
预训练语言模型
Encoder 块中是堆叠起来的 N 层 Encoder Layer,BERT 有两种规模的模型,分别是 base 版本(12层 Encoder Layer,768 的隐藏层维度,总参数量 110M),large 版本(24层 Encoder Layer,1024 的隐藏层维度,总参数量 340M)。对于不同的NLP任务,每次输入都会加上一个任务描述前缀。MLM 的思路也很简单,在一个文本序列中随
1. Encoder-Only
1.1 Bert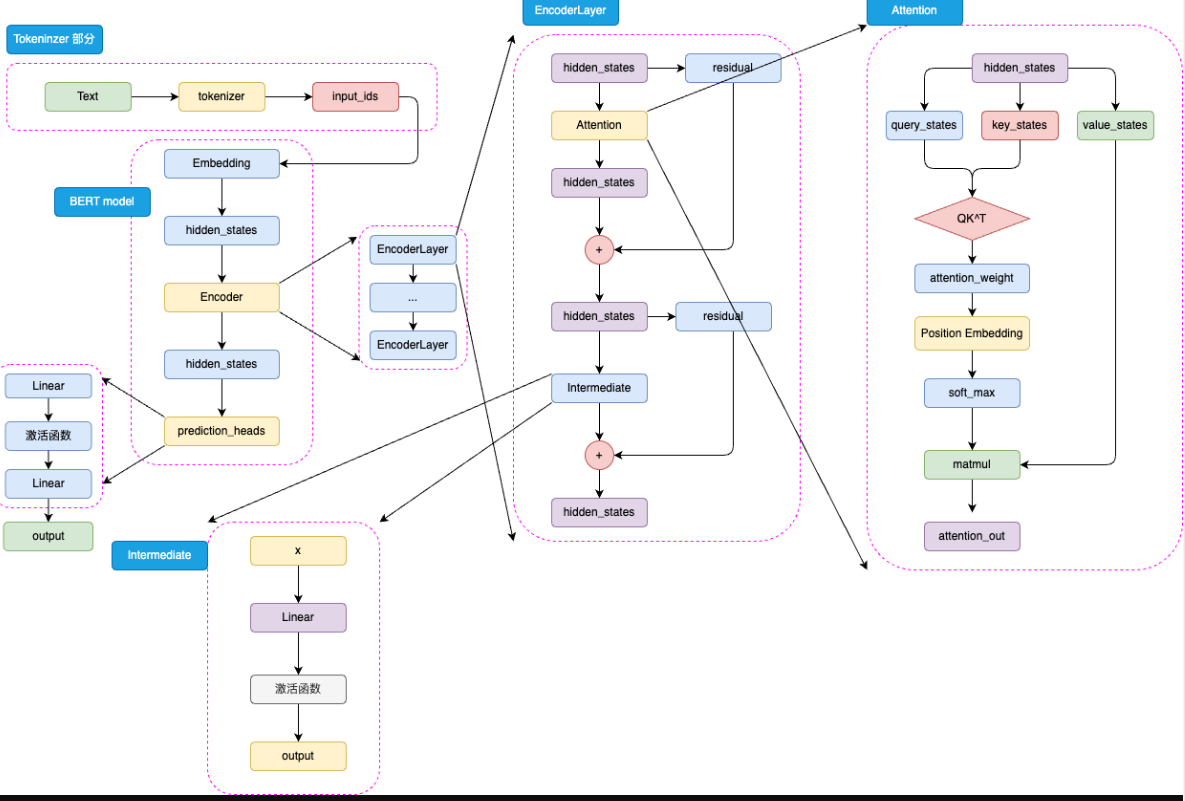
Bert是针对NLU任务打造的预训练模型,输入一般是文本序列,输出一般是Label。但是Encoder堆叠的Bert本质上也是一个Seq2Seq模型,只是没有加入对特定任务的Decoder,因此,为适配各种NLU任务,在模型的最顶层加入了一个分类头Prediction_heads,用于将隐藏状态通过线性层转换到分类维度。
输入的文本序列会首先通过 tokenizer(分词器) 转化成 input_ids(基本每一个模型在 tokenizer 的操作都类似,可以参考 Transformer 的 tokenizer 机制,后文不再赘述),然后进入 Embedding 层转化为特定维度的 hidden_states,再经过 Encoder 块。Encoder 块中是堆叠起来的 N 层 Encoder Layer,BERT 有两种规模的模型,分别是 base 版本(12层 Encoder Layer,768 的隐藏层维度,总参数量 110M),large 版本(24层 Encoder Layer,1024 的隐藏层维度,总参数量 340M)。通过Encoder 编码之后的最顶层 hidden_states 最后经过 prediction_heads 就得到了最后的类别概率,经过 Softmax 计算就可以计算出模型预测的类别。
BERT 所使用的激活函数是 GELU 函数,全名为高斯误差线性单元激活函数,这也是自 BERT 才开始被普遍关注的激活函数。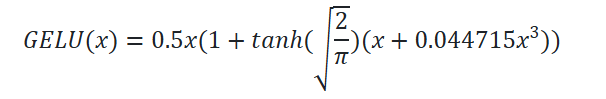
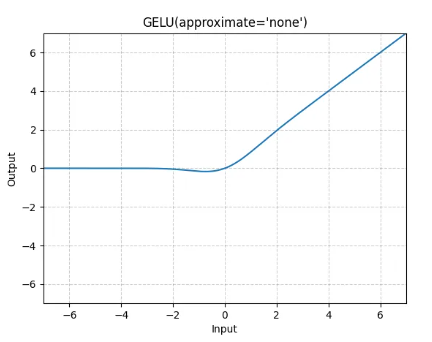
优点:1.连续且可导,平滑性好,有助于稳定训练。2.对小于0的输入并非完全置0,而是给予较小的权重,有助于特征表达。3.在参数量较大的大模型中表现较好。
与Transformer的位置编码不同的是,Bert将其视为可训练的权重参数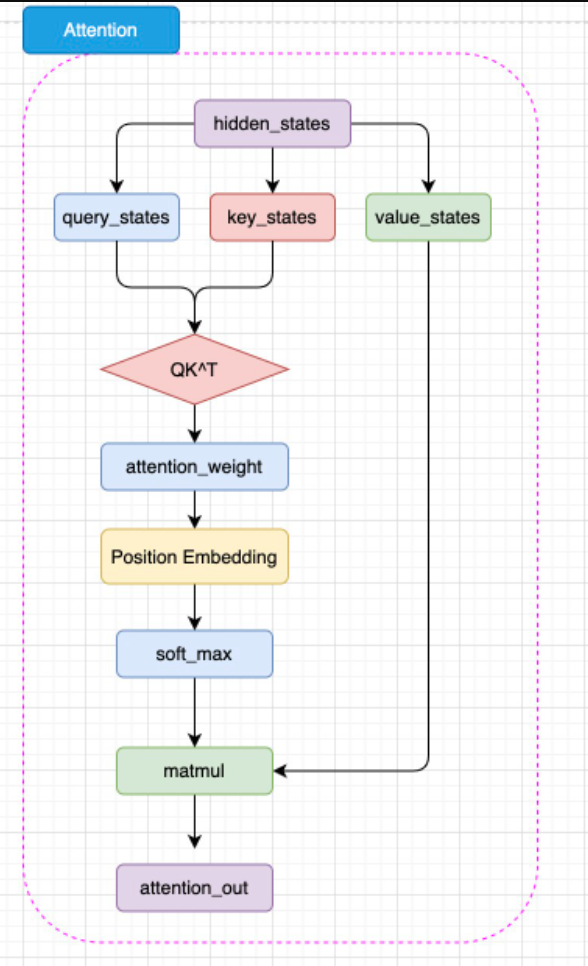
本质还是一层线性矩阵,相比绝对位置编码Sinusoidal能够拟合更丰富的相对位置信息,但是也增加了模型参数,同时由于矩阵大小的限制,无法处理超过模型训练长度的输入。对于Bert而言能处理的最大上下文长度是512个token。
预训练任务------MLM+NSP
BERT 更大的创新点在于其提出的两个新的预训练任务上——MLM 和 NSP(Next Sentence Prediction,下一句预测)。
MLM 的思路也很简单,在一个文本序列中随机遮蔽部分 token,然后将所有未被遮蔽的 token 输入模型,要求模型根据输入预测被遮蔽的 token。例如,输入和输出可以是:
输入:I <MASK> you because you are <MASK>
输出:<MASK> - love; <MASK> - wonderful
因此,模型可以拟合双向语义。但是也存在其固有缺陷:在对下游任务微调和推理时,并不存在我们人工加入的<MASK>的。预训练和微调的不一致,会极大程度影响模型在下游任务微调的性能。对此,作者做出了以下改进: 在进行具体的MLM训练时,随机选择15%的token用于遮蔽。但这15%并非全部遮蔽为<mask>,而是有80%的概率被遮蔽,10%被替换为任意一个token(迫使模型保持对上下文信息的学习),10%保持不变(为了消除预训练和微调的不一致)。
MLM是token级拟合的语义关系。NSP任务用来训练模型在句级的语义关系拟合。NSP 任务的核心思路是要求模型判断一个句对的两个句子是否是连续的上下文。
2. Encoder-Decoder
1. T5
T5 的大一统思想将不同的 NLP 任务如文本分类、问答、翻译等统一表示为输入文本到输出文本的转换,这种方法简化了模型设计、参数共享和训练过程,提高了模型的泛化能力和效率。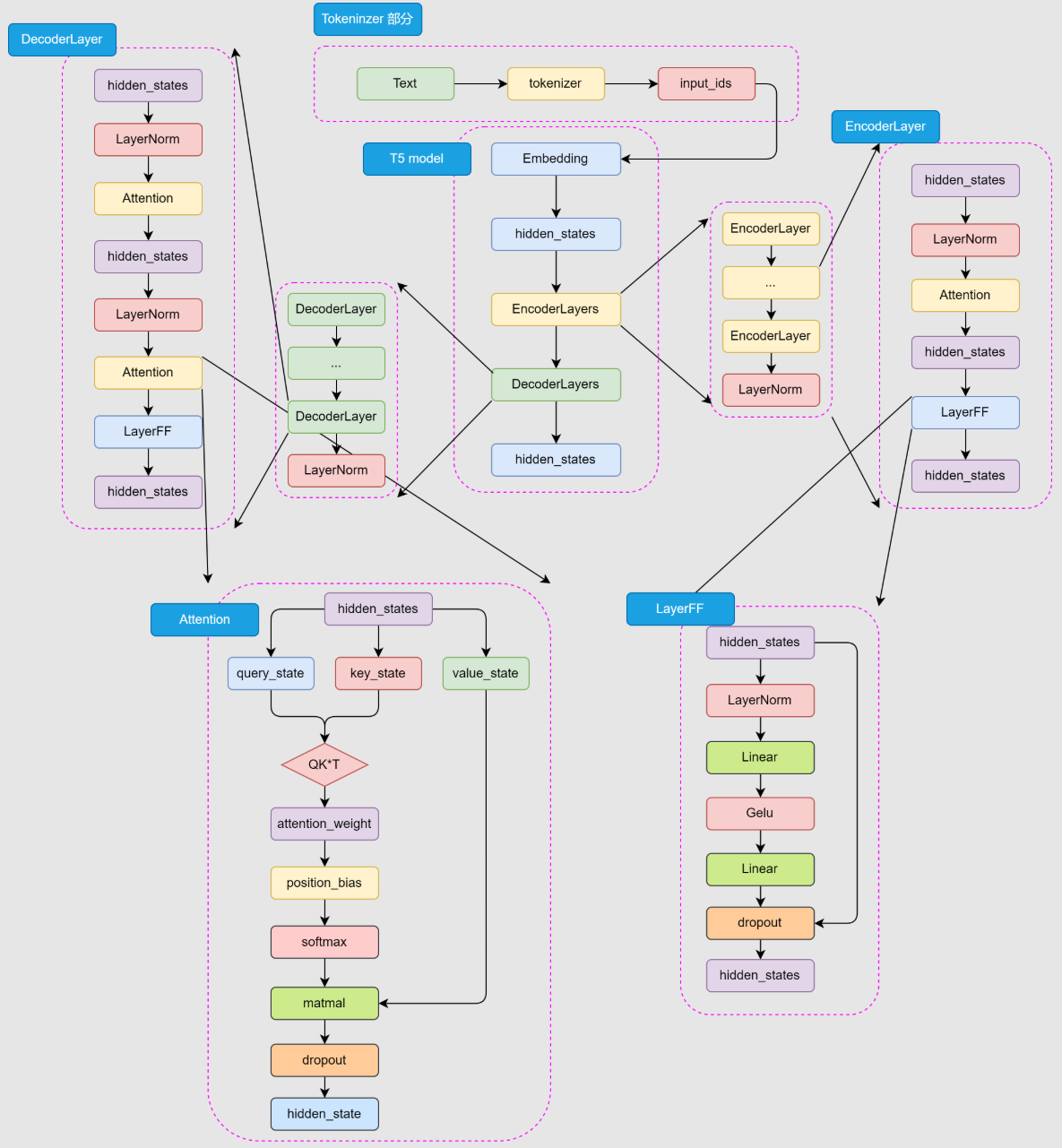
T5模型的预训练任务是 MLM,也称为BERT-style目标。具体来说,就是在输入文本中随机遮蔽15%的token,然后让模型预测这些被遮蔽的token。这个过程不需要标签,可以在大量未标注的文本上进行。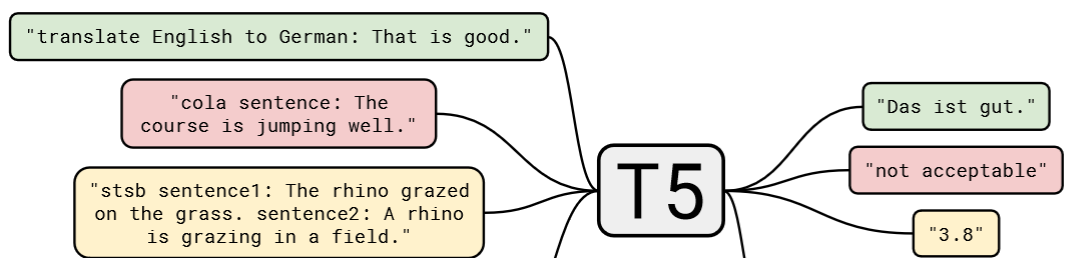
对于不同的NLP任务,每次输入都会加上一个任务描述前缀。例如,任务前缀可以是“summarize: ”用于摘要任务,或“translate English to German: ”用于翻译任务。
3. Decoder-Only
1. GPT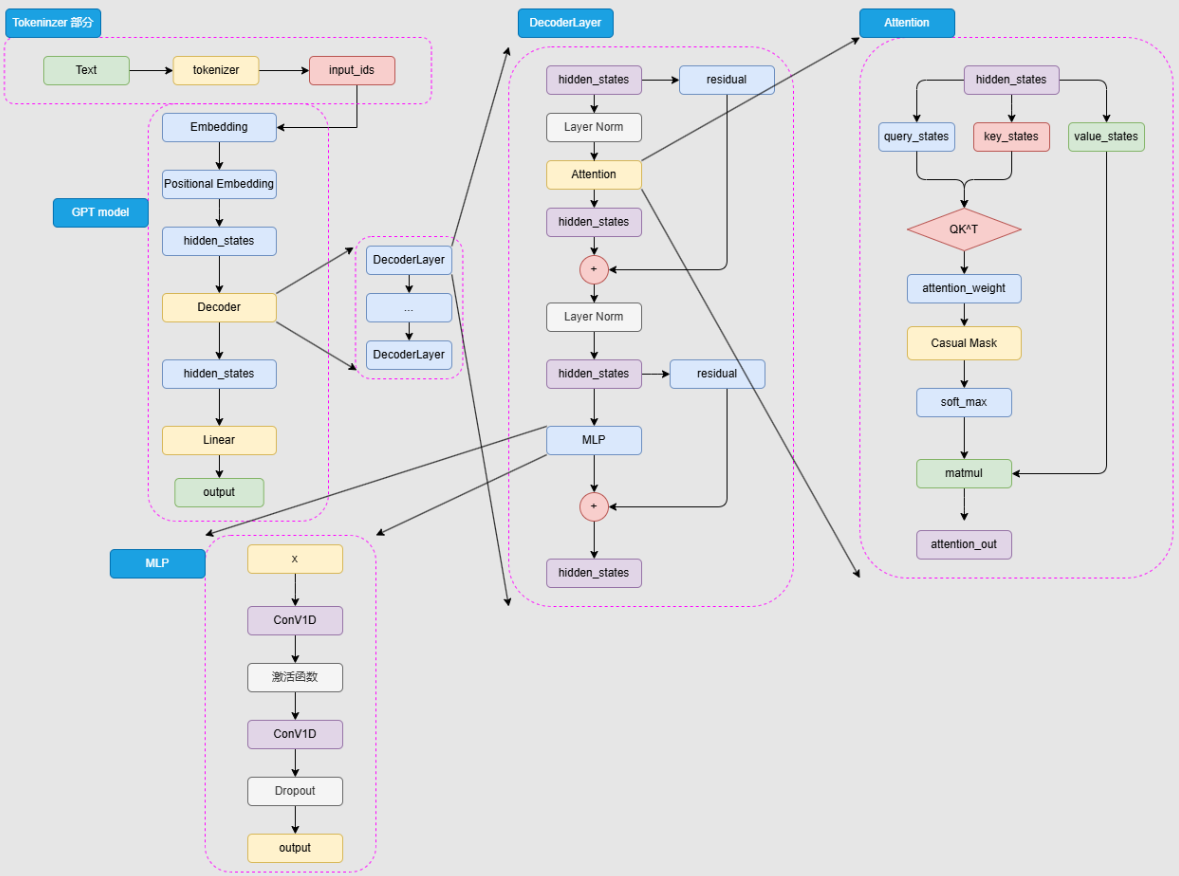
由于不存在 Encoder 的编码结果,Decoder 层中的掩码注意力也是自注意力计算。也就是对一个输入的 hidden_states,会通过三个参数矩阵来生成 query、key 和 value,而不再是像 Transformer 中的 Decoder 那样由 Encoder 输出作为 key 和 value。GPT 的 MLP 层没有选择线性矩阵来进行特征提取,而是选择了两个一维卷积核来提取,不过,从效果上说这两者是没有太大区别的。
预训练任务----CLM
Decoder-Only模型往往选择因果语言模型(Casual Language Model)作为预训练任务:CLM是基于一个自然语言序列前面所有token来预测下一个token,通过不断重复该过程来实现目标文本序列的生成。
input: 今天天气
output: 今天天气很
input: 今天天气很
output:今天天气很好
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)