
深度学习入门(五)——常见模块与工程实践:从激活函数到BatchNorm、Dropout、初始化与训练稳定性
本文深入探讨了深度学习训练中的关键模块与实践经验。主要内容包括:1)激活函数的选择与比较(如ReLU、GELU等);2)BatchNormalization的原理与优势;3)Dropout的正则化作用;4)权重初始化策略(Xavier、He等);5)正则化技巧与学习率调度方法。文章强调,良好的训练稳定性需要这些模块的协同配合,并提供了工程实践建议:如卷积网络推荐ReLU+BN组合,Transfor
一、前言
前几篇我们讲了神经网络的基本结构、反向传播机制,以及优化算法的演化。
到了这一步,模型的数学原理我们已经有了清晰的认识。
但在真正的训练过程中,你会发现事情并不如公式那般优雅。
有时候,模型刚开始训练就发散;
有时候,loss 会莫名停在一个地方不再下降;
有时候,同样的代码,只是改了个激活函数,效果就天差地别。
这些问题都属于训练稳定性与模型工程结构设计的范畴。
而这里面涉及的关键模块,正是——激活函数、Batch Normalization、Dropout、权重初始化、正则化与学习率调度等。
这篇文章,我们将以实践为核心、原理为支撑,深入探讨这些模块的作用机制与工程经验。
二、激活函数:让网络真正“活”起来
2.1 为什么需要激活函数
如果网络中每一层都是线性的,例如:
![]()
那其实整个网络可以简化为:
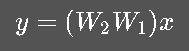
也就是说,多层线性变换仍然是线性变换。
这样一来,模型再深也无法拟合复杂的非线性模式。
激活函数的作用,就是在层与层之间引入非线性变换。
这使得神经网络能够逼近任意函数(即通用逼近定理)。
2.2 常见激活函数与分析
(1) Sigmoid
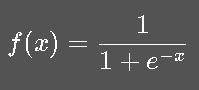
优点:
-
输出范围在 (0,1),可视作概率;
-
早期神经网络中使用广泛。
缺点:
-
梯度容易在饱和区(x很大或很小时)变得接近 0;
-
中心点非零(均值不为0),导致后层梯度偏移;
-
在深层网络中容易出现梯度消失。
(2) Tanh
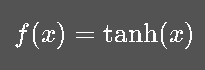
输出范围在 (-1,1),中心对称性更好,但仍存在梯度消失问题。
(3) ReLU
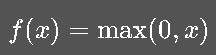
优点:
-
简单高效;
-
非线性明显;
-
不会饱和(在正区间)。
缺点:
-
负区间输出恒为0,可能导致“神经元死亡”(参数永远不更新)。
(4) Leaky ReLU
为了解决 ReLU 死亡问题,给负区间加上微小斜率:
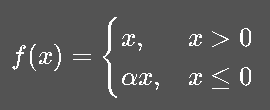
常取
(5) GELU(Gaussian Error Linear Unit)
Transformer 等模型常用:
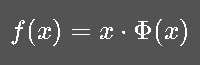
其中![]() 是标准高斯分布的累积分布函数。
是标准高斯分布的累积分布函数。
它在![]() 时平滑衰减,表现介于 ReLU 与 Sigmoid 之间。
时平滑衰减,表现介于 ReLU 与 Sigmoid 之间。
直观理解:GELU 比 ReLU 更平滑,对梯度友好;在大模型中普遍表现更优。
2.3 工程实践建议
| 场景 | 建议激活函数 |
|---|---|
| 卷积网络 | ReLU / Leaky ReLU |
| RNN | Tanh / ReLU |
| Transformer / 大语言模型 | GELU |
| 小模型或轻量任务 | ReLU 优先(计算快) |
一般情况下,ReLU 是默认首选。
如果模型较深或对梯度流动敏感,可以考虑 GELU 或 Swish。
三、Batch Normalization:为训练稳定保驾护航
3.1 背景问题
在训练过程中,随着参数不断更新,各层输入分布也在变化——
这被称为 Internal Covariate Shift(内部协变量偏移)。
这种变化会导致模型训练不稳定,学习率需要很小才能收敛。
Batch Normalization(简称 BN)由 Ioffe 和 Szegedy 于 2015 年提出,用于解决此问题。
3.2 BN 的核心思想
BN 在每个 mini-batch 内,对每个通道的数据进行标准化:
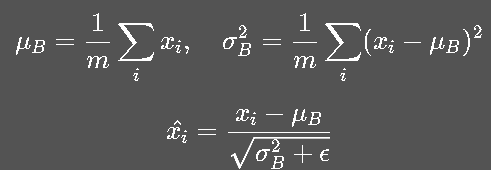
然后引入可学习的缩放和平移参数:
![]()
这样可以让网络在不同 batch 间保持统计稳定性,又不限制模型表达能力。
3.3 BN 的优势
-
缓解梯度消失/爆炸;
-
允许更高学习率,加速收敛;
-
起到一定正则化效果,减少过拟合。
3.4 实践细节
-
对 CNN:通常放在卷积层和激活函数之间或之后。
-
对 全连接层:同理,可在激活函数前或后。
-
对 RNN / Transformer:可使用 LayerNorm 替代 BN,因为 BN 在时间维度上难以统计稳定。
3.5 BN 的推理阶段
训练时使用 batch 内统计量;
推理时使用移动平均统计量(running mean/var),以保持一致性。
伪代码:
# Training phase
mu = mean(x_batch)
var = var(x_batch)
x_hat = (x_batch - mu) / sqrt(var + eps)
y = gamma * x_hat + beta
# Inference phase
x_hat = (x - running_mean) / sqrt(running_var + eps)
y = gamma * x_hat + beta
四、Dropout:主动“遗忘”以防过拟合
4.1 背景
过拟合是深度学习常见问题。
模型参数太多时,会“死记硬背”训练样本,而不是学习通用规律。
4.2 思想
Dropout 的核心思路是:
训练时,随机“关闭”一部分神经元。
这样可以防止网络过度依赖某些节点,迫使模型学到更健壮的特征。
公式上:
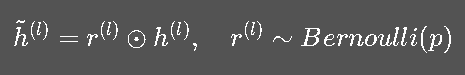
其中 ppp 是保留概率。
4.3 推理阶段的处理
推理时,我们不再丢弃节点,而是按期望缩放:
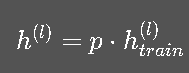
4.4 实践建议
| 网络类型 | Dropout 范围 |
|---|---|
| 全连接层 | 0.3~0.5 |
| 卷积层 | 0.1~0.3 |
| RNN | 使用 Variational Dropout |
| Transformer | 常用 0.1 |
值得注意的是,在现代网络(如 ResNet, Transformer)中,BN 与数据增广 已足够强,Dropout 反而可能削弱性能。
五、权重初始化:深度学习的隐形基石
5.1 为什么初始化重要
在训练开始时,如果参数初始化不当:
-
太大:梯度爆炸;
-
太小:梯度消失;
-
偏置过多:学习速度极慢。
所以,良好的初始化策略能显著提高模型收敛速度。
5.2 常见初始化方法
(1) Xavier 初始化
适用于 Sigmoid / Tanh 激活:
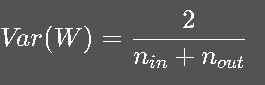
(2) He 初始化
适用于 ReLU / Leaky ReLU:
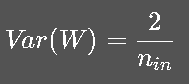
(3) Orthogonal 初始化
保持不同通道方向独立,适合 RNN。
5.3 实践经验
| 激活函数 | 推荐初始化 |
|---|---|
| ReLU / Leaky ReLU | He 初始化 |
| Tanh / Sigmoid | Xavier 初始化 |
| GELU | He 初始化 |
| RNN / LSTM | Orthogonal 初始化 |
六、正则化与泛化技巧
除了 Dropout,以下几种正则化也常用于深度学习:
6.1 L2 权重衰减
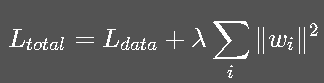
与 AdamW 结合效果最好。
6.2 数据增强
对于视觉任务,数据增强几乎是默认操作:
-
随机裁剪、翻转、颜色扰动;
-
Mixup / CutMix;
-
AutoAugment 自动增强策略。
对于 NLP,可使用同义词替换、Mask、回译等。
6.3 Early Stopping
监控验证集 loss,当其不再下降时提前终止训练。
七、学习率调度:控制收敛节奏
即便是同一优化器,学习率曲线的设计 也会影响训练结果。
常见策略:
| 调度策略 | 特点 |
|---|---|
| StepLR | 固定步长下降 |
| Cosine Annealing | 平滑衰减,收敛稳定 |
| Warmup + Cosine | Transformer 标配 |
| Cyclical LR | 周期性波动,可跳出局部最优 |
伪代码示例(Cosine):
lr_t = lr_min + 0.5 * (lr_max - lr_min) * (1 + cos(pi * t / T))
八、综合实践经验
-
激活函数选得对,训练能快一半。
ReLU 是默认选择,GELU 是现代Transformer常用。 -
BatchNorm 几乎是训练深网的标配,尤其在卷积网络中。
-
初始化决定第一步是否能走对方向。
不恰当初始化会让优化器“找不到梯度”。 -
正则化与数据增强相辅相成。
不要迷信 Dropout,它不是万灵药。 -
学习率调度与优化算法配合使用,往往比单独换优化器更有效。
九、结语
到这里,我们已经从理论走到了实践。
从神经元与前向传播,到反向传播、优化算法,再到这篇的激活函数、BN、Dropout 与初始化,
这条路径基本覆盖了深度学习训练中最核心的“通用底层知识”。
深度学习并不神秘,它只是大规模的数值优化与经验工程的结合。
当你理解了梯度的意义,掌握了训练稳定的技巧,
你会发现,大多数“玄学调参”其实都有可解释的逻辑。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)