
【强化学习-02】Value-based reinforcement learning
Value-based reinforcement learningValue-based reinforcement learningAction-value functionsDeep Q Network (DQN)训练神经网络的算法:`Temporal difference algorithm`一个例子Apply TD learning to DQNSummary参考文献本文整理自教学视频
Value-based reinforcement learning
本文整理自教学视频 (作者: Shusen Wang):https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
Value-based reinforcement learning
Action-value functions
- U t U_t Ut是未来奖励的总和的期望,依赖于未来所有动作 A t , A t + 1 , A t + 2 , ⋯ A_t, A_{t+1}, A_{t+2}, \cdots At,At+1,At+2,⋯和所有状态 s t , s t + 1 , s t + 2 , ⋯ s_t, s_{t+1}, s_{t+2}, \cdots st,st+1,st+2,⋯。由于我们对 U t U_t Ut求了期望,因此就将未来所有的动作和状态的不确定性消除掉了(也就是消除了随机变量),只留下当前的观测值 a t a_t at和 s t s_t st。



Q ∗ ( s t , a t ) = max π Q π ( s t , a t ) \begin{aligned} Q^{*}(s_t, a_t) = \max_{\pi} Q_{\pi}(s_t, a_t) \end{aligned} Q∗(st,at)=πmaxQπ(st,at)
Deep Q Network (DQN)
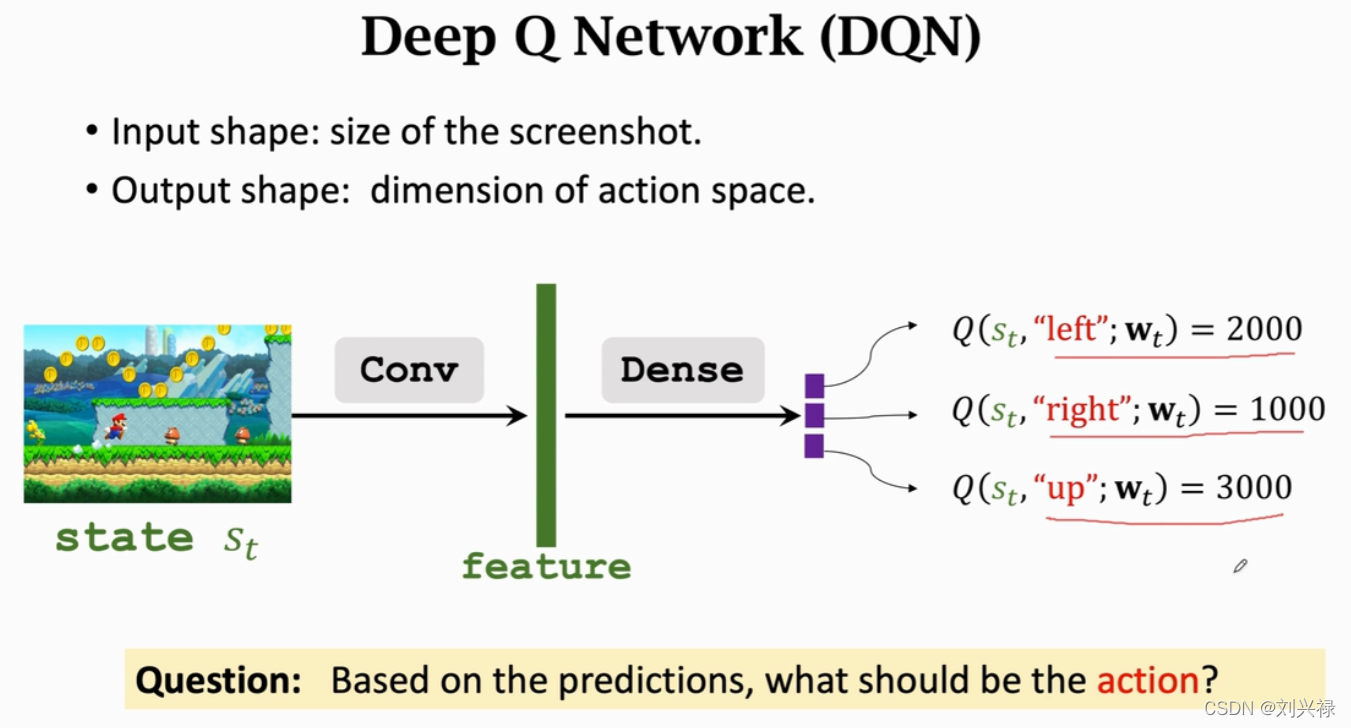
DQN就是用神经网络近似一个Q function.


- 我们用神经网络 Q ( s , a : w ) Q(s, a: \mathbf{w}) Q(s,a:w)去近似Q function: Q ∗ ( s , a ) Q^{*}(s, a) Q∗(s,a).
- 我们把神经网络记为 Q ( s , a : w ) Q(s, a: \mathbf{w}) Q(s,a:w).,其中:
- s , a s, a s,a是神经网络的输入
- w \mathbf{w} w是神经网络的参数,也就是weights of connections
- 神经网络的输出是很多数值,这些数值是对所有可能动作的打分,每一个动作对应一个分数
- 我们通过reward来学习这个神经网络,这个神经网络给动作的打分就会逐渐改进,打分就会越来越准
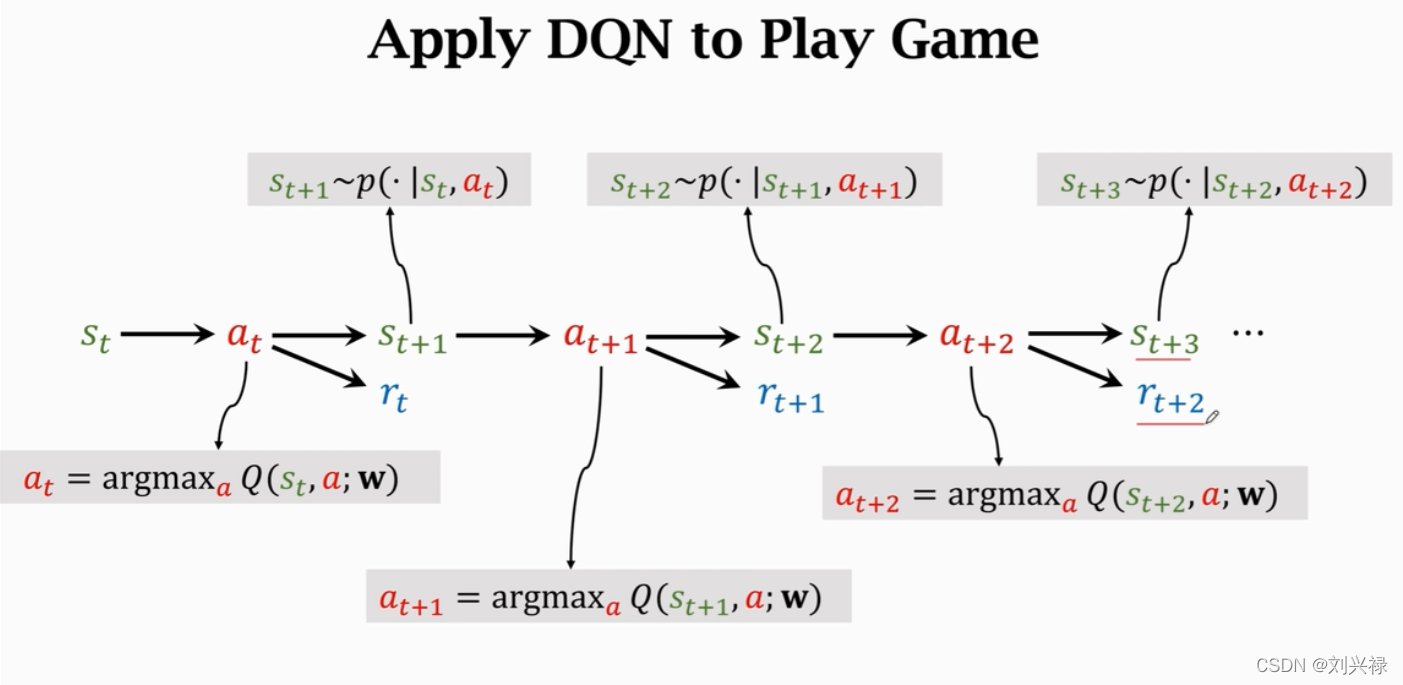
训练神经网络的算法:Temporal difference algorithm

@article{sutton2008convergent,
title={A convergent O (n) algorithm for off-policy temporal-difference learning with linear function approximation},
author={Sutton, Richard S and Szepesv{'a}ri, Csaba and Maei, Hamid Reza},
journal={Advances in neural information processing systems},
volume={21},
number={21},
pages={1609–1616},
year={2008},
publisher={MIT Press}
}
@inproceedings{sutton2009fast,
title={Fast gradient-descent methods for temporal-difference learning with linear function approximation},
author={Sutton, Richard S and Maei, Hamid Reza and Precup, Doina and Bhatnagar, Shalabh and Silver, David and Szepesv{'a}ri, Csaba and Wiewiora, Eric},
booktitle={Proceedings of the 26th Annual International Conference on Machine Learning},
pages={993–1000},
year={2009}
}
一个例子






TD算法不需要完成旅程也可以更新参数
Apply TD learning to DQN


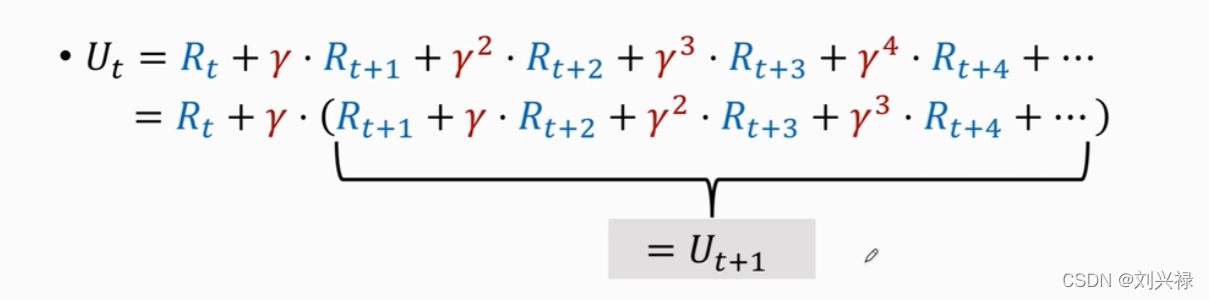
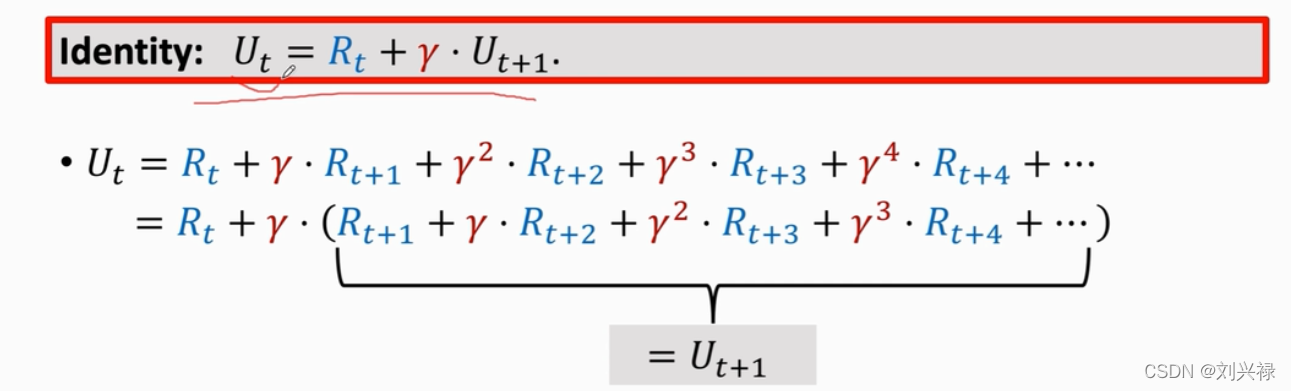

用DQN分别来估计 U t U_t Ut和 U t + 1 U_{t+1} Ut+1,也就是我们用神经网络预测
- Q ( s t , a t : w ) → E [ U t ] Q(s_t, a_t: \mathbf{w}) \rightarrow \mathbb{E}[U_t] Q(st,at:w)→E[Ut]
- Q ( s t + 1 , a t + 1 : w ) → E [ U t + 1 ] Q(s_{t+1}, a_{t+1}: \mathbf{w}) \rightarrow \mathbb{E}[U_{t+1}] Q(st+1,at+1:w)→E[Ut+1]

做梯度下降,是为了让loss最小
Summary


参考文献
[1] https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)