
YOLO --- 目标检测基础
本文介绍了目标检测的基础概念、技术架构及关键指标。主要内容包括:1)目标检测定义及面临的挑战;2)标注方法(边界框标注);3)与图像分类、分割任务的对比;4)在自动驾驶、安防等领域的应用场景;5)技术架构分类(单阶段与双阶段检测方法);6)关键评估指标如边界框和交并比(IoU)。文章还提供了YOLO等主流算法的对比分析,帮助读者快速掌握目标检测的核心知识要点。
YOLO — 目标检测基础
文章目录
一,目标检测概念
- 目标检测(Object Detection)是计算机视觉中的一个重要领域,它涉及到识别图片或视频某一帧中的物体是什么类别,并确定它们的位置。通常用于多个物体的识别,可以同时处理图像中的多个实例,并为每个实例提供一个边界框和类别标签
- 目标检测面临到的问题:
- 目标种类和数量问题
- 目标尺度问题
- 环境干扰问题
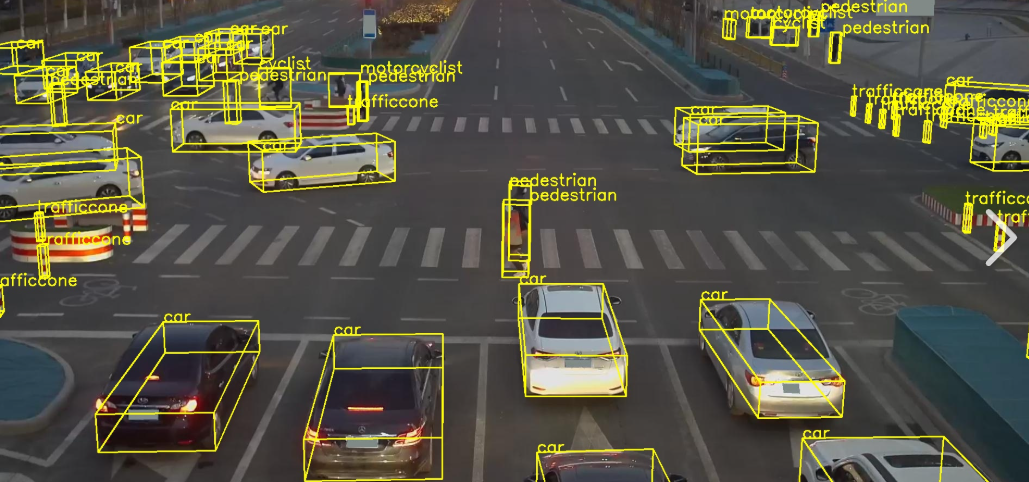
二,标注
- 在目标检测任务中,标注主要涉及的是边界框标注,即为图像中的每一个需要检测的目标物体画出一个边界框,并给定类别标签
- 在训练目标检测模型的时候,我们就需要先为数据集做标注
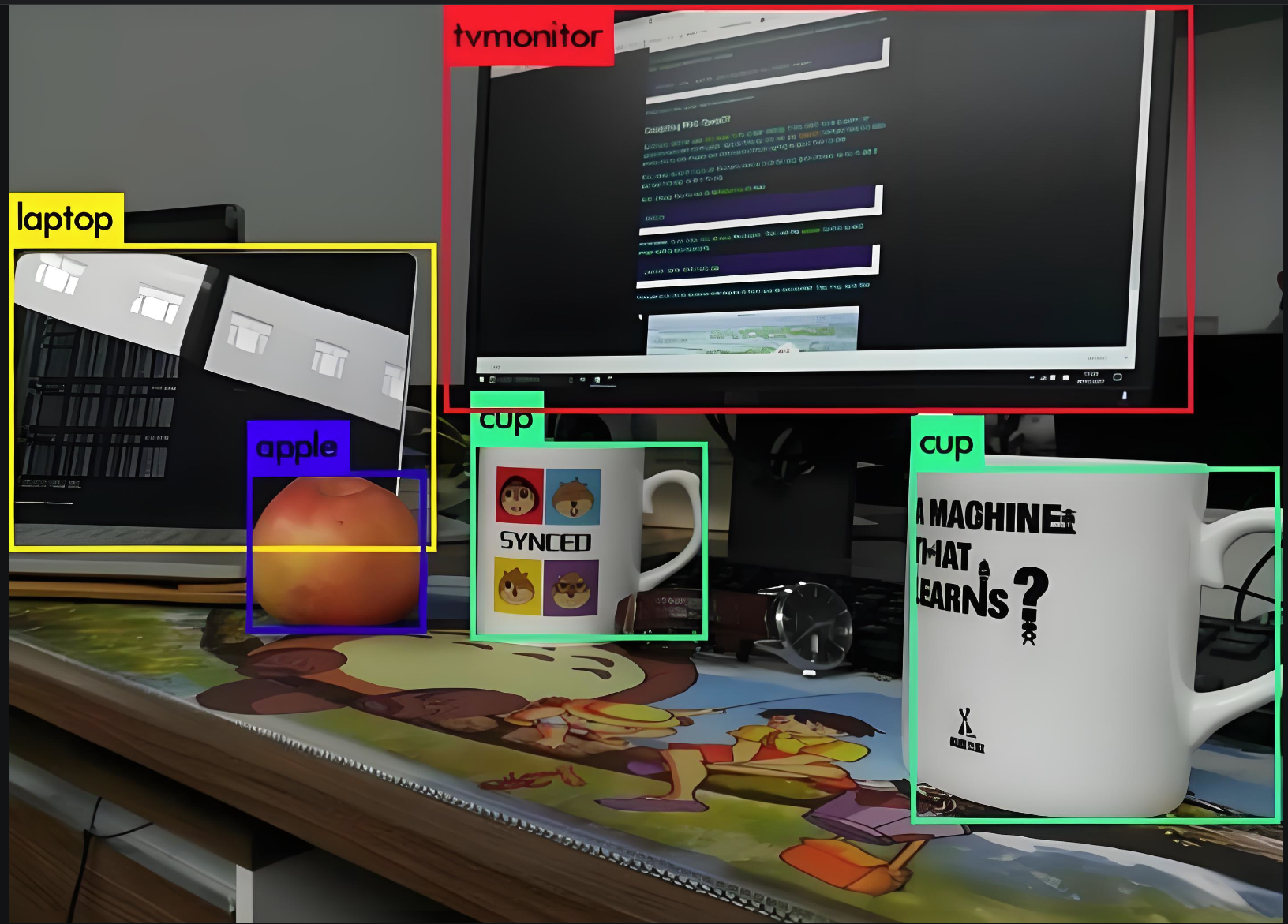
三,目标检测、图像分类、图像分割
| 维度 | 图像分类 Image Classification | 目标检测 Object Detection | 语义分割 Semantic Segmentation | 实例分割 Instance Segmentation |
|---|---|---|---|---|
| 定义 | 只回答“图里主要是什么” | 回答“有什么+在哪” | 回答“每个像素是什么类别” | 回答“每个像素属于哪个实例” |
| 输入 | 一张 RGB 图 | 一张 RGB 图 | 一张 RGB 图 | 一张 RGB 图 |
| 输出 | 单标签 / 概率向量 | 多组 (框, 类别, 置信度) | H×W 单通道 mask | 多组 (mask, 类别) |
| 标注成本 | ★ 图级标签 | ★★ 框+类 | ★★★★ 像素级多边形 | ★★★★★ 像素级实例 |
| 常用标注格式 | 文本/CSV | COCO JSON, VOC XML | PNG mask, COCO panoptic | COCO JSON (segmentation) |
| 评价指标 | Top-1 / Top-5 Accuracy | mAP @IoU=0.5:0.95 | mIoU, Pixel Accuracy | mAP (mask), AP50/AP75 |
| 典型网络 | ResNet, ViT | YOLO, Faster R-CNN | DeepLab, U-Net | Mask R-CNN, SOLOv2 |
| 应用示例 | 相册自动分类 | 安防行人/车辆检测 | 遥感地物、医疗病灶 | 自动驾驶可行驶区域+行人区分 |
| 主要优点 | 简单、速度快 | 兼顾类别与位置 | 像素级精细、无实例概念 | 像素级+实例级最完备 |
| 主要缺点 | 无位置信息 | 框粗略、重叠难分 | 不区分同类个体 | 标注昂贵、计算量大 |
四,应用场景
- 自动驾驶:检测周围的车辆、行人、交通灯、道路标志等
- 安防监控:监控公共场,发现异常行为,保障公共安全
- 人脸检测
- 医学影像分析:在医学影像方面可以识别肿瘤、组织变异等,用于医疗辅助
- 无人机应用:识别特定目标,引导无人机飞行,比如监测天气、线路检测、搜寻救援、军事等
- 缺陷检测:工业


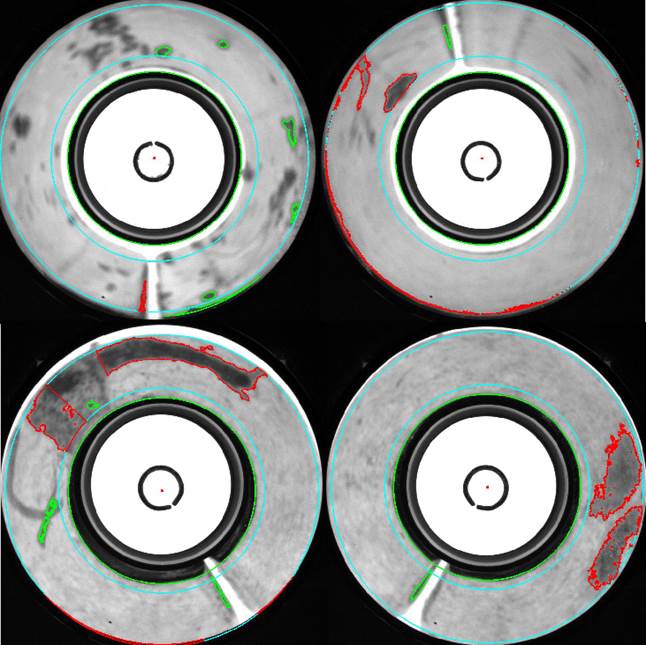

更多场景:
- 【https://blog.csdn.net/wcl291121957/article/details/138313404】
- 【https://blog.csdn.net/wcl291121957/article/details/138318995】
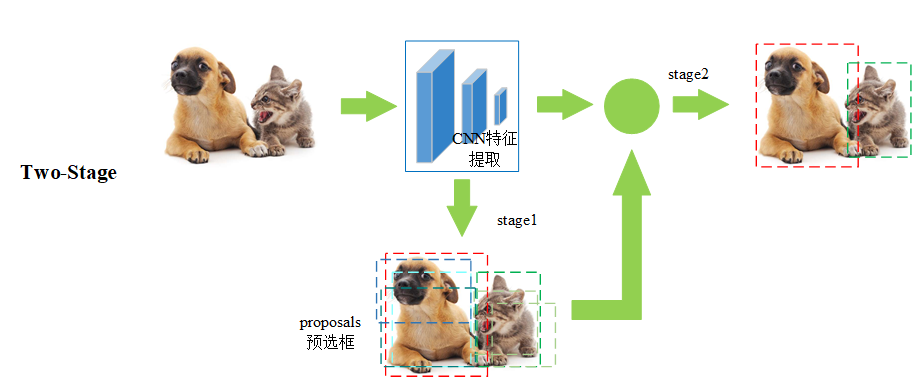
五,技术架构
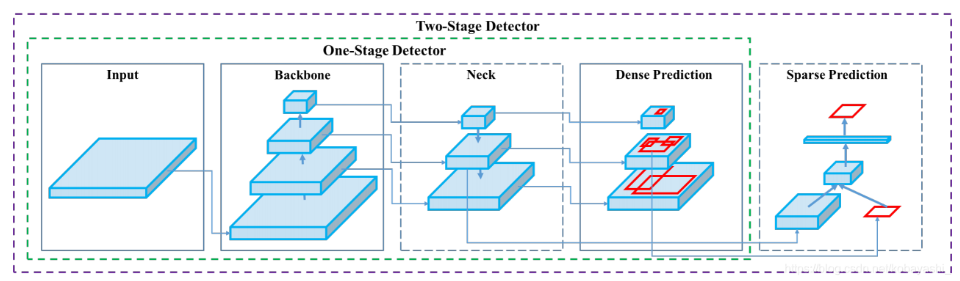
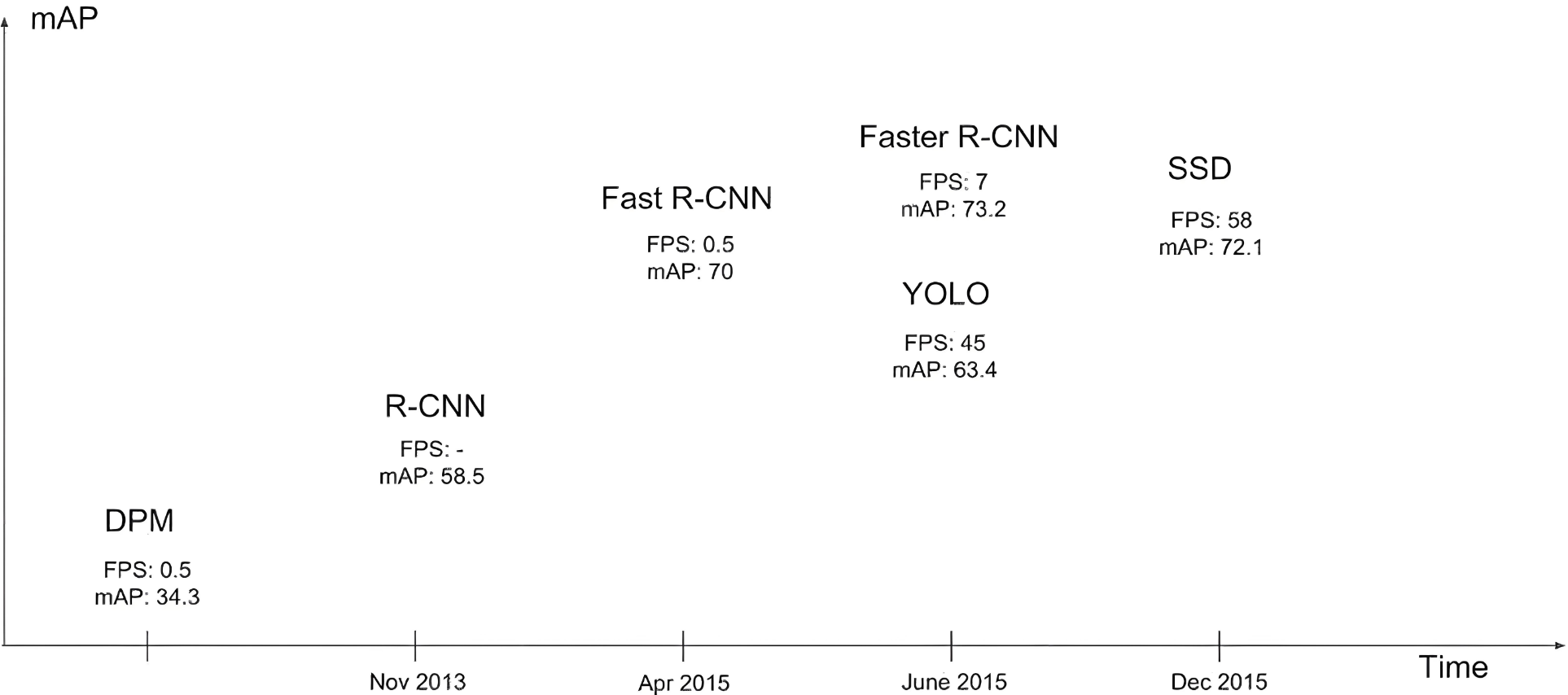
- 目标检测方法可以根据其架构和技术特点进行分类。目前主流的目标检测方法可以分为两大类:两阶段检测方法(Two-stage Detection Methods)和单阶段检测方法(One-stage Detection Methods)
- 分类信息如下表:
| one-stage | two-stage | |
|---|---|---|
| 主要算法 | YOLO系列、SSD | R-CNN、Fast R-CNN、Faster R-CNN |
| 检测精度 | 较低(版本不断更新,精度不断增加) | 较高 |
| 检测速度 | 较快(达到视频流检测级别) | 较慢 |
- two-stage
| 步骤 | 名称 | 输入 | 关键操作 | 输出 | 备注 |
|---|---|---|---|---|---|
| ① Input | 图像输入 | 原始 RGB 图像 | — | 整张图片 | 任意尺寸 |
| ② Conv & Pooling | 主干网络(Backbone) | 图像 | 多层卷积 + 池化 提取深度特征 | 高维特征图 | 常用 ResNet、VGG |
| ③ Conv-Proposal | RPN(Region Proposal Network) | 特征图 | 滑动窗口 + Anchor 机制 → 二分类(前景/背景)+ 框回归 | 候选区域(RoIs) | 每个 RoI 含坐标与前景置信度 |
| ④ RoI Pooling / Align | 区域特征对齐 | 特征图 + RoIs | 将不同大小的 RoI 映射到统一尺寸特征图 | 固定尺寸特征 | 消除尺寸差异,便于后续全连接 |
| ⑤ FC | 全连接层 | 固定尺寸特征 | 展平 → 全连接 → 得到高级特征向量 | 特征向量 | 供分类与回归分支共享 |
| ⑥ Lcls & Lreg | 分类与回归头 | 特征向量 | 并行两个全连接分支: • Lcls:Softmax → 类别概率 • Lreg:BBox 回归 → Δx,Δy,Δw,Δh |
最终检测框 (x,y,w,h,class,score) | 损失函数:L = Lcls + λ·Lreg |
六,指标
6.1 边界框
| No. | 字段 | 详细说明 |
|---|---|---|
| 1 | 定义 | 在目标检测任务中,Bounding Box 是一个轴对齐的矩形,用于在图像中精确标出检测到的物体位置与大小。 |
| 2 | 表示方式 | 常见两种: ① (xmin, ymin, xmax, ymax) – 绝对像素坐标; ② (cx, cy, w, h) – 中心点+宽高。 |
| 3 | 类别标签 | 与框绑定的离散类别名,如 “person”、“car”。在数据集中通常映射为整数 id。 |
| 4 | 置信度分数 | 模型给出的 0–1 连续值,反映“该框内确实存在该类物体且位置准确”的信心。 |
| 5 | 坐标归一化 | 在训练阶段常把坐标除以图像宽高,缩放到 [0, 1],提升数值稳定性。 |
| 6 | 多尺度问题 | 同一物体在不同分辨率的特征图上会生成不同大小的框,需要后续 NMS 去重。 |
| 7 | 方向问题 | 经典轴对齐框无法描述旋转目标;如需旋转检测,可用 (cx, cy, w, h, θ) 五元组。 |
| 8 | IoU 计算依赖 | 框的格式必须统一才能正确计算 IoU;先转成 (xmin,ymin,xmax,ymax) 最方便。 |
| 9 | 标注工具 | LabelImg、CVAT、LabelMe 均支持画矩形框并写入 Pascal VOC / COCO 格式。 |
| 10 | 常见错误 | 框超出图像边界、框面积为零、类别与框错位、重复框未合并。 |
6.2 交并比
| No. | 字段 | 详细说明 |
|---|---|---|
| 1 | 数学公式 | IoU = |A ∩ B| / |A ∪ B| = |A∩B| / (‖A‖+‖B‖−‖A∩B‖)。 |
| 2 | 坐标实现 | 先算交集面积:inter_w = max(0, min(xmax1,xmax2)−max(xmin1,xmin2));高同理。 |
| 3 | 取值范围 | [0, 1]。0 完全不重叠;1 完全重叠。 |
| 4 | 阈值设定 | COCO 默认 mAP 用 0.5:0.05:0.95 十个阈值;Pascal VOC 只用 0.5。 |
| 5 | 图形示意 | 绿框=GT,红框=Pred,重叠部分面积占并集面积的比例即 IoU。 |
| 6 | 退化情况 | 若两框无重叠,交集面积为 0,IoU 直接为 0,无需额外判断。 |
| 7 | 反向传播 | IoU 本身不可导,训练时常用可导近似如 GIoU、DIoU、CIoU Loss。 |
| 8 | 评价影响 | IoU 阈值越高,TP 越严格,mAP 越低;阈值越低,召回高但精度下降。 |
| 9 | 多类别扩展 | 每个类别独立计算 IoU 后再合成 TP/FP/FN,避免跨类别混淆。 |
6.3 置信度
| No. | 字段 | 详细说明 |
|---|---|---|
| 1 | 定义 | 模型对“该框存在目标且定位准确”的总体信心,0–1 连续值。 |
| 2 | 组成 | 在 YOLO 系列中:Conf = Pr(Object) × IoU_pred。 |
| 3 | Pr(Object) | 二分类输出,表示框内有任何前景物体的概率。 |
| 4 | IoU_pred | 非真实 IoU,而是网络额外分支输出的“预测 IoU”,训练时以真实 IoU 做回归目标。 |
| 5 | 类别置信度 | 经过 Softmax 的类别后验概率 Pr(class_i | Object)。 |
| 6 | 综合置信度 | 最终对外展示的分数 = Conf × Pr(class_i | Object)。 |
| 7 | 作用-训练 | 作为正/负样本划分的依据,正样本需要 Conf>τ 且 IoU>τ。 |
| 8 | 作用-推理 | 先滤掉 Conf<τ 的框,再做 NMS,减少冗余和假阳性。 |
| 9 | 阈值经验 | 通用检测:τ=0.3–0.5;严格场景:τ=0.7;召回优先:τ=0.1。 |
| 10 | 输出层 | 最终卷积层输出 (B×(5+C)) 的张量:B 为 anchor 数,5 含 (cx,cy,w,h,Conf),C 为类别置信度。 |
| 11 | 数值校准 | 若发现置信度普遍偏高,可在验证集上用 Platt Scaling 或 Isotonic Regression 重新校准。 |
| 12 | 可视化 | 在 demo 上把置信度保留两位小数画在框旁,便于人工快速判断质量。 |
6.4 混淆矩阵
| No. | 字段 | 详细说明 |
|---|---|---|
| 1 | 定义 | 一个 N×N 方阵 (N=类别数),列=真实标签,行=预测标签,单元格=样本数。 |
| 2 | 扩展 | 检测任务中需先根据 IoU 阈值把预测框分成 TP / FP / FN,再落到矩阵。 |
| 3 | TP | 预测框与 GT 的 IoU≥阈值且类别一致。 |
| 4 | FP | 1) 类别错;2) 类别对但 IoU<阈值;3) 重复检测。 |
| 5 | FN | GT 框没有任何预测框与之匹配(IoU≥阈值且类别对)。 |
| 6 | TN | 背景区域被正确忽略,无框产生。TN 在目标检测里通常数量巨大。 |
| 7 | 构造流程 | a. 按类别循环;b. 每个 GT 找最佳匹配预测;c. 未匹配预测记 FP;d. 未匹配 GT 记 FN。 |
| 8 | 多尺度处理 | 同一 GT 只允许一个 TP,其余重复框即使满足 IoU 也算 FP。 |
| 9 | 结果解读 | 对角线越亮越好;对角线外亮点表示易混淆类别。 |
6.5 精确度和召回率
| No. | 字段 | 详细说明 |
|---|---|---|
| 1 | Precision 定义 | 查准率 = TP / (TP + FP)。衡量“报出来的目标里有多少是对的”。 |
| 2 | Recall 定义 | 查全率 = TP / (TP + FN)。衡量“所有真目标里有多少被找到”。 |
| 3 | AP 计算 | 把 Precision-Recall 曲线按单调递减包络后做积分,得到该类别的 AP。 |
| 4 | mAP | 所有类别 AP 的均值;COCO mAP 还要在 0.5:0.95 十个 IoU 阈值上再平均。 |
| 5 | F1 Score | 2·(P·R)/(P+R),单一指标平衡 Precision 与 Recall。 |
| 6 | PR 曲线 | 横轴 Recall∈[0,1],纵轴 Precision∈[0,1],曲线下面积=AP。 |
| 7 | 阈值影响 | 提高置信度阈值 → Precision↑ Recall↓;降低阈值则相反。 |
| 8 | 可视化 | 把 PR 曲线和 mAP 数值直接画在验证集 TensorBoard,便于调参。 |
| 9 | 实例级统计 | 必须先把框按 IoU 匹配成 TP/FP/FN,再计算 P、R,否则指标无意义。 |
| 10 | 实践注意 | 类别极度不平衡时(如背景占 99%),单独看 Accuracy 会失效,必须看 Precision/Recall/F1。 |
6.6 mAP
6.6.1 PR 曲线
- PR曲线,即精确率(Precision)- 召回率(Recall)曲线,是评估分类模型性能的重要工具之一,尤其是在类别不平衡问题中。它通过展示不同阈值下的精确率和召回率之间的关系,帮助我们理解模型在不同决策边界上的表现
- PR 曲线的生成过程:
- 对于每个样本,模型会输出一个预测分数或置信度,表示该样本属于某一类别的概率
- 设定多个置信度阈值:通常会设定一系列的置信度阈值,比如从 0 到 1,每隔 0.1 设置一个阈值,这些阈值将用于决定哪些预测被视为“正例”(Positive),哪些被视为“负例”(Negative)
- 对于每一个阈值,根据预测分数与该阈值的比较结果,我们可以计算出当前阈值下的精确率(Precision)和召回率(Recall)
- 将每个阈值下的精确率和召回率作为坐标点,绘制在二维平面上,横轴为召回率,纵轴为精确率,从而形成一条曲线

6.6.2 AP
- 在 PR 曲线中,曲线上每个点表示了在对应召回率下的最大精确率值。当 P=R 时成为平衡点(BEP),如果这个值较大,则说明学习器的性能较好。所以 PR 曲线越靠近右上角性能越好。即 PR 曲线的面积越大,表示分类模型在精确率和召回率之间有更好的权衡,性能越好
- 常用的评估指标是 PR 曲线下的面积,即 AP(Average Precision),通过 PR 曲线下的面积来计算 AP,从而综合评估模型在不同置信度阈值下的性能,值越接近 1 越好
- 平均精度(Average Precision, AP)通过计算每个类别在不同置信度阈值下的 Precision(查准率)和 Recall(查全率)的平均值来综合评估模型的性能。AP 被广泛应用于评估模型在不同置信度阈值下的表现,并且是计算 mAP(平均平均精度)的基础
- AP 就是用来衡量一个训练好的模型在识别每个类别时的表现好坏。AP 越高,说明模型在这个类别上的识别能力越强
6.6.3 AP 计算
-
11 点插值法:只需要选取当 Recall >= 0, 0.1, 0.2, …, 1 共11个点,找到所有大于等于该 Recall 值的点,并选取这些点中最大的 Precision 值作为该 Recall 下的代表值,然后 AP 就是这 11 个 Precision 的平均值
A P = 1 11 ∑ r ∈ { 0 , 0.1 , . . . , 1 } p i n t e r p ( r ) p i n t e r p ( r ) = max r ~ : r ~ ≥ r p ( r ~ ) r ~ 表示大于或等于 r 实际召回率,并选择这些召回率对应的精确率中的最大值作为插值精确率 \mathrm{AP}=\frac{1}{11}\sum_{r\in\{0,0.1,...,1\}}p_{interp(r)}\\ p_{interp(r)}=\max_{\tilde{r}:\tilde{r}\geq r}p(\tilde{r}) \\ \tilde{r}表示大于或等于r实际召回率,并选择这些召回率对应的精确率中的最大值作为插值精确率 AP=111r∈{0,0.1,...,1}∑pinterp(r)pinterp(r)=r~:r~≥rmaxp(r~)r~表示大于或等于r实际召回率,并选择这些召回率对应的精确率中的最大值作为插值精确率
-
面积法:需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些 Recall 值时的 Precision 最大值,然后计算 PR 曲线下面积作为 AP 值,假设真实目标数为 M,recall 取样间隔为 [0, 1/M, …, M/M],假设有 8 个目标,recall 取值 = [0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0]
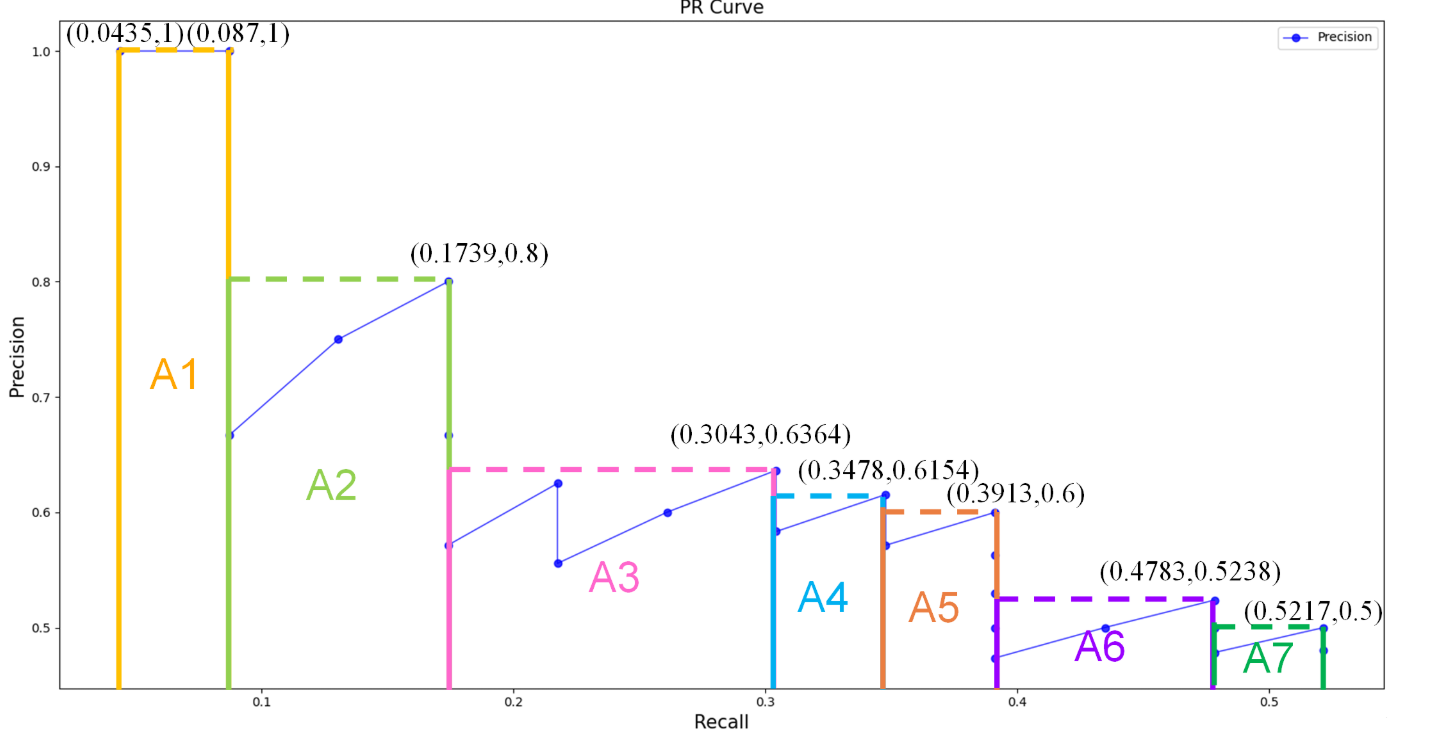
-
把各块面积加起来就是 AP 值
6.6.4 mAP
- 平均平均精度(mean Average Precision,mAP) 是在不同置信度阈值下计算的平均精确度(Average Precision, AP)的平均值AP 是在不同召回率水平下的精确度平均值,而 mAP 则是多个类别上的 AP 的平均值
| 名称 | 含义 | 说明 |
|---|---|---|
| AP(Average Precision) | 衡量模型在某一类别上的检测或分类性能 | 通过 Precision-Recall 曲线下的面积来计算,值越高表示模型在该类别上的性能越好 |
| mAP(mean Average Precision) | 模型在所有类别上的 AP 的平均值 | 衡量模型整体性能的综合指标,值越高表示模型在所有类别上的平均表现越好 |
- mAP 计算步骤:
- 计算每个类别的 AP:对于数据集中包含的每个类别,分别计算 AP
- 计算 mAP:将所有类别的 AP 取平均值,得到 mAP
七,NMS 后处理技术
- 非极大值抑制(Non-Maximum Suppression,NMS) 是目标检测任务中常用的后处理技术,用于去除冗余的边界框(Bounding Boxes),保留最有可能的检测结果
- 在目标检测中,模型通常会对同一目标生成多个边界框(预测框),这些边界框之间可能高度重叠。NMS 的作用就是筛选出置信度高、位置准确的边界框,抑制其他冗余的预测框
- NMS 的基本思想是:对于每一个预测的类别,按照预测边界框的置信度(Confidence Score)对所有边界框进行排序,然后依次考虑每个边界框,将其与之前的边界框进行比较,如果重叠度过高,则丢弃当前边界框,保留置信度更高的那个,对于每个类别会独立进行操作
- NMS 的步骤:
- 设定目标框置信度阈值,常设置为 0.5,小于阈值的目标框被过滤掉
- 将所有预测的满足置信度范围的边界框按照它们的置信度从高到低排序
- 选取置信度最高的框(不同类型分开处理)添加到输出列表,并将其从候选框列表中删除
- 对于当前正在考虑的边界框,计算其与前面已选定的边界框的重叠程度(IoU),如果当前边界框与已选定边界框的 IoU 大于某个阈值(如 0.5),则将其抑制(即不保留,重合度过高);否则保留当前边界框,并继续处理下一个边界框
- 重复上述步骤,直到所有边界框都被处理完毕
- 输出列表就是最后留下来的目标框

八,检测速度
| 维度 | 子维度 | 定义 / 公式 | 包含阶段或单位换算 | 典型耗时或数值范围 | 实时性要求 | 备注 & 易错点 |
|---|---|---|---|---|---|---|
| 前向传播耗时 | 概念 | 从输入图像到最终检测结果的总耗时 | Preprocessing + Forward-Pass + Postprocessing | 桌面 GPU:20–100 ms / 张;嵌入式:100–500 ms / 张 | 越低越好 | 通常以毫秒 (ms) 为单位 |
| ① 前处理 | 图像归一化、缩放、填充、BGR→RGB、NHWC→NCHW | 约 1–5 ms(CPU) | 可并行 | OpenCV + CUDA 可加速 | ||
| ② 网络推理 | backbone+neck+head 完整前向 | 占整体 60–90 % | 与 FLOPS/内存带宽强相关 | 需实测,框架差异大 | ||
| ③ 后处理 | NMS、置信度过滤、类别筛选 | 1–10 ms(CPU NMS)或 <1 ms(GPU NMS) | NMS 可并行 | batch>1 时耗时线性增长 | ||
| FPS | 定义 | Frames Per Second,每秒处理帧数 | FPS = 1 / Total Inference Time (s) | ≥ 30:实时;≥ 60:低延迟;15–25:移动端可用 | 30/60/120 为常用门槛 | 需区分 “batch=1 FPS” 与 “batch=8 FPS” |
| FLOPS | 概念 | 每秒浮点运算次数,衡量硬件算力 | 理论峰值:设备规格给出;模型 FLOPs:统计网络总乘加数 | 模型侧:0.5 GFLOPs (MobileNet-YOLO) – 200 GFLOPs (YOLOv7-X) | 越低越易部署 | 勿混淆 FLOPS(设备)与 FLOPs(模型) |
| 单位 | KFLOPS | 10³ FLOPS | — | — | 极少用于深度学习 | |
| MFLOPS | 10⁶ FLOPS | — | — | 老文献/ MCU 场景 | ||
| GFLOPS | 10⁹ FLOPS | RTX 3060:≈ 13 TFLOPS → 13 000 GFLOPS | 最常用 | 报告模型时常用 GFLOPs | ||
| TFLOPS | 10¹² FLOPS | A100:312 TFLOPS (FP16) | 数据中心卡 | 乘以利用率≈实际 | ||
| PFLOPS | 10¹⁵ FLOPS | 超算整机 | — | 极少在单卡出现 |
九,yolo整体结构
-
YOLO(You Only Look Once) 是一类单阶段目标检测器(One-stage Detector),其核心特点是速度快、端到端推理。其网络结构通常由以下 三个主要模块 组成:
- Backbone(主干网络):负责从输入图像中提取高维特征信息,提供丰富的语义与空间信息供后续使用。
- Neck(颈部网络):对主干网络输出的多尺度特征进行整合与融合,增强特征的表达能力与鲁棒性。
- Detection Head(检测头):在融合后的特征图上直接预测物体的类别与边界框坐标,生成最终检测结果。
-
网络结构图:

-
内部结构图:
9.1 Backbone network
- 描述:
- Backbone network,即主干网络(骨干网络),是目标检测网络最为核心的部分,主要使用不同的卷积神经网络构建。
- 任务:
- 特征提取:从输入图像中提取特征信息,这些特征通常包含丰富的语义与空间信息,能够帮助后续模块进行目标检测。
9.2 Neck network
- 描述:
- Neck network,即颈部网络,主要对主干网络输出的特征进行整合。
- 任务:
- 特征融合:将主干网络提取的多尺度特征进行融合,以增强特征的表达能力和鲁棒性。
9.3 Detection head
- 描述:
- Detection head,即检测头,在特征之上进行预测,包括物体的类别和位置。
- 任务:
- 目标检测:检测头的主要任务是基于融合后的特征图,通过回归任务预测边界框的坐标,通过分类任务预测目标的类别,生成最终的检测结果,包括边界框和类别。
9.4 总结
- YOLOv1–YOLOv4:学习掌握 YOLO 作者的设计思路和优化方式【理论】。
- YOLOv5 和 YOLO11:学习掌握使用 YOLO 开源算法完成模型的训练、应用、优化等【实践】。
十,YOLO系列发展史
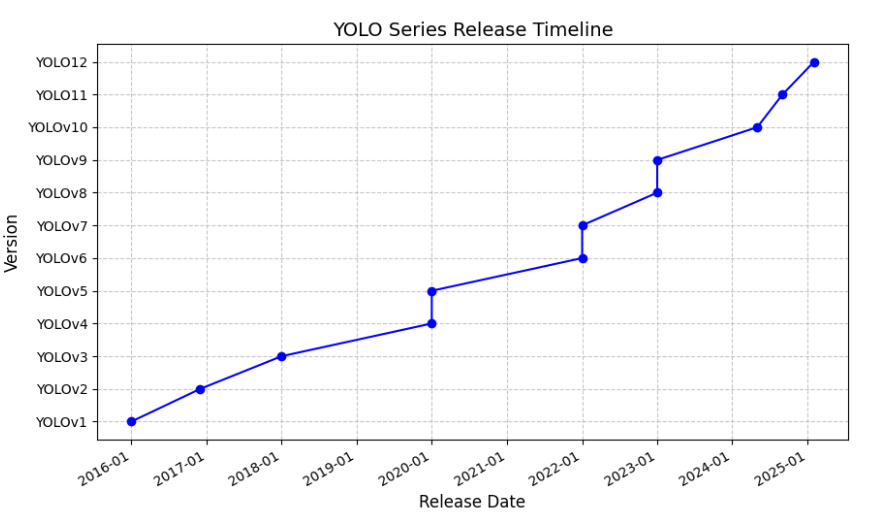
YOLOv1 到 YOLO13 的主要贡献者列表:
-
YOLOv1:主要由 Joseph Redmon、Santosh Divvala、Ross Girshick 和 Ali Farhadi 共同开发
-
YOLOv2:主要由 Joseph Redmon 和 Ali Farhadi 共同开发
-
YOLOv3:主要由 Joseph Redmon 和 Ali Farhadi 共同开发
-
YOLOv4:主要由 Alexey Bochkovskiy、Chien-Yao Wang 和 Hong-Yuan Mark Liao 开发
-
YOLOv5:主要由 Ultralytics 团队开发
-
YOLOv6:主要由美团团队开发
-
YOLOv7:主要由 I-Hau Yeh、Chien-Yao Wang 和 Hong-Yuan Mark Liao 开发
-
YOLOv8:主要由 Ultralytics 团队开发,被 YOLO11 覆盖了
-
YOLOv9:主要由 Alexey Bochkovskiy、Chien-Yao Wang 和 Hong-Yuan Mark Liao 开发
-
YOLOv10:主要由清华大学团队开发
-
YOLO11:主要由 Ultralytics 团队开发,2024 年 9 月 30 日发布
-
YOLO12:由纽约州立大学布法罗分校的田运杰,David Doermann 和中国科学院大学的叶齐祥合作完成,2025 年 2 月 18 日发布
-
YOLO13:清华大学联合太原理工大学、北京理工大学等高校团队于2025年6月26日正式发布
更多推荐
 38
38 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)