
深度学习-MNIST手写数字识别(MLP)
我是一名刚开始学习深度学习的小白,可能是我不会找资源吧(官方是有一些示例的,但都学我没那么多时间),也没找到什么可以跟练的项目。下面是我学习到的内容(来自up主DT算法工程师前钰,好多人搬视频,认准正版),做一个分享。如果大家有什么学习建议,十分乐意倾听您的指教@~@torchvision.datasets里面包含了一些常用的图像数据集(比如 MNIST 手写数字数据集),直接调用即可下载使用。
前言:我是一名刚开始学习深度学习的小白,可能是我不会找资源吧(官方是有一些示例的,但都学我没那么多时间),也没找到什么可以跟练的项目。下面是我学习到的内容(来自up主DT算法工程师前钰,好多人搬视频,认准正版),做一个分享。如果大家有什么学习建议,十分乐意倾听您的指教@~@
torchvision.datasets里面包含了一些常用的图像数据集(比如 MNIST 手写数字数据集),直接调用即可下载使用。所以我选择复现里面的MNIST手写数字识别项目(属于图像分类)做个小的入门吧,没有卷积层,是一个纯全连接神经网络,属于深度学习中的 “多层感知机(MLP)” 范畴。
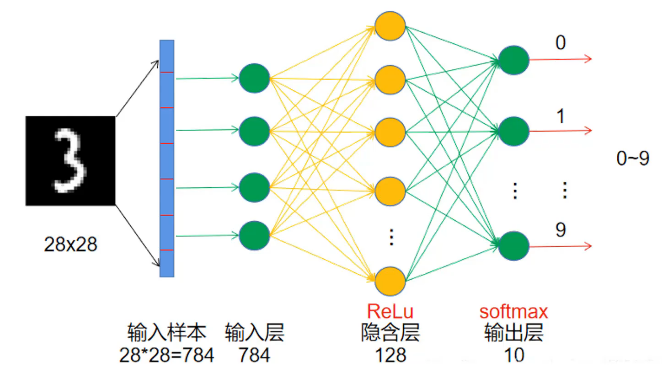
神经网络算法
输入层是展平的神经元,前向传播,通过线性变换,相加求和得到隐藏层。再通过ReLu增加非线性,隐藏层神经元可自定义,层数也自定义。输出层通过softmax计算概率,再与真实值比较,计算损失Loss,再反向传播,计算梯度,跟新线性变换的参数。
数据处理及加载
train.py文件
from torchvision import datasets,transforms # torchvision.datasets包含常用的图像数据集(比如MNIST手写数字数据集);torchvision.transforms包含图像预处理工具,比如缩放、转张量、归一化等
from torch.utils.data import DataLoader # 批量加载数据的工具
import matplotlib.pyplot as plt # 可视化绘图工具
transform = transforms.Compose([ # 图像预处理的组合操作
transforms.Grayscale(num_output_channels=1), # 转为灰度图,通道数为1
transforms.ToTensor(), # 将图像转换为张量,像素值变为0-1(原始图像像素值为0-255)
transforms.Normalize([0.5], [0.5]) # 归一化,标准化到[-1, 1],公式:(x - 均值) / 标准差,前一个[0.5] 是均值,后一个[0.5] 是标准差
])
# 加载MNIST数据集
train_dataset = datasets.MNIST( # 加载MNIST训练数据集
root='./data', # 数据集存放路径
train=True, # 加载训练集
transform=transform, # 应用预处理操作
download=True # 如果数据集不存在则下载
)
# 加载MNIST测试数据集
test_dataset = datasets.MNIST( # 加载MNIST测试数据集
root='./data', # 数据集存放路径
train=False, # 加载测试集
transform=transform # 应用预处理操作
)
# 创建数据加载器
train_loader = DataLoader( # 创建训练数据加载器
dataset=train_dataset, # 传入训练数据集
batch_size=64, # 每个批次64张图像
shuffle=True # 每个epoch打乱数据(epoch指数据集被完整遍历一次的过程)
)
# 创建测试数据加载器
test_loader = DataLoader( # 创建测试数据加载器
dataset=test_dataset, # 传入测试数据集
batch_size=64, # 每个批次64张图像
shuffle=False # 不打乱数据
)
# 获取一张训练集的图像和对应的标签
image,label = train_dataset[0]
# 可视化图像
plt.imshow(image.squeeze(),cmap='gray') # 灰度图是(1,H,W),用squeeze()去掉多余的通道维度,cmap='gray'指定为灰度图
plt.title(f'Label: {label}') # 设置图像标题为标签
plt.axis('off') # 关闭坐标轴显示
plt.show() # 显示图像模型构建
新建一个model.py文件
import torch # PyTorch深度学习框架核心库
import torch.nn as nn # PyTorch的神经网络模块
# 自定义神经网络模型
class SimpleNN(nn.Module): # 自定义模型继承自nn.Module(PyTorch所有模型的基类)
def __init__(self): # 初始化函数,定义网络层
super().__init__() # 继承父类的初始化
# 定义全连接层(也叫线性层,nn.Linear),是最基础的神经网络层,作用是对输入数据做线性变换(类似 y = wx + b,w 是权重,b 是偏置)
self.fc1 = nn.Linear(28*28, 256) # 全连接层1,输入大小为28*28,输出大小为256( MNIST数据集的图片是28x28像素的灰度图,展平后就是一个长度为28*28的一维向量)
self.fc2 = nn.Linear(256, 128) # 全连接层2,输入大小为256,输出大小为128(输入必须和上一层输出一致)
self.fc3 = nn.Linear(128, 64) # 全连接层3,输入大小为128,输出大小为64 (中间层的256、128等是隐藏层的神经元熟练,是认为设定的,通过多层变换,学习到更复杂的特征)
self.fc4 = nn.Linear(64, 10) # 全连接层4,输入大小为64,输出大小为10(对应10个类别)
def forward(self, x): # 前向传播函数,定义输入数据x如何流过网络
x = torch.flatten(x,start_dim=1) # 展平输入,维度start_dim=1表示从第1维开始展平,保持第0维(批次大小)不变,输入的图片格式是 (批量大小, 通道数, 高度, 宽度)
x = torch.relu(self.fc1(x)) # 通过全连接层1,再应用ReLU激活函数(把负数变成 0,正数不变,给网络增加 “非线性”,让它能学习更复杂的规律)
x = torch.relu(self.fc2(x)) # 通过全连接层2,再应用ReLU激活函数
x = torch.relu(self.fc3(x)) # 通过全连接层3,再应用ReLU激活函数
x = self.fc4(x) # 通过全连接层4(输出10个数字,不需要激活函数,后续计算损失时内部包含了softmax操作,进行概率计算)
return x模型训练
train.py文件(从第38行开始)
from torchvision import datasets,transforms # torchvision.datasets包含常用的图像数据集(比如MNIST手写数字数据集);torchvision.transforms是图像预处理工具,比如缩放、转张量、归一化等
from torch.utils.data import DataLoader # 批量加载数据的工具
import matplotlib.pyplot as plt # 可视化绘图工具
from models import SimpleNN # 导入自定义的神经网络模型
import torch
transform = transforms.Compose([ # 图像预处理的组合操作
transforms.Grayscale(num_output_channels=1), # 转为灰度图,通道数为1
transforms.ToTensor(), # 将图像转换为张量,像素值变为0-1(原始图像像素值为0-255)
transforms.Normalize([0.5], [0.5]) # 归一化,标准化到[-1, 1],公式:(x - 均值) / 标准差,前一个[0.5] 是均值,后一个[0.5] 是标准差
])
# 加载MNIST数据集
train_dataset = datasets.MNIST( # 加载MNIST训练数据集
root='./data', # 数据集存放路径
train=True, # 加载训练集
transform=transform, # 应用预处理操作
download=True # 如果数据集不存在则下载
)
# 加载MNIST测试数据集
test_dataset = datasets.MNIST( # 加载MNIST测试数据集
root='./data', # 数据集存放路径
train=False, # 加载测试集
transform=transform # 应用预处理操作
)
# 创建数据加载器
train_loader = DataLoader( # 创建训练数据加载器
dataset=train_dataset, # 传入训练数据集
batch_size=64, # 每个批次64张图像
shuffle=True # 每个epoch打乱数据(epoch指数据集被完整遍历一次的过程)
)
# 创建测试数据加载器
test_loader = DataLoader( # 创建测试数据加载器
dataset=test_dataset, # 传入测试数据集
batch_size=64, # 每个批次64张图像
shuffle=False # 不打乱数据
)
import torch.nn as nn # PyTorch的神经网络模块
import torch.optim as optim # 优化器模块,包含各种优化算法
from tqdm import tqdm # 进度条显示工具
#检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
#初始化模型
model = SimpleNN().to(device) # 实例化自定义的神经网络模型,并将其移动到指定设备(GPU或CPU)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数(错的越离谱值就越大),常用于多分类任务
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器(根据损失函数的结果,调整模型线性变换里的权重w和偏置b,学习率0.001是调整幅度)
#用于保存训练过程中的损失和准确率
train_losses = []
train_accuracies = []
test_accuracies = []
#训练模型
num_epochs = 10 # 训练轮数
best_accuracy = 0.0 # 用于保存最佳测试准确率
best_model_path = 'best_model.pth' # 保存最佳模型的路径
for epoch in range(num_epochs):
running_loss = 0.0 # 累计本轮的损失
correct_train = 0 # 训练集上正确预测的样本数
total_train = 0 # 训练集上总样本数
model.train() # 设置模型为训练模式
# 用tqdm显示进度条(desc参数设置进度条前缀),遍历训练集中的每一批数据
for images, labels in tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs}'):
images, labels = images.to(device), labels.to(device) # 将数据移动到指定设备
optimizer.zero_grad() # 清零梯度
outputs = model(images) # 前向传播,模型对图片做预测
loss = criterion(outputs, labels)# 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item() # 累计损失
_, predicted = torch.max(outputs, 1) # 获取预测结果(_为最大值,predicted取最大值索引即预测数字),模型输出的二维张量格式是【batch_size,类别维度】,取1代表类别维度(概率)
total_train += labels.size(0) # 累计样本数
correct_train += (predicted == labels).sum().item() # 累计正确预测数
# 计算训练集上的准确率
train_accuracy = correct_train / total_train
train_losses.append(running_loss / len(train_loader)) # 计算并保存本轮的平均损失
train_accuracies.append(train_accuracy)
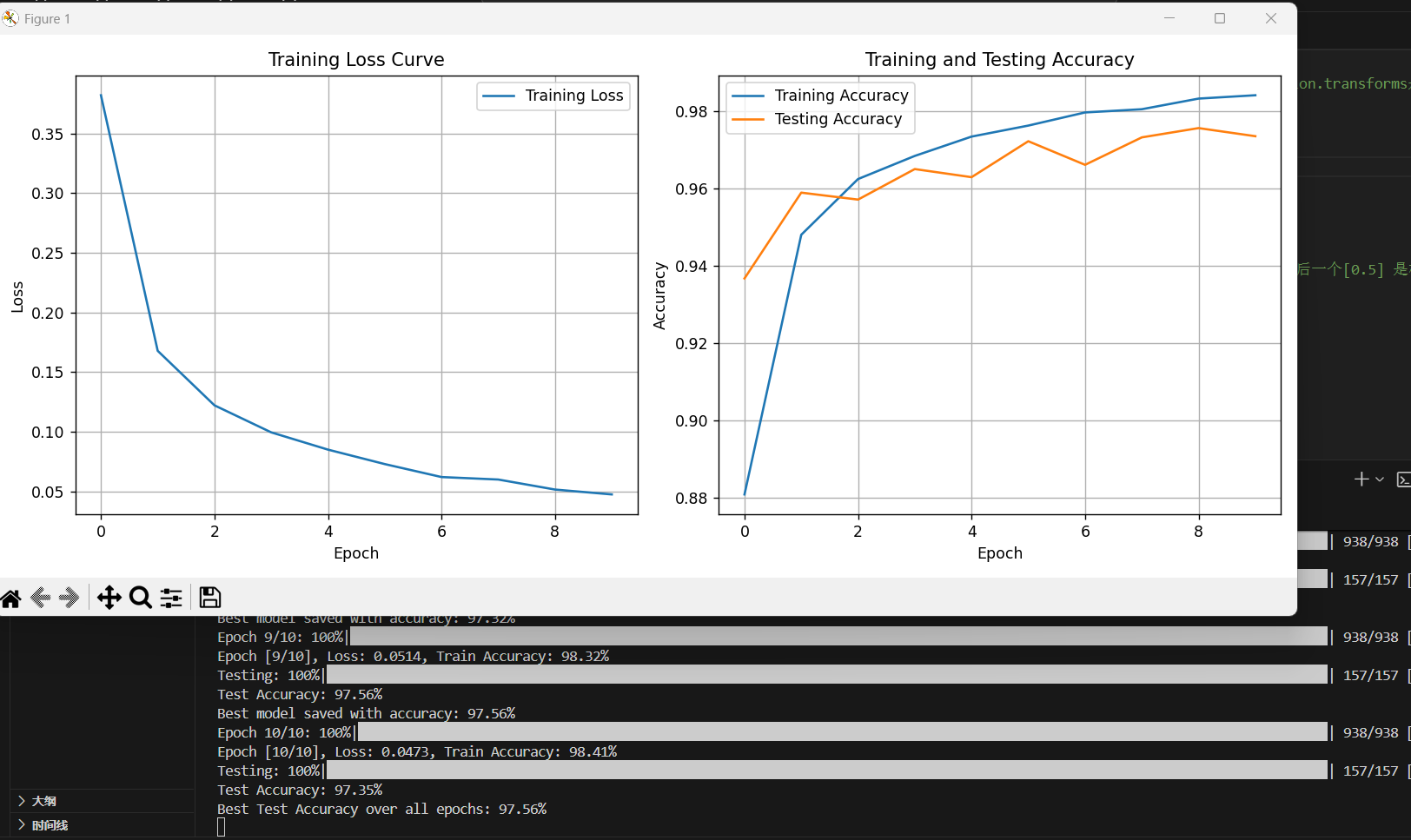
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}, Train Accuracy: {train_accuracy*100:.2f}%')
# 训练完一轮后,在测试集上评估模型
model.eval() # 设置模型为评估模式
correct_test = 0 # 测试集上正确预测的样本数
total_test = 0 # 测试集上总样本数
with torch.no_grad(): # 评估时不计算梯度
for images, labels in tqdm(test_loader, desc='Testing'):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total_test += labels.size(0)
correct_test += (predicted == labels).sum().item()
test_accuracy = correct_test / total_test # 计算测试集上的准确率
test_accuracies.append(test_accuracy)
print(f'Test Accuracy: {test_accuracy*100:.2f}%')
# 保存最佳模型
if test_accuracy > best_accuracy:
best_accuracy = test_accuracy
torch.save(model.state_dict(), best_model_path) # 保存模型参数(权重和偏置)
print(f'Best model saved with accuracy: {best_accuracy*100:.2f}%')
print(f'Best Test Accuracy over all epochs: {best_accuracy*100:.2f}%')
# 绘制损失曲线
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.grid(True)
# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='Training Accuracy')
plt.plot(test_accuracies, label='Testing Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and Testing Accuracy')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig('training_curves.png') # 保存图像到文件
plt.show()训练的轮数更多,Loss还能更少点,准确率还能更高点。
加载模型权重,推理图片
predict.py加载MNIST测试集中的图片进行预测
import cv2 # 用于图像显示和处理
import torch # PyTorch深度学习框架核心库
from torchvision import datasets,transforms # 数据集和图像预处理工具
from torch.utils.data import DataLoader # 批量加载数据的工具
from models import SimpleNN # 导入自定义的神经网络模型
transform = transforms.Compose([ # 图像预处理的组合操作
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# 加载MNIST测试集
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=transform,
download=True
)
# 创建测试集的数据加载器
test_loader = DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=True
)
model = SimpleNN() # 实例化模型结构
model.load_state_dict(torch.load('best_model.pth')) # 加载训练好的模型参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 将模型移动到指定设备(GPU或CPU)
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 关闭梯度计算
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images) # 模型推理:输入图像,输出预测结果
_, predicted = torch.max(outputs.data, 1) # 从输出概率中取最大值对应的索引,_是最大值(概率),predicted是索引(预测结果)
# 遍历当前批次的每张图像,显示预测结果
for i in range(images.size(0)):
# 1. 处理图像格式:从张量转为OpenCV可显示的格式
img = images[i].cpu().numpy().transpose(1, 2, 0) # 从[C, H, W]转为[H, W, C](OpenCV要求的格式)
img = (img * 0.5 + 0.5) * 255 # 反归一化,从[-1,-1]到[0, 255]
img = img.astype('uint8') # 转为整数类型(像素值必须是0-255的整数)
# 2. 显示图像,窗口标题为预测结果
img_resized = cv2.resize(img, (500, 500), interpolation=cv2.INTER_LINEAR) # 放大图像以便观察(Inter_LINEAR双线性插值,避免模糊)
cv2.imshow(f'Predicted: {predicted[i].item()}', img_resized)
# 3. 按任意键显示下一张,按q键直接退出所有窗口
key = cv2.waitKey(0) # 等待按键
if key & 0xFF == ord('q'): # 按q退出
cv2.destroyAllWindows() # 关闭所有窗口
exit() # 退出程序
else:
cv2.destroyWindow(f'Predicted: {predicted[i].item()}') # 关闭当前窗口
cv2.destroyAllWindows() # 处理完一个批次后关闭所有窗口
break # 只处理一个批次以示例展示
predict1.py加载本地图片进行推理,需注意,图片预处理,以及输入图像的特征必须与训练集一致(黑底白字,像素为28*28),myfigure.png我没有调整像素大小,使用强制压缩图片到28*28,推理结果错误,myfigure2.jpg像素大小我手动裁剪过了,预测正确
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image # 用于读取自定义图片(MNIST数据集用datasets自动读,自定义图需手动读)
from models import SimpleNN
import matplotlib.pyplot as plt # 用于显示图片
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
# 定义图像预处理(和训练时保持一致)
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), # 转为单通道灰度图
transforms.Resize((28, 28)), # 调整图像大小为28x28像素(MNIST数据集的标准尺寸)
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# 加载训练好的模型
model = SimpleNN().to(device) # 实例化模型并放入设备
model.load_state_dict(torch.load('best_model.pth', map_location=device)) # 加载模型参数(map_location=device 确保参数加载到指定设备)
model.eval() # 设置模型为评估模式,关闭训练特有的层
# 读取并处理单张图片
img_path = r'./myfigure2.jpg' # 要推理的图片路径
image = Image.open(img_path) # 使用PIL打开图片
image = transform(image).unsqueeze(0).to(device) # 图片预处理+添加批次维度+放入设备(模型中的图片格式为B C H W是一个四维的张量,而图片格式是C H W,Batch size默认为1)
# 进行预测
with torch.no_grad(): # 关闭梯度计算,节省内存和计算
output = model(image) # 将处理后的图片输入模型进行推理
_, predicted = torch.max(output, 1) # 获取预测结果
print(f'Predicted class: {predicted.item()}') # 打印预测的类别
# 展示图片和预测类别
plt.imshow(Image.open(img_path), cmap='gray') # 读取原始图片(用于显示)
plt.title(f'Predicted class: {predicted.item()}') # 给图片加标题,显示预测结果
plt.axis('off') # 关闭坐标轴
plt.show() # 展示图片两个预测代码对比
| 单张自定义图片推理(predict1.py) | 批量预测 MNIST 测试集(predict.py) | |
|---|---|---|
| 处理对象 | 本地自定义图片(如myfigure.png) |
MNIST 数据集自带的测试集(datasets.MNIST(train=False)) |
| 图片读取方式 | 用PIL.Image.open()手动读取 |
用datasets.MNIST自动读取(无需手动处理路径) |
| 数据加载方式 | 单张图手动处理(加批次维度) | 用DataLoader批量加载(自动分批次,batch_size=64) |
| 显示工具 | matplotlib.pyplot(单张图 + 标题,简洁) |
cv2(批量图循环显示,需控制窗口关闭) |
| 核心场景 | 验证自定义图片(如自己写的数字,实际应用场景) | 验证模型在标准测试集上的泛化能力(评估模型性能) |
| 输入格式处理 | 需手动加unsqueeze(0)补批次维度 |
DataLoader自动生成[B, C, H, W]格式批量数据 |
整个项目已上传github,可自行copylin00007/MNIST
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)