
百度开源语音识别强大工具PaddleSpeech从0到1快速上手:安装、部署、Debug与测试详尽指南
掌握语音识别,从百度PaddleSpeech开始!本文详细介绍了PaddleSpeech的环境搭建、安装步骤和实用代码示例,助您轻松入门语音识别技术。面对安装难题?别担心,我们提供了详尽的故障排查指南。一文在手,让您快速启动语音识别项目,开启AI语音世界的大门。
Introduction 导言
在当今快速发展的人工智能领域,语音识别技术正扮演着越来越重要的角色。它不仅能够极大地提高我们的工作效率,还能在多种场景下提供便利,如自动字幕生成、语音助手、以及智能客服等。PaddleSpeech,作为百度推出的一款开源的语音识别和合成引擎,因其强大的功能和易用性受到了开发者们的广泛关注。
在本篇文章中,我们将深入探讨如何安装和部署PaddleSpeech,以及如何进行基本的测试。我们将从环境要求开始,逐步引导您完成整个安装过程,并提供详细的命令和代码示例。此外,我们还会讨论在安装过程中可能遇到的一些常见问题及其解决方案,确保您能够顺利地开始使用PaddleSpeech。
无论您是AI领域的新手还是资深开发者,本文都将为您提供一个全面的指南,帮助您快速上手PaddleSpeech,并在您的项目中实现语音识别功能。让我们开始吧!
PaddleSpeech安装部署和测试
环境要求:
- Python >= 3.7
- C++编译环境
- pip版本为20.2.2或更⾼版本
安装参考:
- CSDN博客:PaddleSpeech安装指南
- PaddleSpeech源代码:GitHub - PaddlePaddle/PaddleSpeech
安装整体过程如下:
-
创建python3.9的环境:
conda create -n speech python=3.9 -
安装pytest-runner:
pip install pytest-runner -i https://pypi.tuna.tsinghua.edu.cn/simple -
安装paddlepaddle:
pip install paddlepaddle==2.5.2 -i https://mirror.baidu.com/pypi/simple -
安装paddlespeech:
pip install paddlespeech==1.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
注意:安装paddlepaddle和paddlespeech时可以不指定版本;建议在安装 paddlepaddle 的时候使用百度源 https://mirror.baidu.com/pypi/simple,而在安装 paddlespeech 的时候使用清华源 https://pypi.tuna.tsinghua.edu.cn/simple。
使用代码示例:
from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.text.infer import TextExecutor
import time
time_st = time.time()
asr = ASRExecutor()
result = asr(audio_file="xiangchao_ch_1.wav", model='conformer_wenetspeech', force)
text_punc = TextExecutor()
text = text_punc(text=result, model='ernie_linear_p3_wudao_fast')
time_ed = time.time()
print(f"base: {text}, time: {time_ed - time_st}")
Bug处理
遇到下面问题,可以查看网络环境或更换解释器。
Traceback (most recent call last):
File “e:\Steven_Hu\STT\PaddleSpeech\paddletest.py”, line 4, in
result = asr(audio_file=“xiangchao_ch_2.wav”, model=‘conformer_wenetspeech’)
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\utils.py”, line 328, in _warpper
return executor_func(self, *args, **kwargs)
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\asr\infer.py”, line 502, in call
self._init_from_path(model, lang, codeswitch, sample_rate, config,
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\asr\infer.py”, line 159, in _init_from_path
self.task_resource.set_task_model(tag, version=None)
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\resource\resource.py”, line 90, in set_task_model
self.res_dir = self._fetch(self.res_dict,
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\resource\resource.py”, line 228, in _fetch
return download_and_decompress(res_dict, target_dir)
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\utils.py”, line 148, in download_and_decompress
uncompress_path = download.get_path_from_url(archive[‘url’], path,
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\download.py”, line 102, in get_path_from_url
fullpath = _download(url, root_dir, md5sum, method=method)
File “e:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\download.py”, line 198, in _download
raise RuntimeError("Download from {} failed. "
RuntimeError: Download from https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1_conformer_wenetspeech_ckpt_0.1.1.model.tar.gz failed. Retry limit reached
如果遇到以下问题,可以将paddlepaddle版本升级到2.5.2。
ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
onnx 1.16.0 requires protobuf>=3.20.2, but you have protobuf 3.20.0 which is incompatible.
paddlenlp 2.6.1 requires protobuf==3.20.2, but you have protobuf 3.20.0 which is incompatible.
pip install --upgrade paddlepaddle==2.5.2 -i https://mirror.baidu.com/pypi/simple/
如果遇到AttributeError: module 'numpy' has no attribute 'complex'错误,可以按照以下步骤解决:
pip uninstall numpy
pip install numpy==1.23.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果遇到下面问题,需要将paddlepaddle降级到2.4.2,可以执行以下命令: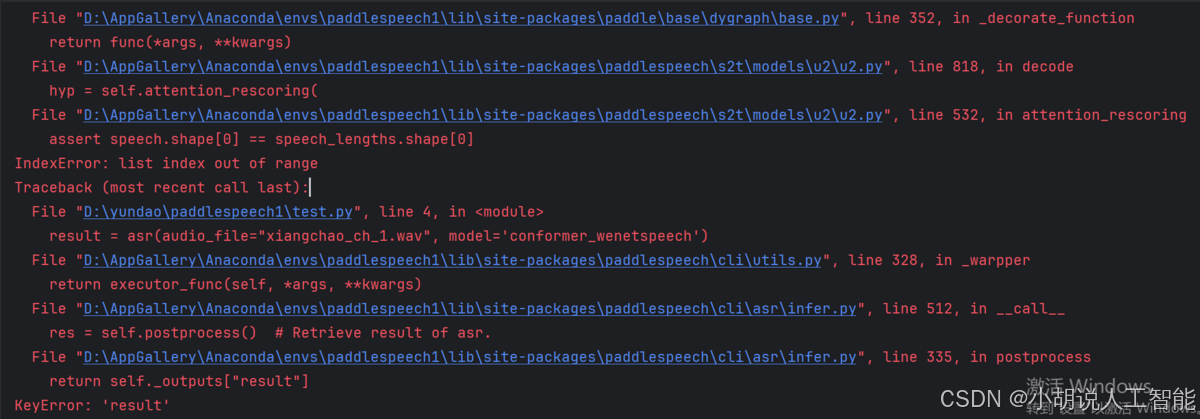
pip uninstall paddlepaddle
pip install paddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple
同样,遇到下面问题,需要将scipy降级到1.7.3,可以执行以下命令:
pip uninstall scipy
pip install scipy==1.7.3 -i https://mirror.baidu.com/pypi/simple
如果遇到ModuleNotFoundError: No module named 'paddle.nn.layer.layers'错误,可以将paddlepaddle更新到2.5.2:
Traceback (most recent call last):
File “E:\Steven_Hu\STT\PaddleSpeech\paddletest.py”, line 2, in
from paddlespeech.cli.text.infer import TextExecutor
File “E:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\text_init_.py”, line 14, in
from .infer import TextExecutor
File “E:\Steven_Hu\STT\PaddleSpeech\paddlespeech\cli\text\infer.py”, line 29, in
from paddlespeech.text.models.ernie_linear import ErnieLinear
File “E:\Steven_Hu\STT\PaddleSpeech\paddlespeech\text\models_init_.py”, line 14, in
from .ernie_crf import ErnieCrf
File “E:\Steven_Hu\STT\PaddleSpeech\paddlespeech\text\models\ernie_crf_init_.py”, line 14, in
from .model import ErnieCrf
File “E:\Steven_Hu\STT\PaddleSpeech\paddlespeech\text\models\ernie_crf\model.py”, line 16, in
from paddlenlp.layers.crf import LinearChainCrf
File “C:\Users\dell\anaconda3\envs\paddle_speech\lib\site-packages\paddlenlp_init_.py”, line 35, in
from . import (
File “C:\Users\dell\anaconda3\envs\paddle_speech\lib\site-packages\paddlenlp\data_init_.py”, line 18, in
from .data_collator import *
File “C:\Users\dell\anaconda3\envs\paddle_speech\lib\site-packages\paddlenlp\data\data_collator.py”, line 26, in
from …transformers import BertTokenizer
File “C:\Users\dell\anaconda3\envs\paddle_speech\lib\site-packages\paddlenlp\transformers_init_.py”, line 17, in
from .model_utils import PretrainedModel, register_base_model
File “C:\Users\dell\anaconda3\envs\paddle_speech\lib\site-packages\paddlenlp\transformers\model_utils.py”, line 62, in
from …generation import GenerationConfig, GenerationMixin
File “C:\Users\dell\anaconda3\envs\paddle_speech\lib\site-packages\paddlenlp\generation_init_.py”, line 15, in
from .logits_process import (
File “C:\Users\dell\anaconda3\envs\paddle_speech\lib\site-packages\paddlenlp\generation\logits_process.py”, line 22, in
from paddle.nn.layer.layers import in_declarative_mode
ModuleNotFoundError: No module named ‘paddle.nn.layer.layers’
pip install --upgrade paddlepaddle==2.5.2 -i https://mirror.baidu.com/pypi/simple/
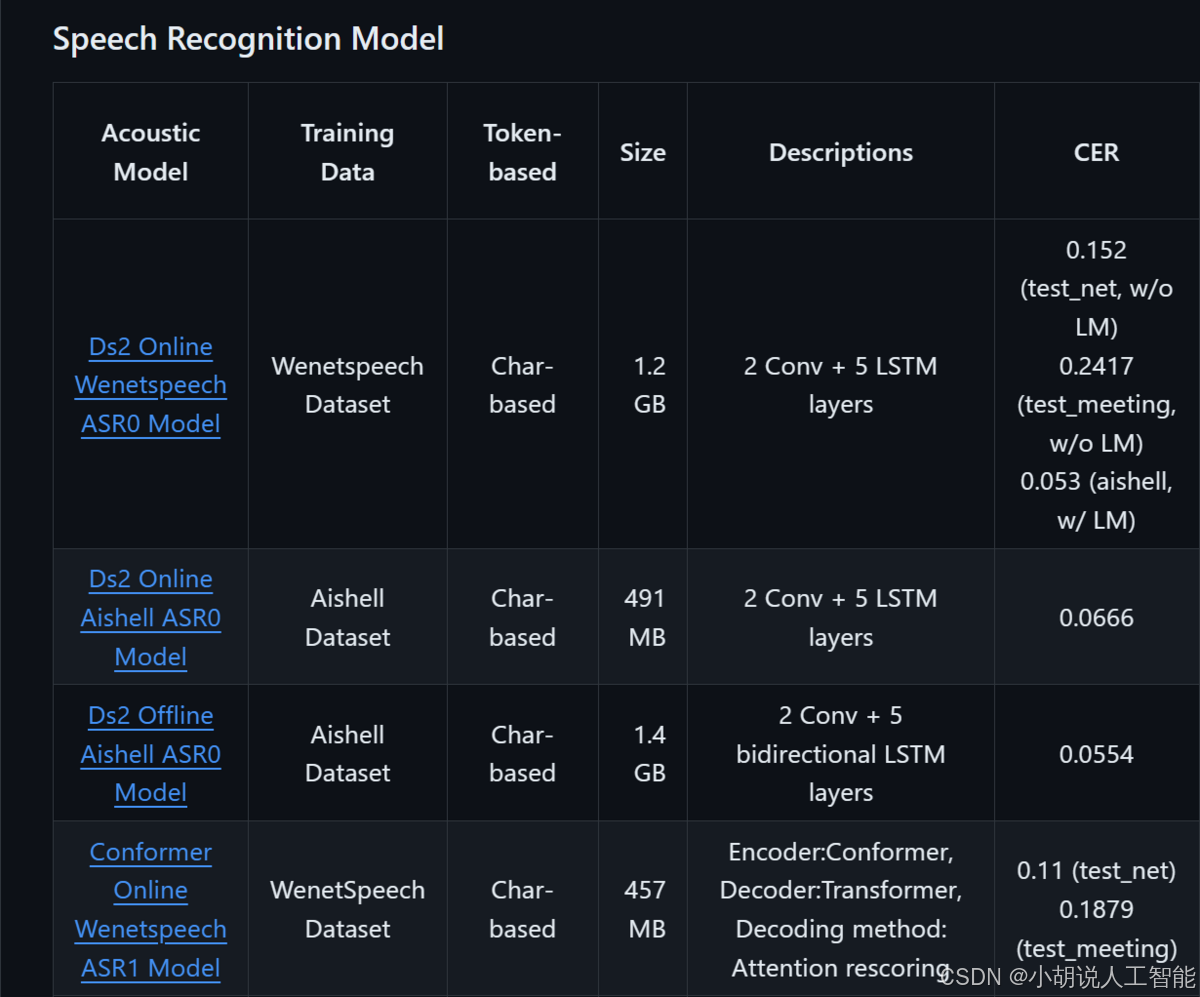
模型选择
使用paddlespeech进行语音识别时,首先通过ASRExecutor模型将语音转为文本,然后再通过TextExecutor模型给文本添加标点符号。在选择ASR模型时,可以参考官方给出的中文语音识别模型列表,依据CER(字错率)和模型大小,共考虑了4个模型:['conformer_wenetspeech', 'conformer_u2pp_online_wenetspeech', 'conformer_aishell', 'deep_speech2online_aishell'];TextExecutor共有3个模型,分别为:['ernie_linear_p7_wudao', 'ernie_linear_p3_wudao', 'ernie_linear_p3_wudao_fast']。
在固定ASR模型的情况下,先分别测试3个TextExecutor的性能,确定TextExecutor模型后,再测试ASR模型的表现(详情见“性能测试”)。

性能测试
- 首先选择ASR模型为“conformer_wenetspeech”,然后分别测试TextExecutor的性能,结果如下所示:
#xiangchao_ch_1.wav
ernie_linear_p3_wudao_fast:base: 制造商的目的是要以最低成本,将客户能接受的产品送到他们手上。为了保证我们产品的品质, time: 44.83989906311035
ernie_linear_p3_wudao;base: 制造商的目的是要以最低成本将客户能接受的产品送到他们手上,为了保证我们产品的品质。, time: 42.6201434135437
ernie_linear_p7_wudao;base: 制造商的目的是:要以最低成本,将客户能接受的产品送到他们手上,为了保证我们产品的品质。, time: 48.108585357666016
#xiangchao_ch_2.wav
ernie_linear_p3_wudao_fast:base: 能被接受所有的生产流程,不管是生产早餐招聘,新人,还是制造变异器,, time: 37.90652251243591
ernie_linear_p3_wudao;base: 能被接受所有的生产流程,不管是生产早餐,招聘新人,还是制造变异器。, time: 53.535842418670654
ernie_linear_p7_wudao;base: 能被接受所有的生产流程,不管是生产早餐、招聘新人,还是制造变异器。, time: 61.340282678604126
#xiangchao_ch_3.wav
ernie_linear_p3_wudao_fast:base: 区设有检查点。如果想以最低成本得到可接受的品质,你必须在产品尚未消耗太多成本之前,便淘汰掉。, time: 34.23006796836853
ernie_linear_p3_wudao;base: 区设有检查点,如果想以最低成本得到可接受的品质,你必须在产品尚未消耗太多成本之前便淘汰掉。, time: 40.53564476966858
ernie_linear_p7_wudao;base: 区设有检查点,如果想以最低成本得到可接受的品质,你必须在产品尚未消耗太多成本之前,便淘汰掉。, time: 60.724369287490845
- 确定TextExecutor模型为“ernie_linear_p3_wudao”,然后分别测试所选ASR模型。在测试时发现部分模型的依赖包存在版本冲突,故最终选择两个模型进行测试,结果如下所示:
#xiangchao_ch_1.wav
conformer_wenetspeech:base: 制造商的目的是要以最低成本将客户能接受的产品送到他们手上,为了保证我们产品的品质。, time: 53.7806670665741
conformer_aishell:base: 制造商的目的是要以最低成本将客户能接受的产品送到他们手上,为了保证我们产品的品质。, time: 43.718218088150024
#xiangchao_ch_2.wav
conformer_wenetspeech:base: base: 能被接受所有的生产流程,不管是生产早餐,招聘新人,还是制造变异器。, time: 38.204508781433105
conformer_aishell:base: 能被接受所有的生产流程,不管是生产早餐,招聘新人,还是制造电异器都必。, time: 25.896536827087402
#xiangchao_ch_3.wav
conformer_wenetspeech:base: base: 区设有检查点,如果想以最低成本得到可接受的品质,你必须在产品尚未消耗太多成本之前便淘汰掉。, time: 68.42701816558838
conformer_aishell:base: 需设有检查点如果想以最低成本得到可接受的品质,你必须在产品尚未消耗太多成本之前便淘汰的。, time: 36.03130602836609
参考资料
- CSDN博客:PaddleSpeech安装指南
- PaddleSpeech源代码:GitHub - PaddlePaddle/PaddleSpeech
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
更多推荐


 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)