
强化学习的常见概念和知识
本文介绍了强化学习的基础概念,包括随机变量、概率密度函数、期望值等概率论基础,以及强化学习中的核心要素:状态、动作、策略、奖励和状态转移。重点讲解了价值函数(动作价值函数和状态价值函数)及其在智能体控制中的应用方式(策略控制和最优动作价值函数控制)。最后通过OpenAI Gym中的CartPole游戏示例,演示了如何实现一个简单的强化学习环境交互流程,包括环境初始化、状态观测、动作选择和环境反馈等
注:day1(学习于王树森老师)
1 随机变量(Random Variable)
1.1 概念
随机变量:一个其取值依赖于随机事件结果的变量。
|
随机变量 |
可能取值 |
事件概率 |
|
X |
x=0 |
0.5 |
|
x=1 |
0.5 |

1.2 符号表示
随机变量用大写字母表示(如X)
随机变量的观测值用小写字母表示(如x)
|
观测值 |
数值 |
|
x1 |
1 |
|
x2 |
0 |
|
x3 |
1 |
|
x4 |
0 |

2 概率密度函数(PDF)
2.1 概念
概率密度函数(Probability Density Function, PDF)是描述连续型随机变量概率分布的核心工具。它的核心思想是:用“密度”刻画随机变量取值可能性的大小。

2.2 作用
PDF描述连续随机变量X在某个取值附近的可能性密集程度。
PDF提供了随机变量的值等于特定样本点的相对可能性。
注意:PDF的值p(x)不是概率本身,而是概率密度。
例:高斯分布中,靠近均值μ的位置p(x)更大,远离均值的区域密度减小。

离散的概率分布:

注:在其他任何地方的取值概率都是0。
2.3 性质
定义域:随机变量X所有可能取值的集合称为定义域,记作X。
如果p是一个连续的概率分布,对p(x)做定积分,结果为1。
如果p是一个离散的概率分布,全部加上结果为1。

3 期望(Expectation)

3.1 概念
有一个随机变量X,它代表一个随机现象的结果,我们感兴趣的是计算函数f(X)的期望值。期望值表示我们无数次重复随机实验时,函数f(X)的平均结果。它是概率论中亨利“平均值”或“中心趋势”的核心概念。
3.2 计算方式
取决于X的类型
连续型随机变量:需将函数值f(x)乘以其对应的概率密度p(x),然后在整个随机变量X所有可能的取值域上进行积分。
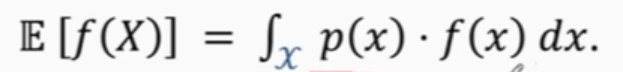
离散型随机变量:需遍历随机变量X所有可能的取值x,将函数值f(x)乘以其对应的概率密度p(x)然后将所有乘积进行求和。
4 随机抽样(Random Sampling)
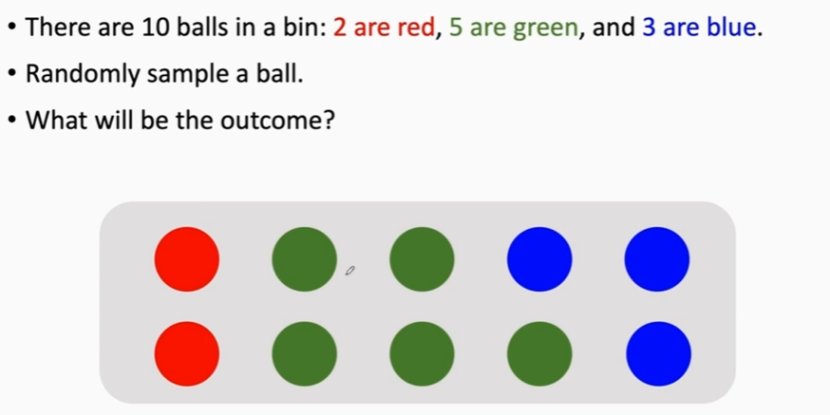
概念:从样本空间中随机抽取样本。

5 基本术语(Terminology)
5.1 state(状态)和action(行为)
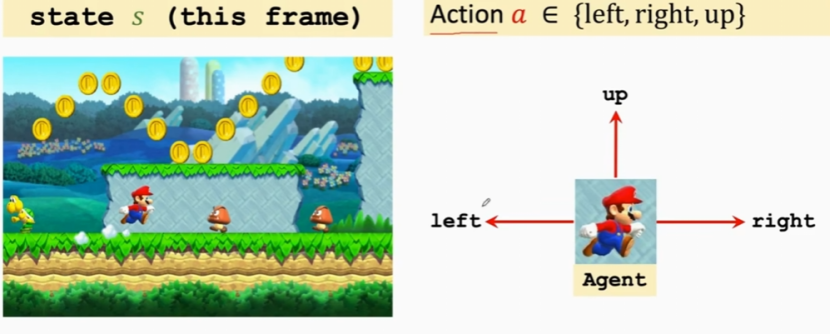
状态:当前游戏的内容,也叫做环境。
行为:智能体感受到游戏的环境状态做出的行为。
这里我们的智能体(Agent)可以做出三个动作(行为)。在不同行业里,动作是由谁做的谁就是Agent。
5.2 policy(策略)

策略:策略是函数π,表示在一个状态s下选择动作a的概率。
注:使每个动作都有可能发生可以使智能体更加灵活,可以处理现实中复杂的环境,在一些博弈中不会被人摸到规律。
5.3 reward(奖励)

智能体做出一个动作,我们可以给出一个奖励,奖励要我们自己定义,奖励定义的好坏非常影响强化学习的结果。通过奖励让智能体达到我们想要的结果。
注:奖励的定义要根据具体的情况和个人的习惯。
强化学习的目标是使得一轮游戏中得到的奖励最大。
5.4 state transition(状态转移)
智能体做出动作后,游戏的环境会发生变化,状态转移可以是随机的,也可以是确定的。通常我们的状态转移是随机的,它的随机主要来自于游戏的环境。
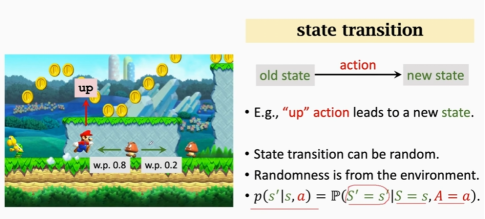
环境有状态转移函数,这个函数只有游戏知道,我们不知道。我们的智能体做出动作后,环境可能发生的变化是有一定的概率的,比如:我们的智能体向上跳,怪物有0.8的概率向左,0.2的概率向右。
5.5 智能体-环境交互(Agent-Environment)
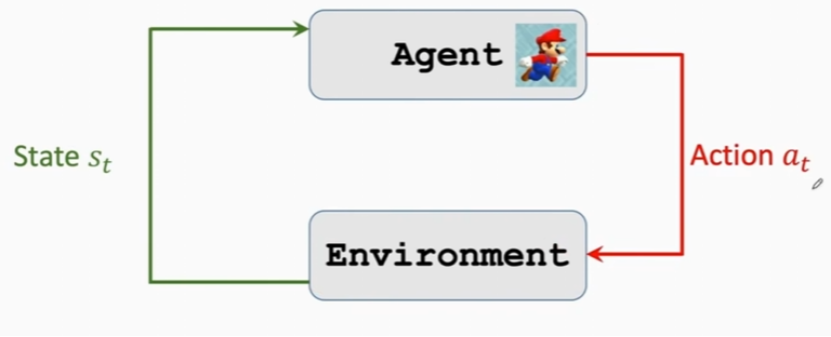
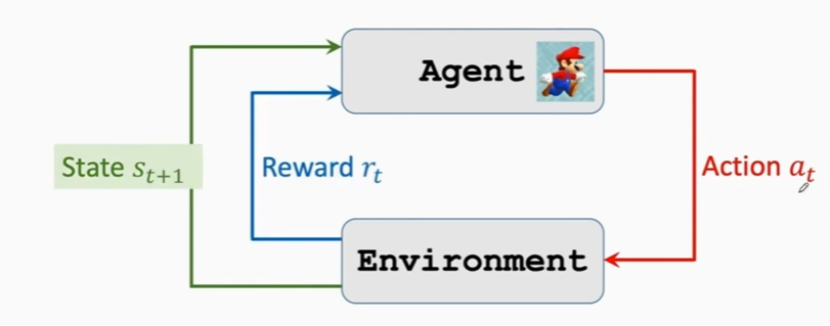
环境输入给智能体一个状态,智能体做出状态反馈给环境,环境再给智能体发出奖励;之后环境输入给智能体更新后的状态,继续做出循环,直到到达一个特殊的条件结束。
6 强化学习中的随机性
第一个随机性来自智能体行为的随机性,它是随机抽样得来的。

第二个随机性是来自于环境状态转移的随机性,智能体做出动作后环境就要生成下一个状态进行状态转移,这个状态具有随机性,通过状态转移函数生成概率,然后用概率随机抽样生成下一个状态。

7 如何使用ai玩游戏(轨迹)
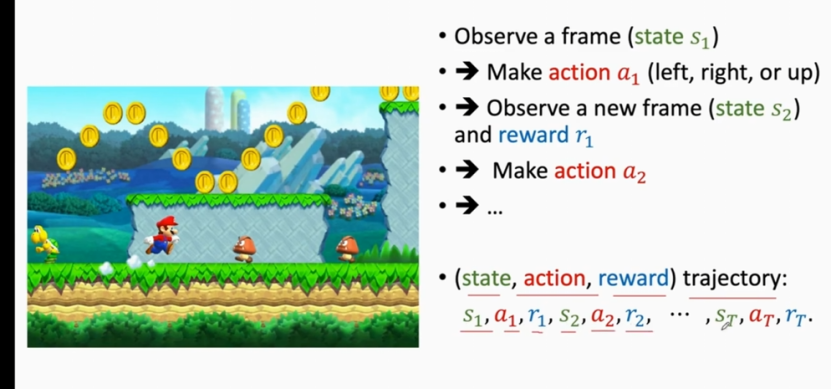
trajectory(轨迹):当智能体结束游戏,得到的状态、动作、奖励...就是轨迹。
8 Rewards and Returns(奖励和回报)

回报:回报Ut是从时间步t开始的累计未来奖励。
Rt:当前时刻的即时奖励。
注:但是在实际情况中,如果时间间隔过于大,当前的动作对于之后的得分的影响可能太小,我们会加上一个折扣因子,折扣因子一般在0-1。

9 Randomness in returns(回报的随机性)

随机性来自两点:行为的随机性,下一个状态
对于任意未来时刻,reward Ri 取决于当前的环境和动作。

10 Value Functiions(价值函数)
10.1 动作价值函数

动作价值函数的含义:在当前的策略下,从状态st执行动作at后,能获得的期望累积折扣回报,可以告诉我们的动作好不好。
输入:当前状态st和动作at;输出:标量值(评估动作的长期价值)。
Ut和Q的取值取决于:即时决策:当前动作;未来轨迹:后续状态序列,后续动作序列;策略。

最优动作价值函数:在无数的策略中,找到一个最好的:使得积累奖励最大。
10.2 状态价值函数


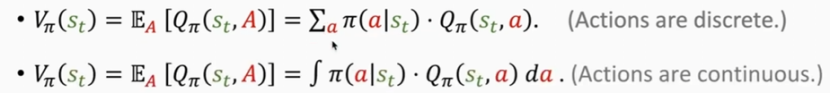
含义:评估我们的环境的好坏。
注:A所有动作的合集。
10.3 总结

动作价值函数:评估状态s下选择动作a的长期价值。
“如果在状态s下选择动作a,未来能获得多少总奖励”
状态价值函数:评估状态s的整体价值。
“如果我在状态s下,平均能获得多少总奖励”。
11 AI ruh 控制智能体:两种方式

基于策略控制和基于最优动作价值函数控制。
11.1 策略控制
假如我们有了策略函数,我们就可以使用它做动作。输入环境s,输出每一个动作的概率,进行随机抽样,执行动作。
11.2 最优动作价值函数控制
假如我们有最优价值函数,输入环境和动作,得到每一个动作的积累得分,输出最大的那个,让那个动作执行。
12 OpenAI Gym
它是强化学习算法的开发和评测工具包。
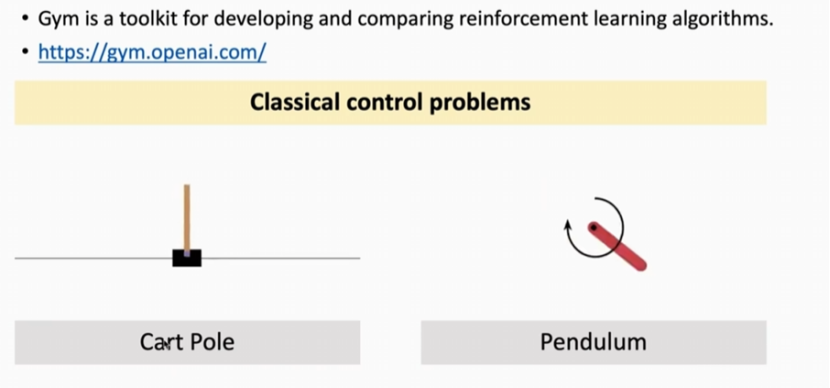
经典控制问题:
倒立摆(CartPole):控制小车,保持杆子树立不倒。
钟摆(Pendulum):施加扭矩使钟摆保持竖直向上。

Atari 经典游戏问题:强化学习的黄金测试平台
乒乓球(Pong)、太空侵略者(Space Invader),打砖块(Breakout)

连续控制问题MuJoCo(Continuous control tasks)
Ant(蚂蚁机器人),Humanoid(人型机器人),Half Cheetah(猎豹机器人)
13 Play CartPole Game


import gym # 导入Gym库
env = gym.make(“CartPole-v0”) # 创建CartPole环境
state = env.reset() # 返回初始状态 [小车位置, 速度, 杆角度, 角速度]
# 运行最多100个时间步
for t in range(100):
# 1. 弹出游戏窗口,可视化当前状态
env.render() # 渲染:显示小车和倒立摆的实时位置
# 2. 打印当前状态向量
print(state) # 输出格式示例: [-0.02, 0.15, 0.03, -0.25]
# 3. 随机选择动作 (0=向左推, 1=向右推)
action = env.action_space.sample() # 随机策略
# 4. 执行动作并获取环境反馈
state, reward, done, info = env.step(action)
"""
返回值说明:
- state: 新状态 (4维向量)
- reward: 奖励值 (存活每步+1)
- done: 是否结束 (布尔值)
- info: 额外信息 (通常为空)
"""
# 5. 检查游戏是否结束
if done: # done=1 表示游戏终止
print('Finished') # 输出结束信息
break # 退出循环
# 关闭游戏窗口
env.close() # 清理资源
注:由于参数过多,我们可以使用下面的代码运算。
import gym
def play_cartpole():
# 创建环境
env = gym.make('CartPole-v1', render_mode='human')
# 初始化环境
state = env.reset()
if isinstance(state, tuple):
state = state[0] # 新版Gym返回元组
total_reward = 0
print("游戏开始!控制台将显示状态向量,窗口显示游戏画面")
print("状态向量格式: [小车位置, 小车速度, 杆角度, 杆角速度]")
# 运行100个时间步
for t in range(100):
# 渲染游戏画面
env.render()
# 打印当前状态
print(f"步数 {t}: {state}")
# 随机选择动作 (0=向左推, 1=向右推)
action = env.action_space.sample()
# 执行动作
result = env.step(action)
state, reward, done, _, _ = result # 新版Gym返回5个值
# 累积奖励
total_reward += reward
# 检查游戏是否结束
if done:
print(f'\n游戏结束! 原因: {"杆子过度倾斜" if abs(state[2]) > 0.2 else "小车出界"}')
print(f'总步数: {t}, 总得分: {total_reward}')
break
# 关闭环境
env.close()
print("游戏窗口已关闭")
if __name__ == "__main__":
play_cartpole()更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)