
毕业设计:基于深度学习实现人脸识别防伪的活体检测技术研究
人脸识别防伪检测方法,集中于活体检测技术的实现,结合了FaceNet与Dlib深度学习框架。通过构建自制的人脸图像数据集,收集并标注不同条件下的活体与非活体图像,采用深度学习算法对人脸进行自动识别与验证。研究中应用了多种数据增强和特征提取技术,以提高活体检测的准确性和系统的鲁棒性。对于计算机专业、人工智能专业、大数据专业、信息安全专业、软件工程专业的毕业生而言,不论是对于深度学习技术感兴趣的同学,
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习实现人脸识别防伪的活体检测技术研究
项目背景
随着人脸识别技术的广泛应用,安全性和防伪性问题逐渐凸显。尤其在金融、安防等领域,如何有效实现对人脸的准确识别并防止伪造身份的行为,成为亟待解决的挑战。活体检测作为人脸识别中的一个重要环节,旨在通过判断识别对象是否为真实存在的人来提高系统的安全性。传统的人脸识别技术容易受到照片、视频等静态图像的欺骗,因此结合深度学习技术,如FaceNet和Dlib,可以有效提升活体检测的准确性和鲁棒性。通过构建自制数据集并采用先进的算法,我们可以实现高效的人脸防伪检测,为各类安全应用提供有力的技术保障。
数据集
数据收集的重点是收集多样化的人脸图像,包括真实的活体图像和伪造的图像(如照片、视频流或面具等)。为了确保数据集的广泛性和代表性,图像应涵盖不同年龄、性别、种族和光照条件下的人脸。此外,建议在不同的环境和场景中收集数据,以增强模型的泛化能力。收集到的图像需要进行准确的标注,将活体图像标记为“真实”,而伪造图像则标记为“伪造”。在这一过程中,使用专业的图像标注工具可以提高效率和准确性。同时,通过仔细审查图像,去除重复、不清晰或低质量的样本,以确保数据集的质量。

数据预处理包括裁剪、缩放和归一化等步骤,使所有图像统一到固定的尺寸和格式。此外,应用数据增强技术(如旋转、翻转、亮度调整等)可以增加训练样本的多样性,这对于提高模型的鲁棒性和泛化能力具有重要意义。
设计思路
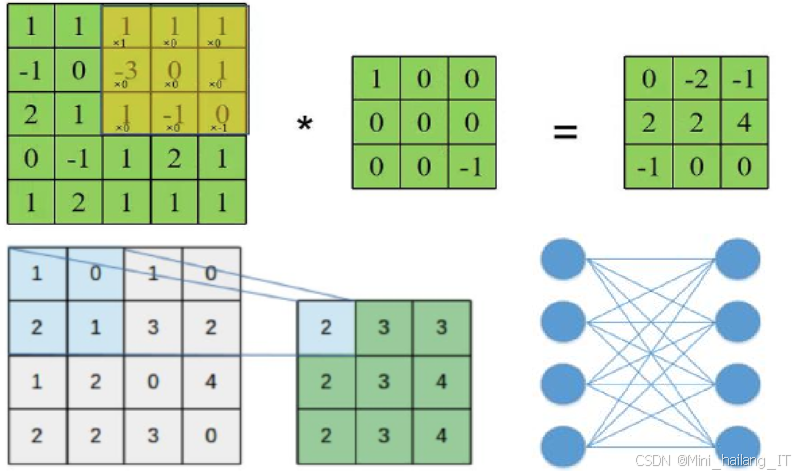
卷积神经网络(CNN)作为深度学习的重要组成部分,已成为计算机视觉领域的基础模型之一,其设计灵感源自人类大脑处理视觉信息的方式。CNN通过局部连接、共享权重和空间不变性等机制,能够有效提取图像中的层次特征,从简单的边缘和纹理到更复杂的形状和对象,从而实现自动化的特征学习。网络的基本结构通常包括卷积层、激活层、池化层和全连接层,其中卷积层通过卷积运算提取特征,激活层引入非线性特性,池化层有效降低计算复杂度并提高特征的稳定性,全连接层则将提取到的特征映射到特定的输出类别。
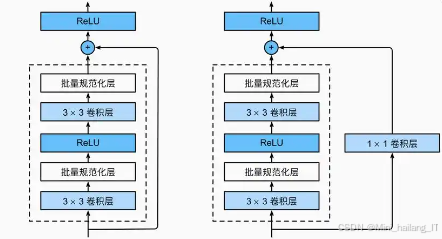
ResNet是一种深度卷积神经网络架构,核心思想是通过引入残差学习机制来解决深层网络训练中的梯度消失和梯度爆炸问题。传统的深度网络随着层数的增加,训练效果往往会恶化,而ResNet通过添加“跳跃连接”允许信号在网络中直接传递,从而使得网络的深度可以显著增加而不影响训练效果。网络的每个残差块由两层卷积层和一个短路连接组成。短路连接将输入直接加到卷积层的输出上,这样模型不仅学习到当前层的特征,还能够保留前面层的特征信息。这种结构使得网络在学习特征时能够更加灵活,同时也加速了收敛过程。
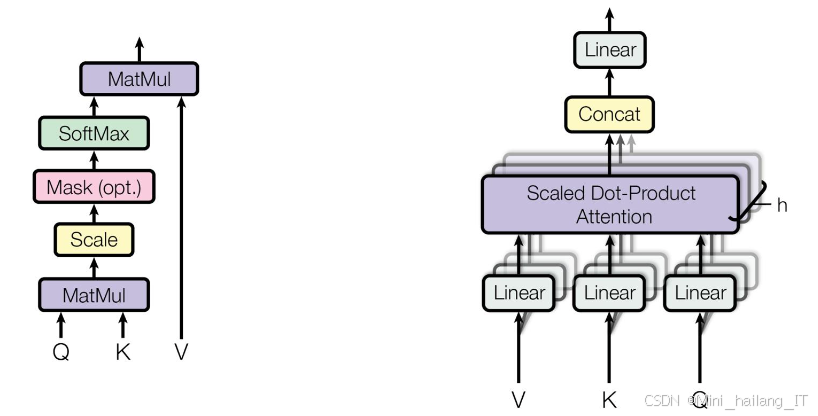
位置注意力机制和通道注意力机制是计算机视觉中提升特征图表示能力的关键技术,它们通过不同方式帮助模型聚焦于图像中的关键信息。位置注意力机制通过动态计算特征图中各空间位置的关联性,为每个位置分配权重,使模型能够自适应关注重要区域,从而提升特征表达能力。这一机制通常采用类似自注意力的方法,计算位置间的相似性得分,并通过Softmax函数归一化生成权重,强调重要区域并抑制无关部分,广泛应用于图像分类和目标检测等任务。相对而言,通道注意力机制则专注于特征图中各通道之间的关系,动态调整通道权重,突出重要特征通道并抑制不重要通道。在实现上,它利用全局平均池化或全局最大池化获取通道统计信息,通过小型全连接网络学习通道重要性,最终通过加权通道特征优化特征表示效果。
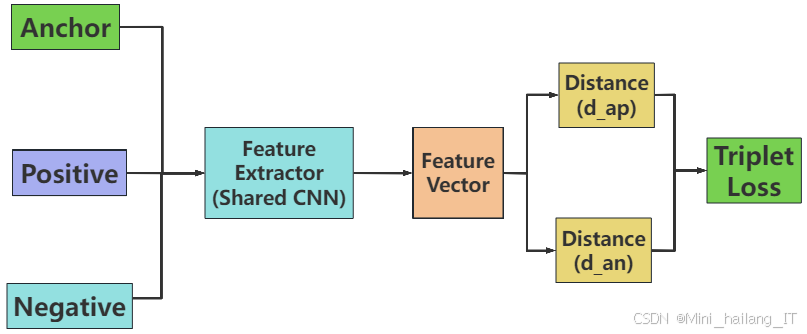
三元组挖掘算法是一种用于优化特征空间的技术,特别在处理人脸识别和图像检索等任务中应用广泛。该算法基于三元组结构,其中锚样本是待识别的样本,正样本是与锚样本属于同一类别的样本,负样本是与锚样本属于不同类别的样本。通过最小化锚样本与正样本之间的距离,同时最大化锚样本与负样本之间的距离,模型能够更好地学习到特征空间中不同类别之间的决策边界。在三元组挖掘过程中,选择合适的正样本和负样本至关重要。通常会采用半难样本挖掘策略,即选择那些距离锚样本较近但仍属于不同类别的负样本,以增强模型的学习效果。这种方法有助于提高模型的区分能力,特别是在样本不均衡或类别重叠严重的情况下。
收集大量的图像数据集。这些图像应包括真实的人脸图像(活体数据)和伪造的人脸图像(如照片、视频或面具等)。数据集应该具有多样性,包括不同年龄、性别、种族和光照条件下的人脸图像,以确保模型的泛化能力。在训练之前,对收集到的数据进行预处理是非常重要的。预处理步骤包括图像的裁剪、缩放、归一化以及数据增强。裁剪和缩放可以确保所有图像具有相同的尺寸,而归一化可以帮助模型更快地收敛。数据增强技术(如旋转、翻转、亮度调整等)可以增加训练样本的多样性,提升模型的鲁棒性。
from keras.preprocessing.image import ImageDataGenerator
def preprocess_data(images):
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
processed_images = []
for img in images:
img = cv2.resize(img, (224, 224)) # Resize to a fixed size
processed_images.append(img)
return processed_images
processed_real_faces = preprocess_data(real_faces)
processed_fake_faces = preprocess_data(fake_faces)根据任务需求选择合适的深度学习模型。常用的模型包括卷积神经网络和预训练的深度学习模型。预训练模型在大规模数据集上训练过,能够提取更丰富的特征,因此通常用于迁移学习,特别是在数据量较少的情况下。使用预处理后的数据集训练模型。通常会将数据分为训练集和验证集。训练过程中,使用合适的损失函数和优化器来更新模型参数。监控训练过程中的损失和准确率,根据验证集的表现调整超参数。
from keras.applications import VGG16
from keras.models import Model
def build_model():
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = base_model.output
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x) # Binary classification (real or fake)
model = Model(inputs=base_model.input, outputs=predictions)
return model
model = build_model()对模型进行评估,使用独立的测试集来验证模型的性能。评估指标通常包括准确率、精确率、召回率和F1分数。通过这些指标可以判断模型的有效性和鲁棒性。训练和评估完成后,模型可以部署到实际应用中。部署时需要考虑模型的推理速度和资源消耗,确保其在实时检测中的可用性。可以使用TensorFlow 进行模型的服务化部署。
def evaluate_model(model, test_data, test_labels):
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print(f'Test accuracy: {test_accuracy:.2f}')
evaluate_model(model, processed_test_faces, test_labels)海浪学长项目示例:
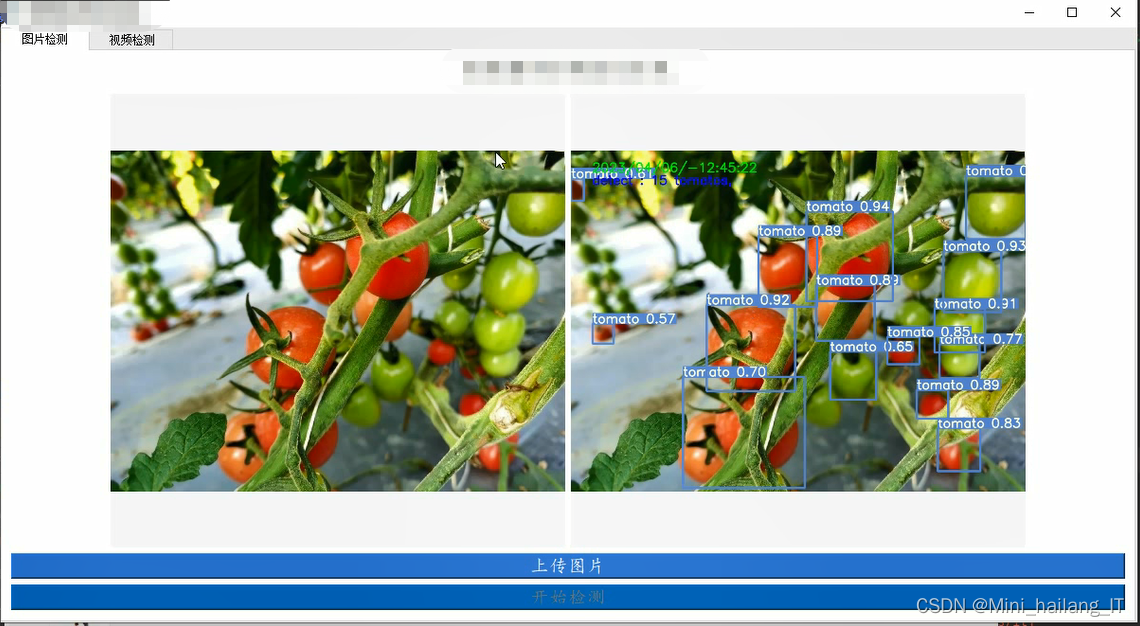



更多帮助
更多推荐


 25
25 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)