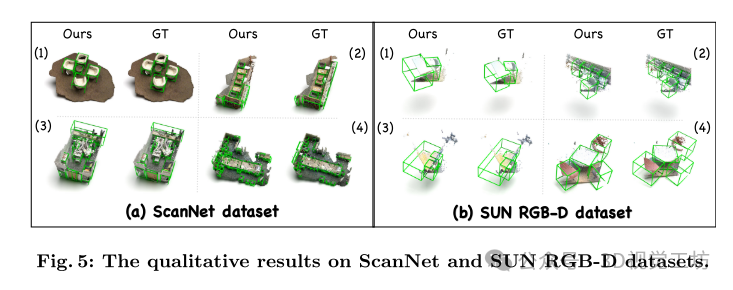
3. 效果展示
ScanNet和SUN RGB-D数据集上的定性结果。
4. 主要贡献
-
我们在统一的DETR框架中引入了一种基于智能体的扩散模型,其中包括一个基于智能体的物体查询生成器和一个箱体感知去噪模块。据我们所知,这是半监督三维物体检测领域中首个基于扩散的DETR框架。
-
我们开发了一个基于智能体的物体查询生成器,以生成更好地适应动态场景的物体查询,同时平衡采样位置和内容嵌入。此外,我们设计了一个箱体感知去噪模块,利用DDIM去噪过程的逐步优化能力和变换器解码器的长范围注意力来去噪初始框,实现准确的三维物体检测。
-
在ScanNet和SUN RGB-D数据集上的大量实验结果表明,Diff3DETR表现出优越的性能,超越了现有的最先进方法。
5. 基本原理是啥?
-
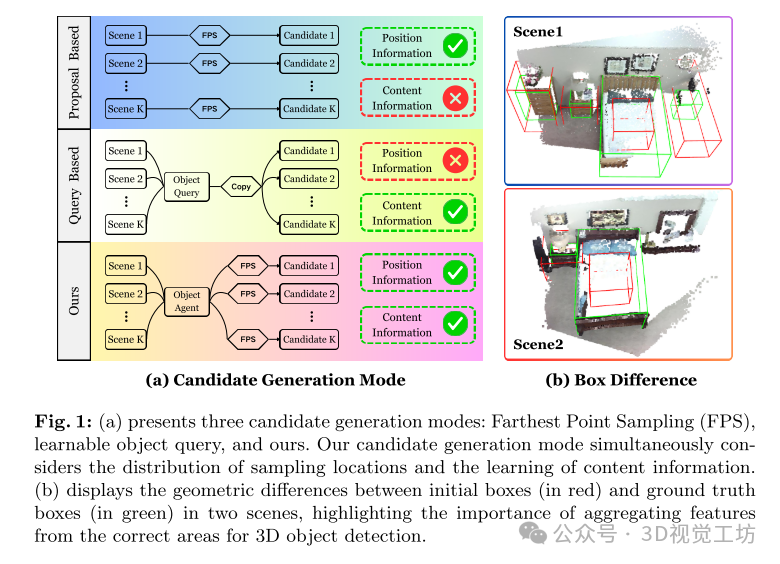
基于代理的物体查询生成器:
-
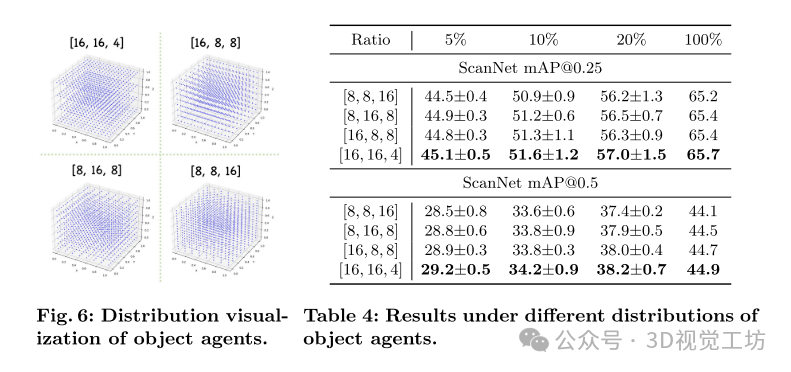
代理:在 Diff3DETR 中,代理(agent)是用于生成物体查询的可学习向量,这些向量在3D空间中均匀分布。代理的数量和分布对于生成有效的物体查询至关重要。
-
动态适应:生成的物体查询能够动态适应不同的场景,以提高对复杂和多变环境的检测能力。
-
采样位置与内容嵌入:生成的物体查询在采样位置和内容嵌入之间找到平衡,确保生成的查询能够准确反映物体的空间信息和特征。
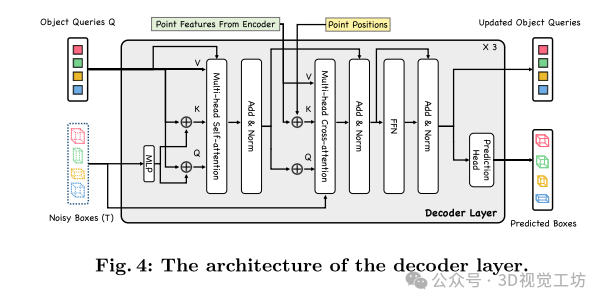
盒子感知去噪模块:
-
去噪过程:利用 DDIM(Denoising Diffusion Implicit Models)去噪过程,通过将噪声逐步去除,逐步精炼物体的边界框。
-
长距离注意力:在变换器(transformer)解码器中使用长距离注意力机制,增强对不同区域之间信息的关联,从而改进边界框的精确度。
DETR 框架:
-
DETR(DEtection TRansformer):是一种基于变换器的检测框架,能够直接将图像映射到检测结果,而无需传统的候选框生成步骤。
-
统一框架:Diff3DETR 结合了 DECT 和扩散模型,利用变换器框架中的长距离注意力机制来增强模型的检测能力。

6. 实验结果
以下是 Diff3DETR 在实验中的主要结果总结:
数据集
-
ScanNet 数据集:包含 1,201 个训练场景和 312 个验证场景,基于 250 万张高分辨率 RGB-D 图像。重点关注 18 个语义类别。
-
SUN RGB-D 数据集:包含 5,285 个训练场景和 5,050 个验证场景。对 10 个目标类别进行评估。
评估指标
-
数据集划分为不同的标记数据和未标记数据比例来支持半监督学习(SSL)。具体分配为 ScanNet 的 5%、10%、20% 和 100% 标记数据,以及 SUN RGB-D 的 1%、5%、10% 和 20% 标记数据。
-
使用平均精度均值(mAP)进行性能评估。报告了 mAP@0.25 和 mAP@0.5 这两个指标,以提供细粒度的目标检测精度。
-
评估在三个随机数据拆分上进行,以确保结果的稳健性,并报告了平均性能和标准差。
实现细节
-
检测器:设定对象代理网格为 (L, W, H) = (16, 16, 4),设置噪声中心和对象查询数量为 128。扩散过程的最大时间步数设为 1000。
-
采样均值:设置为 0.25。噪声标签的随机采样均值设为相应类别数量的倒数。
-
教师模型:使用双步 DDIM 采样技术 (T=2) 生成伪标签并生成最终评估结果。
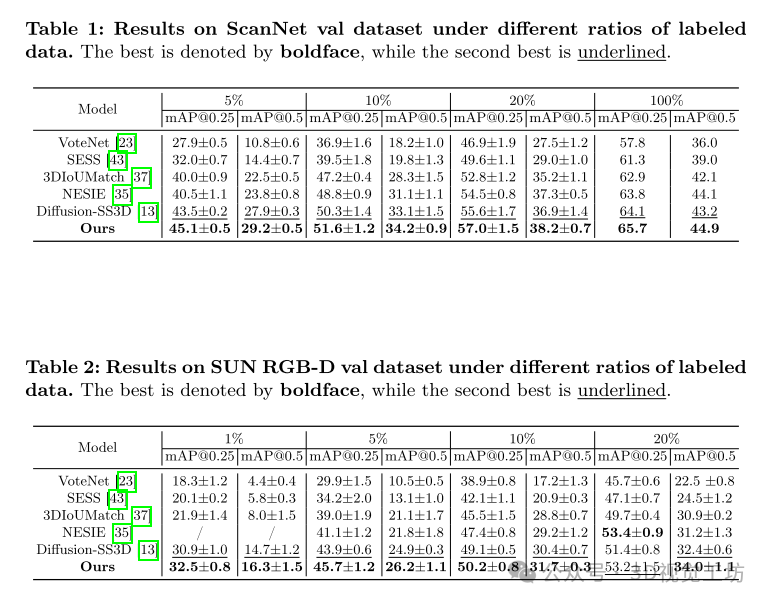
与最先进方法的比较
-
ScanNet 数据集:
-
Diff3DETR 在不同标记数据比例下均取得领先结果。
-
使用 5% 标记数据时,Diff3DETR 比现有最先进方法高出 1.6% 的 mAP@0.25 和 1.3% 的 mAP@0.5。
-
定性结果显示在图 5(a) 中。
-
-
SUN RGB-D 数据集:
-
Diff3DETR 在不同标记数据比例下均表现出色。
-
使用 5% 标记数据时,Diff3DETR 比现有最先进方法高出 1.8% 的 mAP@0.25 和 1.3% 的 mAP@0.5。
-
定性结果展示在图 5(b) 中。
-
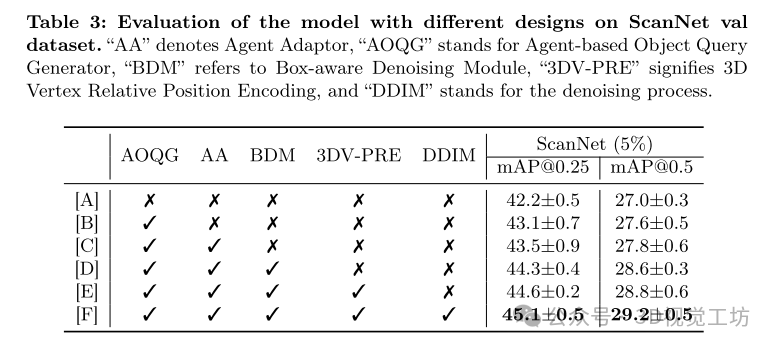
消融研究
-
模型设计评估:
-
A:基础模型 IoU-aware VoteNet,不使用 DDIM 迭代去噪。
-
B:引入基于代理的对象查询生成器,mAP@0.25 增加 0.9%,mAP@0.5 增加 0.6%。
-
C:对比 B,显示代理适配器对于动态场景的适应性。
-
D:引入盒子感知去噪模块,mAP@0.25 和 mAP@0.5 分别增加 0.8%。
-
E:验证 3D 顶点相对位置编码对对象查询的聚焦效果。
-
F:完整的 Diff3DETR 模型表现最佳。
-
-
基于代理的对象查询生成器的效果:
-
通过不同的 [L, W, H] 分辨率设置对比,[16, 16, 4] 的分布取得最佳性能。
-
-
盒子感知去噪模块的效果:
-
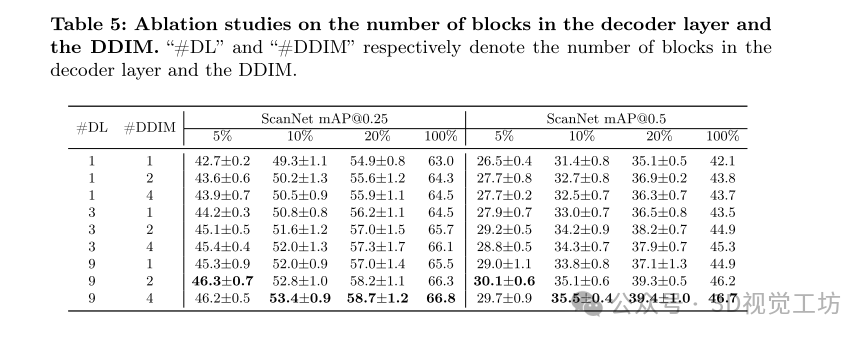
解码器层和 DDIM 中的块数量对模型的解码能力有显著影响。更多的块和迭代通常能获得更好的检测结果,但也会影响训练和推理速度。因此,最终模型选择了 #DL=3 和 #DDIM=2 的配置,以实现精度和计算成本之间的平衡。
-
限制
-
扩散模型的局限性:
-
扩散模型从真实的边界框到随机分布的扩散过程可能导致训练和推理过程中的高计算资源需求。
-
扩散过程虽然能够生成更多的伪标签,但其慢速的去噪过程限制了模型在实时设备和大规模场景中的应用潜力。有关模型开销的详细分析和讨论已在补充材料中进行。
-
7. 总结 & 未来工作
在本文中,我们提出了一种新颖的基于代理的扩散模型,融合在统一的 DETR 框架中,用于半监督3D目标检测。我们提出的 Diff3DETR 包括一个基于代理的物体查询生成器和一个盒子感知去噪模块。基于代理的物体查询生成器旨在生成能够有效适应动态场景的物体查询,同时在采样位置和内容嵌入之间取得平衡。与此同时,盒子感知去噪模块利用 DDIM 去噪过程和变换器解码器中的长距离注意力,逐步精炼边界框,从而取得更好的结果。在 ScanNet 和 SUN RGB-D 基准测试上的大量实验强调了我们 Diff3DETR 的优越性。
本文仅做学术分享,如有侵权,请联系删文。

3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
「3D视觉从入门到精通」知识星球,已沉淀6年,星球内资料包括:秘制视频课程近20门(包括结构光三维重建、相机标定、SLAM、深度估计、3D目标检测、3DGS顶会带读课程、三维点云等)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。
具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~

更多推荐


 0
0 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)