
车辆检测-目标检测-YOLO-深度学习毕设
本文介绍了基于深度学习的车辆检测识别项目,采用YOLO系列算法(包括YOLOV5/V8/V10/V11)实现目标检测。项目针对交通管理需求,通过改进网络结构、添加动态卷积模块和注意力机制等优化措施,提升模型在复杂场景下的检测性能。提供完整的技术路线、数据集信息(9202张图片)和多种模型对比实验,并基于PYQT5开发了两种风格的GUI演示系统。项目包含详细视频教程(4-6小时),涵盖环境配置、代码
大家好,我是B站的UP主:我喜欢吃小熊饼干。我在CSDN会写一些文章介绍我做的项目,这些项目我都录制了详细的讲解视频(约4-6个小时的内容量),讲解基础知识,环境配置,代码使用等内容。
详细了解请移步-目标检测合集:
详细讲解视频-哔哩哔哩视频-我喜欢吃小熊饼干的主页![]() https://space.bilibili.com/284801305
https://space.bilibili.com/284801305
几分钟快速预览项目效果的演示视频:
【计算机毕设】基于深度学习的车辆检测识别【YOLO】【目标检测】【车辆检测】【Pytorch】

详细的讲解视频合集:
- 合集第一集:主要讲对整个教程的介绍,深度学习项目的基本做法和基本概念。然后介绍具体该项目的基本做法。如何去扩张项目,增加更多的内容。(这里不会涉及到代码,纯从项目的做法的角度,以PPT讲解的方式带大家入门,建立深度学习的基本概念)
- 合集第二集:毕设选题指导,毕设服务等内容
- 合集第三集:从代码使用和演示的角度,介绍项目的内容。科普深度学习环境配置的知识,如何配置项目,如何使用项目,更换数据集训练,完成特定的课题。
- 合集第四集:讲解文档相关的内容,开题报告、开题ppt、开题答辩,论文写作,论文答辩等
第一集和第三集比较重要,可以整体看下这两个视频。
下面我用文字介绍一下项目的内容
项目的背景意义:
在城市化进程加速与机动车保有量持续增长的背景下,交通系统面临着管理效率提升、安全风险防控、资源优化配置的多重挑战,而车辆检测作为交通信息采集与智能化管理的核心环节,其精准性与实时性直接关系到交通系统的运转效率与安全水平。传统车辆检测模式依赖线圈感应、视频人工监控等技术,存在覆盖范围有限、环境适应性差、实时响应不足等问题 —— 例如,线圈检测易受道路施工影响,人工监控难以应对复杂交通流中的多车辆动态追踪,且无法快速捕捉违规变道、闯红灯等瞬时行为,制约了交通管理从 “被动应对” 向 “主动预警” 的转型。同时,在智慧交通体系建设中,车辆检测数据是交通流量分析、信号配时优化、交通事故追溯的重要基础,传统检测方式难以提供规模化、高精度的数据分析支撑,难以满足现代交通对精细化管理的需求。
随着深度学习技术在计算机视觉领域的突破,目标检测算法(如 YOLO)凭借实时性强、多目标识别能力优、复杂环境适应性好的特点,为车辆检测提供了全新技术路径。YOLO 算法通过单次卷积神经网络实现目标定位与分类,能够在复杂场景(如雨天、夜间、多车辆遮挡)中快速捕捉车辆的形态特征与运动轨迹,突破传统检测的技术瓶颈。对于深度学习方向的毕业设计而言,基于 YOLO 的车辆检测项目不仅是对理论知识的实践转化,更承载着连接学术研究与行业需求的重要价值。
从实践意义来看,该项目能够探索 YOLO 算法在车辆检测场景中的优化空间 —— 例如,通过改进网络结构提升小目标车辆(如摩托车)的检测精度,通过数据增强技术增强算法对恶劣天气的适应性,为实际交通场景中的技术落地提供实验依据。同时,项目所形成的车辆检测模型可作为智慧交通系统的核心模块,为交通流量预测、违规行为自动识别、应急车辆优先通行调度等应用提供技术支撑,推动交通管理向智能化、高效化转型。从科研意义来看,项目通过对目标检测算法的应用与优化,有助于加深对深度学习模型在计算机视觉领域应用逻辑的理解,培养数据处理、模型训练、性能评估的综合科研能力,为后续在智能交通、自动驾驶、视频监控等领域的深入研究奠定基础。
此外,该毕设项目还具备行业与社会层面的延伸价值:在行业层面,其研究成果可为交通科技企业提供技术参考,推动车辆检测技术的产品化与标准化;在社会层面,通过提升车辆检测的精准性与实时性,有助于减少交通事故发生率、缓解交通拥堵、优化公共交通资源配置,提升公众出行的安全性与便捷性。从长远来看,基于 YOLO 的车辆检测技术不仅是智慧交通建设的重要支撑,更是推动城市基础设施智能化升级的关键环节,对构建高效、安全、绿色的现代交通体系具有深远意义,而毕设项目作为技术探索的起点,其研究过程与成果将为这一领域的发展注入鲜活的学术实践力量。
项目的技术路线图
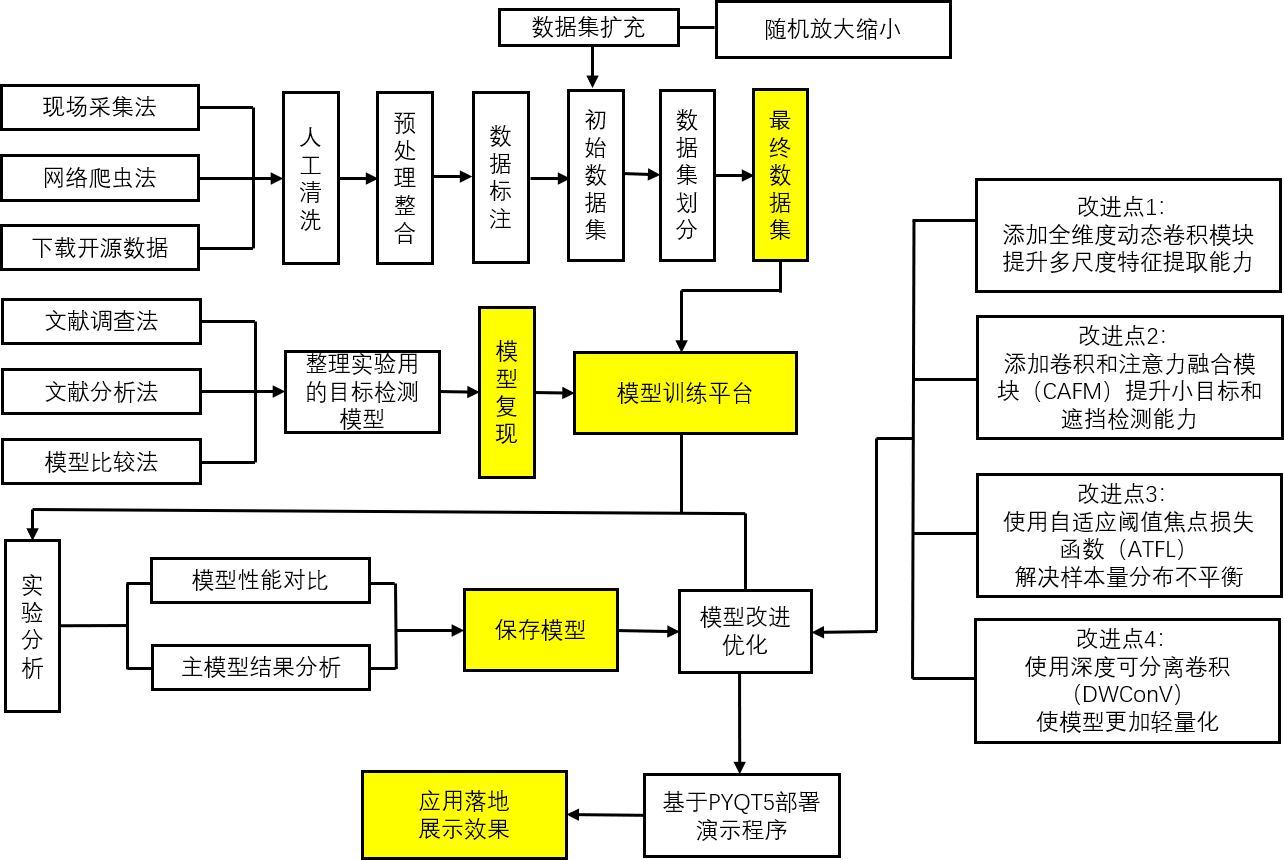
项目的数据集信息如下:
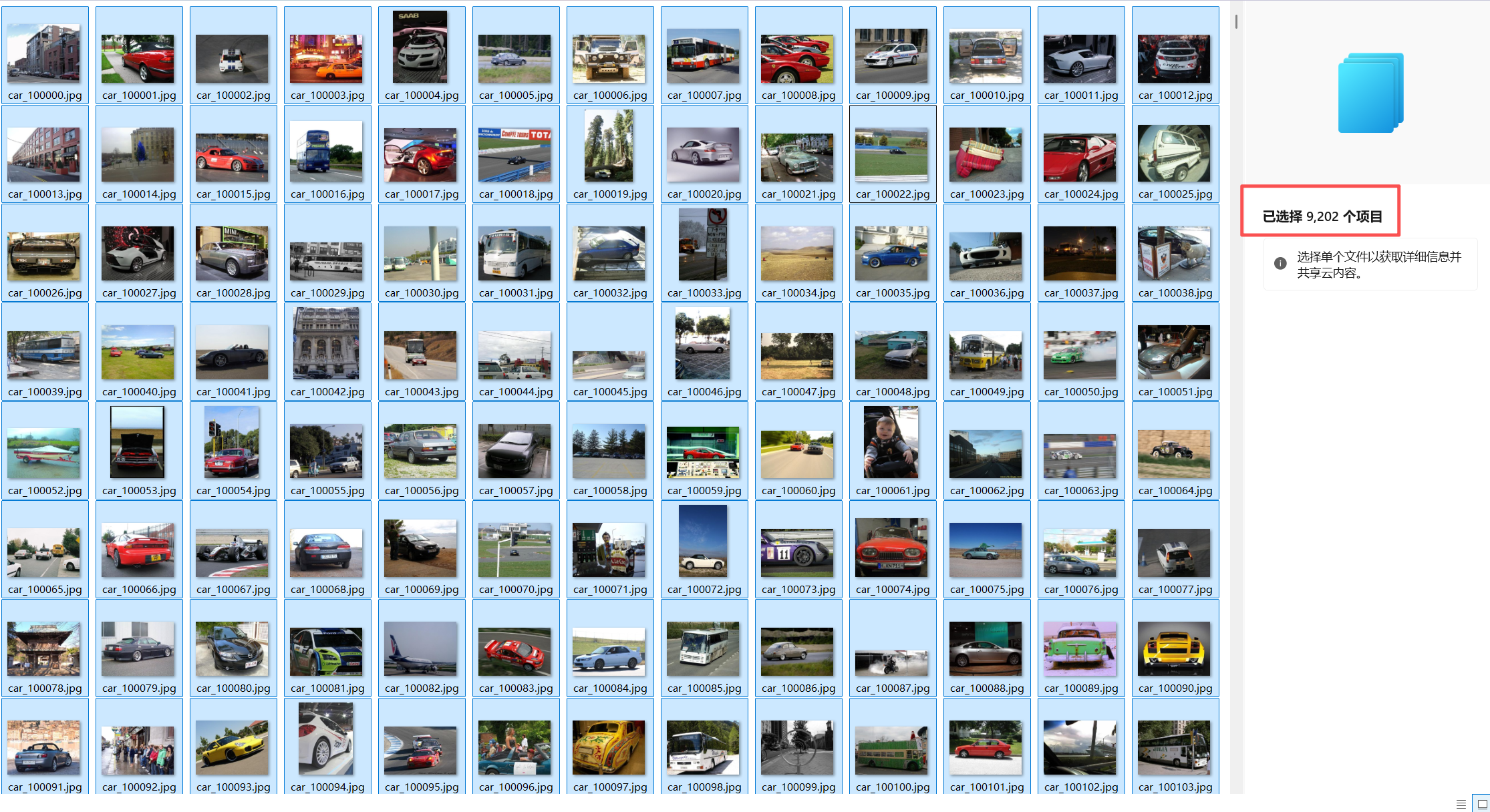

数据集图片一共有9202张图片。
标注数量信息如下:
bus: 7999 巴士
car: 27440 小轿车
类别数量: 2
一张图片可以有多个标注对象,所以标注数量的总和不一定是图片的总和。
项目里实现了多种目标检测YOLO模型:
1.YOLOV5
2.YOLOV8
3.YOLOV10
4.YOLOV11
并且对YOLO模型做了优化改进
在我的设计的项目里,一般结构如下:
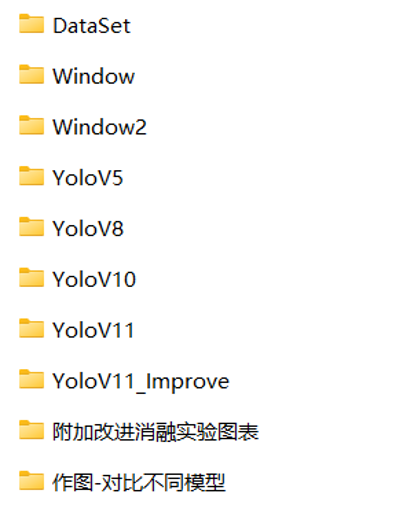
DateSet: 数据集相关的内容
Window:GUI演示系统
Window2:GUI演示系统
(提供了2种风格的演示系统,选择其中一种使用就行)
YOLOV5:YOLOV5模型代码
YOLOV8:YOLOV8模型代码
YOLOV10:YOLOV10模型代码
YOLOV11:YOLOV11模型代码
YOLOV11_Improve:YOLOV11模型和改进优化的内容
改进说明如下:
改进点1:使用深度学习可分离(DWConV)卷积代替主干网络中的传统卷积,减小参数量和计算量,使得模型轻量化。
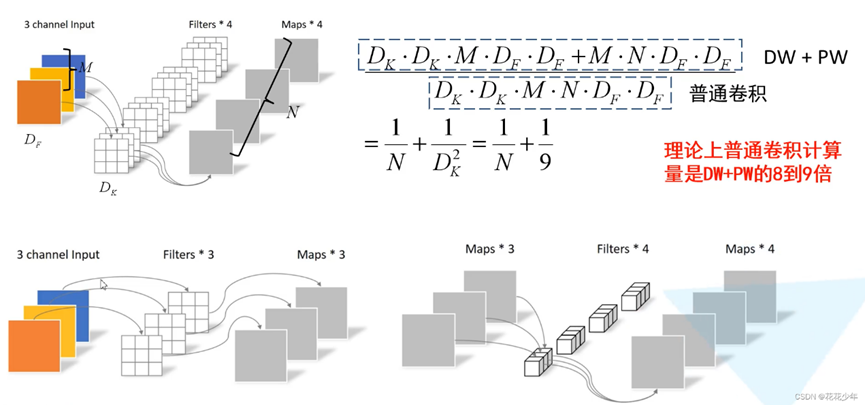
常用的轻量化模型: MobileNet 核心就是这个
论文题目:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
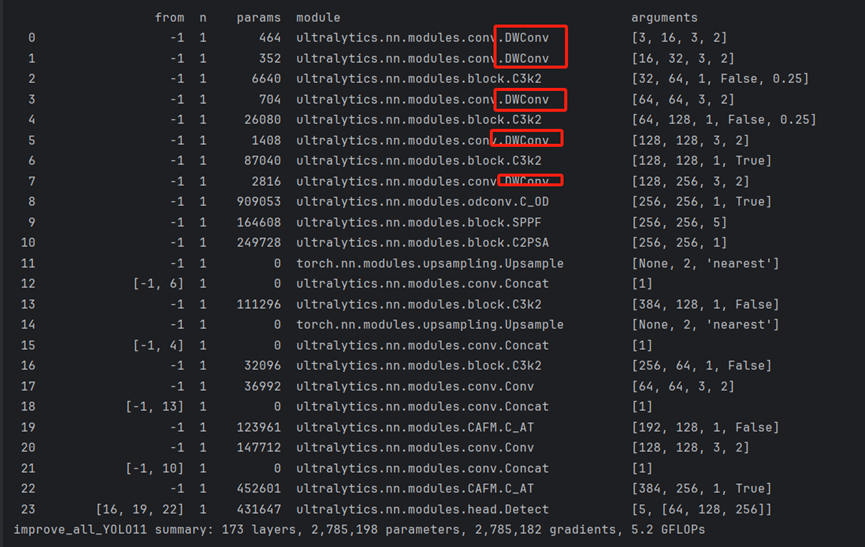
改进点2:添加全维度动态卷积模块(Omni-dimensional Dynamic Convolution,ODConv):
class ODConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=1, dilation=1, groups=1,
reduction=0.0625, kernel_num=4):
super(ODConv2d, self).__init__()
in_planes = in_planes
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.kernel_num = kernel_num
self.attention = Attention(in_planes, out_planes, kernel_size, groups=groups,
reduction=reduction, kernel_num=kernel_num)
self.weight = nn.Parameter(torch.randn(kernel_num, out_planes, in_planes // groups, kernel_size, kernel_size),
requires_grad=True)
self._initialize_weights()
if self.kernel_size == 1 and self.kernel_num == 1:
self._forward_impl = self._forward_impl_pw1x
else:
self._forward_impl = self._forward_impl_common
def _initialize_weights(self):
for i in range(self.kernel_num):
nn.init.kaiming_normal_(self.weight[i], mode='fan_out', nonlinearity='relu')
def update_temperature(self, temperature):
self.attention.update_temperature(temperature)
def _forward_impl_common(self, x):
# Multiplying channel attention (or filter attention) to weights and feature maps are equivalent,
# while we observe that when using the latter method the models will run faster with less gpu memory cost.
channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x * channel_attention
x = x.reshape(1, -1, height, width)
aggregate_weight = spatial_attention * kernel_attention * self.weight.unsqueeze(dim=0)
aggregate_weight = torch.sum(aggregate_weight, dim=1).view(
[-1, self.in_planes // self.groups, self.kernel_size, self.kernel_size])
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
output = output * filter_attention
return output
def _forward_impl_pw1x(self, x):
channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)
x = x * channel_attention
output = F.conv2d(x, weight=self.weight.squeeze(dim=0), bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups)
output = output * filter_attention
return output
def forward(self, x):
return self._forward_impl(x)全维度动态卷积(Omni-dimensional Dynamic Convolution,ODConv)算法是一种新型的卷积神经网络(CNN)架构。它通过动态调整卷积核的形状和大小,以适应不同的输入数据维度,从而提高模型的灵活性和性能。
灵活性:ODConv能够根据输入数据的维度动态调整卷积核,使得模型能够处理不同形状和大小的输入数据。
性能提升:通过动态调整卷积核,ODConv能够更好地捕捉输入数据的特征,从而提高模型的性能。
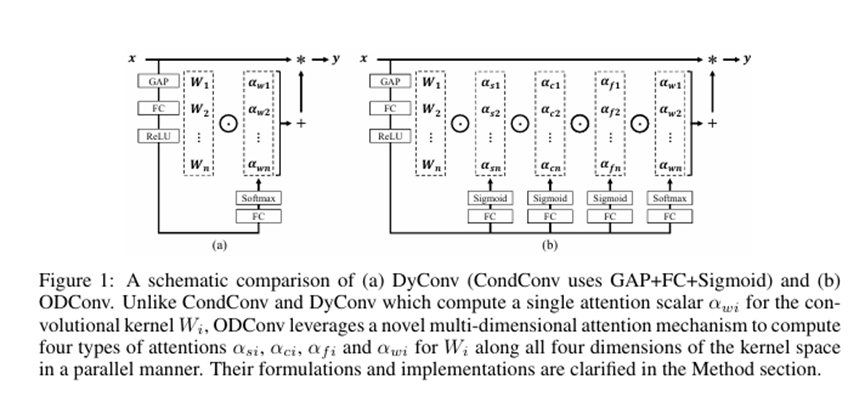
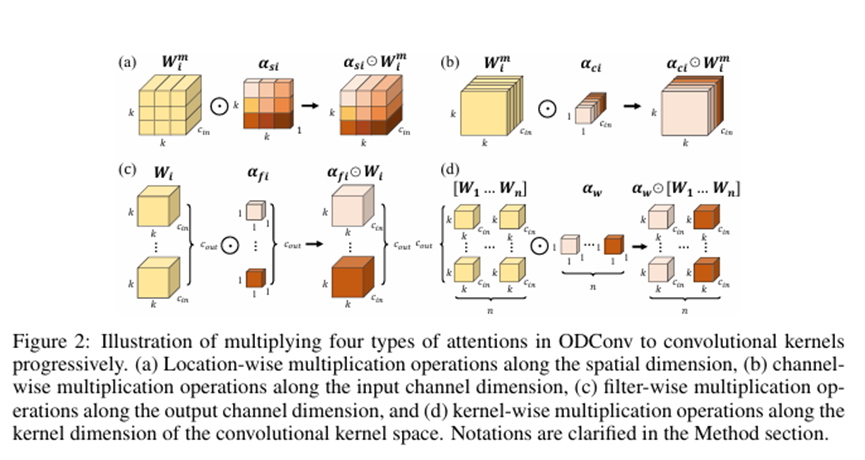
在配置文件中,用C_OD代替原来的C3k2,实现全维度动态卷积(Omni-dimensional Dynamic Convolution,ODConv)代替原来的传统卷积模块
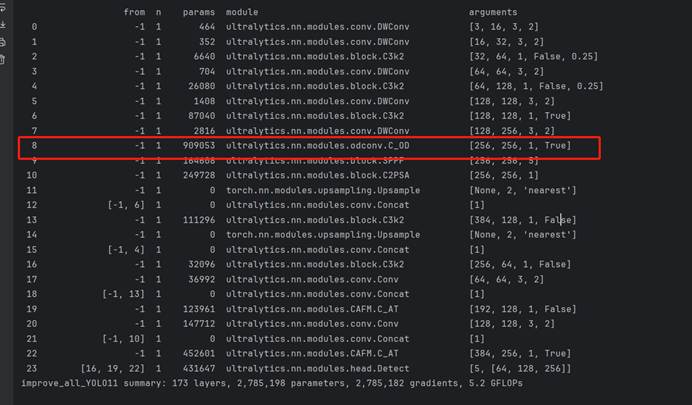
总结:结合具体的检测场景去写,如果说场景里面有明显小目标的,可以倾向于写提升小目标特征提取能力,如果没有明显的小目标的,可以说提升模型的多尺度特征提取能力。
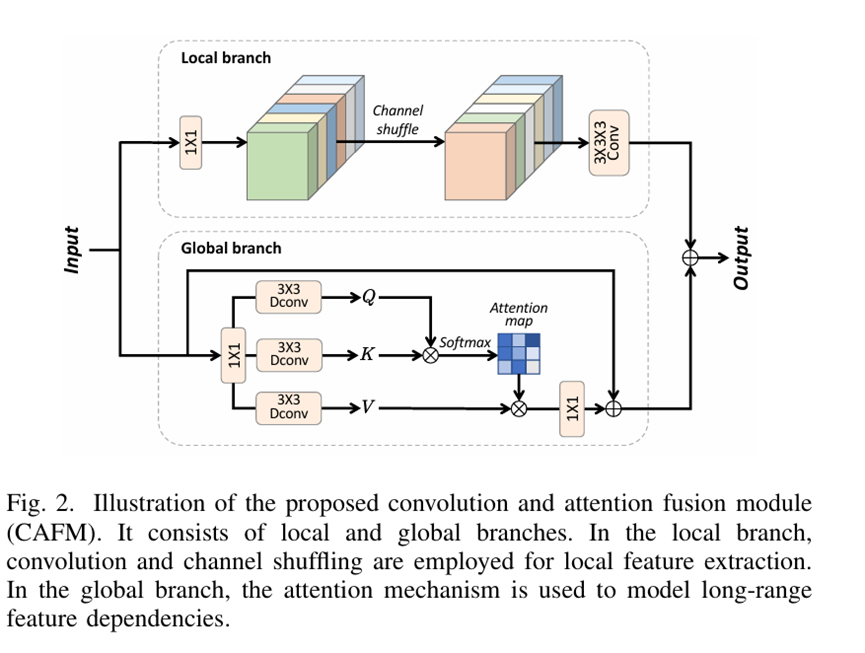
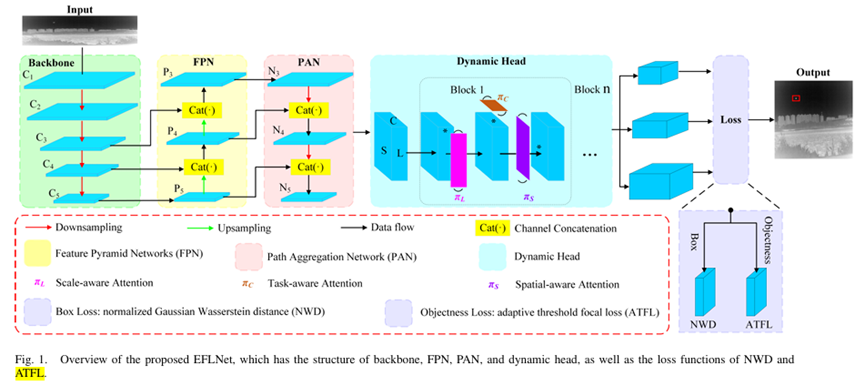
改进点3:添加卷积和注意力融合模块(CAFM)提升小目标和遮挡检测能力
CAFM 旨在融合卷积神经网络(CNNs)和 Transformer 的优势,通过结合局部特征捕捉能力(卷积操作)和全局特征提取能力(注意力机制),对图像的全局和局部特征进行有效建模,以提升检测效果。
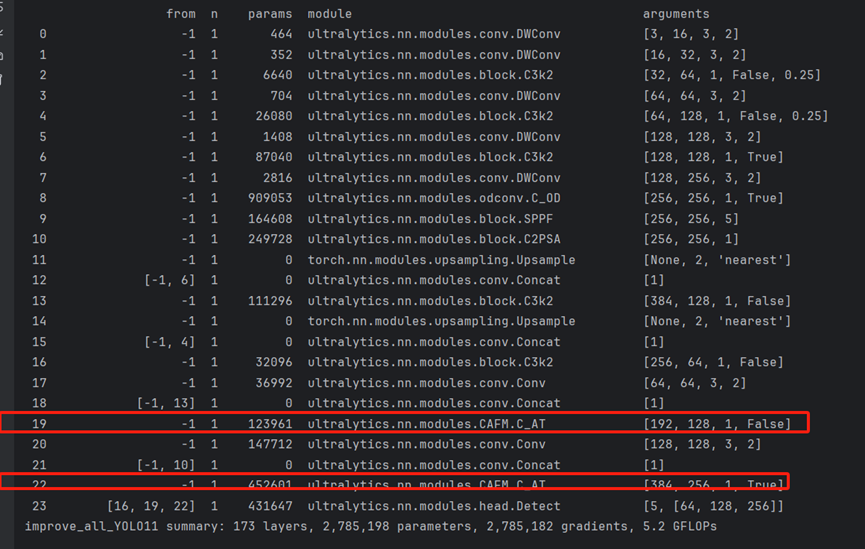
在配置文件中,主干网络部分:用C_AT 代替原来的C3k2:
总结:
增强特征提取:通过结合卷积操作和注意力机制,CAFM能够有效捕捉局部和全局信息。卷积操作擅长处理局部特征,而注意力机制则善于建模全局信息。
改进信息嵌入:CAFM可以高效地在输入数据的不同部分之间进行信息嵌入和特征融合,从而对输入特征有更全面的理解。(提升遮挡检测的能力)
双向信息流:CAFM构建了双向信息流桥梁,允许输入数据的不同部分之间进行信息嵌入和特征融合,增强了模型的整体性能。
可以往,场景中目标存在一些遮挡的情况,往提升遮挡情况下的性能,这方面编。(如果没有遮挡,就直接说它提升模型的特征融合能力,增强性能)
class Bottleneck_AT(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Attention(c1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C_AT(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_AT(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))改进点4:使用自适应阈值焦点损失(ATFL)函数
自适应阈值焦点损失(ATFL)是一种动态调整损失权重的损失函数,旨在通过降低易分类样本的影响,增强对难分类样本的关注,从而提升目标检测和分割任务中的模型性能。
在类别不平衡的情况下,比较有效。
ATFL 主要有以下几个特点:
自适应性:ATFL 根据每个样本的特征和模型的输出自适应地调整损失权重。它能够动态地根据预测结果和真实标签之间的差异,调整阈值,使得模型在训练时更加关注难以分类的样本。
焦点机制:通过引入焦点机制,ATFL 在处理易分类和难分类样本时,降低了易分类样本的影响力,同时增强了对难分类样本的关注。这种机制有助于提升模型的整体性能,尤其是在类别不平衡的情况下。
阈值调整:ATFL 引入了自适应阈值,能够针对每个样本计算一个合适的阈值,以决定如何加权损失。这种方式使得损失函数能够更好地反映出样本的重要性。
增强学习能力:ATFL 通过优化的损失计算方式,使得模型能够更快地学习到有价值的特征,从而提升了训练的效率和效果。
这里是对损失函数的改进,所以在代码里不用修改配置文件(yaml文件)
总结:如果你的样本量分布不平衡,就说这个ATFL针对这个,围绕这个编加了以后的优点。
如果样本比较平衡,就不提分布问题,直接说,ATFL通过降低易分类样本的影响,增强对难分类样本的关注,从而提升目标检测和分割任务中的模型性能。
训练完模型会得到训练日志。
里面有结果图片,部分展示如下:
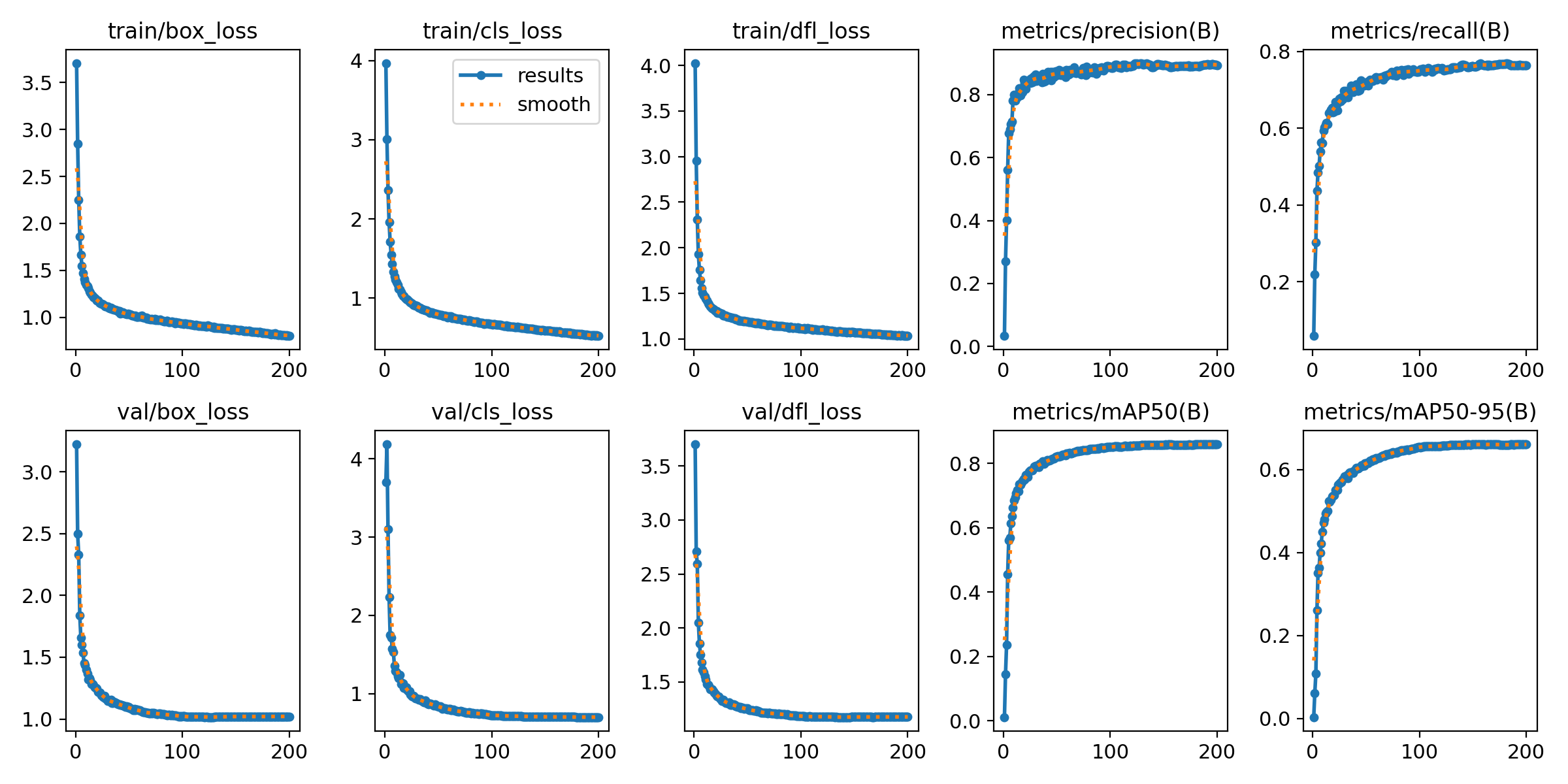
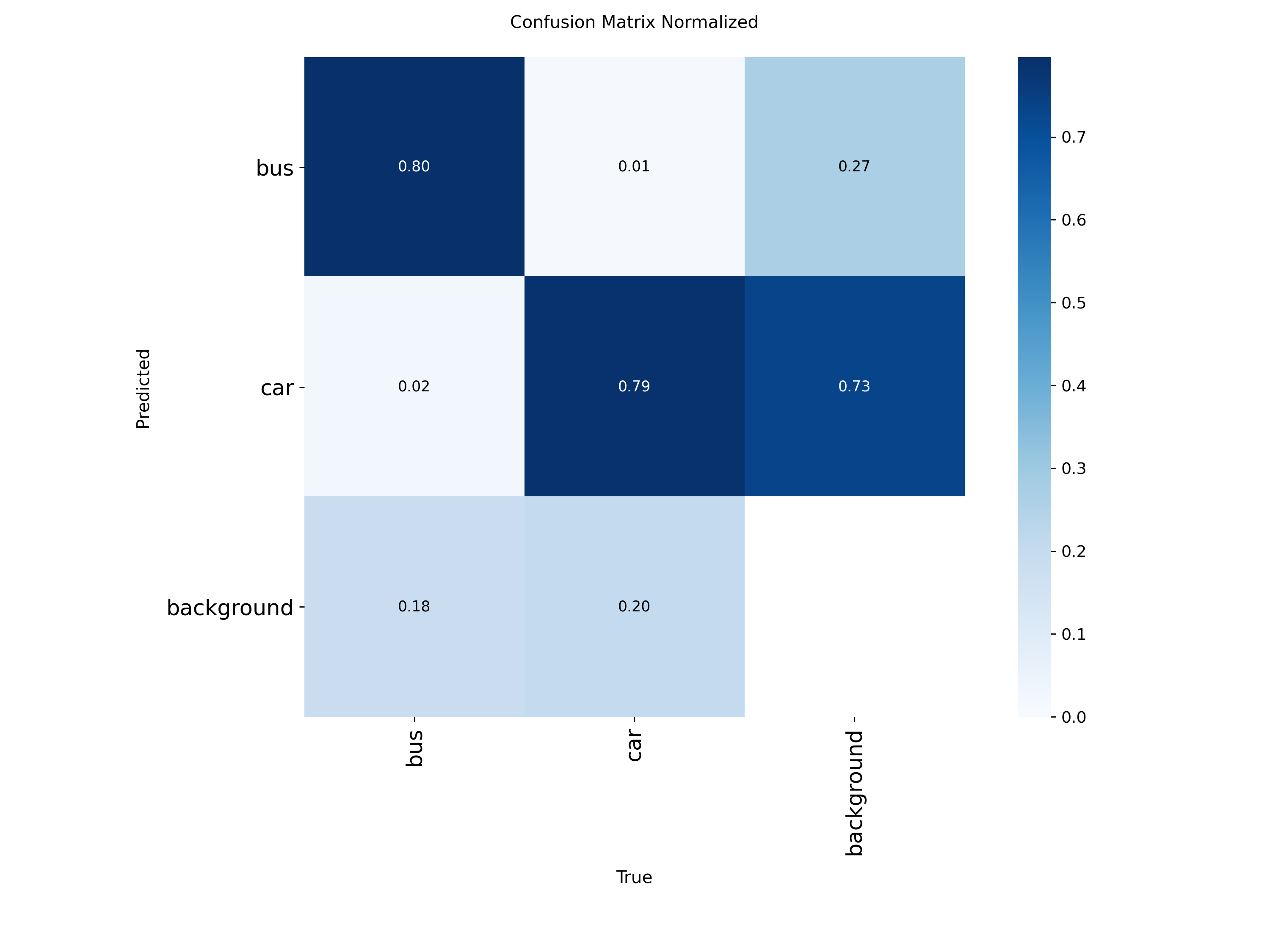
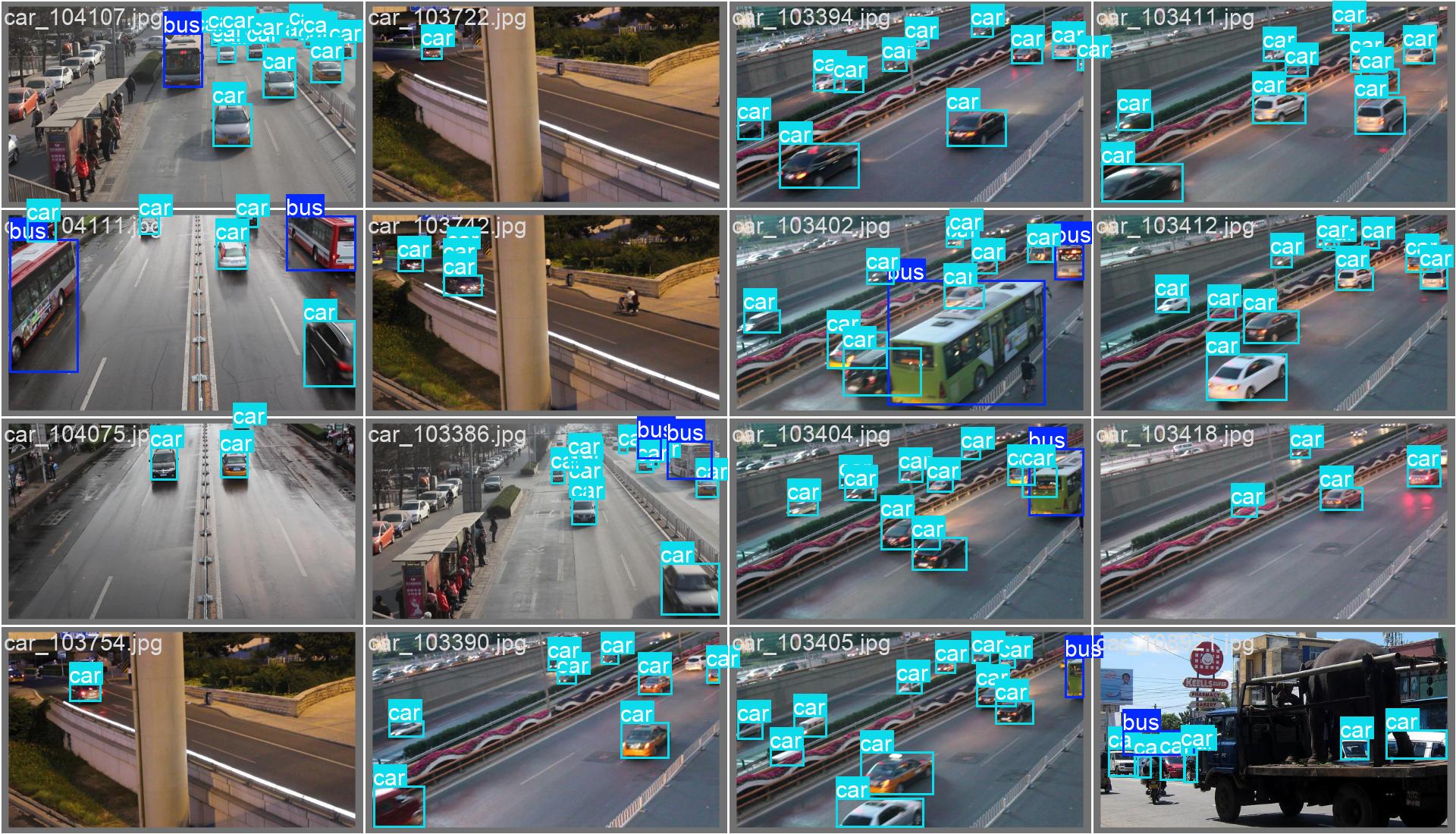
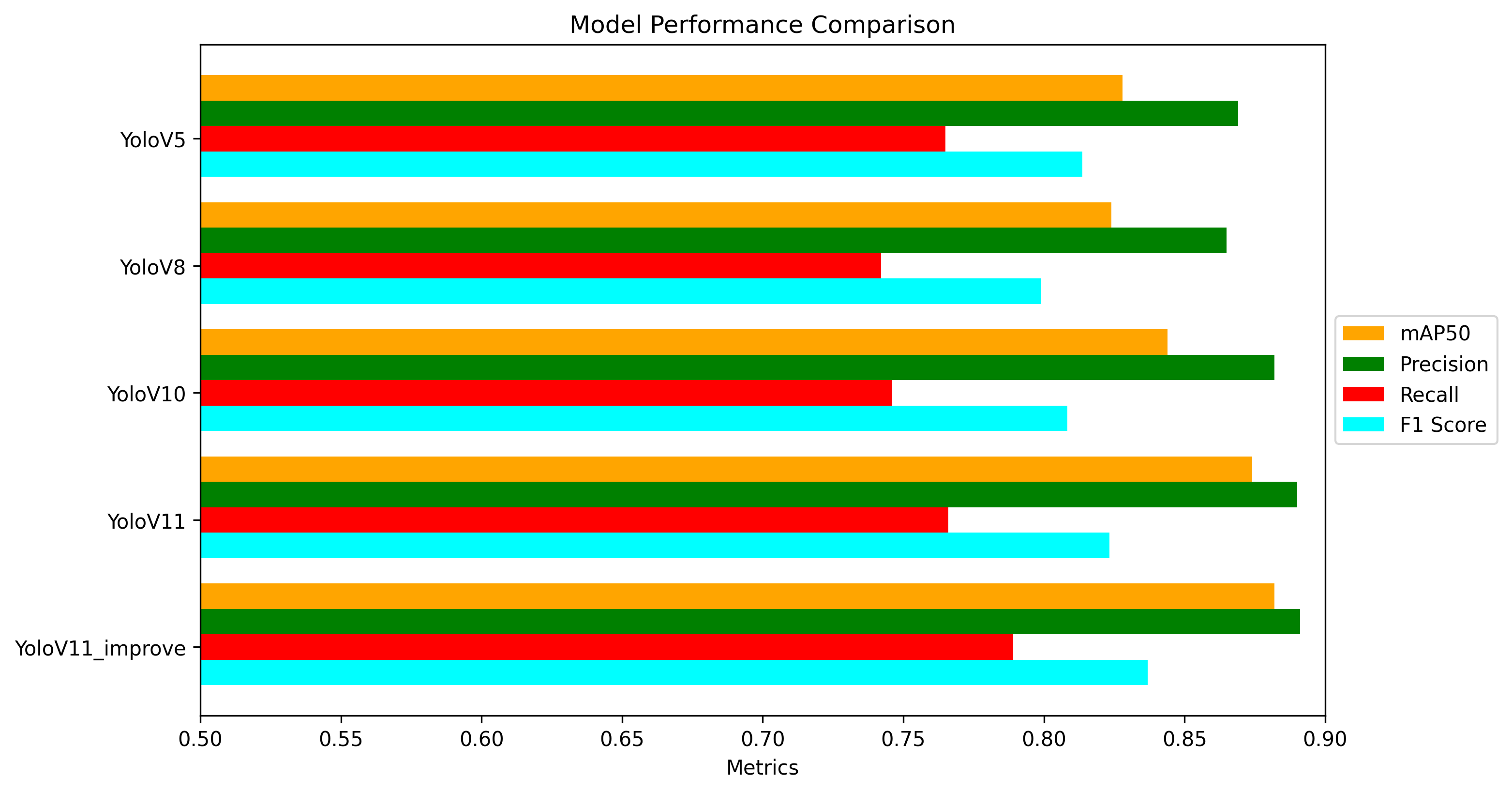
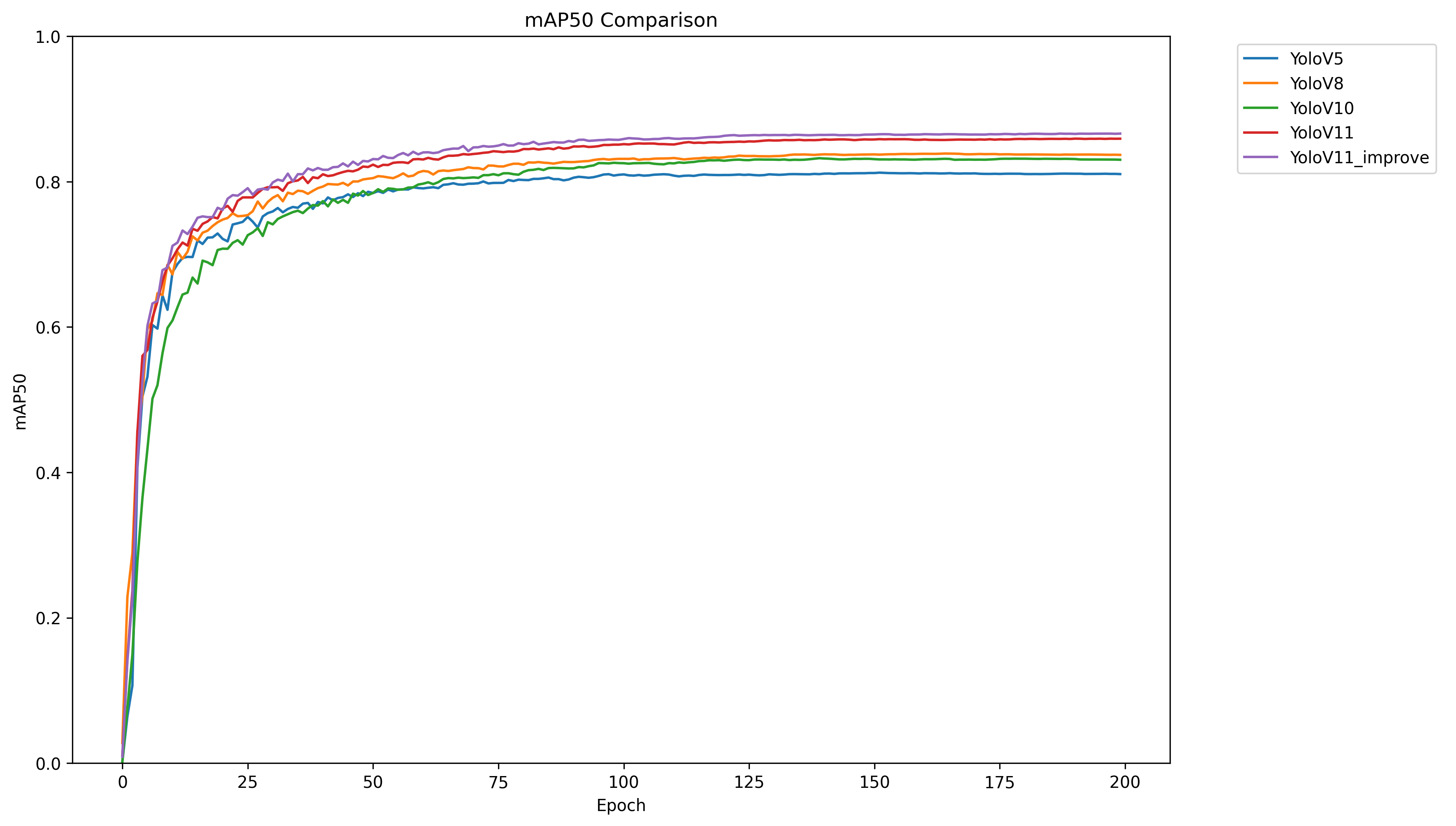
训练完多个模型后,可以做对比实验,通过写代码可以制作对比曲线图和柱状图,项目的最终实验效果如下:
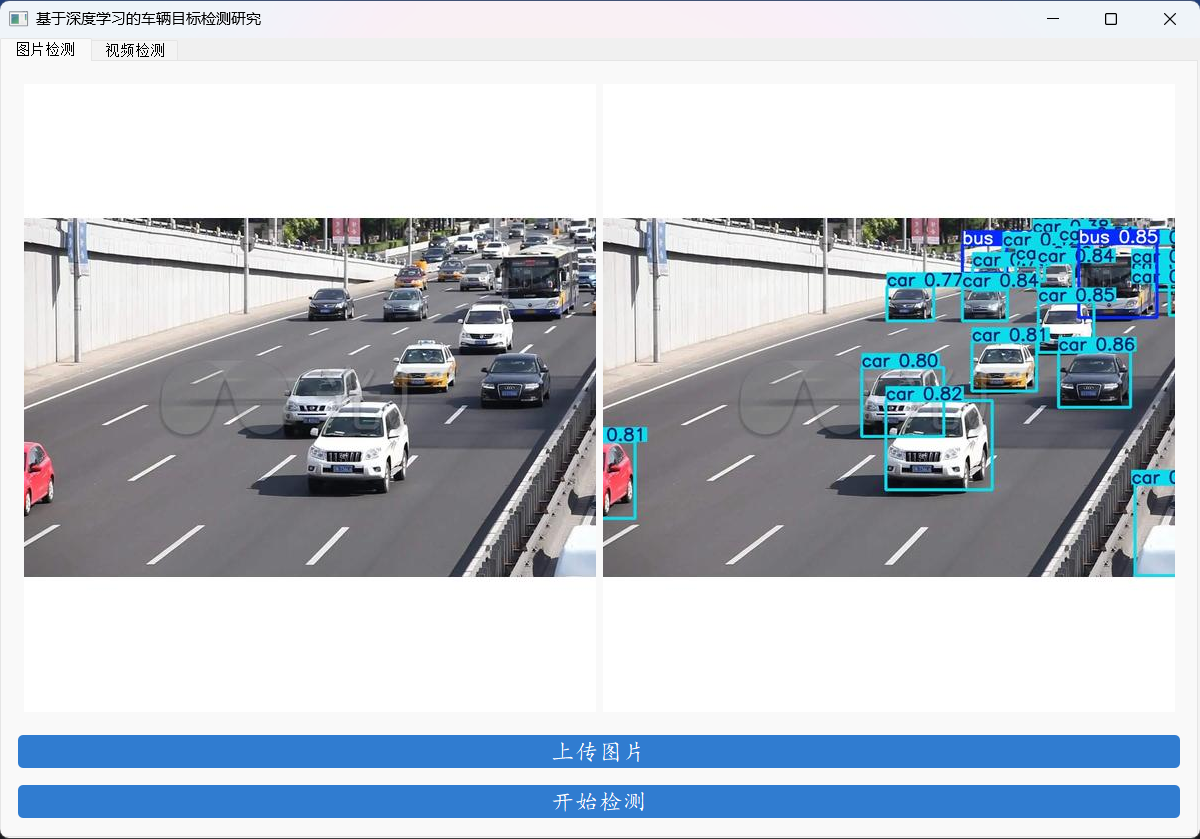
最后基于Python的PYQT5框架,制作最终的GUI演示系统。
实现对图片,视频,摄像头等多种输入的检测。
提供两种不同的风格供选择,另外一个不用的话,直接删除就行。
第一种:
 第二种:
第二种:
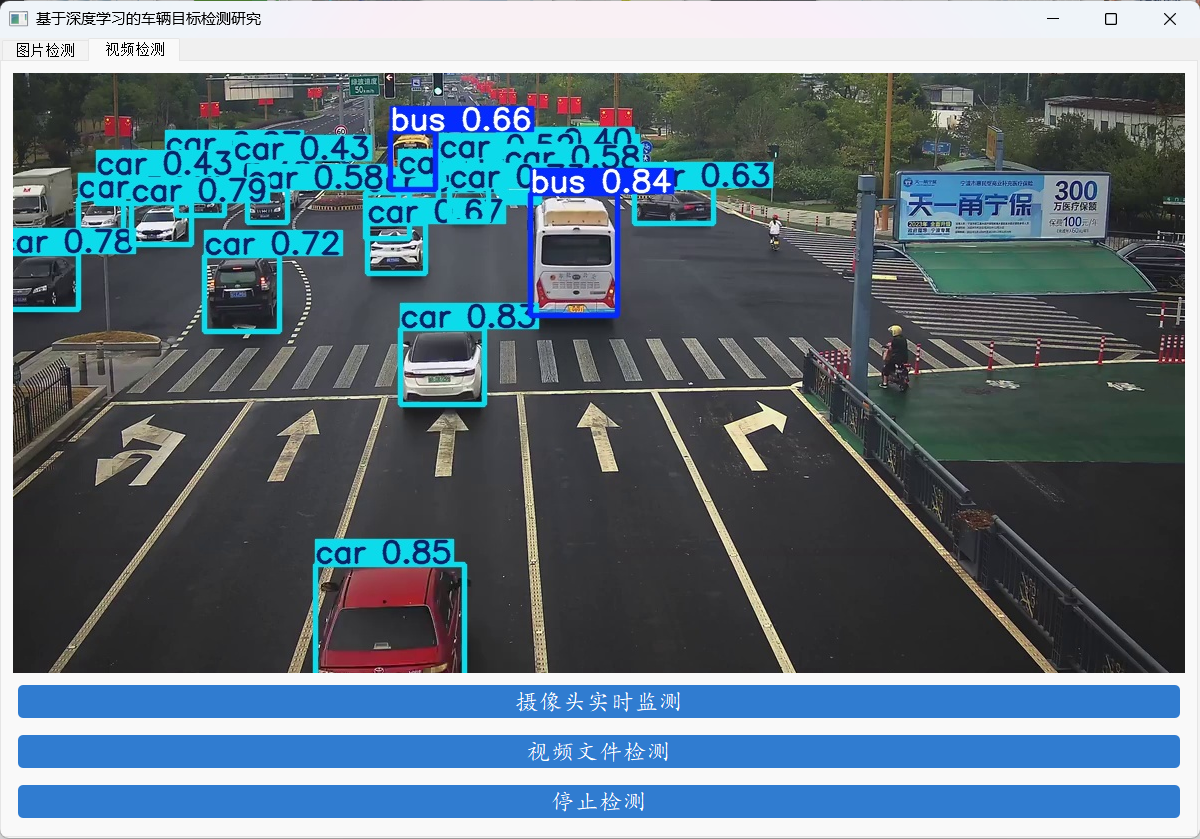 本项目包含:
本项目包含:
1.多模型的对比实验和图表,丰富了项目的内容。
2. 模型的优化改进,实现项目的创新。
3. 多种实验分析,拓展的项目的深度和内容量
4.实现了最终的演示系统,实现了项目的落地和应用。

更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)