
算力和GPU卡(入门整理贴)
算力和GPU卡(入门整理贴)
一、基本概念
-
GPU(GraphicsProcessingUnit)是一种专门用于处理图形和并行计算的处理器,最初是为加速计算机图形渲染而设计的。但由于其并行计算的架构(拥有成千上万个核心,能同时处理大量简单任务),人们发现它在处理非图形任务,特别是人工智能、科学计算等领域,效率远超CPU。因此,GPU演变成了通用的并行计算处理器,一般我们将“并行计算能力”称为“GPU算力”。
-
算力卡相当于阉割版的GPU卡(专门用于提供计算能力的扩展卡,算力卡没有对外视频输出信号,是专门用来做数据计算和服务深度学习工作。),或者通指一种服务或资源,指在云端租用的、包含GPU的计算能力,它在计算机系统中扮演着“计算引擎”的角色。这种卡片的核心特点是拥有大量的计算核心,能够并行处理多个计算任务,从而实现高效的计算加速。
-
本文内容整编自
-
CSDN|算力与GPU卡入门解析|晚安是一只小猫
-
知乎|大模型涉及到的精度有多少种?FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8都有什么关联,一文讲清楚|一步留神
-
联泰集群|DeepSeek 算力平台推荐方案
(一)算力的单位-(FLOPS)
FLOPS(全称Floating-Point Operations Per Second),意为每秒浮点运算次数,是算力的一种常见衡量单位,表示每秒能够进行的浮点运算次数。算力单位中,FLOPS可以有多种表示,如TFLOPS(百万亿次浮点运算每秒)和EFLOPS(亿亿次浮点运算每秒)。
(二)计算精度
衡量算力的参数不止看每秒运算次数,还需要关注FP即浮点运算数据格式,FP包含双精度(FP64)、单精度(FP32)、半精度(FP16)以及FP8等,INT代表整数格式,包括INT8、INT4等。总的来说,后面的数字位数越高,意味着精度越高,能够支持的运算复杂程度就越高,适配的应用场景也就越广,但更高的精度也会带来更高的计算和存储成本,较低的精度会降低计算精度,但可以提高计算效率和性能。所以多种不同精度,需要在不同情况下选择最适合的一种。
FP精度
Floating Point,是最原始的,IEEE定义的标准浮点数类型。由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。
FP64,是64位浮点数,由1位符号位,11位指数位和52位小数位组成。FP32、FP16、FP8、FP4都是类似组成,只是指数位和小数位不一样。
双精度(Fp64):浮点数使用64位表示,提供更高的精度和动态范围。通常在需要更高精度计算的科学和工程应用中使用,相对于单精度,需要更多的存储空间和计算资源。
单精度(Fp32):浮点数使用32位表示,具有较高的精度和动态范围,适用于大多数科学计算和通用计算任务。通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32,应用上往往有AI大模型、自动驾驶、智慧城市等需要学习大量数据、训练复杂的深度学习模型。
半精度(FP16):浮点数使用16位表示,相对于FP32提供了较低的精度,但可以减少存储空间和计算开销。按照理论来说可以跑机器学习这些任务,但是FP16会出现精度溢出和舍入误差,所以很多应用都是使用混合精度计算的也就是FP16+FP32模式,简单来说FP16其实在图像处理有更大优势点。
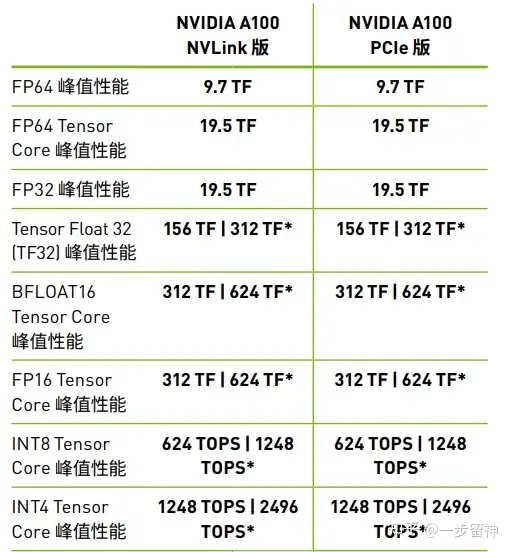
A100在不同精度下的算力差别
特殊精度
TF32:Tensor Float 32,英伟达针对机器学习设计的一种特殊的数值类型,用于替代FP32。首次在A100 GPU中支持。由1个符号位,8位指数位(对齐FP32)和10位小数位(对齐FP16)组成,实际只有19位。在性能、范围和精度上实现了平衡。
固定点数(INT8):固定点数使用固定的小数点位置来表示数值,可以使用定点数算法进行计算。INT8与FP16、FP32的优势在于计算的数据量相对小,计算速度可以更快,并且能通过减少计算和内存带宽需求来提高能耗。
多精度和混合精度
多精度计算,是指用不同精度进行计算,在需要使用高精度计算的部分使用双精度,其他部分使用半精度或单精度计算。
混合精度计算,是在单个操作中使用不同的精度级别,从而在不牺牲精度的情况下实现计算效率,减少运行所需的内存、时间和功耗
不同的量化精度
量化的概念:一般情况下,精度越低,模型尺寸和推理内存占用越少,为了尽可能的减少资源占用,量化算法被发明。FP32占用4个字节,量化为8位,只需要1个字节。常用的是INT8和INT4,也有其他量化格式(6位、5位甚至3位)。具体量化算法实现细节,请查考知乎|大模型涉及到的精度有多少种?FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8都有什么关联,一文讲清楚|一步留神
在2025中国算力大会开幕式上,《2025算力发展报告》发布。报告显示,截至今年6月底,我国在用算力中心机架总规模达1085万标准机架,智算规模达788 EFLOPS(FP16),基础设施建设增质提速。
(三)硬件基础
1.流处理器数量:相当于GPU的胳膊腿数量,数量越多,表示能同时干活的“小人儿”就越多,算力理论上也就越大。一般主流的高性能GPU,流处理器数量能到几千个,有的甚至能到上万个。
2.显存与带宽:显存是GPU干活时临时放数据和工具的“工作台”,显存越大,能同时摆下的数据就越多,就不用老来回从电脑内存调取,省事多了;而“带宽”,就是数据 在GPU和显存之间跑的速度快慢,如果带宽不够,工人们(流处理器)手头没数据了,干等着也就白费力气,所以显存大小和带宽高低要搭配着看才行。
3.核心频率:主频高,代表单个流处理单元干活时的“手脚麻利程度”,但是,频率也不是越高就越好,还得平衡发热、耗电这些问题,得找个中间的平衡点才行。
二、常见产品及应用方案
(一)国内的厂商及产品
宝德、星环科技、五十二所、紫光恒越、中科曙光、重庆江锋智能科技、重庆电信、联想
宝德:
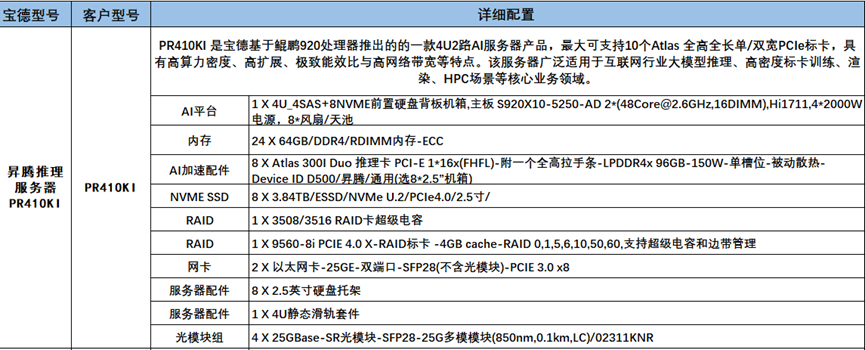
CPU:两颗鲲鹏920系列处理器,单颗48核,共96核,2.6主频,ARM架构共96线程 GPU:8张Atlas 300I DUO推理卡,单卡算力140TFLOPS(半精度),算力共1120TFLOPS,显存共769GB 内存:1536 存储:共30.72TB固态
CPU:两颗鲲鹏920系列处理器,单颗48核,共96核,2.6主频,ARM架构共96线程 GPU:8张Atlas 300I DUO推理卡,单卡算力140TFLOPS(半精度),算力共1120TFLOPS,显存共769GB 内存:1536 存储:共30.72TB固态
星环科技: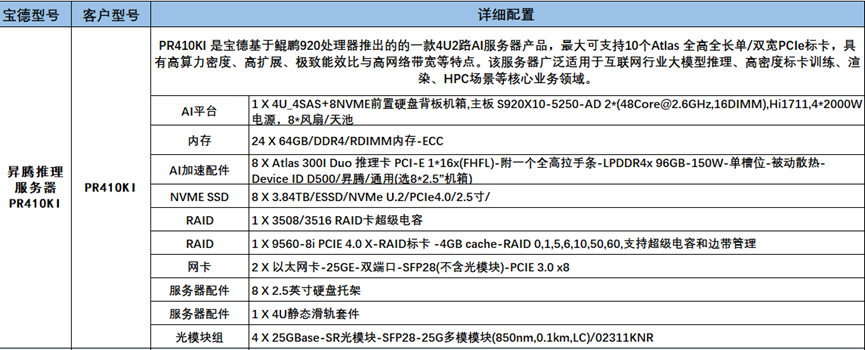
CPU:两颗海光7380系列处理器,单颗32核,共64核,2.2主频,X86架构共128线程 GPU:4张海光DCU K100-AI,单卡算力峰值150TFLOPS(半精度),算力共600TFLOPS,显存共256GB 内存:512GB 存储: 23.04固态,1.92T机械。
五十二所:
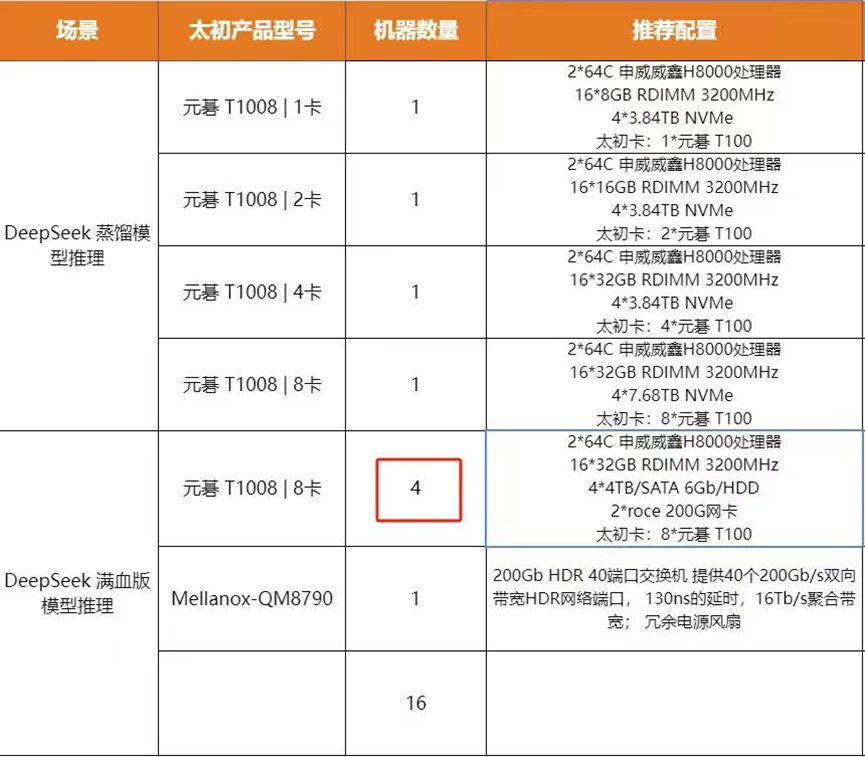
CPU:两颗申威威鑫H8000处理器,单颗64核,共128核,2.0-2.2主频,申威自主指令集架构 SW64,最高共256线程 GPU:4张元碁T100,单卡算力峰值240 TFLOPS(半精度),算力共960TFLOPS,显存共256GB 内存:512GB 存储: 未知不清楚
紫光恒越:

CPU:两颗飞腾S5000C处理器,单颗64核,共128核,2.8主频, ARMv8.2 架构最高共256线程 GPU:2张天数智芯BI-V100,单卡算力205TFLOPS(半精度),算力共410 TFLOPS,显存共64GB 内存:512GB 存储:17.36TB 固态
(二)部署方案
以部署一个deepseek大模型算力平台建设为例:
DeepSeek 目前的主要模型及对应的参数量如下:
●DeepSeek-V3:2024 年 12 月 26 日发布,基于混合专家(MoE)架构,参数量 671B,每次推理仅激活 370 亿参数。
●DeepSeek-R1:2025 年 1 月 20 日发布,参数量 671B,是专注于推理任务的模型。
●DeepSeek-R1 蒸馏系列模型:基于 DeepSeek-R1 蒸馏得到,参数规模从 70B 到 1.5B 不等。
<aside>
**备注:**DeepSeek-R1 蒸馏系列模型是因为完整的满血版 DeepSeek-R1 参数量较大,需要更大的硬件资源。为了降低硬件要求,所以基于千问系列大模型和 llama 系列大模型。采用大模型蒸馏技术生成了 1.5B 到 70B 的 DeepSeek-R1 蒸馏系列模型。
</aside>
例如部署一个deepseek(14B)大模型并满足16个人同时访问(即=16),
- 所需算力 ≈ QPS × 单次推理计算量 × 冗余系数 ; 吞吐量(QPS,每秒查询数)= 16
- 单次推理计算量 ≈ 2 × 模型参数量
- 对于14B模型,参数量14e9,所以单次计算量 ≈ 2 * 14e9 = 28e9 FLOPs = 28 GFLOPs
- QPS=16
- 冗余系数=1.3
- 所以所需算力 ≈ 16 * 28e9 * 1.3 = 16 * 36.4e9 ≈ 582.4 GFLOPs/s
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)