
计量经济与深度学习融合的短时交通流预测
本研究提出一种结合向量自回归(VAR)模型与CNN-LSTM混合神经网络的短期交通流预测框架。通过VAR模型分析交通变量间的可预测关系,确定速度为响应变量,交通指数和交通量为解释变量。随后利用多特征输入的CNN-LSTM模型进行预测,结果表明其性能优于单一特征及其他模型。预测精度受空间相关性影响,并通过时空热力图实现可视化,为交通管理与出行信息发布提供支持。
短时交通流预测:一种计量经济学与混合深度学习相结合的集成方法
摘要
本研究提出了一种短期交通流量预测框架。该框架结合了基于计量经济理论的向量自回归(VAR)模型和基于深度学习的CNN‐LSTM混合神经网络模型进行分析。首先利用VAR模型评估交通变量之间的内在关联,并确定这些变量的可预测关系。然后,采用CNN‐LSTM混合神经网络模型对某一空间位置进行多特征速度预测,结果证明,使用多特征的预测效果优于单一特征的预测。随后,将若干流行的深度学习模型及其他浅层预测模型与所构建的CNN‐LSTM模型进行对比,比较结果表明,所提出的CNN‐LSTM模型在短期交通流量预测方面的性能优于其他模型。接着,进一步利用CNN‐LSTM模型对一组空间位置进行多特征速度预测,结果表明预测精度与交通流量的空间相关性相关。最后,生成热力图以可视化预测速度,从而清晰地呈现时空交通状况。研究成果有望应用于出行信息发布和交通拥堵管理。
Index Terms— 短期交通流量,向量自回归,CNN‐LSTM混合神经网络,多特征,时空热力图。
一、引言
ROAD 交通拥堵经常发生在中国许多城市,导致一些社会、经济和环境问题。缓解这些问题的首要方法是将智能交通系统(ITS)应用于现实世界交通管理。如今,智能交通系统生动地促进了交通研究、政策制定和技术开发领域的发展,其基础是预测实时交通流量[2]。实时交通流量预测是识别拥堵先兆的重要方法,对交通管理者和出行者都至关重要。对于交通管理者而言,他们需要掌握路网的交通运行状况,进而实施针对性措施以缓解交通拥堵。而对于出行者来说,他们希望在出行前获取实时出行信息,并在旅途中获得精确路线引导。所有这些交通应对措施和需求都离不开精确交通流量预测。
过去开展了大量的交通流量预测研究。在这些研究中,速度预测是最广泛研究的课题。许多研究通过预测行驶速度来评估实时交通状态[3]–[7]。除了速度预测之外,一些研究还使用交通量作为预测指标[3],[5],[8]。此外,一些学者也通过预测行程时间和密度来估计交通流状态[3],[5],[9],[10]。随着机动车保有量的持续增长和城市交通的多样化发展,交通管理模式也发生了巨大变化。传统交通管理方法已无法满足当前多样化的出行需求。近年来,中国政府提出了寻求科学化精细化交通管理的目标。因此,未来的交通管理需要与新兴的人工智能技术相结合。在此背景下,亟需利用可靠指标和深度学习方法对实时交通流量状态进行系统性评估和预测。
在本研究中,为了全面评估短时交通状态,预测交通流量时考虑了多交通特征。该研究包括两种主要理论方法:基于计量经济理论的向量自回归模型(VAR),以及结合卷积神经网络(CNN)和长短期记忆神经网络(LSTM)的混合CNN‐LSTM模型。VAR模型旨在评估交通变量之间的可预测关系,从而确定响应变量和预测变量。然后,混合深度学习模型利用这些预测变量对响应变量进行预测。这些方法的详细信息将在方法论部分介绍。
关于交通流量预测的研究文献主要集中在三个方向:时间序列预测研究、人工智能(AI)方法(如机器学习预测和深度学习预测),以及其他预测方法。
在时间序列研究中,最广泛使用的方法是自回归积分滑动平均模型(ARIMA)。ARIMA最初由艾哈迈德和库克[11]提出,用于预测交通量。随后,开发了若干扩展的ARIMA模型,包括季节性自回归积分滑动平均模型[12],[13], 和时空自回归积分滑动平均模型[14]。此外,一些研究还开发了卡尔曼滤波模型,用于预测城市道路或高速公路的交通流量[15]–[19]。这些方法具有较高的计算效率和良好的准确性,但最适合用于平稳或线性时间序列[20]。之后,在交通流量预测中也探索了其他时间序列模型。Schimbinschi et al.[21] 提出了一种用于大型城市地区交通预测的学习拓扑正则化通用向量自回归模型。Ghosh et al.[22]开发了一种简约且计算上简单的多元短期交通流量预测算法。经过多年的发展,基于时间序列方法的交通流量预测逐渐成熟,并取得了巨大成就。然而,由于交通流量具有非线性和随机特性,上述时间序列模型可能无法很好地描述其独特性质,同时可能导致较大的预测误差。
近年来,基于人工智能的技术在交通工程领域[23],中得到了快速应用,尤其是在交通流量预测研究领域,因其强大的处理非线性问题的能力而备受关注。许多研究人员已采用机器学习方法来预测短期交通流量,包括支持向量机(SVM)模型[24]–[27],、K近邻(KNN)模型[28]–[31],以及神经网络模型[32]–[36]。这些模型具备处理复杂函数的能力,无需事先了解函数的组织结构,且具有较强的鲁棒性和预测能力。
随着传统神经网络的发展和演变,深度学习方法也成为研究热点。许多深度学习模型已被应用于短期交通流量预测[37]。Ma et al.[38]将CNN模型应用于交通流量预测,从而将交通流量预测定义为图像学习问题。张等[39]提出了一种端到端多任务学习时间卷积神经网络(MTL‐TCNN),并基于叫车数据预测短期客流,数值结果表明MTL‐TCNN优于其他深度学习方法。随后,沙赫萨瓦里和阿贝尔[40]基于图神经网络(GNN)模型研究了交通流量预测,结果表明,与自回归积分滑动平均模型相比,GNN在提取长期依赖和学习网络动态方面更为高效。在无监督学习方面,深度置信网络(DBN)常被用于交通预测,已有若干研究采用该深度学习框架来预测交通流量[41]–[43]。除了DBN模型外,其他无监督学习方法,如堆叠自动编码器(SAE)方法[44]及其改进版本[45],也被用于预测交通流量。
通常,上述深度学习模型在提取时空特征方面存在一些困难,因为其神经元结构无法满足这一需求[7]。为解决此问题,提出了循环神经网络(RNN)模型用于交通流量预测,因其在刻画时间相关性以及处理时间序列任务方面具有优势。然而,传统RNN模型无法有效应对长期记忆问题,因为当时间序列较长时,序列后端的梯度难以向前传播,从而导致梯度消失。LSTM网络[46]是一种特殊的RNN,具有较强解决长期记忆问题的能力。已有若干研究基于LSTM网络对交通流量序列进行预测[47]–[51]。尽管LSTM网络在处理长期记忆问题上表现良好,但基本的LSTM网络无法充分利用数据的空间特征[7]。因此,一些研究对LSTM网络进行了扩展,包括CNN‐LSTM模型[52],[53],、改进的小波包分析(IWPA)‐LSTM模型[54], 、LSTM与循环单元神经网络的组合[55],以及图注意力(GA)‐LSTM模型[56]。此外,为了更好地学习交通流量数据的时空特征,一些近期研究还结合其他深度学习神经网络来预测短期交通流量,例如图注意力网络(GAT)与时间卷积网络(TCN)的集成框架[57],,以及卷积神经网络(FCNs)与Conv‐LSTM的组合[58]。所有这些改进的LSTM网络和集成神经网络均解决了数据空间特征的利用问题,能够更有效地描述交通流量的随机性和非线性特性。
除了上述相关研究外,还探索了一些其他交通流量预测方法。Pan et al.[59]提出了一种随机元胞传输模型来预测短期交通流量,该模型考虑了交通流量的时空相关性。鉴于高速公路交通的动态性和随机性,齐和伊沙克[60]提出了一种隐马尔可夫模型(HMM)方法用于预测高速公路的短期交通流量。Liu et al. [61]提出了一种大规模交通流量预测的时空集成方法,其中引入了一种基于语义分割技术的全卷积模型。此外,Antoniou et al.[62]研究了数据驱动的交通状态估计,他们采用两步法,第一步是将观测值分配给交通状态,然后使用状态特定函数来预测交通状态。Ma et al.[63]提出了一种时空阈值向量误差修正(TS‐TVEC)模型用于短期交通流量预测,并揭示了误差修正模型的数学形式与交通流量理论之间的内在联系。
上述大多数研究都是直接使用交通流量数据进行预测,很少考虑内生性问题交通变量。实际上,交通数据通常在实时情况下显得杂乱、不规则且波动较大,导致具有强烈的非平稳性特征。尽管已有若干研究采用深度学习方法来分析这些复杂特征[37],[38],但在交通变量之间仍缺乏可预测关系分析。换句话说,很少有研究探讨所选变量是否可以利用其他特征进行预测。本研究填补了这一空白。本研究构建VAR模型以评估交通变量之间的可预测关系。通过一系列VAR建模过程的研究,识别出交通变量间的可预测关系。该计量经济分析为短期交通流量的预测提供了可信的支持。
此外,大多数先前的研究主要使用单个特征来预测一个空间位置的交通流量(即,使用单一位置的单变量时间序列数据来预测其未来趋势)。极少有研究在预测时考虑交通流的空间演化,因为现有研究很少利用多特征对多个空间位置的交通流量进行预测(即,使用多特征时间序列数据预测多个位置的未来趋势)。鉴于交通流异质性,交通流量的影响因素多种多样且不确定,因此仅使用一个特征来预测其未来趋势可能过于理想化。为此,本研究采用多特征变量来预测一组位置的交通流量。本文提出一种混合深度学习网络,利用多特征变量进行短期交通流量预测。为了充分利用交通流量数据的时空特征,并克服单一LSTM网络模型和CNN网络模型的缺陷,引入注意力机制以融合LSTM与CNN网络模型。最终构建了CNN‐LSTM混合神经网络模型,该混合模型兼具LSTM网络和CNN网络的优势。
总体而言,本研究的贡献可以总结如下:
(1)基于计量经济理论的VAR模型被用于探索交通变量之间的可预测关系。随后,识别出响应变量(即速度)是否能够通过多特征(即速度、TI和交通量)进行有效预测。此前的研究中尚未有使用VAR模型进行此类关系分析的工作。
(2)开发了一种混合神经网络模型,用于利用多特征预测短期交通流量。该混合神经网络模型通过注意力机制融合了单一的LSTM和CNN模型。所提出的CNN‐LSTM网络模型的预测性能优于其他深度学习模型和浅层模型,因为它既能处理交通流量数据的复杂空间特征,又能解决时间序列数据的长期记忆问题。
(3) 对多组空间位置的交通流量进行了预测,结果表明这些空间位置的预测精度与交通流的空间相关性密切相关。具体而言,不同位置之间的交通流空间相关性越大,预测结果越接近,这一发现对交通管理具有重要的启示意义。
然后,本文其余部分结构如下:在第二节中,描述了研究路段和数据;在第三节中,介绍了方法论;在第四节中,展示了研究结果;最后,在第五节中,提出了讨论和简要结论。
II. 研究路段和数据
上海延安高架路是本研究的走廊路段。作为上海城市快速路中最拥堵的道路之一[64],,延安高架路的交通状况通常较差。延安高架路承担着上海市道路网中东西方向的跨区域交通功能,日交通流量较大。张[65] 指出,上海城市快速路的高峰时段包括:早高峰时段(7:00‐9:59)、午间高峰时段(14:00‐16:00)和晚间高峰时段(16:00‐18:59)。在这种情况下,不同时段的交通流量差异显著,尤其是在高峰时段。这将导致复杂的交通状况,不利于出行。因此,短时交通流预测十分必要,因为它有助于交通管理者掌握整体交通运行情况,并为出行者提供直接的出行信息,从而促进交通管理措施的实施。
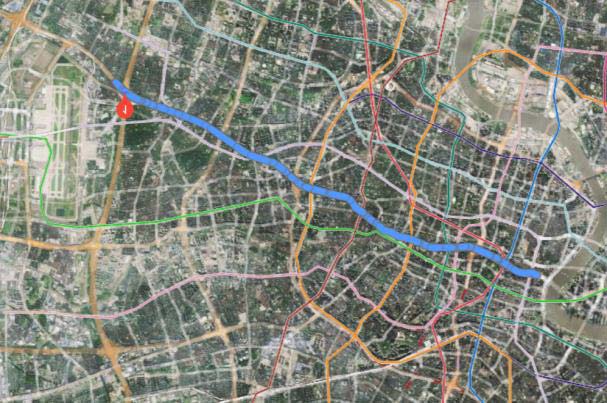
研究路段的交通流向为由西向东(见图1)。共包含七个路段:红景路至虹许路的路段(“红景路‐红徐路”),虹许路至娄山关路的路段(“虹许路‐娄山关路”),娄山关路至西立交的路段(“娄山关路‐西立交”),西立交至凯旋路的路段(“西立交‐凯旋路”),凯旋路至江苏路的路段(“凯旋路‐江苏路”),江苏路至华山路的路段(“江苏路‐华山路”),以及华山路至茂名路的路段(“华山路‐茂名路”)。研究路段总长度为11.16公里,七个路段的路段长度分别为2.1公里、1.8公里、0.86公里、1.7公里、1.8公里、1.4公里和1.5公里。
本研究所使用的主要数据由上海市公安局交通警察总队提供。数据中可获取三种交通参数:交通指数(TI)、速度和交通量。TI数据包含采集时间(采集间隔为2分钟)、道路编码和TI序列。速度和交通量数据则包括采集时间(采集间隔为2分钟)、路段编码、速度(公里/小时)和交通量。
III. 方法论
A. 向量自回归模型
本研究涉及三种交通变量:交通指数、速度和交通量。交通指数是基于实时路网数据计算得出的量化交通状态指标,能够准确反映特定时空视角下的交通状况。交通指数综合考虑了交通状况和道路设计[64]。在本研究中,交通指数由上海市政府定义,取值范围为1至100,交通指数越大,表示道路交通越拥堵;反之,交通指数越小,表示道路交通越通畅。交通指数表达如下[65]。
$$
TI= \frac{\sum_{i=1}^{I} k_i l_i [(v_f - v_i)/v_f]}{\sum_{i=1}^{I} k_i l_i} \times 100
$$
其中 $l_i$ 表示道路i的里程长度,$k_i$ 表示道路i的车道数量。然后 $v_f$ 和 $v_i$ 分别为自由流速度和实际速度。
由于重点是预测短期交通流量,因此需要首先确定响应变量和预测变量。通常,上述所有交通参数均可作为响应变量。然而,在考虑交通流量预测的稳健性能时,应首先检验这些变量之间的关系,而不是随机选择交通变量进行预测。由于本研究包含三个交通变量,因此需要探讨如何选择响应变量和解释变量(预测变量)。换句话说,我们需要确定所选的响应变量是否能够利用相应的预测变量得到良好预测。因此,我们使用VAR模型来检验这些变量之间的可预测关系。
VAR模型是一种计量经济学模型,它利用模型中的所有当前变量对若干个滞后变量进行回归分析。该模型通常用于估计联合内生变量的动态关系,且无需任何先验约束。VAR模型是基于数据的统计特性构建的。其原理是将每个内生变量作为其滞后值的函数来构建模型,从而将单变量自回归模型扩展为由多时间序列变量组成的“向量”自回归模型。VAR模型表达式如下。
$$
y_t= c+ A_1y_{t−1}+ A_2y_{t−2}+…+ A_p y_{t−p}+ \xi_t
$$
其中 $y_t$ 是内生变量的向量,$p$ 为滞后阶数,$c$ 是 $n×1$ 常数向量,且 $A$ 是一个 $n×n$ 矩阵,$\xi_t$ 是 $n×1$ 误差向量。VAR模型在实际应用中通常被转化为矩阵形式。例如,上述VAR(p)模型可表示如下(考虑滞后阶数为2,即VAR(2)):
$$
\begin{bmatrix}
y_{1,t} \
y_{2,t}
\end{bmatrix}
=
\begin{bmatrix}
c_1 \
c_2
\end{bmatrix}
+
\begin{bmatrix}
A_{1,1} & A_{1,2} \
A_{2,1} & A_{2,2}
\end{bmatrix}
\begin{bmatrix}
y_{1,t−1} \
y_{2,t−2}
\end{bmatrix}
+
\begin{bmatrix}
\zeta_{1,t} \
\zeta_{2,t}
\end{bmatrix}
$$
VAR模型在建模过程中需要确定两个指标:一是变量数量,因为需要识别哪些变量相互关联,并将这些变量纳入VAR模型中;二是自回归最大滞后长度,因为选择合理的滞后阶数能够较好地反映变量之间的关系。应在VAR模型中选择具有相关性的变量作为解释变量,并采用格兰杰因果检验来判断这些变量之间是否存在相关性。格兰杰因果检验的机制如下:对于两个服从平稳随机过程的时间序列(例如X、Y),如果利用X和Y的历史数据对Y进行预测的效果优于仅使用Y自身历史数据的预测效果,则认为X有助于提高对Y的预测精度,即X对Y存在因果关系。
VAR模型是一种用于分析和预测多个相关指标的有效模型。在本研究中,我们构建VAR模型来分析多个相关的交通指标,并检验所选的响应变量是否受到其他内生变量的影响。VAR模型要求所有变量均为平稳时间序列,因此应首先进行单位根检验以测试其平稳性。然后根据AIC、SC和LR的综合评估结果确定滞后阶数。接着进行变量外生性检验和VAR模型稳定性检验,从而识别变量间的可预测关系。最后分别进行脉冲响应和方差分解,以进一步分析内生变量对响应变量的解释程度。VAR模型的建模过程包括单位根检验、滞后阶数确定、变量外生性检验、模型稳定性检验、脉冲响应和方差分解等步骤,如图2所示。
B. 长短期记忆神经网络模型
长短期记忆神经网络是一种特殊的循环神经网络(RNN),能够学习长期依赖关系[66], ,其隐藏层具有复杂的结构(即LSTM单元)[67]。LSTM单元包含三个门:输入门、遗忘门和输出门,如图3所示。
这些门控单元控制着信息流在单元和神经网络中的传递。假设输入为 $x_t$,隐藏层输出为 $h_t$,则 $h_{t−1}$ 是该隐藏层的前一时刻输出。$C_{t−1}$ 为单元输入状态,则细胞输出状态及其前一时刻分别为 $C_t$、$C_{t−1}$。这三个门分别是 $i_t$、$f_t$ 和 $o_t$。这些门的方程为:
$$
i_t = \sigma(w_{i1} \cdot x_t + w_{ih} \cdot h_{t−1} + b_i)
$$
$$
f_t = \sigma(w_{f1} \cdot x_t + w_{fh} \cdot h_{t−1} + b_f)
$$
$$
o_t = \sigma(w_{oh} \cdot h_{t−1} + b_o)
$$
$$
C_t’ = \tanh(w_{ch} \cdot h_{t−1} + b_c)
$$
其中,$i_t$、$f_t$、$o_t$、$C_t’$ 分别为输入门、遗忘门、输出门和单元输入。$w_{i1}$、$w_{f1}$、$w_{c1}$ 是连接 $x_t$ 到三个门和单元输入的权重矩阵。同样地,$w_{ih}$、$w_{fh}$、$w_{oh}$ 和 $w_{ch}$ 是连接 $h_{t−1}$ 到三个门和单元输入的矩阵。$b_i$、$b_f$、$b_o$ 和 $b_c$ 是三个门和单元输入的偏置项。 $\sigma$ 表示标准Sigmoid函数。$\tanh$ 是双曲正切函数。
$$
\sigma = \frac{1}{1+ \exp(−x)}
$$
$$
\tanh = \frac{\exp(x) − \exp(−x)}{\exp(x)+ \exp(−x)}
$$
LSTM单元输出 $C_t$ 表达如下。
$$
C_t = i_t × C_t’ + f_t × C_{t−1}
$$
其中 $i_t$、$f_t$、$C_t’$、$C_{t−1}$ 和 $C_t$ 具有相同的维度。
最后,隐藏层输出可以表示为:
$$
h_t = o_t × \tanh(C_t)
$$
对于交通流量预测,LSTM预测机制可以描述如下。在时间 $t$,将输入(即历史数据 $x_t$)提供给LSTM网络,则其未来趋势的输出为 $x_{t+1}’$,基于 $h_t$ 的方程,可计算出网络输出。
$$
x_{t+1}’ = w_2 \cdot h_t + b
$$
其中 $w_2$ 是输出层与隐藏层之间的权重矩阵,$b$ 是输出层的偏置项。
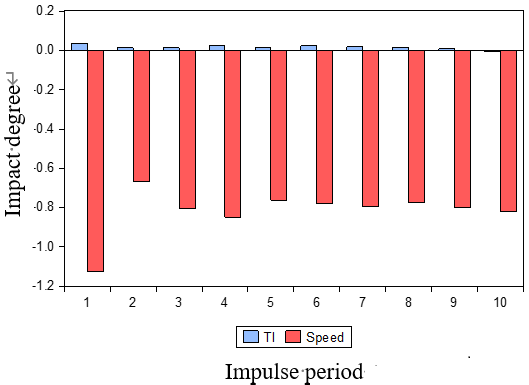
图4展示了长短期记忆神经网络预测的结构,其中我们使用N个历史数据来输入交通流量序列到长短期记忆神经网络中。随后,历史信息通过循环计算在网络中传递,预测则从网络状态中吸收长短时记忆。
C. CNN-LSTM混合神经网络模型
从上述关于LSTM网络的描述可知,由于LSTM网络模型具有长期记忆功能,适用于长时间序列数据的预测,但在提取数据的复杂空间特征方面能力较差。为了弥补这一缺陷,通常将具备较强空间特征分析能力的CNN模型与LSTM网络结合。一些研究已将这种混合CNN‐LSTM模型应用于飞行数据的故障诊断以及股票价格预测[68],[69]。考虑到CNN网络模型和LSTM网络模型各自的优势,我们采用CNN‐LSTM混合神经网络模型[69],利用多特征对短期交通流量进行预测。在该混合模型中,使用注意力机制将CNN模型和LSTM模型作为两个通道进行融合,进而预测交通流量数据的复杂时空特性。相比单一LSTM模型和CNN模型,CNN‐LSTM混合模型具有更强的时空分析能力,其混合模型结构如图5所示。
在图5中,$P_n$ 是输入样本的第n个交通参数(共有三个交通参数,分别为速度、交通量和TI),$T$ 是样本的时间段,$F_{nr}$ 是提取出的第n个特征向量,$h_{nf}$ 是第n个隐藏层的输出。输入样本包括左通道和右通道,其中左通道为CNN网络。CNN网络输出的最后一层是1× n维特征向量,如下所示。
$$
F_r = [f_{1r}, f_{2r}, f_{3r},… f_{nr}]
$$
右通道是LSTM网络,序列长度为n,则LSTM隐藏层的输出维度为m。最终得到 $n × m$ 特征向量,如下所示。
$$
H_f = [h_{1f}, h_{2f}, h_{3f},… h_{nf}]
$$
在获得CNN网络和LSTM网络的样本特征后,使用注意力机制来融合这些特征。注意力结构如图6所示。通过注意力机制对LSTM网络和CNN网络的融合过程可表示为公式(15)‐(17)。
$$
\phi(h_{nf}, F_r) = \tanh(h_{nf} \cdot w_a \cdot F_r^T + b_a)
$$
$$
\alpha_i = \frac{\exp(\phi(h_{if}, F_r))}{\sum_{j=1}^{n} \exp(\phi(h_{jf}, F_r))}
$$
$$
f_{map} = \sum_{i=1}^{n} \alpha_i h_{if}
$$
其中,$w_a$ 是 $n × m$ 权重矩阵,$b_a$ 是从训练过程中获得的偏置项,$F_r^T$ 是 $F_r$ 的转置。卷积神经网络和LSTM网络的特征向量通过公式(15)融合为一组权重向量,然后通过公式(16)将权重在 $[0, 1]$ 范围内进行标准化。最终特征(即 $f_{map}$)由隐含层输出(即 $h_{if}$)与对应权重(即 $\alpha_i$)的乘积表示。通过上述融合过程,混合CNN‐LSTM模型能够体现CNN模型和LSTM模型的能力。
第四部分. 结果
A. 向量自回归模型结果
1) 单位根检验 :ADF检验是一种常用的单位根检验方法,用于检验交通指数、速度和交通量的平稳性。ADF检验的基本原理是利用一阶自回归方法构建生成序列数据的处理过程,然后模型表示如下。
$$
x_i = \beta x_{i−1} + \varepsilon_i, i= 1, 2, 3,···
$$
其中 $\varepsilon_i$ 是满足独立同分布的随机误差。实证模型如下方程所示。
$$
X_i = \alpha + \delta X_{i−1} + \mu_i
$$
在传统的平稳性假设检验中,使用假设 $H_0: \delta= 0$ 和 $H_1: \delta< 0$ 进行分析。ADF检验利用泛函中心极限定理推导出两个统计量,并获得显著性检验的新临界值。然后将统计量与临界值进行比较,对假设 $H_0: \delta= 0$ 做出判断。当t统计量的值分别大于1%、5%和10%水平下的临界值时,接受原假设,则该数据序列为非平稳过程;否则为平稳过程。ADF检验中常用的三种实证模型包括:含截距模型(模型1)、包含截距和趋势的模型(模型2)以及不含截距和趋势的模型(模型3)。这三种模型在进行ADF检验时均需满足统计要求。
以一天的交通数据为例,对交通指数(TI)、速度和交通量的平稳性进行检验。图7(a)展示了一天内交通参数的时间序列。这些时间序列的波动不稳定,尤其是在高峰时段,呈现出非平稳的特征。为此进行了ADF检验,结果如表I所示。根据ADF检验结果,TI、速度和交通量三个模型的t统计量均大于临界值1%水平、5%水平和10%水平的值,因此原始数据是非平稳序列。
为满足VAR模型的要求,我们对原始数据进行了一阶差分的平稳性处理。处理后,三个交通参数的时间序列如图7(b)所示。这些数据的新分布围绕0上下波动,波动范围相对稳定,符合平稳时间序列的特征。随后进行新的ADF检验以验证其平稳性。这三个交通参数模型的ADF检验统计量均小于1%、5%和10%水平下的临界值,且概率在5%置信水平下也显著,表明新的数据序列是平稳时间序列,结果如表II所示。
表I 原始数据的ADF检验结果(5%置信水平)
表II 一阶差分后数据的ADF检验结果(5%置信水平)
2) 滞后阶数确定 :在确定滞后阶数时,应同时考虑AIC信息准则、SC信息准则和LR统计量。使用Eviews软件确定最佳滞后阶数。结果表明,当滞后阶数为3时,AIC信息准则、SC信息准则和LR统计量均显著,如表III所示。因此,本研究选择“3”作为最佳滞后阶数。
表III VAR模型中滞后阶数的确定
3) 变量外生性与模型稳定性检验 :采用格兰杰因果检验分析交通变量的外生性。结果如表IV‐VI所示。结果表明,速度和交通量对交通指数(TI)的预测能力相对较弱(见表IV)。相比之下,TI和交通量对速度具有较好的预测能力(见表V),TI和速度对交通量也表现出良好的预测性能(见表VI)。由此推断,这三个变量整体上具有相互内生性。因此,
表IV 交通指数的格兰杰因果检验
使用这三个交通参数构建VAR模型。速度和交通量可分别作为响应变量,其他变量为解释变量。
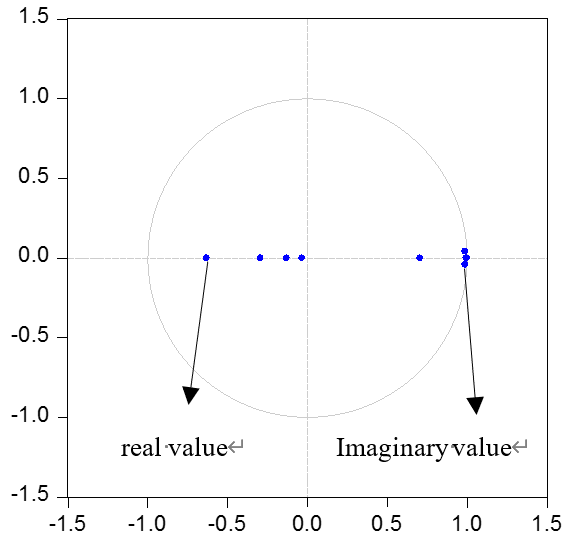
然后我们使用AR根图像来识别VAR模型的稳定性,见图8。蓝色点表示特征根。当点位于水平线上时,特征根为实数。否则,它们为虚数。当所有特征根都在单位圆内时,模型是稳定的。否则,模型是不稳定的。从图8可以看出,所有特征根都位于单位圆内,因此所建立的VAR模型是稳定的。
短时交通流预测:一种计量经济学与混合深度学习相结合的集成方法
IV. 结果
A. 向量自回归模型结果(续)
表V 速度的格兰杰因果检验
表VI 交通量的格兰杰因果检验
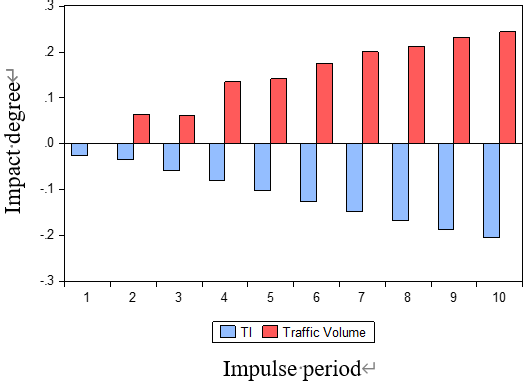
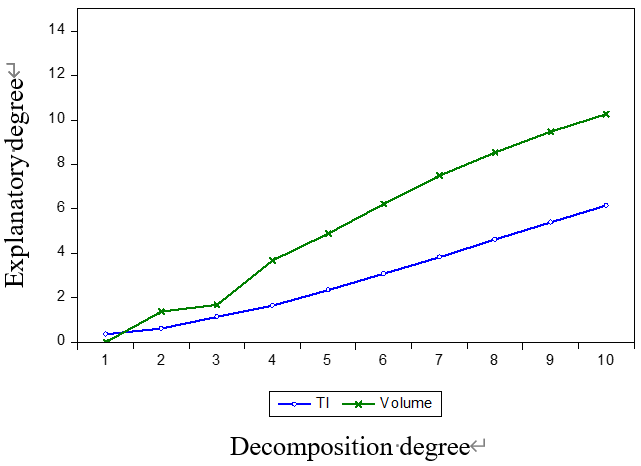
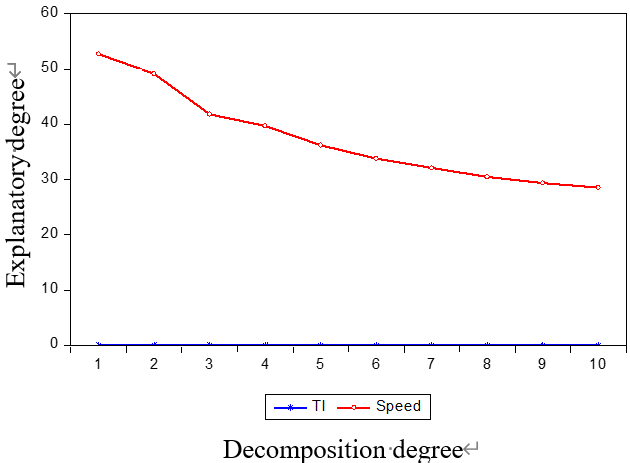
4) 脉冲响应和方差分解 :脉冲响应和方差分解进一步分析了解释变量对响应变量的影响。我们选择速度(对应的解释变量为TI和交通量)和交通量(对应的解释变量为TI和速度)作为响应变量。脉冲响应和方差分解的结果如图9、10所示。
当速度为响应变量时,交通指数和交通量对速度有显著影响。具体而言,交通指数对速度的影响为负,而交通量对速度的影响为正。影响程度随着脉冲周期的增加,表明交通指数和交通量能够很好地解释速度。当以交通量为响应变量时,速度对交通量有明显影响,但交通指数对交通量的影响较小,同时交通指数对交通量的影响也较弱。这些分析表明,在VAR模型中,最佳的响应变量应为速度,而交通指数和交通量可作为解释变量。只有在这种情况下,交通流量预测才是合理且稳健的。
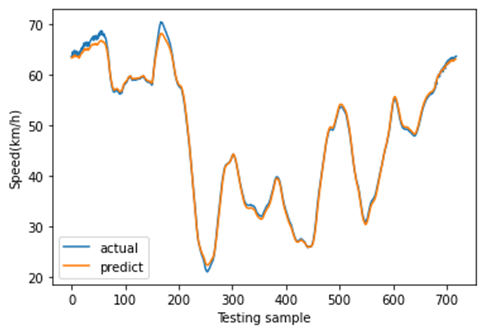
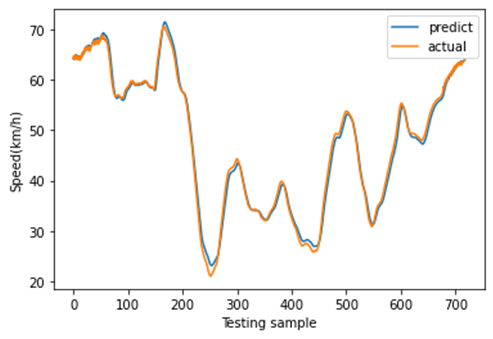
B. 单一空间位置的预测结果
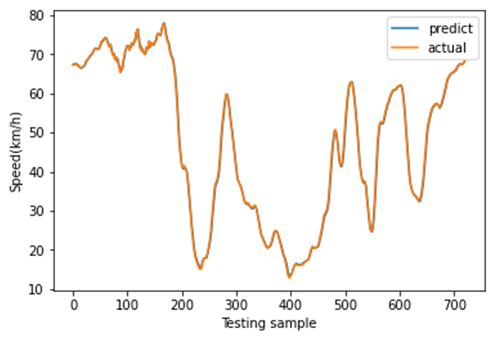
在使用深度学习模型进行速度预测时,提取了延安高架路在几个工作日(2018年8月27日至8月30日,分别为星期一至星期四)的交通数据。需要注意的是,本研究中的短时速度预测主要针对工作日。其中,8月27日的数据被选为测试样本,其余数据作为训练样本,测试样本与训练样本的比例为3:7。由于本研究的目的是利用多特征(如速度、交通指数和交通量)进行速度预测,这与以往仅使用单个特征(即速度)进行速度预测的研究不同。因此,分别进行了单特征预测和多特征预测,以比较两者之间的差异。具体而言,单特征预测指的是仅使用历史速度数据进行速度预测;而多特征预测主要是利用速度、交通指数和交通量的历史数据进行速度预测。
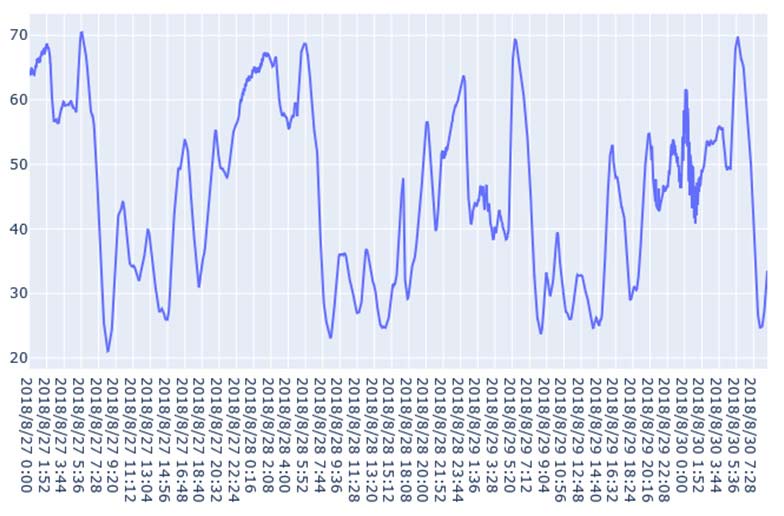
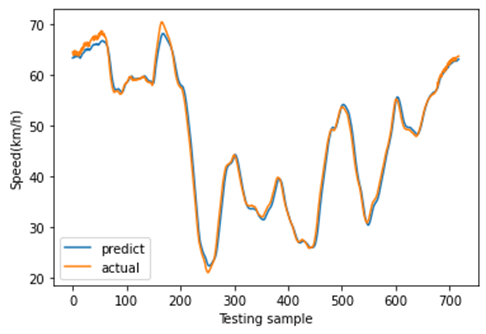
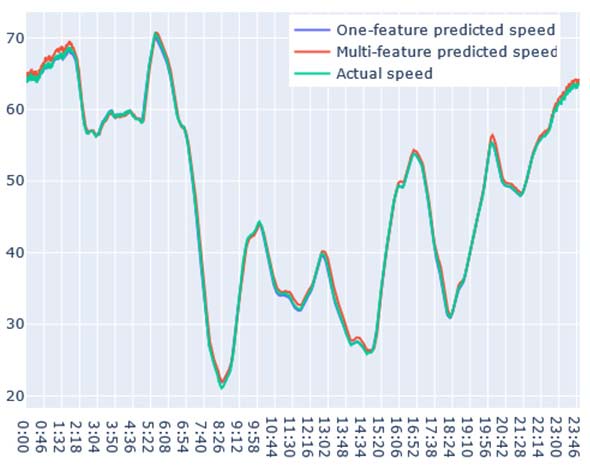
图11展示了8月27日(星期一)至8月30日(星期四)的速度分布。这是一个周期性时间序列,其变化趋势与实际情况一致。在本研究中,我们利用三个连续的历时段数据(即输入为:$x_{t−2}$、$x_{t−1}$、$x_t$)来预测未来一个时段的速度(即输出为:$x_{t+1}’$)。当观测值尚未获取时,预测速度将作为模型的输入。为了体现不同深度学习模型的预测结果差异,我们分别采用所提出的CNN‐LSTM模型、CNN模型、LSTM模型、堆叠LSTM和ConvLSTM模型对短时速度进行预测。其中,堆叠LSTM网络是一种针对复杂的序列预测问题的稳定技术,可进一步提升非线性拟合能力。堆叠LSTM架构可定义为由多个LSTM层组成的LSTM模型。ConvLSTM模型是一种时空模型,其将输入的卷积读取直接集成到每个LSTM单元中。随后,不同深度学习方法的预测结果如图12‐16所示。这些结果表明,使用多特征预测的预测结果比单特征预测更可靠,因为使用多特征预测的这些深度学习模型的预测曲线比单特征预测更接近实际曲线。此外,从这些预测结果可以看出,CNN‐LSTM模型的预测曲线与实际曲线的拟合程度优于其他深度学习模型,这表明使用CNN‐LSTM混合模型进行速度预测比其他流行的深度学习方法更符合实际情况。然后,图17展示了使用CNN‐LSTM混合模型进行的一天的速度预测。
从图17可以看出,使用单特征预测的速度略小于实际速度,且模型在2:00‐5:00和11:00‐18:00的拟合效果相对较差。而使用多特征进行速度预测的结果几乎始终与实际速度一致,且多特征预测的曲线比单特征预测更接近实际速度曲线。为进一步评估单特征预测、多特征预测以及不同深度学习模型的预测性能,计算了均方根误差(RMSE)、均方误差(MSE)和平均绝对误差(MAE)三项指标。不同深度学习方法的这些指标比较结果如表VII所示。多特征预测的三项指标均低于单特征预测,进一步证明了利用交通指数、交通量和速度的历史数据进行速度预测是一种具有前景的方法。值得注意的是,在使用单特征进行速度预测时,堆叠LSTM模型的性能优于LSTM模型;但在进行多特征预测时,堆叠LSTM模型相对较差。此外,时空模型(如CNN‐LSTM模型和ConvLSTM模型)的预测性能优于其他时空模型(LSTM模型、堆叠LSTM模型和CNN模型)。总体而言,不同深度学习模型的比较表明,所提出的CNN‐LSTM混合模型在短时速度预测方面优于其他深度学习模型。
上述分析表明,使用CNN‐LSTM混合模型进行多特征速度预测是可行的,能够较好地预测现实世界中的未来速度趋势。然而,目前尚不清楚所提出的深度学习方法在速度预测能力上是否优于其他非深度学习模型。为了验证这一点,我们还比较了CNN‐LSTM模型与其他预测模型(如线性回归模型、高斯过程回归模型、决策树模型和支持向量机模型)的多特征预测性能。如表VIII所示,结果表明CNN‐LSTM模型的性能优于其他模型。
$$
RMSE = \sqrt{\frac{1}{N} \sum_{i=1}^{N}(f(i) - y(i))^2}
$$
$$
MSE = \frac{1}{N} \sum_{i=1}^{N}(f(i) - y(i))^2
$$
$$
MAE = \frac{1}{N} \sum_{i=1}^{N}|f(i) - y(i)|
$$
其中 $f(i)$, $y(i)$ 分别为样本 $i$ 的真实值和预测值,$N$ 为样本数量。
表VII 不同深度学习方法的预测性能比较
表VIII CNN‐LSTM模型与其他模型的比较
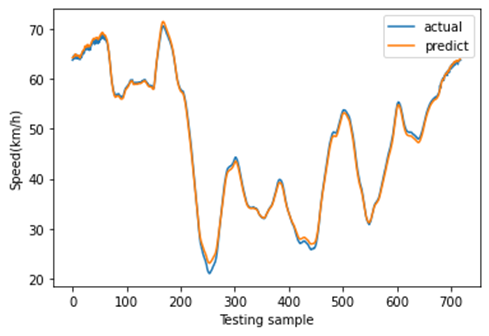
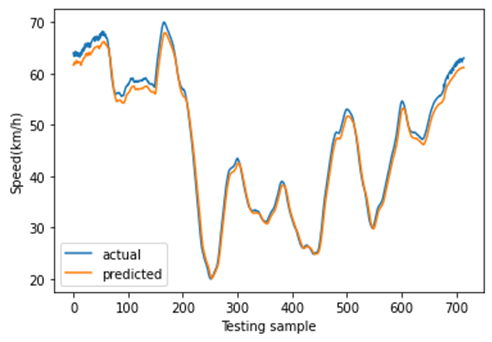
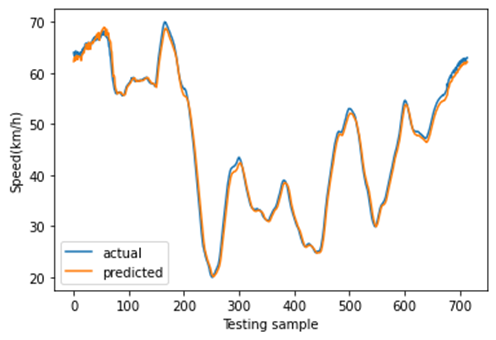
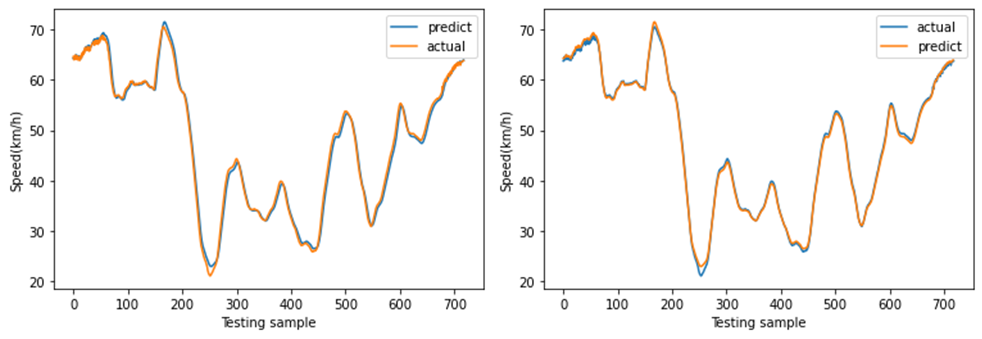
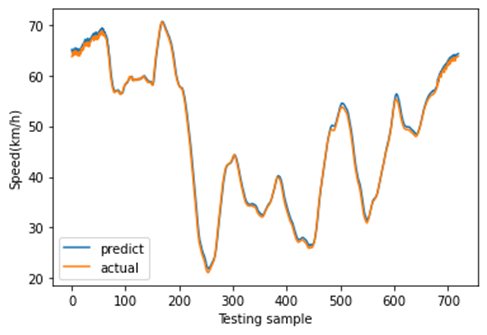
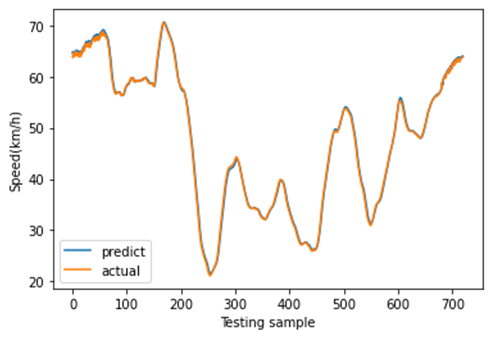
C. 不同空间位置的CNN-LSTM预测
上述预测主要针对一个地点(即“虹井路‐红徐路”)的速度预测。在实际应用中,需要对不同空间位置的交通流量进行预测,因为多组空间位置的交通流量预测有助于大规模路网的出行信息发布和交通拥堵管理。因此,除了上述“红景路‐红徐路”的交通流量预测外,还基于CNN‐LSTM模型采用多特征预测方法对其余六个路段的速度进行了预测。
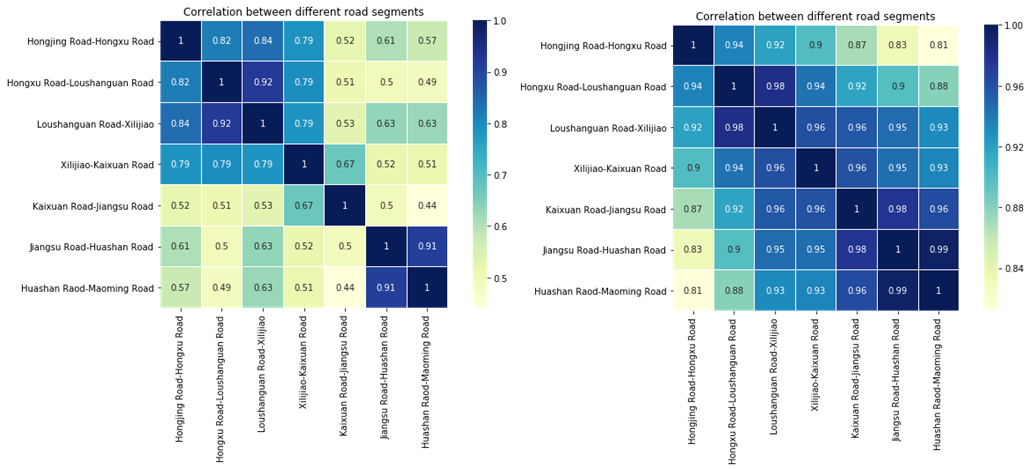
Ma等[70]研究了多组空间位置的交通预测,并提供了充分证据证明空间相关性对预测准确性的重要性和有效性。基于此,首先对七个路段的交通流量空间相关性进行检验。由于延安城市快速路(包含这七个路段)的交通指数(TI)是统一的,因此只需检验这些不同路段的速度和交通量的空间相关性(见图18)。结果表明,前四个路段(即红景路‐红徐路、红徐路‐娄山关路、娄山关路‐西立交和西立交‐凯旋路)之间的交通流空间相关性较高;后三个路段(即凯旋路‐江苏路、江苏路‐华山路和华山路‐茂名路)之间的交通流空间相关性也较高。然而,前四个路段与后三个路段之间的交通流空间相关性相对较低。
由于这些差异,不同路段的预测准确性可能有所不同。为验证这一点,使用所提出的CNN‐LSTM模型对不同空间位置进行多特征预测,如图19所示。相应的预测误差如表IX所示。从结果可以看出,前四个路段(包括红景路‐红徐路、红徐路‐娄山关路、娄山关路‐西立交和西立交‐凯旋路)之间的预测误差较为接近,且高于后三个路段(包括凯旋路‐江苏路、江苏路‐华山路和华山路‐茂名路)。同时,后三个路段之间的预测误差也彼此相似,且相对低于前四个路段。这些结果与不同位置交通流量的空间相关性一致,符合[70]的结果。该发现应在采取交通管理措施时作为重要考虑因素。
表IX 不同空间位置的预测误差
D. 预测结果可视化
上述结果表明,所提出的CNN‐LSTM网络模型能够以较低的误差预测短期交通流量。为了充分利用不同路段的预测结果并将其应用于实际交通管理,提出了一种时空热力图来可视化预测速度。我们选择一天中不同时段(从0:00到23:00)作为时间尺度,空间范围包括七个路段。然后通过热力图对平均预测速度进行可视化,如图20所示。
从热力图可以看出,不同时段和路段的速度分布各不相同,体现了不同的交通状况。具体而言,这些路段在10:00‐17:00期间的速度较低,而在其他时段则相对较高。这表明10:00‐17:00期间的交通状况可能较差,这与延安城市快速路的午间高峰时段(14:00‐16:00)和晚间高峰时段(16:00‐18:59)的情况一致。总体来看,早高峰时段(7:00‐9:59)的速度较为流畅,反映出延安城市快速路在早晨的路况优于其他时段。
这些路段中大部分的速度分布相似,表明交通状况相同。但凯旋路‐江苏路的情况与其他路段不同,该路段全天车流畅通,无拥堵现象,因此路况优于其他路段。延安城市快速路的路况从畅通到拥堵的排序为:虹许路‐娄山关路、西利交路‐凯旋路、娄山关路‐西利交路、江苏路‐华山路、虹井路‐虹许路、华山路‐茂名路和凯旋路‐江苏路。基于上述分析,可通过该可视化热力图评估交通状况的未来趋势,有助于交通拥堵管理。
V. 讨论与结论
可靠的交通流量预测为发布实时出行信息和缓解交通拥堵提供了依据,在交通管理中发挥着至关重要的作用。本研究提出了一种基于计量经济学和深度学习理论的短期交通流量预测框架。引入VAR模型以研究延安城市快速路交通变量之间的可预测关系。VAR模型结果表明,交通指数(TI)和交通量在速度预测方面具有优异的能力。因此,选择速度作为响应变量(即目标预测变量),TI和交通量作为解释变量。由此,本研究中的短期交通流量预测问题转化为基于多特征(如速度、TI和交通量)的速度预测问题。
在分析了交通变量之间的关系后,提出了一种混合CNN‐LSTM网络模型,利用速度、交通指数(TI)和交通量的历史数据来预测短时速度。对比了单特征预测与多特征预测,结果表明使用多特征的预测效果优于单特征预测。除了单特征预测与多特征预测的比较外,还对不同模型以及不同空间位置的预测结果进行了比较。结果表明,所提出的CNN‐LSTM模型在速度预测方面优于其他深度学习和机器学习方法。同时,该预测准确性与交通流量的空间相关性相关。因此,采用多特征预测的CNN‐LSTM网络模型在延安城市快速路短期交通流量预测中被证明是一种有前景的方法。随后研究了时空速度热力图,为出行信息发布和交通拥堵管理提供了可视化指导。
本研究提出的方法和获得的结果具有理论研究价值和重要的工程意义。利用计量经济理论进行的整套预测分析可增强短时交通流预测的鲁棒性,并能清晰解释交通变量之间的可预测关系。随后,开发了一种混合深度学习方法,利用历史速度、交通指数(TI)和交通量对多地点群组的短时速度进行预测。采用该混合深度学习方法实现的多特征与多地点速度预测,有利于精细化交通管理,为未来研究奠定了基础。此外,研究成果有助于深入理解如何有效评估和可视化城市快速路交通流量,推动交通拥堵干预措施的实施以及出行信息的发布。例如,预测的交通流量结果可用于基于现代计算机技术生成动态交通状态图,并将该动态图与智能交通系统(ITS)连接。交通管理者可通过交通状态图了解哪些时段和地点发生拥堵,进而采取相应的控制措施,从而有助于出行和拥堵管理。
然而,在将本研究结果应用于理论研究和工程实践之前,仍需进行一项工作。本研究中使用的交通指数(TI)是指上海标准,该标准由上海市政府提出,并已成功应用于评估上海市的道路交通运行状况。由于中国各城市交通状态标准不同,交通指数的定义也可能存在差异,这将影响结果,因此该指标在其他中国城市的适用性仍有待探讨。为此,作者建议未来的研究应解决这一问题。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)