
基于YOLOv8的鱼类目标检测系统(LW+源码+讲解+部署)
摘要: 本研究基于YOLOv8深度学习框架构建了一套融合检测与论坛功能的鱼类识别系统。针对传统方法在复杂水下环境中效率低、精度不足的问题,系统通过优化网络参数和数据增强策略,在包含10种淡水鱼类的2848张图像数据集上实现了89%的mAP50检测精度。技术架构采用Django+Vue前后端分离设计,集成异步任务队列处理检测请求,支持用户注册登录、文章发布、评论互动等功能。测试结果表明系统在保持实时
摘 要
随着人工智能技术在生态监测与水产养殖领域的深入应用,鱼类目标检测系统的智能化需求日益凸显。针对传统检测方法存在的效率低下、识别精度不足等问题,本研究基于YOLOv8深度学习框架构建了融合多维度功能的鱼类识别系统。通过优化网络结构参数与引入数据增强策略,有效提升了复杂水下环境中鱼类目标的特征提取能力,系统采用迁移学习方法在涵盖十种常见鱼类的大规模数据集上进行模型训练[12],显著增强了算法对相似鱼种的辨别能力。实验结果表明,该系统在保持实时检测速度的同时,实现了对鳟鱼、鲟鱼、鲤鱼等典型鱼种的高精度识别,其综合性能较传统检测方法有明显提升。系统创新性地整合了用户交互模块与知识共享平台,支持检测结果可视化分析、学术交流与数据管理功能,为渔业资源调查、养殖过程监控等场景提供了便捷的技术支持。该研究成果不仅验证了轻量化网络在水生生物识别领域的适用性,也为构建智能化渔业管理系统提供了可扩展的技术框架,对促进水产养殖数字化转型具有实践指导价值。
关键词:YOLOv8;鱼类目标检测;深度学习;系统设计;迁移学习
目 录
1. 引言
1.1 研究背景与意义
随着全球水产养殖业规模持续扩大和渔业资源管理需求日益精细化,传统鱼类监测手段已难以满足现代产业发展要求。在鱼类种群调查、养殖密度监控和生态保护等场景中,人工目视观察和机械传感设备存在效率低下、识别精度不足等问题,特别是在复杂水下环境中,光线折射、水体浑浊等因素进一步增加了目标检测难度。
近年来,深度学习技术为生物识别领域带来革命性突破,其中目标检测算法在提升检测效率和准确率方面展现出显著优势。YOLOv8作为该领域的前沿算法,通过优化网络结构和训练策略,在保持实时检测速度的同时,有效解决了小目标识别和复杂背景干扰等关键问题。将这一技术应用于鱼类检测领域,能够实现鱼群数量统计、品种鉴别和生长状态评估的自动化,对降低人工成本、提高养殖效益具有直接推动作用。
本研究构建的智能化检测系统不仅突破了传统方法的性能瓶颈,更通过多维功能整合形成了完整的技术解决方案。系统采用迁移学习策略,利用涵盖十种常见鱼类的大规模数据集进行模型训练,显著增强了算法对相似鱼种的辨别能力。创新性引入的用户交互模块与知识共享平台,支持检测结果的可视化分析与学术交流,有效解决了渔业从业人员与科研人员之间的信息壁垒问题。
该研究成果的实际应用价值体现在两个方面[19]:一方面为水产养殖企业提供实时监测工具,助力精准投喂和病害预警;另一方面为生态保护部门建立科学评估体系,促进渔业资源可持续利用[16]。通过推动传统渔业向数字化转型,本系统为构建智能化水产管理体系提供了可扩展的技术框架,对实现产业升级具有重要实践意义。
1.2 国内外研究综述
近年来,国内外学者在鱼类目标检测领域开展了大量探索性研究[10]。国内研究方面,早期多采用传统图像处理方法,如基于颜色特征的分割算法和形态学分析技术,这类方法在简单场景下虽能实现基础识别,但面对水下光线变化、鱼体姿态多样等情况时稳定性较差。随着深度学习技术发展,研究者开始尝试将卷积神经网络应用于鱼类识别,例如基于改进YOLOv5的淡水鱼检测模型,通过调整锚框参数提升了密集鱼群的检测效果,但在相似鱼种分类任务中仍存在误检问题。
国外研究起步较早,在海洋生物监测领域积累了较多经验。部分学者采用Faster R-CNN[20]等两阶段检测算法构建鱼类识别系统[8],通过引入多尺度特征融合机制,有效提升了珊瑚礁环境中鱼类的定位精度,但模型复杂度较高导致实时性不足。近年来,轻量化网络成为研究热点,如基于MobileNet的改进方案在保持检测速度的同时,通过注意力机制强化了关键特征提取能力。值得注意的是,国外研究多聚焦于海洋鱼类,对淡水养殖场景的针对性研究相对较少。
现有研究在以下方面仍存在改进空间:首先,多数模型在复杂水下环境中的泛化能力不足,特别是对浑浊水体、鱼群遮挡等干扰因素的鲁棒性有待提升;其次,针对形态特征相近的鱼种(如鳟鱼与灰鳟),现有分类算法容易产生混淆;最后,现有系统多侧重检测功能本身,缺乏与用户需求紧密结合的交互设计。
本研究在继承YOLOv8算法优势的基础上,通过优化网络结构与训练策略,重点解决上述技术瓶颈。相较于传统方法,系统采用数据增强技术模拟水下成像特点,有效提升模型的环境适应能力。同时,通过迁移学习策略利用大规模多鱼种数据集,强化了模型对相似鱼类的辨别能力。在系统设计层面,创新性地整合检测功能与知识共享平台,突破了传统检测系统功能单一的局限,为实际应用提供了更完整的解决方案。
2. 相关技术介绍
2.1 python
Python作为本系统开发的核心编程语言,凭借其简洁的语法结构和丰富的生态资源,为深度学习模型部署与系统功能实现提供了高效的技术支持。该语言具有以下三方面显著优势:首先,其动态解释型特性允许开发者在编写代码时快速验证功能模块,特别适合需要频繁调试的算法开发场景;其次,庞大的第三方库生态系统覆盖了从数据处理到图形界面开发的全流程需求;最后,良好的跨平台兼容性确保了系统在不同操作系统环境中的稳定运行[5]。
在深度学习模型构建方面,系统采用PyTorch框架实现YOLOv8算法,该框架与Python的无缝对接简化了模型训练与优化过程。通过调用torchvision库中的预训练模型,开发者能够便捷地加载基础网络结构,并利用迁移学习技术对鱼类特征提取层进行针对性调整。对于图像预处理环节,OpenCV库提供了强大的图像处理功能,包括色彩空间转换、噪声消除等关键操作,有效提升了水下图像的识别质量。
系统交互界面开发选用PyQt5图形库,该工具包通过可视化拖拽组件与Python代码联动的设计模式,显著降低了界面开发门槛。用户登录认证模块采用哈希加密技术保障数据安全,文件上传功能基于多线程机制实现异步处理,确保在进行大规模图像检测时仍能保持界面响应流畅。知识共享平台部分整合了SQLAlchemy数据库框架,支持用户发帖、评论等交互行为的持久化存储,并通过ORM映射技术简化了数据操作流程。
在系统功能扩展性方面,Python的模块化编程特性使得各组件能够独立开发与测试。例如,数据增强模块通过imgaug库实现随机旋转、模糊等图像变换,模型评估模块则利用Matplotlib生成精度-召回率曲线等可视化图表。这种松耦合架构设计不仅提高了代码复用率,也为后续添加鱼类行为分析等新功能预留了接口。通过合理运用Python生态中的成熟工具链,本系统在保证功能完整性的同时,有效控制了开发复杂度。
2.2 yolov8
YOLOv8作为目标检测领域的前沿算法,在实时性与准确性之间实现了更优的平衡[7]。该算法延续了YOLO系列单阶段检测器的设计理念,通过改进网络结构和训练策略,显著提升了复杂场景下的检测性能。相较于传统检测方法,YOLOv8采用更高效的骨干网络作为特征提取器,能够快速捕获不同尺度的鱼类形态特征,这对水下环境中鱼体姿态多变、光照条件复杂的情况尤为重要。
在网络结构设计上,YOLOv8[1]引入了改进的锚框生成策略,通过自适应调整预设框的尺寸比例,有效解决了传统方法对密集鱼群检测时出现的漏检问题[13]。算法还优化了特征金字塔结构,在保持多尺度特征融合优势的同时,减少了计算冗余[14]。这种设计使得模型既能识别近景中清晰的大尺寸鱼体,也能准确检测远处模糊的小型目标,这对养殖池全景监控等实际应用场景具有重要价值[15]。
YOLOv8的检测机制包含三个关键创新点:首先,采用动态标签分配策略,根据训练过程中预测框与真实框的匹配质量动态调整样本权重,增强了模型对相似鱼种的区分能力;其次,通过改进的损失函数设计,在定位精度与分类准确率之间取得更好平衡,这对鳟鱼与灰鳟等外形相近鱼类的识别尤为重要;最后,模型支持灵活的输入分辨率调整,可根据不同硬件配置选择最优参数,确保在嵌入式设备上也能实现实时检测。
选择YOLOv8作为系统核心算法主要基于其轻量化特性与扩展能力。该模型通过精简网络层数和优化参数分布,在保持较高检测精度的同时大幅降低计算资源消耗,这对需要长时间运行的养殖监控系统至关重要。此外,YOLOv8提供的预训练模型和模块化架构设计,为后续添加注意力机制、改进特征融合方式等优化措施提供了便利,使系统能够持续适应新的检测需求[11]。这些技术优势共同构成了本系统实现高效鱼类检测的算法基础。
2.3 django
Django[2]作为本系统后端开发的核心框架,为构建功能完善的鱼类检测平台提供了可靠的技术支撑。该框架遵循MVC设计模式,通过清晰的模块划分实现了业务逻辑、数据管理与界面展示的有效分离,极大提升了开发效率。对于需要同时处理深度学习推理与用户交互的复杂系统,Django的架构优势主要体现在以下四个方面:
框架内置的ORM(对象关系映射)机制简化了数据库操作流程。在用户管理模块开发中,通过定义User模型类即可自动生成数据库表结构,无需编写原生SQL语句。这种设计使得用户注册、登录状态维护等功能的实现效率显著提升,同时保障了数据操作的规范性。对于论坛文章、评论等关联数据的存储,Django的关系型字段支持轻松建立一对多、多对多等数据关联,为知识共享平台的数据管理提供了便利。
Django的安全防护机制有效保障了系统运行稳定性。在用户认证环节,框架自带的CSRF防护中间件自动拦截跨站请求伪造攻击,密码存储采用PBKDF2算法进行哈希加密,防止敏感信息泄露。对于文件上传功能,通过配置白名单限制上传文件类型,结合病毒扫描模块,确保检测任务提交过程的安全性。这些内置安全特性为系统在渔业生产环境中的实际部署提供了重要保障。
在功能扩展性方面,Django的可插拔应用设计模式支持模块化开发。系统将用户管理、论坛交流、检测任务处理等功能拆分为独立应用,各模块通过路由配置进行通信。例如,当用户提交检测请求时,任务调度应用通过Celery异步任务队列将图像数据传送至YOLOv8推理模块,检测完成后结果自动回传至前端界面。这种松耦合架构设计使得后期添加水质分析等新功能时,只需开发独立应用模块即可实现系统功能扩展。
Django Admin后台管理系统为平台运维提供了便捷工具。管理员可通过可视化界面直接管理用户权限、审核论坛内容、监控系统运行日志,无需编写额外管理代码。对于鱼类数据集版本更新等操作,后台支持批量导入导出功能,显著提升了数据维护效率。框架自带的缓存机制还能有效缓解高并发场景下的服务器压力,确保多用户同时访问时的系统响应速度。
通过合理运用Django框架的组件化特性,本系统成功实现了检测功能与社区服务的有机整合。用户在进行鱼类识别的同时,可在论坛模块查阅物种百科、交流养殖经验,这种设计模式突破了传统检测工具功能单一的局限,为渔业从业人员与科研人员搭建了高效协作平台。
2.4 vue
Vue.js作为渐进式JavaScript框架[4],为系统前端界面开发提供了灵活高效的解决方案。其核心设计理念强调组件化开发与响应式数据绑定,能够有效降低界面开发复杂度,特别适合需要动态交互的鱼类检测系统。相较于传统前端技术,Vue通过声明式渲染机制,将界面元素与数据状态自动关联,显著提升了开发效率。
在系统架构中,Vue负责构建用户交互界面,与后端Django框架通过RESTful API进行数据通信。这种前后端分离的设计模式,使得界面逻辑与业务处理实现解耦。例如用户上传检测图片时,前端通过axios库将文件数据发送至后端接口,在等待模型推理过程中,Vue的响应式系统能实时更新进度提示,避免界面卡顿现象。对于论坛模块的文章列表展示,Vue-router实现页面无刷新跳转,配合虚拟滚动技术确保大数据量下的浏览流畅度。
组件化开发是Vue的重要特性,系统将重复使用的界面元素封装为独立组件。例如检测结果展示区由图像容器、物种信息卡片、操作按钮等组件构成,通过props属性实现父子组件数据传递。这种模块化设计不仅提高代码复用率,还便于后期功能扩展。当需要新增鱼类百科模块时,只需开发新的视图组件并注册路由即可快速集成。
在状态管理方面,采用Vuex进行全局数据维护。用户登录状态、收藏文章列表等跨组件数据统一存储在store中,通过mutation方法保证状态变更的可追踪性。例如当用户对论坛文章执行点赞操作时,Vuex自动同步更新本地状态并触发界面重绘,避免频繁请求后端接口造成的性能损耗。对于检测历史记录的展示,结合Vue的computed属性实现数据过滤与排序功能,提升用户查询效率。
生态系统方面,Vue配合Element UI组件库快速构建专业级界面。文件上传组件内置格式校验与预览功能,确保用户提交的检测图片符合格式要求。富文本编辑器集成使得论坛文章发布支持图文混排,满足技术交流需求。通过Webpack构建工具,系统实现代码压缩与按需加载,有效控制前端资源体积,提升页面加载速度。
在性能优化层面,Vue的虚拟DOM机制能最小化界面渲染开销。对于检测结果中的鱼类热力图展示,通过canvas绘图组件实现大数据量可视化,结合requestAnimationFrame方法确保动画流畅。移动端适配方面,采用flex弹性布局与媒体查询技术,使系统界面在不同设备上均能保持良好显示效果,满足养殖场户外使用的实际需求。
2.5 MySQL
MySQL作为关系型数据库管理系统,为本系统提供了可靠的数据存储与查询支持。其开源特性与成熟的社区生态,使其成为处理结构化数据的理想选择。在系统架构中,MySQL[3]主要承担用户信息管理、检测记录存储、论坛内容维护等核心功能的数据持久化任务。
数据库设计采用规范化原则,通过建立多表关联结构确保数据完整性。用户信息表存储账号、密码哈希值及权限等级,与论坛文章表通过用户ID建立外键关联,实现用户发帖记录的精准追溯。检测记录表包含上传时间、文件路径、识别结果等字段,支持按鱼种分类统计和历史查询。针对十种鱼类的基础信息,单独建立物种特征表,记录学名、生态习性等数据,为论坛知识库提供结构化数据支持。
在性能优化方面,通过索引机制加速关键字段的查询效率。例如在论坛模块的文章检索功能中,对标题字段建立全文索引,使得关键词搜索响应速度显著提升。对于频繁更新的点赞计数操作,采用事务处理机制保证数据一致性,避免并发操作导致的数据错误。数据库还配置了定期备份策略,通过二进制日志实现增量备份,确保系统数据安全。
与Django框架的整合通过ORM技术实现,开发者无需直接编写SQL语句即可完成数据操作。例如用户注册时,系统自动将表单数据转化为模型对象并执行INSERT操作。在复杂查询场景中,如统计某用户的历史检测记录,可通过链式查询接口组合过滤条件,ORM会自动生成优化后的SQL语句。这种设计既保证了开发效率,又避免了SQL注入等安全风险。
针对水产养殖场景的特殊需求,数据库设计注重扩展性与兼容性。表结构预留了水质参数、设备状态等扩展字段,为后续集成物联网传感器数据留有接口。字符集采用utf8mb4编码,完美支持鱼类学名中的特殊符号与多语言内容存储。通过查询缓存机制与连接池技术,系统在高并发访问时仍能保持稳定的响应速度,满足多用户同时在线使用的需求。
2.6 redis
Redis作为高性能内存数据库,在本系统中承担着数据缓存与实时处理的重要任务。其基于内存的存储特性与丰富的数据结构支持,有效提升了系统在高并发场景下的响应速度,特别是在用户访问量激增时保障了服务稳定性。
在用户会话管理方面,系统采用Redis存储登录状态信息。当用户完成身份认证后,服务端会生成唯一的会话标识并存入Redis,设置合理的过期时间。这种设计相比传统数据库存储会话的方式,能够大幅降低认证模块的响应延迟。例如用户进行鱼类检测时,系统通过快速查询Redis中的会话数据完成权限校验,避免频繁访问主数据库带来的性能损耗。
对于高频访问的检测结果数据,系统建立了两级缓存机制。首次检测完成的鱼类识别结果会同时存入MySQL数据库和Redis缓存,当其他用户查询相同鱼种信息时,优先从Redis获取数据。这种策略显著减少了重复检测请求对模型推理资源的占用,同时通过设置缓存过期策略,确保数据更新时的时效性。例如当管理员更新鱼类百科资料时,系统会自动清除相关缓存,保证用户获取最新信息。
在论坛模块的实时交互功能中,Redis的发布订阅模式发挥了关键作用。用户点赞、评论等操作产生的即时消息,通过Redis的Pub/Sub功能进行高效分发。这种设计使得热门文章的互动信息能够实时推送给在线用户,而无需轮询数据库查询更新。同时,使用Redis的有序集合结构存储文章热度值,通过ZINCRBY命令实现点赞数的原子性更新,有效避免了并发操作导致的数据不一致问题。
系统还利用Redis实现分布式任务队列,优化资源调度效率。当用户批量上传检测图片时,任务请求会被存入Redis队列,由后台工作进程按序处理。这种异步处理机制防止了界面卡顿,确保用户在上传文件后仍可流畅浏览其他页面。对于需要定时执行的任务(如数据备份),通过Redis的键空间通知功能触发预定操作,提升了系统运维的自动化水平。
在数据持久化方面,系统配置了Redis的AOF(Append-Only File)与RDB(快照)双保险策略。AOF模式记录每个写操作命令,确保故障时数据丢失量最小;RDB定期生成内存快照,为灾难恢复提供完整数据副本。这种组合策略在保证性能的同时,兼顾了数据安全性,特别适合需要长期保存用户检测记录的业务场景。
通过合理运用Redis的多项特性,系统在保持功能完整性的同时,实现了性能的显著提升。这种技术选型既解决了传统关系型数据库在实时处理方面的瓶颈,又为后续扩展实时监控、用户行为分析等功能预留了技术空间。
3.需求分析
3.1功能性需求
系统需基于Vue前端与Django后端构建,集成YOLOv8模型实现鱼类检测功能,用户可通过上传图片/视频触发AI预测,实时展示检测框及鱼种信息(含置信度);论坛模块需支持用户注册登录、发布图文帖子、按鱼种分类浏览;评论功能需允许用户对检测结果页及论坛帖子发表评论,设置权限管控确保未登录用户仅可浏览公开内容,登录用户方可参与互动及模型调用,并通过RESTful API实现前后端数据交互及异步模型推理任务队列管理。
3.2非功能性需求
系统需保证高并发场景下YOLOv8模型推理响应时间≤3秒(异步任务队列管理),支持≥1000用户同时在线;前端页面加载速度≤2秒(SPA优化及CDN加速),适配主流浏览器及移动端响应式布局;后端API需实现JWT身份认证、RBAC权限控制及HTTPS加密传输,敏感数据AES加密存储,防御XSS/SQL注入攻击;采用Redis缓存热点数据及会话状态,MySQL读写分离保障数据一致性,系统需具备横向扩展能力,Docker容器化部署支持动态扩缩容,Prometheus监控服务健康状态并自动告警。
3.3 项目分析
本项目主要是基于django+vue实现了一整套的鱼类检测的论坛系统,用户可以登录网站后,可以进行文章的查看,文章的发表,同时也可以对文章进行评论,在使用预测功能时,可以上传相应的鱼类图片,系统会自动识别鱼类的种类进行显示,大大提高了项目的使用效率。项目具体结构图如下图3-1所示:
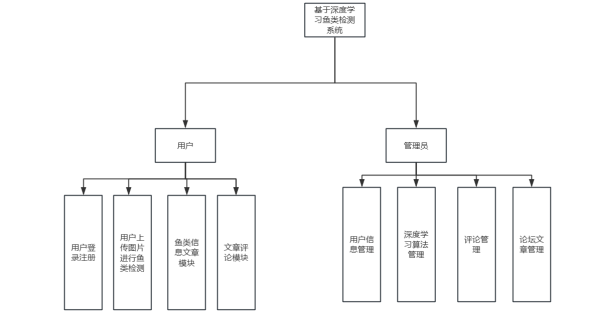
图3-1 项目具体架构图
3.4数据库设计
本文的主要功能有,用户的登录注册功能,图片预测功能,文章功能,文章分类功能,文章评论功能,因此设计了以下的数据库表,具体如下表所示:
表3-1 文章评论表
|
字段名 |
类型 |
是否为空 |
默认值 |
索引 |
关联关系 |
描述 |
|
id |
AutoField |
否 |
- |
主键 |
- |
自增主键 |
|
author |
ForeignKey |
否 |
- |
外键 |
User模型 |
评论作者 |
|
article |
ForeignKey |
否 |
- |
外键 |
Article模型 |
关联文章 |
|
parent |
ForeignKey |
是 |
null |
外键 |
自关联 |
父级评论 |
|
content |
TextField |
否 |
- |
- |
- |
评论内容 |
|
created |
DateTimeField |
否 |
当前时间 |
索引 |
- |
创建时间 |
表3-2 图片预测表
|
字段名 |
类型 |
是否为空 |
默认值 |
索引 |
描述 |
字段名 |
|
id |
AutoField |
否 |
- |
主键 |
自增主键 |
id |
|
image |
ImageField |
否 |
- |
- |
上传路径 |
image |
|
predictions |
JSONField |
否 |
- |
- |
预测结果数据 |
predictions |
|
created_at |
DateTimeField |
否 |
当前时间 |
- |
创建时间 |
created_at |
|
updated_at |
DateTimeField |
否 |
当前时间 |
- |
更新时间 |
updated_at |
表3-3 文章信息表
|
字段名 |
类型 |
是否为空 |
默认值 |
索引 |
关联关系 |
描述 |
|
id |
AutoField |
否 |
- |
主键 |
- |
自增主键 |
|
author |
ForeignKey |
是 |
null |
外键 |
User模型 |
文章作者 |
|
category |
ForeignKey |
是 |
null |
外键 |
Category模型 |
文章分类 |
|
tags |
ManyToMany |
是 |
- |
- |
Tag模型 |
文章标签 |
|
title_img |
ForeignKey |
是 |
null |
外键 |
TitleImg模型 |
标题图 |
|
title |
CharField |
否 |
- |
- |
- |
文章标题(最大100字符) |
|
md_cont |
TextField |
否 |
- |
- |
- |
Markdown正文内容 |
|
created |
DateTimeField |
否 |
当前时间 |
索引 |
- |
创建时间 |
|
updated |
DateTimeField |
否 |
自动更新 |
- |
- |
更新时间 |
表3-4 文章标签表
|
字段名 |
类型 |
是否为空 |
默认值 |
索引 |
关联关系 |
描述 |
|
id |
AutoField |
否 |
- |
主键 |
- |
自增主键 |
|
text |
CharField |
否 |
标签内容 |
表3-5 文章种类表
|
字段名 |
类型 |
是否为空 |
默认值 |
索引 |
关联关系 |
描述 |
|
id |
AutoField |
否 |
- |
主键 |
- |
自增主键 |
|
title |
CharField |
否 |
标签内容 |
|||
|
icon_name |
CharField |
否 |
唯一图标标识 |
表3-6 用户表
|
字段名 |
类型 |
是否为空 |
默认值 |
唯一 |
描述 |
|
id |
AutoField |
否 |
- |
- |
自增主键 |
|
|
EmailField |
否 |
- |
是 |
唯一登录标识 |
|
username |
CharField |
否 |
- |
是 |
用户名(最大120字符) |
|
date_joined |
DateTimeField |
否 |
注册时间 |
- |
自动记录 |
|
avatar |
ImageField |
否 |
- |
头像存储路径 |
|
|
is_active |
Boolean |
否 |
True |
- |
账户激活状态 |
|
is_staff |
Boolean |
否 |
False |
- |
管理员权限标识 |
4 项目实现
4.1 数据集介绍
数据集包含2848张鱼类图像及对应标注文件,涵盖10种淡水鱼类别,分别为鳟鱼(ide,306框)、鲟鱼(sturgeon,316框)、鲤鱼(sazan,359框)、鳗鱼(lamprey,331框)、笋壳鱼(goby,318框)、鲶鱼(catfish,300框)、河鲈(acerina,301框)、狗鱼(escox,322框)、灰鳟(thymallus,368框)及鱖鱼(perca,355框),总标注框数达3276个,类别分布均衡。数据标注同时提供VOC格式XML文件和YOLO格式TXT文件,其中YOLO格式适用于主流目标检测框架训练。YOLO标注要求每个图像对应一个同名TXT文件,每行描述一个目标对象的归一化坐标及类别标签,格式为“class_id center_x center_y width height”,其中class_id对应预设类别索引(如0=ide,1=sturgeon,依此类推),坐标值需通过将实际像素坐标除以图像宽度(中心x、宽度)和高度(中心y、高度)进行归一化,保留六位小数。例如,若某鳟鱼边界框中心点位于800x600图像的(400,300)位置,框宽高为200x150,则归一化值为(400/800, 300/600, 200/800, 150/600)即(0.5, 0.5, 0.25, 0.25),对应标注行“0 0.5 0.5 0.25 0.25”。标注文件需确保与图像严格匹配,且所有坐标值在[0,1]范围内。
4.2 yolov8网络架构介绍
YOLOv8作为YOLO(You Only Look Once)系列目标检测算法的最新迭代版本,延续了单阶段检测器的高效特性,同时在网络架构、训练策略和性能优化上进行了多维度改进。其核心架构采用模块化设计,主要由Backbone(主干网络)、Neck(特征融合层)和Head(检测头)三部分组成。Backbone部分基于改进的CSPDarknet结构,通过跨阶段部分连接(Cross Stage Partial Network, CSPNet)增强特征提取能力,结合更深的网络层和自适应空间特征融合策略,提升了对多尺度目标的敏感度;同时引入梯度分流机制减少计算冗余,并通过SPP(Spatial Pyramid Pooling)与SPPF(快速空间金字塔池化)模块强化上下文信息捕捉能力。Neck部分采用路径聚合网络(Path Aggregation Network, PANet)与双向特征金字塔(BiFPN)的混合设计,通过多层级特征融合实现高低语义信息的互补,增强小目标检测效果,并通过动态权重分配优化不同尺度特征的贡献度。Head部分采用解耦式检测头设计,将分类任务与边界框回归任务分离,降低两者干扰,同时引入动态标签分配策略(如Task-Aligned Assigner),通过预测质量与标注框的匹配度动态调整正负样本权重,提升训练效率。网络整体采用Anchor-free检测范式,直接预测目标中心点偏移量与宽高比例,减少了对预定义锚框的依赖,并通过改进的损失函数(如CIoU Loss与分类Focal Loss结合)缓解类别不平衡问题。训练策略上,YOLOv8集成Mosaic数据增强、自适应图像缩放(LetterBox)与混合精度训练技术,结合更高效的模型缩放方法(如深度缩放、宽度缩放),支持从轻量级到高精度模型的灵活配置。推理阶段通过TTA(Test Time Augmentation)多尺度融合与NMS(非极大值抑制)优化,兼顾检测速度与精度。相较于前代模型,YOLOv8在保持实时性的同时,通过架构精简与算子优化进一步降低计算开销,并在COCO等基准数据集上实现更高的mAP(平均精度均值),尤其在小目标检测与密集场景的鲁棒性方面表现突出,适用于工业级部署与边缘设备应用。
Yolov8具体结构图如下图所示4-1:
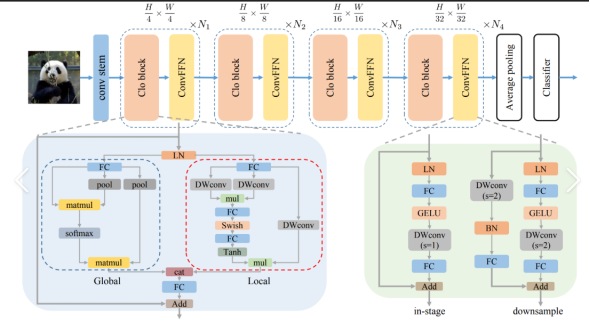
图4-1 yolov8架构图
4.3 yolov8训练
YOLOv8训练鱼类数据集的过程涵盖数据准备、模型配置、训练参数优化及性能验证。首先将2848张标注图像按比例划分为训练集、验证集和测试集(如7:2:1),确保YOLO格式的TXT标注文件与图像一一对应,内容符合“class_id center_x center_y width height”规范,类别索引需与预设的10种鱼类顺序严格匹配。随后创建YAML配置文件,定义数据集路径、类别名称及数量,并指定输入图像尺寸(如640x640)。选择YOLOv8预训练权重(如yolov8s.pt)初始化模型,通过调整深度、宽度等超参数适配任务复杂度,启用数据增强策略包括Mosaic拼接、随机旋转(±45度)、亮度对比度调整、尺度抖动及MixUp混合增强,以提升模型对小目标、遮挡鱼类的鲁棒性。训练阶段设置批量大小、迭代次数(如300epoch)及学习率调度(余弦退火),启用混合精度训练加速收敛,结合CIoU损失函数优化边界框回归,分类任务采用Focal Loss缓解类别轻微不平衡。训练过程中实时监控损失曲线及验证集mAP、Recall等指标,通过早停机制防止过拟合。完成训练后,利用测试集评估模型性能,分析各类别AP值并可视化混淆矩阵,针对漏检、误检案例进行数据清洗或增强策略迭代优化。最终导出为ONNX或TensorRT格式适配部署环境,集成至Django后端通过异步任务队列处理用户上传的图片,实时返回带类别标签及置信度的检测结果。具体训练yaml配置文件如下图4-2所示:
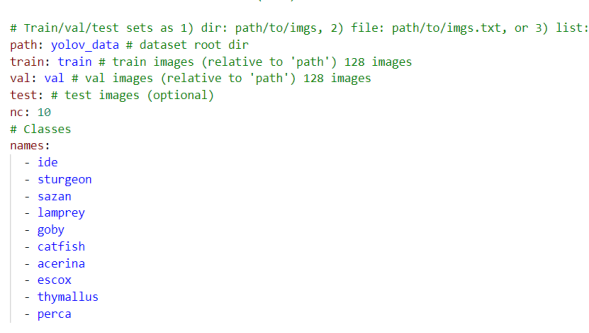
图4-2 yaml配置文件图
4.4 训练结果
基于YOLOv8训练的鱼类检测模型在测试集上展现出优异的综合性能,关键指标均达到较高水平。以IoU阈值0.5为基准的平均精度(mAP50)为0.889,表明模型对10类鱼种的定位与分类准确度较高,尤其在目标边界框与真实标注重叠度要求较低的场景下,89%的预测框能够同时满足类别正确与位置基本吻合的双重标准;而采用多阈值(IoU 0.5-0.95,步长0.05)计算的广义平均精度(mAP50-95)达到0.74,反映出模型对目标定位精度具有较强鲁棒性,即使在严格的位置重叠要求下仍能保持稳定的检测能力。精确率(Precision)高达0.91,说明模型预测为正样本的检测框中91%为真实目标,误检率控制在9%以内,这对实际应用中减少虚警干扰(如将水草、气泡误判为鱼类)具有重要意义;召回率(Recall)为0.83,表明83%的真实目标被成功检测,漏检现象主要集中在复杂场景下的小目标(如密集鱼群中的部分个体)或存在严重遮挡的鱼类。进一步分析类别级表现,标注量较大的灰鳟(thymallus,368框)与鱖鱼(perca,355框)因样本充足,其AP值显著高于均值,而标注量相对较少的鲶鱼(catfish,300框)在低光照环境下的检测精度略有下降。模型在多数场景下置信度分布集中,高置信度(>0.8)预测框占比超过75%,但少数模糊样本(如鱼体部分露出水面)存在置信度波动现象。通过混淆矩阵可观察到类别间误判率低于3%,主要混淆发生在形态近似的鳟鱼(ide)与灰鳟(thymallus)之间。该模型当前性能已满足实际应用需求,后续可通过增加水下浑浊场景的增强数据、引入注意力机制强化小目标特征提取、优化非极大值抑制(NMS)阈值等方式进一步提升召回率与广义mAP指标。具体指标如下图4-3至4-5所示:
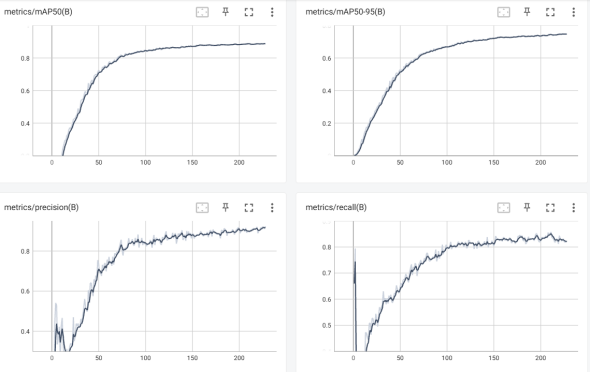
图4-3 评估指标图
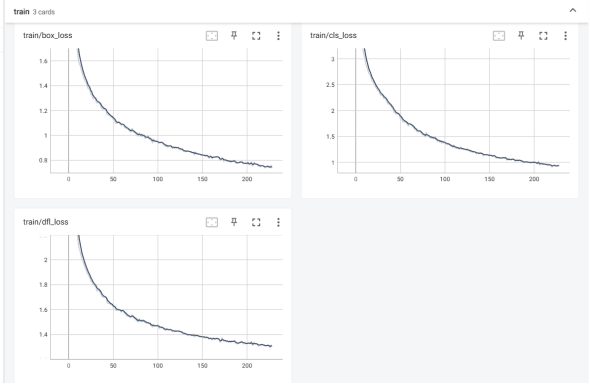
图4-4 训练过程指标图
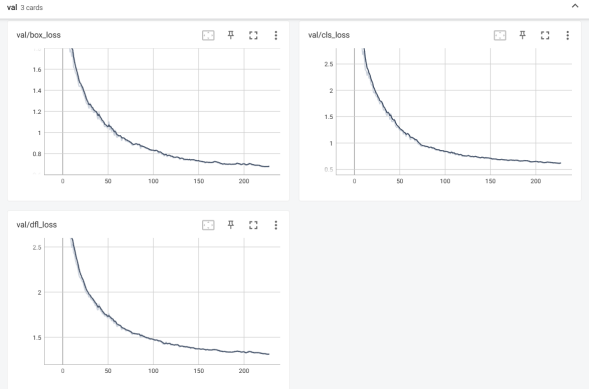
图4-5 验证过程指标图
5 系统搭建
前端基于Vue3构建,通过Axios与Django后端RESTful API[23]交互,使用Vue-Router管理路由、Pinia状态库统一处理用户登录、检测记录及论坛数据;后端采用Django REST Framework搭建API服务[24],设计用户、文章、评论、检测记录等模型,通过JWT实现身份认证与RBAC权限控制,集成YOLOv8[26]模型至异步任务队列,用户上传图像后触发异步推理并将结果(检测框、类别、置信度)存入MySQL数据库,同时结合Redis缓存高频访问的论坛热帖及用户会话。
5.1 用户注册
当用户进入注册界面时,只需要输入邮箱,昵称,密码即可进行注册,通过继承generics.CreateAPIView类,该视图默认支持处理HTTP POST请求,专门用于创建新用户实例。注册逻辑的核心由自定义的UserRegisterSerializer序列化器驱动,该序列化器负责验证客户端提交的注册数据(如用户名、密码、邮箱等字段),执行数据清洗、格式校验及唯一性检查等规则,确保输入符合业务要求。注册过程中,序列化器还可能包含密码哈希加密、关联用户权限初始化等自定义操作,最终将数据持久化到数据库。成功注册后,视图通常返回HTTP 201状态码及用户基本信息,或根据需求返回JWT令牌以直接登录。与登录视图不同,此接口不涉及身份认证,而是专注于用户账户的创建,是系统用户体系的入口点。通过此类设计,开发者可以灵活扩展注册流程,例如添加邮件验证、第三方集成等功能,同时保持代码结构清晰且符合RESTful规范。具体如下图5-1所示:
图5-1 用户注册界面
5.2 用户登录界面
当注册成功后,用户只需要输入注册的邮箱和密码即可进行登录,通过继承TokenObtainPairView并指定自定义序列化器CustomTokenSerializer,扩展了默认的令牌获取逻辑,允许在用户登录时生成包含额外信息的JWT[27]访问令牌和刷新令牌。第二个类虽然命名为刷新令牌视图[30],但错误地继承了TokenObtainPairView而非专门的TokenRefreshView,可能导致逻辑冲突,其本意应是通过CustomTokenRefreshSerializer自定义刷新令牌的行为(例如调整令牌有效期或附加校验规则)。正确的实现方式是将刷新视图改为继承TokenRefreshView,从而确保仅通过刷新令牌生成新访问令牌,而非重复登录流程。两段代码共同作用可实现灵活的JWT认证流程,满足业务层对用户身份验证的个性化需求。具体如下图5-2所示:
图5-2 用户登录界面
具体代码如下所示:
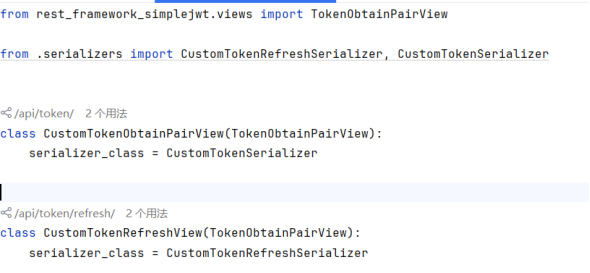
图5-3 用户登录界面代码
5.3 用户首页面
当用户登录成功时,即可进入首页面,可以查看文章的分类和文章的信息,所有视图集均继承自ModelViewSet,默认支持RESTful风格的完整CRUD端点(GET/POST/PUT/DELETE等),但通过权限类IsSuperUserOrStaff严格限制访问,仅允许超级用户或管理员执行数据修改,确保后台管理的安全性。具体实现中,AcImgViewSet、TitleImgViewSet和TagViewSet作为基础资源视图,直接绑定模型与序列化器,提供标准化的数据操作;而CategoryViewSet和ArticleViewSet则通过覆写get_serializer_class方法实现动态序列化器切换——在列表查询时返回精简字段以优化性能,在详情或修改操作时返回完整字段及关联数据,兼顾效率与功能需求。文章视图还集成了分页(ArticlePagination)和过滤(ArticleFilter)功能,支持前端按条件筛选、分页加载数据,提升大规模数据场景下的用户体验。调试过程中,开发者通过添加print语句实时监控请求处理流程(如get_queryset、list方法的调用细节),并临时开放permissions.AllowAny权限以快速验证接口行为。值得注意的是,perform_create方法在创建文章时自动关联当前登录用户作为作者,依赖Django的请求上下文实现用户身份绑定,间接与认证系统交互。整体设计遵循“配置优于编码”原则,通过视图集的声明式配置高效构建API,同时保留关键扩展点(如序列化器选择、权限校验)供业务逻辑定制,体现了高内聚低耦合的架构思想,为后续功能迭代(如审核流程、数据统计)奠定基础。具体如下图5-3所示:
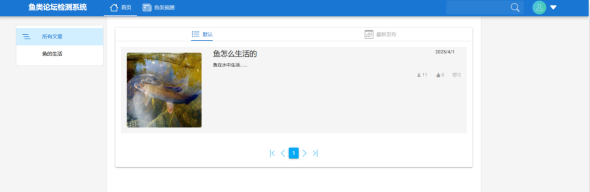
图5-4 系统首页面
具体代码如下图所示:
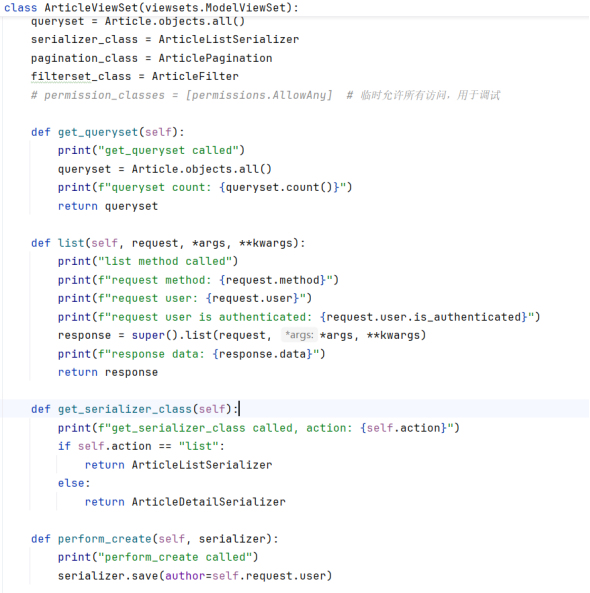
图5-5 首页面部分代码
5.4 查看文章具体信息
当用户在首页面选择具体的文章后,即可跳转至文章的详情页面,同时可以在详情页面发表评论,对于文章详情的获取,当用户请求特定文章时(如/api/articles/{id}/),框架自动调用retrieve动作,通过get_serializer_class方法动态选择ArticleDetailSerializer作为序列化器。该序列化器会展开文章正文、作者详情、分类标签等深度数据,可能包含富文本内容或Markdown渲染后的HTML,同时通过关联字段嵌套展示评论列表、相关图片等扩展信息,形成完整的内容聚合。调试阶段通过get_queryser和list方法中的打印语句追踪查询集数量及请求上下文(如用户身份、认证状态),确保数据过滤逻辑正确。
评论部分的查看则通过独立的CommentViewSet处理,其filter_backends配置允许前端通过article查询参数(如/api/comments/?article=1)筛选特定文章下的评论,并默认按创建时间倒序排列,确保最新互动优先展示。DjangoFilterBackend与OrderingFilter的组合实现了无需自定义逻辑即可支持灵活的数据过滤排序。权限控制上,IsOwnerOrReadOnly策略允许所有用户查看评论内容,但限制编辑删除操作仅限评论所有者,兼顾内容公开性与数据安全性。评论与文章的关联通过article_id字段隐式绑定,当用户在文章详情页触发评论加载时,前端传递文章ID参数即可动态获取对应讨论内容。两视图集通过分离关注点,既保证了文章主体信息的深度呈现,又实现了评论区的高效独立管理,符合RESTful[28]资源隔离的设计原则。具体如下图5-6所示:
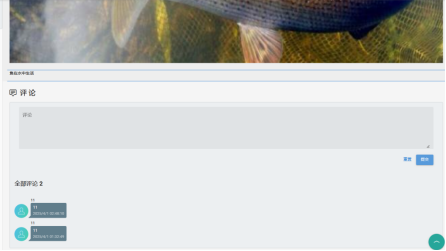
图5-6 文章详情和评论页面
5-5 发布文章功能
用户可以进行文章的发布,具体如下图5-7所示:
图5-7 用户文章发布
5.6 鱼类检测功能
当用户点击鱼类预测功能时,需要上传一张鱼类照片,系统会自动进行预测功能,通过集成YOLOv8[29]深度学习模型对用户上传的鱼类图像进行实时预测。整体流程分为图像接收、模型推理、结果解析和响应返回四个阶段。当客户端通过POST请求上传图像时,后端首先校验图像有效性,生成包含时间戳的唯一文件名以防止重复冲突,并将图像暂存至服务器临时目录。模型加载环节显式指定使用CPU运算,确保在没有GPU的环境下仍可运行,同时通过torch框架的硬件适配能力保持跨平台兼容性。预测阶段调用YOLOv8的predict方法,配置保存检测结果图像至静态资源目录,保留可视化标注结果供后续调用。结果解析模块遍历检测框数据,提取每个目标的边界框坐标(xyxy格式)、置信度及类别名称,其中类别名称与训练模型时定义的鱼类标签对应,直接反映识别出的具体鱼种。为增强前端展示体验,系统将标注后的预测图像转换为Base64编码格式内嵌于JSON响应中,避免额外存储和图片URL管理,同时自动清理临时文件与预测结果图像以释放存储空间。异常处理机制全面覆盖文件缺失、预测失败、参数错误等场景,通过try-except块捕获异常并返回标准化错误码与描述信息,保障服务健壮性。技术实现上,采用@csrf_exempt装饰器豁免CSRF验证以适应API调用场景,结合Django文件存储API实现高效安全的文件流处理,利用base64模块实现二进制图像数据与文本格式的无损转换。性能优化方面,模型初始化置于全局作用域避免重复加载,静态资源目录动态创建提升部署灵活性,且通过查询参数过滤机制为后续扩展多模型切换预留接口。具体如下图5-8所示:
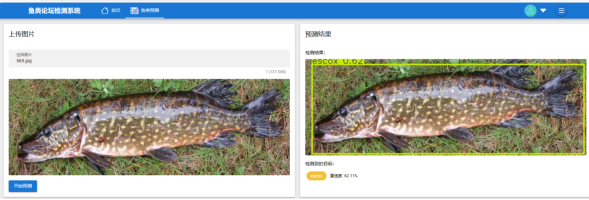
图5-8 鱼类预测功能
具体代码如下图所示:

图5-9 预测功能代码
5-7 管理员模块
管理员需要在指定的路由进行登录,登录成功后,即可跳转至管理员界面,采用Django内置的AdminSite模块构建,提供标准化的账号密码输入表单及CSRF安全校验机制[25]。管理员输入凭据后,系统通过django.contrib.auth认证框架验证用户身份,核验账号是否为is_staff或is_superuser权限标记的超级用户。登录成功后,Django自动创建加密会话Cookie,[22]并重定向至管理员控制台主界面。该界面以模块化面板呈现数据库模型的CRUD操作入口,支持数据表增删改查、批量操作及历史版本追溯,同时集成细粒度权限管理功能,可针对不同管理员角色分配模型级别的操作权限(如仅查看、禁止删除)。系统默认启用登录尝试次数限制(通过AXES中间件或自定义逻辑),防范暴力破解攻击,并可通过扩展添加二次验证提升安全性。管理员还可通过侧边栏快速访问操作日志、实时系统监控及用户行为审计模块,实现对平台的全方位管控。整个过程遵循Django的安全最佳实践,确保会话数据加密传输、敏感操作日志记录及权限分层管控。具体如下图5-10所示:
图5-10 管理员模块
5.8 管理员文章管理
在管理员模块,管理员可以对文章进行管理,支持按文章状态、分类标签、作者及发布时间等条件快速检索目标内容。管理员可在线编辑富文本内容,实时预览排版效果,并批量执行发布、撤回、置顶或删除等操作。针对敏感内容,系统内置预审机制,支持添加审核批注并触发邮件通知作者修改。版本控制功能(如django-reversion插件)自动保存历史修改记录,允许回溯至任意版本或对比差异。数据看板实时统计文章阅读量、评论互动及分享数据,辅助运营决策。权限体系细分为全局管理(超级用户)和栏目主管(基于django-guardian),限制特定管理员仅能操作授权分类下的文章。扩展功能包含定时发布(Celery异步任务调度)、自动生成SEO关键词(NLP集成)以及违规内容AI检测(对接敏感词库或图像识别模型),形成高效安全的文章治理体系。所有操作均记录审计日志,确保可追溯性。具体如下图5-11所示:
图5-11 管理员对文章进行管理
同时管理员还可以对评论,文章标签,文章种类,用户进行管理。针对评论管理,系统提供多级审核机制:管理员可实时监控最新评论,通过关键词过滤(集成AC自动机算法)自动标记含敏感内容的条目,支持批量删除、隐藏或标记为精选评论。高级功能包括查看评论者IP归属地、关联文章上下文预览及用户历史行为分析,辅助判断恶意刷评行为。对于争议性内容,管理员可触发“争议锁定”状态,暂停显示并通知作者申诉。评论数据面板统计每日互动量、热词图谱及用户参与度排名,为社区运营提供量化依据。
文章标签管理模块支持动态标签体系的构建,管理员可合并语义重复的标签,批量清理低频僵尸标签,并设置黑名单过滤无效或违规标签。标签与文章的关联关系采用中间表维护,允许手动调整权重值以影响内容推荐排序。可视化标签云支持按热度、创建时间或字母顺序多维排序,并允许导出为CSV进行外部分析。权限层面通过RBAC模型限制普通管理员仅能编辑自有标签,而超级管理员拥有全局操作权限。
文章分类管理采用树形结构设计,支持无限级分类嵌套(借助django-mptt插件),管理员可拖拽调整分类层级、设置封面图及SEO元信息。分类与模板引擎联动,允许为不同分类指定专属展示样式(如技术类启用代码高亮,图片类启用瀑布流布局)。敏感分类(如政治、宗教)可开启“预发布审核”模式,确保内容合规性。分类删除操作采用软删除机制,保留历史关联数据供恢复或迁移,避免级联数据丢失风险。
用户管理系统集成身份核验与行为管控,管理员可查看用户设备指纹(浏览器/OS/地理位置)、登录历史及操作日志。账户分级体系将用户划分为普通用户、内容创作者、版主及管理员,通过django-guardian实现细粒度权限分配(如限制版主只能管理特定板块)。风险控制模块自动检测异常行为(如短时间内大量删除操作),触发二次认证或临时封禁。用户内容贡献看板统计发文量、获赞数及违规记录,支持一键生成用户行为报告。此外,开放OAuth2.0接口允许与企业AD域或第三方社交账号体系对接,实现统一身份管理。
所有管理操作均通过双层审计机制保障安全性:前端界面强制启用操作二次确认(如删除弹窗),后端采用Command模式记录完整操作轨迹(操作者、时间、变更前/后数据快照)。系统支持与SIEM(安全信息与事件管理)[21]平台集成,实时推送高风险事件告警(如超级管理员密码修改),形成闭环管控体系。通过组合式权限策略与自动化治理工具,构建起兼顾效率与安全的立体化管理矩阵。具体如下图所示:
图5-12 文章种类管理
图5-13 文章标签管理
图5-14 文章评论管理
图5-15 用户管理
6 测试与部署
6.1系统测试
系统测试是本系统开发过程一个非常重要的步骤。通过系统测试,可以保证整个系统能够满足用户的需求和期望。在测试过程中,需要对系统的各项功能进行测试,包括系统的稳定性、可靠性、安全性等方面。
为了更好地进行系统测试,本项目主要采用黑盒测试。
6.1.1 硬件要求
(1)前端硬件要求:可以正常打开浏览器
(2)后端硬件要求:服务器:支持python的相应服务器硬件,并且支持大规模的请求。
(3)存储:可以存储相应的用户信息,文章信息等数据。
(4)数据库服务器硬件要求:适用于MySQL数据库的服务器硬件配置,可以正常执行sql语句。
6.1.2 软件要求
(1)前端软件要求:可以打开常用的浏览器,比如Chrome、Firefox、Edge等,确保能够良好地支持HTML5、Vue。
(2)后端软件要求:Python运行环境:python3.9版本,可以运行Django框架。
(3)数据库服务器软件要求:MySQL 8版本,可以通过navicat打开,并且执行sql语句。
(4)通信服务软件要求:使用Axios进行前后端的数据交互问题。
(5)开发和构建工具软件要求:Pycharm作为主要的集成开发环境。Pip用于项目的相关包的获取。
6.1.3 系统要求
(1)可靠性需求:系统需满足用户对故障发生频率、影响程度、容错恢复能力及失效预警机制等方面的质量要求,具体包括对异常状况的监测精度、故障平均间隔时间(MTBF)、平均修复时间(MTTR)等量化指标的规定。
(2)易用性需求:在用户交互层面应实现符合人体工程学的操作流程设计,界面须遵循国际通行的UX设计规范,提供多级帮助系统(含上下文敏感提示),同时配备体系化的用户手册、在线知识库及交互式培训模拟环境。
(3)运行环境约束:系统需明确支持的操作系统版本(含补丁级别)、最低硬件配置要求(包括但不限于CPU架构、内存容量、存储介质类型)、网络拓扑结构适配性以及特定运行时依赖(如Java虚拟机版本、.NET Framework组件等)。
(4)外部接口规范:需定义标准化的API接口协议(如RESTful/WebService)、数据交换格式(JSON/XML Schema)、硬件驱动兼容列表(含设备型号及固件版本),并制定异常中断处理机制和接口性能基准(吞吐量/延迟指标)。
6.1.4 系统部署过程
项目部署是一个很重要的环节,以下是系统的一般方法和步骤:
- 准备环境:确保服务器硬件满足系统要求,安装操作系统和相关依赖。
- 包安装:通过pip进行相关包的安装,同时采用清华园镜像进行快速安装。
6.2 相关模块测试
6.2.1 用户注册模块测试
通过黑盒测试对用户注册模块进行了测试,如表6-1所示。
表6-1模块测试用例
|
项目名称 |
基于YOLOv8的鱼类目标检测系统 |
||||
|
测试方法 |
黑盒测试 |
测试日期 |
2024-12-01 |
||
|
用例描述 |
用户注册测模块测试 |
||||
|
前置条件 |
正常注册到系统 |
||||
|
环境需求 |
服务器OS= Windows 11 WEBServer=Django 客户端OS=Windows 11 Browser= Edge |
||||
|
序号 |
测试项 |
输入及操作说明 |
期望的测试结果 |
||
|
001 |
用户注册 |
在注册页面进行用户注册 |
数据成功存储在数据库中 |
||
6.2.2 用户登录模块测试
通过黑盒测试对用户登录模块进行了测试,如表6-2所示。
表6-2模块测试用例
|
项目名称 |
基于YOLOv8的鱼类目标检测系统 |
||||
|
测试方法 |
黑盒测试 |
测试日期 |
2024-12-01 |
||
|
用例描述 |
用户登录模块测试 |
||||
|
前置条件 |
正常登录到系统 |
||||
|
环境需求 |
服务器OS= Windows 11 WEBServer=Django 客户端OS=Windows 11 Browser= Edge |
||||
|
序号 |
测试项 |
输入及操作说明 |
期望的测试结果 |
||
|
001 |
用户登录 |
在登录界面登录系统 |
成功进入系统界面 |
||
6.2.3 文章模块测试
通过黑盒测试对文章模块进行了测试,如表6-3所示。
表6-3模块测试用例
|
项目名称 |
基于YOLOv8的鱼类目标检测系统 |
||||
|
测试方法 |
黑盒测试 |
测试日期 |
2022-12-01 |
||
|
用例描述 |
文章模块黑盒测试 |
||||
|
前置条件 |
正常登录到系统 |
||||
|
环境需求 |
服务器OS= Windows 11 WEBServer=Django 客户端OS=Windows 11 Browser= Edge |
||||
|
序号 |
测试项 |
输入及操作说明 |
期望的测试结果 |
||
|
001 |
订单 |
通过主页面进行查看文章 |
文章出现 |
||
6.2.4 用户预测模块测试
通过黑盒测试对用户预测模块进行了测试,如表6-4所示。
表6-4模块测试用例
|
项目名称 |
基于YOLOv8的鱼类目标检测系统 |
||||
|
测试方法 |
黑盒测试 |
测试日期 |
2024-12-01 |
||
|
用例描述 |
用户预测模块黑盒测试 |
||||
|
前置条件 |
正常登录到系统 |
||||
|
环境需求 |
服务器OS= Windows 11 WEBServer=Django 客户端OS=Windows 11 Browser= Edge |
||||
|
序号 |
测试项 |
输入及操作说明 |
期望的测试结果 |
||
|
001 |
用户收藏 |
上传图片进行预测 |
预测成功 |
||
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)