
目标检测评价指标
目标检测评分标准IoU 大于指定阈值?学习完了transformer,用pytorch复现了nlp任务类别是否正确?confidence 大于指定阈值?
目标检测评分标准
-
IoU 大于指定阈值?学习完了transformer,用pytorch复现了nlp任务
-
类别是否正确?
-
confidence 大于指定阈值?
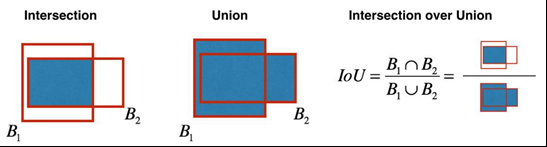
一、IoU(交并比)
1、IOU的全称为交并比(Intersection over Union),是目标检测中使用的一个概念,IoU计算的是“预测的边框”和“真实的边框”的交叠率,即它们的交集和并集的比值。
2、IoU等于“预测的边框”和“真实的边框”之间交集和并集的比值。IoU计算如下图,B1为真实边框,B2为预测边框。最理想情况是完全重叠,即比值为1。
二、TP、FP、FN
2.1 定义
T/F:表示预测的对错
P/N:表示预测的结果
目标检测中正负样本指的是模型自己预测出来的框与GT的IoU大于你设定的阈值即为正样本。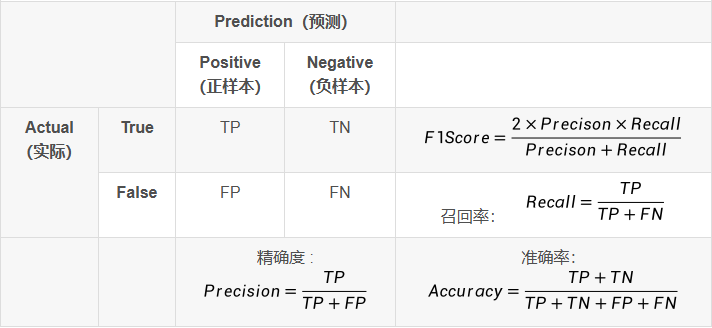
三、准确率(查准率)、召回率(查全率)、F1-Score

It is the harmonic mean of precision and recall. It takes both false positive and false negatives into account. Therefore, it performs well on an imbalanced dataset.它是精确率和召回率的调和平均值。它同时考虑了假阳性和假阴性。因此,它在不平衡数据集上表现良好。
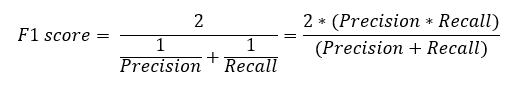
F1 score gives the same weightage to recall and precision.F1分数赋予召回率和准确率相同的权重。
There is a weighted F1 score in which we can give different weightage to recall and precision. As discussed in the previous section, different problems give different weightage to recall and precision.有一个加权的F1分数,我们可以给召回率和准确率赋予不同的权重。正如上一节所讨论的,不同的问题对召回率和准确率的权重不同。
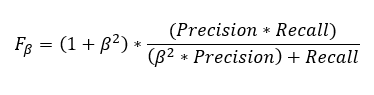
Beta represents how many times recall is more important than precision. If the recall is twice as important as precision, the value of Beta is 2.Beta表示召回率比准确率重要多少倍。如果召回率的重要性是准确率的两倍,则Beta值为2。
四、ROC曲线、P-R曲线
4.1 ROC曲线
在信号检测理论中,接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)是一种坐标图式的分析工具,用于 (1) 选择最佳的信号侦测模型、舍弃次佳的模型。 (2) 在同一模型中设定最佳阈值。
在衡量学习器的泛化性能时,根据学习器的预测结果对样本排序,按此顺序逐个把样本作为正例进行输出,每次计算测试样本的真正率TPR,和假正率FPR并把这两项作为ROC的纵轴和横轴.其中真正率衡量实际值为正例的样本中被正确预测为正例的样本的比例,假正率表示实际值为负例的样本中被错误的预测为正例的样本的比例

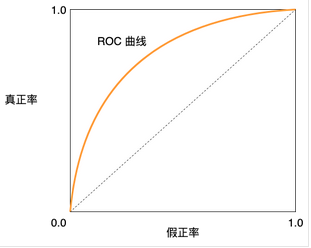
当上图中的ROC曲线接近于(1,0)点,表明模型泛化性能越好,越接近对角线的时候,表明此时模型的预测结果为随机预测结果。
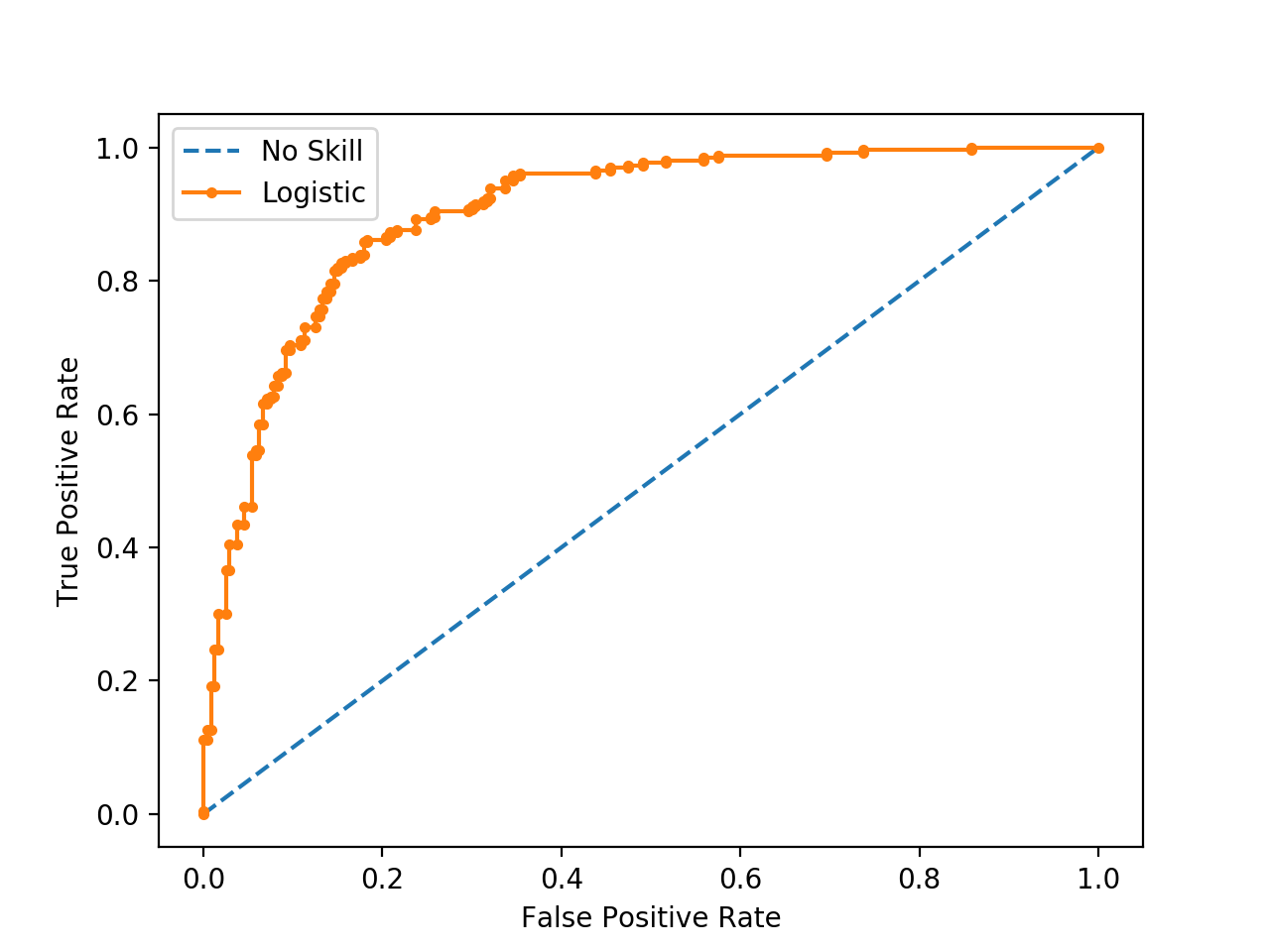
在实际中ROC曲线没有这么光滑,更多的会接近下图的样子,下图中的橙色曲线上每一个点对应于一个阈值下的真正率和假正率。
优点:
-
可以利用ROC曲线对不同模型进行比较,如果一个模型的ROC曲线被另一个模型的曲线完全包住,则可断言后者的性能由于前者。
-
ROC曲线下方的面积(AUC)可以用来作为评估模型模型性能的指标.如当两个模型的ROC曲线发生交叉,则很难说哪一个模型更好,这时候可以用AUC来作为一个比较合理的判据。
4.2 Precision-Recall (PR)
PR曲线常被用在信息提取领域,同时当我们的数据集中类别分布不均衡时我们可以用PR曲线代替ROC.PR曲线的横轴代表查全率,实际上就是真正率,纵轴代表查准率,表示预测为正例的样本里实际也为正例的样本所占的比例.对于查准率和查全率的理解可以参考我的上一篇博文机器学习--如何理解Accuracy, Precision, Recall, F1 score
与ROC曲线类似,我们根据学习器的预测结果对样例排序,"最可能"是正例的排在最前边或者说最左边,"最不可能"是正例的排在最后边或者说最右边.按此顺序逐个把样本作为正例进行输出,每次计算测试样本的查准率和查全率并把这两项作为PR曲线的纵轴和横轴.
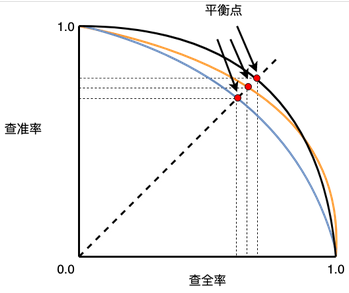
图片来源于周志华老师的<机器学习>一书.
当PR曲线越靠近右上方时,表明模型性能越好,与ROC曲线类似,在对不同模型进行比较时,若一个模型的PR曲线被另一个模型的PR曲线完全包住则说明后者的性能优于前者.如上图中橘色线代表的模型要优于蓝色线代表的模型,若模型的PR曲线发生了交叉,则无法直接判断哪个模型更好.在周志华老师的机器学习上中提到了可以用平衡点.它是查准率=查全率时的取值,如上图黑色线代表的模型的平衡点要大于橘色线模型代表的平衡点,表明前者优于后者,除此之外更为常用的是F1 score,也就是查准率和查全率的加权平均,F1 = (2*查准率*查全率)/(查准率+查全率)
4.3 如何选择
-
ROC曲线:如果我们的测试数据集类别分布大致均衡的时候我们可以用ROC曲线
-
PR曲线:当数据集类别分布非常不均衡的时候采用PR曲线
五、混淆矩阵

六、如何将YOLO在验证集上的评估结果转为COCO评估格式评估结果?
6.1 为什么要转换?
由于YOLO默认的评估指标(如mAP@0.5、mAP@0.5:0.95)与COCO官方指标(如AP、AP@[0.5:0.95])的计算逻辑存在差异。这种差异源于两者在PR曲线采样策略、交并比(IoU)阈值设定及多任务评价维度上的不同设计。例如:YOLO默认采用线性插值法生成PR曲线,而COCO评估工具(pycocotools)则优先匹配真实数据点,导致同一模型在不同框架下指标波动。
6.2 AP差异
6.2.1 PR曲线采样策略不同
-
YOLOv8-v12:在计算AP时,若某个召回率(Recall)采样点没有对应的精确率(Precision)真值,YOLO 会通过线性插值左右两个临近的真值点生成估算值。
-
pycocotools:遇到同样情况时,直接选择最接近采样点的真值点的精确率值,避免插值引入误差。
-
影响:当PR曲线波动较大时(尤其是小目标检测场景),插值法会平滑曲线,导致AP偏高或偏低,而pycocotools的“真值优先”策略更符合实际数据分布。
6.2.2 适用范围差异
pycocotools 是COCO官方评估工具,其方法被广泛认可为标准化指标计算方式,而YOLO的默认实现可能因插值导致横向对比偏差。
6.3 修改策略
找到AP计算部分(位于ultralytics/utils/metrics.py)的compute_ap函数中
elif method == "searchsorted":
q = np.zeros((101,))
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
inds = np.searchsorted(recall, x, side='left')
try:
for ri, pi in enumerate(inds):
q[ri] = precision[pi]
except:
pass
q_array = np.array(q)
ap = np.mean(q_array[q_array > -1])
注意:确保在调用AP计算时,设置method='searchsorted',禁用插值逻辑。
6.4 其他损失函数
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)