
大型语言模型推理能力评估——李宏毅2025大模型课程第9讲内容
本节课主要探讨了“如何科学评估大型语言模型的推理能力”,指出当前模型可能依赖记忆而非真正推理,介绍了 ARC-AGI 和 Chatbot Arena 等评估平台,并提醒人们注意评估指标的局限性和误导性。
本节课主要探讨了“如何科学评估大型语言模型的推理能力”,指出当前模型可能依赖记忆而非真正推理,介绍了 ARC-AGI 和 Chatbot Arena 等评估平台,并提醒人们注意评估指标的局限性和误导性。
一、如何评估大型语言模型的「推理」能力?
简单粗暴的方式:是否能解出数学题、是否能写出代码。比如deepseek-R1的技术报告中,展示的推理能力。AIME是一个数学竞赛,codeforces是代码相关的正确率。
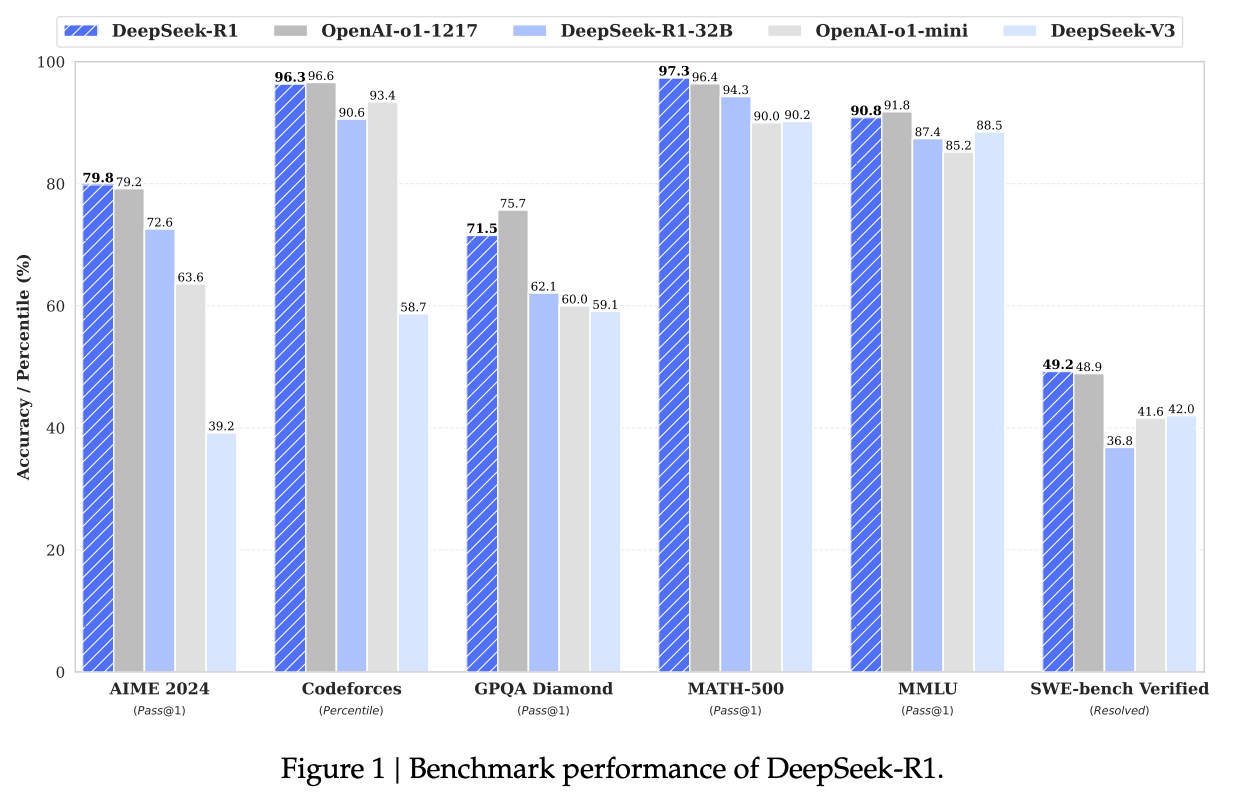
-
论文参考:https://arxiv.org/abs/2501.12948
二、模型答案中有多少是「记忆」出来的?
-
解出数学题,就代表模型的推理能力更强吗?
-
多篇研究指出,大型语言模型在回答问题时,可能并非真正「理解」或「推理」,而是依赖于训练数据中的记忆内容。
-
相关论文 https://arxiv.org/abs/2410.05229
-
论文内容:把GSM8k(数学题库)中的题目,只换掉人名等无关紧要的词,模型的正确率就会下降。
-

-
https://arxiv.org/abs/2402.08939
把GSM8K题目中,句子的顺序调换但不影响题目的意思,各个模型的正确率都有下降(灰色柱子为原题目、蓝色柱子为调换顺序的题目)

三、ARC-AGI:通用人工智能的抽象与推理评测基准
-
ARC-AGI(Abstraction and Reasoning Corpus for AGI)是评估 AI 抽象与推理能力的重要基准。 有图形的推理题目

-
相关资源:
-
论文:https://arxiv.org/abs/1911.01547
-
视频介绍:https://www.youtube.com/watch?v=SKBG1sqdyIU
-
示例代码与提示:https://github.com/arcprize/model_baseline/blob/main/prompt_example_o3.md
-
-
官方博客更新:
-
https://arcprize.org/blog/3-month-update
-
https://arcprize.org/blog/oai-o3-pub-breakthrough
-
四、Chatbot Arena:语言模型对战平台
-
网站:https://lmarena.ai/
-
通过成千上万的用户与模型对话的胜率统计,生成模型的 Elo 评分(评分方式如截图)。理论上,用户的问题千奇百怪,所以模型不能刷分。但是chatbot Arena指出模型排名可能受非技术因素(如风格、情感倾向)影响,提醒人们注意评估指标的局限性。

考虑风格和情感模型后,模型的评分会变化,比如claude的模型剔除掉风格因素后排名上升很多

-
相关博客:
-
https://blog.lmarena.ai/blog/2024/style-control/
-
https://blog.lmarena.ai/blog/2025/sentiment-control/
-
五、Goodhart’s Law(古德哈特定律)
「当一项指标成为目标时,它就不再是一个好指标。」
过度依赖某个评估指标可能导致模型优化方向偏离真实能力,提醒研究者和开发者保持警惕。
背后的故事:英国殖民者统治印度的时候,发现印度蛇很多,英国人提出,捉到蛇的印度人可以获得金钱奖励,印度人会偷偷养很多蛇骗奖励,结果蛇更多了。
更多推荐


 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)