
YOLOv5深度学习目标检测模型实战指南
YOLOv5是目标检测领域中的一个先进模型,它延续了YOLO系列的快速与准确的特性,并通过多项改进,提升了模型的性能与易用性。YOLOv5不仅仅是一个单一度量值的检测器,它能够实时地在各种硬件平台上进行部署,并保持高效与精确。在本章中,我们将简要介绍YOLOv5的发展背景,它的特点,以及它在不同应用场景中的潜力。通过对该模型的初步了解,我们将为读者提供一个扎实的基础,以便深入探讨YOLOv5的技术

简介:YOLOv5是一个先进的目标检测模型,由Ultralytics开发,以高效率、准确性和易训练性著称。包含源代码,适配PyTorch 1.6.0。YOLOv5结合了改进的网络架构、损失函数和数据增强策略,相较于之前的版本在速度和精度上有所提升。提供了详细的代码结构和训练指南,适合有深度学习和PyTorch背景的开发者。 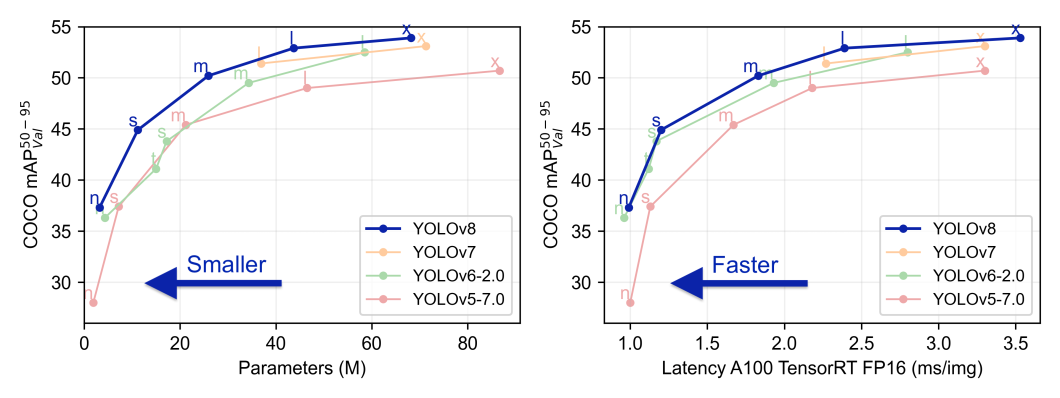
1. YOLOv5目标检测模型简介
YOLOv5是目标检测领域中的一个先进模型,它延续了YOLO系列的快速与准确的特性,并通过多项改进,提升了模型的性能与易用性。YOLOv5不仅仅是一个单一度量值的检测器,它能够实时地在各种硬件平台上进行部署,并保持高效与精确。在本章中,我们将简要介绍YOLOv5的发展背景,它的特点,以及它在不同应用场景中的潜力。通过对该模型的初步了解,我们将为读者提供一个扎实的基础,以便深入探讨YOLOv5的技术细节和实际应用。
1.1 发展背景与技术特点
YOLOv5的发展背景是基于前代YOLO模型的成功,特别是在处理速度与准确率上进行了大幅的提升。YOLOv5通过引入更深和更宽的网络结构、改进的损失函数设计以及更有效的数据增强方法,成功地平衡了速度和精度。它特别适合边缘设备,如手机和嵌入式系统,这使得它在工业界特别受欢迎。
1.2 应用潜力与行业影响力
由于YOLOv5的灵活性和扩展性,它被广泛应用于各个行业,从自动驾驶汽车的环境感知,到智能视频监控的异常行为检测,再到工业视觉检测等领域。随着深度学习技术的不断进步和硬件性能的提高,YOLOv5等先进模型正在成为解决各种现实世界问题的关键技术之一。
以上就是YOLOv5目标检测模型的简单介绍。接下来,我们将深入探讨源代码包的结构,以及如何通过这些工具和库来充分利用YOLOv5模型的潜力。
2. 源代码包”yolov5-master.zip”特性
2.1 源代码包结构概览
2.1.1 文件组织结构
YOLOv5的源代码包具有清晰的文件组织结构,便于开发者理解和使用。源代码包的根目录通常包含以下几个子目录:
- data/ :包含数据集、类别名称、训练和测试数据的标注文件。
- models/ :存储不同版本的预训练模型权重文件以及模型架构定义。
- utils/ :包含各种实用工具脚本,例如用于数据增强的脚本和训练过程的辅助工具。
- train.py :主训练脚本,用于启动训练过程。
- val.py :主验证脚本,用于评估模型性能。
- detect.py :主推理解析脚本,用于运行模型进行目标检测。
- requirements.txt :列出所有依赖的Python包及其版本。
2.1.2 关键文件功能解析
关键文件主要负责整个YOLOv5训练流程的各个阶段。这里对几个核心文件进行详细解析:
- train.py :设置训练参数,如学习率、批量大小等,启动训练过程,并提供保存模型和日志的功能。
- val.py :执行模型验证,加载训练好的模型权重,并在验证集上计算各项指标。
- detect.py :允许用户将训练好的模型用于实际的图像或视频进行目标检测任务,并展示结果。
2.2 YOLOv5版本迭代与改进
2.2.1 更新日志解析
每个新的YOLOv5版本通常会包含性能改进、错误修复和新功能。在 CHANGELOG.md 文件中,开发者会列出每一个版本的更新内容。例如:
- v5.0:添加了SPP模块,提高了小目标检测的准确率。
- v5.1:优化了训练速度和收敛稳定性。
- v5.2:引入了新的数据增强技术,进一步提升模型泛化能力。
2.2.2 不同版本性能对比
为了评估不同版本之间的性能差异,可以通过运行基准测试,对比不同版本在相同的硬件配置和数据集上的结果。以下是性能对比的示例表格:
| Version | mAP (val) | FPS (GPU) | 更新时间 |
|---|---|---|---|
| v5.0 | 35.8% | 120 | 2021-01 |
| v5.1 | 38.0% | 115 | 2021-03 |
| v5.2 | 40.2% | 110 | 2021-06 |
2.3 源代码包中的辅助工具与库
2.3.1 数据增强工具
YOLOv5提供了一系列数据增强工具,用于在训练过程中增加数据多样性,提高模型的泛化能力。工具包括但不限于:
- 随机裁剪 (Random Cropping)
- 颜色抖动 (Color Jittering)
- 平移 (Translation)
- 缩放 (Scaling)
- 翻转 (Flipping)
2.3.2 评估与可视化脚本
YOLOv5提供了一系列评估和可视化脚本,用以在训练后分析模型性能和结果。这些脚本包括:
- eval.py :计算模型在验证集上的各项指标,如mAP。
- plot-loss.py :绘制训练过程中损失值的变化曲线。
- plot-mAP.py :绘制模型在验证集上的mAP曲线图。
以下是一个简单的代码块展示如何使用评估脚本:
# plot-loss.py
import matplotlib.pyplot as plt
import json
# 加载训练损失数据
with open('path/to/log.txt', 'r') as f:
logs = f.readlines()
losses = []
for line in logs:
loss = json.loads(line)['train/loss']
losses.append(loss)
# 绘制损失曲线图
plt.plot(losses)
plt.title("Training Loss")
plt.xlabel("Steps")
plt.ylabel("Loss")
plt.show()
该脚本首先从日志文件中读取损失数据,然后绘制出训练损失随步骤变化的曲线图。通过该脚本,开发者可以直观地观察到模型在训练过程中的表现。
3. 模型定义文件和训练、推理脚本
3.1 模型定义文件详解
3.1.1 网络架构的描述
YOLOv5模型定义文件是其架构的核心,描述了模型的网络结构以及前向传播的方式。YOLOv5采用了Backbone、Neck和Head的模块化设计思想,使得模型具有更好的灵活性和可扩展性。
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None):
super(Model, self).__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
with open(cfg, errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
self.yaml['nc'] = nc # update yaml for new number of classes
self.model, self.save = ModelData(self.yaml, ch=ch)
# Freeze backbone layers
for layer in self.model.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.requires_grad = False
# Register actions for saving, loading and tracing
if self.save:
model_path = get_model_path()
register_save(self, model_path)
register_load(self, model_path)
register_trace(self, self.save)
def forward(self, x, profile=False, visualize=False):
return self.model.forward(x, profile, visualize)
上述代码定义了YOLOv5的网络架构,该模型使用了 yaml 配置文件来定义不同的网络参数。代码中的 Model 类继承自 nn.Module ,并重写了 forward 方法来处理输入数据。在初始化时,会读取 yaml 文件中定义的网络配置,并根据该配置初始化模型。此外,模型的某些层,如 BatchNorm2d ,在训练时是冻结的,这有助于提升训练效率。
3.1.2 参数配置与修改方法
YOLOv5模型的参数配置主要通过YAML文件进行,该文件定义了模型的结构和参数。参数的修改通常涉及网络深度、宽度、锚点大小等,这些可以按需调整来改善模型性能。
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
在上述YAML配置中, nc 表示类别数, depth_multiple 和 width_multiple 分别用于调整模型深度和宽度的比例,而 anchors 定义了不同层级的锚点尺寸。通过修改这些参数,开发者可以定制模型的大小和性能,以适应不同的应用场景。
参数修改的方法可以归纳为以下步骤:
- 确定需要修改的参数,如模型深度或类别数。
- 在YAML配置文件中找到对应参数并进行修改。
- 在初始化
Model类时指定更新后的配置文件。 - 重新训练模型以验证修改效果。
通过这种方式,开发者可以灵活地调整YOLOv5模型以更好地适应特定的使用案例。
3.2 训练脚本使用与技巧
3.2.1 训练参数设置
YOLOv5训练脚本负责初始化模型、加载数据集、设置训练参数,并执行训练过程。有效的训练参数设置对于模型性能的提升至关重要。
python train.py --img 640 --batch 16 --epochs 300 --data coco128.yaml --weights yolov5s.pt
上述训练命令行中, --img 指定了输入图像的大小, --batch 指定了批量大小, --epochs 指定了训练周期数, --data 指向了数据集配置文件,而 --weights 则用于指定预训练模型的权重。
训练参数的设置应当基于可用的计算资源进行。较小的图像尺寸和批量大小可以减少内存使用,但可能会降低训练速度和模型的最终性能。较大的批量大小有助于模型收敛,但也可能导致内存不足。此外,训练周期数也应根据模型收敛情况和验证集上的性能进行调整。
3.2.2 训练过程监控与日志分析
在训练过程中,监控训练的进度和性能至关重要。YOLOv5提供了一种简洁的方式通过命令行输出和TensorBoard来监控训练状态。
class TrainEpoch(Epoch):
def __init__(self, model, loss, metrics, stage_name, device, data_loader, valid_data_loader, phase='train', epoch=None):
super(TrainEpoch, self).__init__(model, loss, metrics, phase, epoch, data_loader)
self.valid_data_loader = valid_data_loader
def on_epoch_start(self):
self.model.train()
self.metrics.reset()
def on_epoch_end(self):
log = self.get_logs()
print("Epoch: {}, Train: {}".format(self.epoch, log))
def run(self):
self.on_epoch_start()
with tqdm(self.data_loader, desc=self.stage_name, disable=not self.verbose) as iterator:
for batch in iterator:
self.run_batch(batch)
iterator.set_postfix(self.get_logs())
self.on_epoch_end()
TrainEpoch 类定义了训练周期的开始和结束动作,并在每个epoch结束时记录并输出日志。此外,还可以使用TensorBoard工具来可视化训练过程中的损失和指标变化。
tensorboard --logdir=runs/
通过TensorBoard,可以直观地看到训练损失和验证损失的变化趋势,以及各项性能指标。异常的波动可能是过拟合或数据集问题的标志,而稳定的性能提升则表明模型正在有效学习。
3.3 推理脚本的编写与优化
3.3.1 推理代码结构
推理脚本负责加载训练好的模型并执行目标检测任务。YOLOv5的推理代码结构清晰,支持多种输入格式,并且易于理解和使用。
def detect_image(img, model):
img = img.convert('RGB')
img = img.resize((640, 640))
img = np.array(img)
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img)
img = img.float()
img /= 255
img = img.unsqueeze(0)
with torch.no_grad():
pred = model(img)[0]
return pred
def run_inference(image_path, model):
img = Image.open(image_path)
prediction = detect_image(img, model)
return prediction
上述代码展示了YOLOv5推理的主要流程。首先对输入图像进行预处理,包括转换颜色空间、缩放和归一化,然后通过模型进行预测,并返回结果。推理过程中的数据预处理步骤是保证模型正常工作的关键。
3.3.2 推理性能优化策略
在实际应用中,YOLOv5模型的推理速度对于用户体验至关重要。优化策略包括但不限于模型简化、推理加速库的使用和量化。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
model.to('cpu') # 移到CPU上推理
模型简化可以通过加载预训练的小模型来实现,如 yolov5s 。使用GPU进行推理可以获得更快的速度,而将模型移至CPU则适用于没有GPU环境的场景。此外,推理加速库如TensorRT、OpenVINO和ONNX Runtime提供了针对不同硬件平台的优化方案,可以进一步提高推理速度。
python -m torch.utils.bundled_inputs # 将模型转换为 TorchScript 或 ONNX 格式
将模型转换为TorchScript或ONNX格式可以进一步优化推理性能。这些格式可以被优化推理引擎如TensorRT或ONNX Runtime所利用,从而进一步提升速度。
性能优化不仅仅是提升速度,还包括保持或提高检测的准确性。使用如知识蒸馏等方法可以在保持性能的同时简化模型。根据实际应用场景和需求,可以灵活地选择和组合各种优化策略。
4. 数据预处理和配置文件说明
4.1 数据集的整理与格式化
4.1.1 数据集的下载与解压
为了使用YOLOv5进行目标检测任务,首先需要准备一个合适的训练数据集。数据集通常包含了大量的图片文件和相应的标注信息。这些信息用来告诉模型,哪些地方有目标以及目标的具体位置和类别。在开始使用数据集之前,我们首先要确保数据集的来源是可靠的,并且格式符合YOLOv5的要求。
下载数据集通常可以通过公开的数据集库,如ImageNet、COCO、OpenImage等,或者利用自建数据集。在本章节中,我们假设您已经从相应的数据集资源获取了数据集文件。
下载完成后,需要将数据集文件解压。使用以下命令:
# 假设数据集压缩包为 'dataset.zip'
unzip dataset.zip
这将会在当前目录下解压出文件夹,通常包含图片文件和标注文件。确保解压后的目录结构清晰,方便后续的数据处理和模型训练。
4.1.2 标注文件的创建与校验
标注文件提供了图片中目标的详细信息。每个目标在标注文件中以一系列的数值形式表示,通常包括目标的类别、位置坐标等信息。YOLOv5采用的标注格式是 .txt 文件,每张图片对应一个 .txt 文件,文件名与图片文件名相同,但扩展名不同。
假设我们有如下的图片文件 dog.jpg ,其对应的标注文件 dog.txt 内容可能是这样的:
1 0.586 0.624 0.114 0.294
其中:
- 1 表示类别ID;
- 0.586 是目标中心点的x坐标(相对于图片宽度的比例);
- 0.624 是目标中心点的y坐标(相对于图片高度的比例);
- 0.114 是目标宽度(相对于图片宽度的比例);
- 0.294 是目标高度(相对于图片高度的比例)。
在创建标注文件时,您需要使用专门的标注工具,如LabelImg,来为您的图片生成这些信息。标注完成后,使用脚本进行校验,确保格式无误,例如:
import os
def validate_annotations(directory):
for filename in os.listdir(directory):
if filename.endswith('.txt'):
with open(os.path.join(directory, filename), 'r') as file:
for line in file:
parts = line.split()
# 确保每行都有5个部分(包括类别ID)
if len(parts) != 5:
print(f'警告: 文件 {filename} 格式错误')
# 调用校验函数,传入标注文件所在的目录
validate_annotations('path_to_annotations')
执行上述代码,如果标注文件格式正确,那么什么都不会发生;如果有错误,则会打印出错误信息。
4.2 配置文件的编写与调整
4.2.1 训练配置文件解析
YOLOv5模型训练和推理需要对应的配置文件来定义训练参数和环境设置。在配置文件中,您可以指定诸如训练设备(CPU或GPU)、类别数、批量大小、学习率等参数。
配置文件通常是 .yaml 格式的文件,里面包含三个主要部分:数据、模型和训练。下面是一个例子:
# 模型结构配置
nc: 80
depth_multiple: 0.33
width_multiple: 0.50
# 训练集与验证集路径
train: /path/to/train/images/
val: /path/to/valid/images/
# 类别名称列表
names: ['person', 'bicycle', 'car', ...]
# 训练策略
epochs: 100
batch_size: 16
img_size: 640
data: custom_dataset.yaml
# 优化器设置
optimizer: Adam
# 超参数
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
您需要根据自己的数据集和模型需求来调整这些参数。例如, nc 字段表示类别的总数,需要根据您的数据集中的类别数来设置。
4.2.2 推理配置文件的自定义
推理配置文件用于在模型训练完成后,进行模型评估或实际目标检测任务时定义推理参数。与训练配置类似,推理配置也需要指定数据集路径、类别信息,同时也需要指定训练完成的权重文件。
推理配置文件一般会有如下内容:
# 数据集路径
path: /path/to/images/ # 推理图片的路径或包含图片的文件夹
# 模型路径和参数
model: /path/to/yolov5s.pt # 加载训练好的权重文件
# 推理参数
img_size: 640 # 推理时图片的大小
# 其他参数
conf_thres: 0.25 # 置信度阈值
iou_thres: 0.45 # NMS iou阈值
device: # 使用的设备,如 'cpu' 或 'cuda'
# 输出格式
save_dir: /path/to/save/results/ # 结果保存路径
save_conf: True # 是否保存置信度分数
save_txt: True # 是否保存标注信息为.txt文件
# 是否进行多尺度测试
single_cls: False # 是否单类别检测
agnostic_nms: False # 是否忽略类别进行NMS
augment: False # 是否使用数据增强进行测试
修改推理配置文件以适应您的特定需求,特别是设置好正确的权重文件路径和数据集路径,可以帮助您高效地进行目标检测任务。
通过上述配置文件的设置,可以轻松地对YOLOv5模型进行调优,满足不同的训练和推理需求。在实际操作中,应根据数据集的特性和具体任务的要求,进行细致的调整和优化。
5. 模型训练与评估指南
5.1 训练环境的搭建
5.1.1 硬件需求与软件环境配置
在开始模型训练之前,构建一个合适的训练环境至关重要。YOLOv5模型的训练对计算资源的需求较高,尤其是在处理大规模数据集时。一般而言,建议使用具有NVIDIA GPU的系统来加速模型的训练过程。具体来说,至少需要配备NVIDIA Pascal架构的GPU,以及至少4GB的GPU显存空间。对于更大型的数据集和更复杂的网络结构,可能需要更高级的GPU,例如NVIDIA Turing或Ampere架构的GPU。
在软件方面,YOLOv5支持多种操作系统,包括Linux、Windows以及macOS。但是,为了获得最佳性能,推荐在Ubuntu Linux系统上进行训练和评估。此外,必须安装以下软件包:
- Python 3.6+
- PyTorch 1.7+
- CUDA 10.2+(如果使用NVIDIA GPU)
- cuDNN 7.6+(如果使用NVIDIA GPU)
- OpenCV
- NumPy
- Matplotlib
可以通过Python的包管理工具pip来安装这些依赖项:
pip install torch torchvision
对于使用CUDA的环境,确保安装了正确的版本,以便与PyTorch兼容:
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 -f https://download.pytorch.org/whl/torch_stable.html
5.1.2 驱动与依赖库安装指南
在安装了Python和PyTorch之后,需要确保系统驱动和依赖库正确安装。对于NVIDIA GPU的支持,需要安装CUDA和cuDNN驱动。可以访问NVIDIA官方网站下载与系统相匹配的CUDA和cuDNN版本。
接下来,安装YOLOv5模型依赖的其他库:
pip install opencv-python numpy matplotlib
如果希望使用YOLOv5提供的API进行进一步的开发和自定义,可能还需要安装一些额外的Python库:
pip install scikit-learn seaborn pandas
安装完成后,可以通过以下Python代码检查CUDA是否被正确安装以及PyTorch是否正确识别了GPU:
import torch
print("GPU available?" if torch.cuda.is_available() else "GPU not available.")
输出 “GPU available?” 则表示一切就绪,可以开始训练YOLOv5模型。
5.2 模型训练步骤与常见问题处理
5.2.1 启动训练流程
YOLOv5模型的训练过程可以通过命令行启动。首先,需要从YOLOv5的官方GitHub仓库克隆源代码包,然后下载预训练的权重和数据集。在本地环境中,进入到克隆好的项目目录,可以使用以下命令来启动训练流程:
python train.py --img 640 --batch 16 --epochs 300 --data dataset.yaml --weights yolov5s.pt
在这个例子中,参数指定了训练图像的大小 ( --img 640 ),批量大小 ( --batch 16 ),训练的轮次 ( --epochs 300 ),使用的数据集 ( --data dataset.yaml ) 以及使用预训练的权重 ( --weights yolov5s.pt )。
5.2.2 训练过程中的问题与解决方法
在训练过程中,可能会遇到一些问题,例如硬件资源不足、训练速度过慢、内存泄漏等。以下是一些常见的问题和相应的解决方法:
- 内存不足 : 如果在训练过程中遇到显存不足的问题,可以尝试减小批量大小 (
--batch参数) 或者减小输入图像的尺寸 (--img参数)。 - 训练速度慢 : 如果训练速度过慢,检查是否使用了最新的CUDA和cuDNN驱动,并确保它们与PyTorch版本兼容。此外,可以考虑使用更快的磁盘(如SSD)来存储数据集。
- 不收敛 : 如果模型不收敛,可能需要调整学习率 (
--lr参数) 或者优化器。有时候,重新初始化权重或使用不同的预训练模型可以改善训练过程。
为了避免上述问题,建议在训练之前仔细阅读YOLOv5的官方文档,并关注GitHub仓库的issue页面,了解其他用户的常见问题和解决方案。
5.3 模型评估指标与方法
5.3.1 评估指标解读
训练完成后,评估模型性能是一个重要的步骤。YOLOv5使用以下几种标准指标来评估模型的准确性和效率:
- mAP(mean Average Precision) : 衡量模型在检测任务中的平均精度,是目标检测领域的常用指标。
- F1分数 : 结合了精确度和召回率的指标,用于衡量模型的性能平衡。
- FPS(Frames Per Second) : 衡量模型在实时应用中的处理速度。
为了计算这些指标,通常会在验证集上进行测试,验证集是训练过程中未参与的数据集。YOLOv5提供的评估脚本会自动计算并输出这些指标。
5.3.2 模型效果可视化展示
模型的效果可以通过绘制检测框和标注框来进行可视化展示。这有助于直观地理解模型的检测能力。在YOLOv5中,可以通过执行以下命令来运行推理并可视化结果:
python detect.py --source test.jpg --weights runs/train/exp/weights/best.pt --conf 0.25 --img 640 --save-dir ./output
这个命令会将检测结果保存到指定的目录中,同时在屏幕上显示结果。通过这些图像,研究人员和开发者可以评估模型在实际图像中的表现,从而判断是否需要进一步的优化。
除了命令行的方式外,YOLOv5还支持通过Web界面进行模型效果的可视化展示,这使得非技术用户也能够轻松查看模型的检测结果。
以上各部分构成了模型训练与评估指南的主体内容,对于希望深入理解YOLOv5训练过程的用户来说,这些章节将提供全面的指导和帮助。
6. 数据集准备和训练参数调整
在使用YOLOv5进行目标检测任务时,数据集的准备和训练参数的调整是至关重要的两个步骤。本章节将深入探讨如何准备多样化的数据集并对其进行增强、调整训练参数以获得更好的模型性能,以及如何避免过拟合并提升模型的泛化能力。
6.1 数据集的多样化与增强
在机器学习和深度学习任务中,数据集的质量直接关系到模型的性能。为提高模型的泛化能力,数据集应当足够多样化且尽可能地覆盖实际应用场景中的各种情况。
6.1.1 数据增强技术应用
数据增强技术是扩充数据集的一种常用手段,它通过对原始数据进行一系列转换来增加数据的多样性。例如,YOLOv5项目中提供了多种数据增强策略,包括但不限于:
- 翻转(Flip)
- 缩放(Scale)
- 旋转(Rotate)
- 色调变化(Color shift)
- 噪声注入(Noise injection)
这些策略可以帮助模型在训练时接触到更多样的数据模式,降低过拟合的风险。
graph LR
A[原始图片] --> B[翻转]
A --> C[缩放]
A --> D[旋转]
A --> E[色调变化]
A --> F[噪声注入]
B --> G[增强后的图片]
C --> G
D --> G
E --> G
F --> G
G --> H[训练模型]
6.1.2 数据集质量控制与提升
数据集的质量控制同样重要,需要确保所有的训练图像都达到了一定的标准,例如:
- 图像清晰度
- 标注准确性
- 数据标注的一致性
对数据集进行清洗和质量控制的过程包括:
- 删除模糊不清或过曝的图片
- 修正标注错误或不一致的标注
- 确保图片中的目标类别的标注框位置准确
数据集质量的提升,是获得高性能模型的基础。
6.2 训练参数的调整与优化
训练参数的正确设置对于训练出高性能的YOLOv5模型至关重要。参数调整不仅包括学习率、批次大小等基础参数,还包括模型架构中的超参数。
6.2.1 参数调整的策略与实践
在开始训练前,通常需要根据任务特性和计算资源来调整以下参数:
- 学习率(lr) :学习率决定了模型权重更新的幅度,一般在训练初期使用较大的学习率,随着训练的深入逐步减小。
- 批次大小(batch_size) :批次大小影响内存的使用和模型训练的稳定性,需要根据GPU内存大小合理设置。
- 训练轮次(epochs) :训练轮次决定了模型在整个数据集上迭代的次数,需要根据数据集大小和模型性能来确定。
调整这些参数需要结合实践经验,不断试验与调优。
6.2.2 超参数调优的案例分析
超参数的调优通常会采用一些经验规则和启发式方法,例如:
- 对于学习率,可以采用”学习率预热”和”学习率衰减”策略。
- 对于批次大小,可以通过实验来确定最佳值,保证在训练时不会发生内存溢出,并且能够保持较快的训练速度。
- 对于训练轮次,可以通过验证集上的性能来决定是否继续训练。
下面是一个使用Python代码设置训练参数的示例:
# 训练参数设置
args = {
'img': 640, # 图片尺寸
'batch': 16, # 批次大小
'epochs': 50, # 训练轮次
'lr0': 0.01, # 初始学习率
'momentum': 0.937, # 动量优化参数
'weight_decay': 0.0005, # 权重衰减
}
# 代码逻辑解读:
# - img:定义输入图片的大小。
# - batch:定义每次训练所使用的样本数量。
# - epochs:定义模型将要迭代训练的总轮次。
# - lr0:定义模型训练的初始学习率。
# - momentum:控制优化器的动量,有助于加速模型的收敛。
# - weight_decay:权重衰减参数,用于控制过拟合。
6.3 避免过拟合与提升泛化能力
避免过拟合和提升模型的泛化能力是模型训练过程中的关键问题。过拟合通常发生在模型过于复杂或训练数据不足的情况下。
6.3.1 过拟合现象的识别与处理
识别过拟合通常通过比较训练集和验证集上的性能来进行。当验证集上的损失不再下降或准确率开始降低,而训练集上的性能仍在提高时,可能存在过拟合现象。
处理过拟合的方法包括:
- 数据增强 :如前文所述,增加数据多样性有助于减少过拟合。
- 正则化 :例如权重衰减,限制模型复杂度。
- 减少模型复杂度 :简化模型架构,如减少层数或神经元数量。
- 增加数据量 :如果可能的话,增加更多的训练数据。
6.3.2 提升模型泛化能力的方法
提升模型泛化能力的策略不仅限于处理过拟合,还包括:
- 交叉验证 :使用交叉验证来确保模型在不同数据子集上的性能稳定。
- 集成学习 :通过训练多个模型并结合它们的预测来改善泛化。
- 早停(Early Stopping) :在验证集性能不再提升时停止训练,防止过拟合。
- 超参数优化 :使用网格搜索、随机搜索或贝叶斯优化等方法找到最佳超参数。
# 早停策略示例
class EarlyStopping:
def __init__(self, patience=5, min_delta=0):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = None
self.early_stop = False
def __call__(self, val_loss):
if self.best_loss is None:
self.best_loss = val_loss
elif val_loss > self.best_loss - self.min_delta:
self.counter += 1
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_loss = val_loss
self.counter = 0
# 代码逻辑解读:
# - patience:连续几轮验证集性能不再提升后停止训练的轮数。
# - min_delta:性能提升的最小阈值。
# - counter:用于计数超过设定轮数的变量。
# - best_loss:记录最佳验证集损失。
# - early_stop:标志是否触发早停的布尔值。
通过以上方法,我们可以有效地避免过拟合并提升模型的泛化能力,使模型在未知数据上的表现更加稳定可靠。
7. YOLOv5在各种实际问题中的应用
7.1 YOLOv5在行业领域的应用案例
7.1.1 交通监控
YOLOv5因其出色的实时性能和准确性,在交通监控领域中得到了广泛应用。交通监控系统依赖于目标检测算法来识别和跟踪道路上的车辆和行人,为交通流量分析、事故检测和智能交通信号控制提供实时数据支持。YOLOv5的高精度和快速响应时间能够保证交通监控系统的高效运行,减少交通堵塞和事故发生的概率。
操作步骤示例:
- 将监控摄像头捕获的视频流作为输入数据源。
- 使用YOLOv5进行实时目标检测。
- 通过分析检测结果,对车辆行驶行为进行分类。
- 利用统计信息和历史数据进行交通流量分析。
7.1.2 智能零售
在智能零售领域,YOLOv5可以通过实时识别顾客行为和商品信息来优化零售体验。例如,通过分析顾客与商品的互动,零售商可以进行货架布局优化或个性化推荐。YOLOv5在零售环境中能够实现对顾客的实时跟踪,分析其在商店内的行走路径和关注焦点,帮助零售商更好地理解顾客偏好。
操作步骤示例:
- 在零售店内安装监控摄像头。
- 配置YOLOv5模型,输入实时视频流。
- 通过YOLOv5对顾客和商品进行检测和识别。
- 结合顾客行为数据,为零售商提供经营决策支持。
7.1.3 医疗影像分析
医疗影像分析是一个对准确性要求极高的领域。YOLOv5能够在诸如细胞分类、病变区域识别等任务上发挥作用。在实际应用中,医生可以利用YOLOv5快速识别出CT、MRI等医疗图像中的关键信息,从而提高诊断效率和准确性。
操作步骤示例:
- 将患者的医疗影像数据输入到YOLOv5模型中。
- 使用YOLOv5模型检测出图像中的病变区域。
- 将检测结果作为辅助信息提供给医生进行最终诊断。
7.2 YOLOv5的扩展与改进方向
7.2.1 模型压缩与加速
随着深度学习模型变得越来越复杂,模型压缩和加速变得日益重要。YOLOv5模型虽然已经非常高效,但在资源受限的环境中,进一步压缩模型大小和加快推理速度仍然是一个挑战。通过模型剪枝、量化和知识蒸馏等技术可以实现模型的优化。
优化策略示例:
- 模型剪枝(Pruning) :移除神经网络中不重要的连接,减少模型大小。
- 量化(Quantization) :将模型权重从浮点数转换为低精度整数,加速计算。
- 知识蒸馏(Knowledge Distillation) :使用一个复杂的大型模型来训练一个更小的模型,从而保留大模型的性能。
7.2.2 新兴技术的融合与创新
将YOLOv5与新兴技术融合可以进一步提升模型性能。例如,与联邦学习结合可以在保护数据隐私的同时进行跨设备或跨机构的模型训练;利用多模态学习可以结合图像以外的多种信息源,提高模型在复杂场景下的检测能力。
融合技术示例:
- 联邦学习(Federated Learning) :在客户端设备上训练模型,并仅分享模型更新而不是数据本身。
- 多模态学习(Multimodal Learning) :结合图像和文本、音频等其他类型数据,实现更丰富场景的理解。
7.3 YOLOv5未来发展趋势预测
7.3.1 行业需求驱动的技术演进
随着特定行业的深度定制化需求逐渐增多,YOLOv5的发展将越来越依赖于不同行业内的应用反馈。未来可能会看到YOLOv5在特定场景下的优化版本,比如针对无人机检测的轻量化模型,或者适用于工业检测的高精度模型。
7.3.2 竞争模型对比与YOLOv5的潜力
YOLOv5虽然在速度和准确性方面表现突出,但仍面临来自其他目标检测模型的竞争,例如EfficientDet和Faster R-CNN等。YOLOv5的潜力在于它能够快速适应新数据和新场景,同时保持高性能输出。通过不断地优化和创新,YOLOv5有望在目标检测领域继续保持领先地位。
简介:YOLOv5是一个先进的目标检测模型,由Ultralytics开发,以高效率、准确性和易训练性著称。包含源代码,适配PyTorch 1.6.0。YOLOv5结合了改进的网络架构、损失函数和数据增强策略,相较于之前的版本在速度和精度上有所提升。提供了详细的代码结构和训练指南,适合有深度学习和PyTorch背景的开发者。
更多推荐


 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)