
YOLOv1、YOLOv2、YOLOv3目标检测算法原理与实战|YOLOv1目标检测算法原理
炮哥带你学——YOLOv1、YOLOv2、YOLOv3目标检测算法原理与实战 前面步骤和分类网络类似,最后步骤不同。 虽然有两个预测框,但是最后选择一个,可以增加准确性。20个类别的概率之和为1。Yolov1可以做分类,也可以做目标检测。
·
跟学视频
炮哥带你学——YOLOv1、YOLOv2、YOLOv3目标检测算法原理与实战
1.Yolo目标检测的背景
YOLO(You Only Look Once)是一种实时目标检测算法,其特点是速度快、精度高,广泛应用于自动驾驶、安防监控等领域。YOLO通过将目标检测视为一个回归问题,用一个单一的神经网络预测图像中的多个目标边界框和类别,是目标检测领域的一种主流方法。

 2.Yolov1网络结构
2.Yolov1网络结构
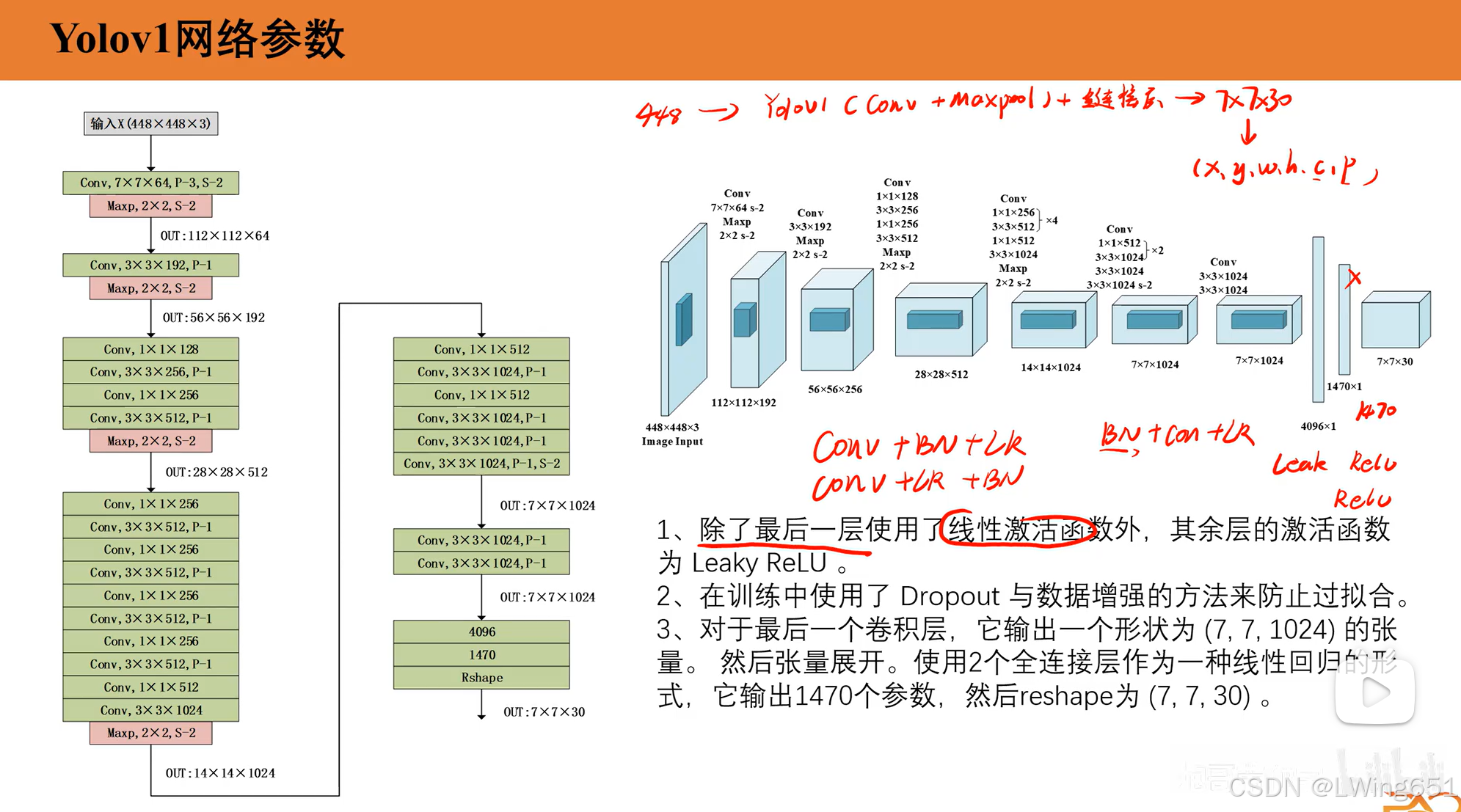
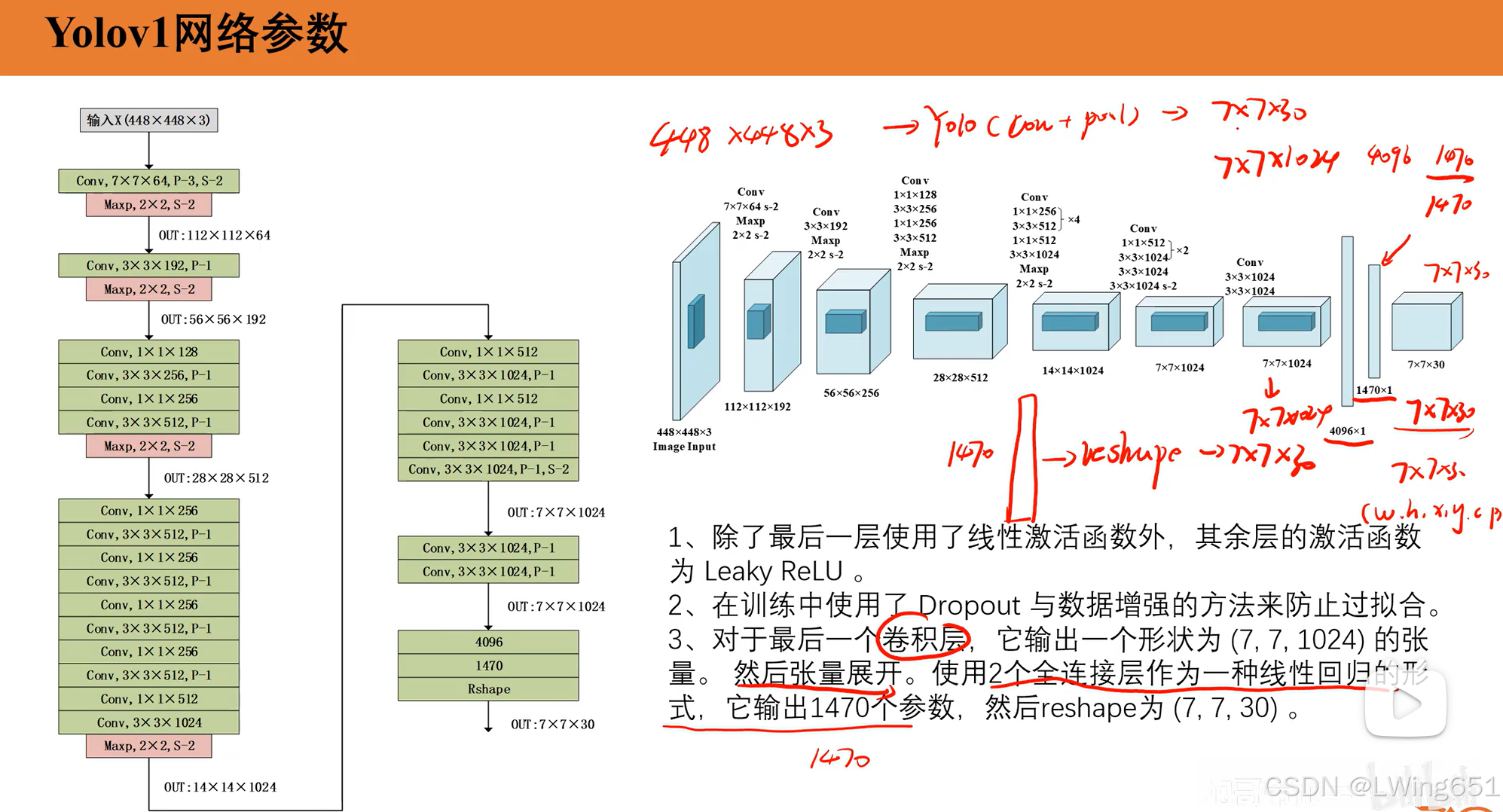
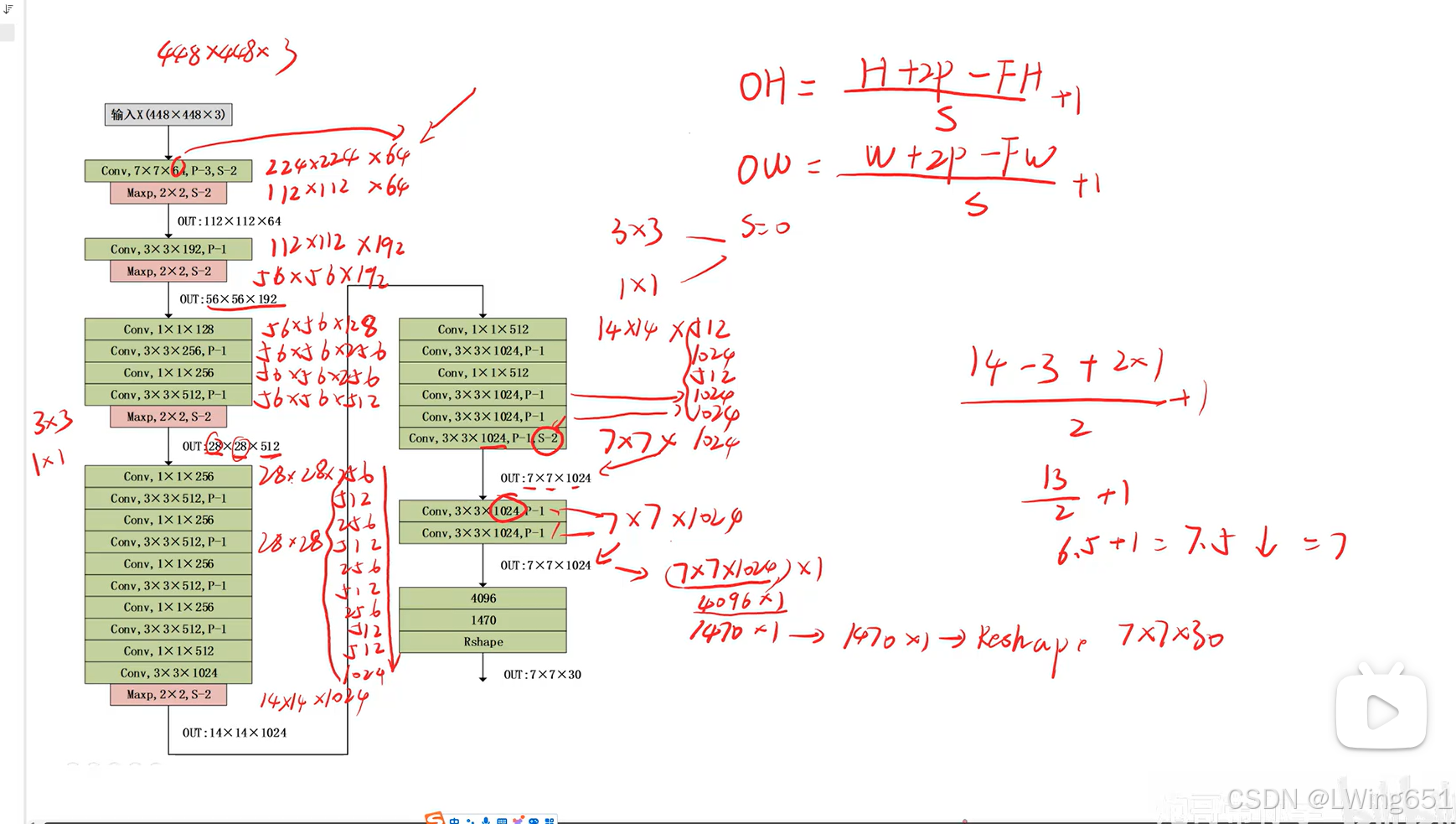
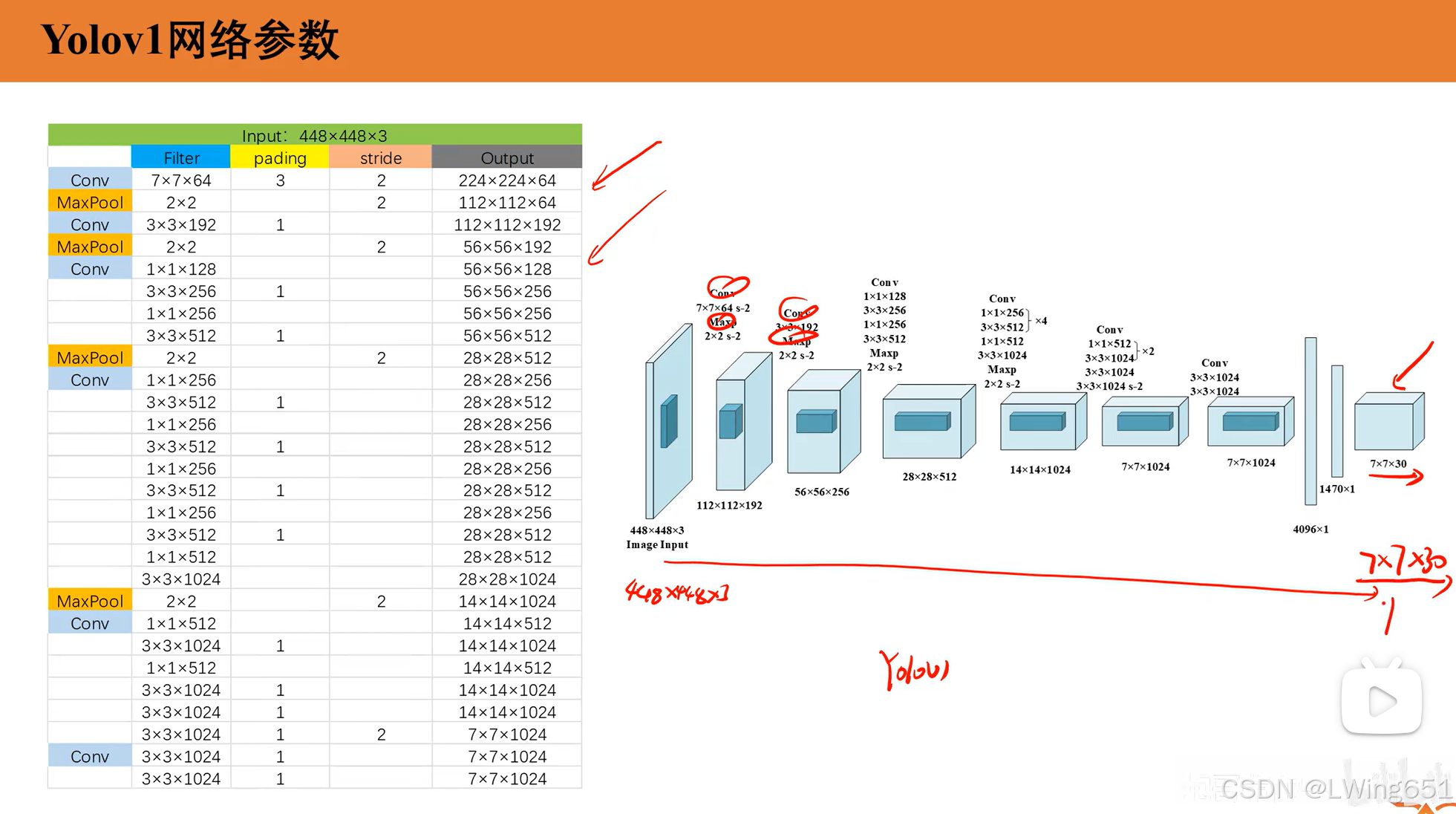
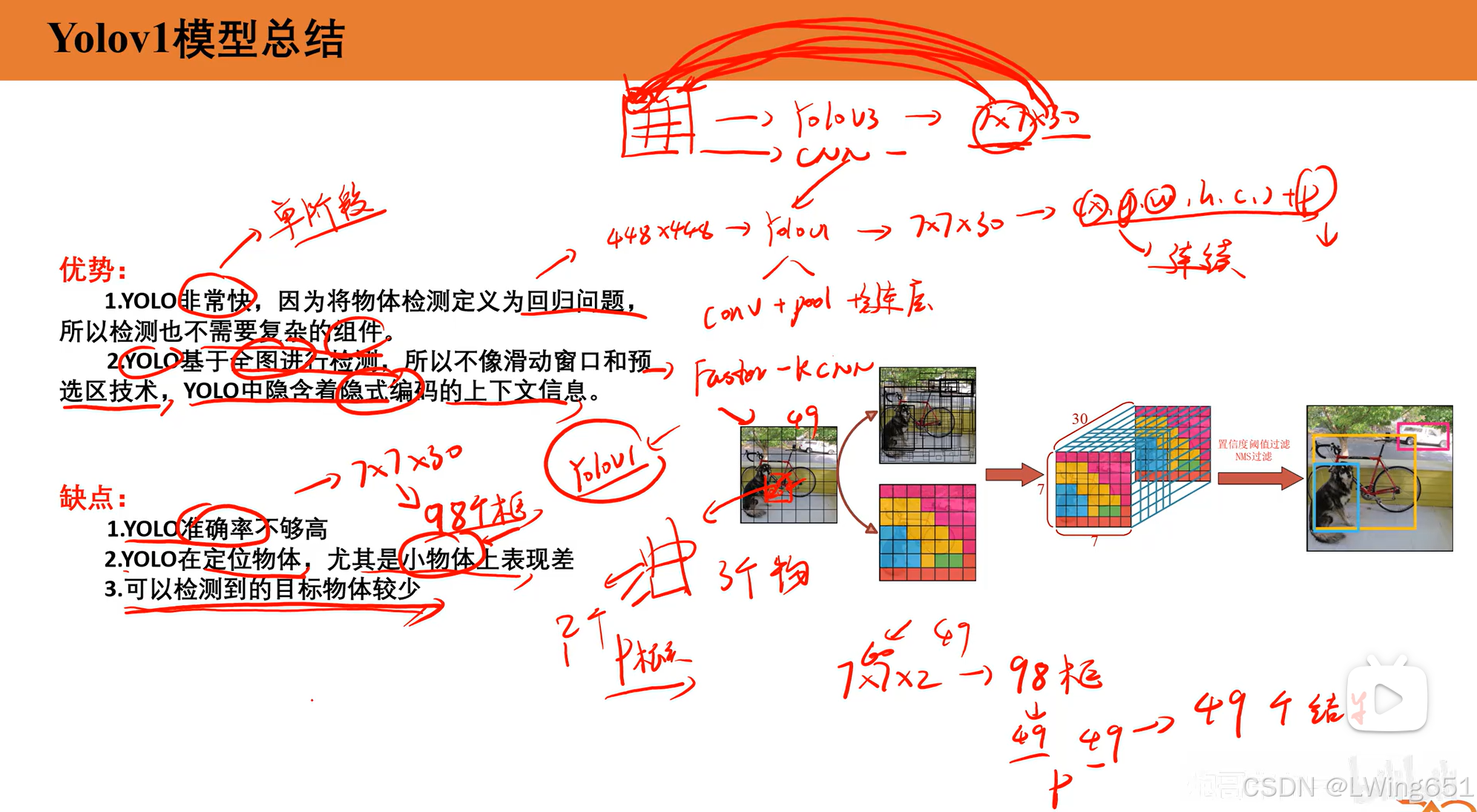
YOLOv1 的网络结构基于 Darknet 框架,由卷积层、池化层和全连接层组成。它的主要目标是通过一次网络前向传播直接预测图像中的目标类别和边界框坐标。
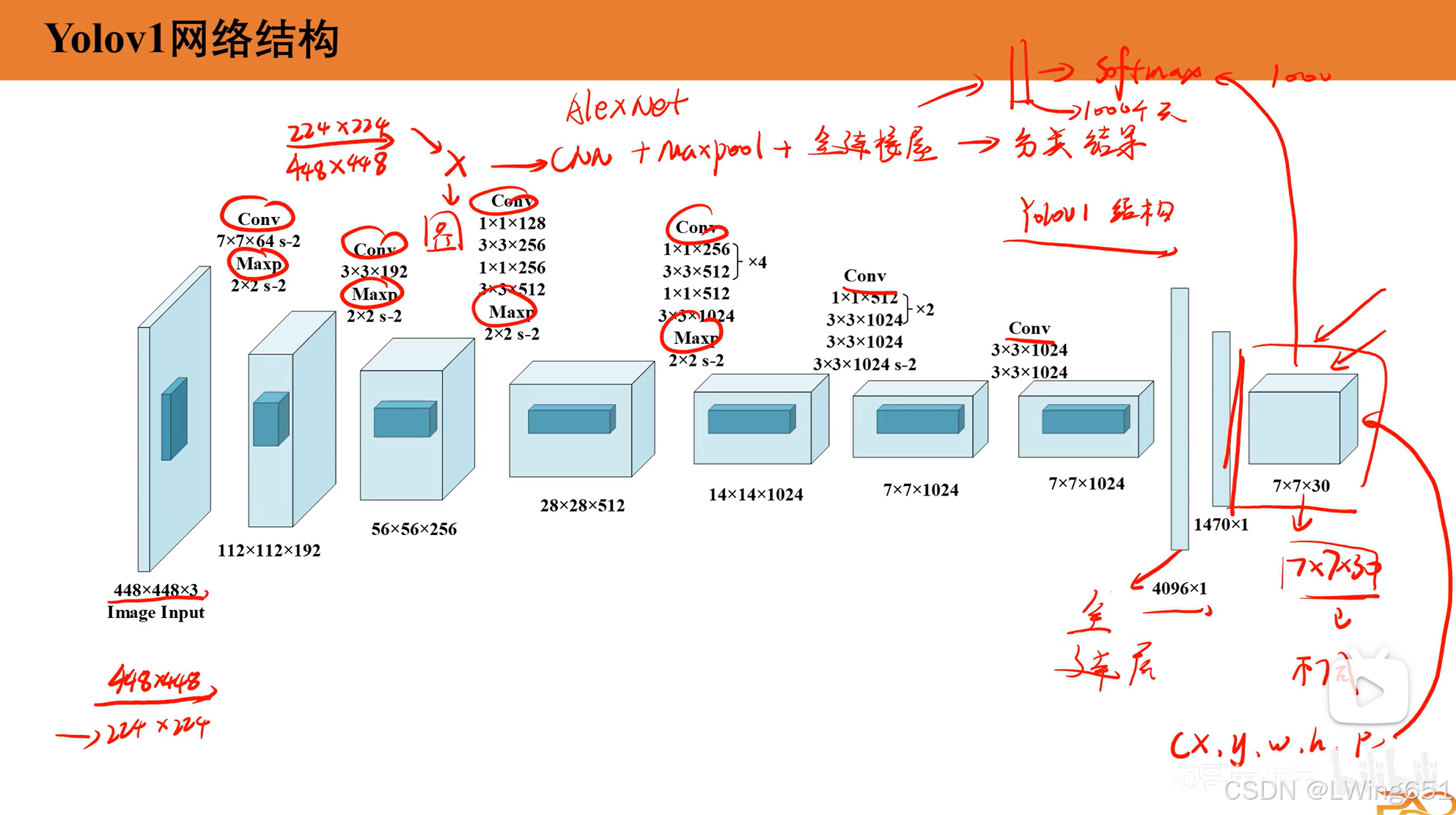
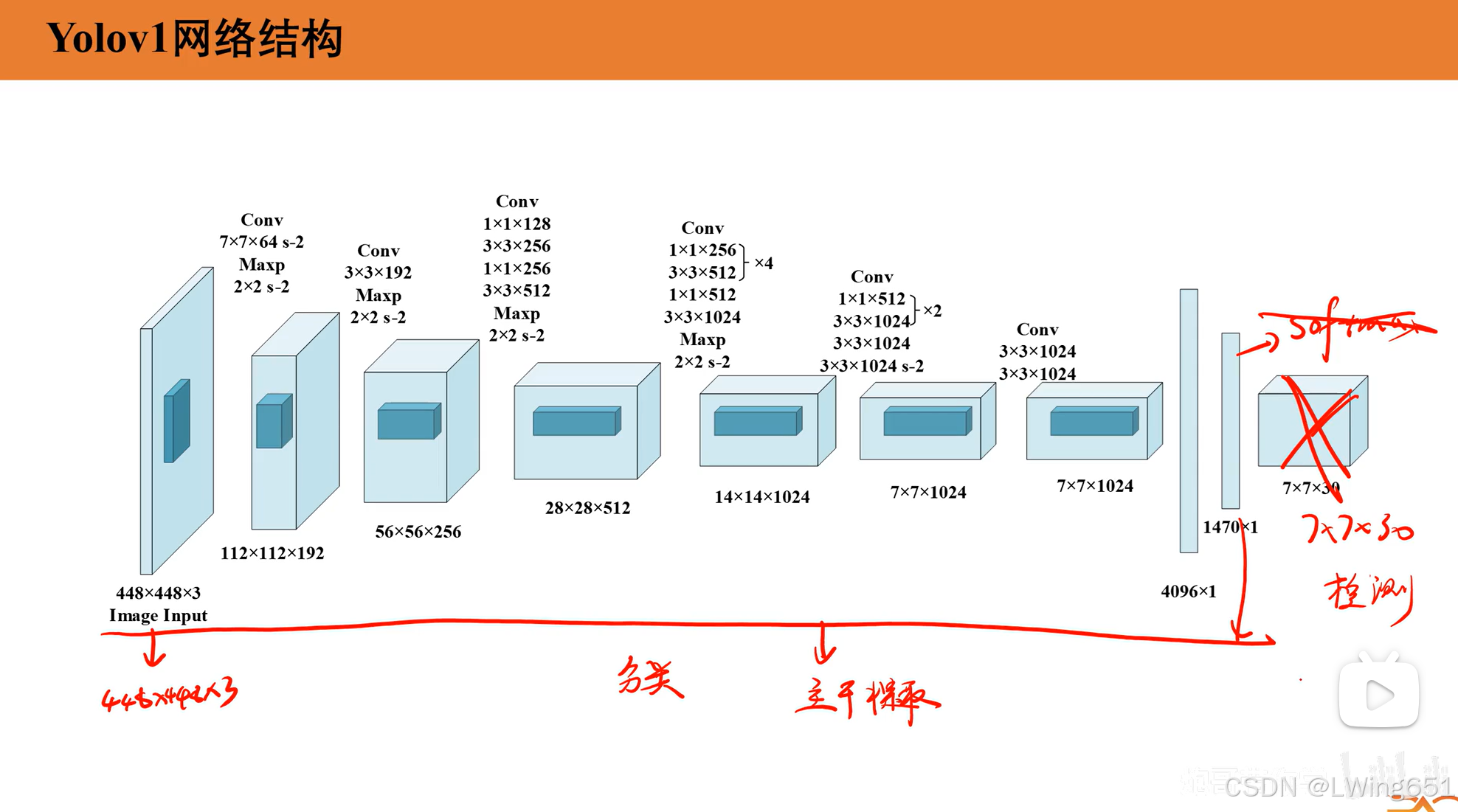 前面步骤和分类网络类似,最后步骤不同。
前面步骤和分类网络类似,最后步骤不同。
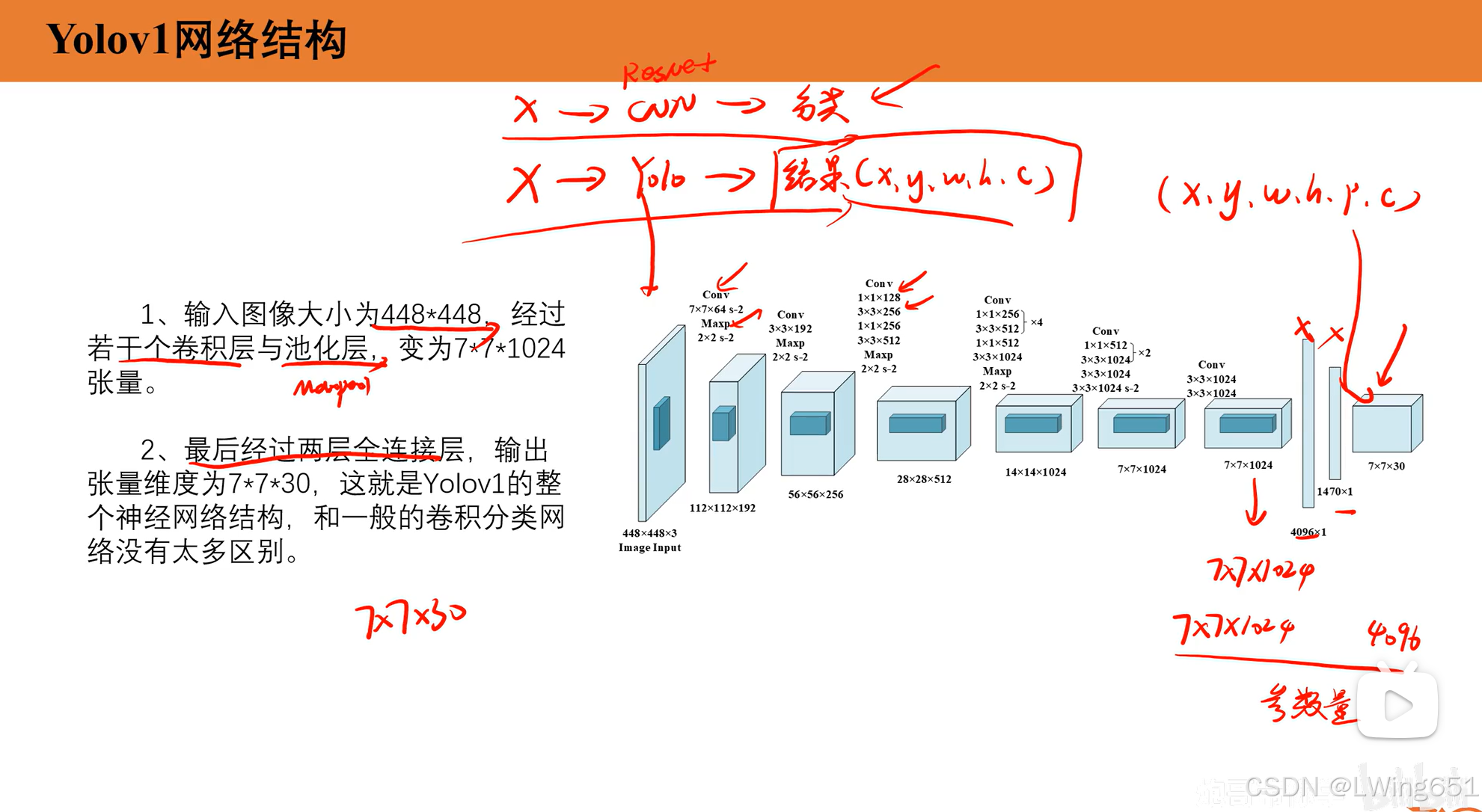
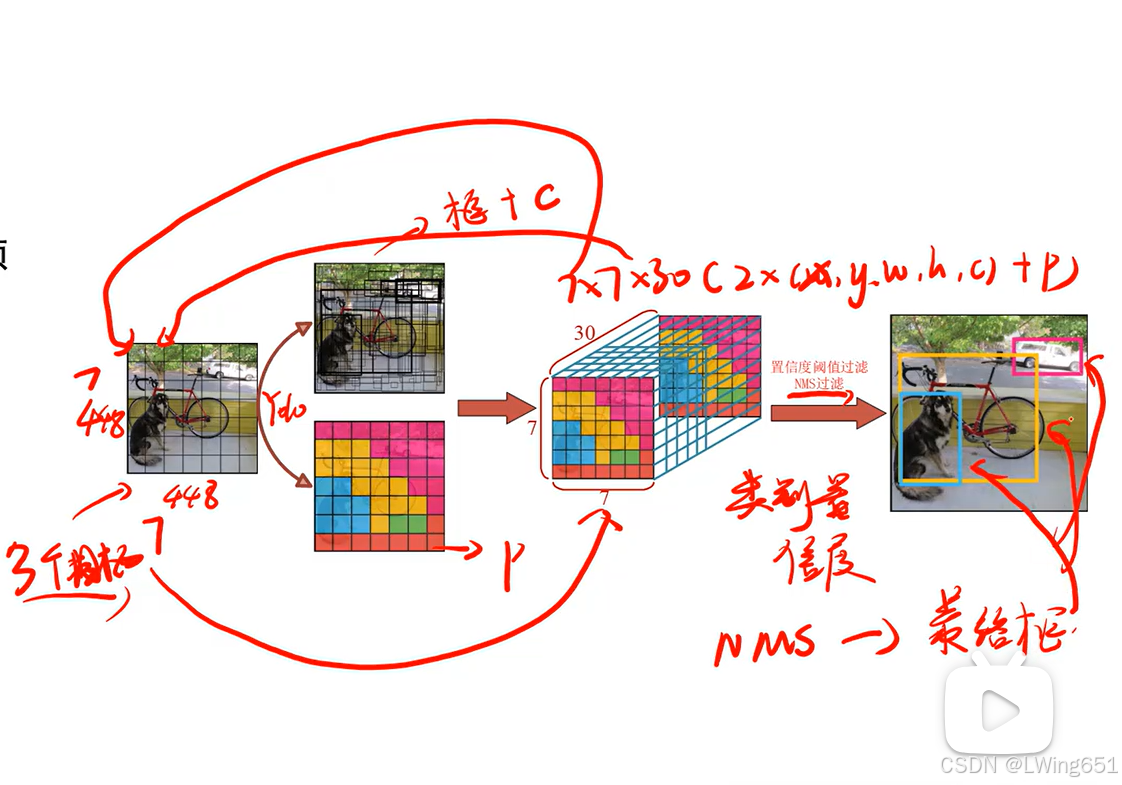
3.Yolov1结果解析
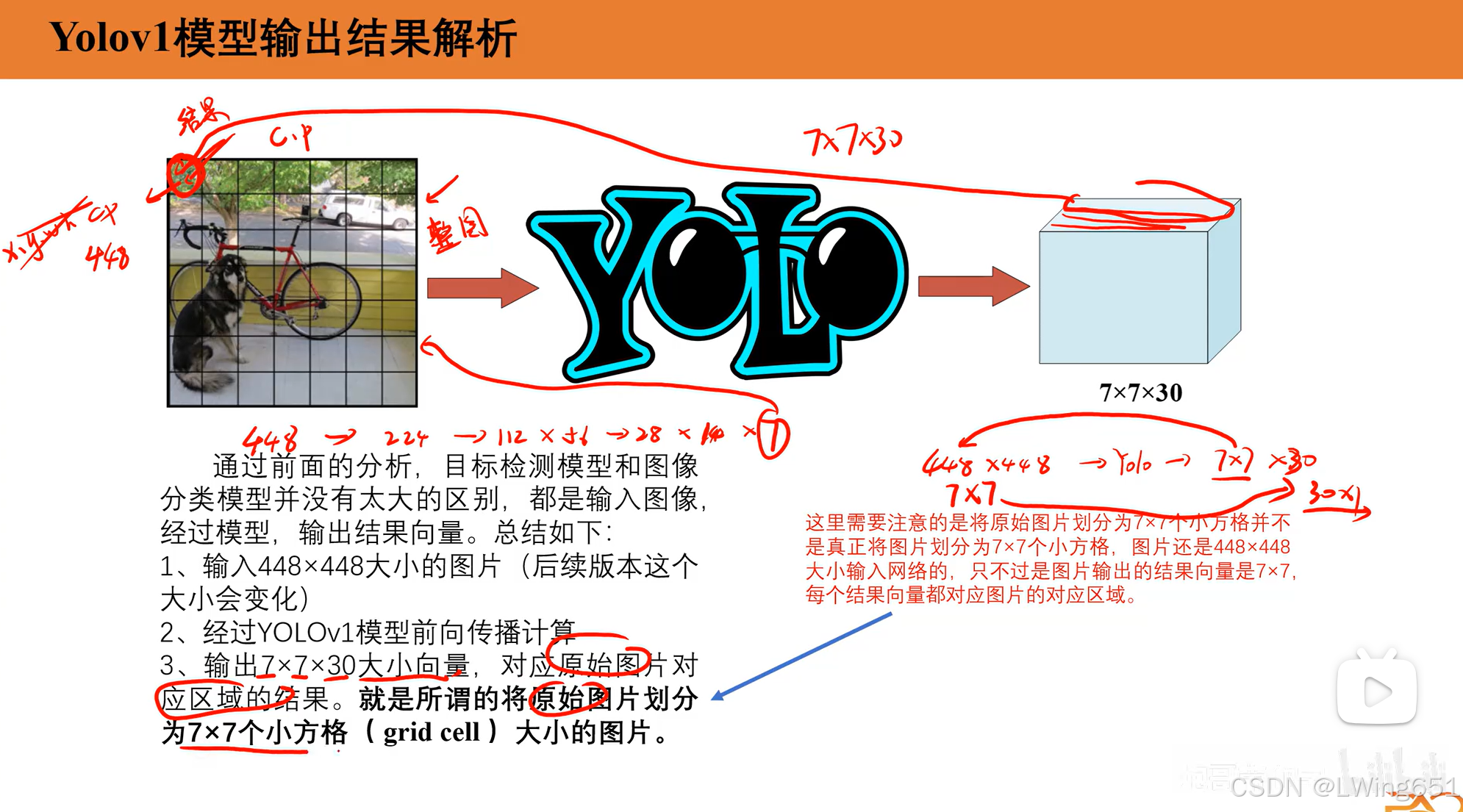
7×7 划分的具体含义
网格划分
- 输入图像被统一调整为 448×448的固定大小。
- 图像被分为 7×7=49个均匀的网格单元(每个网格的大小为 64×64像素)。
- 每个网格单元负责检测其中心点落在网格范围内的目标。
每个网格的预测内容
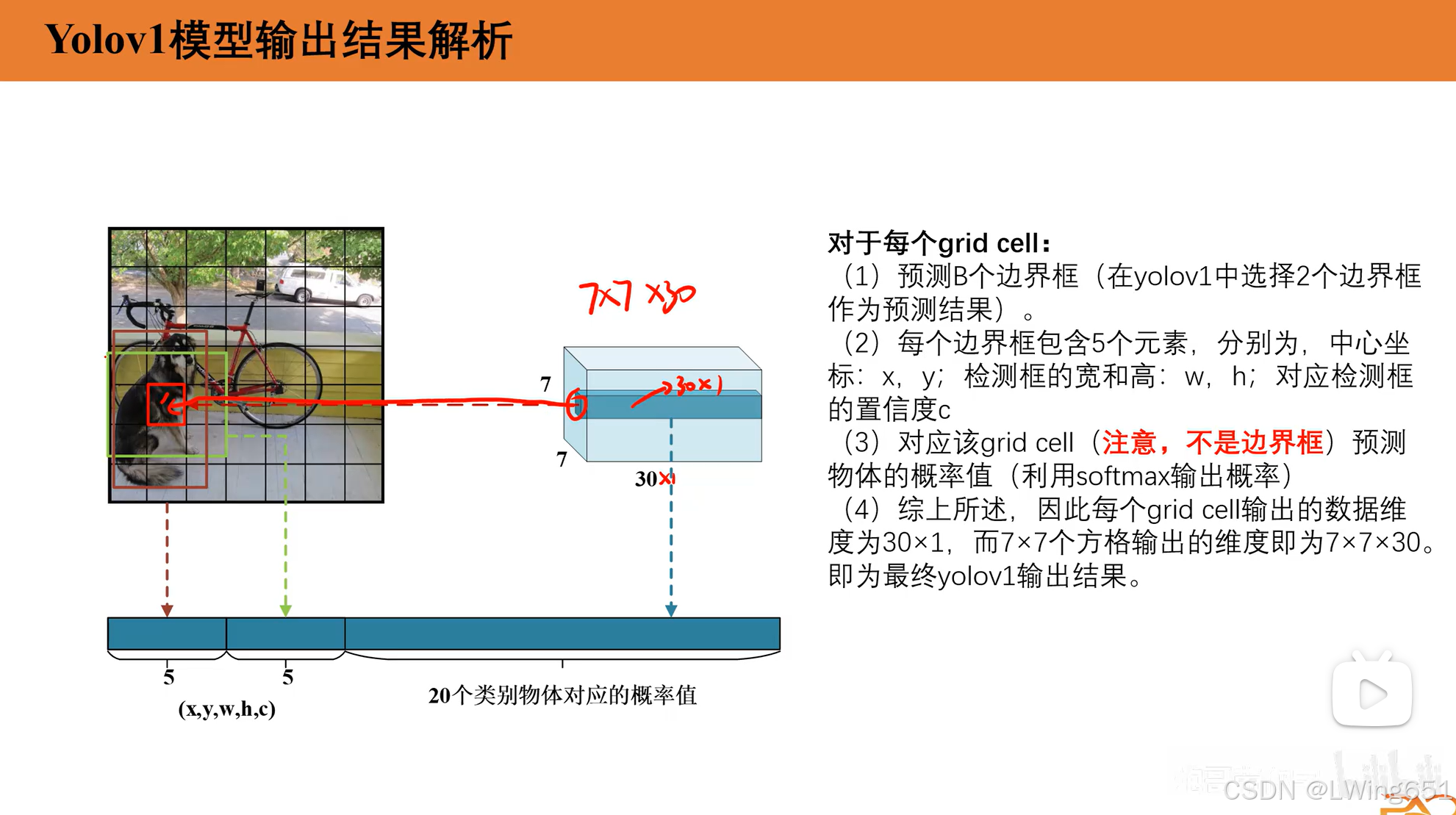
每个网格输出一个向量,包含以下信息:
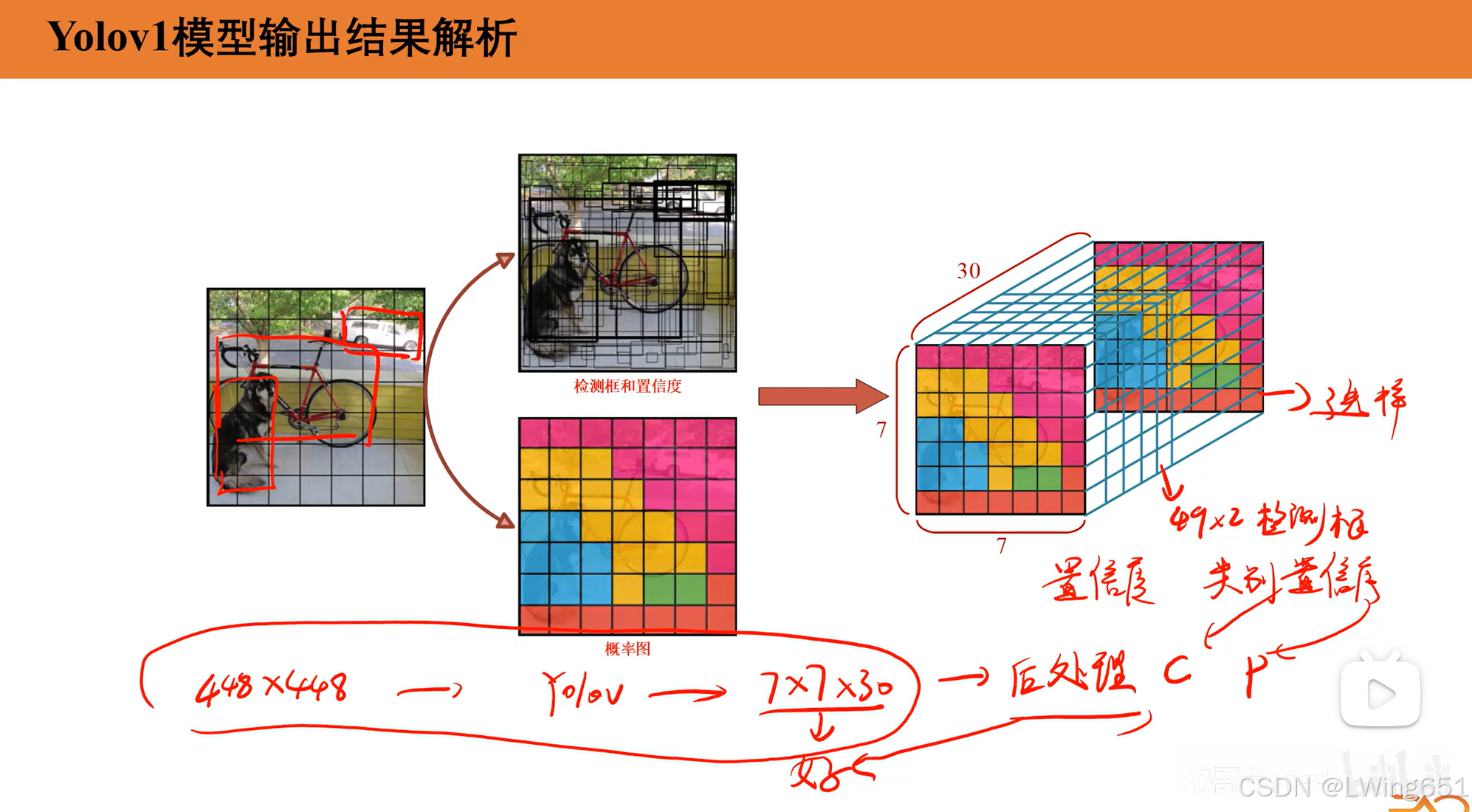
- 类别概率 (C):表示网格单元检测到某一类别目标的概率分布,常用于分类任务。(在 YOLOv1 中,输出向量的大小中 C=20,是因为在常用的目标检测数据集 Pascal VOC 中,有 20 个类别,这些类别定义了模型需要检测和分类的目标。)
- 边界框信息 (B×5):每个网格预测B个边界框,每个边界框包含:
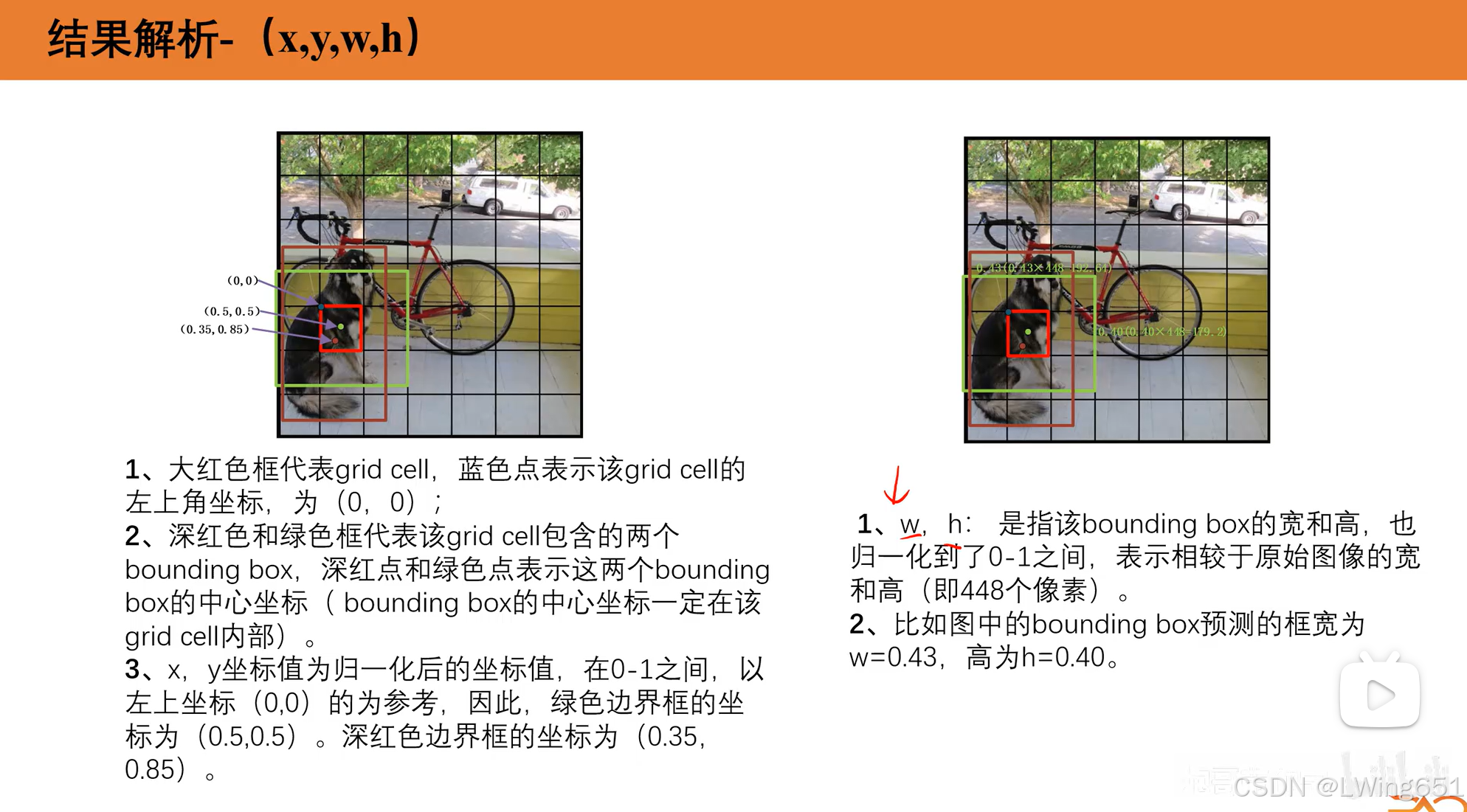
- x,y:边界框中心点相对于网格的归一化坐标。
- w,h:边界框宽度和高度,相对于整个图像的归一化值。
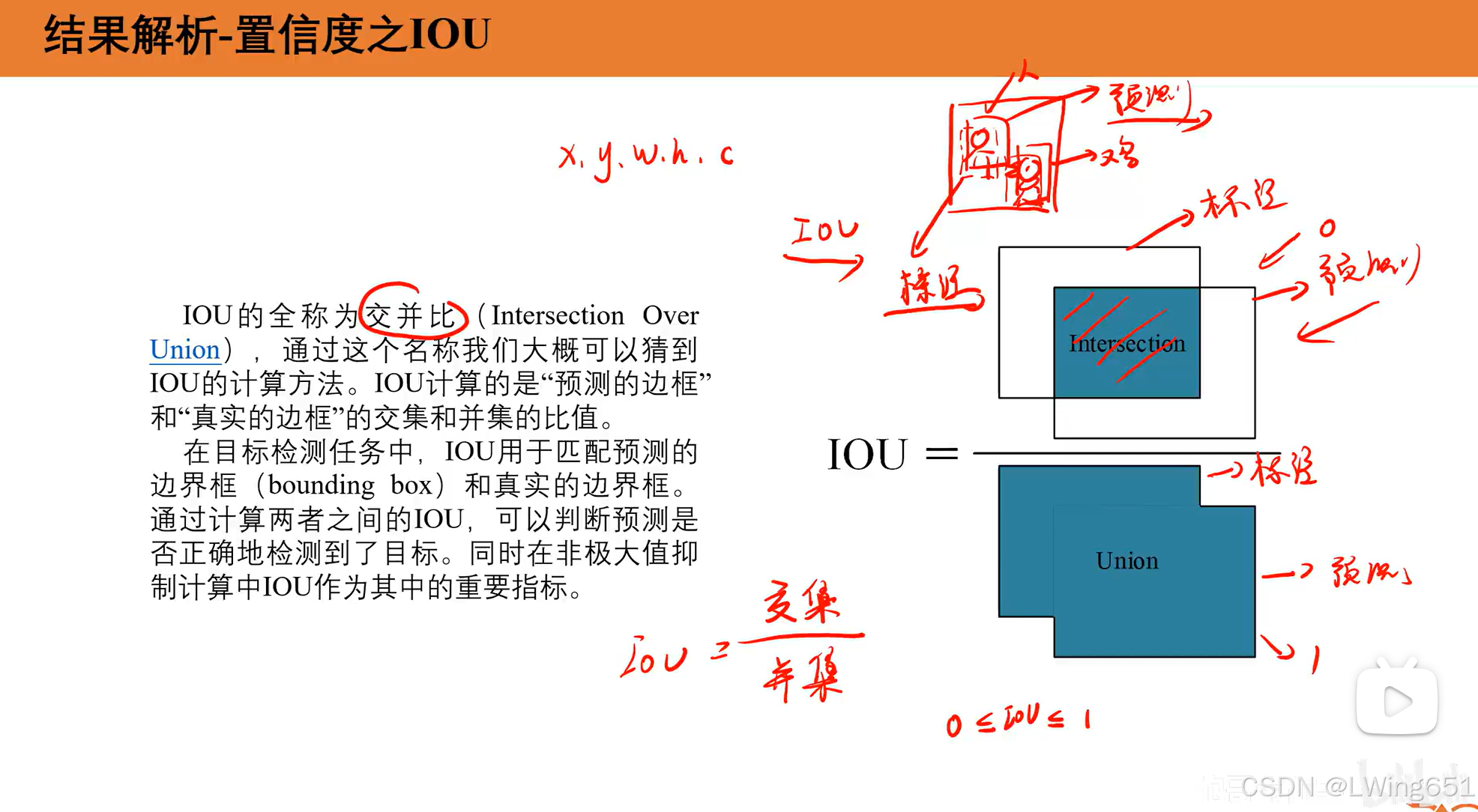
- confidence:边界框内是否有物体的置信度,表示为目标概率与边界框准确性的乘积。
输出向量的大小为:
S×S×(B×5+C)=7×7×(2×5+20)=7×7×30目标分配规则
- 如果目标的中心点落在某个网格内,则该网格负责检测该目标。
- 每个网格最多可以预测 BBB 个边界框,且每个边界框对应一个目标类别。
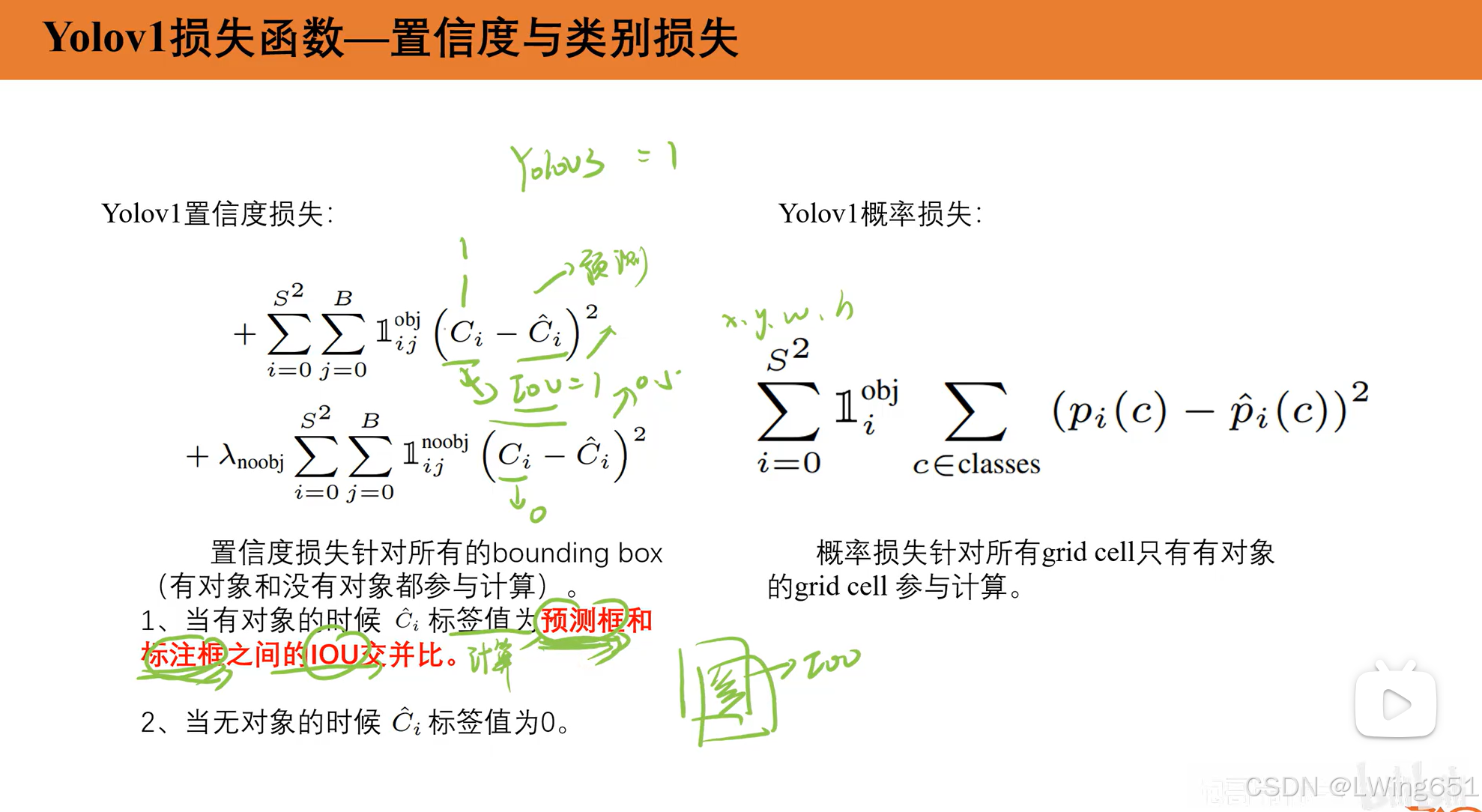
3.1置信度IOU
 3.2置信度
3.2置信度

3.3概率值
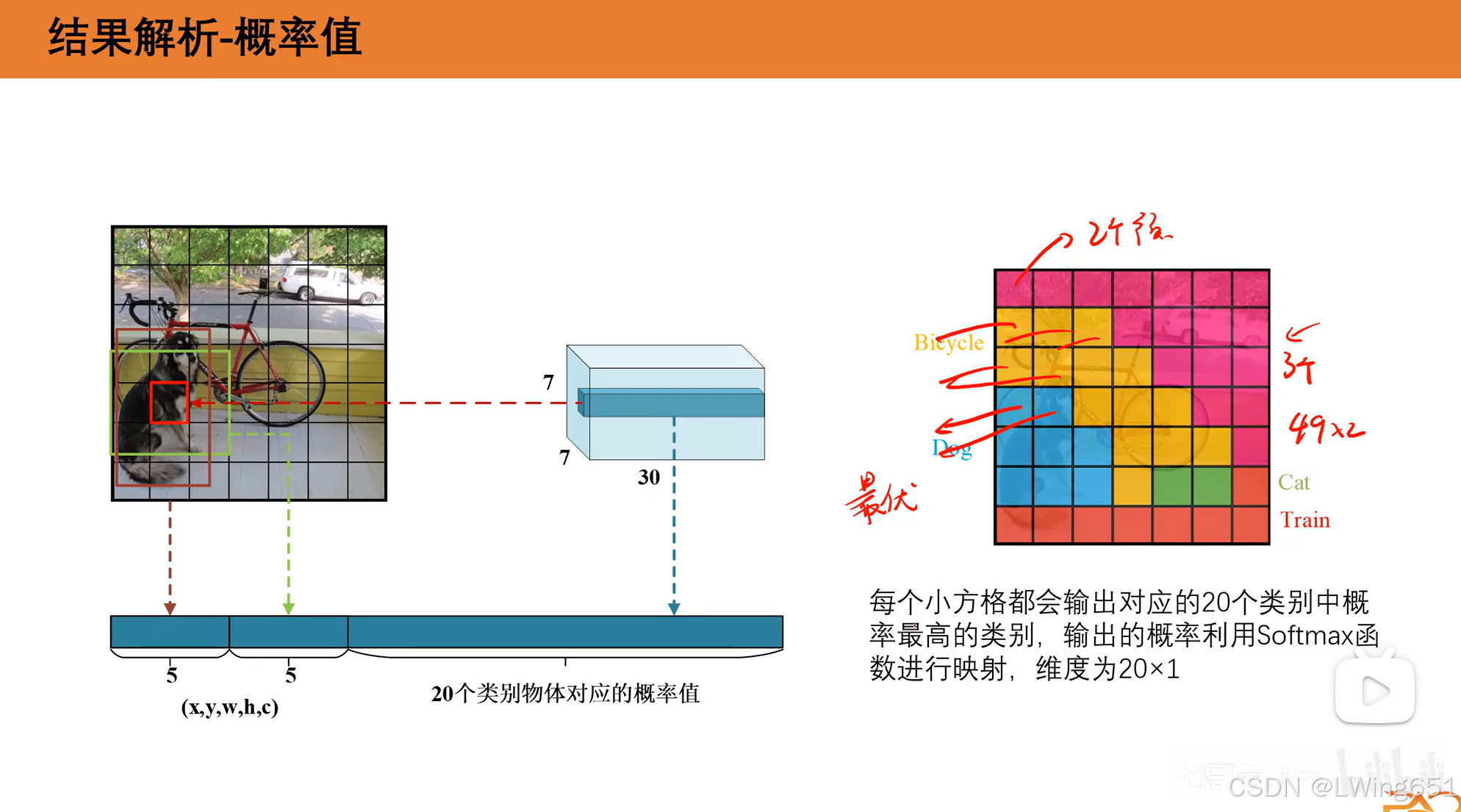
虽然有两个预测框,但是最后选择一个,可以增加准确性。
20个类别的概率之和为1。
3.4类别置信度


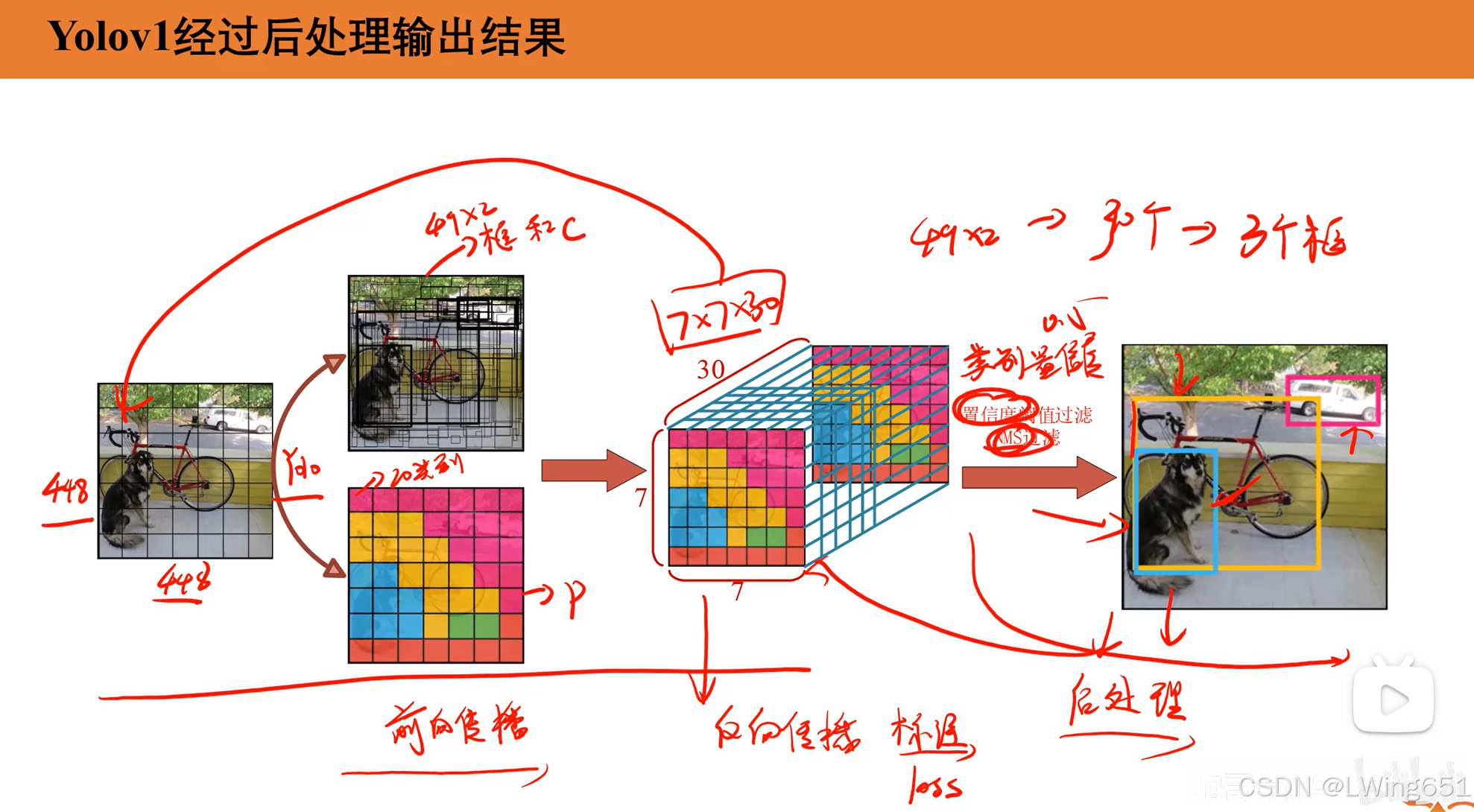
 3.5非极大值抑制NMS
3.5非极大值抑制NMS

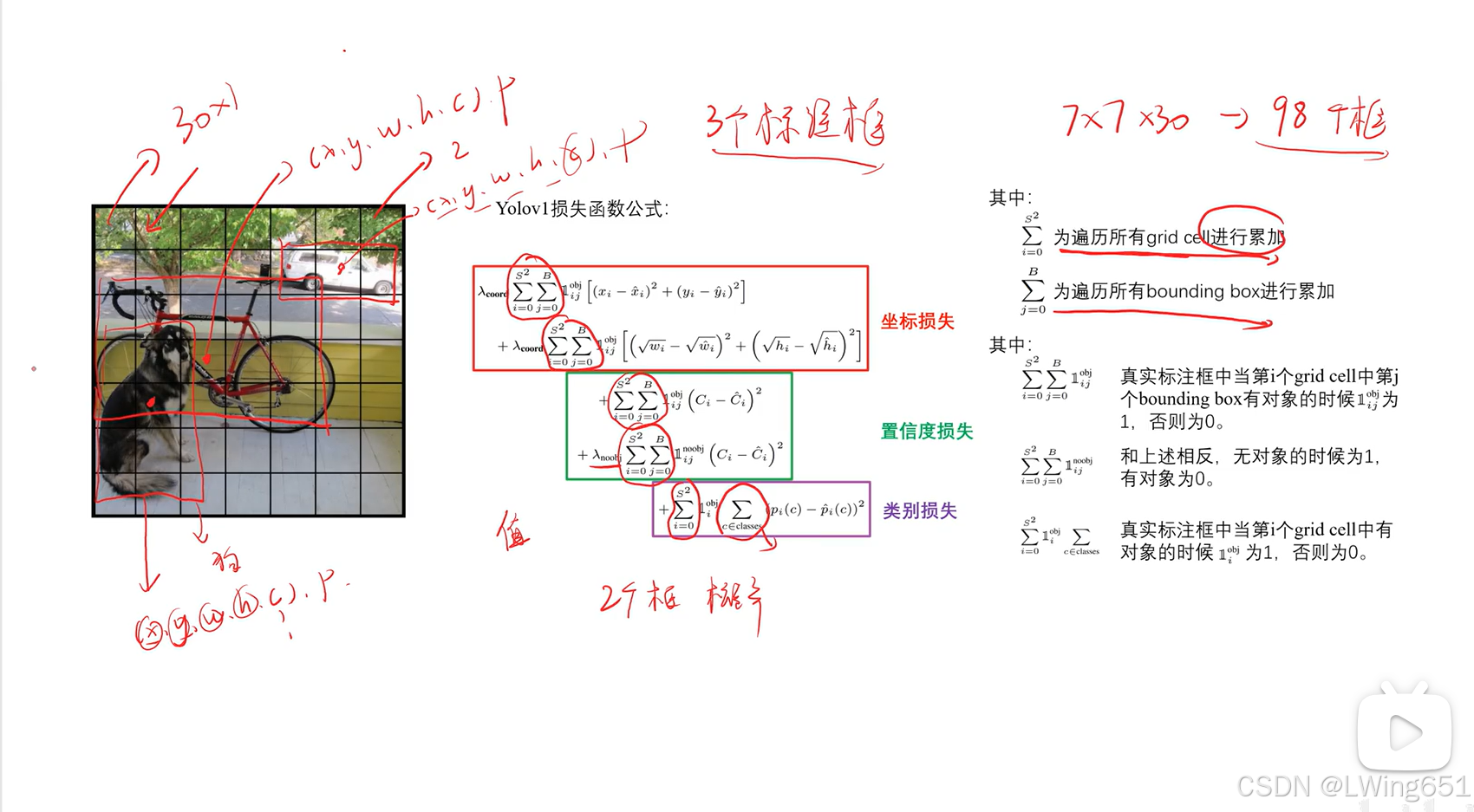
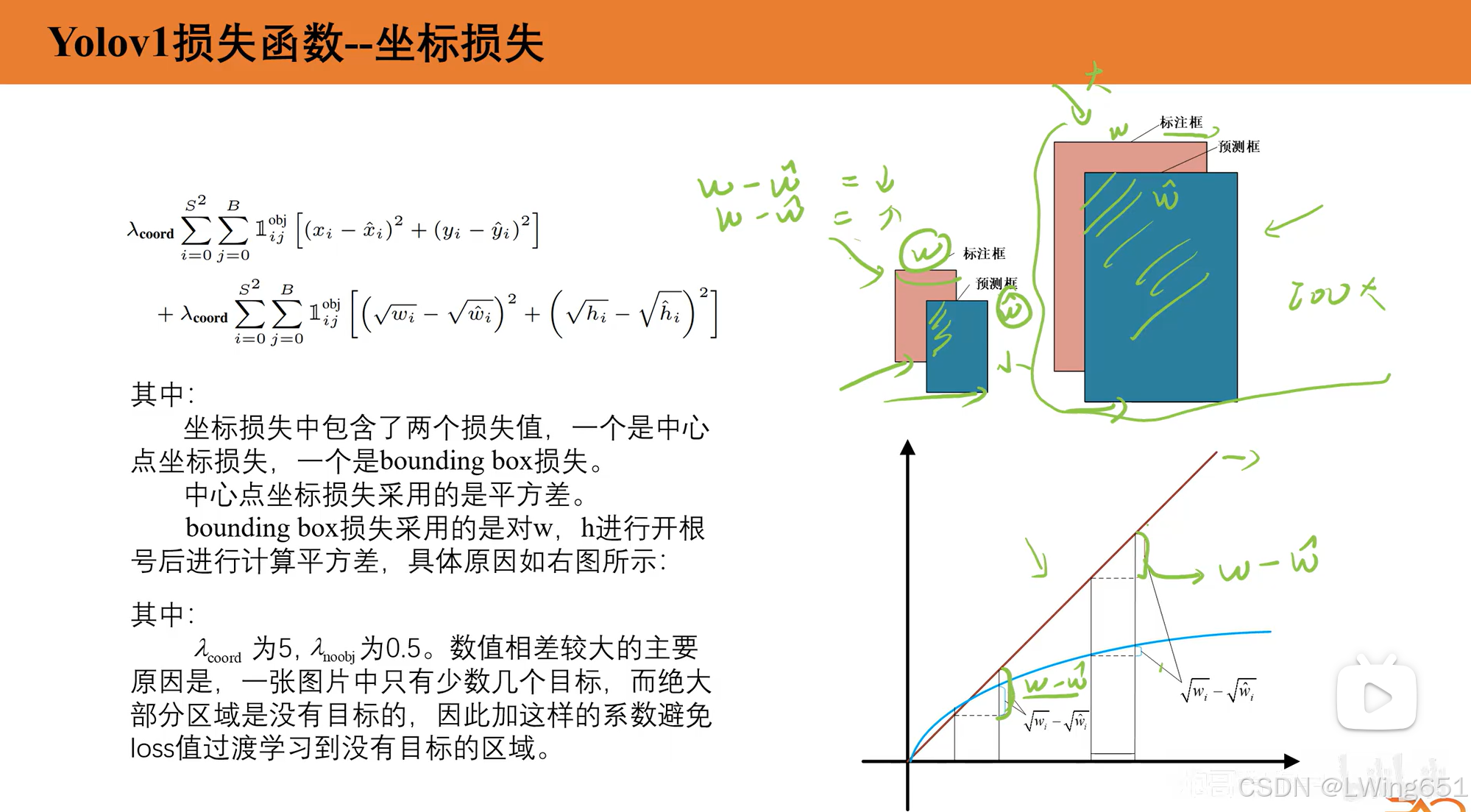
4.Yolov1损失函数
 5.Yolov1训练过程
5.Yolov1训练过程
 Yolov1可以做分类,也可以做目标检测。
Yolov1可以做分类,也可以做目标检测。

6.总结
更多推荐


 38
38 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)