
存储不够用?镜像不会保存?那是你还没学会这招!
摘要:本文提供了一套在CCI平台上实现「数据持久化+环境复用」的完整解决方案。针对存储不足和环境迁移两大痛点,通过开通大容量存储(数据持久化)和私有镜像仓库(配置保存)实现:1)容量可扩展的持久化存储,避免数据丢失;2)环境配置一键复用,单卡/多卡切换无需重复安装。详细演示了从0卡开发到8卡训练的全流程,包括存储挂载、环境配置、资源调整和镜像保存等关键步骤。该方案支持灵活调整资源配置,大幅提升开发
用 CCI 跑模型时,你是不是也被这俩问题卡过?
- 自带 50G 存储根本不够用,下一个大模型就直接满了,数据删也不是、留也不是;
- 单卡调完环境想迁到多卡,结果镜像不会存,之前的配置全白费,又得从头装…
别慌!今天就给大家一套「数据不丢 + 环境复用」的解决方案,从开通配置到多卡迁移,一步一步跟着走就行~
核心要点:
- 使用平台的大容量存储进行持久化,无需担心存储不够!也不用担心容器释放后数据消失!
- 使用平台的镜像仓库,管理私有镜像仓库,随时把想要的配置拿出来用!
- 先搞定 2 个关键前置:大容量存储 + 镜像仓库
这俩是解决问题的核心 —— 存储负责 “持久化存数据”,镜像仓库负责 “保存配置”,先开了再开发,后续少踩坑!
- 大容量存储:数据再也不怕丢 ,再也没有容量焦虑
- 操作路径:找到「存储管理」→ 点击「开通新存储」;
- 关键选择:选对应的存储类型(按项目需求)、填需要的容量(比如模型大就多开点),点开通;
- 放心点:开通后在存储列表能直接看到,后续不够用还能随时扩缩容,容器关了或释放了,里面的数据也不会消失!
- 私有镜像仓库:环境配置随用随取
- 操作路径:进入「AI 资源」→ 找到「镜像仓库」→ 选择「私有镜像」→ 点击「去开通」;
- 关键选择:选好需要的容量和对应的智算中心,确认开通;
- 优势:后续调好的环境存成镜像,下次不管是单卡还是多卡,直接调镜像就能用,不用重复装依赖!
Step1.1 开通大容量存储
- 点击开通新存储:
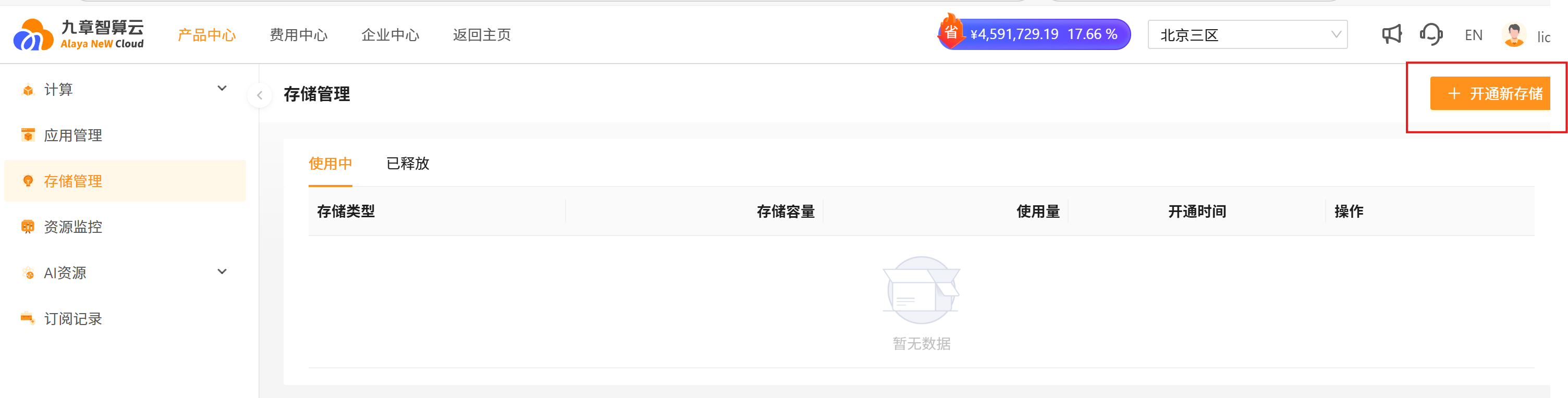
- 选择需要的存储类型以及存储容量,点击开通:
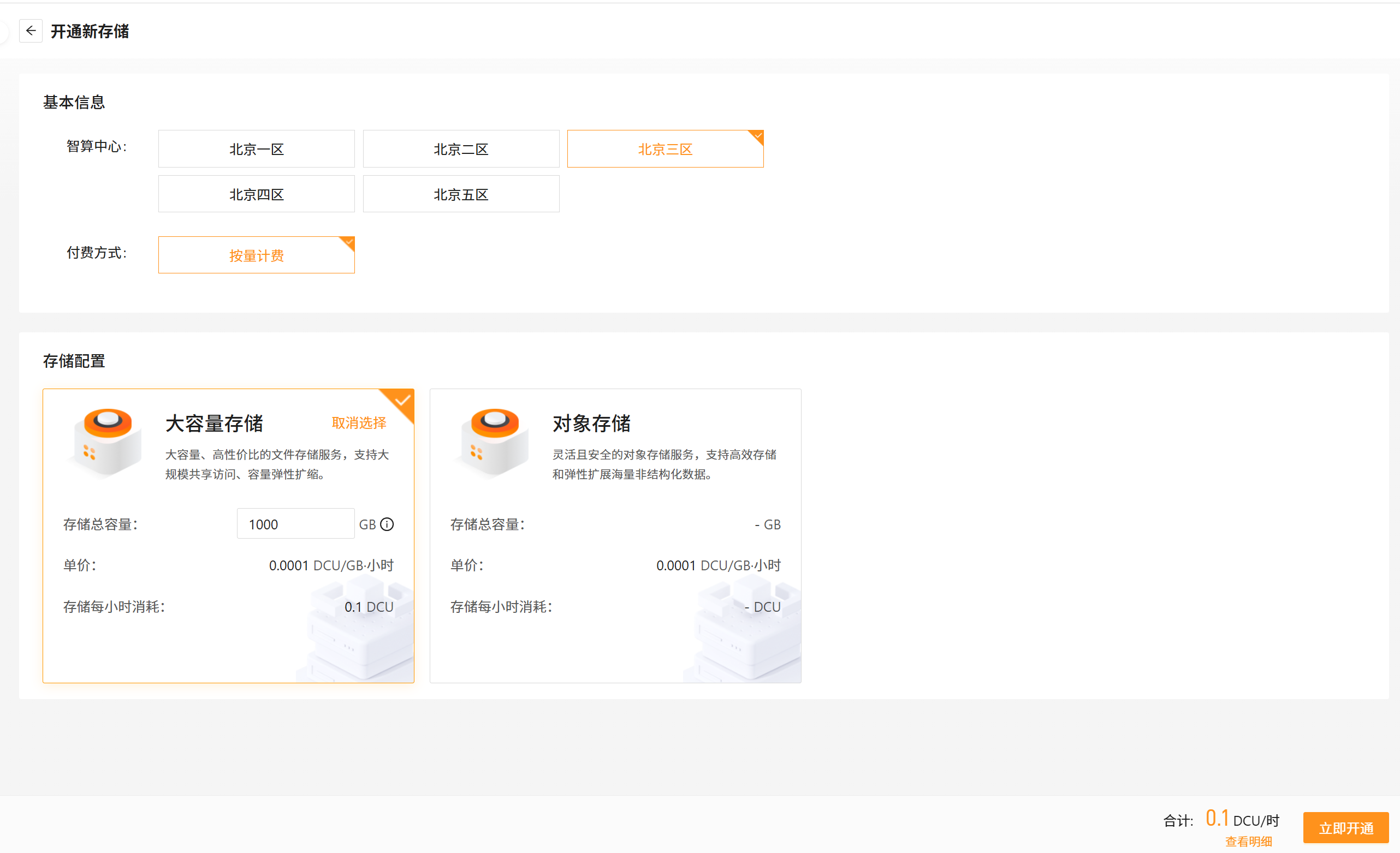
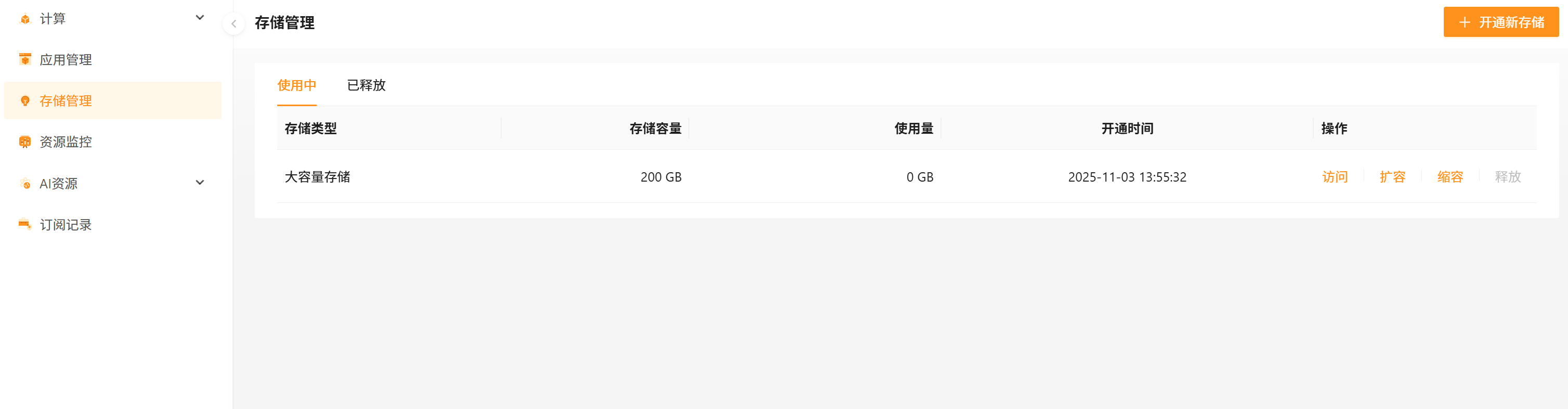
- 开通后即可查看到开通的存储,可随时进行扩缩容和管理
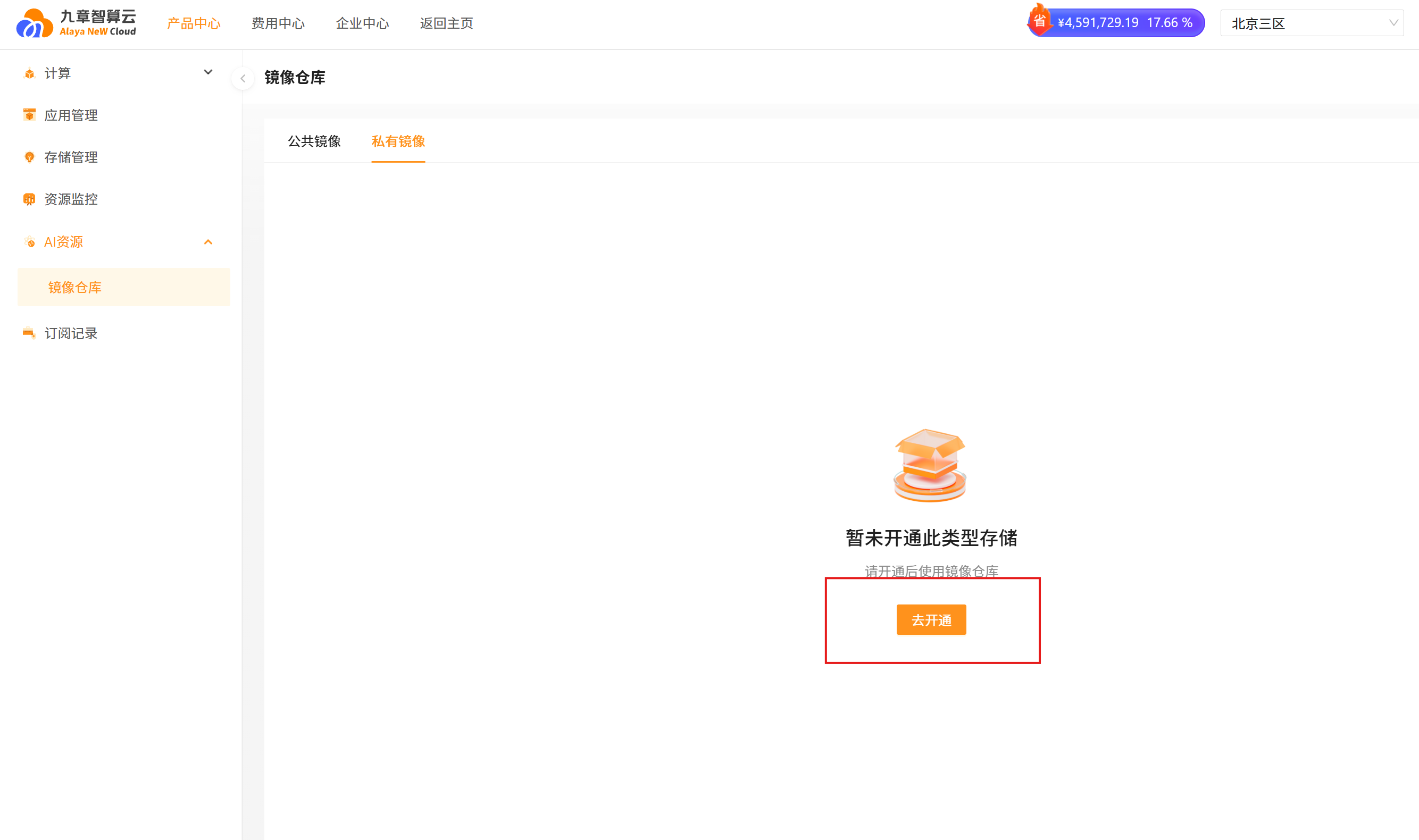
Step1.2: 开通镜像仓库
- 找到AI资源 - 镜像仓库 - 私有镜像,点击去开通:
- 选择想要开通的容量和智算中心,点击开通:
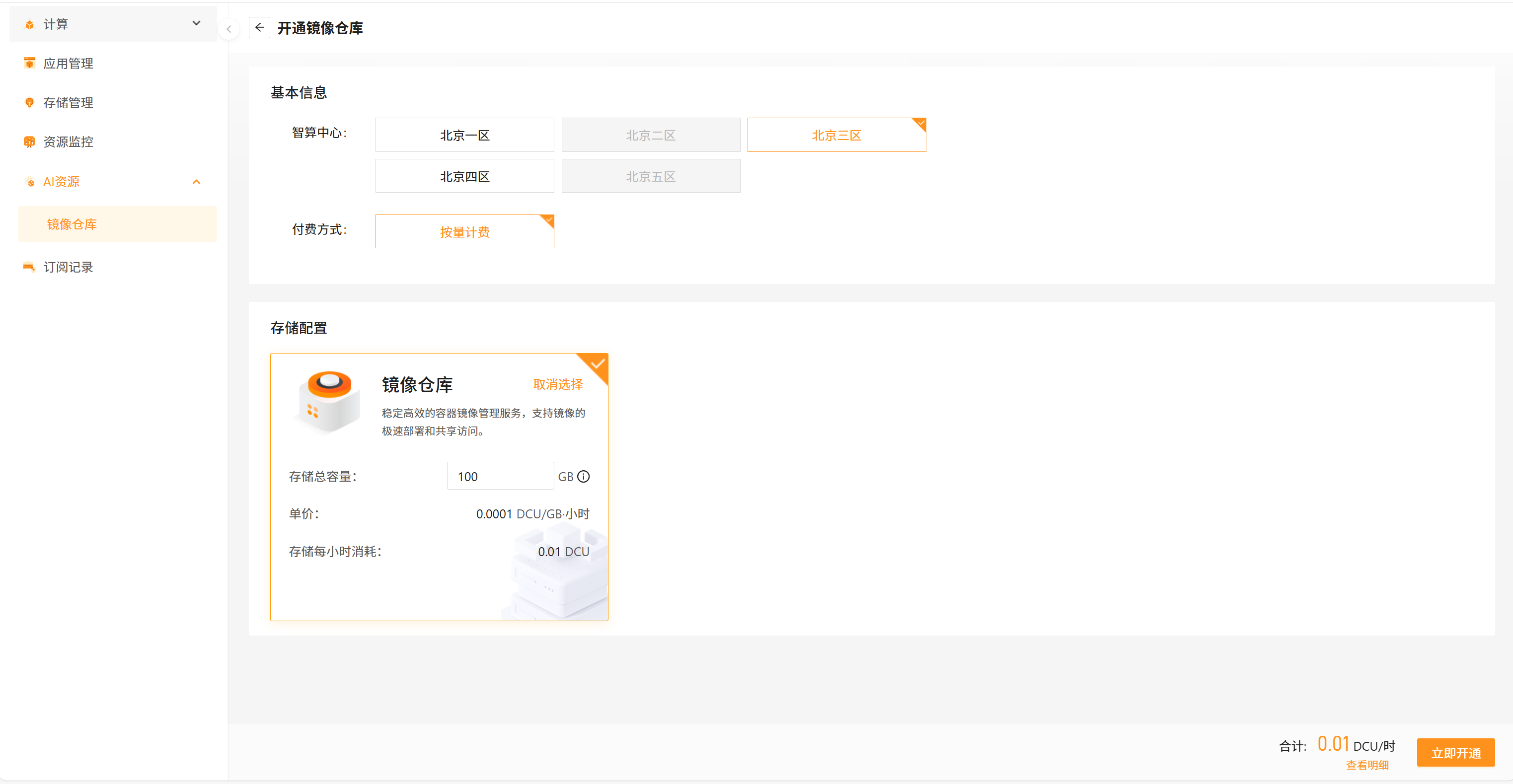
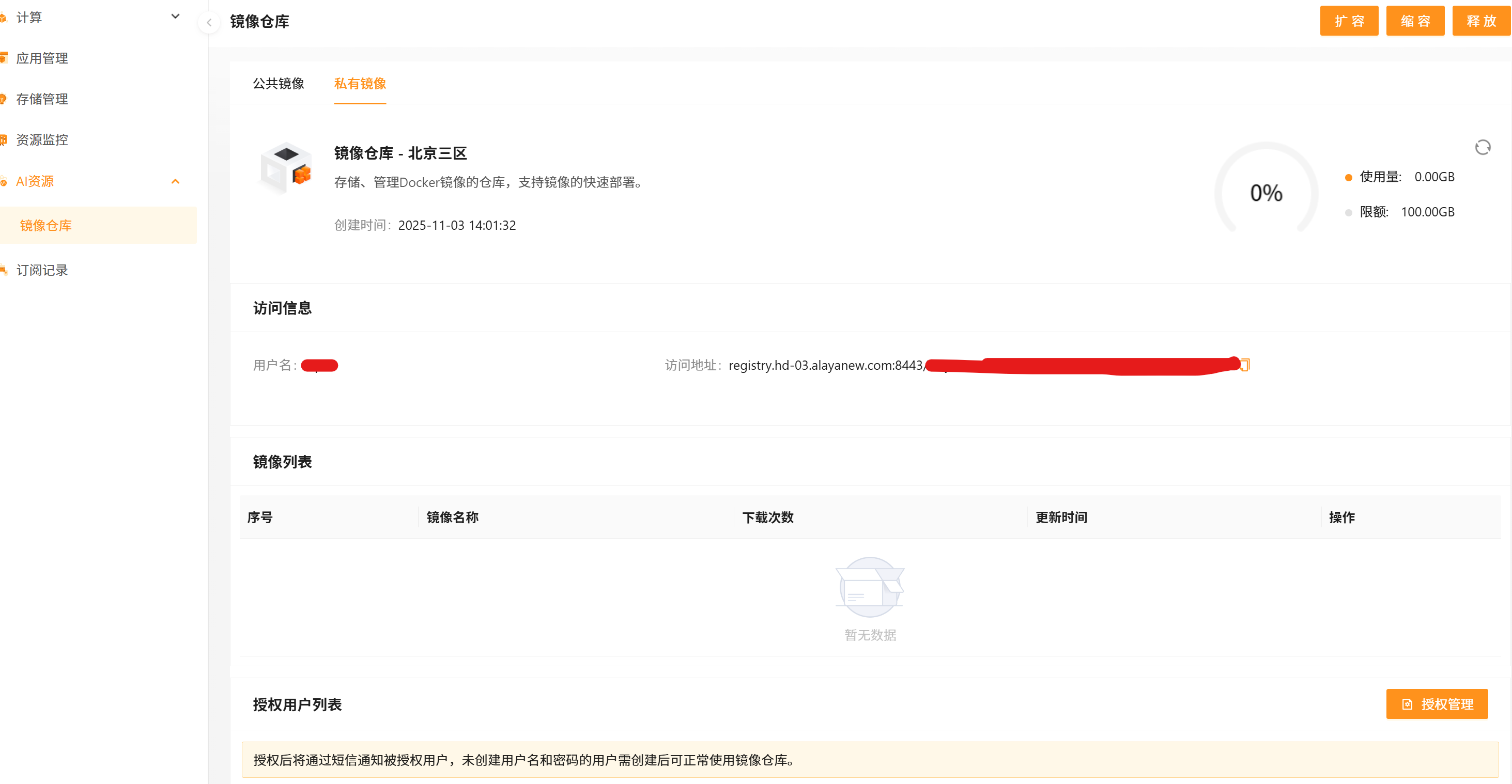
- 开通后可随时进行管理和调整:
- 从 0 到 1 开发:0卡开发 → 单卡微调 → 8 卡训练全流程
Step2.1: 开通一个0卡的云容器实例,进入云容器实例
- 进入 CCI 控制台,点击「创建新云容器实例」:
- 填基本信息(比如实例名称)、选资源规格(刚开始用 0 卡 / 1 卡足够):
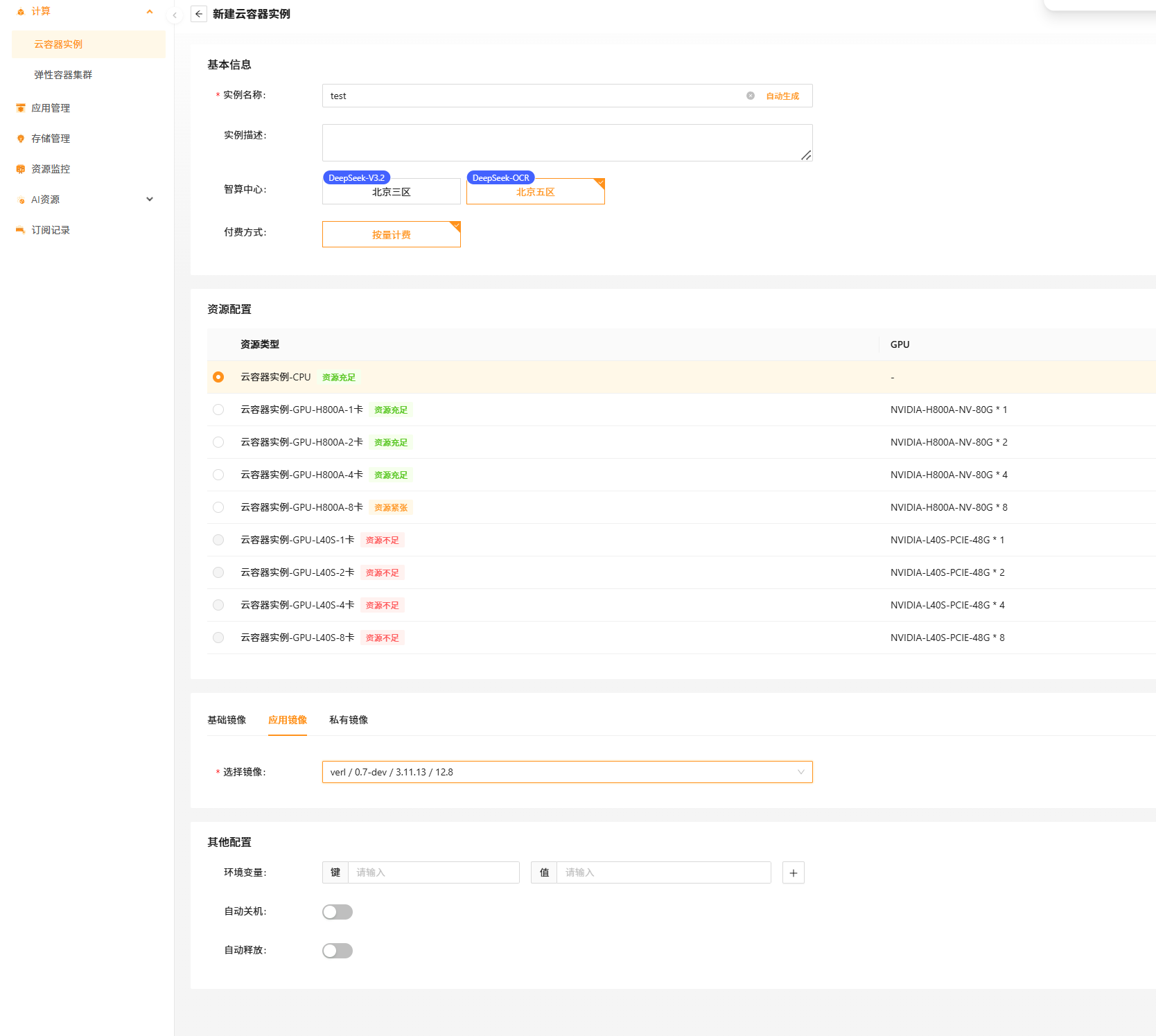
填入基本信息、选择资源,选择预置镜像,即可开通CCI(此处选择的预置强化学习镜像verl)
- 开通后即可查看到,并且可通过Jupyter/web terminal/ssh等方式访问:
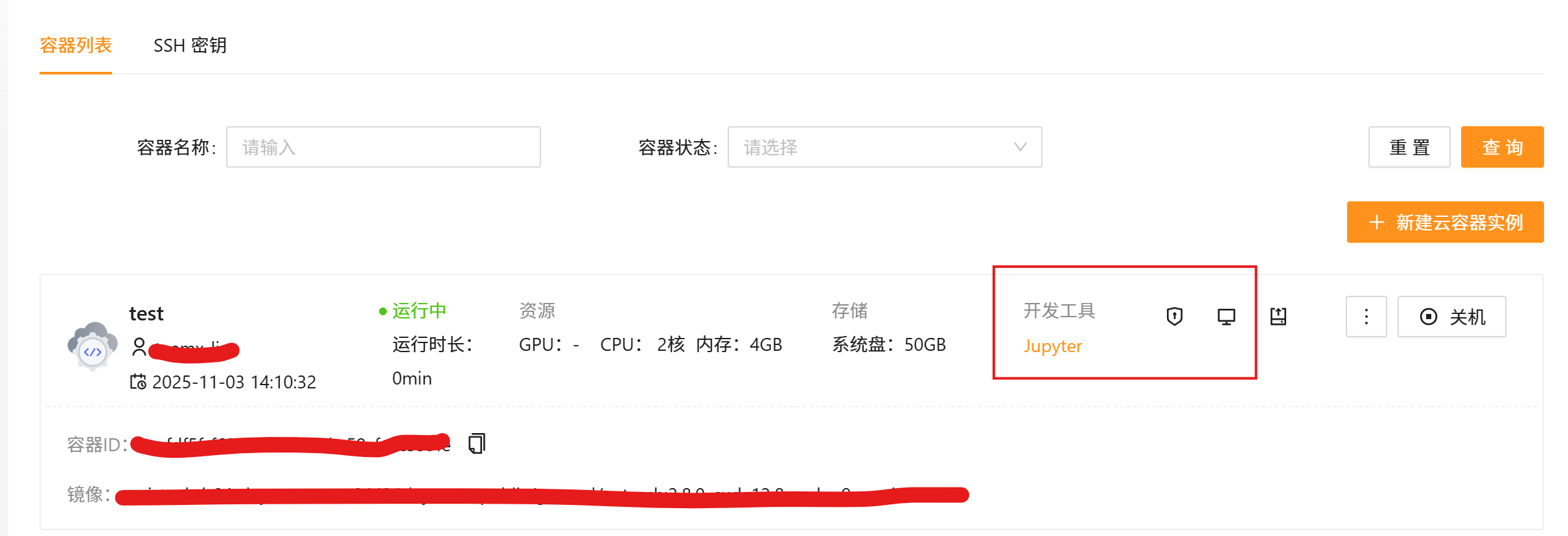
Step2.2 进入挂载的大容量存储、将代码与模型等保存在里面
- 进入实例后,直接把代码、模型文件移动到「userdata 目录」 ,即可实现持久化存储。
在「userdata 目录」下的数据,容器实例关机或释放均不会被删除:
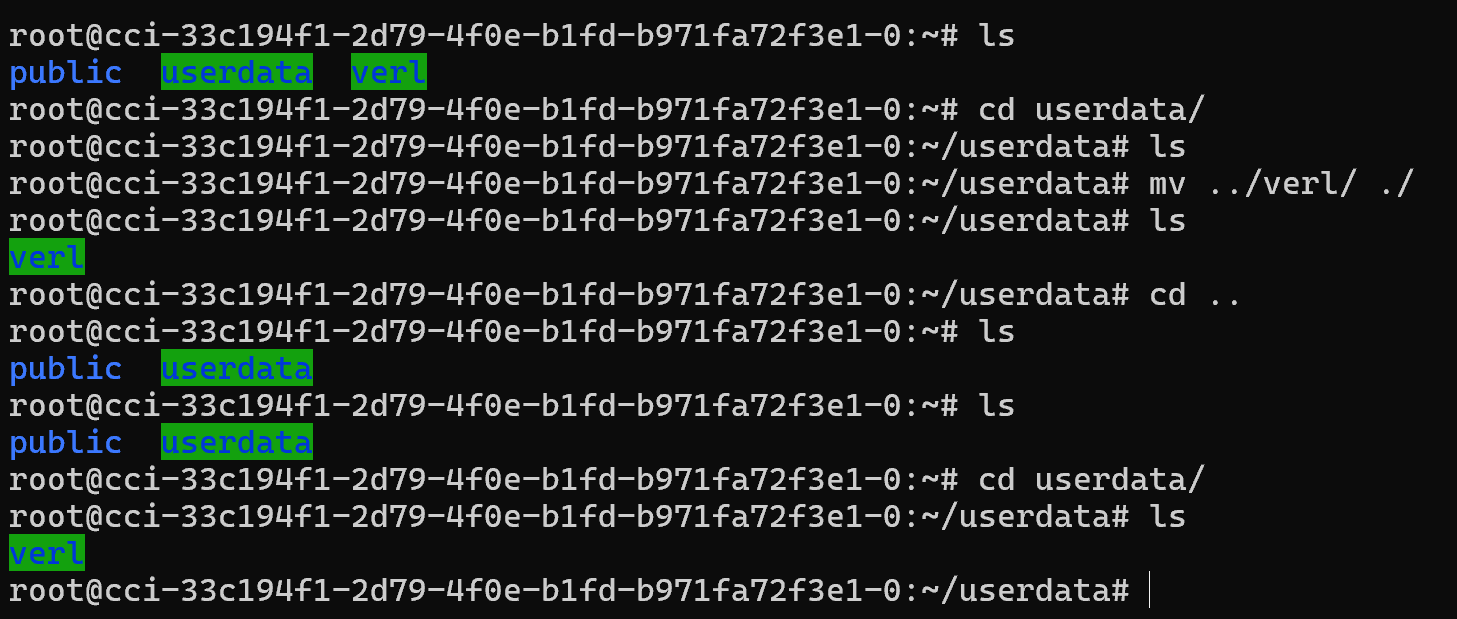
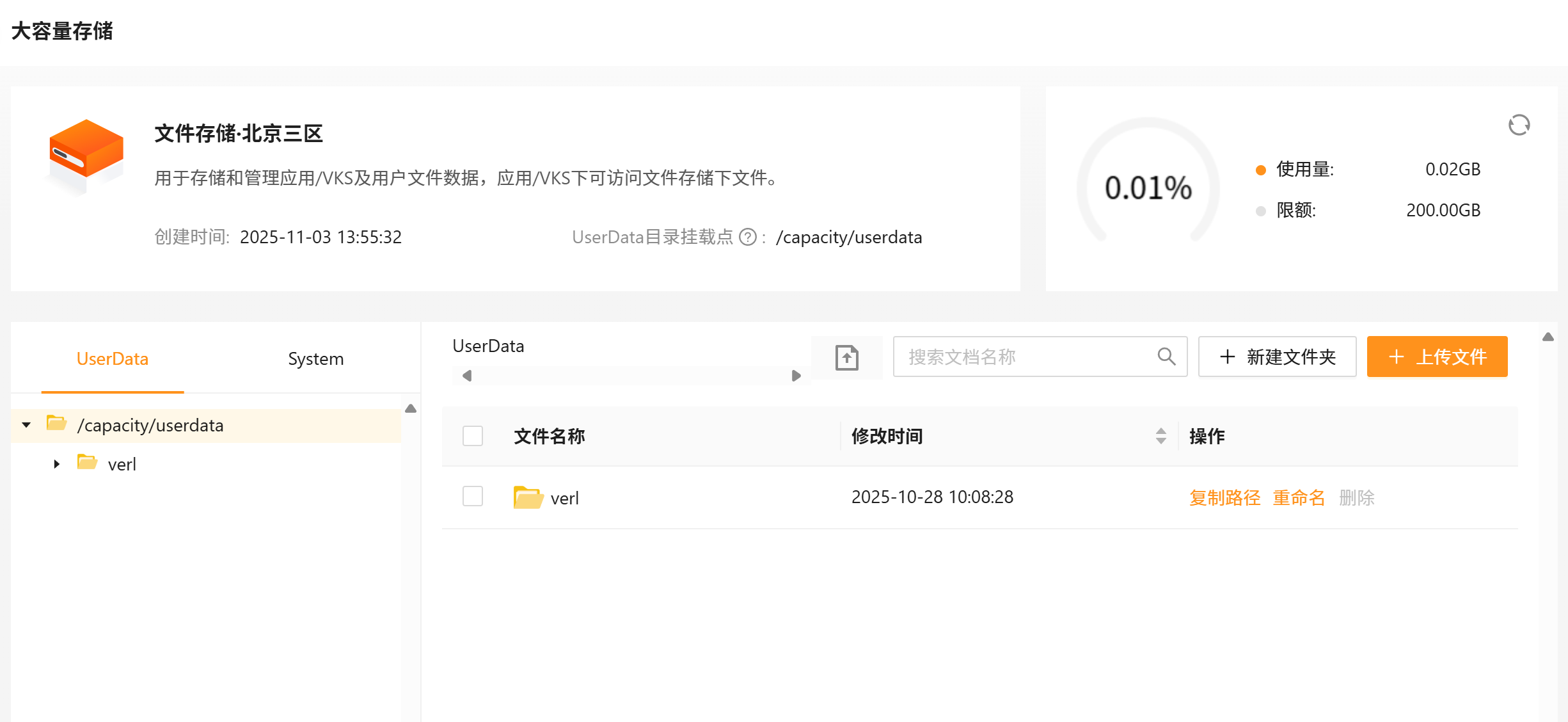
同时在大容量存储中也可查看到相关数据
Step2.3 开始安装相关环境
- 按照实际情况配置相关环境,如python,npm等
Step2.4 更换1卡资源,重新进入容器实例
- 先将容器实例关机,关机后重新点击开机
放心,关机只释放资源,数据不会删;释放实例才会删除数据。另外,关机了之后的容器实例不计费哦,不用着急,慢慢操作~
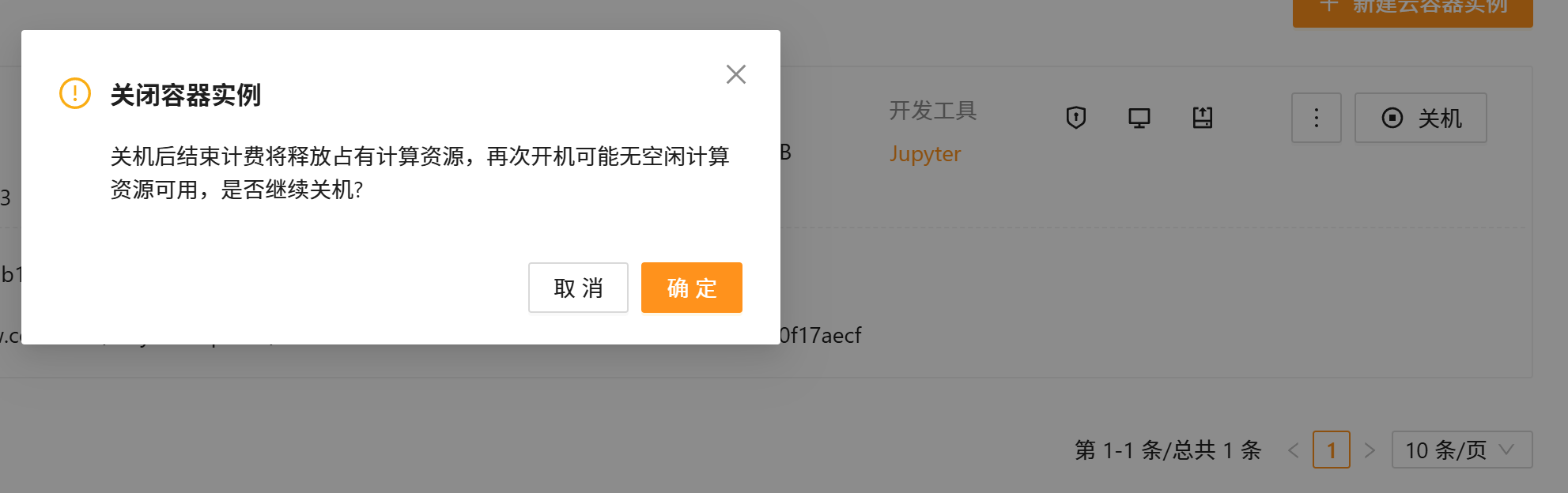
- 点击「开机」,弹框里选「调整资源规格」,把显卡改成 1 卡;
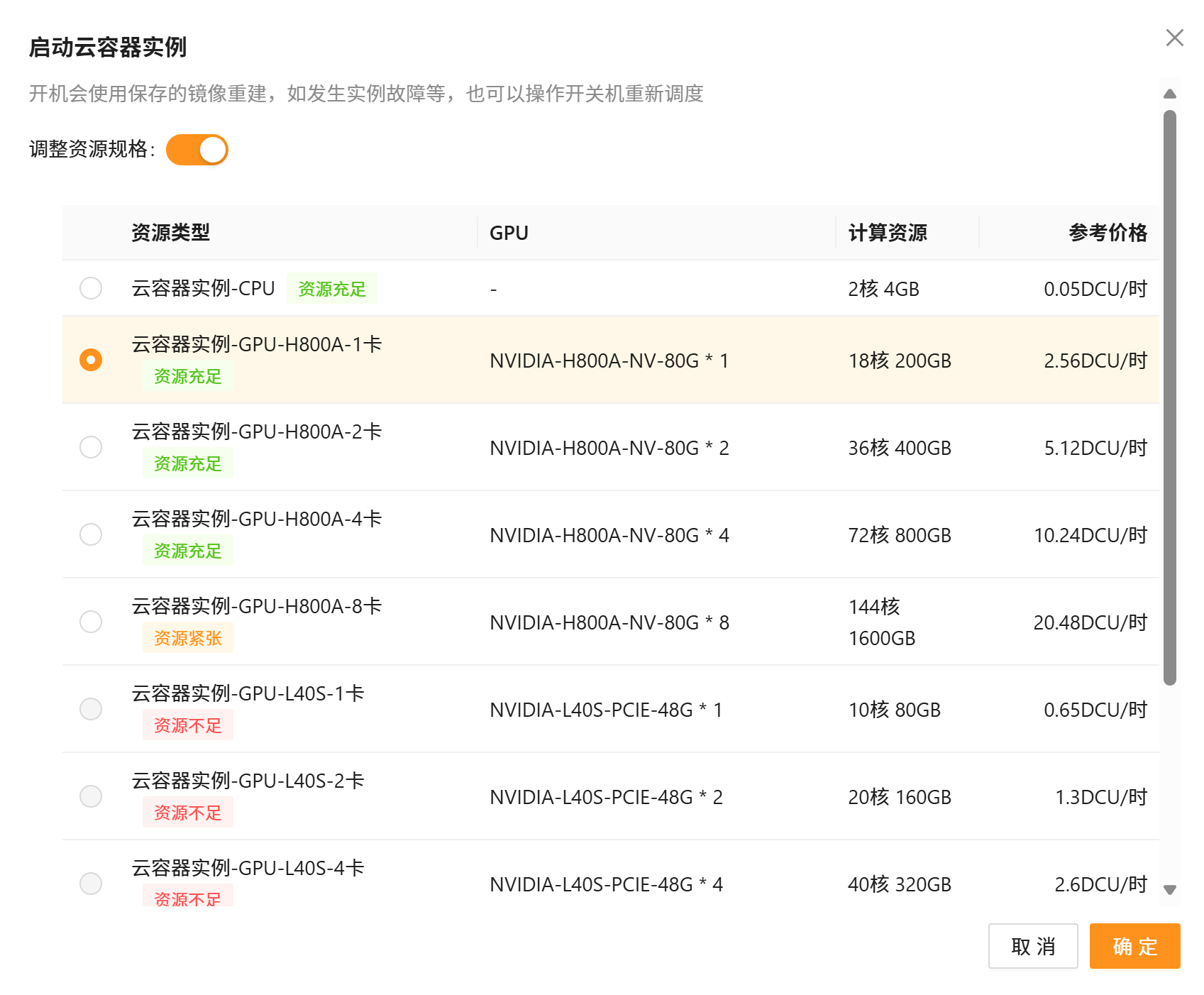
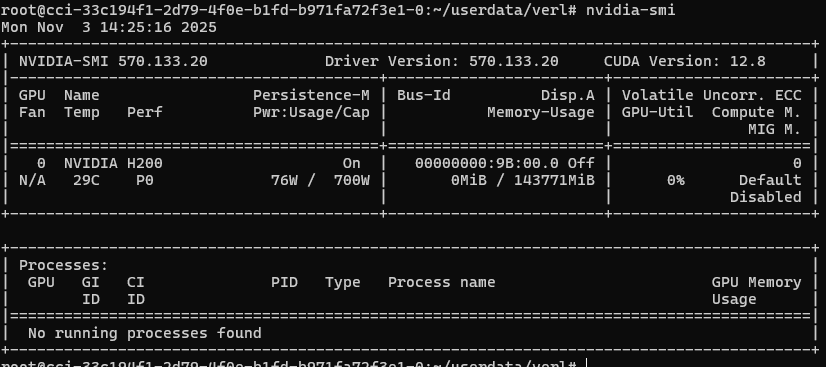
- 开机后进入容器,输入nvidia-smi,能看到显卡信息就说明没问题了:
Step2.5 启动单卡训练/微调
- 执行指令开始训练(以此verl镜像为例,用户可根据实际代码情况开始)
# 配置环境变量
export HF_ENDPOINT=http://hfmirror.mas.zetyun.cn:8082
# 安装verl包
cd /root/userdata/verl
pip3 install --no-deps -e .
# 启动训练任务,指定单卡运行
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=gae \
data.train_files=$HOME/verl/data/gsm8k/train.parquet \
data.val_files=$HOME/verl/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.max_prompt_length=512 \
data.max_response_length=512 \
data.filter_overlong_prompts=True \
data.truncation='error' \
actor_rollout_ref.model.path=deepseek-ai/deepseek-llm-7b-chat \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=16 \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.actor.use_kl_loss=False \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
critic.optim.lr=1e-5 \
critic.model.use_remove_padding=True \
critic.model.path=deepseek-ai/deepseek-llm-7b-chat \
critic.model.enable_gradient_checkpointing=True \
critic.ppo_micro_batch_size_per_gpu=32 \
critic.model.fsdp_config.param_offload=False \
critic.model.fsdp_config.optimizer_offload=False \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger='["console","wandb"]' \
trainer.project_name='verl_example_gsm8k' \
trainer.experiment_name='deepseek_llm_7b_function_rm' \
trainer.n_gpus_per_node=1 \
trainer.nnodes=1 \
trainer.save_freq=20 \
trainer.test_freq=1 \
trainer.use_legacy_worker_impl=auto \
trainer.total_epochs=15
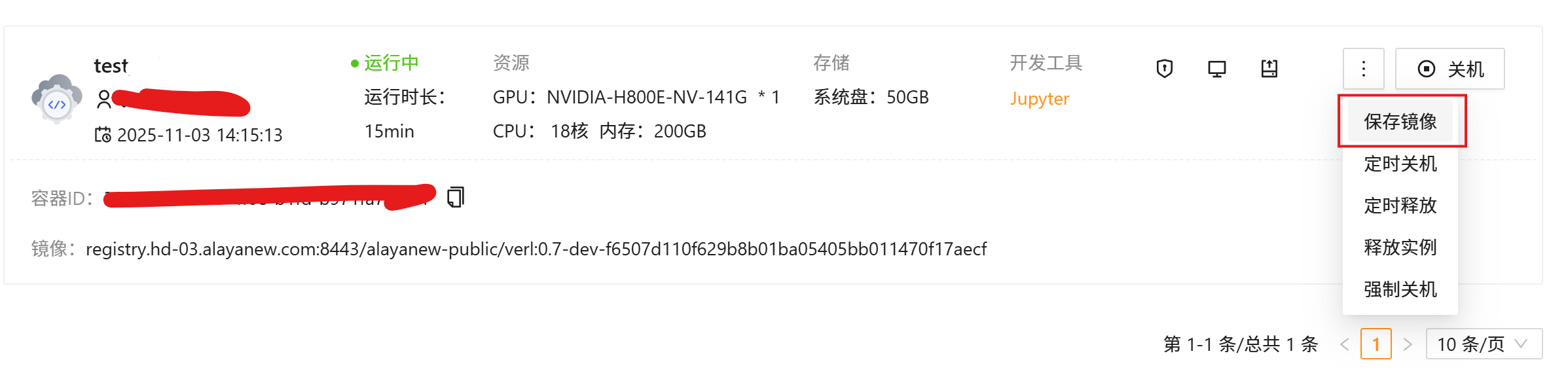
Step2.6 (可选)保存镜像
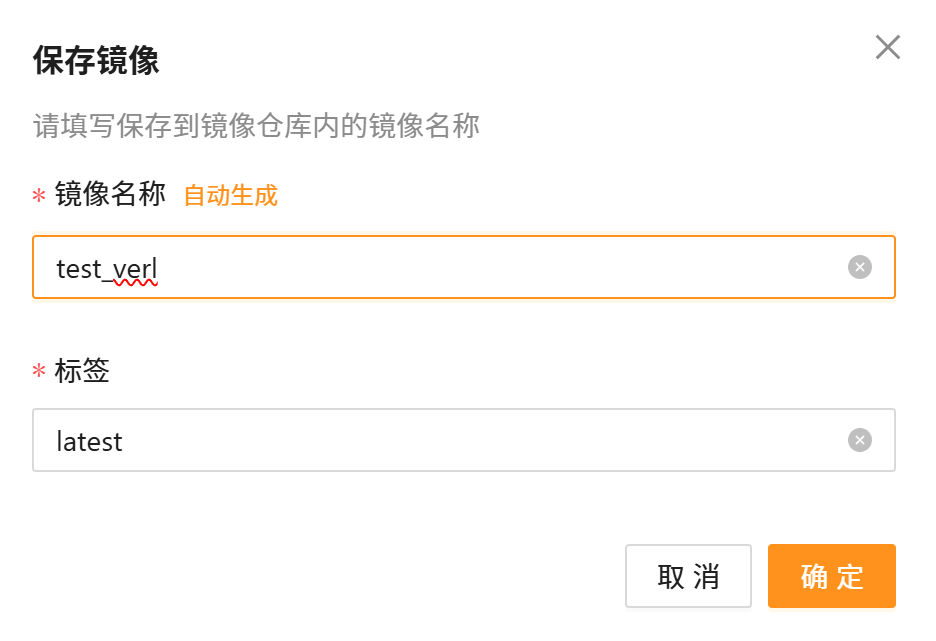
- 确保流程已通的情况下,可手动保存镜像,为下次用户使用做准备。回到实例列表,找到当前实例,点击「保存镜像」:
- 填好镜像名称(比如 test_verl)和标签(方便区分版本),确认保存
- 保存成功后,在「AI 资源→镜像仓库→私有镜像」里就能看到。
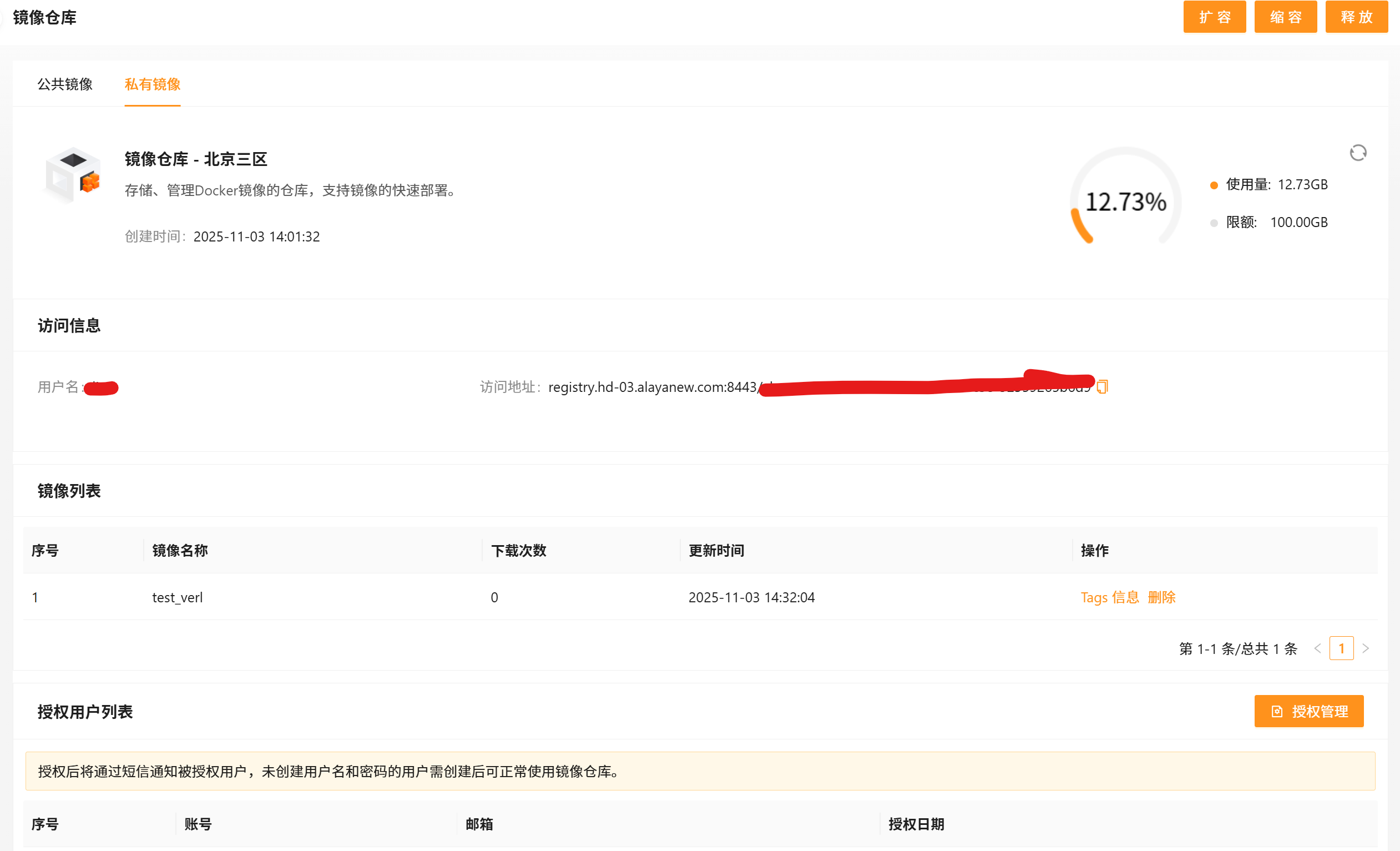
Step2.7 使用8卡资源,重新进入容器实例
- 此时有两种方式均可更换为8卡资源
|
方法1: 开通新的云容器实例,选择刚才保存的test_verl镜像 (参考Step2.1) |
方法2: 修改现有容器实例 (参考Step2.4) |
|
|
|
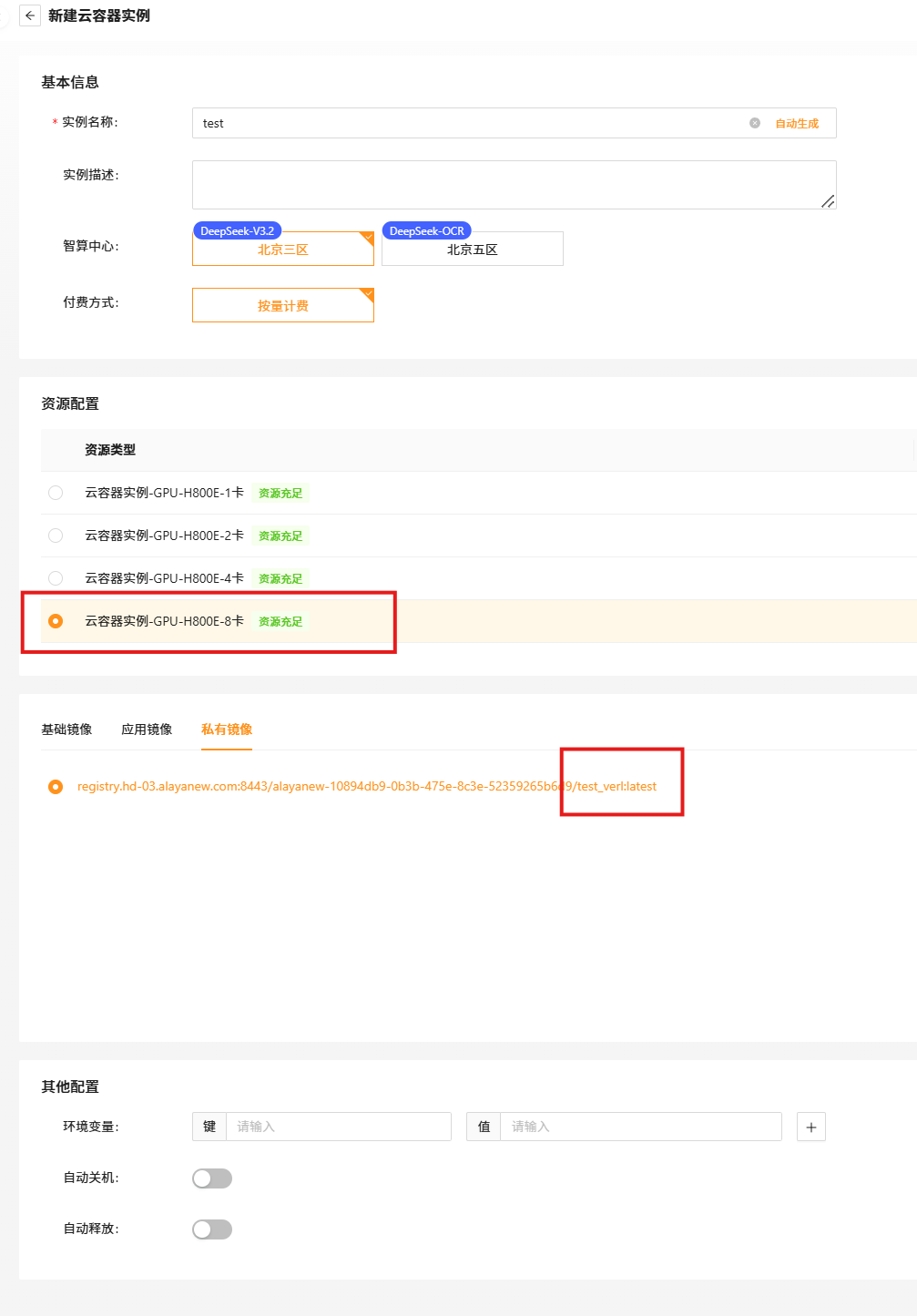
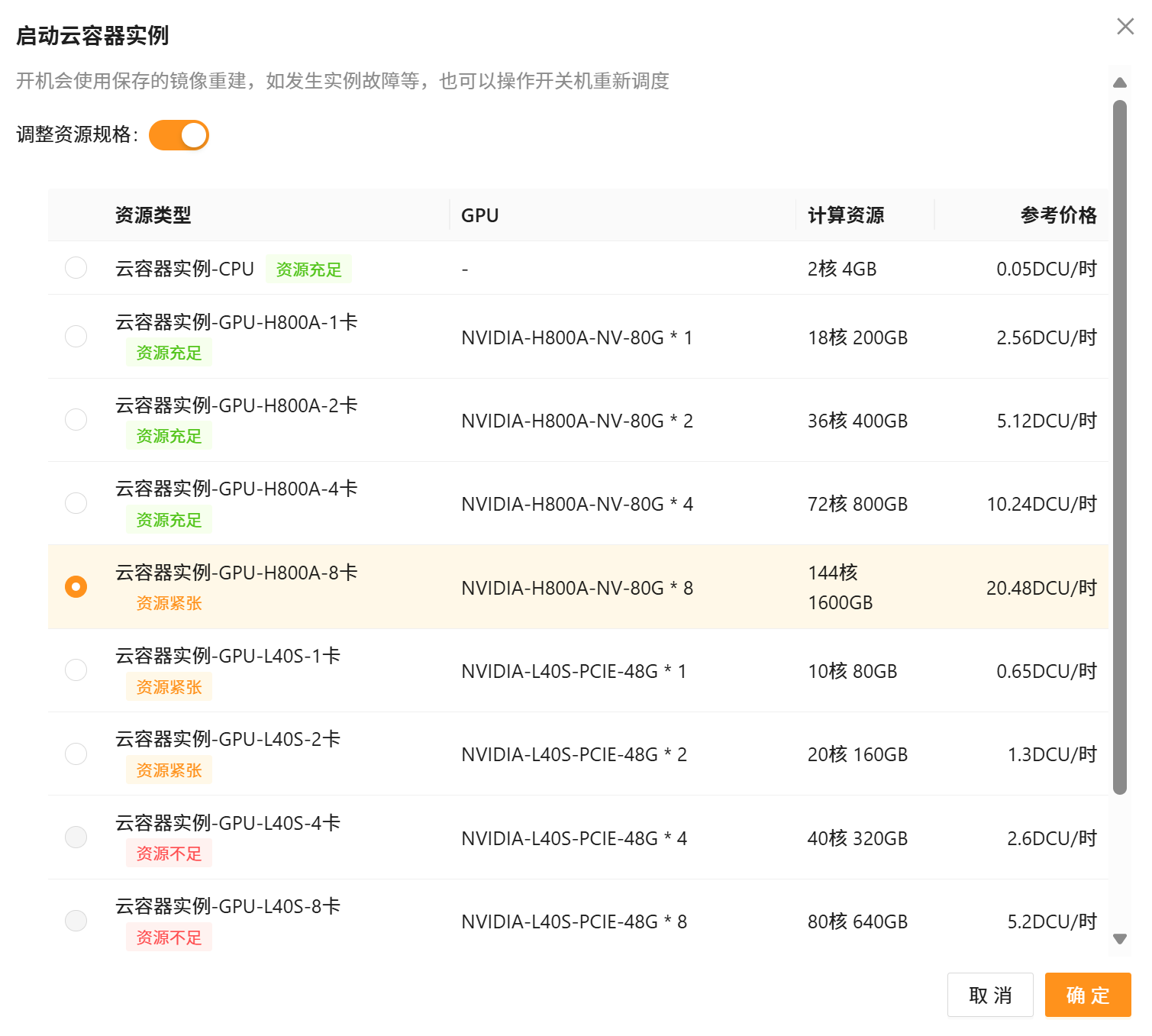
Step2.8 启动8卡训练
# 启动8卡训练任务,修改部分配置
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=gae \
data.train_files=$HOME/verl/data/gsm8k/train.parquet \
data.val_files=$HOME/verl/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.max_prompt_length=512 \
data.max_response_length=512 \
data.filter_overlong_prompts=True \
data.truncation='error' \
actor_rollout_ref.model.path=deepseek-ai/deepseek-llm-7b-chat \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=16 \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.actor.use_kl_loss=False \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.rollout.tensor_model_parallel_size=8 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
critic.optim.lr=1e-5 \
critic.model.use_remove_padding=True \
critic.model.path=deepseek-ai/deepseek-llm-7b-chat \
critic.model.enable_gradient_checkpointing=True \
critic.ppo_micro_batch_size_per_gpu=32 \
critic.model.fsdp_config.param_offload=False \
critic.model.fsdp_config.optimizer_offload=False \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger='["console","wandb"]' \
trainer.project_name='verl_example_gsm8k' \
trainer.experiment_name='deepseek_llm_7b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=20 \
trainer.test_freq=1 \
trainer.use_legacy_worker_impl=auto \
trainer.total_epochs=15
- 最后总结:这套流程的核心优势
- 数据不丢:大容量存储 + userdata 目录,容器怎么折腾都不怕数据没了;
- 环境复用:私有镜像仓库存配置,单卡→多卡迁移不用重装依赖;
- 灵活调整:存储能扩、显卡能换,按项目需求随时改。
如果操作中遇到某个步骤卡壳,评论区留言,咱们一起解决~
- 双十一活动惊喜来袭
另外九章智算云双十一活动正在进行中,3杯咖啡的钱就可以买到20度算力,足够:
- 在 H卡上运行约 7.8小时(H卡 实例约 2.56度/小时)
- 足够完成一次 Llama3-8B LoRA 微调
- 或部署一个 Qwen-VL 多模态推理服务并压测一整天
- 甚至跑通一个完整的 AI Agent 工作流 demo
如何购买:
- 点击链接进入官网:https://www.alayanew.com/?id=online
(建议把链接复制到PC端浏览器进入官网)
2. 进入官网后点击如图所示的【立即购买】即可。可选择微信/支付宝/对公账号支付。

✳记得先登录后购买,在官网右上角选择登录/注册,或者直接点此链接登录/注册:
https://www.alayanew.com/backend/register?id=online
活动时间:2025年11月3日-12月2日
算力有效期:购买次日后30天内有效
更多推荐


 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)