
【视频学习笔记】计算机视觉与深度学习_北京邮电大学_鲁鹏(⭐⭐⭐⭐⭐)
文章目录一、图像分类1. 什么是图像分类任务?2. 图像分类有哪些应用场合?3. 图像分类有哪些难点?(难点拆解)4. 基于规则的分类方法是否可行?5. 什么是数据驱动的图像分类范式?5.1 步骤5.2 分类器设计与学习5.2.1 图像表示5.2.2 分类器视频回顾相关课程:●CS131: Computer Vision: Foundations and Applications一Fall 201
【视频回顾】
相关课程:
●CS131: Computer Vision: Foundations and Applications一Fall 2018, Juan Carlos Niebles and Ranjay Krishna-Undergraduate introductory class
●CS231a: Computer Vision, from 3D Reconstruction to Recognition一Professor Silvio Savarese- Image processing, cameras, 3D reconstruction, segmentation, object recognition, scene understanding; not just deep learning
●CS 230: Deep Learning一Spring 2019, Prof. Andrew Ng and Kian Katanforoosh
●CS231n: Convolutional Neural Networks for Visual Recognition-Justin Johnson & Serena Yeung & Fei-Fei Li- Focusing on applications of deep learning to computer vision
一、图像分类
1. 什么是图像分类任务?
(根据图像特征,把图像区分开)
从已知的类别标签集合中为给定图片选定一个类别标签
2. 图像分类有哪些应用场合?


3. 图像分类有哪些难点?(难点拆解)

- 不同视角、光照、尺度、遮挡、形变、背景杂波、类内形变、动物模糊、类别繁多的影响

4. 基于规则的分类方法是否可行?
- 通过硬编码很困难
5. 什么是数据驱动的图像分类范式?
5.1 步骤
- 数据集构建
- 分类器设计与学习
- 分类器决策
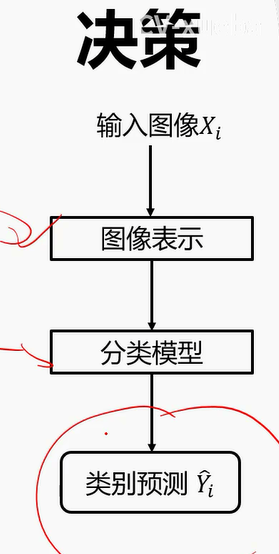
5.2 分类器设计与学习
5.2.1 图像表示
➢像素表示
➢全局特征表示(如GIST)(适用于风景类大场景)
➢局部特征表示(如SIFT特征+词袋模型)
5.2.2 分类器
(了解优势和劣势,遇到问题如何选择应用)
➢近邻分类器
➢贝叶斯分类器
➢线性分类器
➢支撑向量机分类器
➢神经网络分类器
➢随机森林
➢Adaboost
5.2.3 损失函数
➢0-1损失
➢多类支撑向量机损失
➢交叉熵损失
➢L1损失
➢L2损失
5.2.4 优化方法
➢一阶方法
●梯度下降
●随机梯度下降
●小批量随机梯度下降
➢二阶方法
●牛顿法
●BFGS
●L-BFGS
5.2.5 训练过程
➢数据集划分
➢数据预处理
➢数据增强
➢欠拟合与过拟合
➢减小算法复杂度
➢使用权重正则项
➢使用droput正则化
➢超参数调整
➢模型集成
6. 常用的任务评价指标
➢正确率(accuracy) =分对的样本数/全部样本数
➢错误率(error rate) = 1-正确率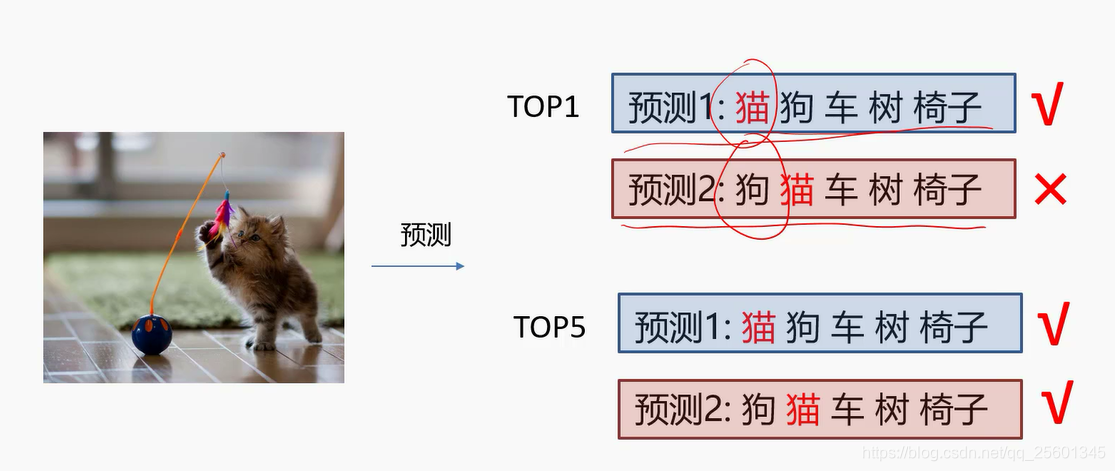
二、线性分类器
1. 数据集

2. 分类器设计
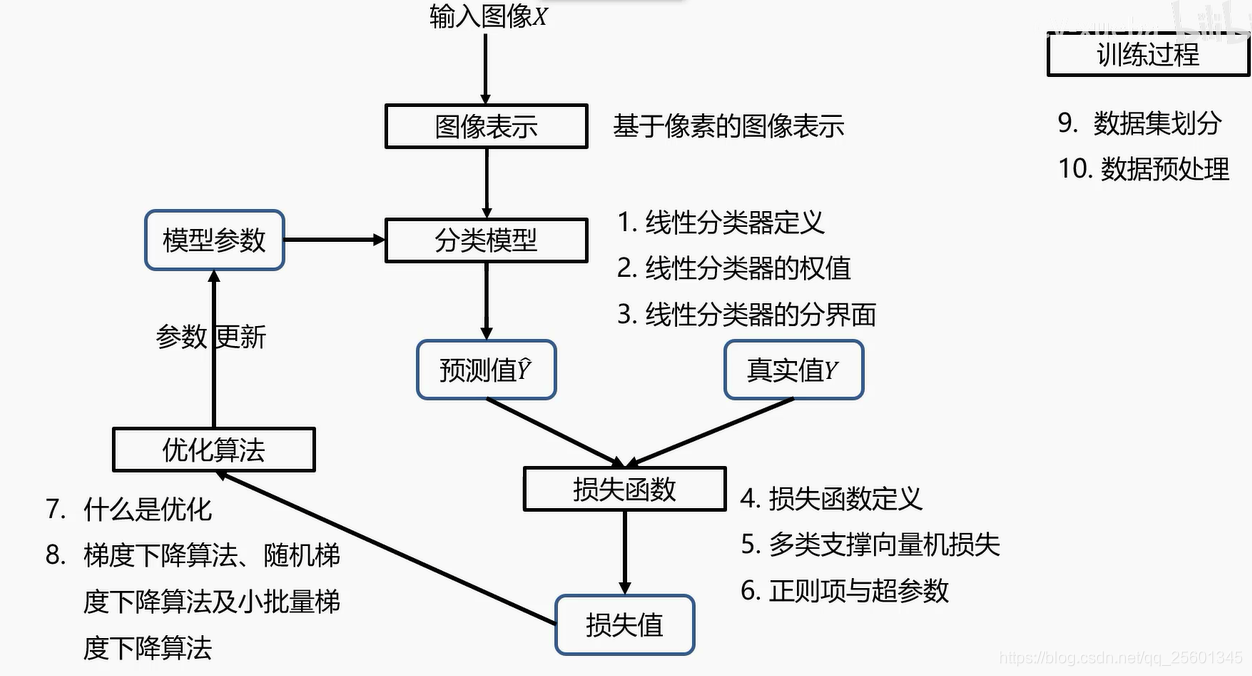
- 基于像素的图像表示
- 图像类型

- 二进制图像
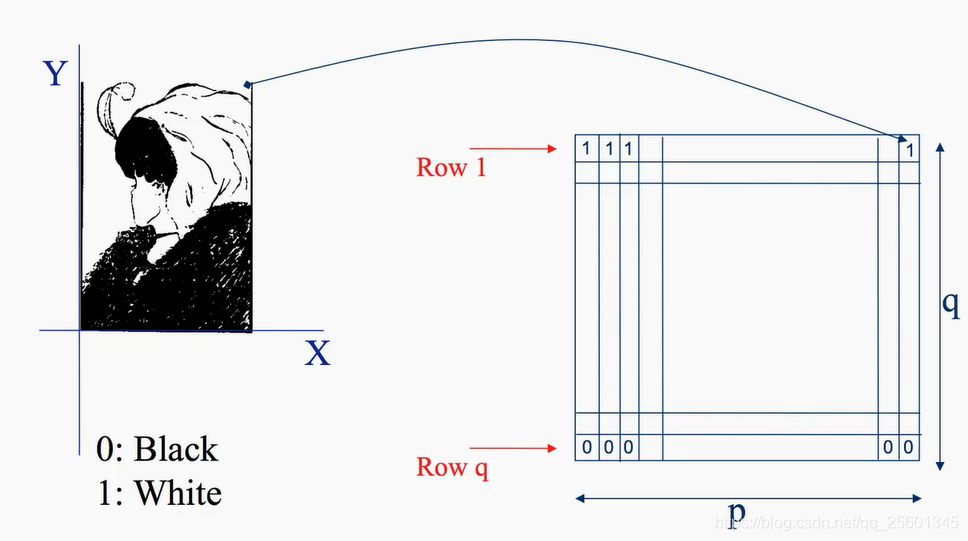
- 灰度图像
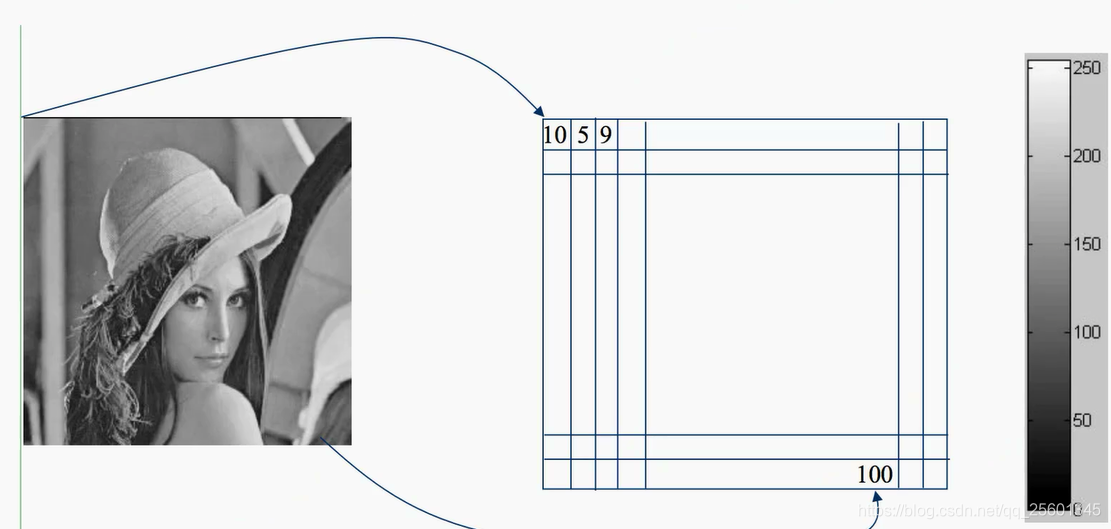
- 彩色图像

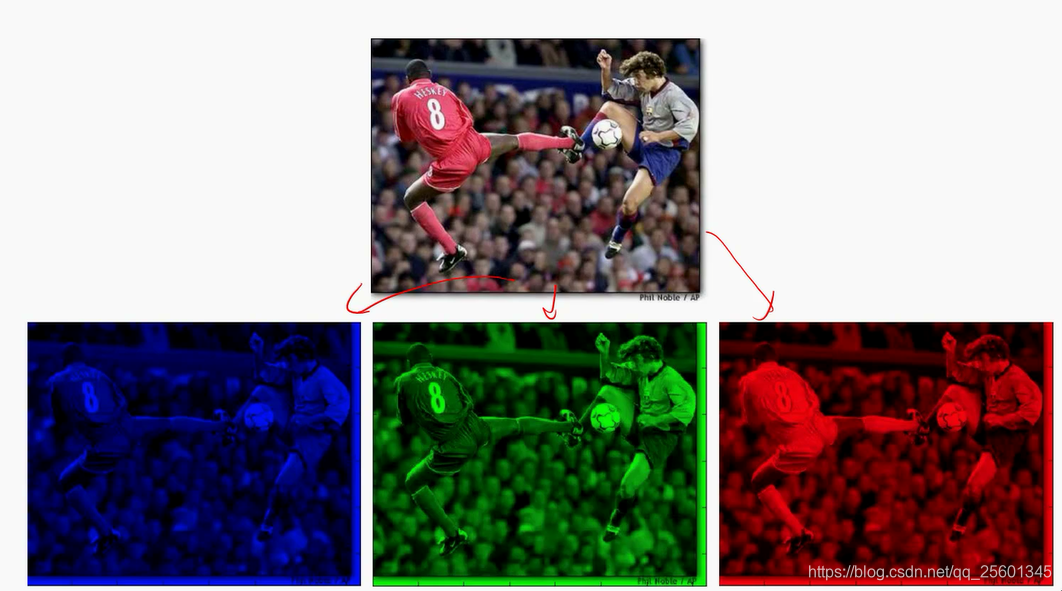
大多数分类算法都要求输入向量!
2.1. 图像表示

2.2. 分类模型
2.2.1. 线性分类器定义⭐
线性分类器是一种线性映射, 将输入的图像特征映射为类别分数。
(是神经网络(大样本)和支持向量机(小样本)的基础)
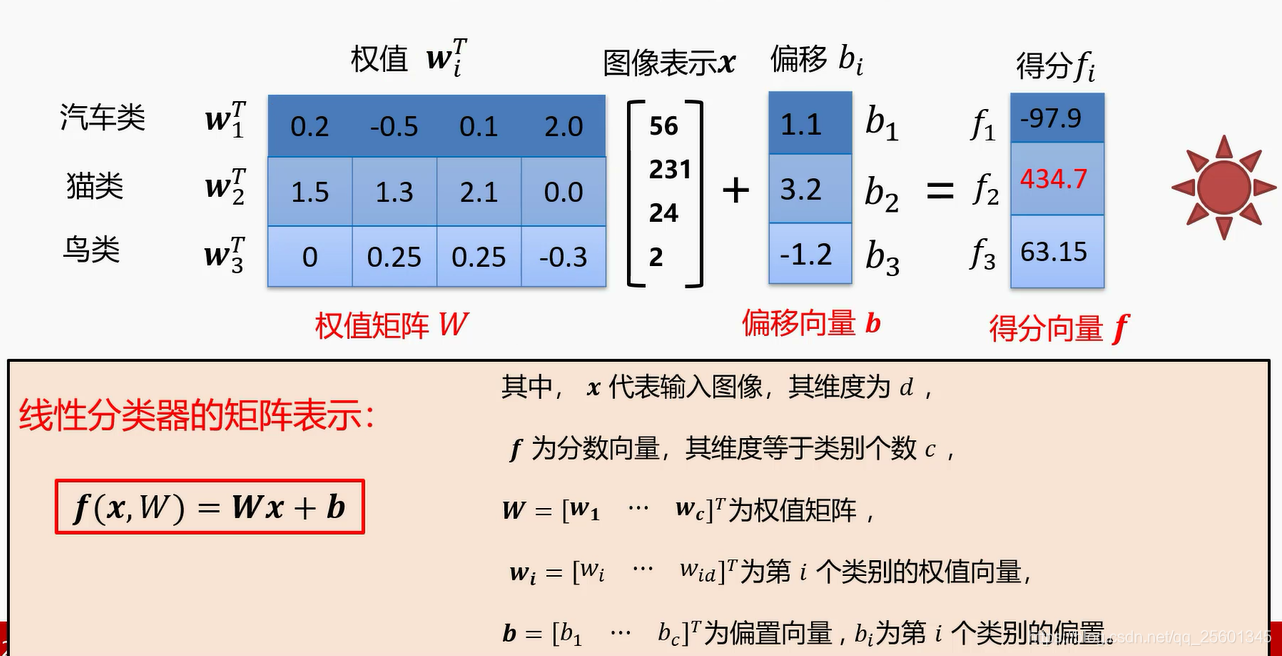
2.2.2. 线性分类器矩阵表示⭐
2.2.3. 线性分类器决策示例⭐

- ●图像表示成向量
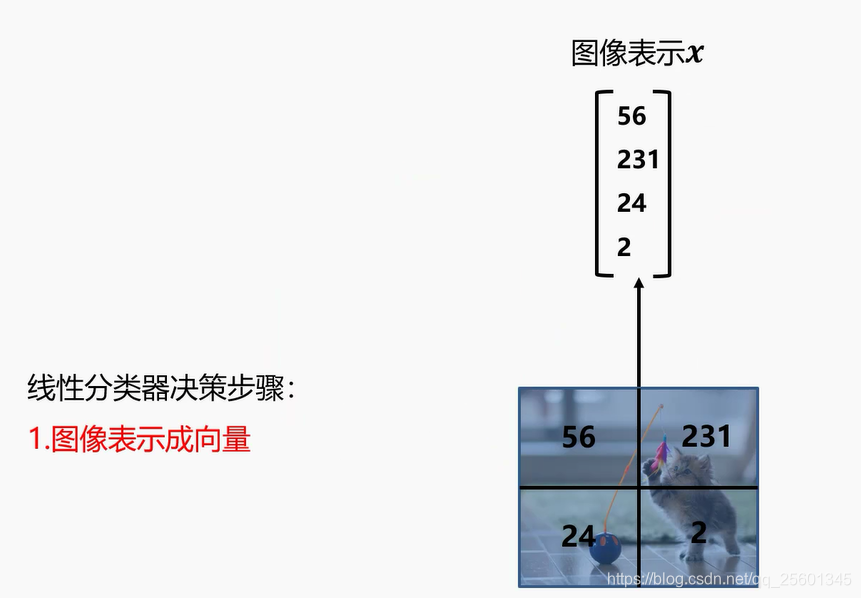
- ●计算当前图片每个类别的分数
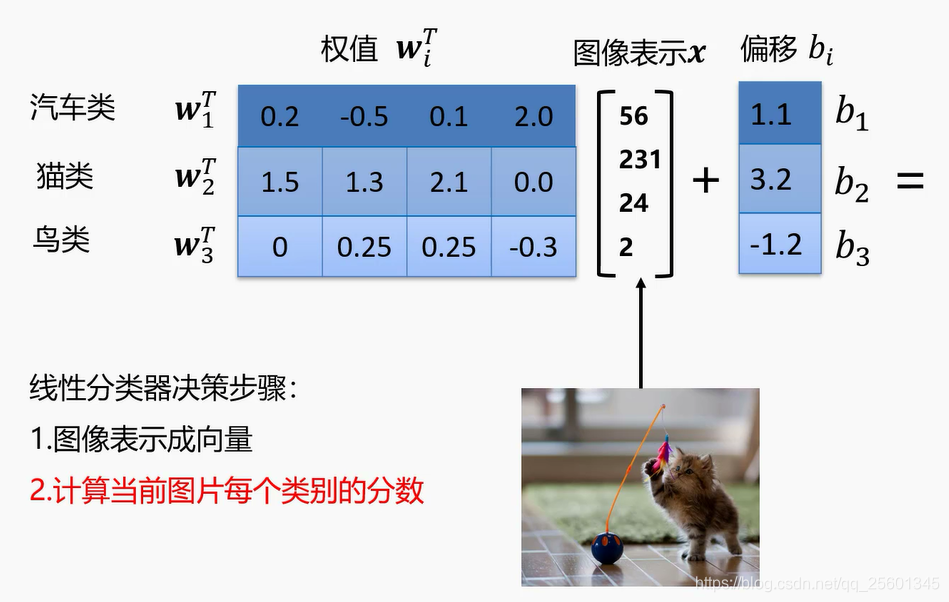
- ●按类别得分判定当前图像
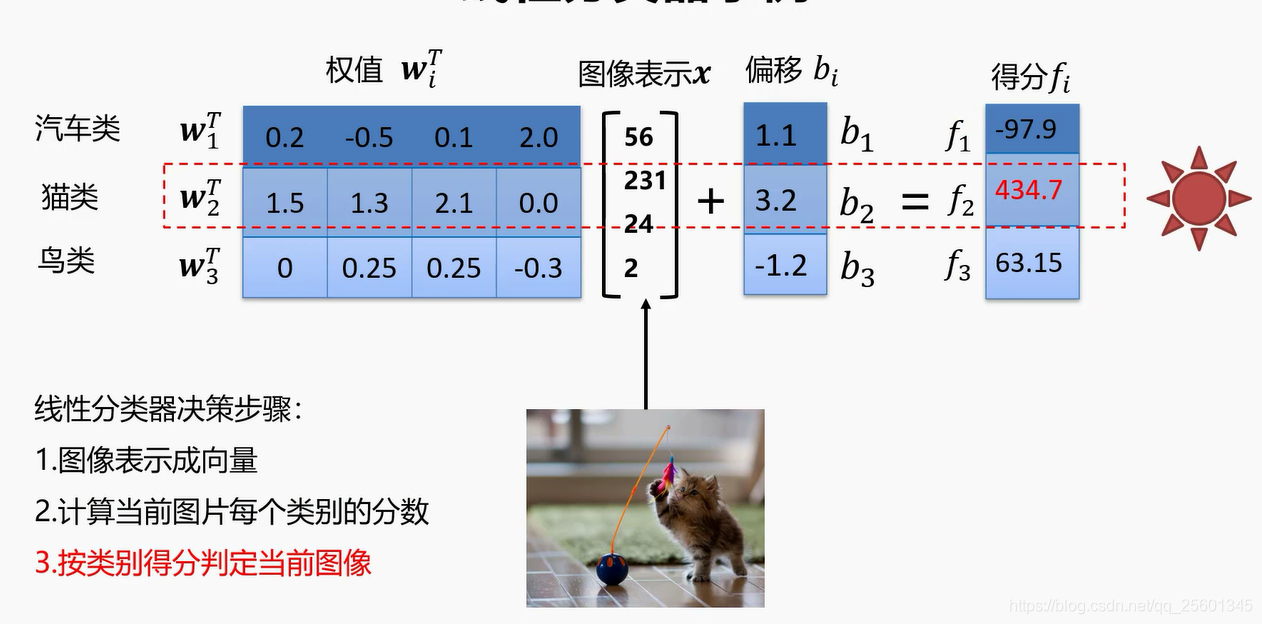
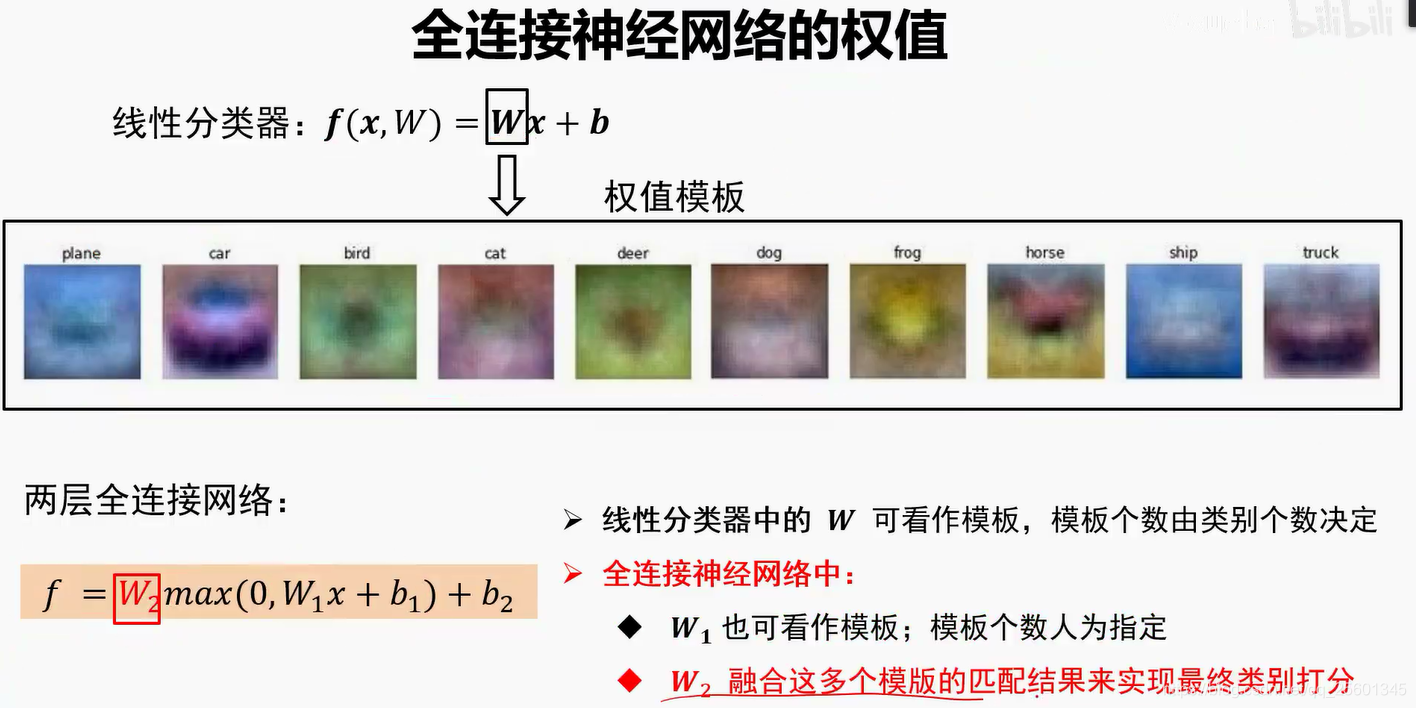
2.2.4. 线性分类器的权值⭐
➢权值看做是一-种模板
➢输入图像与评估模板的匹配程度越高,分类器输出的分数就越高
白话来说:线性分类器权值的作用就是,将图片和模板比一比越像打分越高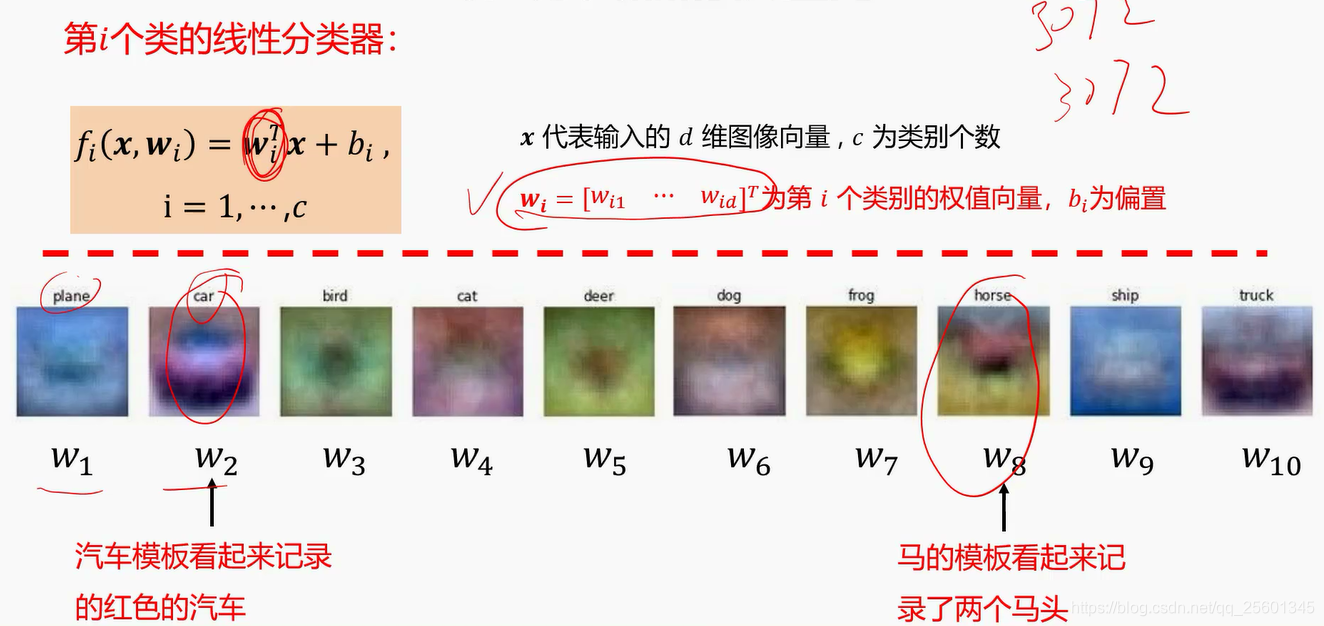
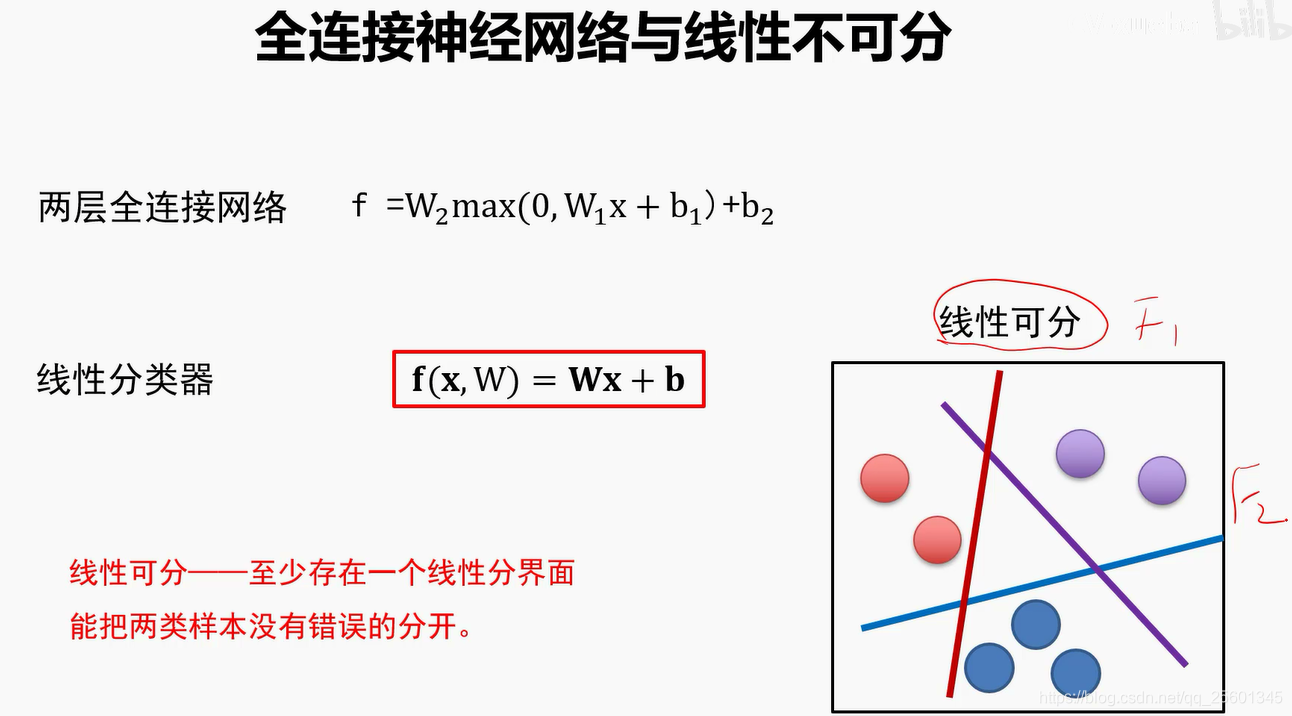
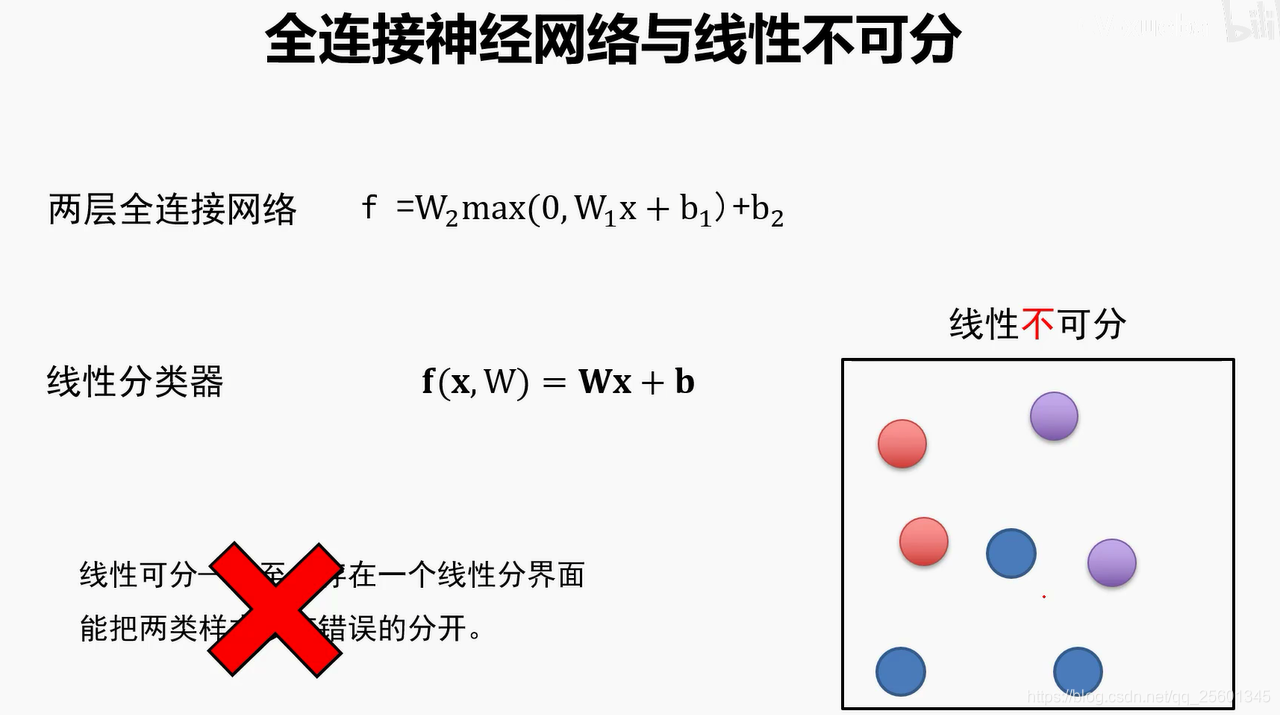
2.2.5. 线性分类器的分界面⭐
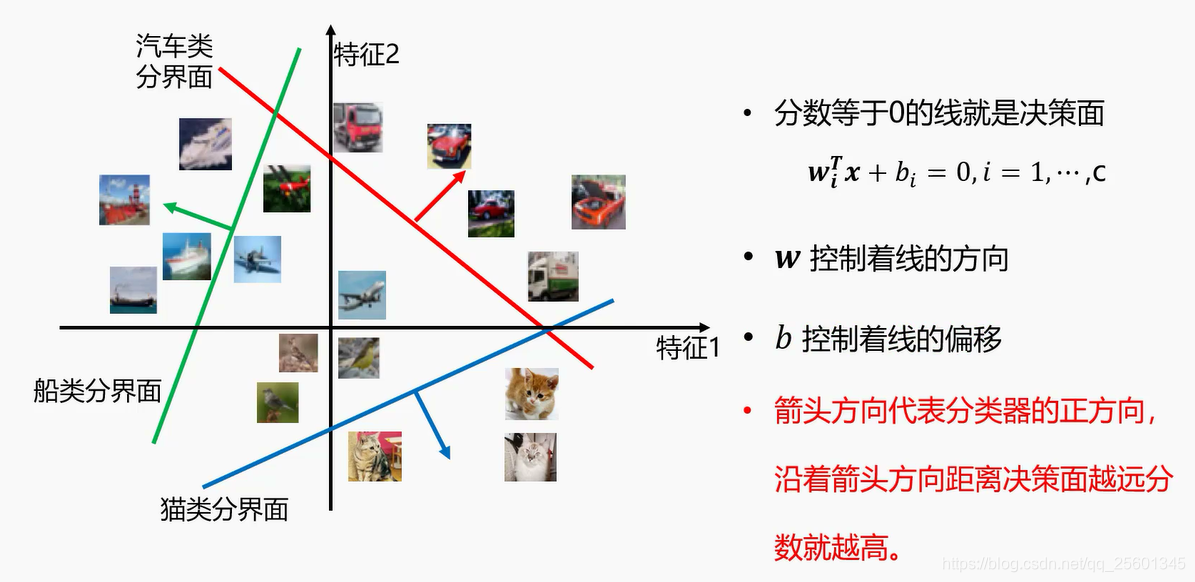
2.3. 损失函数
损失函数搭建了模型性能与模型参数之间的桥梁,指导模型参数优化。
➢损失函数是一个函数,用于度量给定分类器的预测值与真实值的不一致程度,其输出通常是一个非负实值。
➢其输出的非负实值可以作为反馈信号来对分类器参数进行调整,以降低当前示例对应的损失值,提升分类器的分类效果。
➢根据w和b可以计算损失值
2.3.1. 损失函数定义⭐

2.3.2. 多类支撑向量机损失⭐

- 示例
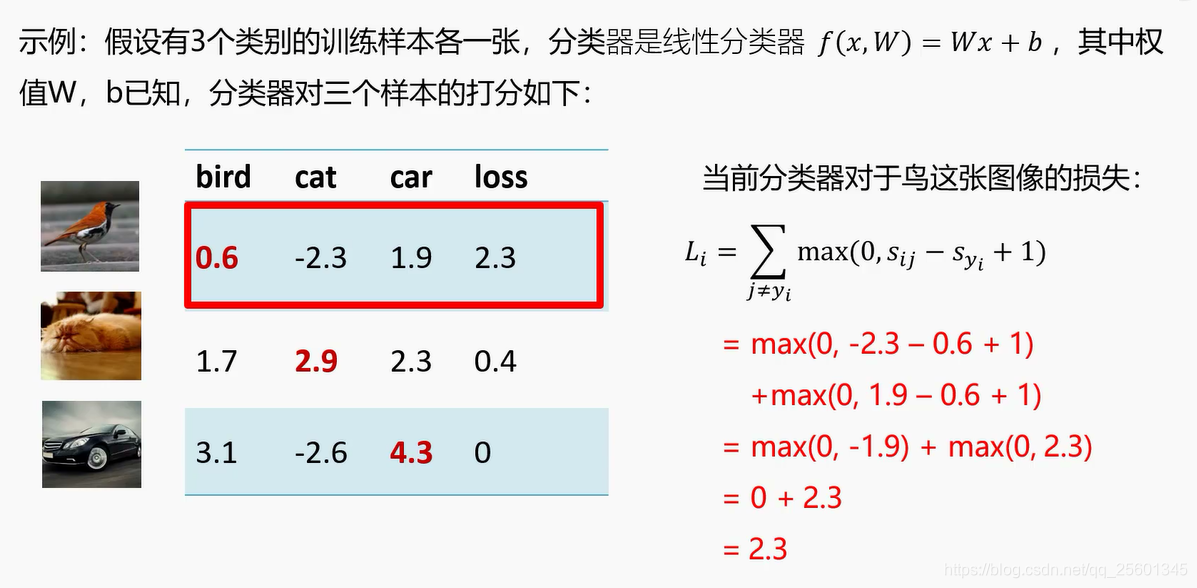
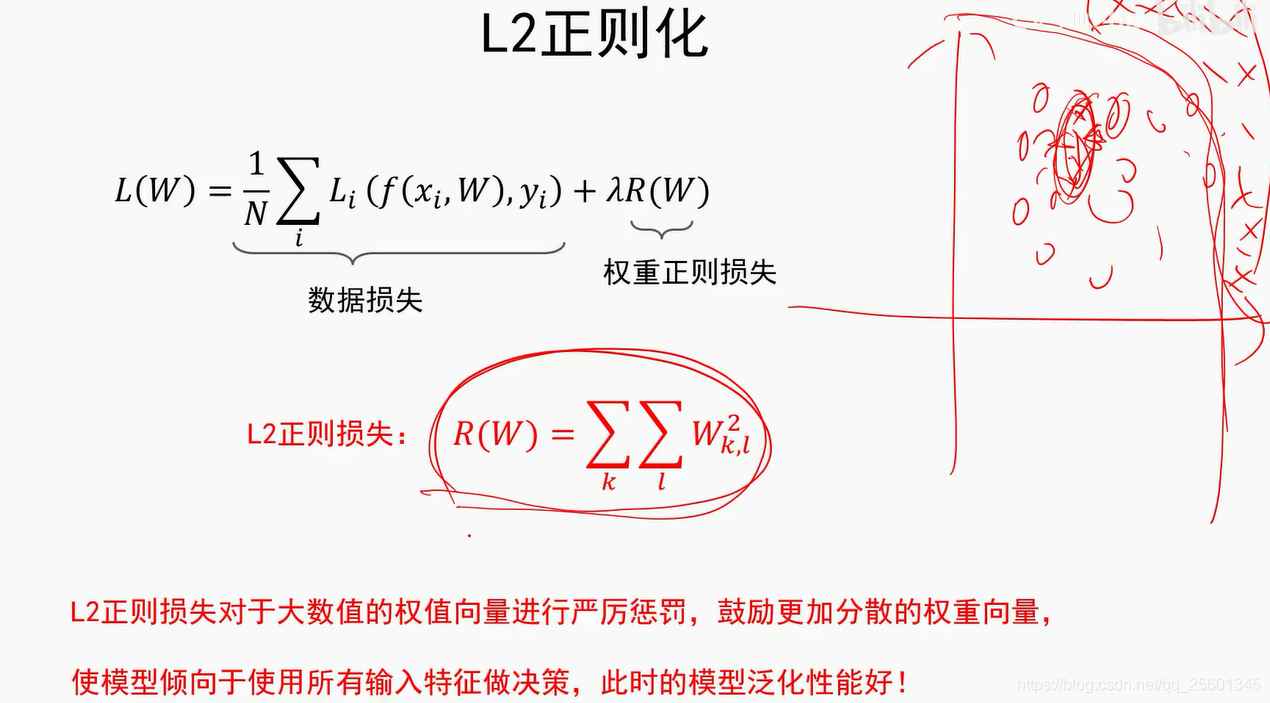
2.3.3. 正则项与超参数⭐
- 正则项损失
- 作用:使解唯一、使偏好分散权值、使避免过拟合
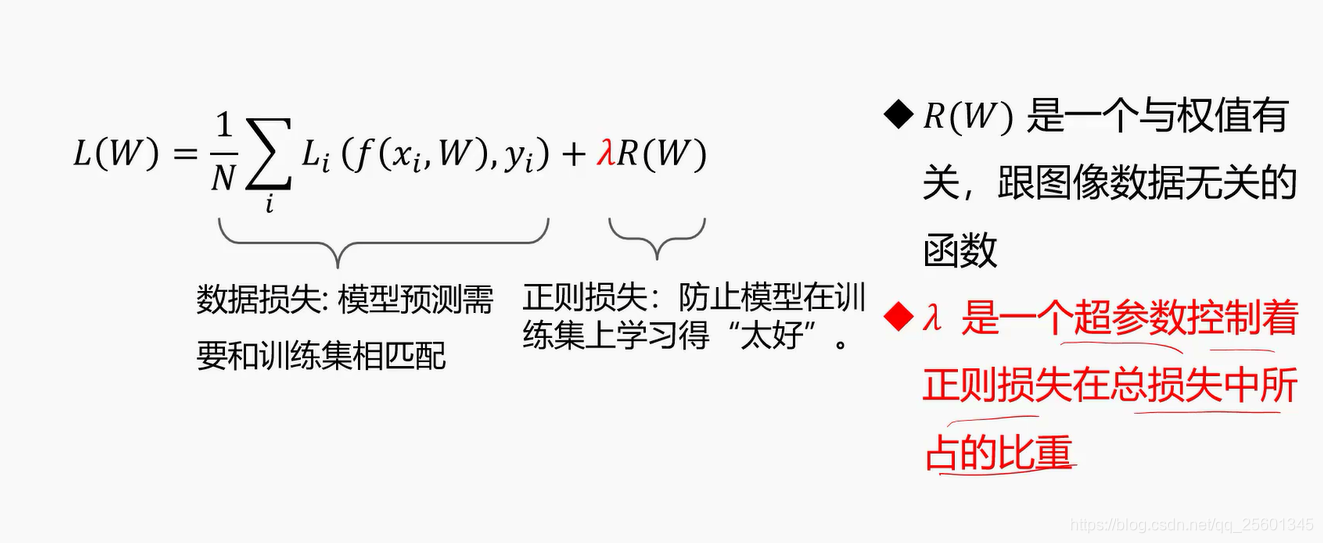
- 超参数
学习之前指定的值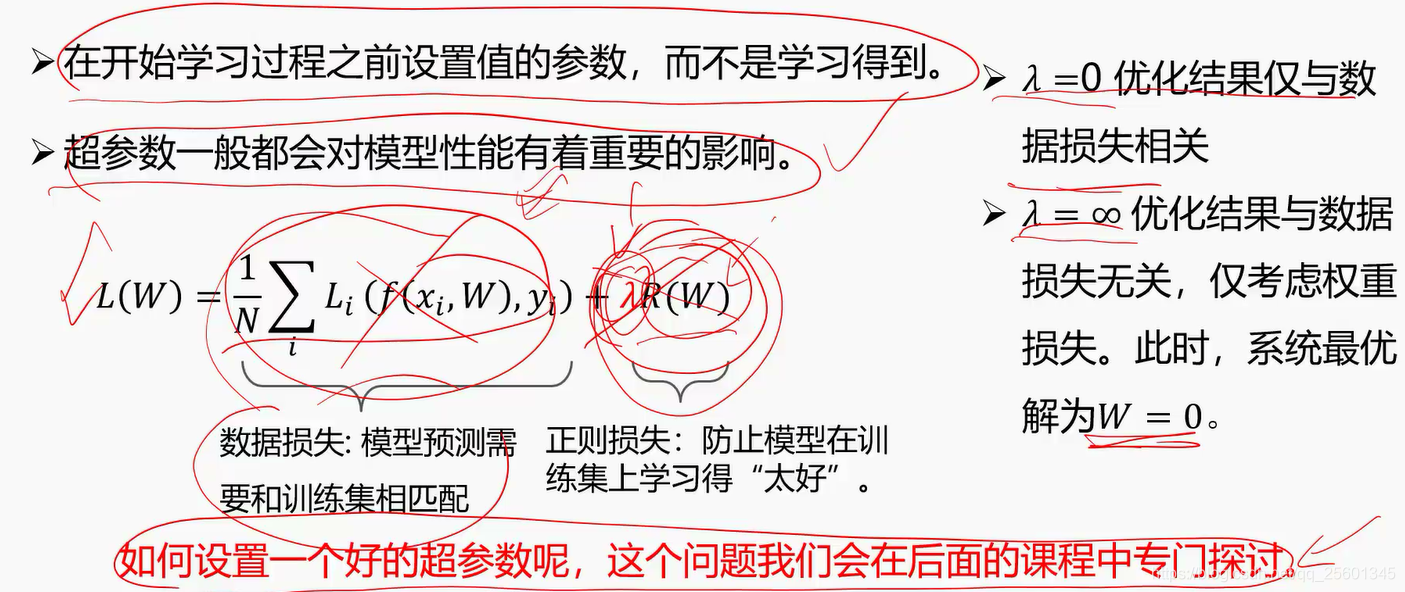
- L2正则项

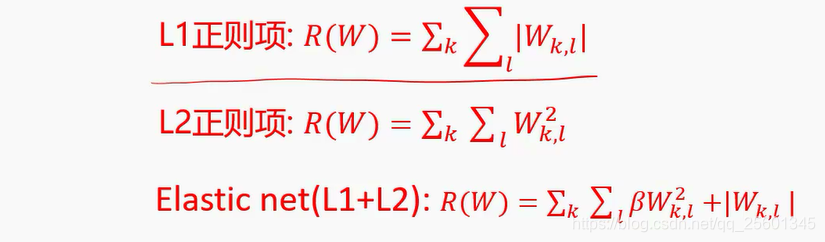
2.4. 优化算法
2.4.1. 什么是优化⭐
参数优化是机器学习的核心步骤之一,它利用损失函数的输出值作为反馈信号来调整分类器参数,以提升分类器对训练样本的预测性能。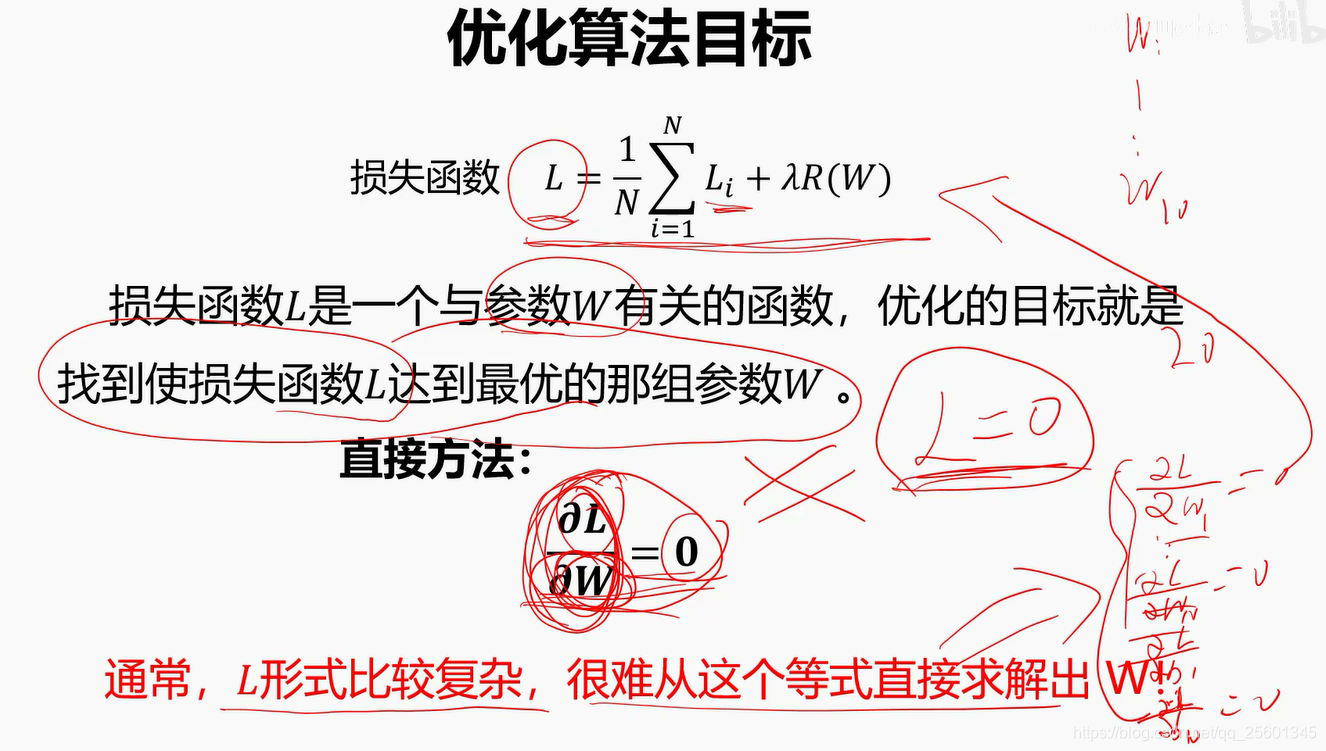
2.4.2. 梯度下降算法⭐
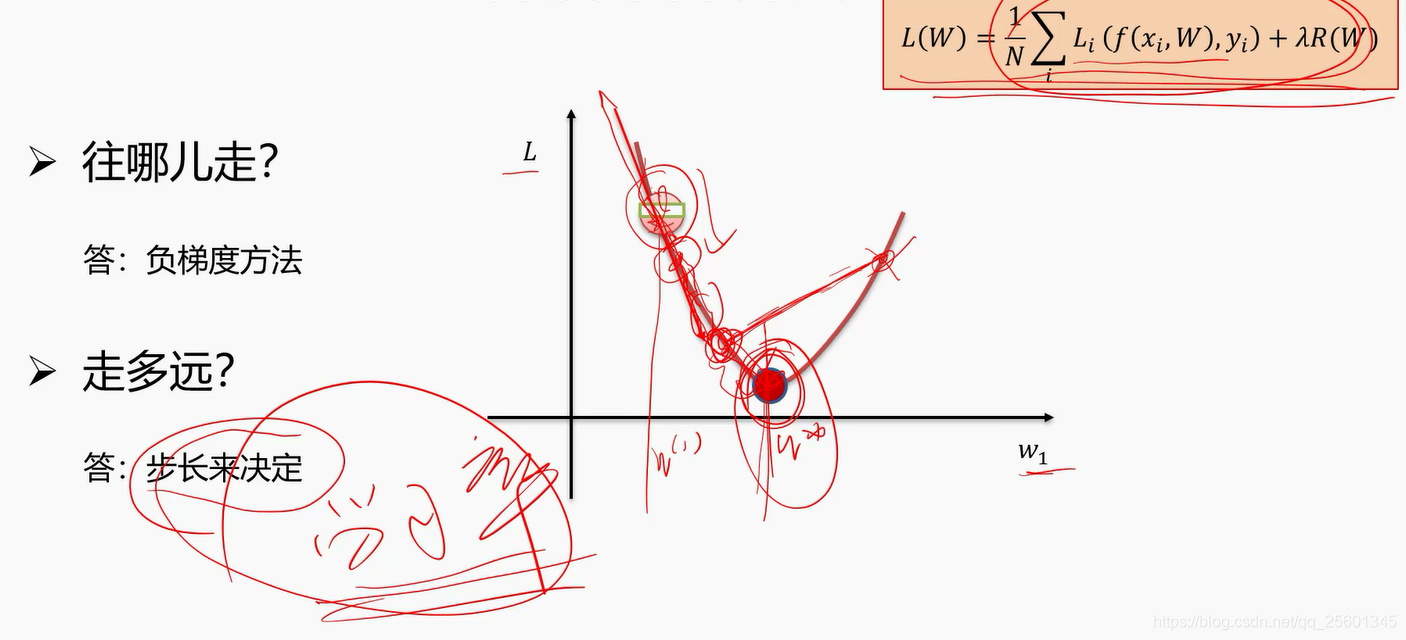

- 梯度计算
数值法一般用于校验
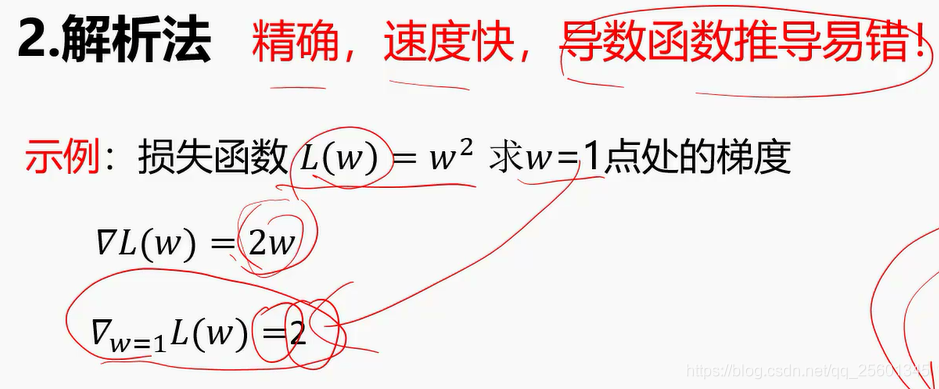
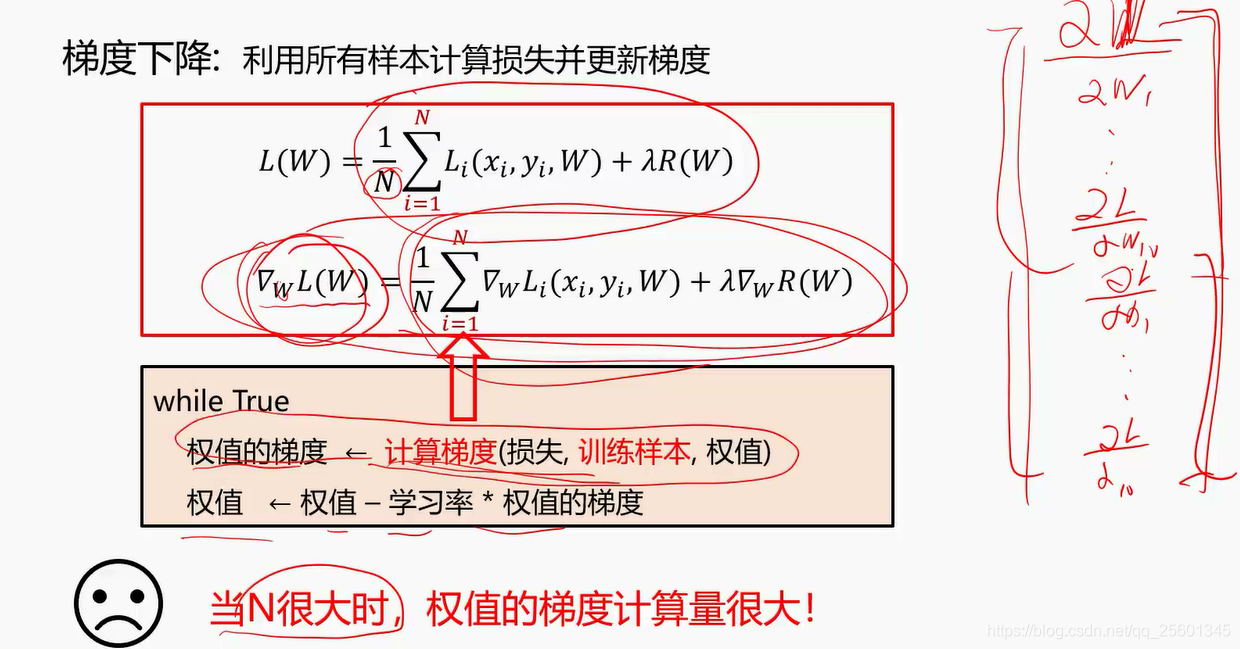

2.4.3. 随机梯度下降算法⭐

2.4.4. 小批量梯度下降算法⭐
每次随机选择m (批量的大小【超参数】)个样本计算损失并更新梯度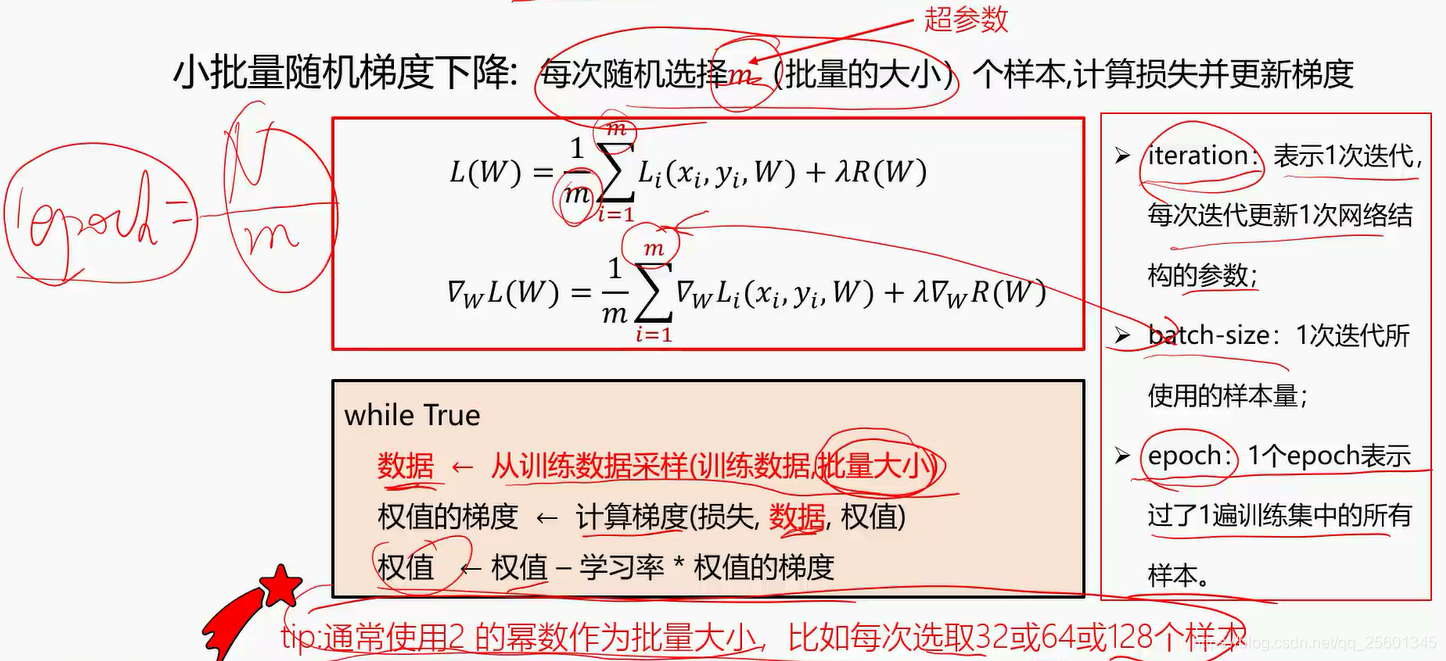
2.4.5. 总结⭐

3. 数据集划分
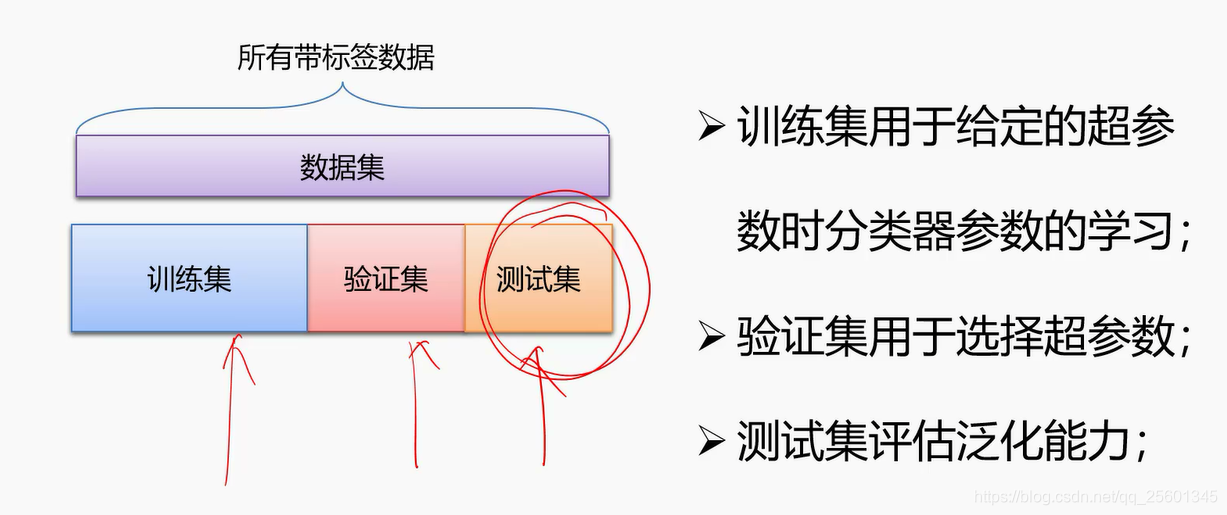
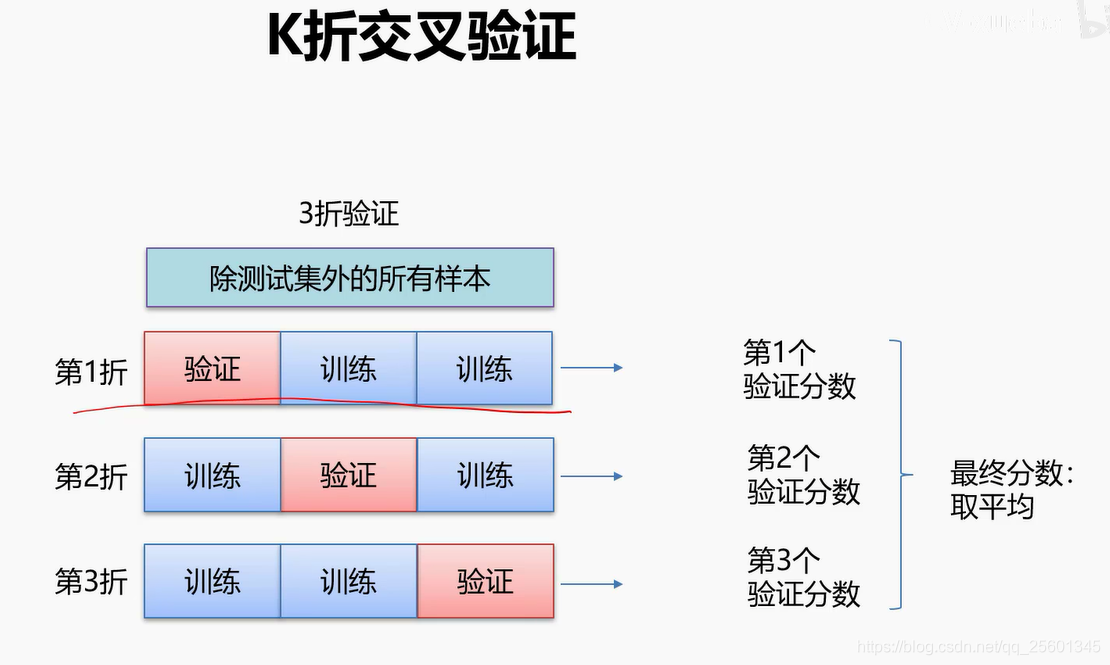
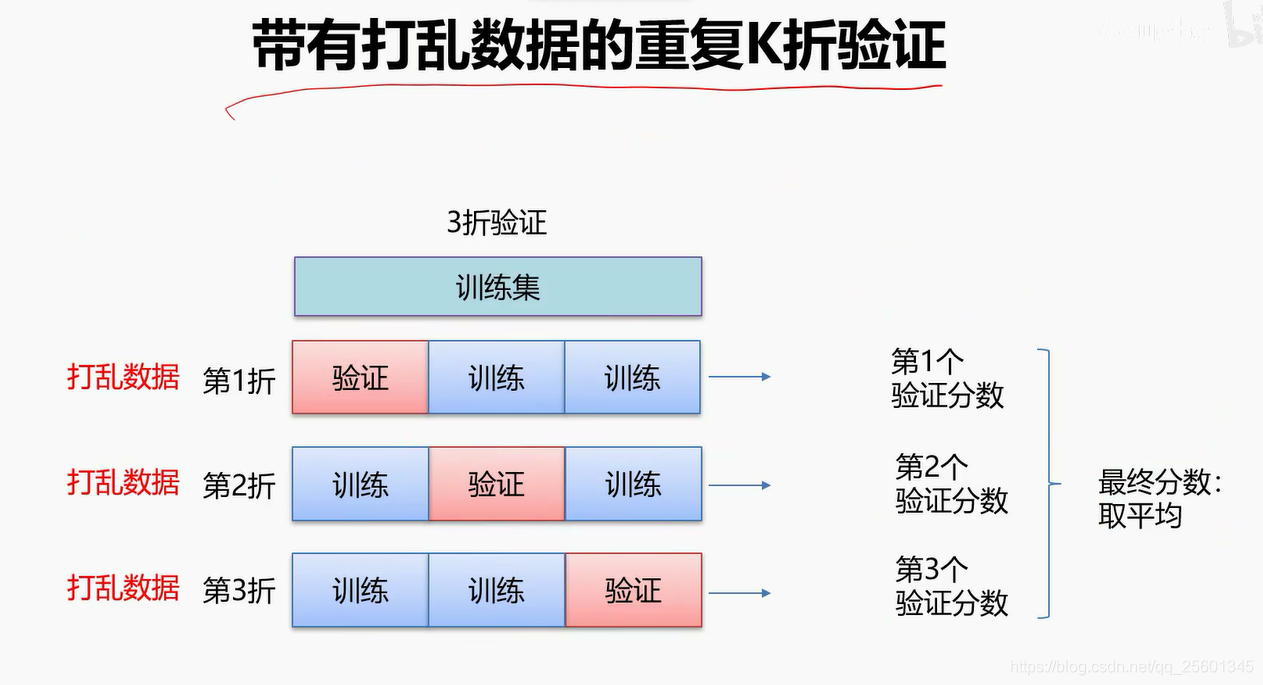
4. 数据集预处理
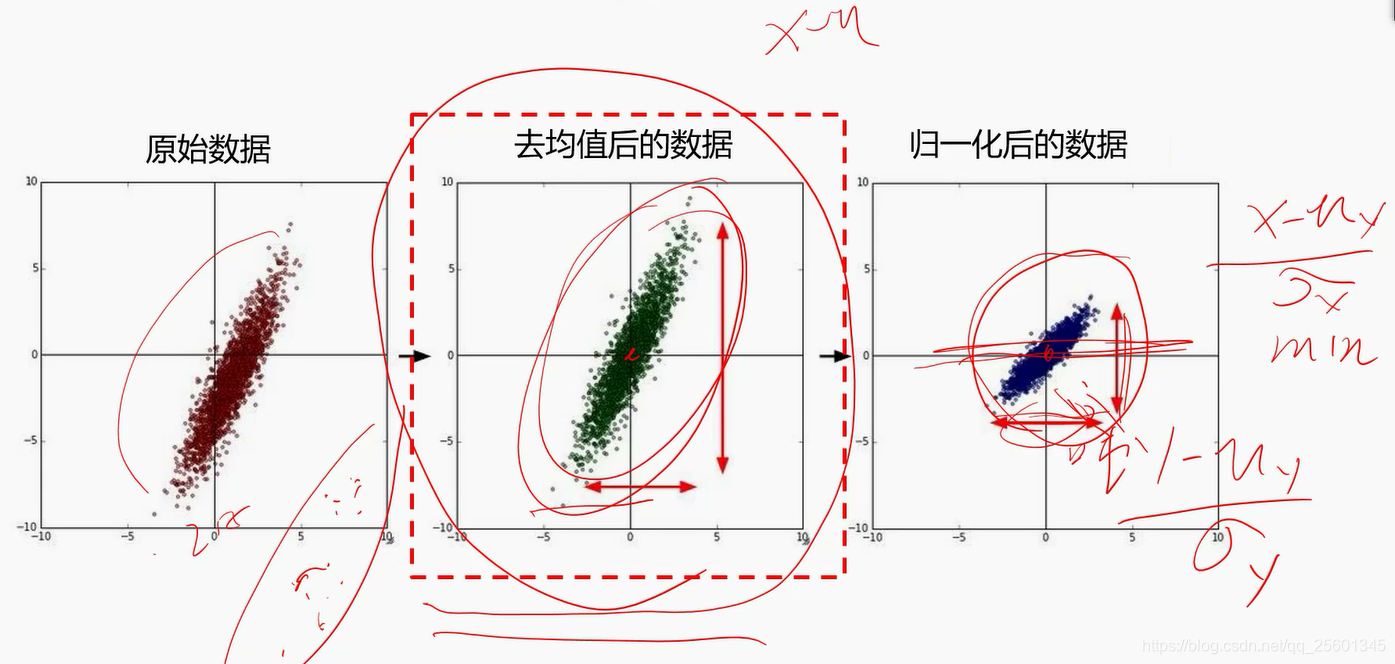
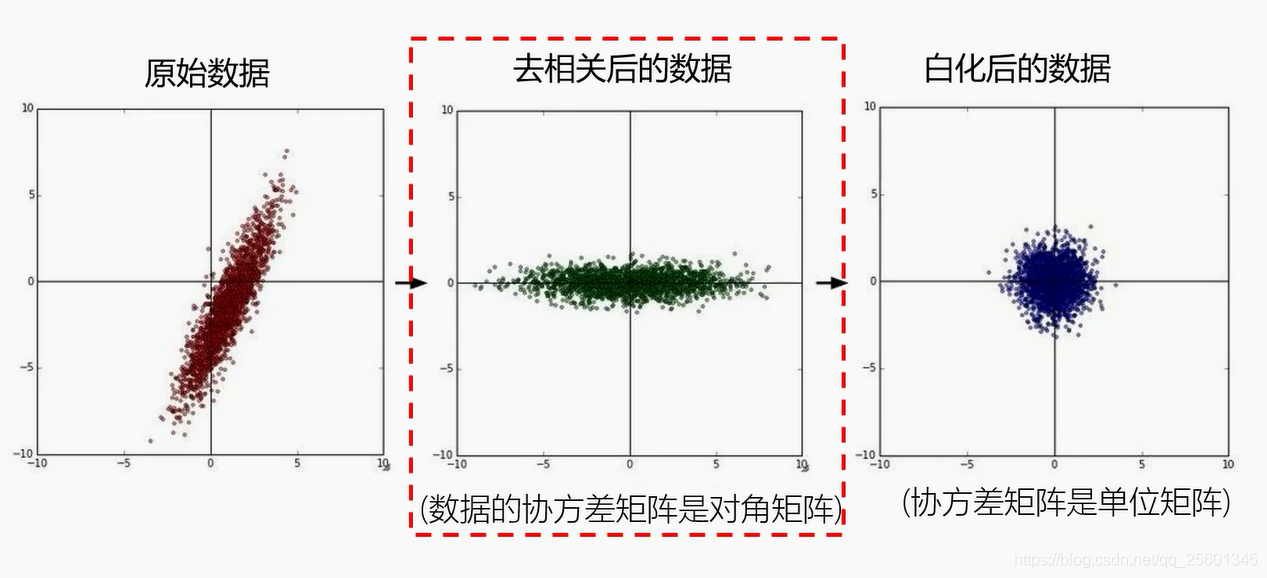
三、全连接神经网络分类器
1. 数据集
2. 分类器设计
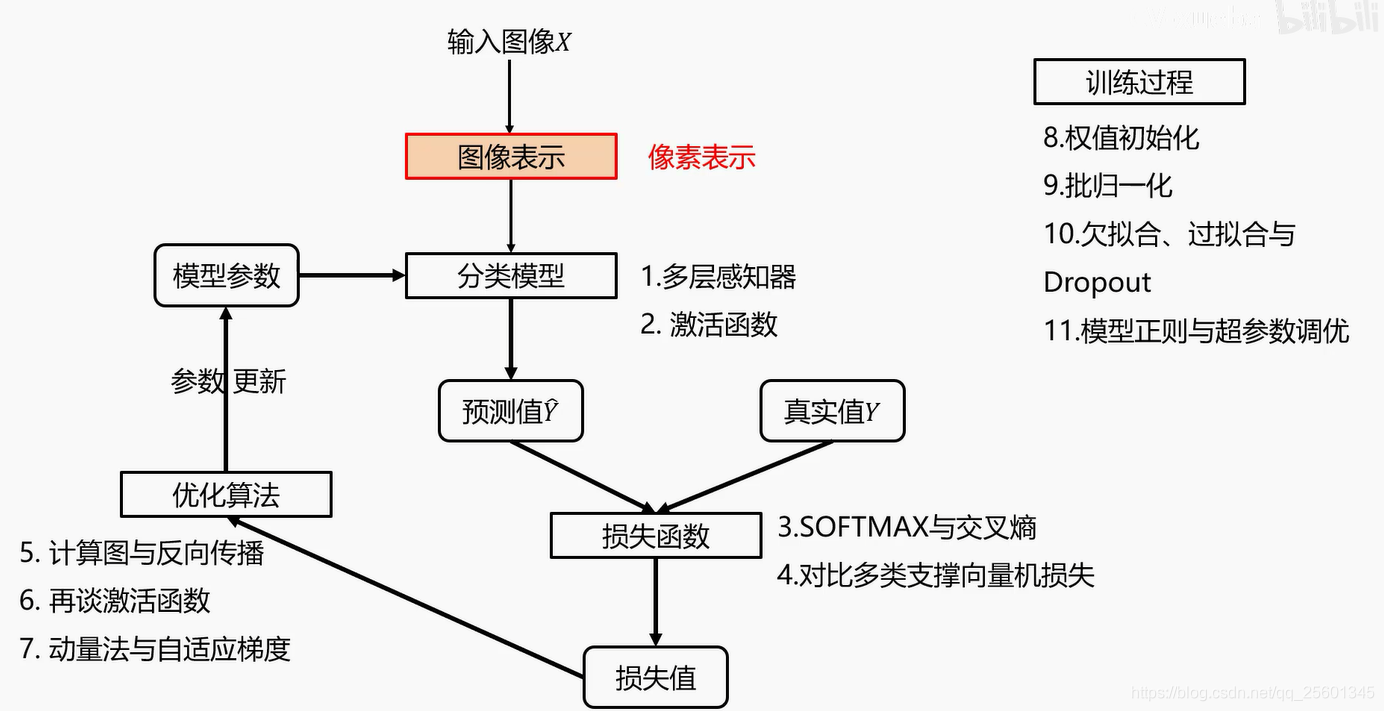
2.1. 图像表示

2.2. 分类模型
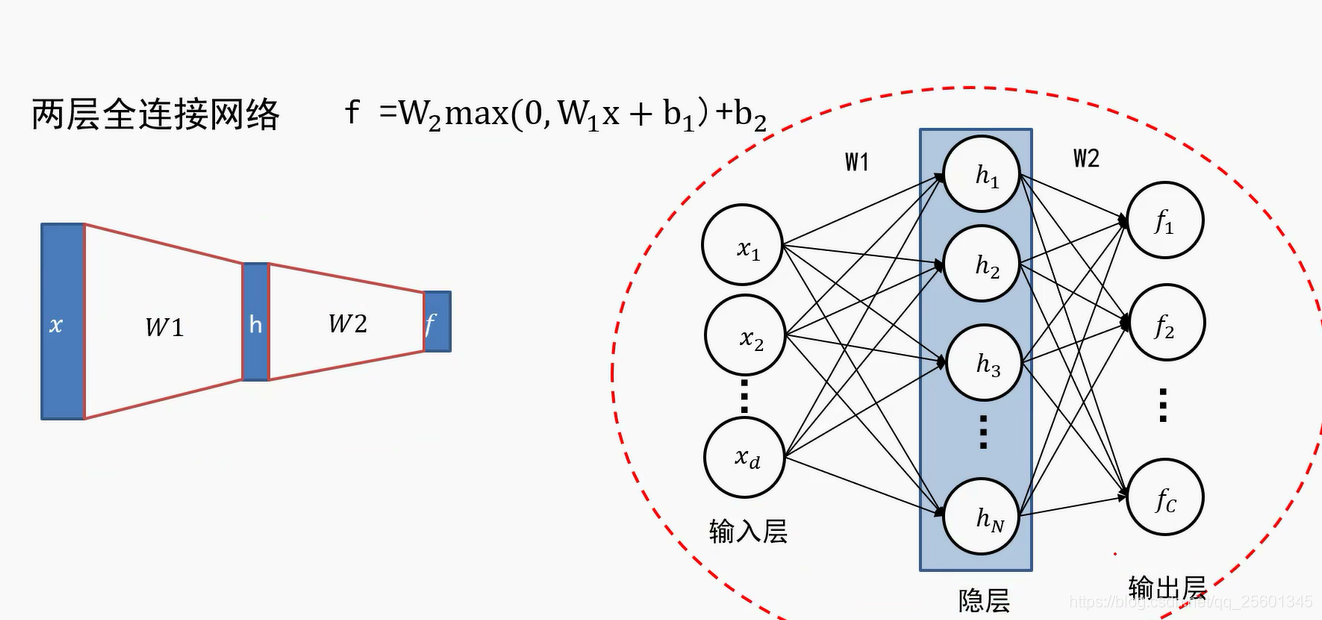
2.2.1. 多层感知器(全连接神经网络)

- 全连接神经网络级联多个变换来实现输入到输出的映射。
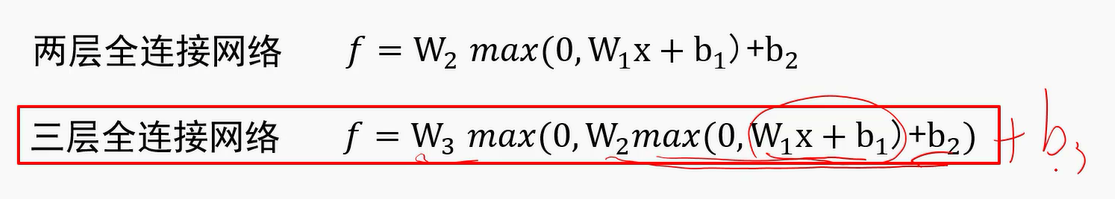
全联接神经网络的描述能力更强。因为调整W1行数等于增加模板个数,分类器有机会学到两个不同方向的马的模板。
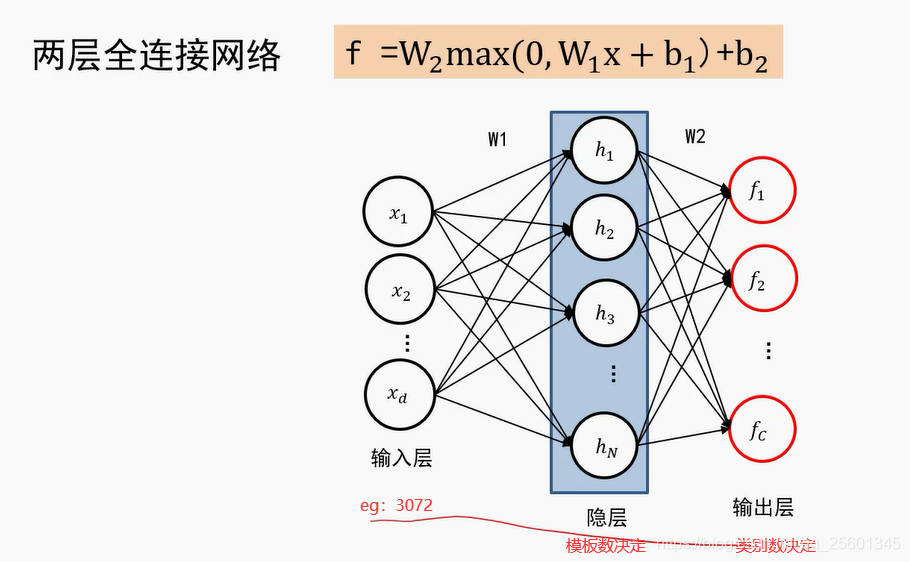
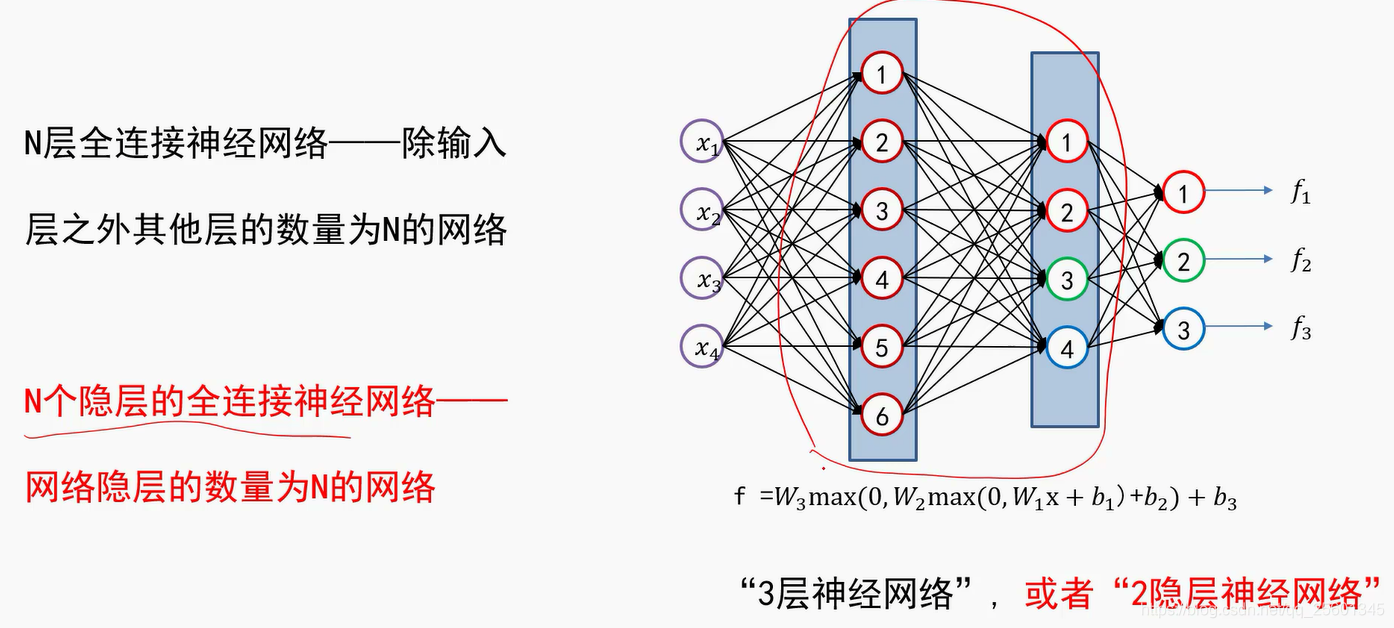
2.2.2. 激活函数


Sigmoid----将数据压缩到0-1之间(不对称)
tanh----将数据压缩到-1-1之间(对称)
ReLU----max(0,x)
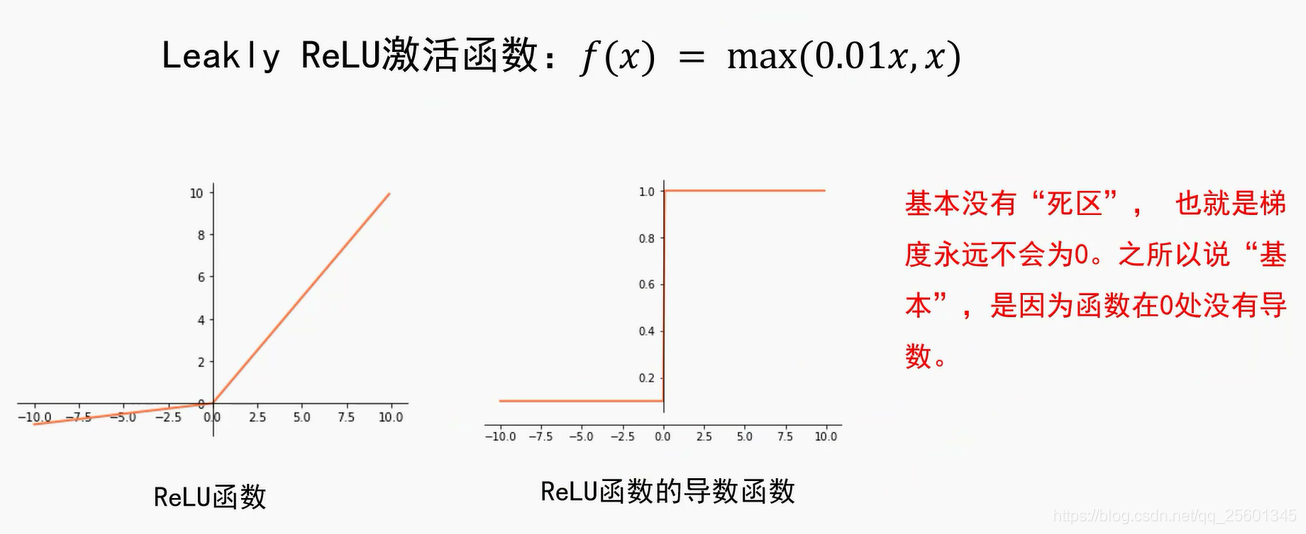
Leaky ReLU-----max(0.1x,x)
网路设计三要素:隐层个数,每个隐层神经元个数,激活函数的选择
- 每个隐层神经元个数
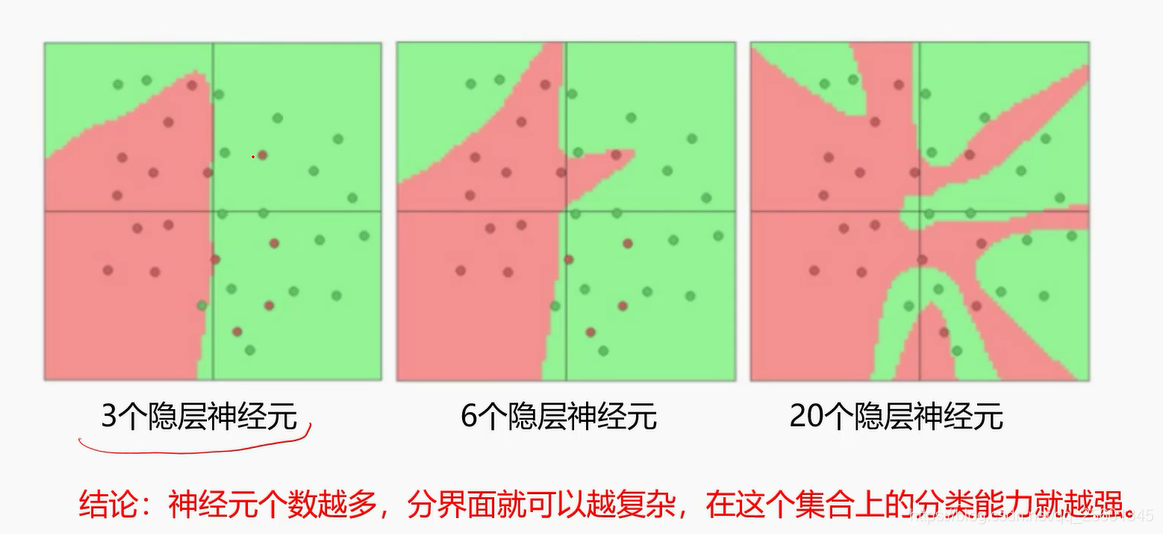
依据分类任务的难易程度来调整神经网络模型的复杂程度。分类任务越难,我们设计的神经网络结构就应该越深、越宽。但是,需要注意的是对训练集分类精度最高的全连接神经网络模型,在真实场景下识别性能未必是最好的(过拟合)
2.2.3. 小结
➢全连接神经网络组成:一个输入层、一个输出层及多个隐层;
➢输入层与输出层的神经元个数由任务决定,而隐层数量以及每个隐层的神经元个数需要人为指定;
➢激活函数是全连接神经网络中的一-个重要部分,缺少了激活函数,全连接神经网络将退化为线性分类器。
2.3. 损失函数
2.3.1. SOFTMAX与交叉熵
- softmax操作
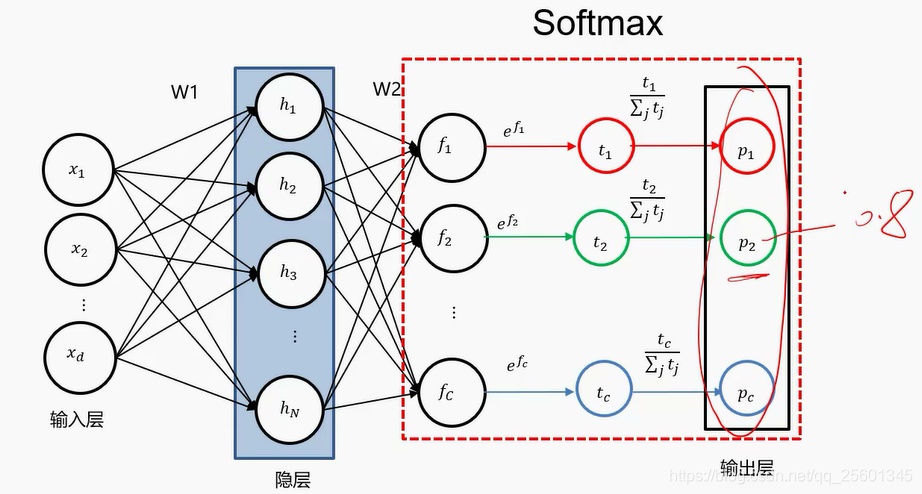
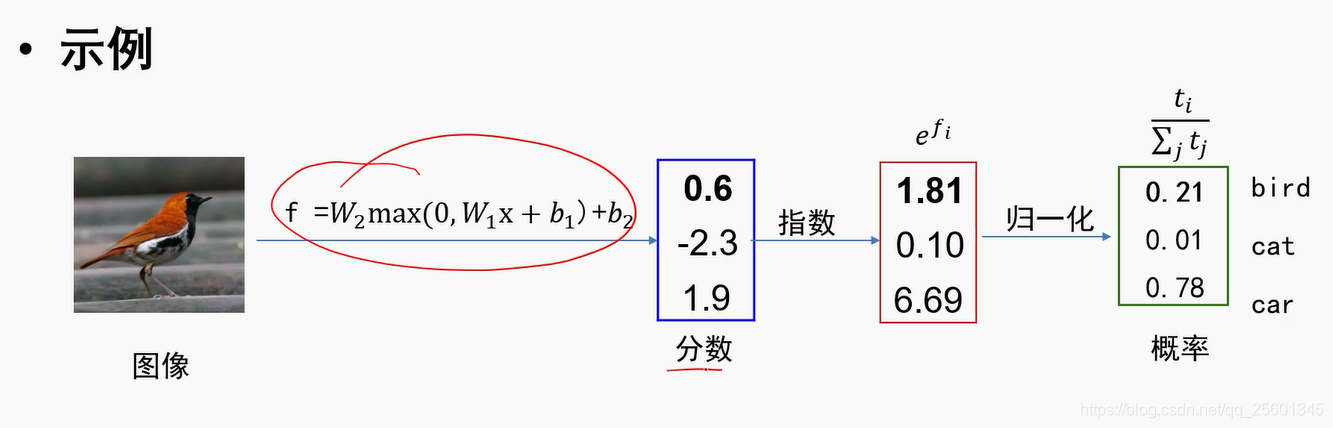
- 交叉熵损失
one-hot形式的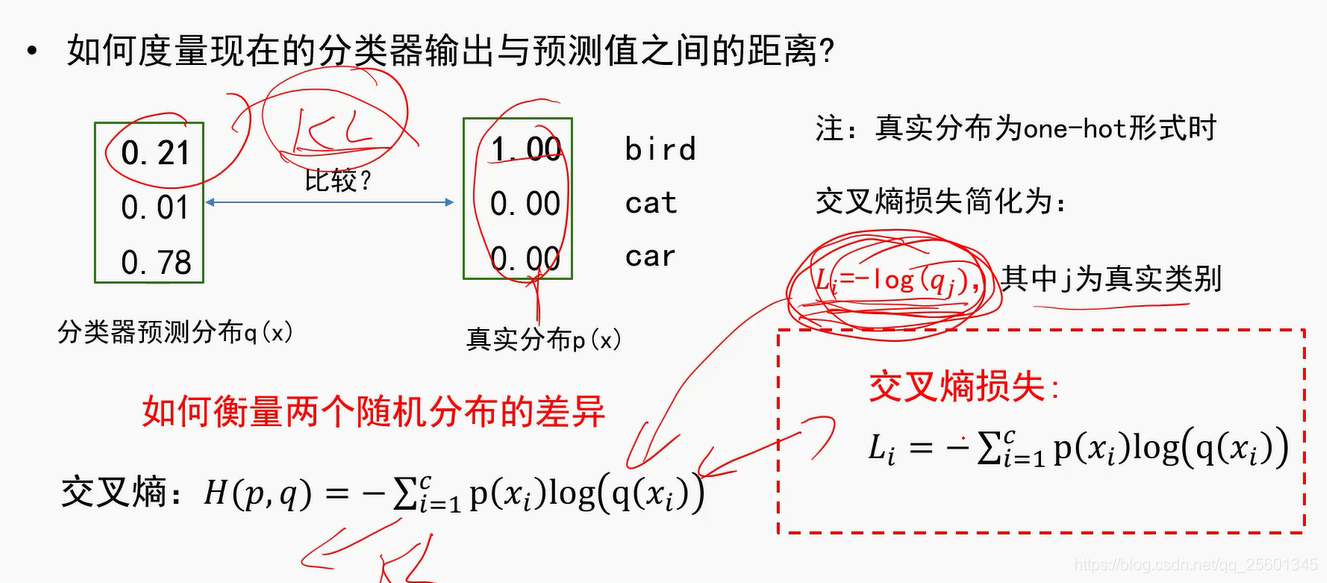

2.3.2. 对比多类支撑向量机损失


2.4. 优化算法
2.4.1. 计算图与反向传播
计算图是一种有向图 ,它用来表达输入、输出以及中间变量之间的计算关系,图中的每个节点对应着一种数学运算。(利用链式法反向求梯度)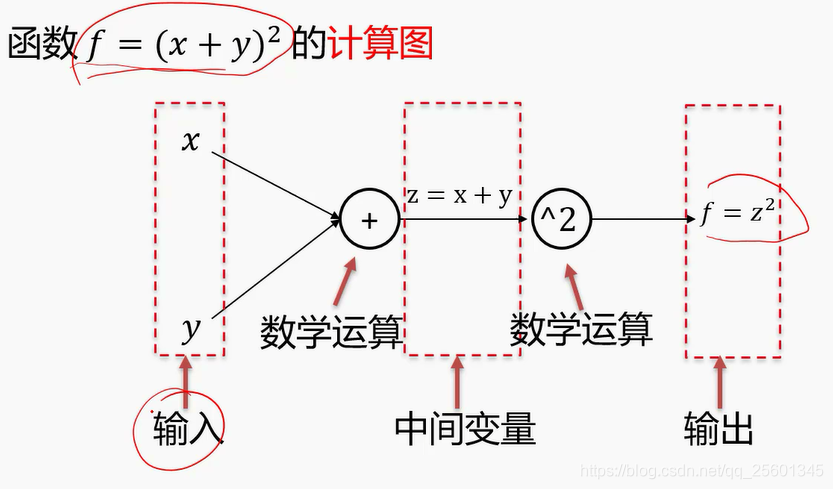
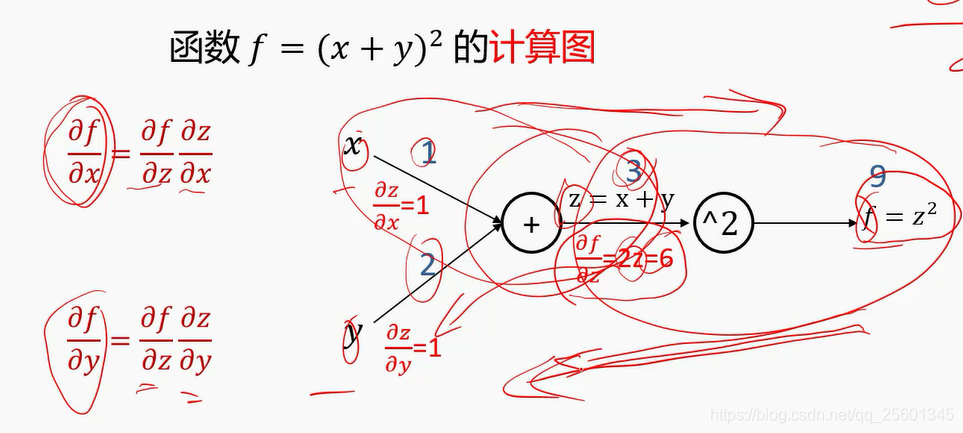
- 反向传播
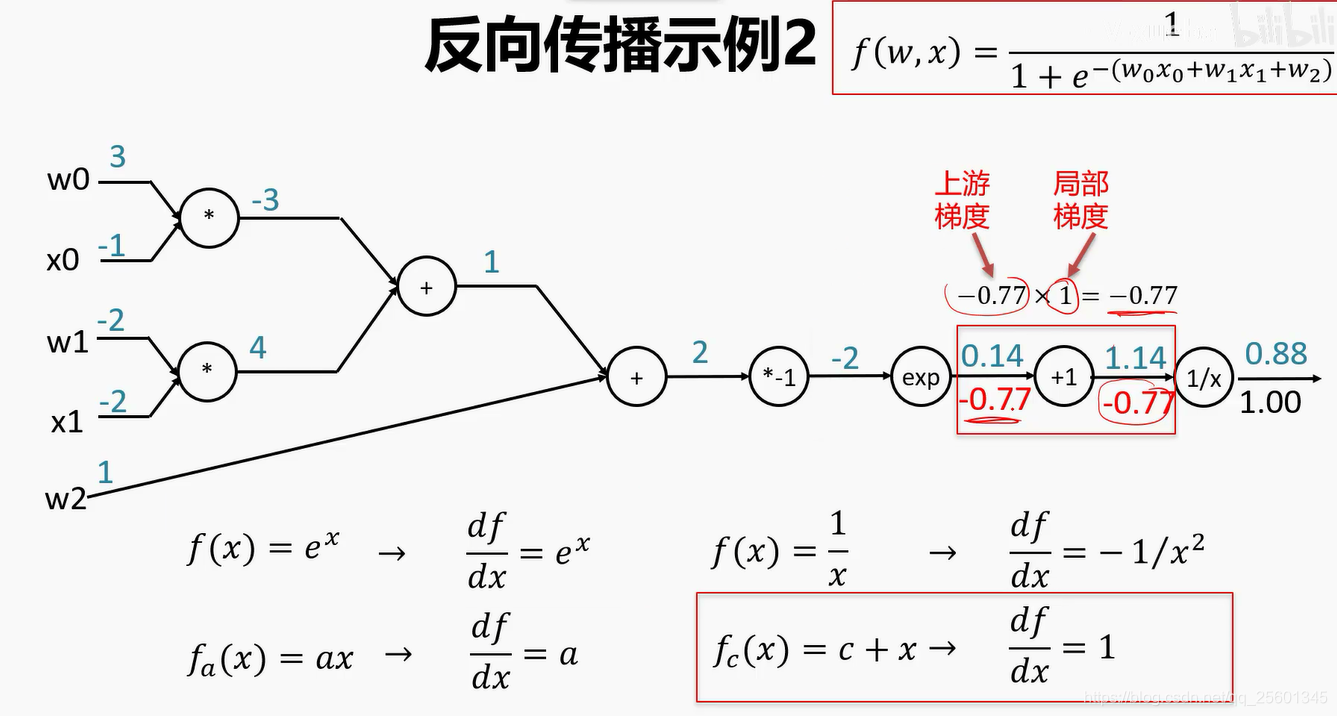
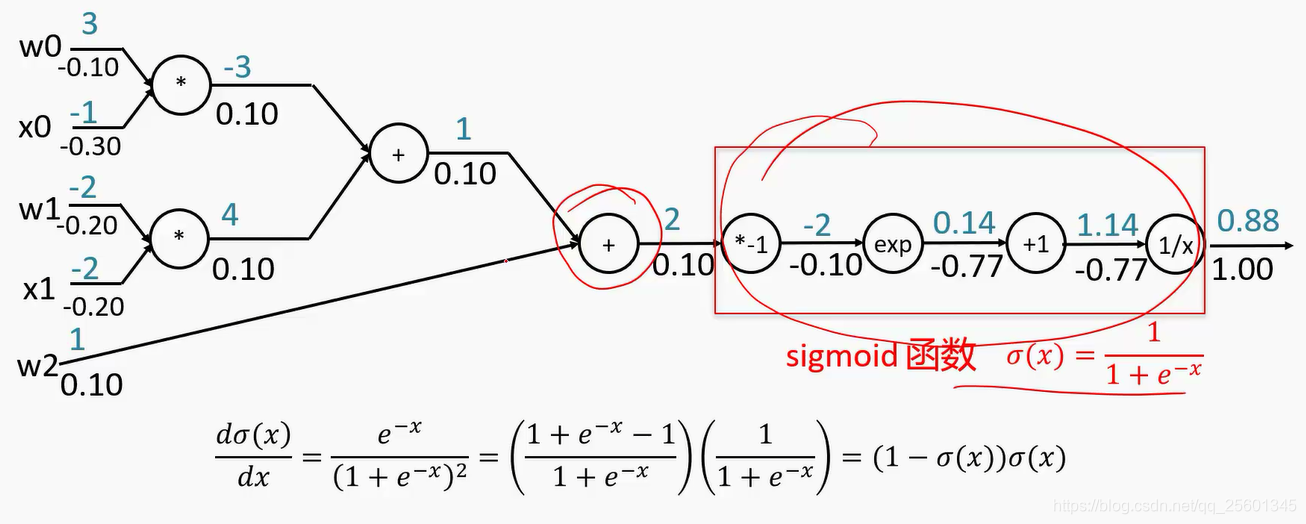
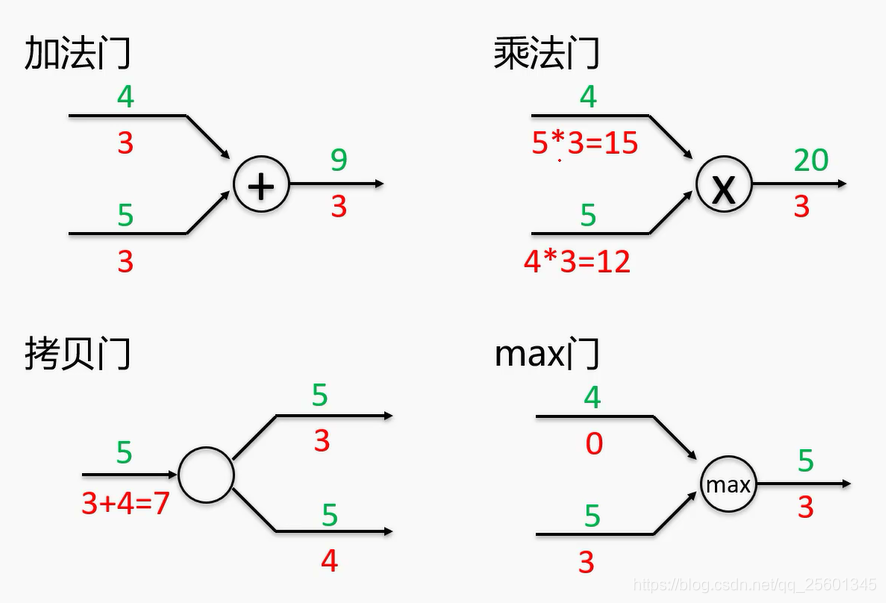

2.4.2. 再谈激活函数
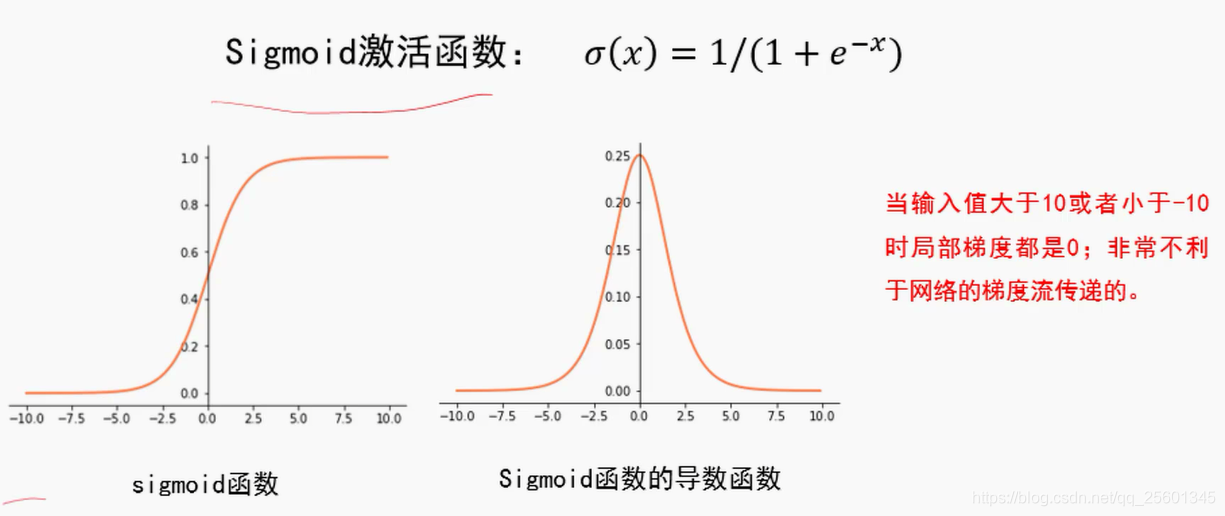
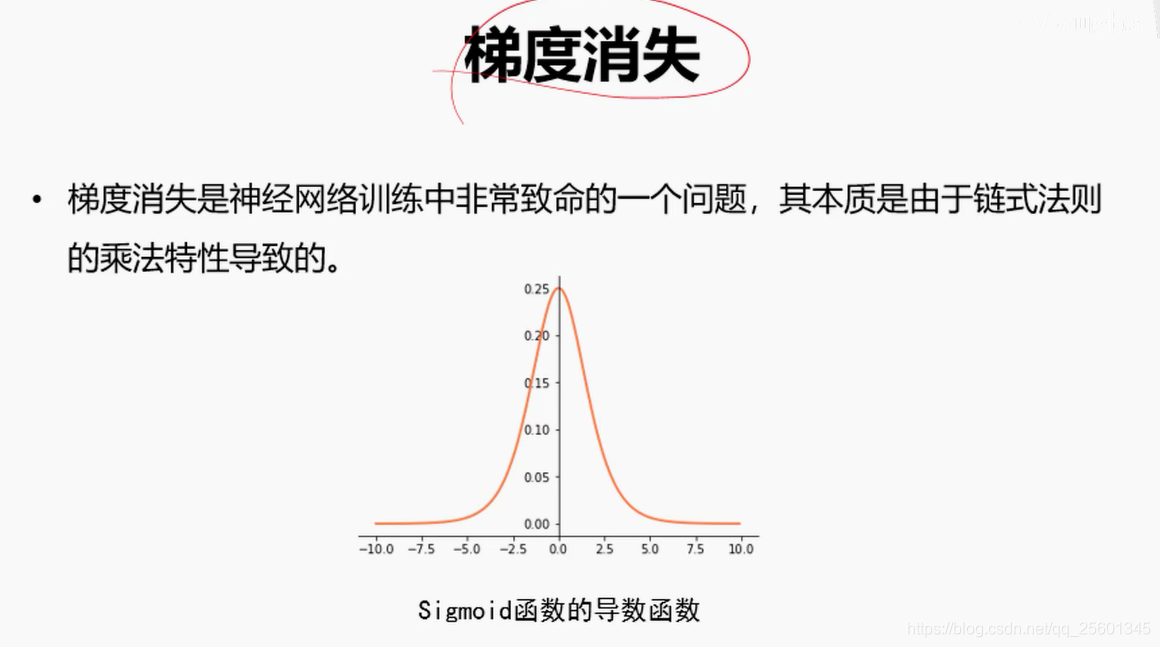
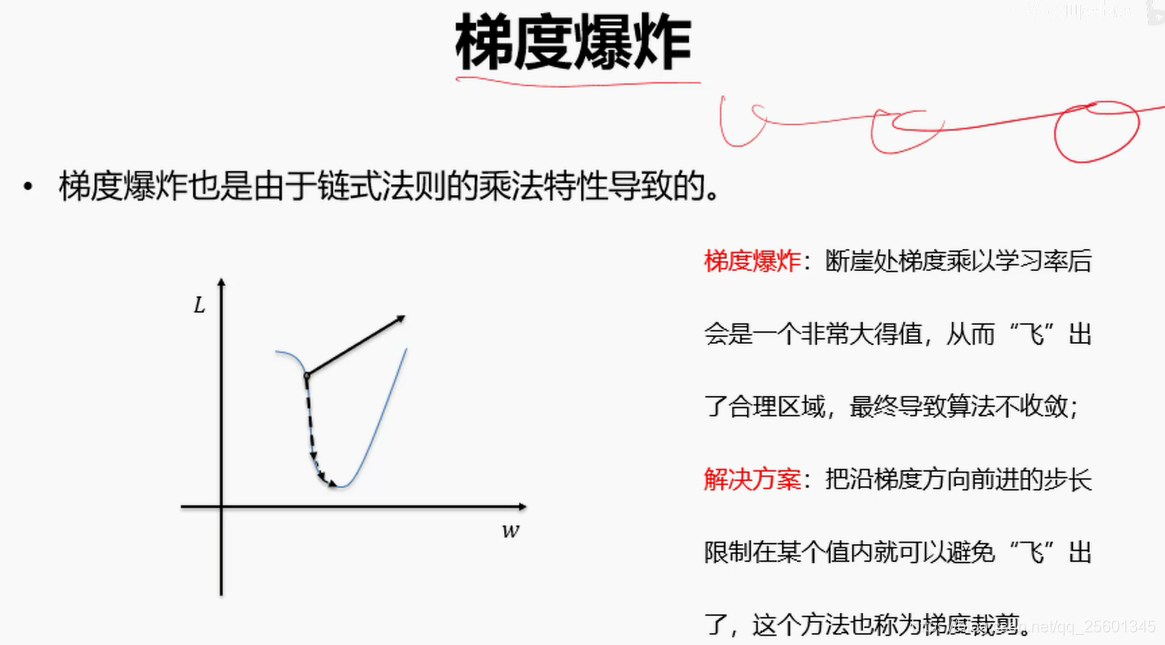
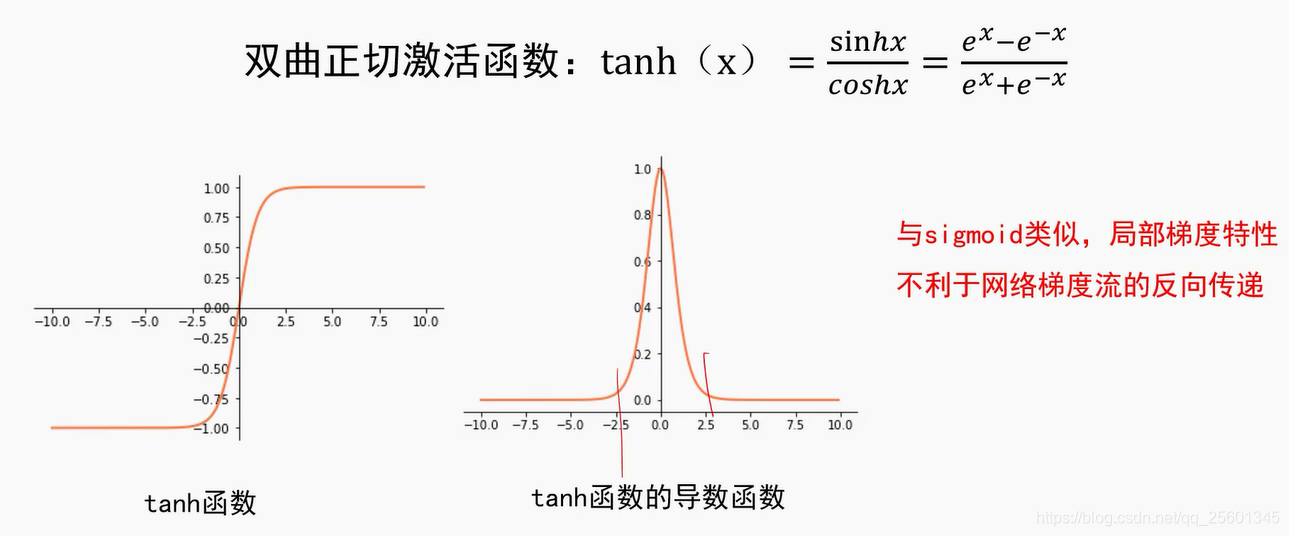
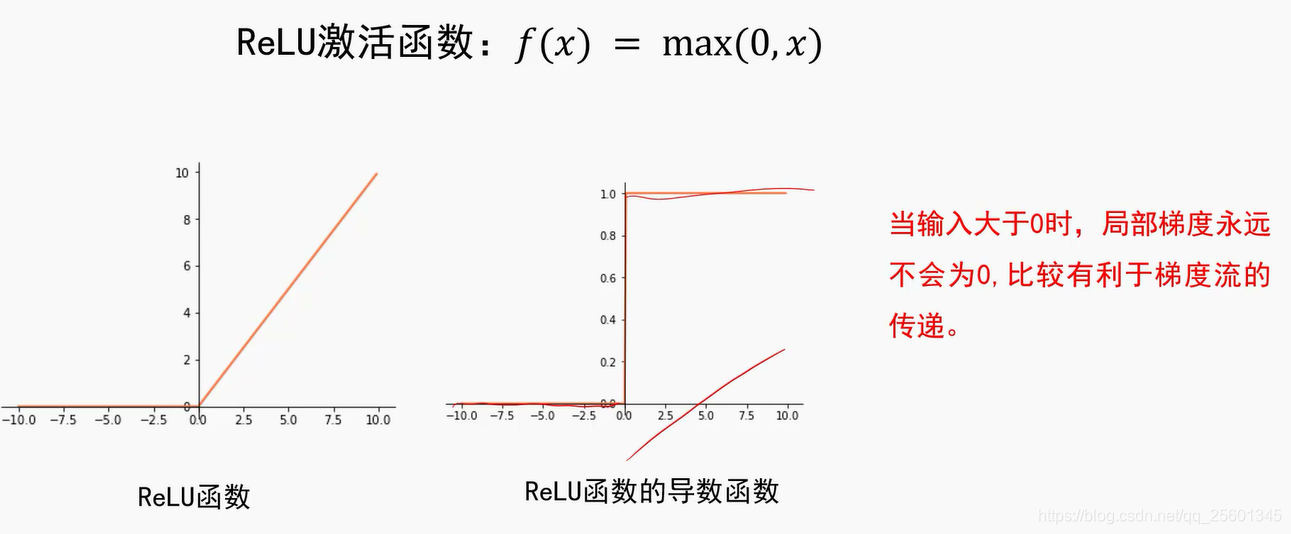
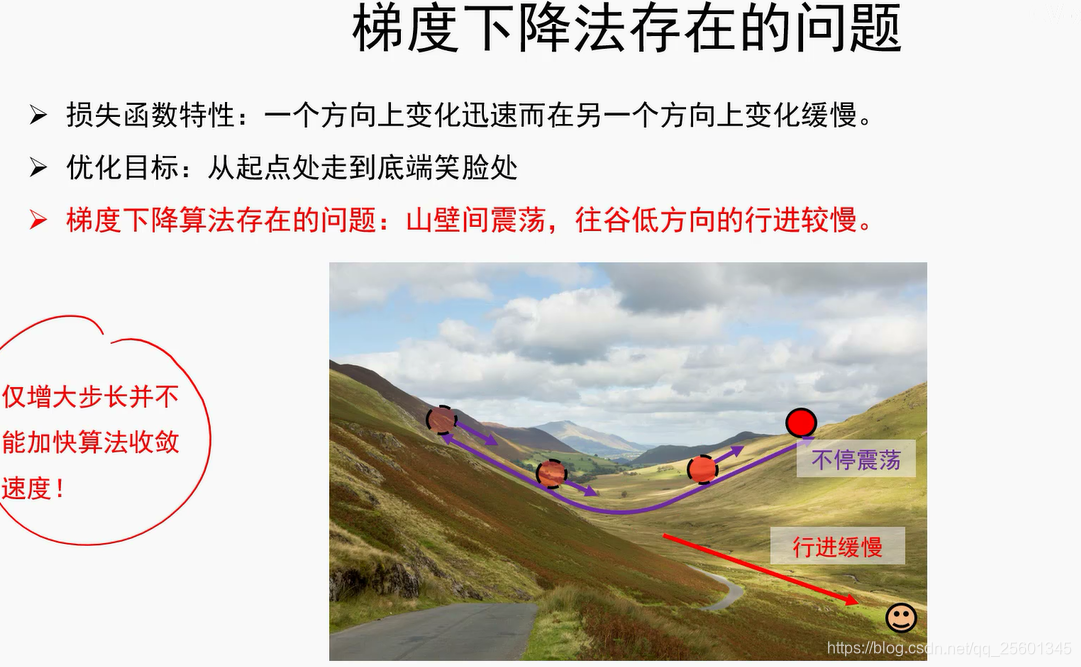
2.4.3. 动量法与自适应梯度
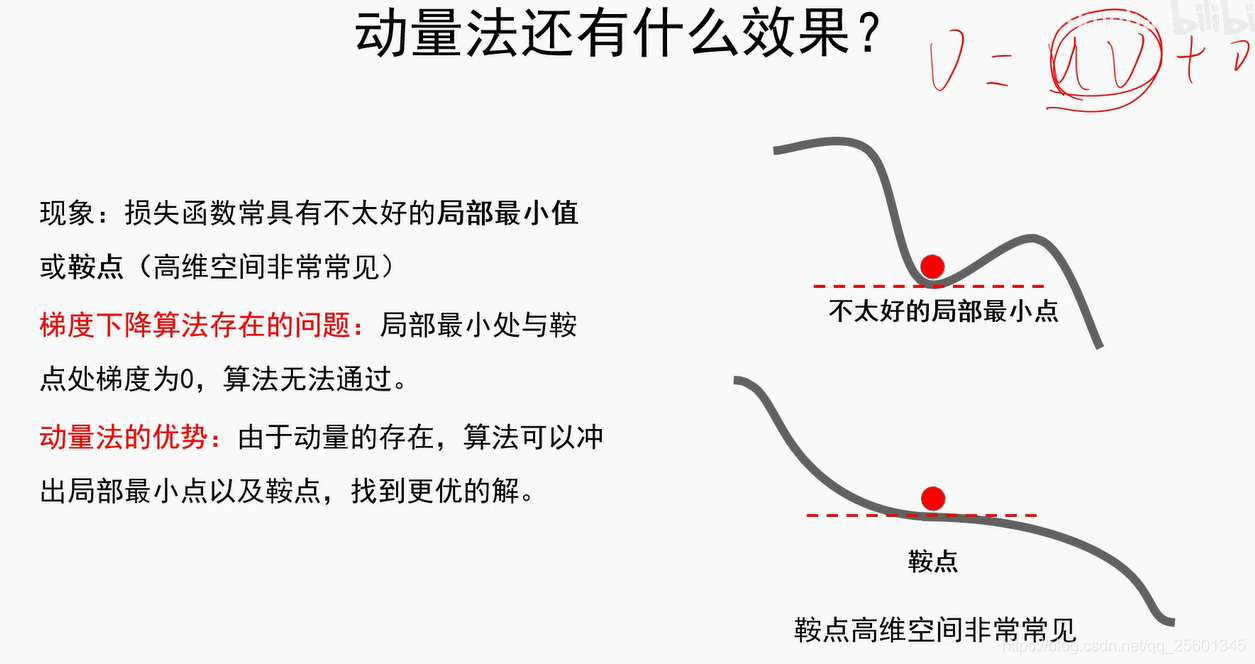
- 动量法(累加抵消,此消彼长)

- 自适应梯度与RMSProp(控制不同方向的步长)


缺点:时间长r会变得非常大,步长会变得非常小 - RMSProp

- ADAM(同时使用动量与自适应的思想)

- 动量法+SGD(手动调),会比ADAM更好一些
2.4.4. 训练过程
2.4.4.1. 权值初始化
避免全零初始化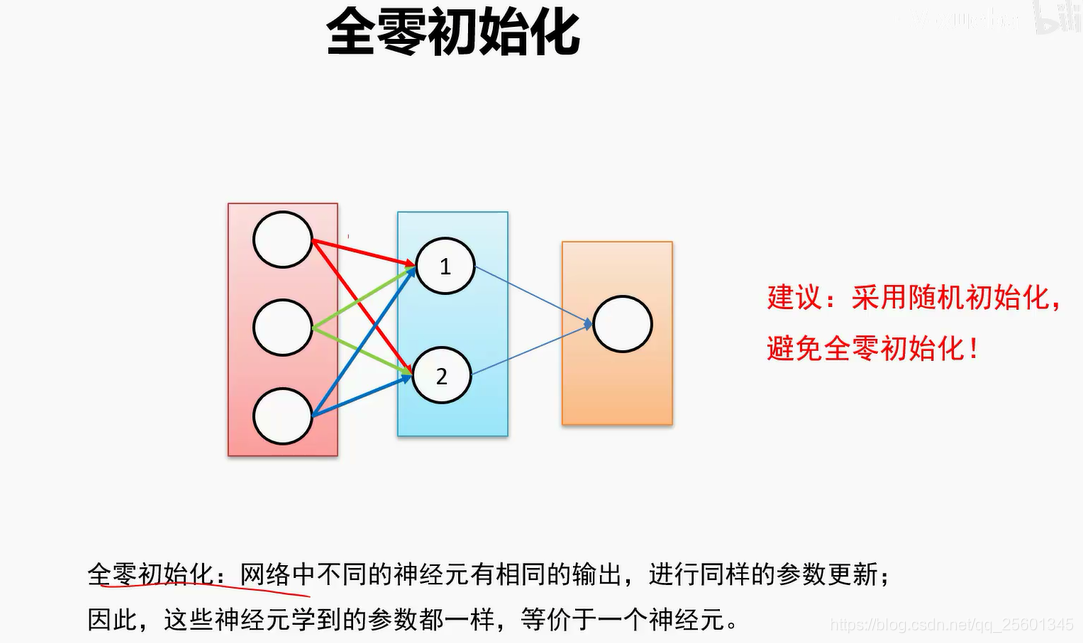

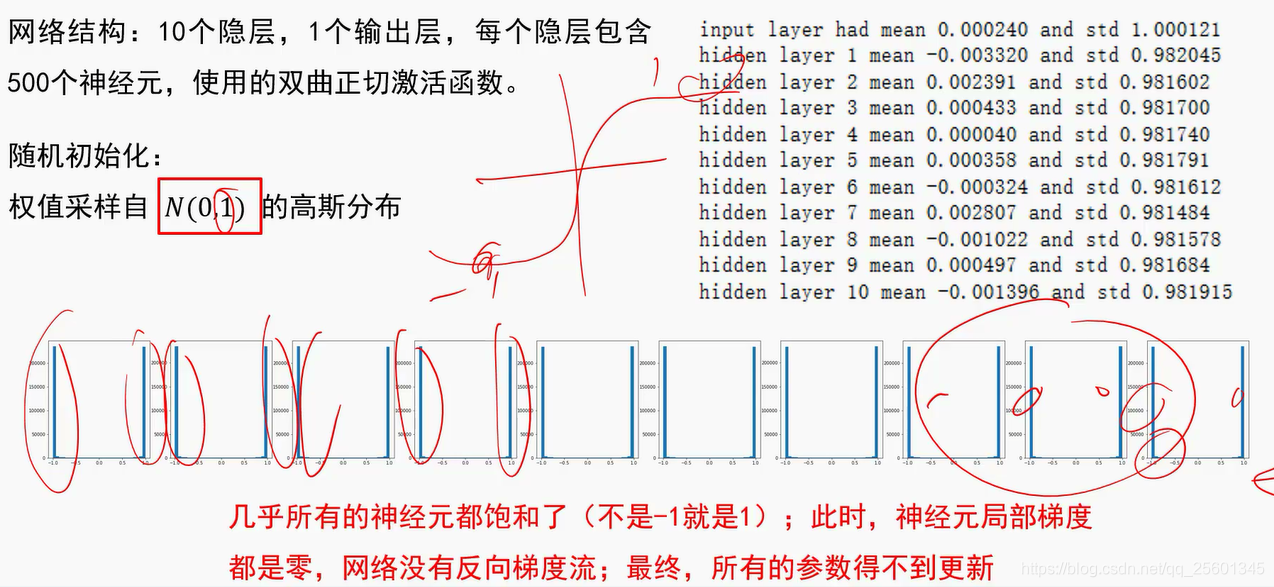
➢实验结论;初始化时让权值不相等,并不能保证网络能够正常的被训练。
➢有效的初始化方法:使网络各层的激活值和局部梯度的方差在传播过程中尽量保持一致;以保持网络中正向和反向数据流动。
- Xavier初始化


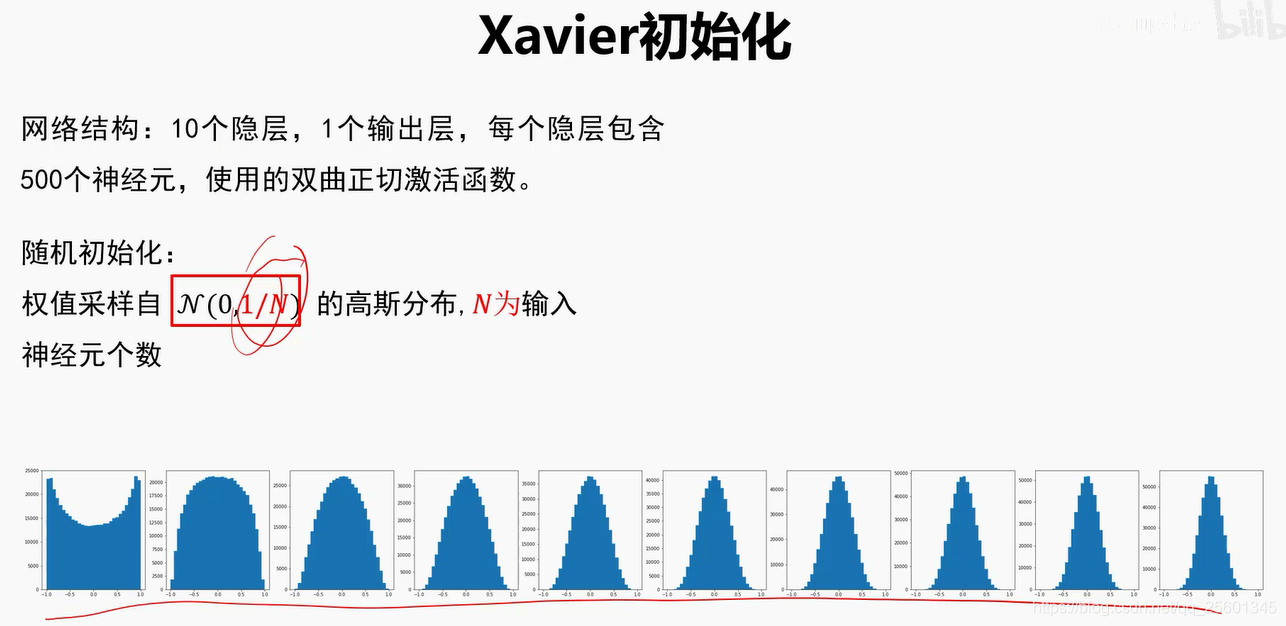
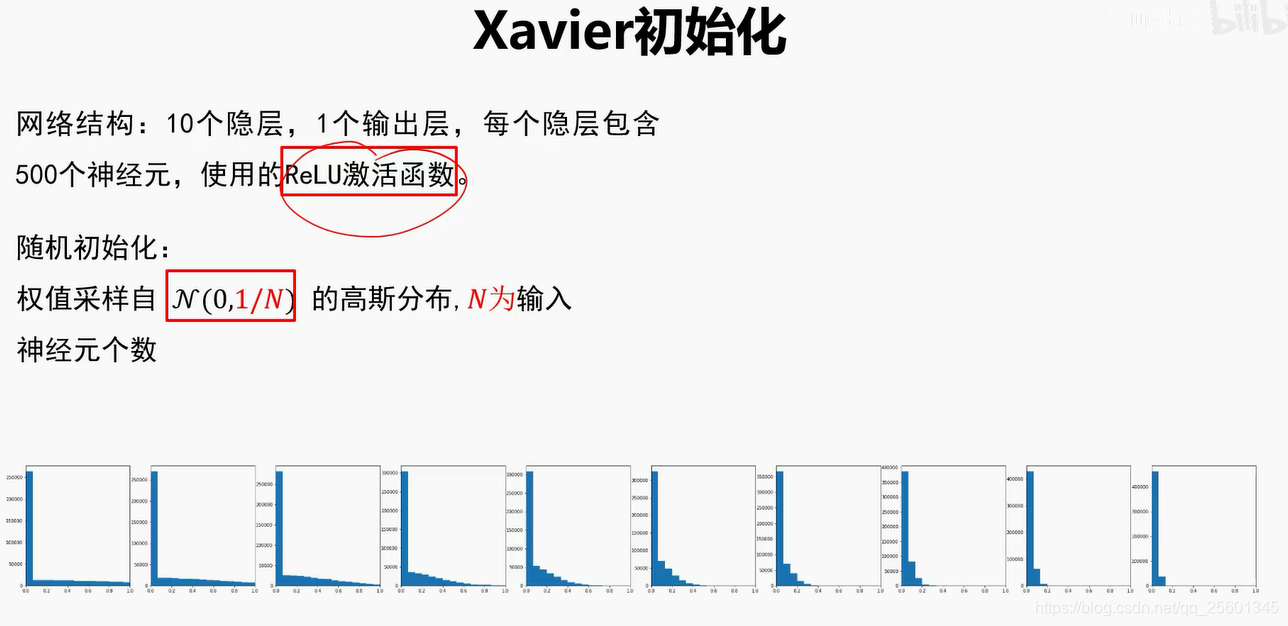
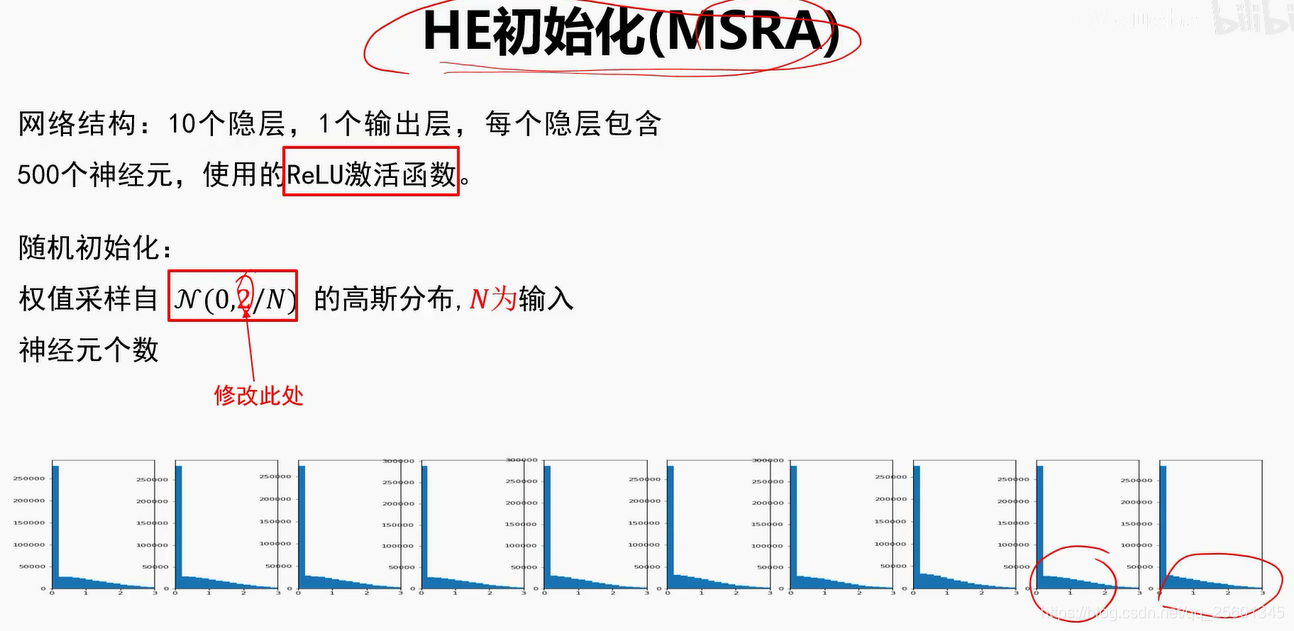
➢好的初始化方法可以防止前向传播过程中的信息消失,也可以解决反向传递过程中的梯度消失。
➢激活函数选择双曲正切或者Si gmoid时,建议使用Xaizer初始化方法;
➢激活函数选择ReLU或Leak ly ReLU时,推荐使用He初始化方法。
2.4.4.2. 批归一化
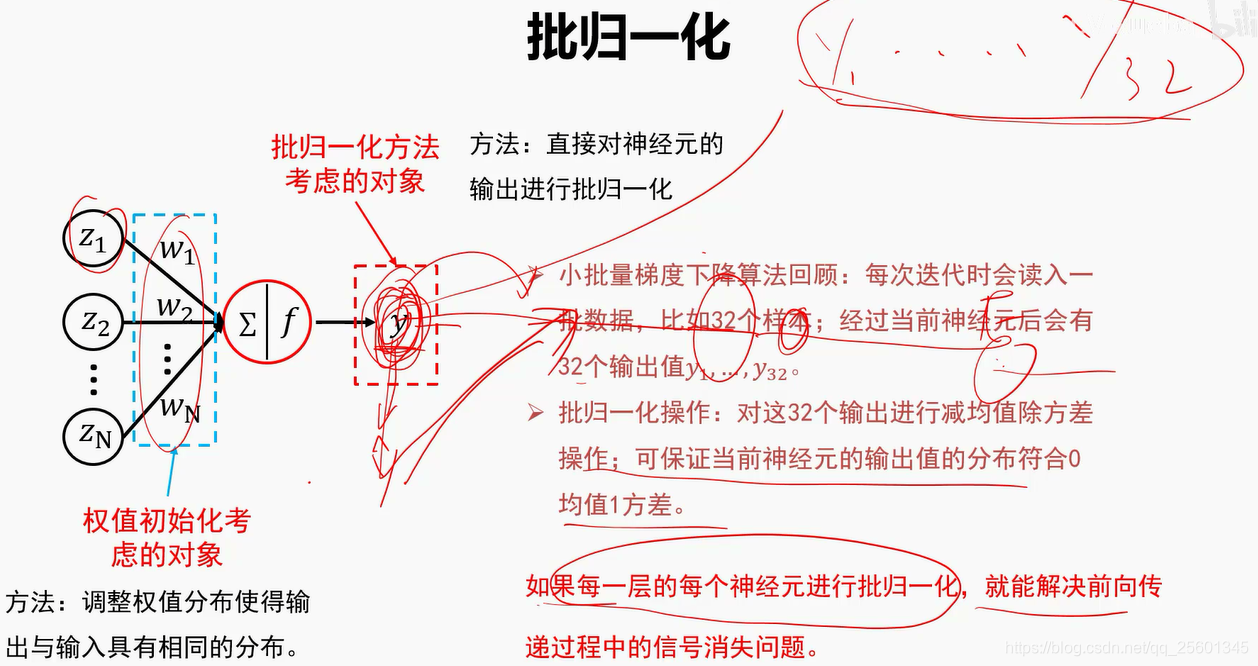
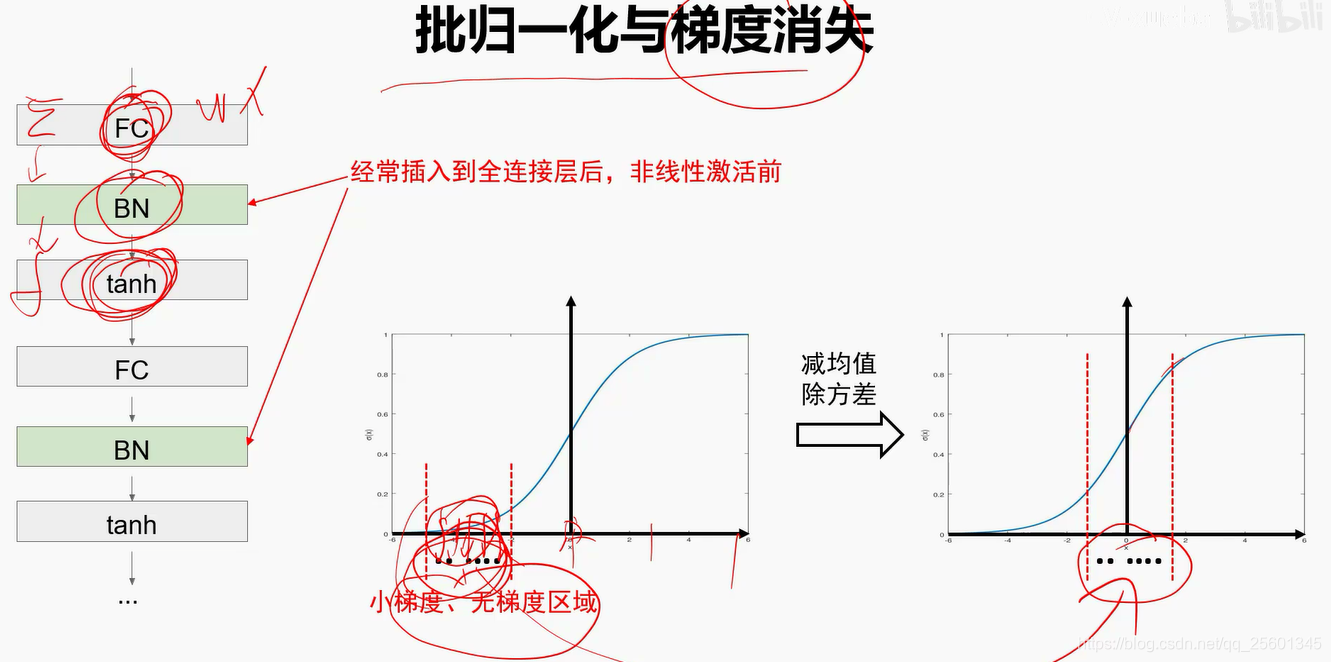

2.4.4.3. 欠拟合、过拟合与Dropout
过拟合
是指学习时选择的模型所包含的参数过多,以至于出现这一-模型对已知数据预测的很好,但对未知数据预测得很差的现象。这种情况下模型可能只是记住了训练集数据,而不是学习到了数据特征。
欠拟合
一模型描述能力太弱,以至于不能很好地学习到数据中的规律。产生欠拟合的原因通常是模型过于简单。
➢机器学习的根本问题是优化和泛化的问题。
➢优化-(是指调节模型以在训练数据上得到最佳性能)
➢泛化-{是指训练好的模型在前所未见的数据上的性能好坏)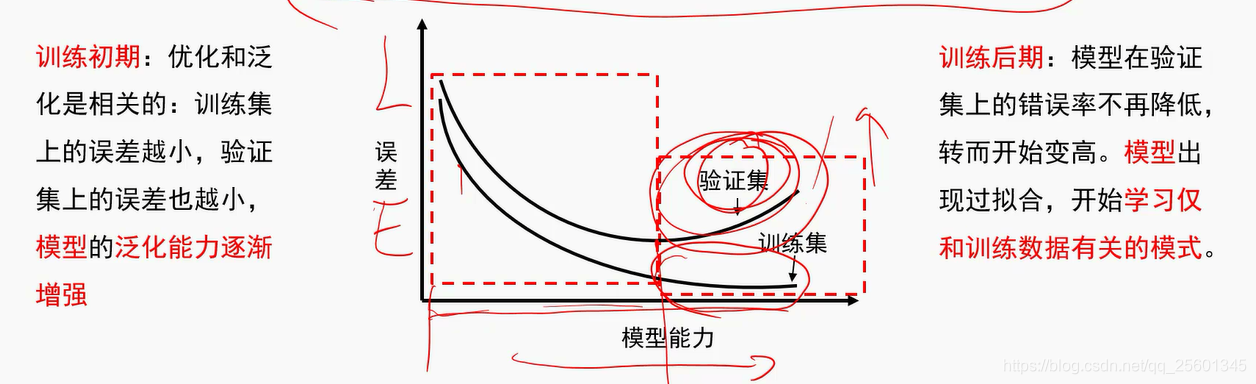
- 应对过拟合
最优方案-获取更多的训练数据
次优方案-调节模型允许存储的信息量或者对模型允许存储的信息加以约束,该类方法也称为正则化。
➢调节模型大小
➢约束模型权重,即权重正则化(常用的有L1、L2正则化)
➢随机失活(Dropout)
正则化:
随机失活(Dropout):

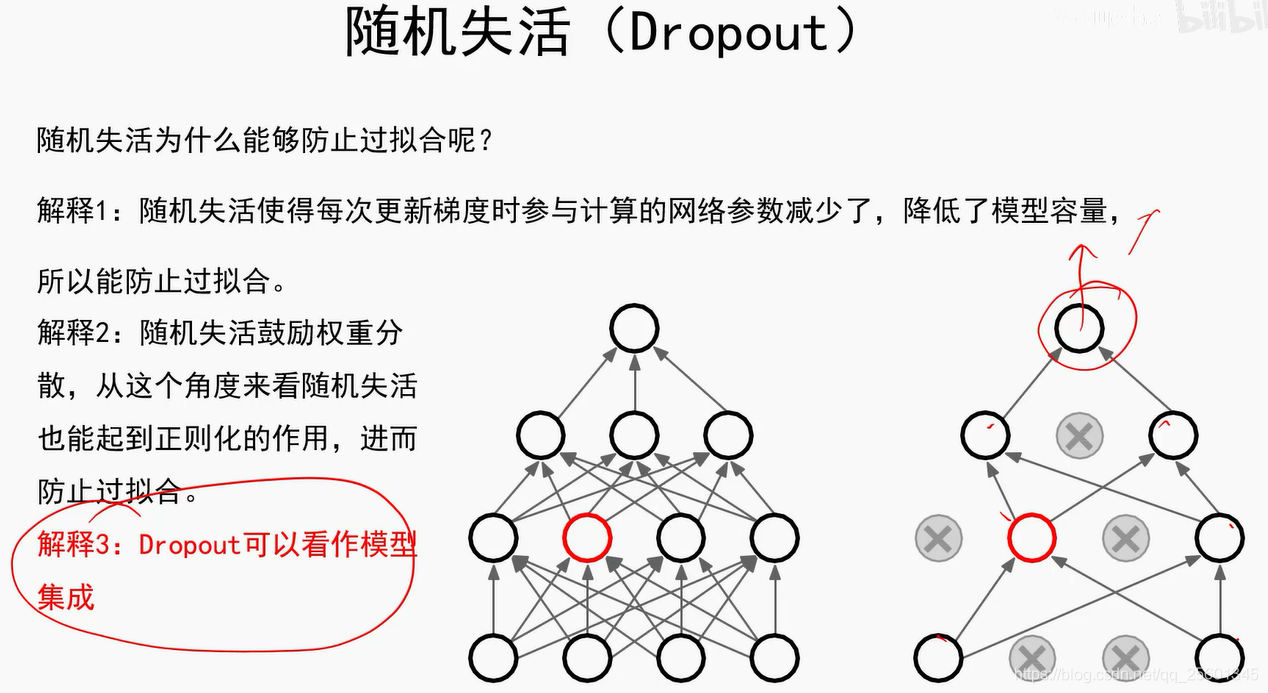
随即失活应用

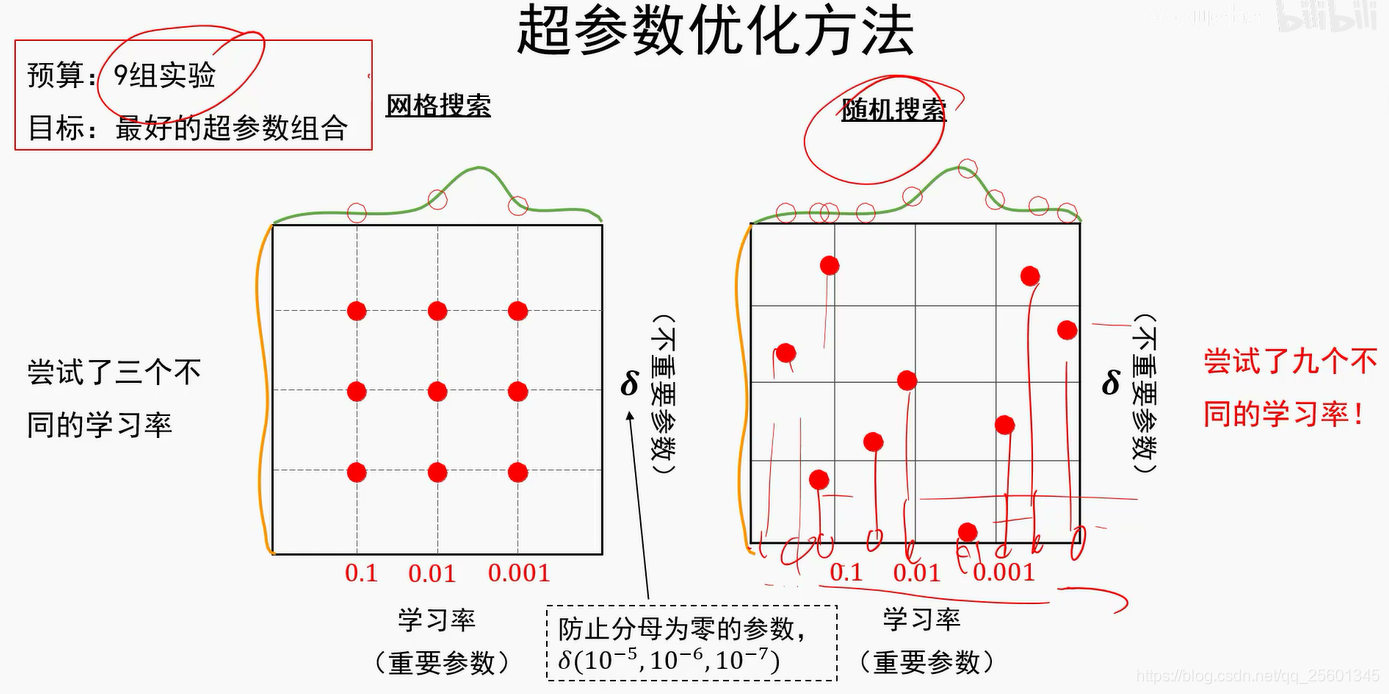
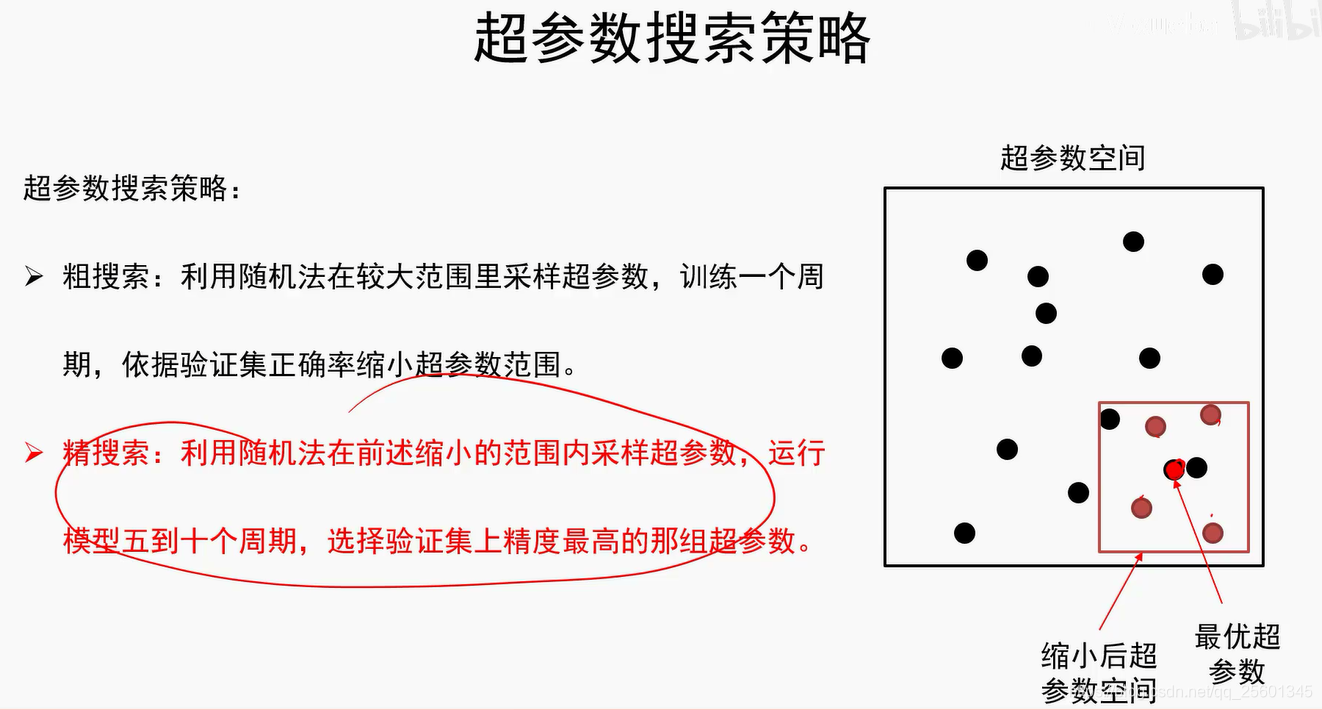
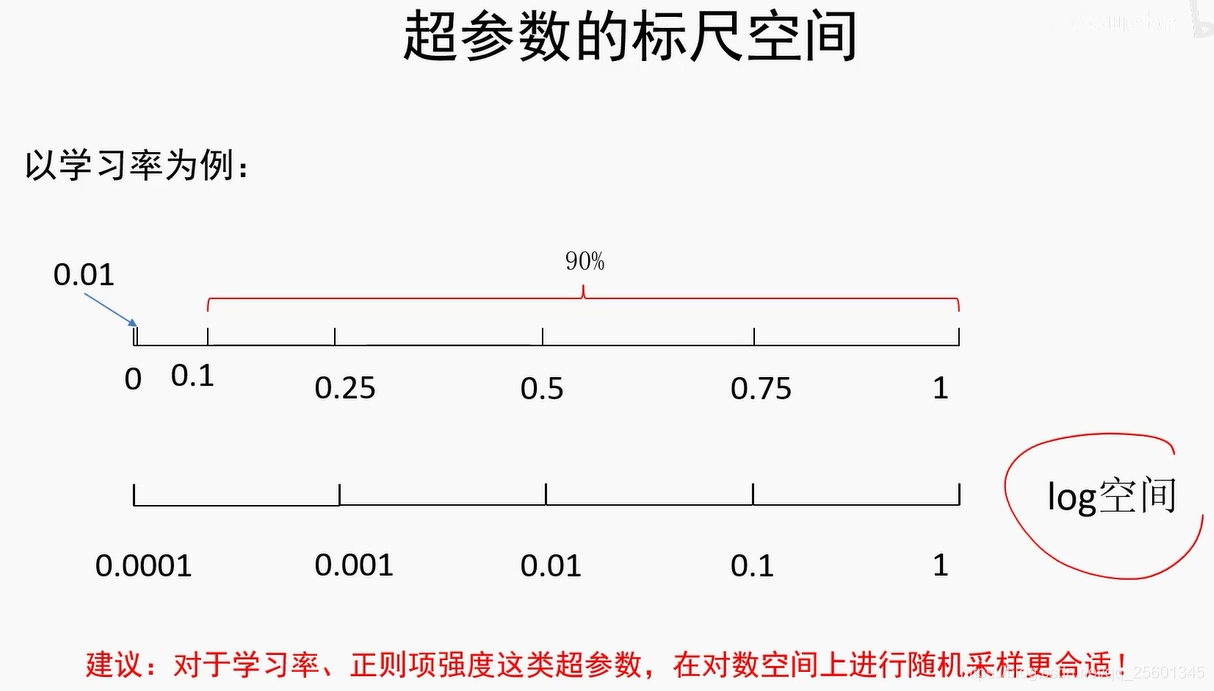
2.4.4.4. 模型正则与超参数调优



四、卷积与图像去噪



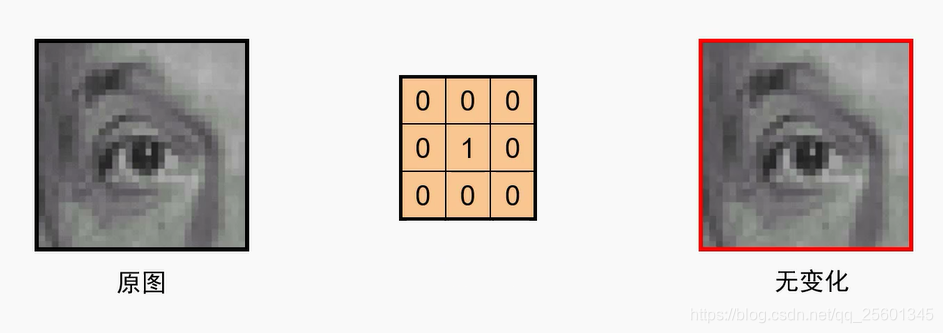
1. 边界填充
- ➢卷积操作后的图像要小于输入时图像,通过边界填充,我们可以实现卷积前后图像的尺寸不变;
- ➢一种最常用的边界填充就是常数填充。
zero padding

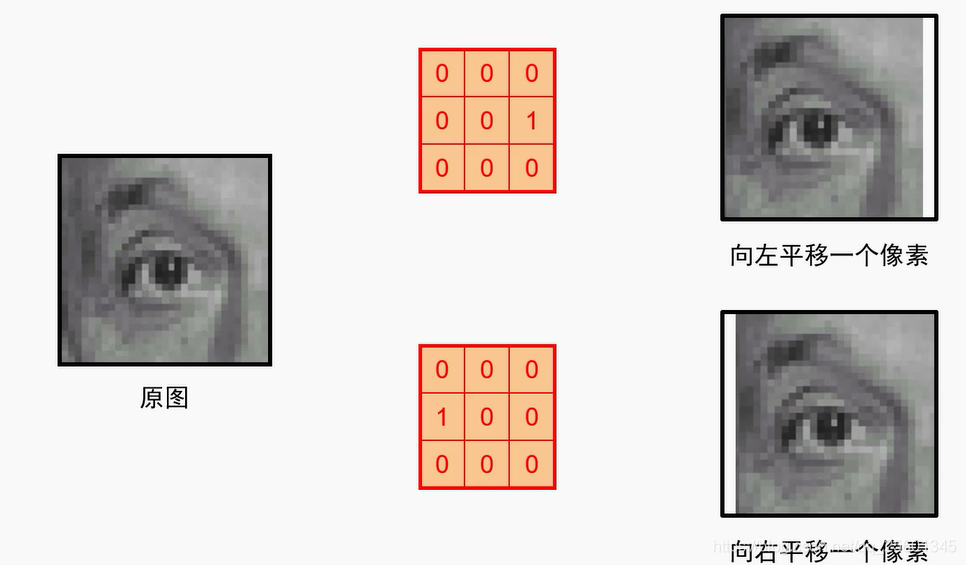
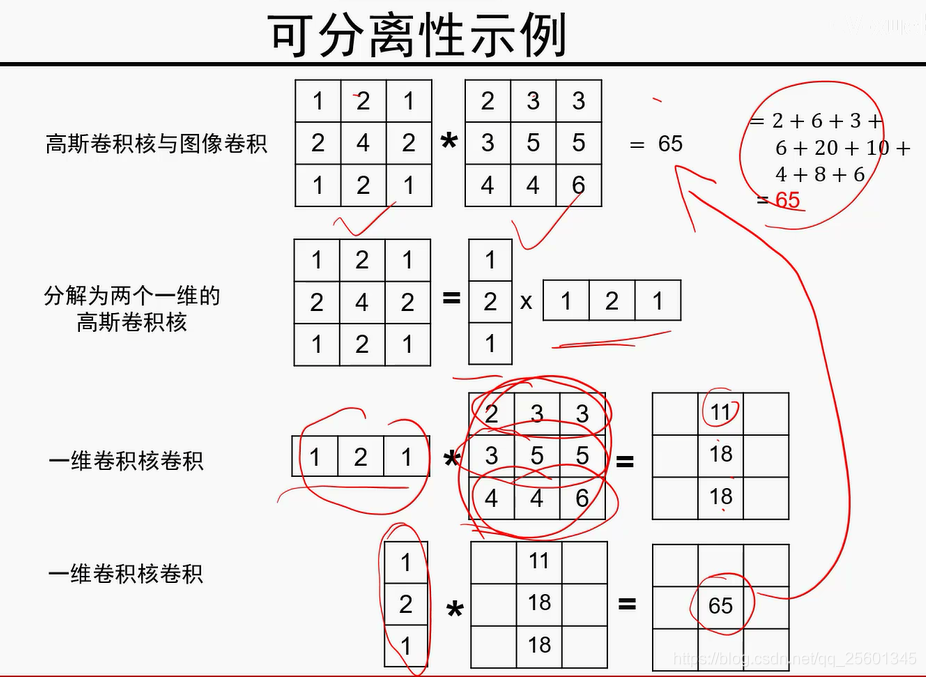
2. 卷积示例
- 可以实现平移操作
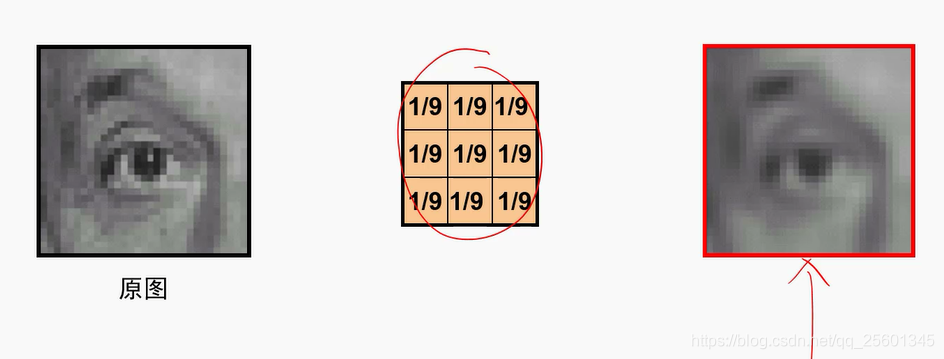
- 平滑
- 锐化
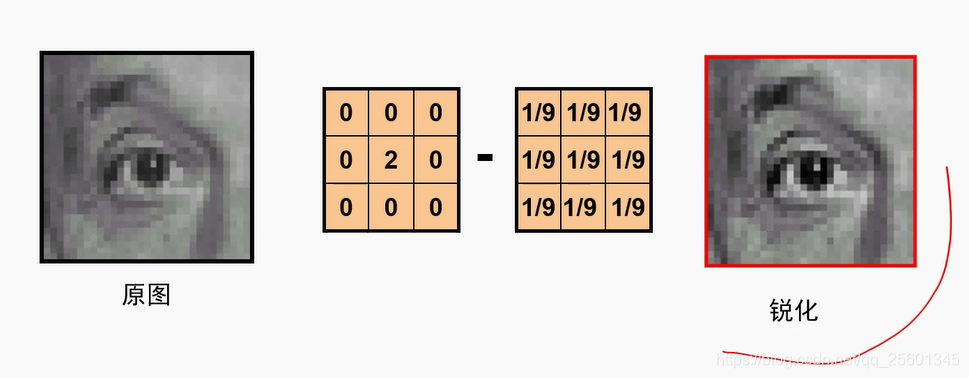

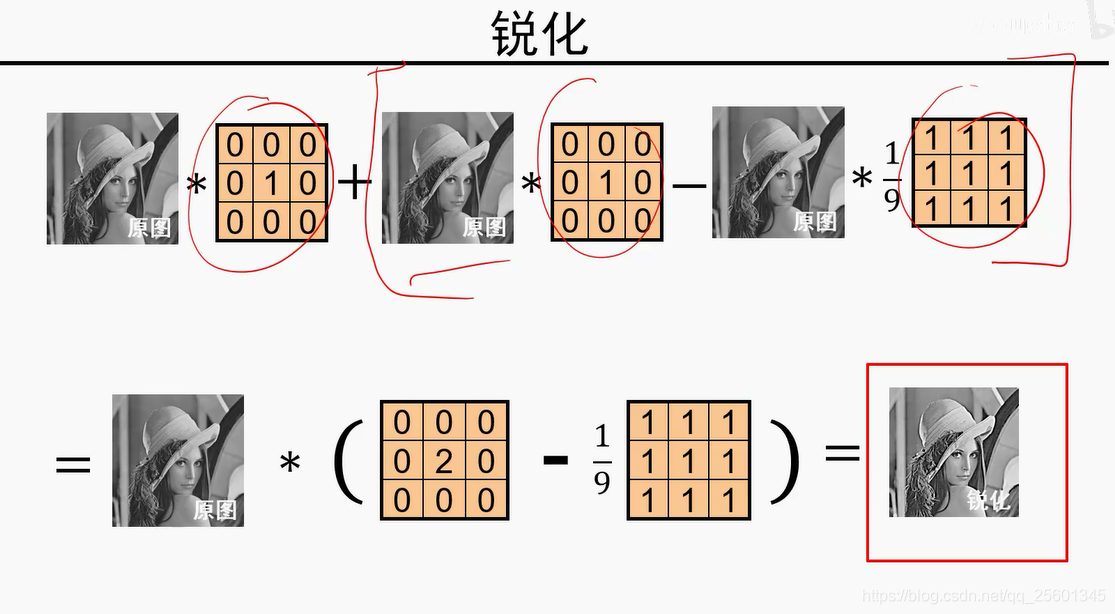
3. 高斯卷积核

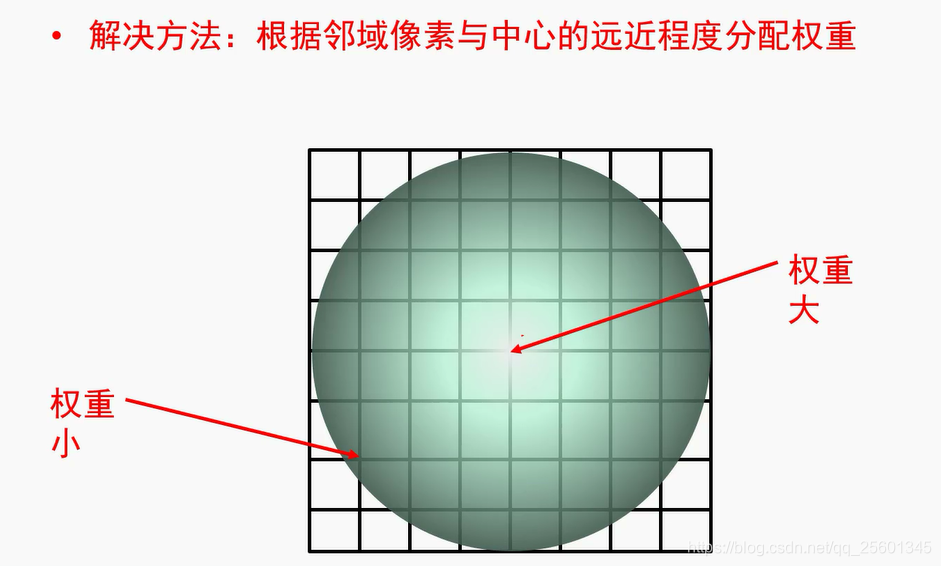
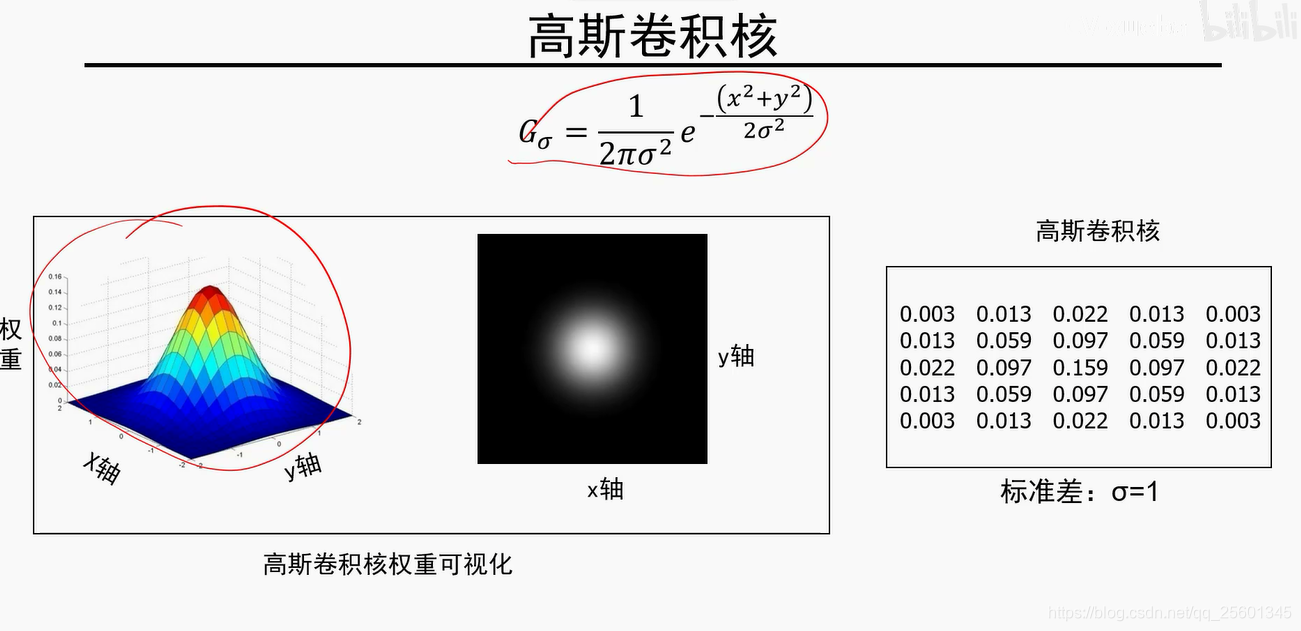
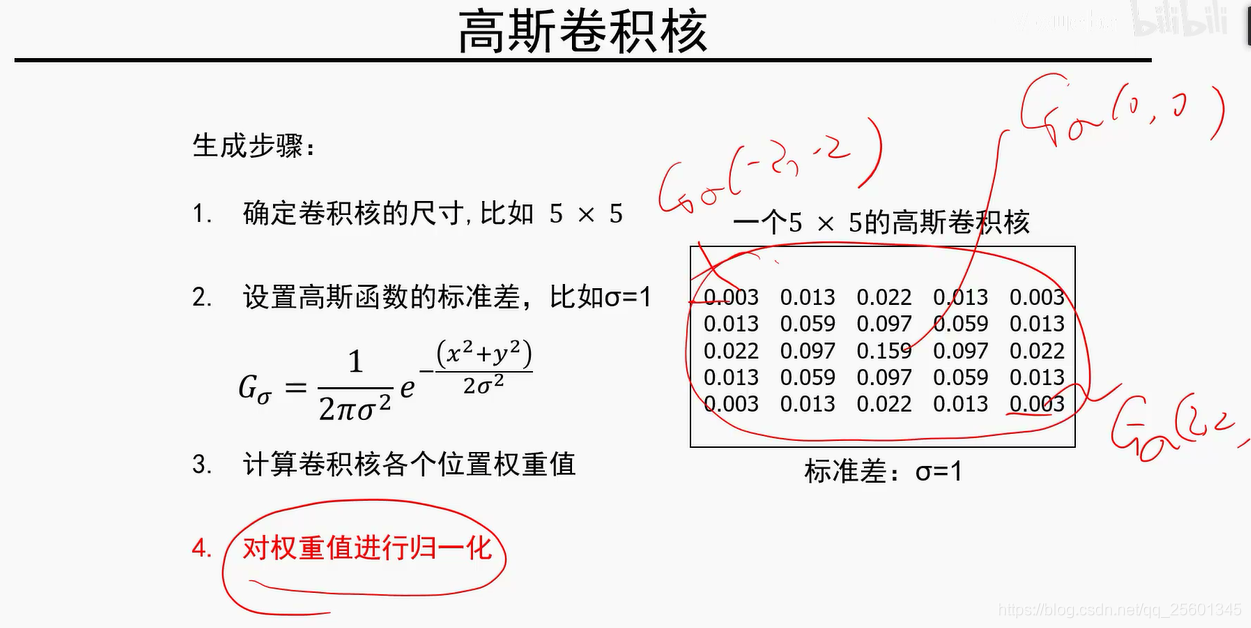
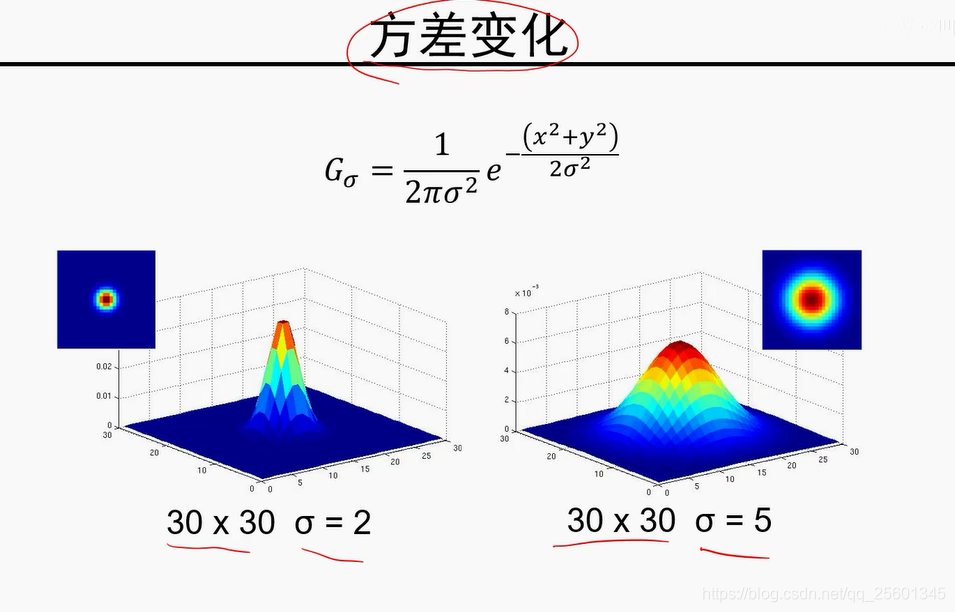
方差越大,平滑程度就比较厉害,平滑效果比较明显
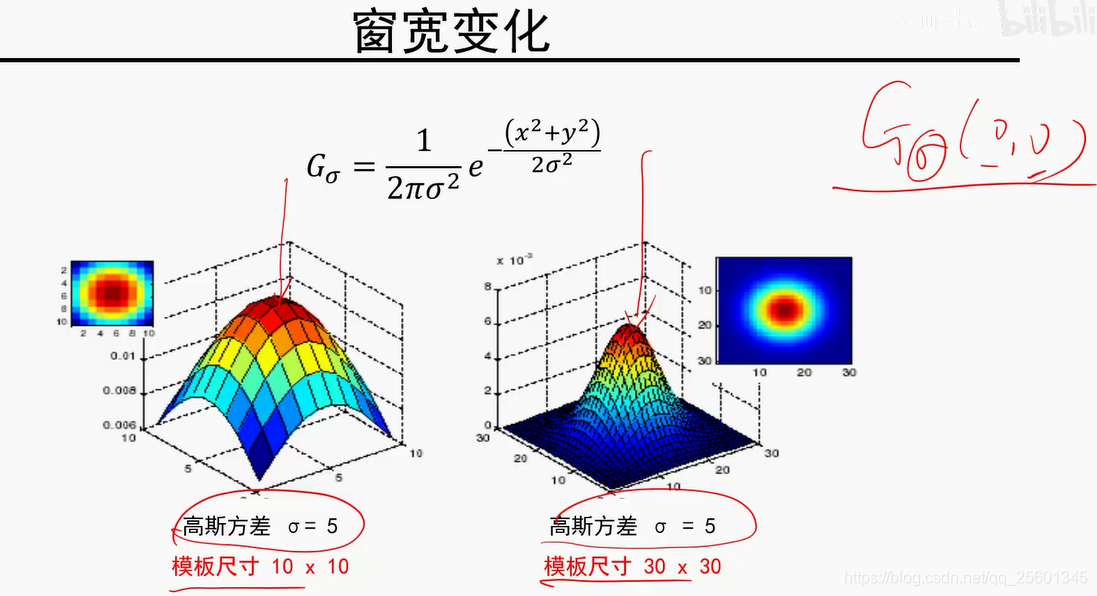
模板尺寸越大,平滑程度就比较厉害,平滑效果比较明显(因为归一化)


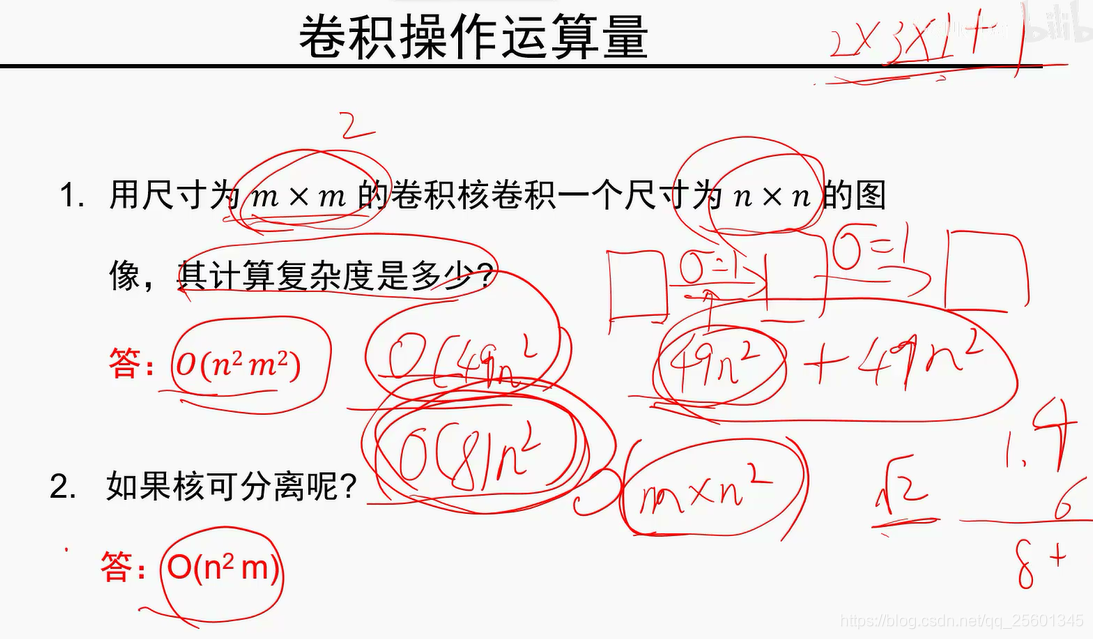
4. 图像噪声与中值滤波器

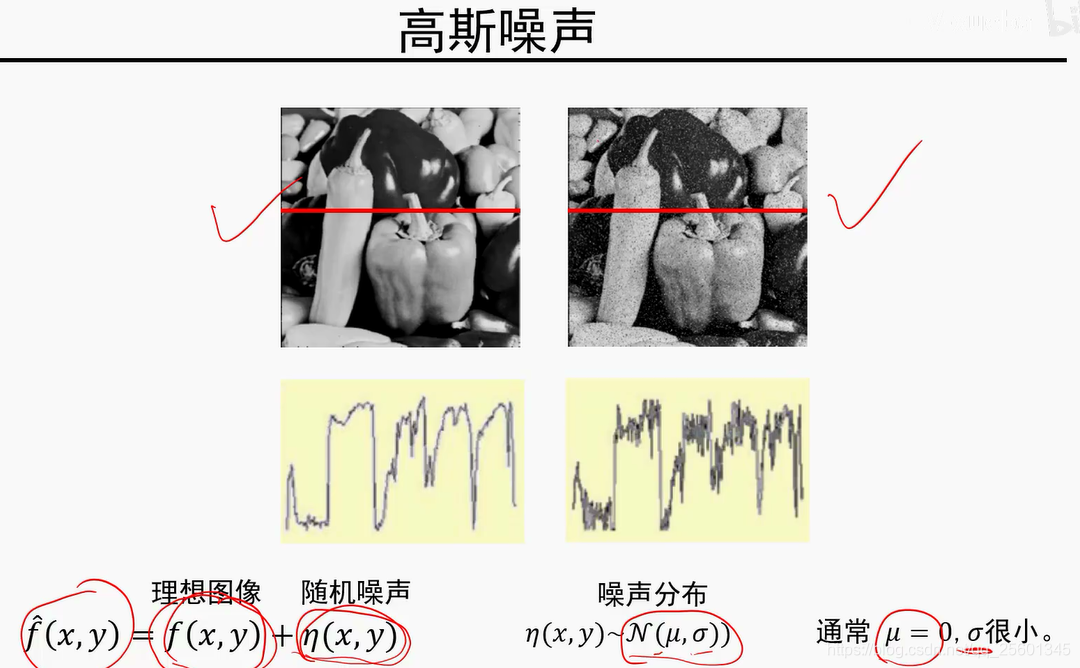

高斯噪声较大,则使用较大方差的卷积模板
4.2. 中值滤波器(不是线性滤波器)
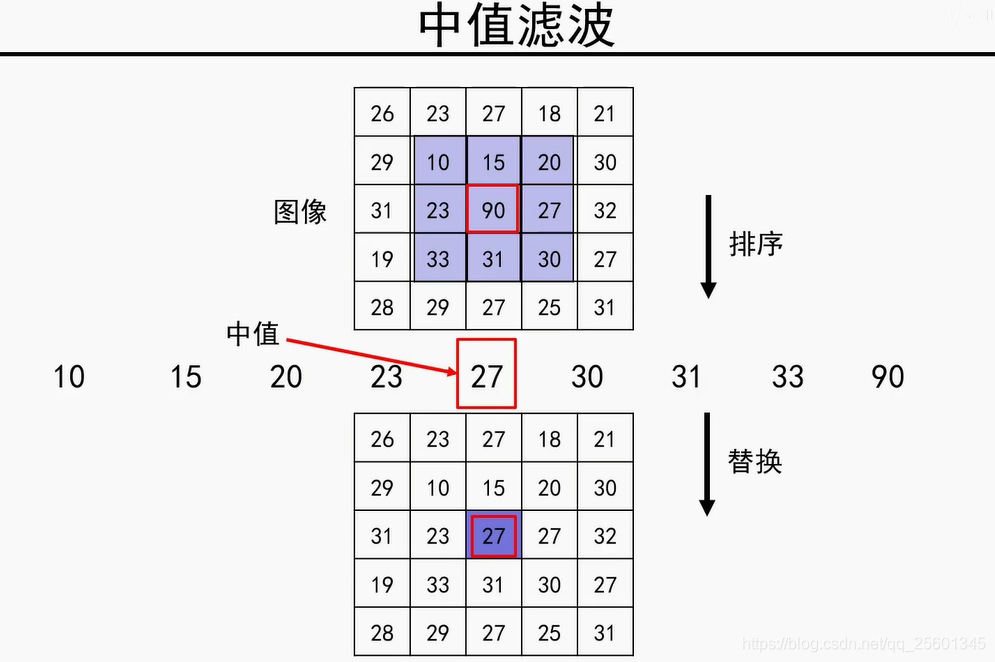
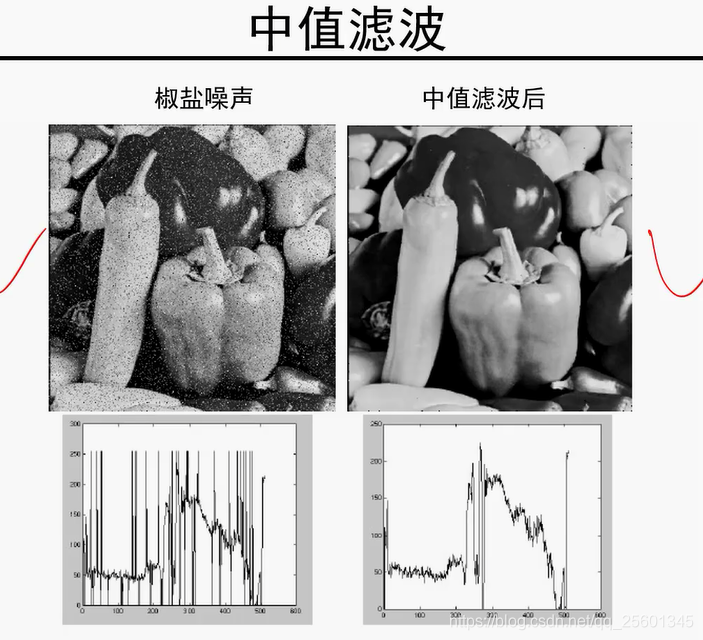
5. 卷积与边缘提取

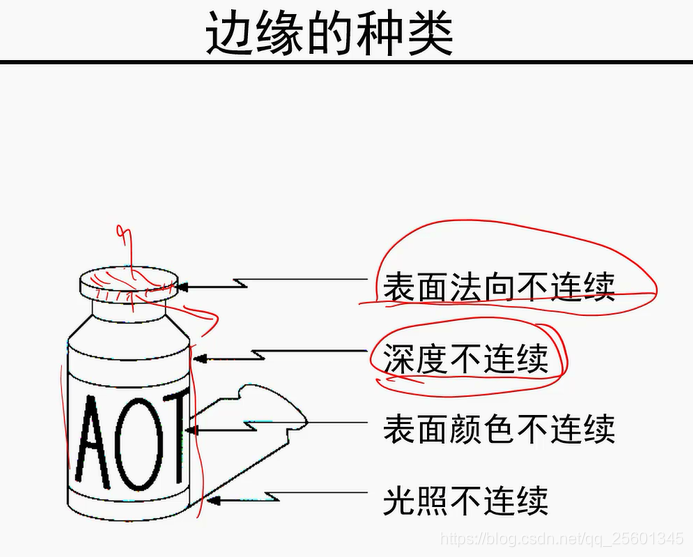
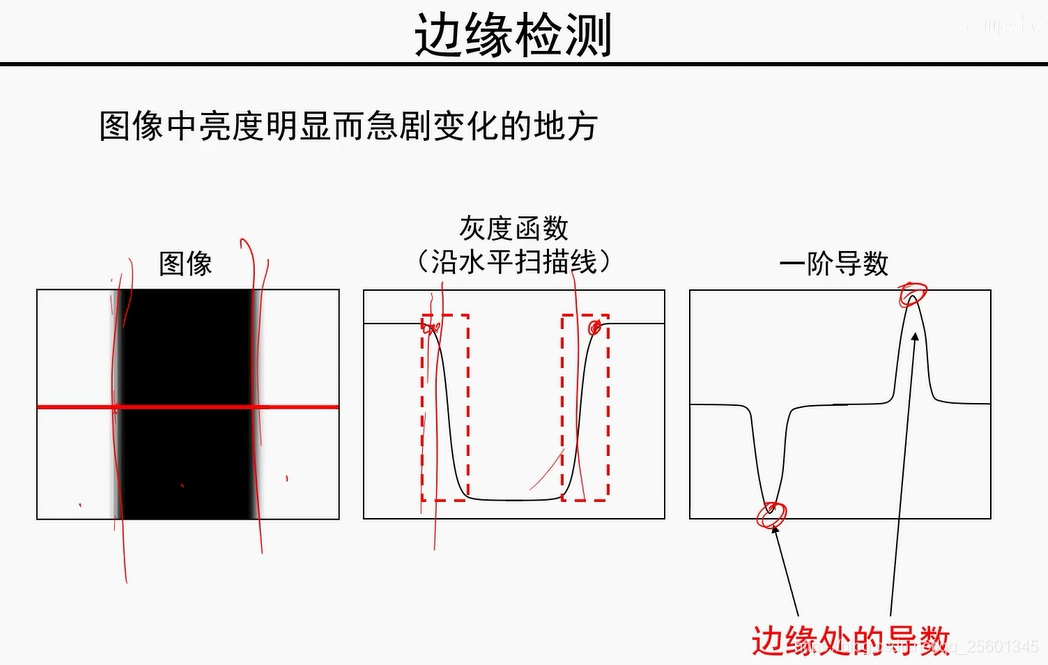


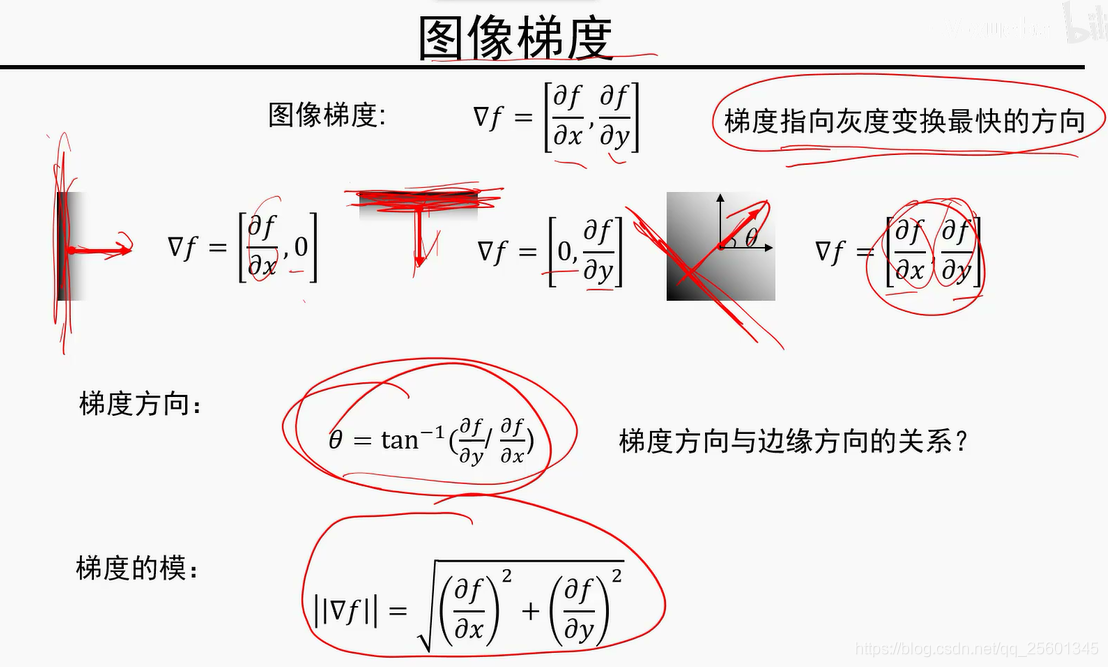
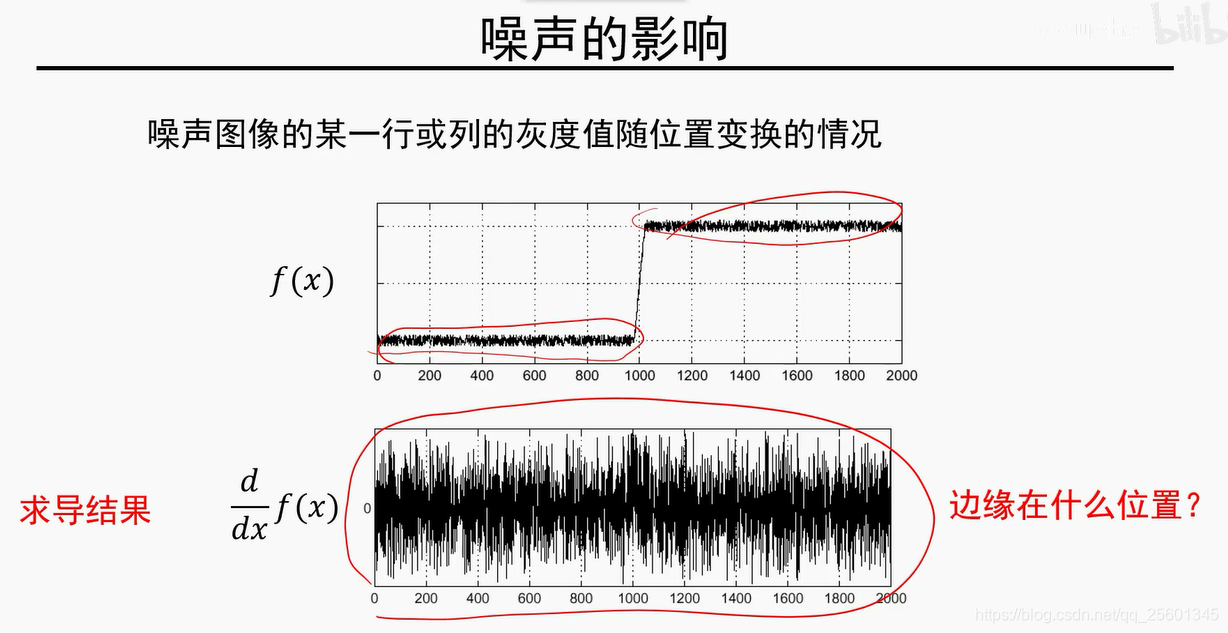
模值越大,是边缘的可能性越大。
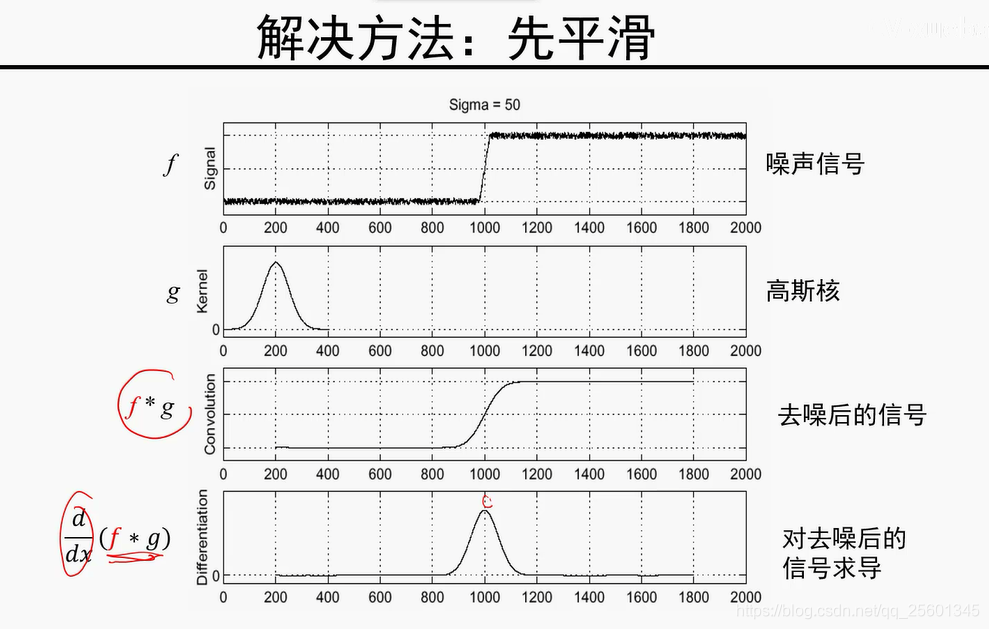
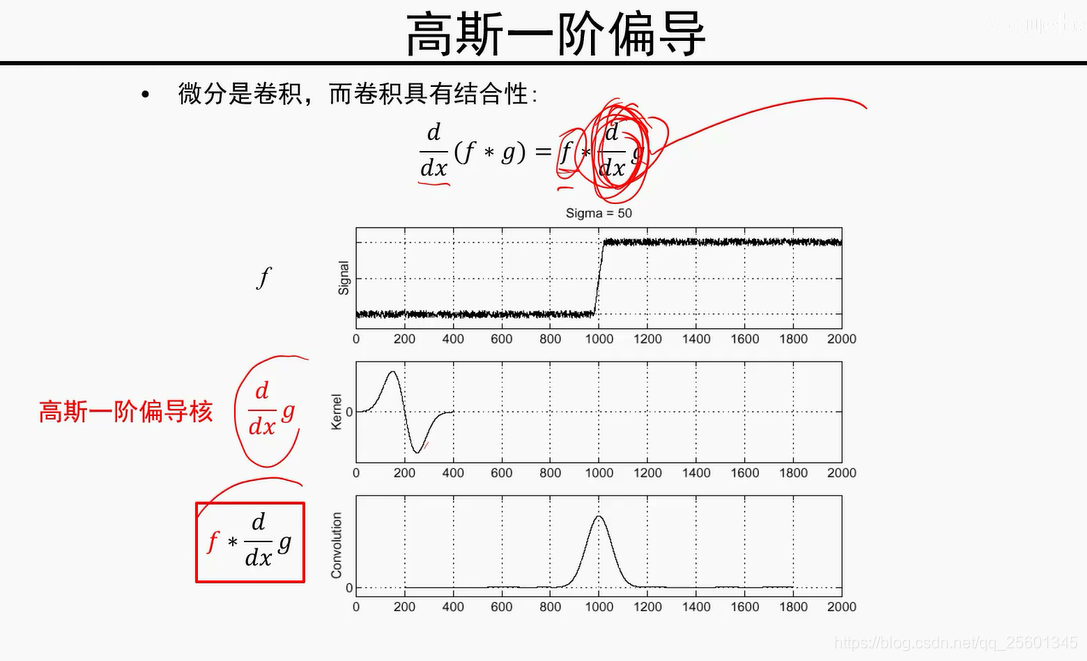
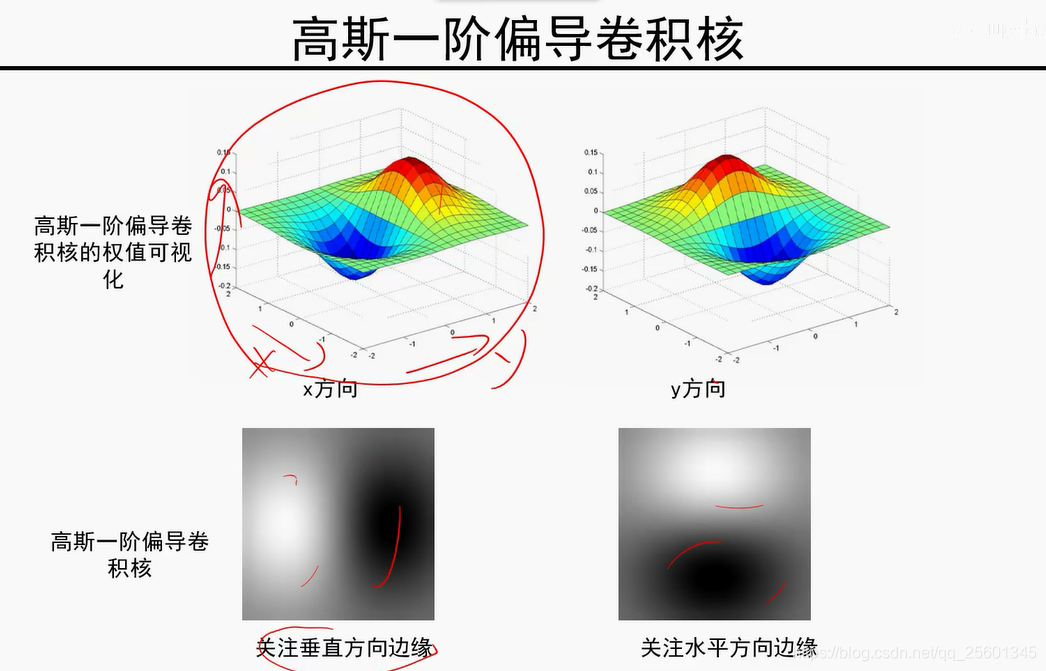
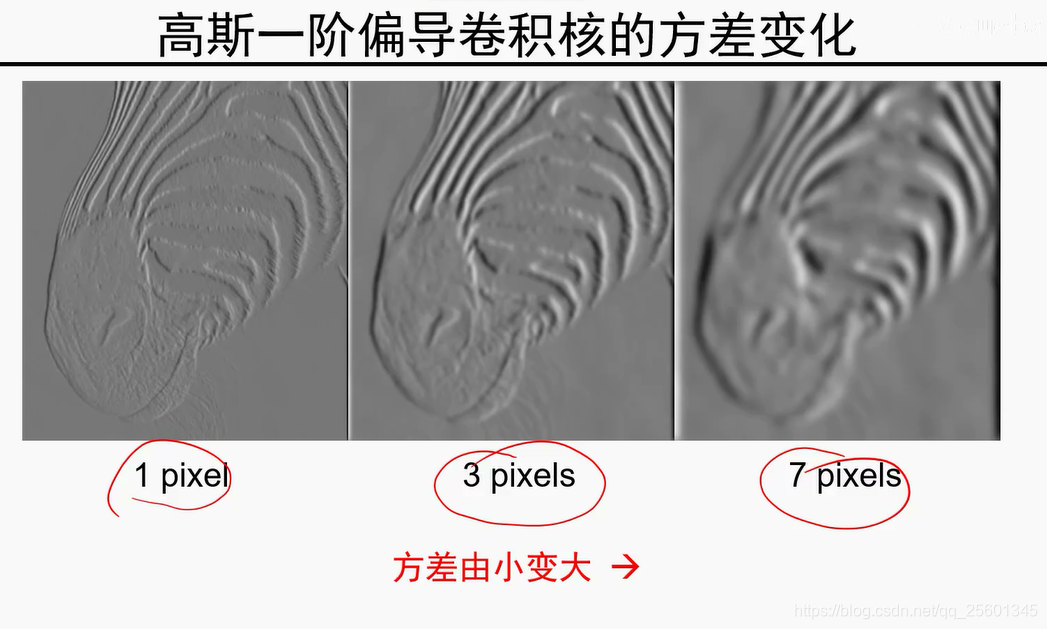
由细到粗


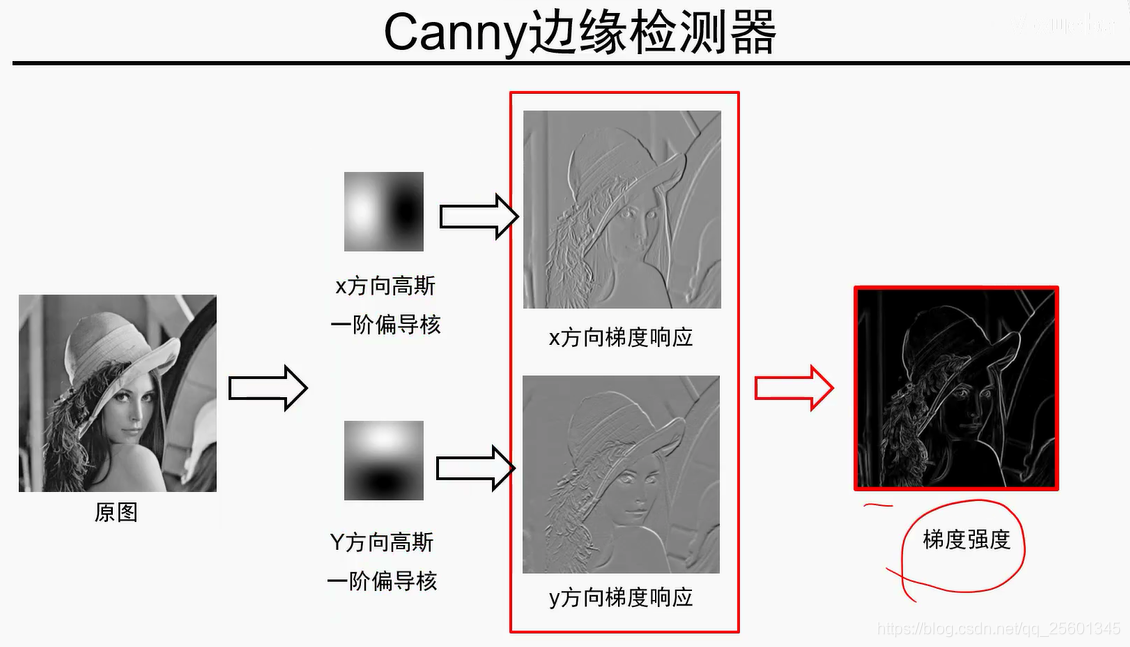
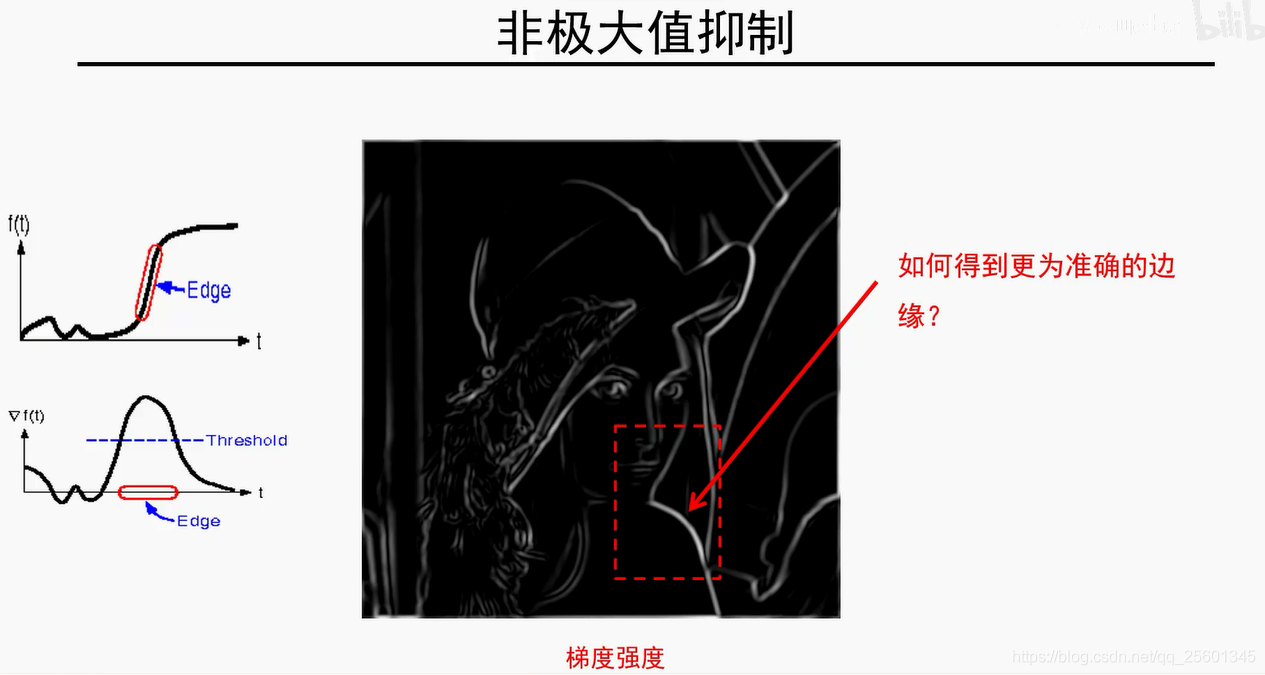
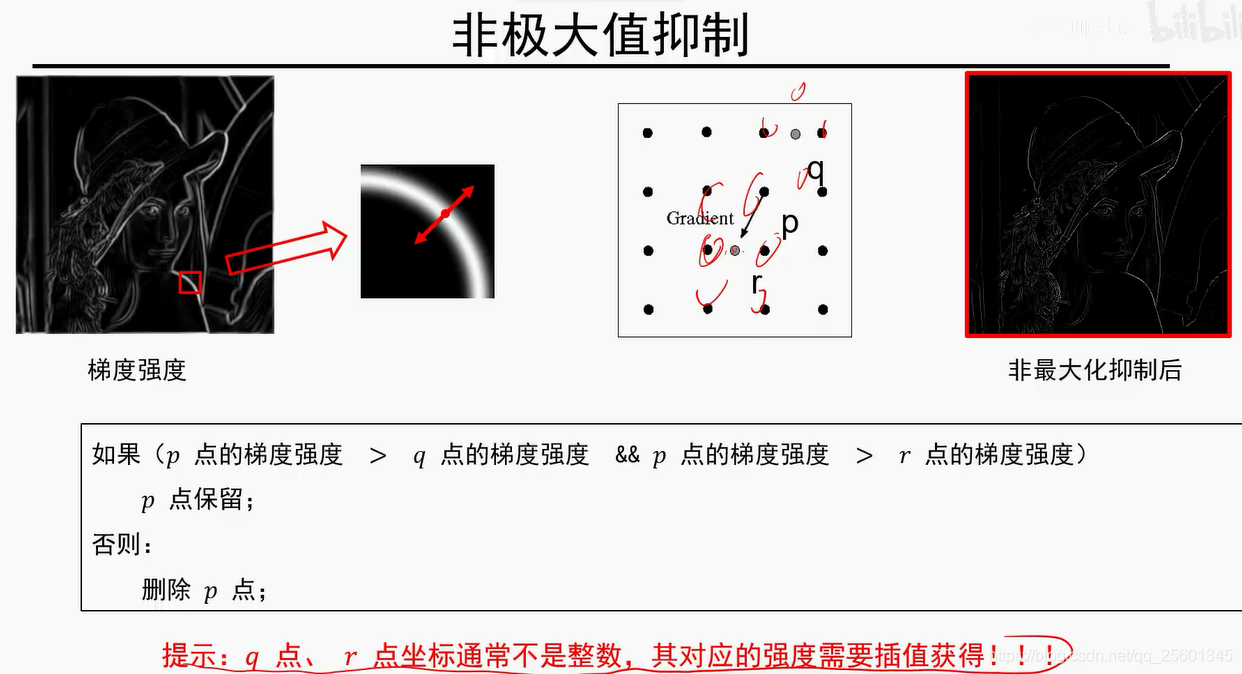
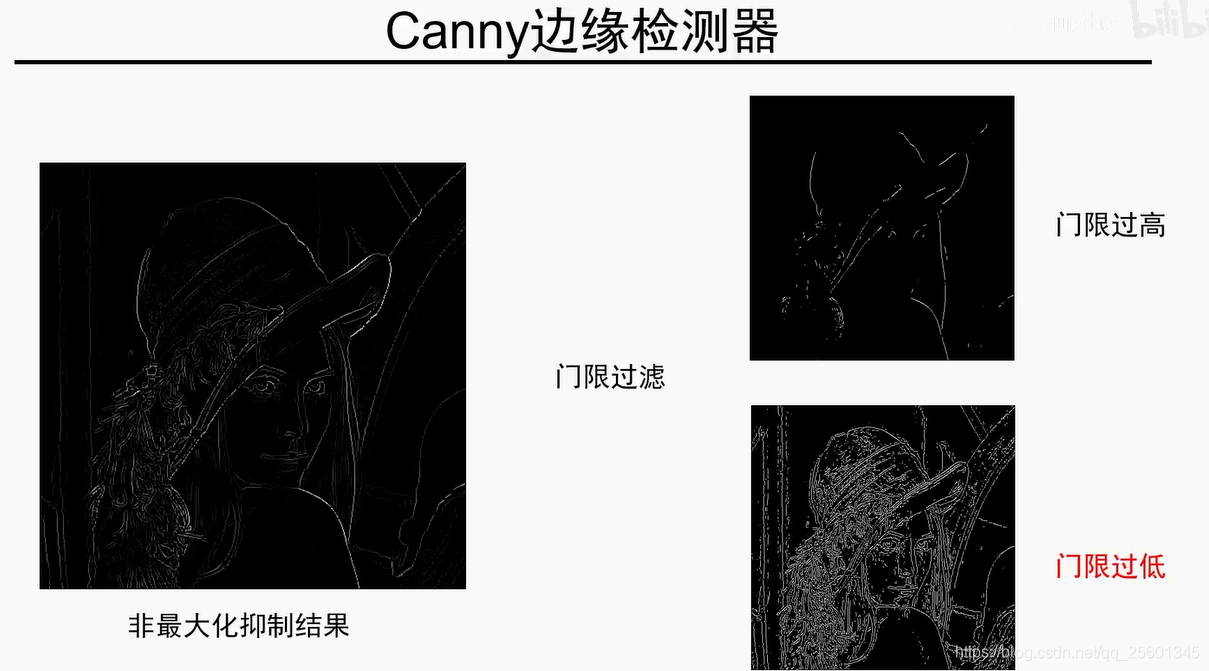
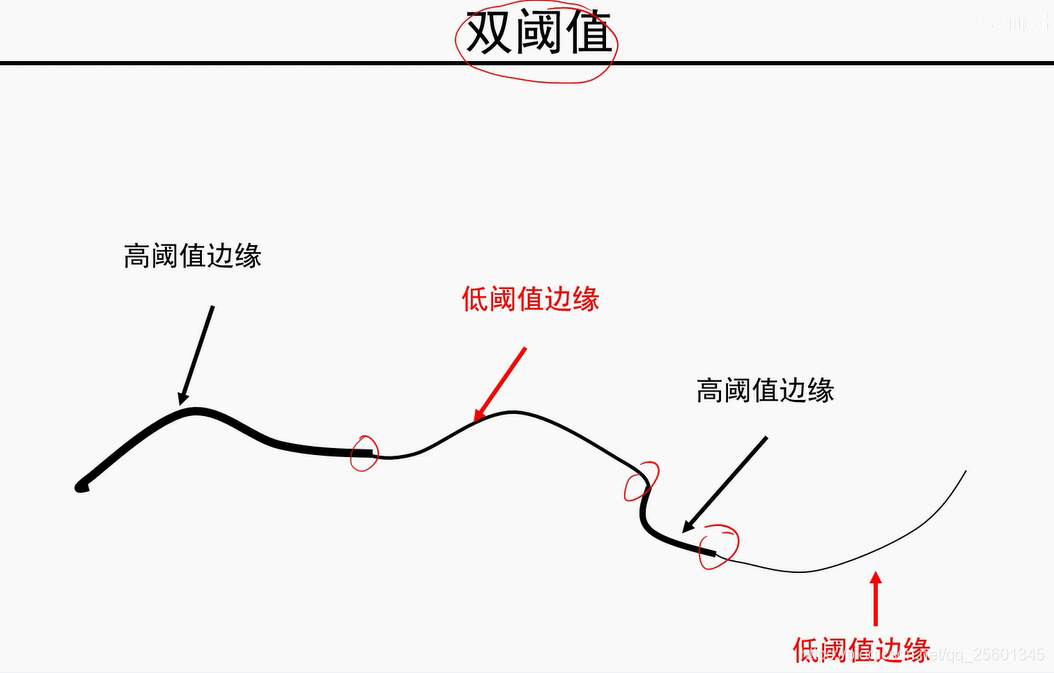

6. 纹理表示


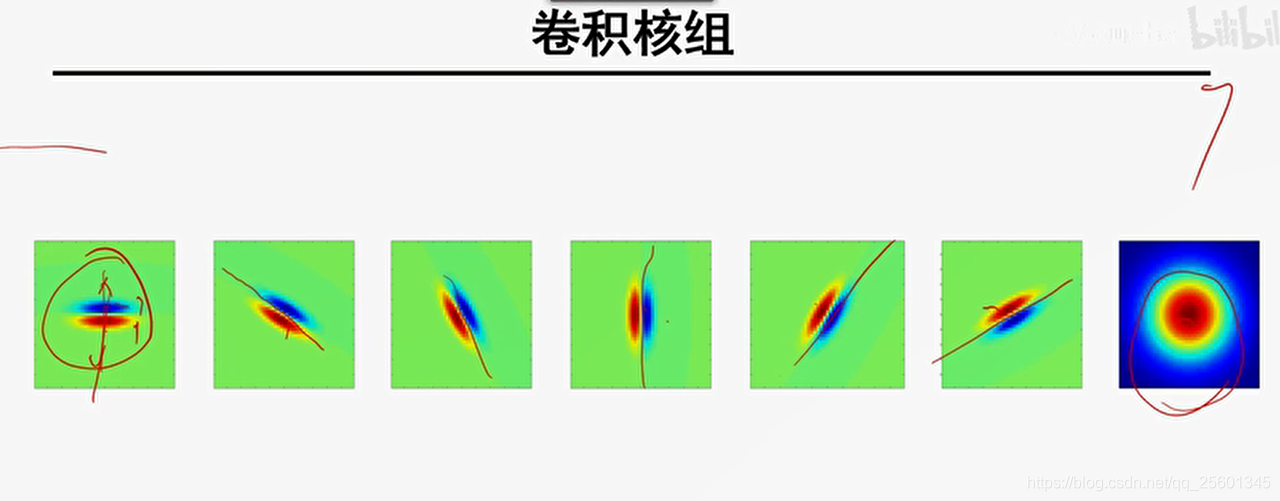


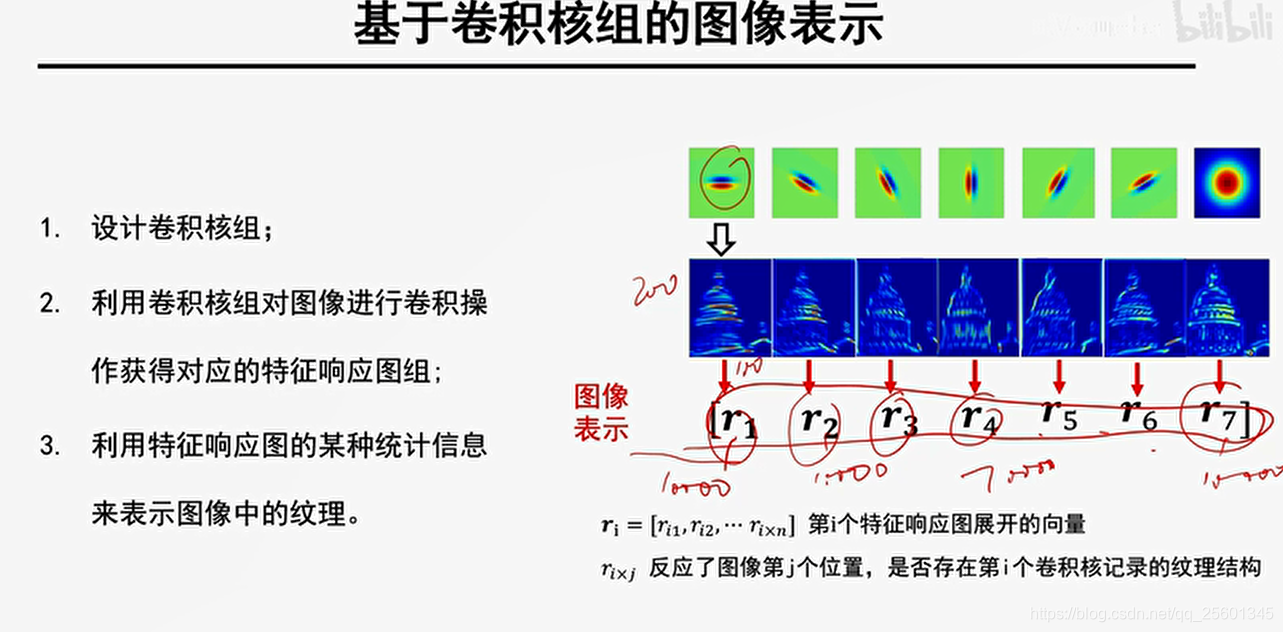

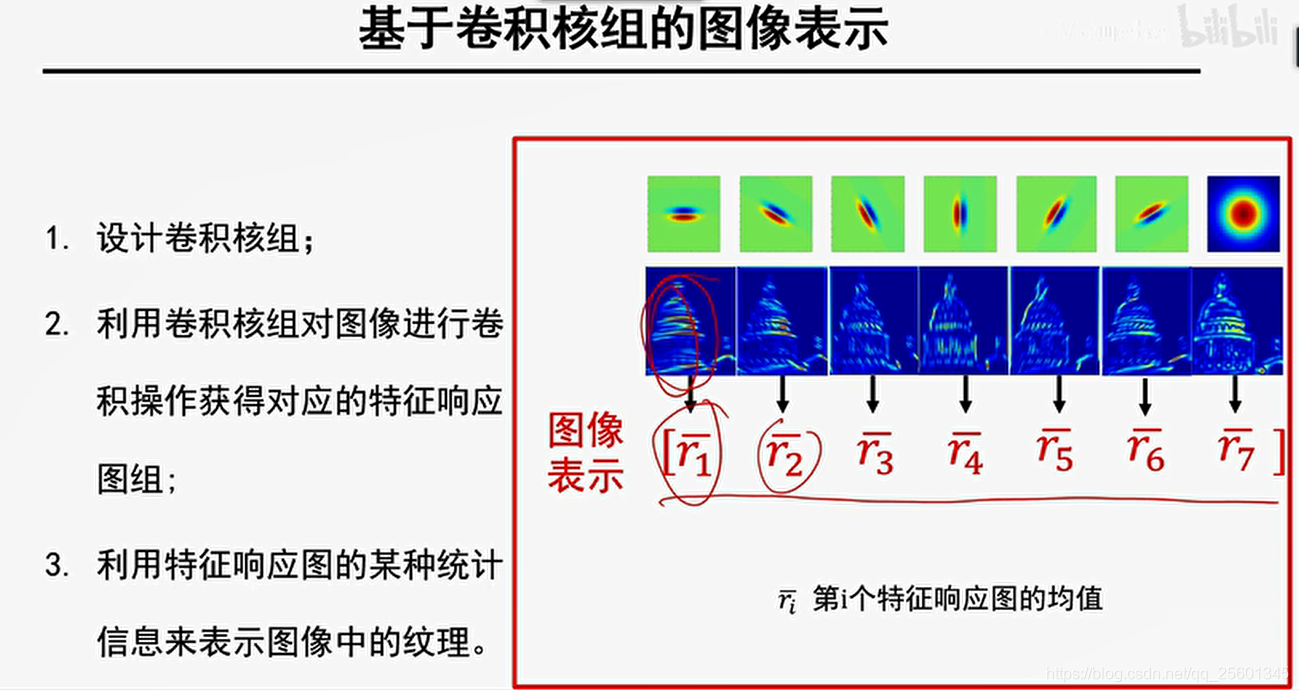
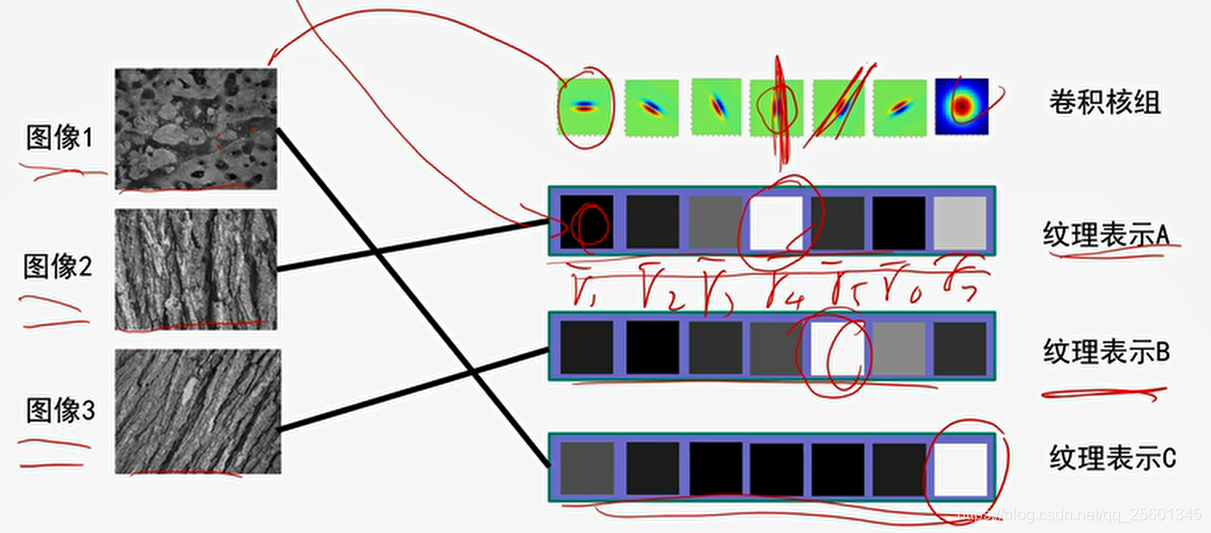

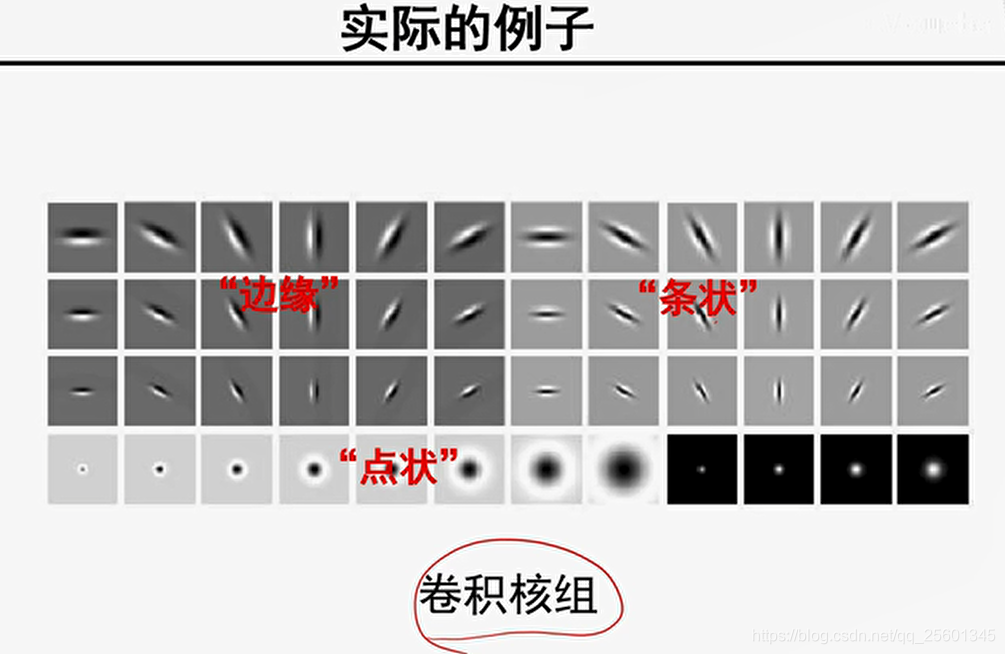
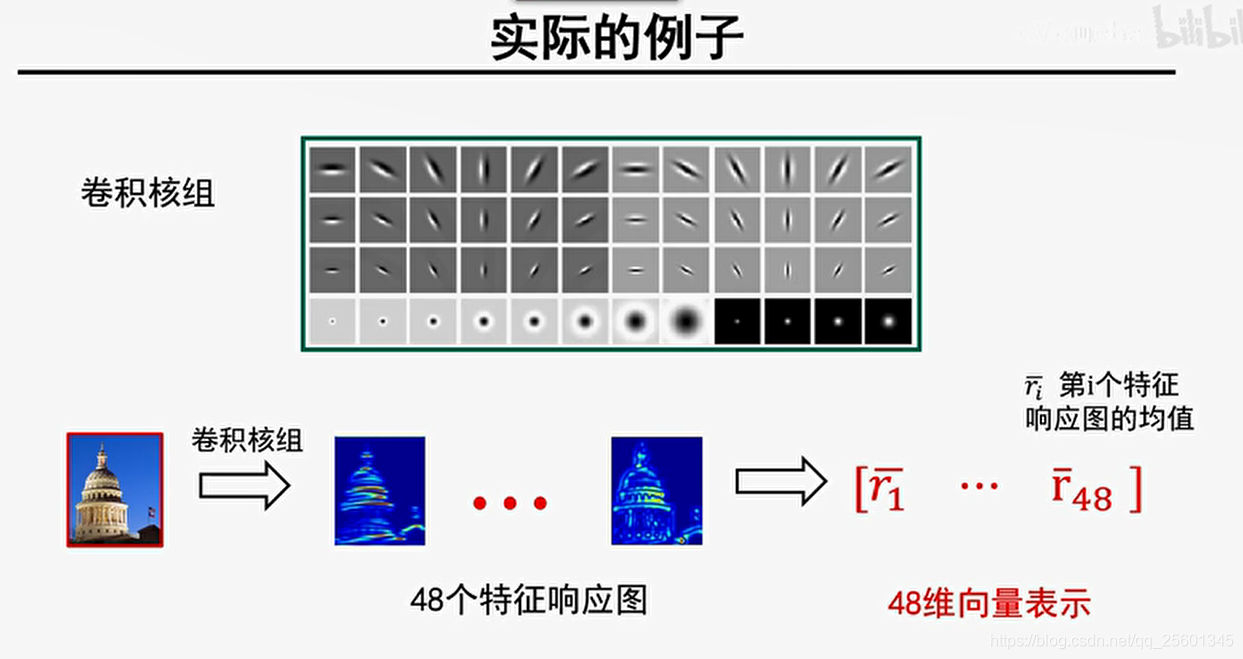
1.设计卷积核组;
2.利用卷积核组对图像进行卷积操作获得对应的特征响应图组;
3.利用特征响应图的某种统计信息来表示图像中的纹理。
7. 卷积神经网络
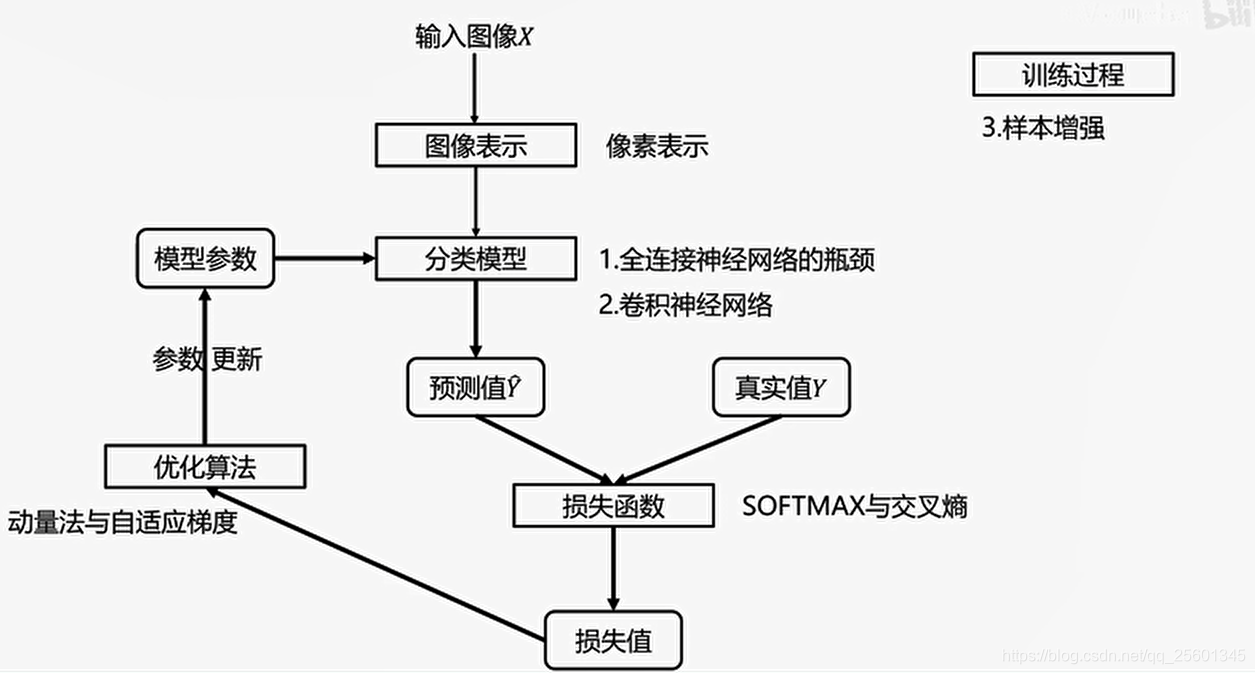
7.1. 图像表示

7.2. 分类模型
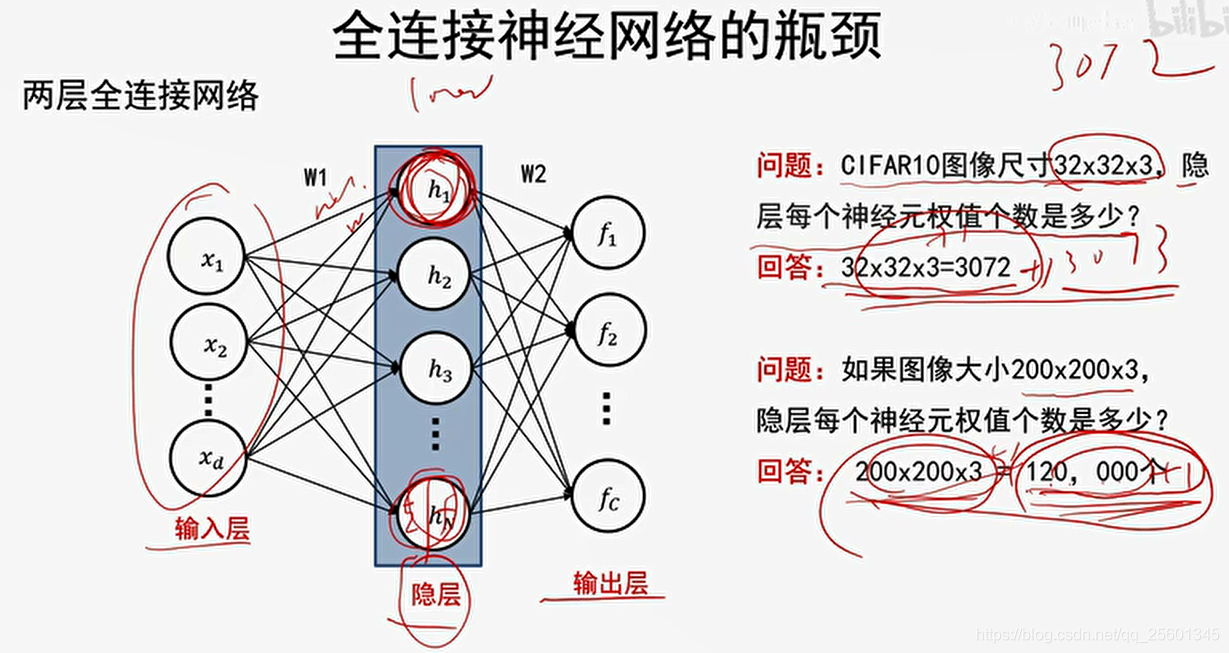
仅适合小图像、或均值输入


不同的特征相应图,包含了不同特征的纹理基元









7.3. 损失函数(交叉熵损失)
7.4. 优化算法(SGD、带动量的SGD以及ADAM)
7.5. 样本增强
➢存在的问题:
过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。
➢数据增强:
是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加样本。
➢数据增强的目标:
模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力




五、经典网络解析
1.AlexNet












2.ZFNet

3.VGG


前部分卷积数量少,因为基元不会那么多





4.GoogleNet













5.ResNet


最差保证输入和输出相等






六、视觉识别

1. 语义分割















UNET?
2. 目标检测










双线性插值








3. 实例分割




- 可视化
反向可视化技术可以得到是否过拟合




















七、生成网络






后验概率、贝叶斯公式、似然函数、密度函数





1. PixeIRNN与PixelCNN






2. VAE















更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)