
【大语言模型 26】混合精度训练:FP16、BF16、FP8深度对比
本文深入探讨了大语言模型训练中的混合精度技术,详细对比了FP16、BF16和FP8三种低精度格式的数值特性、优缺点及适用场景。通过分析不同精度格式的位宽分配、数值范围和表示能力,揭示了它们在训练稳定性和计算效率之间的权衡。文章还介绍了Loss Scaling、梯度溢出检测等关键技术,以及如何根据模型规模和硬件平台选择最佳精度策略,帮助读者全面掌握混合精度训练的核心技术和实践经验。
【大语言模型 26】混合精度训练:FP16、BF16、FP8深度对比
关键词:混合精度训练、FP16、BF16、FP8、Loss Scaling、梯度溢出、数值稳定性、大模型训练、计算加速、内存优化
摘要:本文深入探讨了大语言模型训练中的混合精度技术,详细对比了FP16、BF16和FP8三种低精度格式的数值特性、优缺点及适用场景。通过分析不同精度格式的位宽分配、数值范围和表示能力,揭示了它们在训练稳定性和计算效率之间的权衡。文章还介绍了Loss Scaling、梯度溢出检测等关键技术,以及如何根据模型规模和硬件平台选择最佳精度策略,帮助读者全面掌握混合精度训练的核心技术和实践经验。
文章目录
1. 引言:为什么需要混合精度训练?
在大语言模型(LLM)的发展历程中,模型规模从最初的百万参数量级迅速增长到如今的数千亿甚至万亿参数。以GPT-4为例,其参数量据估计已超过1.7万亿。然而,如此庞大的模型规模带来了两个关键挑战:
- 计算资源需求:训练大模型需要海量的计算资源,使用传统的FP32(单精度浮点)格式进行全部计算会导致训练时间过长,成本高昂。
- 内存限制:大模型的参数、激活值和梯度都需要存储在GPU内存中,而高精度格式会占用更多内存空间,限制了可训练的最大模型规模。
混合精度训练应运而生,它巧妙地结合了低精度(如FP16、BF16或FP8)和高精度(FP32)计算,在保持模型精度的同时,显著提升训练效率和降低内存占用。
2. 浮点数精度格式深度解析
2.1 FP32(单精度):传统标准
FP32是深度学习中的传统标准格式,由1位符号位、8位指数位和23位尾数位组成,总共32位(4字节)。它具有以下特性:
- 数值范围:约±1.18×10-38到±3.4×1038
- 精度:约7位十进制数字精度
- 优势:数值表示精确,训练稳定性好
- 劣势:计算速度较慢,内存占用大
在IEEE 754标准中,FP32的表示公式为:
( − 1 ) s i g n × 2 e x p o n e n t − 127 × ( 1 + m a n t i s s a ) (-1)^{sign} \times 2^{exponent-127} \times (1 + mantissa) (−1)sign×2exponent−127×(1+mantissa)
其中,mantissa是一个0到1之间的小数,通过23位二进制表示。
2.2 FP16(半精度):计算加速的先驱
FP16由1位符号位、5位指数位和10位尾数位组成,总共16位(2字节)。其特性包括:
- 数值范围:约±6.0×10^-8到±65504
- 精度:约3-4位十进制数字精度
- 优势:计算速度快(理论上比FP32快2-8倍),内存占用减半
- 劣势:数值范围小,容易发生梯度下溢和溢出
FP16的主要问题在于其有限的动态范围,特别是在表示非常小的梯度值时容易发生下溢(变为零),导致训练不稳定。
2.3 BF16(脑浮点):谷歌的创新格式
BF16(Brain Floating Point)是由谷歌专为深度学习设计的16位格式,它保留了FP32的8位指数位,但将尾数位减少到7位,总共16位(2字节)。其特性包括:
- 数值范围:与FP32相同,约±1.18×10-38到±3.4×1038
- 精度:约2-3位十进制数字精度
- 优势:保持了FP32的数值范围,不易发生梯度溢出,内存占用减半
- 劣势:精度低于FP16,在某些需要高精度的场景可能不适用
BF16的独特之处在于它牺牲了一些精度来换取与FP32相同的数值范围,这使得它在深度学习训练中特别有用,因为梯度值通常分布在很广的范围内。
2.4 FP8(八分精度):新兴的超低精度格式
FP8是最新兴起的超低精度格式,根据不同实现,可以有不同的位宽分配方案,如E4M3(4位指数,3位尾数)和E5M2(5位指数,2位尾数)。其特性包括:
- 数值范围:E4M3约±1.8×10-9到±57344,E5M2约±5.9×10-20到±57344
- 精度:约1-2位十进制数字精度
- 优势:计算速度极快,内存占用极小(比FP16再减少一半)
- 劣势:精度极低,需要特殊技术保证训练稳定性
FP8主要用于前向和反向传播中的矩阵乘法运算,而权重更新和累加通常仍使用更高精度格式。
3. 混合精度训练核心技术
3.1 混合精度训练工作流程
混合精度训练不是简单地将所有计算都转换为低精度,而是策略性地在不同计算阶段使用不同精度:
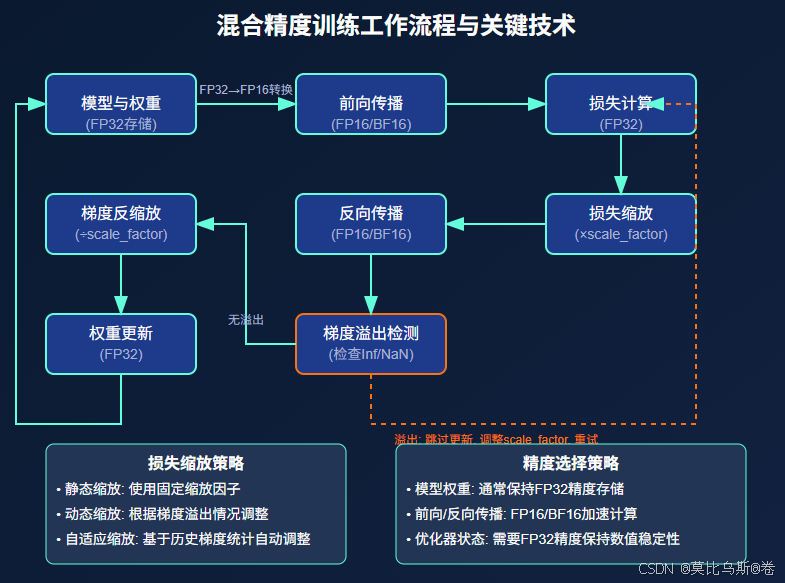
- 模型参数存储:通常使用FP32格式存储主权重副本
- 前向传播:使用低精度格式(FP16/BF16/FP8)进行计算
- 损失计算:使用FP32确保精度
- 反向传播:使用低精度格式计算梯度
- 梯度累加和权重更新:转换回FP32进行精确更新
3.2 Loss Scaling:解决梯度下溢问题
Loss Scaling是混合精度训练中的关键技术,特别是对于FP16格式。它的工作原理是:
- 放大损失值:在反向传播前,将损失值乘以一个缩放因子(如2^16)
- 反向传播:由于损失被放大,计算得到的梯度也相应放大,避免了小梯度下溢为零
- 梯度缩放:在更新权重前,将梯度除以相同的缩放因子,恢复其原始大小
动态Loss Scaling进一步优化了这一过程,它会根据梯度溢出情况自动调整缩放因子:
# 动态Loss Scaling伪代码示例
scale = 2**16 # 初始缩放因子
backoff_factor = 0.5 # 缩小因子
growth_factor = 2.0 # 放大因子
growth_interval = 2000 # 增长间隔
consecutive_successful_steps = 0 # 连续成功步数
def training_step(model, inputs, optimizer):
global scale, consecutive_successful_steps
# 前向传播(FP16/BF16)
outputs = model(inputs)
loss = loss_fn(outputs, targets)
# 应用Loss Scaling
scaled_loss = loss * scale
# 反向传播(FP16/BF16)
scaled_loss.backward()
# 检查梯度是否包含Inf或NaN
overflow = check_overflow(model.parameters())
if overflow:
# 梯度溢出,跳过更新,减小缩放因子
optimizer.zero_grad()
scale = scale * backoff_factor
consecutive_successful_steps = 0
print(f"梯度溢出,缩放因子调整为: {scale}")
else:
# 梯度正常,除以缩放因子并更新权重
for param in model.parameters():
if param.grad is not None:
param.grad.data = param.grad.data / scale
optimizer.step()
optimizer.zero_grad()
# 考虑增加缩放因子
consecutive_successful_steps += 1
if consecutive_successful_steps >= growth_interval:
scale = scale * growth_factor
consecutive_successful_steps = 0
print(f"连续{growth_interval}步无溢出,缩放因子增加到: {scale}")
3.3 梯度溢出检测与处理
梯度溢出是混合精度训练中的常见问题,特别是在使用FP16格式时。有效的检测和处理策略包括:
- 检测机制:在权重更新前检查梯度是否包含Inf或NaN值
- 跳过更新:发现溢出时,跳过当前批次的权重更新
- 调整缩放因子:降低Loss Scaling因子,减少未来溢出的可能性
- 梯度裁剪:限制梯度范数,防止梯度爆炸
3.4 精度格式转换与计算优化
在混合精度训练中,不同操作之间需要进行精度转换,这些转换需要高效实现:
# PyTorch中的精度转换示例
def forward_pass(model, inputs):
# 将输入转换为低精度
inputs = inputs.to(torch.float16) # 或 torch.bfloat16
# 前向传播
with torch.cuda.amp.autocast():
outputs = model(inputs)
# 将输出转回FP32进行损失计算
outputs = outputs.float()
loss = loss_fn(outputs, targets)
return loss
此外,现代GPU提供了专门的硬件加速单元(如NVIDIA的Tensor Cores)来加速低精度矩阵运算,合理利用这些硬件特性可以进一步提升训练效率。
4. 三种低精度格式的性能对比
4.1 计算性能与内存效率
不同精度格式在计算性能和内存效率方面的对比:
| 精度格式 | 相对计算速度 | 内存占用 | 支持硬件 |
|---|---|---|---|
| FP32 | 1x | 4字节/参数 | 所有GPU |
| FP16 | 2-8x | 2字节/参数 | Volta及以上架构 |
| BF16 | 2-8x | 2字节/参数 | Ampere及以上架构,TPU |
| FP8 | 4-16x | 1字节/参数 | Hopper架构,最新TPU |
4.2 训练稳定性与收敛性
不同精度格式对训练稳定性和模型收敛的影响:
- FP16:需要Loss Scaling,对超参数敏感,在某些任务上可能难以收敛
- BF16:通常不需要Loss Scaling,训练稳定性接近FP32,适用于大多数模型
- FP8:需要特殊的量化感知训练技术,仍处于研究阶段
4.3 适用场景分析
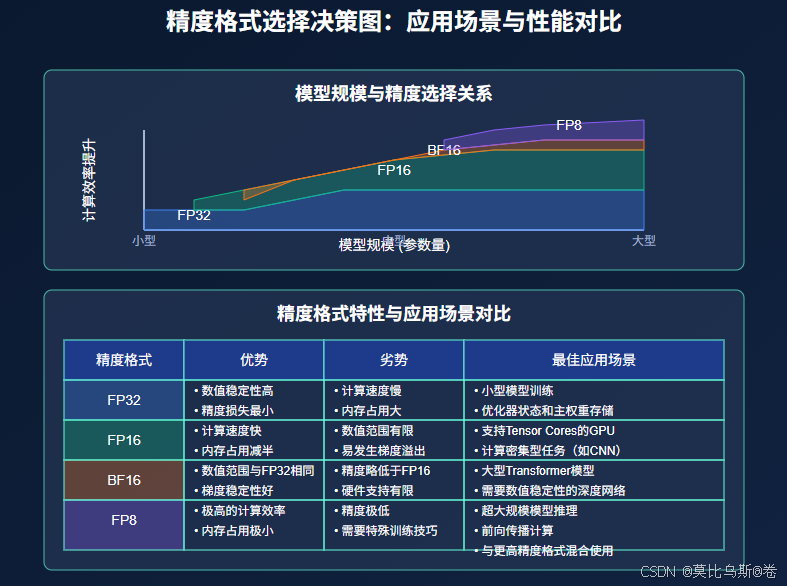
根据模型规模和任务特性,不同精度格式的最佳应用场景:
- FP32:小型模型,或对数值精度极其敏感的任务
- FP16:中小型模型,特别是在较老的GPU上(如Volta、Turing架构)
- BF16:大型语言模型的首选格式,特别是在支持BF16的硬件上(如A100、H100、TPU)
- FP8:超大型模型(万亿参数级别),需要极致的性能优化,但要求最新硬件支持
5. 实战案例:不同框架中的混合精度实现
5.1 PyTorch中的混合精度训练
PyTorch提供了torch.cuda.amp模块,使混合精度训练变得简单:
# PyTorch混合精度训练示例
import torch
from torch.cuda.amp import autocast, GradScaler
# 创建模型和优化器
model = MyModel().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 创建梯度缩放器
scaler = GradScaler()
for epoch in range(num_epochs):
for batch in dataloader:
inputs, targets = batch
inputs = inputs.cuda()
targets = targets.cuda()
# 自动混合精度前向传播
with autocast():
outputs = model(inputs)
loss = loss_fn(outputs, targets)
# 缩放损失并执行反向传播
scaler.scale(loss).backward()
# 缩放优化器步骤
scaler.step(optimizer)
# 更新缩放因子
scaler.update()
optimizer.zero_grad()
5.2 TensorFlow中的混合精度训练
TensorFlow通过mixed_precision策略支持混合精度:
# TensorFlow混合精度训练示例
import tensorflow as tf
# 启用混合精度
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
# 创建模型
model = tf.keras.Sequential([...])
# 编译模型(注意:输出层通常保持float32精度)
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 训练(自动应用混合精度)
model.fit(train_dataset, epochs=num_epochs)
5.3 大模型训练框架中的精度设置
DeepSpeed和Megatron-LM等大模型训练框架提供了更灵活的精度控制:
# DeepSpeed配置示例
ds_config = {
"fp16": {
"enabled": True,
"loss_scale": 0, # 动态Loss Scaling
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
# 或者使用BF16
"bf16": {
"enabled": True
},
# 其他配置...
}
# 初始化DeepSpeed引擎
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
optimizer=optimizer,
config=ds_config
)
6. 混合精度训练的最佳实践
6.1 精度格式选择策略
选择合适的精度格式需要考虑多个因素:
- 硬件支持:确认你的GPU/TPU支持哪些低精度格式
- 模型规模:更大的模型通常从BF16中受益更多
- 任务特性:某些任务(如语言建模)对精度不太敏感,而其他任务(如某些科学计算)可能需要更高精度
- 训练稳定性:如果FP16训练不稳定,考虑切换到BF16
6.2 超参数调整建议
混合精度训练可能需要调整一些超参数:
- 学习率:低精度格式可能需要略小的学习率
- 梯度裁剪:设置合理的梯度裁剪阈值,防止梯度爆炸
- Loss Scaling初始值:FP16通常从2^16开始,根据溢出情况调整
- 权重衰减:可能需要调整权重衰减值以适应低精度训练
6.3 数值稳定性优化技巧
提高混合精度训练稳定性的技巧:
- LayerNorm和Softmax保持FP32:这些操作对数值精度敏感
- 累加器使用更高精度:梯度累加使用FP32可以提高稳定性
- 避免极小值:在模型设计中避免产生极小的中间值
- 监控梯度范数:定期检查梯度范数,及时发现异常
# 数值稳定性优化示例
class StableSoftmax(nn.Module):
def forward(self, x):
# 将输入转为FP32进行计算
x_float = x.float()
result = F.softmax(x_float, dim=-1)
# 返回原始精度
return result.to(x.dtype)
class StableLayerNorm(nn.LayerNorm):
def forward(self, x):
# 将输入转为FP32进行计算
x_float = x.float()
result = super().forward(x_float)
# 返回原始精度
return result.to(x.dtype)
7. 未来趋势与研究方向
7.1 FP8训练的发展前景
FP8作为最新的低精度格式,正在快速发展:
- 硬件支持扩展:更多GPU架构将支持FP8计算
- 训练算法改进:新的量化感知训练方法将提高FP8训练稳定性
- 混合FP8格式:针对不同操作使用不同的FP8格式(E4M3用于前向,E5M2用于反向)
7.2 精度自适应训练技术
未来的研究方向包括:
- 自动精度选择:根据操作特性自动选择最合适的精度格式
- 层级精度控制:不同网络层使用不同精度格式
- 动态精度调整:训练过程中根据梯度特性动态调整精度
7.3 超低位训练与量化技术融合
混合精度训练与量化技术的结合将带来更多可能:
- 训练中量化:在训练过程中应用量化技术
- INT4/INT2训练:探索使用整数格式进行训练
- 稀疏性与低精度结合:结合参数稀疏化和低精度训练
8. 总结与实践建议
混合精度训练已成为大语言模型训练的标准技术,它通过巧妙地结合不同精度格式,在保持模型性能的同时显著提升训练效率。本文详细对比了FP16、BF16和FP8三种低精度格式的特性和适用场景,并介绍了Loss Scaling等关键技术。
对于实践者,我们建议:
- 从BF16开始:如果硬件支持,BF16通常是最佳的起点,它结合了良好的训练稳定性和计算效率
- 监控训练过程:密切关注损失曲线和梯度统计信息,及时发现数值问题
- 渐进式尝试:先在小规模实验中验证混合精度策略,再应用到大规模训练
- 硬件选择:在预算允许的情况下,选择支持更多低精度格式的现代GPU/TPU
随着硬件和算法的不断进步,混合精度训练技术将继续发展,为更大规模、更高效率的大语言模型训练提供支持。
参考资料
- NVIDIA. (2018). Training With Mixed Precision. https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/
- Micikevicius, P., et al. (2018). Mixed Precision Training. ICLR 2018.
- Google. (2020). BFLOAT16: The secret to high performance on Cloud TPUs. https://cloud.google.com/blog/products/ai-machine-learning/bfloat16-the-secret-to-high-performance-on-cloud-tpus
- NVIDIA. (2022). FP8 Formats for Deep Learning. https://developer.nvidia.com/blog/fp8-formats-for-deep-learning/
- Dettmers, T., et al. (2022). 8-bit Optimizers via Block-wise Quantization. ICLR 2022.
- PyTorch. (2023). Automatic Mixed Precision Package - torch.cuda.amp. https://pytorch.org/docs/stable/amp.html
- TensorFlow. (2023). Mixed precision. https://www.tensorflow.org/guide/mixed_precision
22). FP8 Formats for Deep Learning. https://developer.nvidia.com/blog/fp8-formats-for-deep-learning/ - Dettmers, T., et al. (2022). 8-bit Optimizers via Block-wise Quantization. ICLR 2022.
- PyTorch. (2023). Automatic Mixed Precision Package - torch.cuda.amp. https://pytorch.org/docs/stable/amp.html
- TensorFlow. (2023). Mixed precision. https://www.tensorflow.org/guide/mixed_precision
- DeepSpeed. (2023). DeepSpeed Configuration. https://www.deepspeed.ai/docs/config-json/
更多推荐
 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)