
Python基于YOLOv5的智慧交通车型识别 PyQt5可视化界面 深度学习毕业设计(建议收藏)✅
Python基于YOLOv5的智慧交通车型识别 PyQt5可视化界面 深度学习毕业设计(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:Python语言、YOLOv5模型、PyQt5界面、openCV、pytorch框架,支持上传图片、上传视频、摄像头实时检测
研究背景:随着城市汽车保有量持续攀升,传统人工巡查与卡口统计已难以满足智慧交通对实时性、准确率与多目标并发的需求。YOLO系列算法凭借单阶段检测架构,在保持高精度的同时实现毫秒级推理,成为路侧边缘设备与轻量化终端的首选方案。
研究意义:构建一套基于YOLOv5的桌面端车型识别系统,能够在本地完成“图片-视频-摄像头”三通道检测,无需上传云端即可实时输出车辆类型与边界框,既保护数据隐私,又降低部署成本;配套注册登录与记录管理功能,为校园门禁、园区车流统计、毕业设计等场景提供开箱即用的技术模板,推动智慧交通课程的实践教学改革。
2、项目界面
(1)系统界面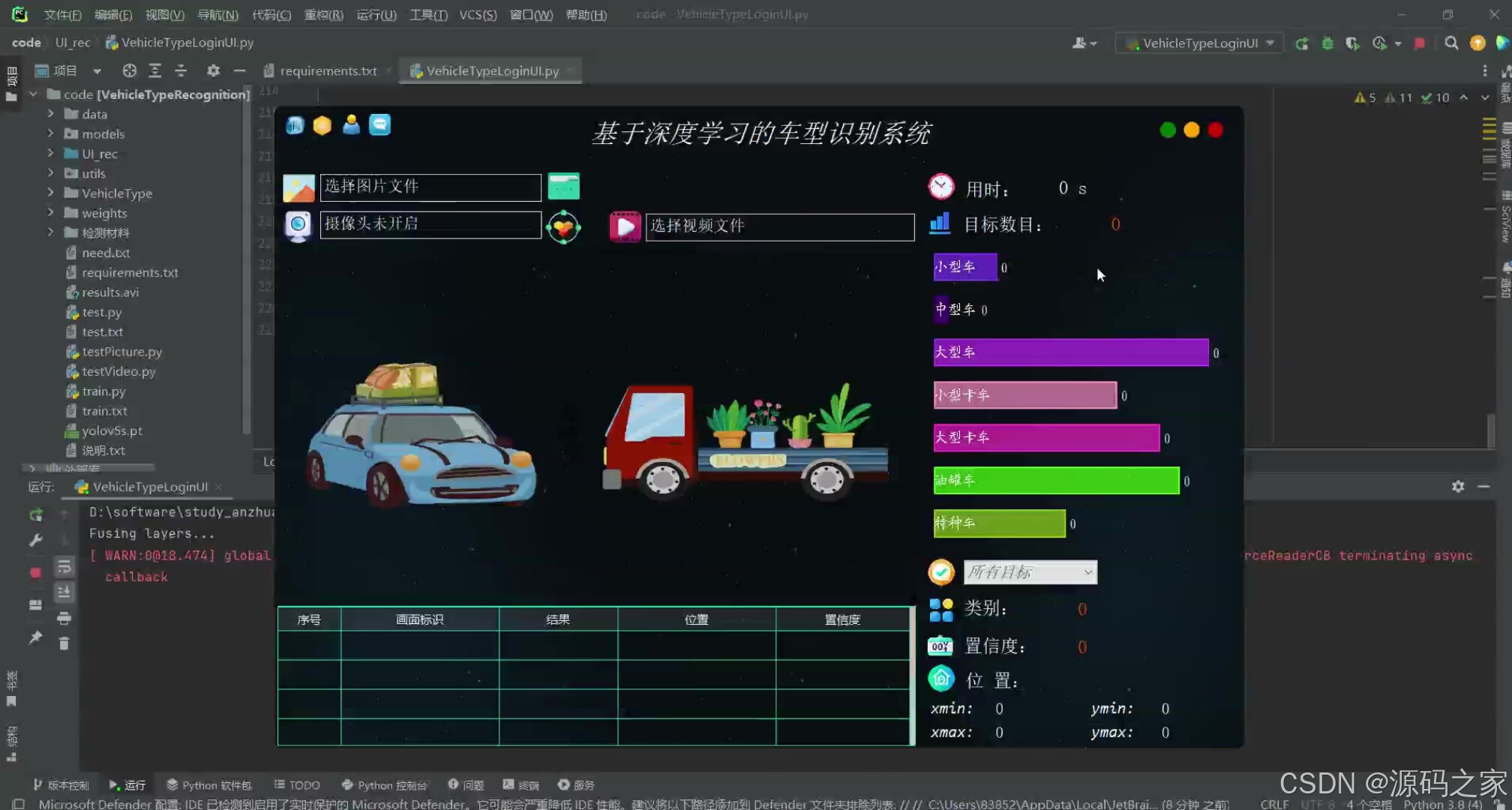
(2)车型识别—多目标检测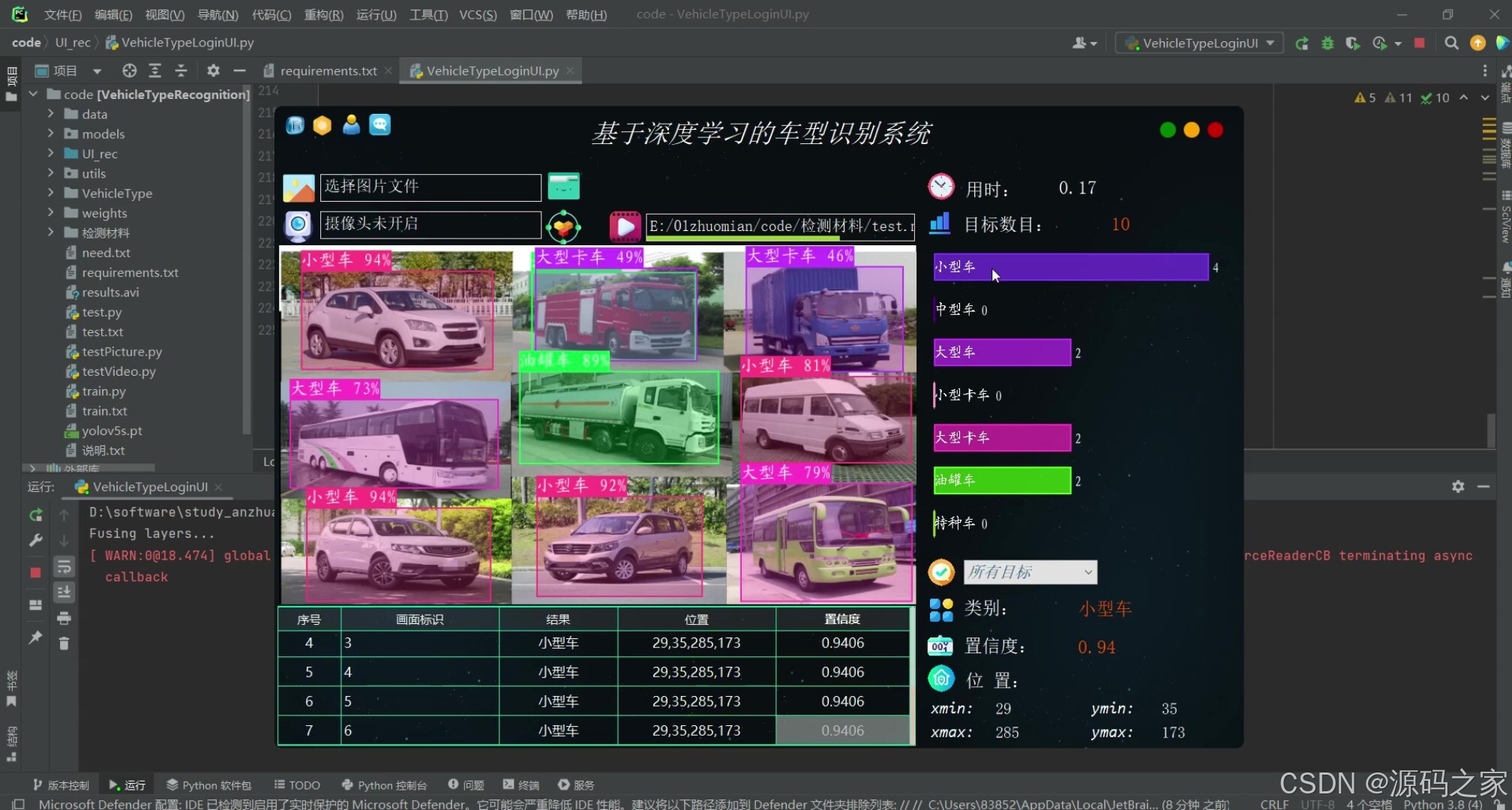
(3)车型识别—多目标检测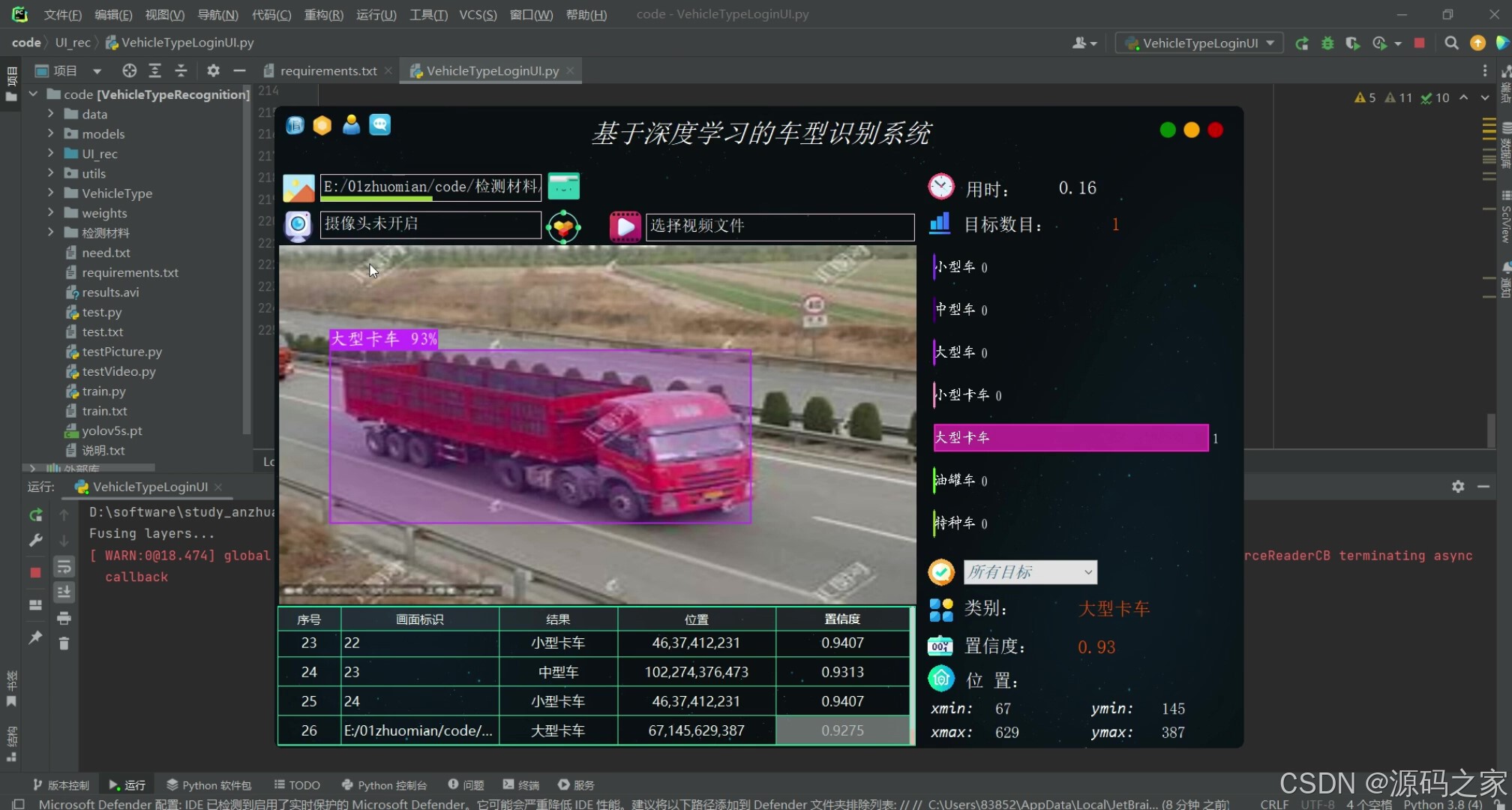
(4)车型识别—多目标检测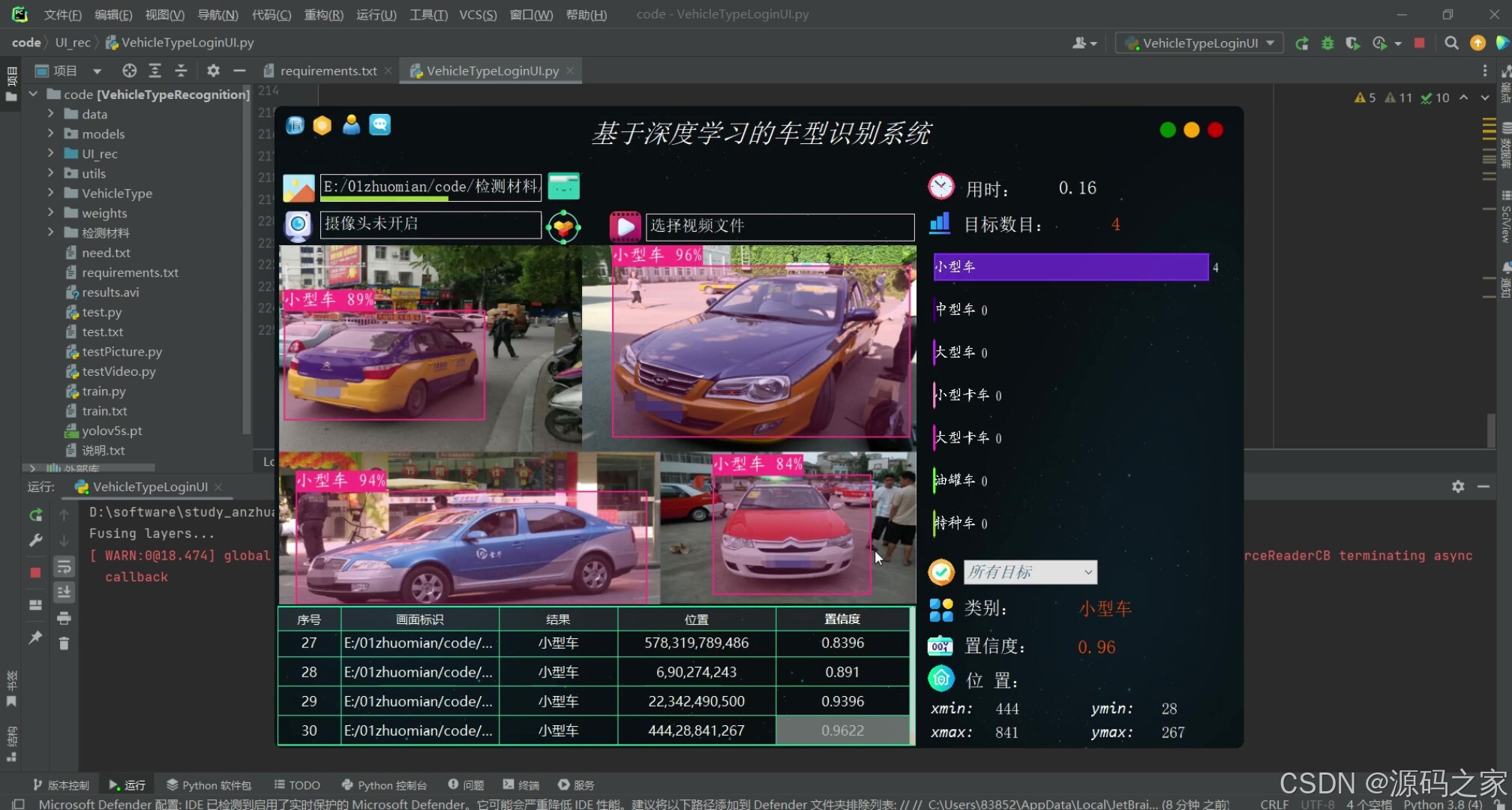
(5)车型识别—多目标检测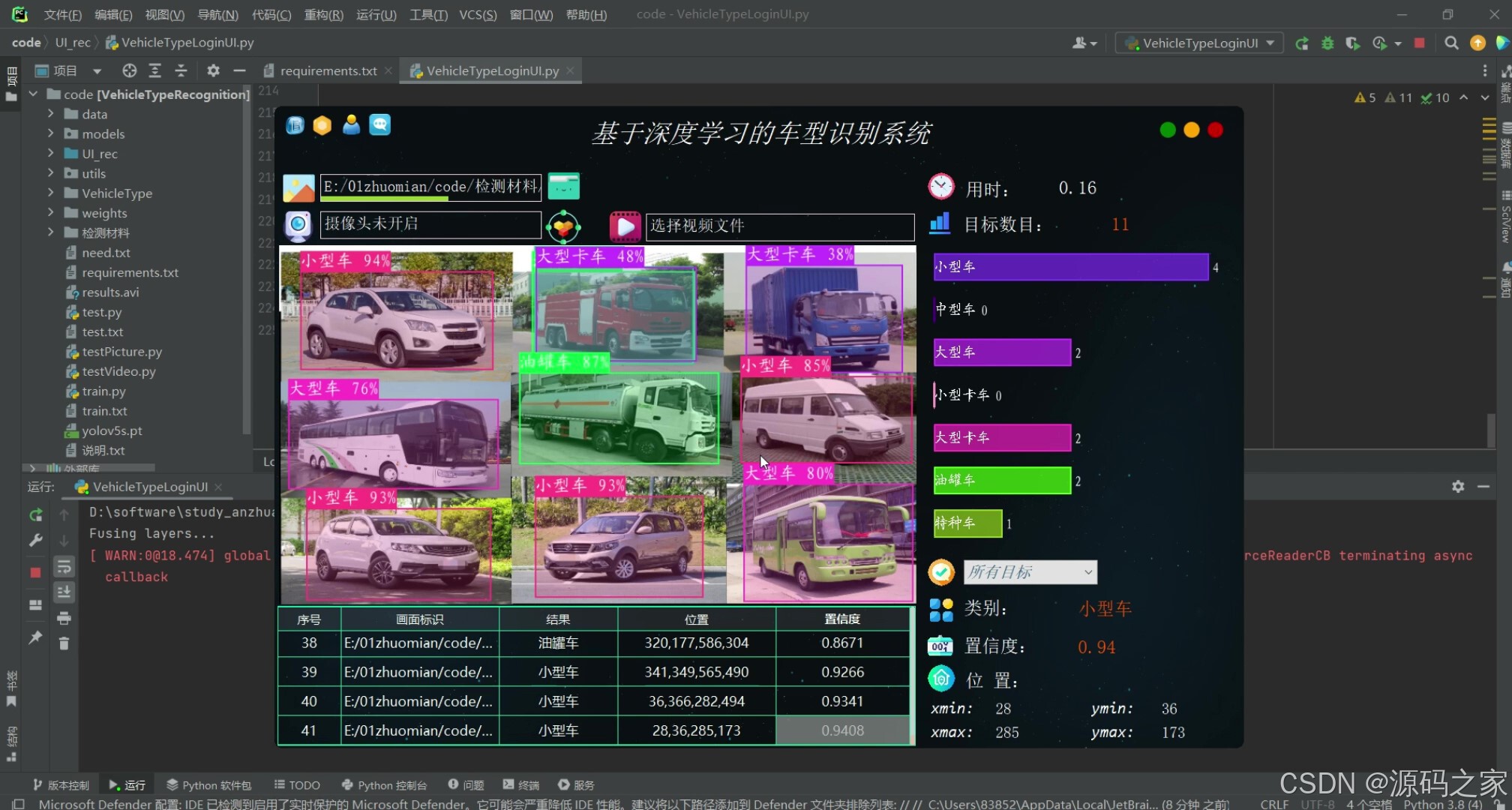
(6)车型识别—多目标检测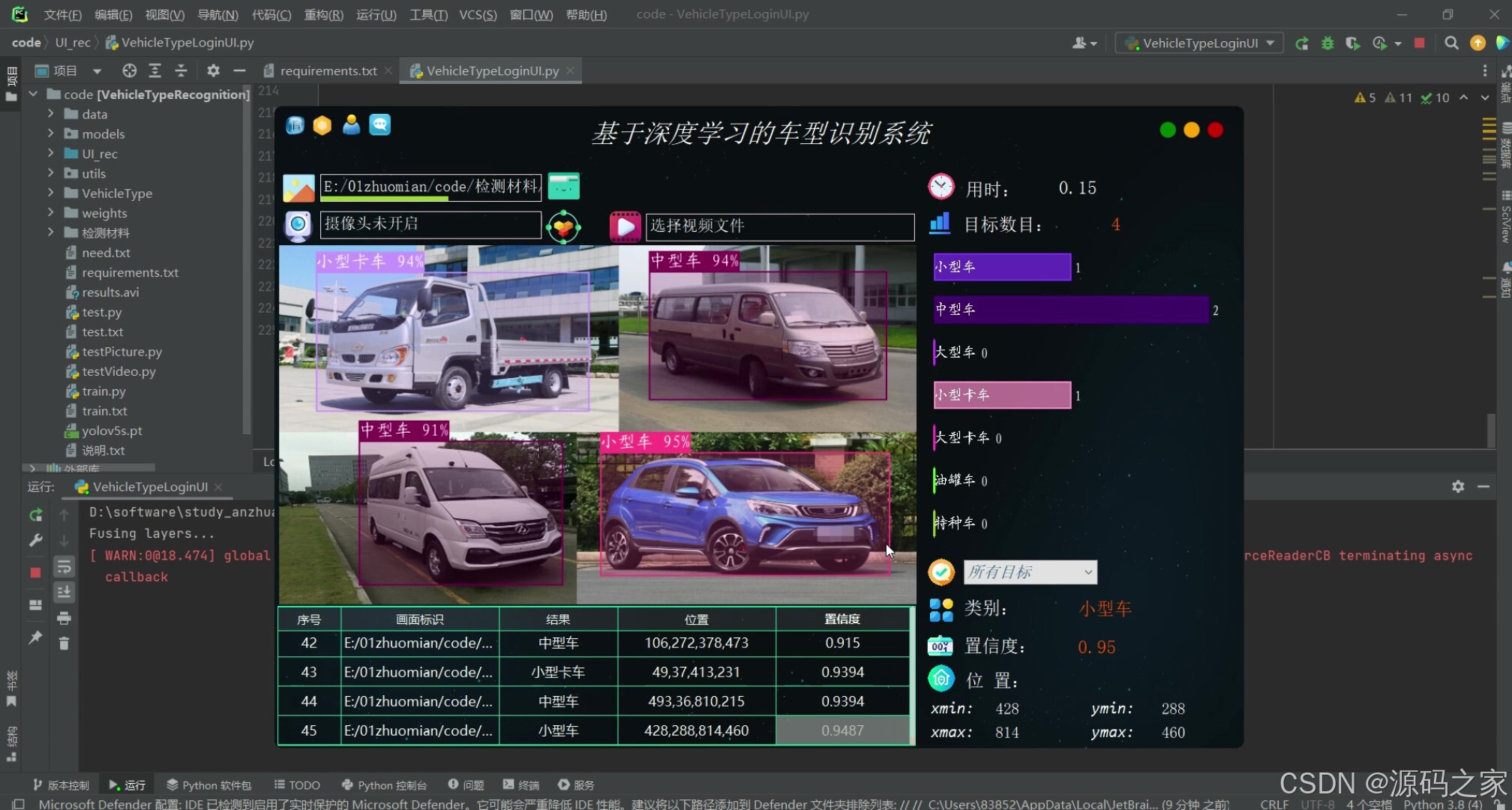
(6)车型识别—多目标检测(上传视频)
(7)注册登录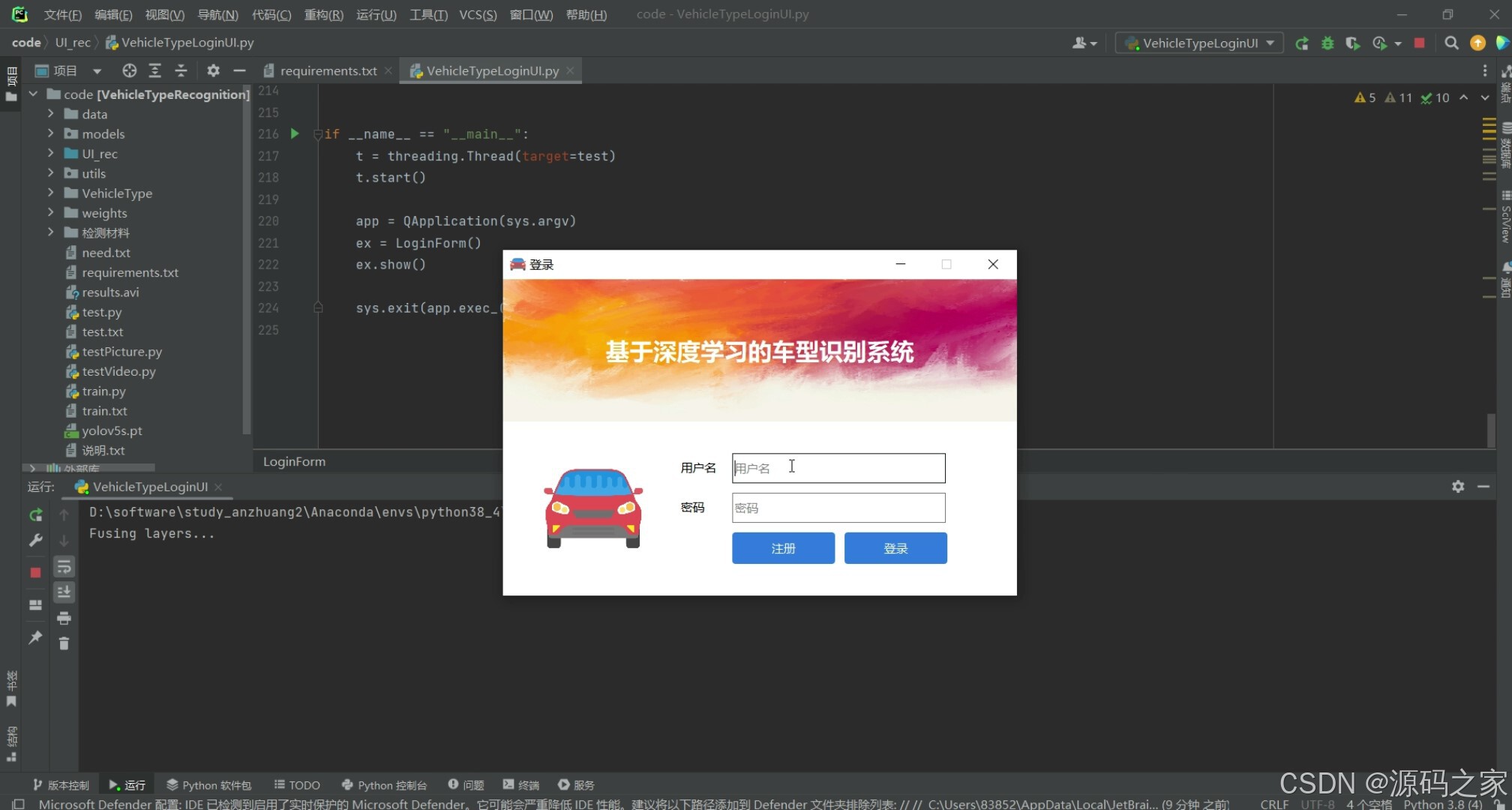
3、项目说明
本系统以YOLOv5为核心检测引擎,结合PyQt5图形框架与OpenCV多媒体处理能力,在本地计算机即可实现“即插即用”的车型识别功能。整体采用前后端分离思想:前端界面负责交互与可视化,后端推理线程负责模型调用与结果回传,两者通过Qt信号槽机制松耦合,保证界面流畅不卡顿。
在功能设计方面,软件提供三种输入模式。图片模式支持单张与批量检测,用户可通过拖拽或对话框选择;视频模式自动解析常见编码格式,按帧顺序逐张推理,并在进度条中实时显示处理进度;摄像头模式则利用OpenCV的VideoCapture类循环取流,结合多线程防止界面阻塞,实现真正的毫秒级反馈。无论哪种模式,系统都会在图像中绘制边界框、类别名称与置信度,同时将结果写入本地数据库,方便后续查询与导出。
为了保护用户隐私与数据安全,软件全程本地运行,无需连接外网;模型权重与参数文件可一键替换,用户若拥有更适用的自定义数据集,只需按照YOLOv5官方格式重新训练即可无缝迁移。注册登录模块采用轻量级SQLite,支持多用户权限隔离,教师与学生可在同一台设备上分别管理各自的实验记录,非常适合教学场景。
在智慧交通教学与科研领域,该车型识别系统可作为“计算机视觉”“深度学习应用”“智能交通系统”等课程的实践案例,学生通过阅读源码、调整阈值、更换模型,能够直观感受目标检测的流程与难点,从而加深对理论知识的理解。同时,系统开放的接口与模块化设计,也为后续功能扩展——如车牌识别、车流统计、违规停车预警——提供了良好基础。
从社会价值角度看,项目成果可直接部署于校园、园区、停车场等封闭场景,替代部分人工登记或地磁传感器,降低建设与维护成本;其轻量级特性使得边缘盒子、树莓派甚至旧笔记本都能胜任运算任务,有助于推动智慧交通技术下沉到更多资源受限的环境。通过开源代码与详细文档,项目期望激发更多开发者关注交通智能化,加速人工智能在民生领域的落地转化。
4、核心代码
import argparse
import os
import random
import time
from os import getcwd
import cv2
import numpy as np
import torch
from PyQt5 import QtCore, QtWidgets
from PyQt5.QtWidgets import QFileDialog, QMessageBox
from VehicleType.label_name import Chinese_name
from models.experimental import attempt_load
# from UI_rec.tools.BeautyUI import QBeautyUI
# from tools.BeautyUI import QBeautyUI
from UI_rec.tools.BeautyUI import QBeautyUI
# from UI_rec.tools.BeautyUI import QBeautyUI 原始
from utils.datasets import letterbox
from utils.general import (
check_img_size, non_max_suppression, scale_coords)
from utils.torch_utils import select_device, time_synchronized
class VehicleType_MainWindow(QBeautyUI):
def __init__(self, *args, obj=None, **kwargs):
super(VehicleType_MainWindow, self).__init__(*args, **kwargs)
self.author_flag = False # 是否输出信息
self.setupUi(self) # 界面生成
self.retranslateUi(self) # 界面控件
self.setUiStyle(window_flag=True, transBack_flag=True) # 设置界面样式
self.path = getcwd()
self.video_path = getcwd()
self.timer_camera = QtCore.QTimer() # 定时器
self.timer_video = QtCore.QTimer() # 视频定时器
self.flag_timer = "" # 用于标记正在进行的功能项(视频/摄像)
self.LoadModel() # 加载预训练模型
self.slot_init() # 定义槽函数
self.files = [] #
self.cap_video = None # 视频流对象
self.CAM_NUM = 0 # 摄像头标号
self.cap = cv2.VideoCapture(self.CAM_NUM) # 屏幕画面对象
self.detInfo = []
self.current_image = []
self.detected_image = None
# self.dataset = None
self.count = 0 # 表格行数,用于记录识别识别条目
self.res_set = [] # 用于历史结果记录的列表
self.c_video = 0
self.count_name = ["小型车", "中型车", "大型车", "小型卡车", "大型卡车", "油罐车", "特种车"]
self.count_table = []
self.plotBar(self.count_name, [0 for i in self.count_name], self.colors, margin=20)
def slot_init(self):
self.toolButton_file.clicked.connect(self.choose_file)
self.toolButton_folder.clicked.connect(self.choose_folder)
self.toolButton_video.clicked.connect(self.button_open_video_click)
self.timer_video.timeout.connect(self.show_video)
self.toolButton_camera.clicked.connect(self.button_open_camera_click)
self.timer_camera.timeout.connect(self.show_camera)
self.toolButton_model.clicked.connect(self.choose_model)
self.comboBox_select.currentIndexChanged.connect(self.select_obj)
self.tableWidget.cellPressed.connect(self.table_review)
self.toolButton_saveing.clicked.connect(self.save_file)
self.toolButton_settings.clicked.connect(self.setting)
self.toolButton_author.clicked.connect(self.disp_website)
self.toolButton_version.clicked.connect(self.disp_version)
def table_review(self, row, col):
try:
if col == 0: # 点击第一列时
this_path = self.tableWidget.item(row, 1) # 表格中的文件路径
res = self.tableWidget.item(row, 2) # 表格中记录的识别结果
axes = self.tableWidget.item(row, 3) # 表格中记录的坐标
if (this_path is not None) & (res is not None) & (axes is not None):
this_path = this_path.text()
if os.path.exists(this_path):
res = res.text()
axes = axes.text()
image = self.cv_imread(this_path) # 读取选择的图片
image = cv2.resize(image, (850, 500))
axes = [int(i) for i in axes.split(",")]
confi = float(self.tableWidget.item(row, 4).text())
# print(axes)
# image = self.drawRectBox(image, axes, res)
count = self.count_table[row]
self.plotBar(self.count_name, count, self.colors, margin=20)
self.label_numer_result.setText(str(sum(count)))
image = self.drawRectEdge(image, axes, alpha=0.2, addText=res)
# 在Qt界面中显示检测完成画面
self.display_image(image) # 在界面中显示画面
# 在界面标签中显示结果
self.label_xmin_result.setText(str(int(axes[0])))
self.label_ymin_result.setText(str(int(axes[1])))
self.label_xmax_result.setText(str(int(axes[2])))
self.label_ymax_result.setText(str(int(axes[3])))
self.label_score_result.setText(str(round(confi * 100, 2)) + "%")
self.label_class_result.setText(res)
QtWidgets.QApplication.processEvents()
except:
self.label_display.setText('重现表格记录时出错,请检查表格内容!')
self.label_display.setStyleSheet("border-image: url(:/newPrefix/images_test/ini-image.png);")
def LoadModel(self, model_path=None):
"""
读取预训练模型
"""
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='../weights/vehicle-best.pt',
help='model.pt path(s)') # 模型路径仅支持.pt文件
parser.add_argument('--img-size', type=int, default=480, help='inference size (pixels)') # 检测图像大小,仅支持480
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold') # 置信度阈值
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS') # NMS阈值
# 选中运行机器的GPU或者cpu,有GPU则GPU,没有则cpu,若想仅使用cpu,可以填cpu即可
parser.add_argument('--device', default='',
help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--save-dir', type=str, default='inference', help='directory to save results') # 文件保存路径
parser.add_argument('--classes', nargs='+', type=int,
help='filter by class: --class 0, or --class 0 2 3') # 分开类别
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') # 使用NMS
self.opt = parser.parse_args() # opt局部变量,重要
out, weight, imgsz = self.opt.save_dir, self.opt.weights, self.opt.img_size # 得到文件保存路径,文件权重路径,图像尺寸
self.device = select_device(self.opt.device) # 检验计算单元,gpu还是cpu
self.half = self.device.type != 'cpu' # 如果使用gpu则进行半精度推理
if model_path:
weight = model_path
self.model = attempt_load(weight, map_location=self.device) # 读取模型
self.imgsz = check_img_size(imgsz, s=self.model.stride.max()) # 检查图像尺寸
if self.half: # 如果是半精度推理
self.model.half() # 转换模型的格式
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names # 得到模型训练的类别名
# self.names = [Chinese_name[i] for i in self.names]
for i, v in enumerate(self.names):
if v in Chinese_name.keys():
self.names[i] = Chinese_name[v]
# hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
# '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
color = [[132, 56, 255], [82, 0, 133], [203, 56, 255], [255, 149, 200], [255, 55, 199],
[72, 249, 10], [146, 204, 23], [61, 219, 134], [26, 147, 52], [0, 212, 187],
[255, 56, 56], [255, 157, 151], [255, 112, 31], [255, 178, 29], [207, 210, 49],
[44, 153, 168], [0, 194, 255], [52, 69, 147], [100, 115, 255], [0, 24, 236]]
self.colors = color if len(self.names) <= len(color) else [[random.randint(0, 255) for _ in range(3)] for _ in
range(len(self.names))] # 给每个类别一个颜色
img = torch.zeros((1, 3, self.imgsz, self.imgsz), device=self.device) # 创建一个图像进行预推理
_ = self.model(img.half() if self.half else img) if self.device.type != 'cpu' else None # 预推理
def choose_model(self):
self.timer_camera.stop()
self.timer_video.stop()
if self.cap and self.cap.isOpened():
self.cap.release()
if self.cap_video:
self.cap_video.release() # 释放视频画面帧
self.comboBox_select.clear() # 下拉选框的显示
self.comboBox_select.addItem('所有目标') # 清除下拉选框
self.clearUI() # 清除UI上的label显示
self.flag_timer = ""
# 调用文件选择对话框
fileName_choose, filetype = QFileDialog.getOpenFileName(self.centralwidget,
"选取图片文件", getcwd(), # 起始路径
"Model File (*.pt)") # 文件类型
# 显示提示信息
if fileName_choose != '':
self.toolButton_model.setToolTip(fileName_choose + ' 已选中')
else:
fileName_choose = None # 模型默认路径
self.toolButton_model.setToolTip('使用默认模型')
self.LoadModel(fileName_choose)
def select_obj(self):
QtWidgets.QApplication.processEvents()
if self.flag_timer == "video":
# 打开定时器
self.timer_video.start(30)
elif self.flag_timer == "camera":
self.timer_camera.start(30)
ind = self.comboBox_select.currentIndex() - 1
ind_select = ind
if ind <= -1:
ind_select = 0
# else:
# ind_select = len(self.detInfo) - ind - 1
if len(self.detInfo) > 0:
# self.label_class_result.setFont(font)
self.label_class_result.setText(self.detInfo[ind_select][0]) # 显示类别
self.label_score_result.setText(str(self.detInfo[ind_select][2])) # 显示置信度值
# 显示位置坐标
self.label_xmin_result.setText(str(int(self.detInfo[ind_select][1][0])))
self.label_ymin_result.setText(str(int(self.detInfo[ind_select][1][1])))
self.label_xmax_result.setText(str(int(self.detInfo[ind_select][1][2])))
self.label_ymax_result.setText(str(int(self.detInfo[ind_select][1][3])))
image = self.current_image.copy()
if len(self.detInfo) > 0:
for i, box in enumerate(self.detInfo): # 遍历所有标记框
if ind != -1:
if ind != i:
continue
# 在图像上标记目标框
label = '%s %.0f%%' % (box[0], float(box[2]) * 100)
self.label_score_result.setText(box[2])
# label = str(box[0]) + " " + str(float(box[2])*100)
# 画出检测到的目标物
# self.names. box[0]
image = self.drawRectBox(image, box[1], addText=label, color=self.colors[box[3]])
# self.label_score_result.setText(str(len(self.detInfo) - count))
# 在Qt界面中显示检测完成画面
self.display_image(image)
# self.label_display.display_image(image)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
更多推荐
 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)