
深度强化学习
深度强化学习(Deep Reinforcement Learning,DRL)是一种结合了。
文章目录
深度强化学习
深度强化学习是什么
一、定义与概念
深度强化学习(Deep Reinforcement Learning,DRL)是一种结合了深度学习和强化学习的技术领域。强化学习主要涉及智能体(agent)在环境(environment)中采取一系列行动(action),并根据环境反馈的奖励信号(reward)来学习最优策略(policy),以最大化长期累积奖励。而深度强化学习则是利用深度神经网络来表示强化学习中的策略、价值函数或者环境模型等关键组件。强化学习与深度学习之间的关系请查看:强化学习与深度学习以及相关芯片之间的区别。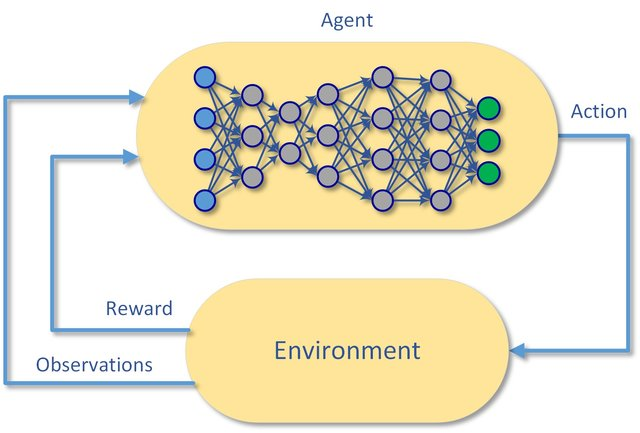
例如,在训练一个机器人在迷宫中寻找宝藏的场景中,机器人就是智能体,迷宫是环境。机器人每次在迷宫中移动(行动),根据是否离宝藏更近(奖励)来学习最优的行走策略。在深度强化学习中,会用深度神经网络来帮助机器人更好地学习这个策略,比如通过学习环境状态(迷宫中的位置、周围墙壁等信息)和行动(向左、向右等移动方式)之间的关系。
二、深度神经网络在强化学习中的应用方式
- 策略网络(Policy Network):用于直接生成智能体的行动策略。它以环境状态作为输入,通过深度神经网络的前向传播,输出在当前状态下各个行动的概率分布。例如,在自动驾驶场景中,策略网络会根据车辆周围的路况、交通信号等环境状态,输出加速、刹车、转向等不同行动的概率,车辆(智能体)就可以根据这些概率来选择行动。
- 价值网络(Value Network):主要用于评估给定状态的价值。它也以环境状态为输入,通过深度神经网络输出一个估计的价值,表示在这个状态下智能体未来可能获得的累积奖励的期望。以围棋游戏为例,价值网络可以评估棋局当前状态对自己是否有利,帮助智能体(棋手)决定下一步的走法。
- 环境模型(Model - based):部分深度强化学习方法会利用深度神经网络构建环境模型,来预测环境在智能体行动后的状态变化和奖励反馈。例如,在机器人控制中,通过学习一个环境模型,机器人可以在虚拟环境中模拟不同行动的后果,从而更高效地学习最优策略。
三、深度强化学习的学习过程
- 交互阶段:智能体与环境进行交互,根据当前策略网络生成的行动概率分布选择一个行动,环境根据这个行动更新状态并反馈一个奖励信号。这个过程会不断重复,形成一个序列,如在游戏场景中,玩家(智能体)根据当前策略选择一个操作(行动),游戏环境更新游戏状态并给予玩家一定的奖励(比如得分增加或减少)。
- 学习阶段:利用收集到的状态、行动和奖励信息来更新策略网络和价值网络(如果有)。在基于策略梯度的方法中,会根据奖励信号来调整策略网络的参数,使得智能体更倾向于选择能带来高奖励的行动。在基于价值的方法中,会更新价值网络的参数,使其更准确地评估状态的价值。例如,在训练一个机器人抓取物体的任务中,当机器人成功抓取物体(获得高奖励),就会更新策略网络,让它在类似的环境状态下更有可能采取相同的成功行动,同时也会更新价值网络,提高对这种成功状态的价值评估。
四、深度强化学习的优势与应用场景
- 优势:深度强化学习能够处理高维复杂的环境状态和行动空间。由于深度神经网络强大的表示能力,它可以自动学习到复杂环境中的特征和模式,从而找到有效的策略。相比传统的强化学习方法,深度强化学习能够更好地适应大规模、复杂的实际问题。
- 应用场景:在游戏领域,如AlphaGo利用深度强化学习击败了人类顶尖棋手,展示了其在复杂策略游戏中的强大能力。在机器人控制方面,可用于机器人的路径规划、物体抓取等任务。在自动驾驶中,帮助车辆学习在各种路况下的最优驾驶策略,包括应对交通堵塞、避开障碍物等复杂情况。
深度强化学习类型
1. 基于价值的深度强化学习
-
详细解释:
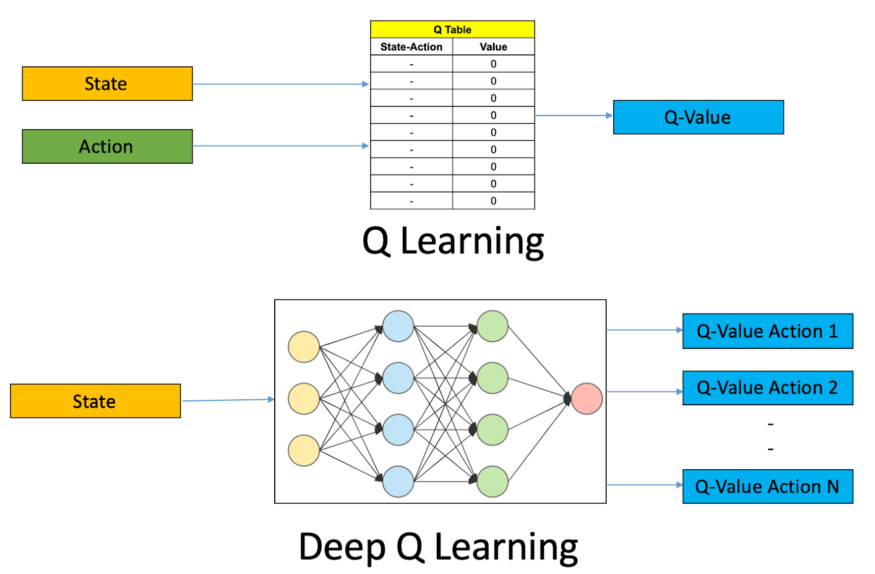
- 这种类型的深度强化学习主要侧重于学习价值函数。价值函数用于估计智能体在某个状态下的长期累积奖励的期望。智能体的目标是找到一个最优策略,使得在每个状态下选择的行动能够最大化这个价值。例如,在一个简单的网格世界游戏中,智能体(如一个虚拟角色)要从起点走到终点,价值函数可以评估每个网格位置(状态)的好坏程度,即智能体从这个位置出发可能获得的奖励总和。
- **深度Q - 网络(DQN)**是基于价值的深度强化学习的典型代表。DQN使用深度神经网络来近似Q - 函数(Q - 函数是一种价值函数,表示在某一状态下采取某一行动后的预期累积奖励)。它通过经验回放和目标网络等技术来稳定训练过程。经验回放是指智能体将之前的经验(状态、行动、奖励、下一个状态)存储在一个回放缓冲区中,在训练时随机抽取这些经验来更新网络,避免了样本之间的相关性,提高了训练效率。目标网络是一个和主网络结构相同但参数更新较慢的网络,用于计算目标Q值,减少了训练过程中的波动。
-
应用场景:
- 这种方法在游戏领域应用广泛,如Atari游戏。在这些游戏中,智能体(游戏角色)需要根据游戏画面(状态)来选择操作(行动),通过学习价值函数可以让智能体知道在不同游戏画面下哪种操作更有利,从而提高游戏得分。
2. 基于策略的深度强化学习
-
详细解释:
- 基于策略的深度强化学习聚焦于直接学习策略函数。策略函数将环境状态映射到行动的概率分布,智能体根据这个概率分布来选择行动。例如,在机器人控制场景中,策略函数可以根据机器人传感器获取的环境状态(如周围物体的位置、自身的姿态等),输出机器人采取不同动作(如前进、后退、转弯等)的概率。
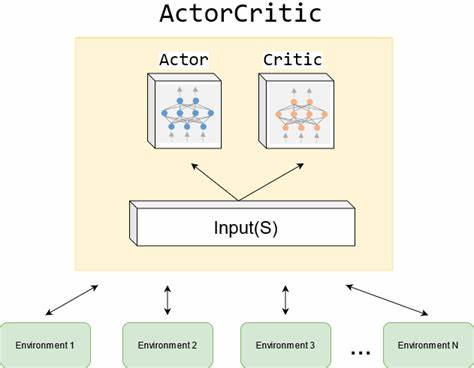
- 策略梯度方法是基于策略的深度强化学习的重要方法。它通过计算策略梯度来更新策略网络的参数,使得策略朝着能够增加累积奖励的方向调整。一种常见的策略梯度算法是A2C(Advantage Actor - Critic)和A3C(Asynchronous Advantage Actor - Critic)。A2C是同步更新的,它有一个演员(Actor)网络用于生成行动策略,一个评论家(Critic)网络用于评估价值。A3C则采用异步更新,利用多个线程同时进行训练,提高了训练效率。
-
应用场景:
- 适用于机器人控制、自动驾驶等领域。在自动驾驶中,车辆(智能体)可以根据策略网络输出的行动概率来决定是加速、刹车还是转弯,以应对不同的路况(环境状态)。
-
参考链接:
- 《Asynchronous Methods for Deep Reinforcement Learning》这篇论文介绍了A3C算法及其应用场景。
3. 基于模型的深度强化学习
- 详细解释:
- 这种类型的深度强化学习尝试构建一个环境模型。环境模型可以根据当前状态和行动来预测下一个状态和奖励。智能体可以利用这个环境模型进行规划,在实际采取行动之前在模型中模拟不同行动的后果,从而选择最优行动。例如,在无人机飞行任务中,环境模型可以根据无人机当前的位置、速度等状态和将要执行的动作(如上升、下降、转弯等),预测无人机下一刻的位置和可能获得的奖励(如是否更接近目标位置)。
- 基于模型的深度强化学习方法可以分为两类:一类是学习一个显式的环境模型,例如使用神经网络来拟合状态转移函数和奖励函数;另一类是隐式地利用模型信息,如通过学习一些基于模型的启发式策略。
- 应用场景:
- 对于一些需要提前规划的任务,如机器人路径规划、无人机任务规划等场景非常有用。通过环境模型,智能体可以在虚拟环境中进行多次模拟,找到最优的行动序列。
- 参考链接:
- 《Model - Based Reinforcement Learning: A Survey》这篇论文对基于模型的强化学习进行了全面的综述,包括各种方法和应用。
4. 深度确定性策略梯度(DDPG)及其衍生方法
- 详细解释:
-
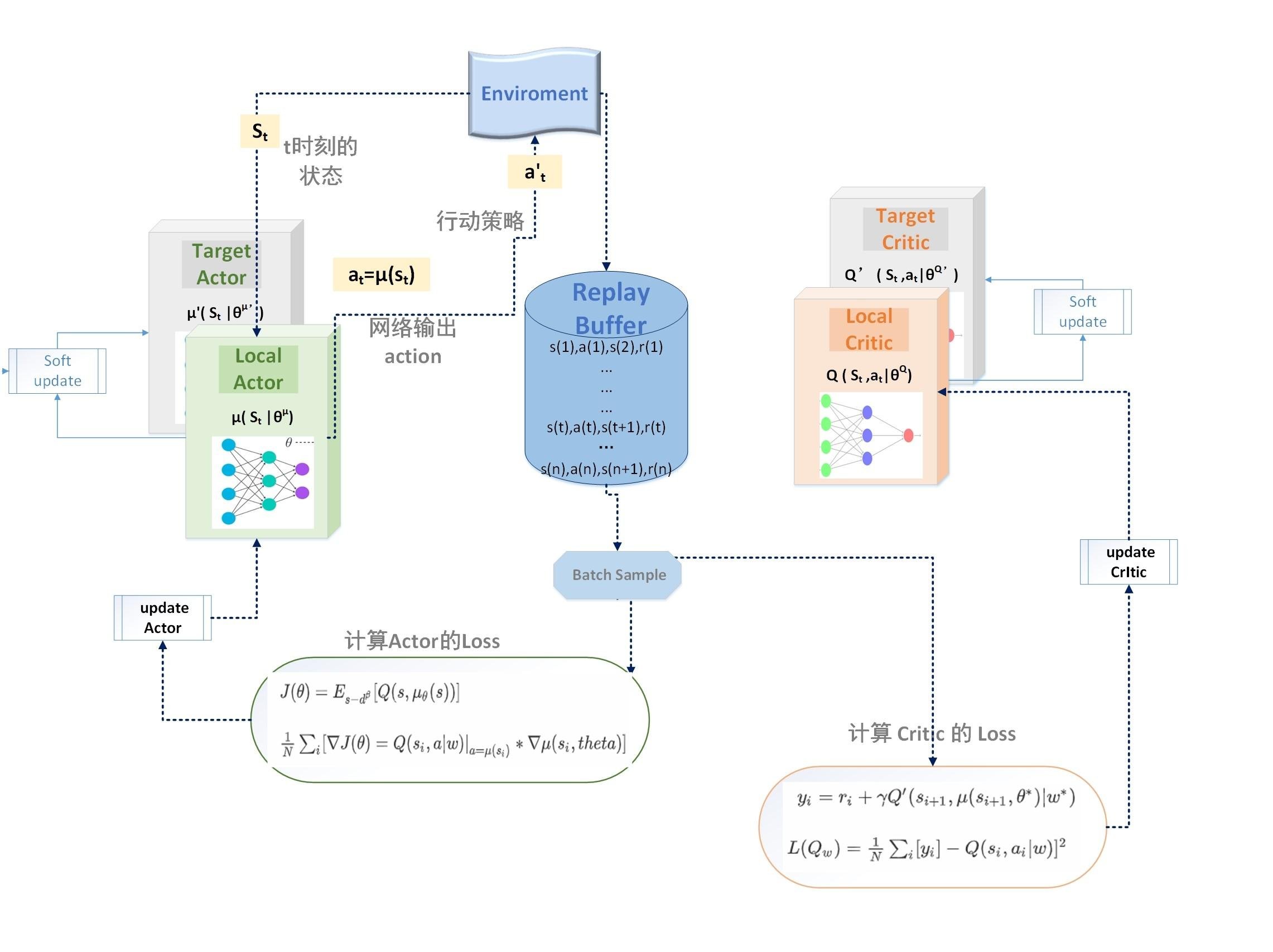
DDPG是一种适用于连续动作空间的深度强化学习方法。它结合了基于价值和基于策略的方法的优点。DDPG中有一个演员网络(Actor Network)用于生成连续的行动,还有一个评论家网络(Critic Network)用于评估行动的价值。例如,在机器人关节角度控制任务中,演员网络可以输出每个关节的连续角度变化(行动),评论家网络则评估这种角度变化是否能使机器人更好地完成任务(如抓取物体)。
-
衍生方法包括TD3(Twin Delayed DDPG)等。TD3在DDPG的基础上进行了改进,通过使用双评论家网络和延迟的策略更新等技术,提高了训练的稳定性和性能。
-
MADDPG(Multi Agent Deep Deterministic Policy Gradient)算法是基于 DDPG 算法发展而来的,而 DDPG(Deep Deterministic Policy Gradient)算法则是受 DQN(Deep Q-Network)算法的启发,并承袭了 DQN 的许多特性,例如经验回放,目标网络冻结等。DQN 虽然使用神经网络代替了传统 Q 值表,但在面对维度爆炸问题时,Q 值计算并不够准确,导致算法训练不够稳定和性能下降等一系列问题。MADDPG 算法在面对多作战智能体大规模围捕任务时,将作战智能体在动作选择时从概率选择变为策略函数,可以提升在大规模围捕任务时的稳定性。
-
- 应用场景:
- 主要应用于具有连续动作空间的控制任务,如机器人控制、物理系统的控制等领域。在机器人的力控制任务中,DDPG及其衍生方法可以帮助机器人根据环境状态(如接触物体的位置、力的大小等)调整自身的力输出(连续行动),以完成精确的操作。
- 参考链接:
更多推荐


 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)