
大数据专业毕业设计之基于深度学习的网络热点舆情分析系统
随着互联网的快速发展,微博作为一款受欢迎的社交媒体平台,拥有大量的博文和用户评论等信息。为了更好地利用做好舆情检测和预警工作,开发了一个基于深度学习的网络热点舆情分析系统。该系统利用python语言、mysql数据库等大数据技术,对海量博文热搜信息、评论数据进行处理和分析,通过与情感分析模型进行对比,准确识别出博主的积极言论与消极言论的比值,并生成对应的舆情预计预测报告。
·

一、项目介绍
随着互联网的快速发展,微博作为一款受欢迎的社交媒体平台,拥有大量的博文和用户评论等信息。为了更好地利用做好舆情检测和预警工作,开发了一个基于深度学习的网络热点舆情分析系统。该系统利用python语言、mysql数据库等大数据技术,对海量博文热搜信息、评论数据进行处理和分析,通过与情感分析模型进行对比,准确识别出博主的积极言论与消极言论的比值,并生成对应的舆情预计预测报告。
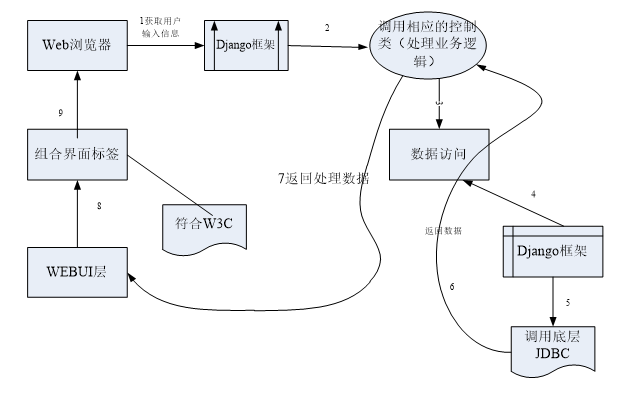
总的来说系统是一个可视化显示web界面,首先通过爬虫技术获取到对应的博文、热搜和评论等数据,考虑数据量较大,系统首先通过pandas进行文本的保存和读取,进而保存到mysql数据库管理系统中,最后通过Django框架结合vue框架进行界面展示。本研究的意义在于,通过对微博平台上的博文和用户评论信息等进行情感分析,提出舆情预警,规避微博用户发布一些不合法的信息。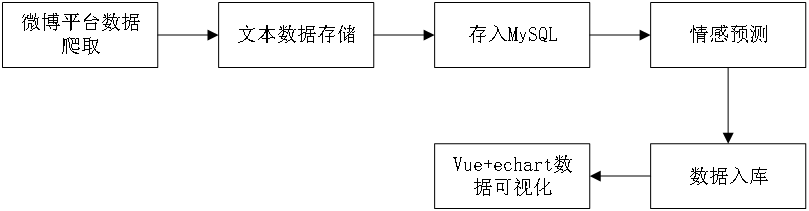
二、文档介绍



三、运行截图



name = 'ReSouSpiders'
allowed_domains = ['weibo.com']
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
# 搜索链接
search_url = 'https://s.weibo.com/weibo?q={}'
# TODO 打开cmd,输入: start chrome --flag-switches-begin --flag-switches-end --remote-debugging-port=9887
def start_requests(self):
yield scrapy.Request(url=self.url, callback=self.parse)
def parse(self, response):
# 获取当天的日期,格式年/月/日
time = datetime.datetime.now().strftime('%Y-%m-%d')
# 定位到 id="pl_top_realtimehot" 的div标签
div = response.xpath('//div[@id="pl_top_realtimehot"]')
# 定位到div标签下的所有的tr标签
trs = div.xpath('./table/tbody/tr')
for tr in trs[1:]:
# 获取热搜的排名,第一个td标签
rank = tr.xpath('./td[1]/text()').extract_first()
# 获取热搜的内容
content = tr.xpath('./td[@class="td-02"]/a/text()').extract_first()
# 获取热搜的链接
link = 'https://s.weibo.com'+tr.xpath('./td[@class="td-02"]/a/@href').extract_first()
# 获取热搜的热度
hot = tr.xpath('./td[@class="td-02"]/span/text()').extract_first()
# 获取热搜的标签
tags = tr.xpath('./td[@class="td-03"]/i/text()').extract()
item = ReSouItem()
item['time'] = time
item['rank'] = rank
item['content'] = content
item['link'] = link
item['hot'] = hot
item['tags'] = tags
yield item
yield scrapy.Request(url=link, callback=self.parse_detail, meta={'item': item,'page': 1})
pass
import pandas as pd
import os
import pymysql
from sqlalchemy import create_engine
mysql_config = {
'host': 'localhost',
'user': 'root', # 改为正确的用户名以及密码
'password': 'root',
'database': 'hz_project_webo',
'port': 3306
}
conn = pymysql.connect(**mysql_config)
cursor = conn.cursor()
engine = create_engine(f"mysql+pymysql://{mysql_config['user']}:{mysql_config['password']}@{mysql_config['host']}:{mysql_config['port']}/{mysql_config['database']}")
create_tables_sql = """
CREATE TABLE IF NOT EXISTS topic_count (
id INT AUTO_INCREMENT PRIMARY KEY,
topic VARCHAR(255),
count INT
);
CREATE TABLE IF NOT EXISTS nickname_count (
id INT AUTO_INCREMENT PRIMARY KEY,
nickname VARCHAR(255),
count INT
);
CREATE TABLE IF NOT EXISTS topic_sum (
id INT AUTO_INCREMENT PRIMARY KEY,
topic VARCHAR(255),
share INT,
comment INT,
`like` INT
);
CREATE TABLE IF NOT EXISTS topic_avg (
id INT AUTO_INCREMENT PRIMARY KEY,
topic VARCHAR(255),
share FLOAT,
comment FLOAT,
`like` FLOAT
);
CREATE TABLE IF NOT EXISTS topic_max (
id INT AUTO_INCREMENT PRIMARY KEY,
topic VARCHAR(255),
share INT,
comment INT,
`like` INT
);
CREATE TABLE IF NOT EXISTS topic_min (
id INT AUTO_INCREMENT PRIMARY KEY,
topic VARCHAR(255),
share INT,
comment INT,
`like` INT
);
CREATE TABLE IF NOT EXISTS weibo (
id INT AUTO_INCREMENT PRIMARY KEY,
topic VARCHAR(255),
nickname VARCHAR(255),
content TEXT,
share INT,
comment INT,
`like` INT,
tag VARCHAR(255),
score FLOAT
);
CREATE TABLE IF NOT EXISTS reshou (
id INT AUTO_INCREMENT PRIMARY KEY,
time DATETIME,
`rank` INT,
content TEXT,
link VARCHAR(255),
hot INT,
tags VARCHAR(255),
bili FLOAT
);
"""
with conn.cursor() as cursor:
for statement in create_tables_sql.split(';'):
if statement.strip():
cursor.execute(statement)
conn.commit()
weibo = pd.read_csv('./dataset/weibo.csv')
reshou = pd.read_csv('./dataset/reshou.csv')
import re
# 去掉中文
def remove_chinese(text):
rex = re.compile(r'[\u4e00-\u9fa5]')
return rex.sub('', text)
# 去掉特殊字符,空格,单引号,双引号,中括号,大括号,小括号
def remove_special_character(text):
rex = re.compile(r'[\s\'\"\[\]\{\}\(\)\【\】\n\r\t]')
return rex.sub('', text)
# 去掉假的转义字符
def remove_escape_character(text):
rex = text.replace(r'\n', '').replace('\\u3000', '')
rex = rex.replace(r'\u200b', '')
return rex
# 处理tags
reshou['tags'] = reshou['tags'].apply(remove_special_character)
# 处理hot
reshou['hot'] = reshou['hot'].apply(remove_special_character)
reshou['hot'] = reshou['hot'].apply(remove_chinese)
# 处理content
weibo['content'] = weibo['content'].apply(remove_special_character)
weibo['content'] = weibo['content'].apply(remove_escape_character)
# 将英文标点转换为中文标点
weibo['content'] = weibo['content'].str.replace(r'!', '!')
weibo['content'] = weibo['content'].str.replace(r'?', '?')
weibo['content'] = weibo['content'].str.replace(r',', ',')
weibo['content'] = weibo['content'].str.replace(r';', ';')
weibo['content'] = weibo['content'].str.replace(r':', ':')
weibo['content'] = weibo['content'].str.replace(r'~', '~')
weibo['content'] = weibo['content'].str.replace(r'`', '·')
# 替换所有的空值为0
weibo = weibo.fillna(0)
# 保存数据
weibo['share'] = weibo['share'].astype(int)
weibo['comment'] = weibo['comment'].astype(int)
weibo['like'] = weibo['like'].astype(int)
weibo['tag'] = None
weibo['score'] = None
reshou['bili'] = None
topic_count = weibo['topic'].value_counts().reset_index()
topic_count.columns = ['topic', 'count']
nickname_count = weibo['nickname'].value_counts().reset_index()
nickname_count.columns = ['nickname', 'count']
topic_sum = weibo.groupby('topic').agg({
'share': 'sum',
'comment': 'sum',
'like': 'sum'
}).reset_index()
topic_avg = weibo.groupby('topic').agg({
'share': 'mean',
'comment': 'mean',
'like': 'mean'
}).reset_index()
topic_max = weibo.groupby('topic').agg({
'share': 'max',
'comment': 'max',
'like': 'max'
}).reset_index()
topic_min = weibo.groupby('topic').agg({
'share': 'min',
'comment': 'min',
'like': 'min'
}).reset_index()
# 只为原始数据表添加id列
weibo = weibo.reset_index(drop=True)
weibo.insert(0, 'id', range(1, len(weibo) + 1))
reshou = reshou.reset_index(drop=True)
reshou.insert(0, 'id', range(1, len(reshou) + 1))
try:
# 统计表使用数据库自动生成的id
topic_count.to_sql('topic_count', engine, if_exists='replace', index=True, index_label='id')
print("已写入topic_count表")
nickname_count.to_sql('nickname_count', engine, if_exists='replace', index=True, index_label='id')
print("已写入nickname_count表")
topic_sum.to_sql('topic_sum', engine, if_exists='replace', index=True, index_label='id')
print("已写入topic_sum表")
topic_avg.to_sql('topic_avg', engine, if_exists='replace', index=True, index_label='id')
print("已写入topic_avg表")
topic_max.to_sql('topic_max', engine, if_exists='replace', index=True, index_label='id')
print("已写入topic_max表")
topic_min.to_sql('topic_min', engine, if_exists='replace', index=True, index_label='id')
print("已写入topic_min表")
# 原始数据表保留手动添加的id列
weibo.to_sql('weibo', engine, if_exists='replace', index=False)
print("已写入weibo表")
reshou.to_sql('reshou', engine, if_exists='replace', index=False)
print("已写入reshou表")
except Exception as e:
print(f"写入数据库时发生错误: {str(e)}")
finally:
conn.close()
print("数据库连接已关闭")
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)