
如何处理红外变电站分割数据集——并使用深度学习方法进行训练
如何处理红外变电站分割数据集——并使用深度学习方法进行训练
·
如何处理红外变电站分割数据集,并使用深度学习方法进行训练。这个数据集包含了不同类型的设备,每种设备都有对应的红外图像以及JSON格式的标注文件。
数据集描述
该数据集包含以下五类设备的红外图像及其对应的标注文件(JSON格式):
- 避雷器:100张
- 绝缘子:919张
- 电流互感器:413张
- 套管:161张
- 电压互感器:153张
标注文件是JSON格式,通常包含每个对象的位置信息,如边界框坐标等。
数据集组织
假设你的数据集目录结构如下:
infrared_substation/
├── images/
│ ├── image1.jpg
│ ├── image2.jpg
│ └── ...
├── annotations/
│ ├── annotation1.json
│ ├── annotation2.json
│ └── ...
└── README.txt # 数据说明其中:
images/存放原始红外图像。annotations/存放每个图像的JSON格式标注文件。
数据预处理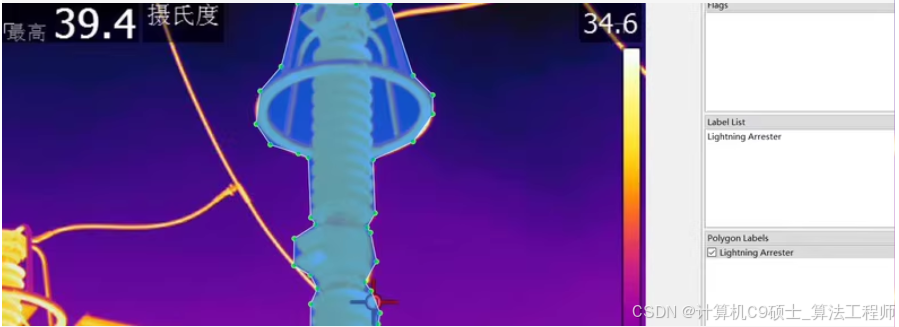
我们需要从JSON文件中提取边界框信息,并将它们转换为适合深度学习模型输入的数据格式。
数据预处理脚本
import json
import os
import shutil
from PIL import Image
import numpy as np
def parse_json(json_file, img_dir, img_size=(448, 448)):
"""
解析JSON文件并返回标签信息。
"""
with open(json_file, 'r') as file:
data = json.load(file)
labels = []
img_path = os.path.join(img_dir, data['filename'])
img = Image.open(img_path)
img_resized = img.resize(img_size)
img_resized.save(img_path) # 保存缩放后的图像
width, height = img_resized.size
for obj in data['objects']:
label = obj['label']
bbox = obj['bbox']
xmin, ymin, xmax, ymax = bbox[0] * width / img.width, bbox[1] * height / img.height, \
bbox[2] * width / img.width, bbox[3] * height / img.height
labels.append([label, xmin, ymin, xmax, ymax])
return labels
def preprocess_data(src_img_dir, src_ann_dir, dest_img_dir, dest_ann_dir):
"""
处理原始数据并将其存储到新的目录。
"""
os.makedirs(dest_img_dir, exist_ok=True)
os.makedirs(dest_ann_dir, exist_ok=True)
for json_file in os.listdir(src_ann_dir):
if json_file.endswith('.json'):
labels = parse_json(os.path.join(src_ann_dir, json_file), src_img_dir)
new_ann_file = os.path.join(dest_ann_dir, json_file.replace('.json', '.txt'))
with open(new_ann_file, 'w') as f:
for label, xmin, ymin, xmax, ymax in labels:
f.write(f'{label} {xmin} {ymin} {xmax} {ymax}\n')
# 调用函数
preprocess_data(
src_img_dir='path/to/infrared_substation/images/',
src_ann_dir='path/to/infrared_substation/annotations/',
dest_img_dir='path/to/preprocessed_images/',
dest_ann_dir='path/to/preprocessed_annotations/'
)数据集划分
我们需要将数据集划分为训练集、验证集和测试集。这里我们简单地按照一定比例分配:
import random
def split_dataset(src_img_dir, src_ann_dir, train_ratio=0.7, val_ratio=0.2, test_ratio=0.1):
"""
将数据集分为训练集、验证集和测试集。
"""
filenames = os.listdir(src_img_dir)
random.shuffle(filenames)
total = len(filenames)
train_end = int(total * train_ratio)
val_end = int(total * (train_ratio + val_ratio))
train_files = filenames[:train_end]
val_files = filenames[train_end:val_end]
test_files = filenames[val_end:]
for files, dest_dir in [(train_files, 'train'), (val_files, 'valid'), (test_files, 'test')]:
os.makedirs(f'data/{dest_dir}/images', exist_ok=True)
os.makedirs(f'data/{dest_dir}/labels', exist_ok=True)
for filename in files:
shutil.copy(f'{src_img_dir}/{filename}', f'data/{dest_dir}/images/')
shutil.copy(f'{src_ann_dir}/{filename.replace(".jpg", ".txt")}', f'data/{dest_dir}/labels/')
# 调用函数
split_dataset(
src_img_dir='path/to/preprocessed_images/',
src_ann_dir='path/to/preprocessed_annotations/'
)数据加载器
我们需要定义一个数据加载器来读取图像和标签文件:
import torch
from torch.utils.data import Dataset, DataLoader
import os
import numpy as np
from PIL import Image
class InfraredSubstationDataset(Dataset):
def __init__(self, images_dir, labels_dir, transform=None):
self.images_dir = images_dir
self.labels_dir = labels_dir
self.transform = transform
self.image_filenames = [os.path.join(images_dir, f) for f in os.listdir(images_dir)]
self.label_filenames = [os.path.join(labels_dir, f.replace('.jpg', '.txt')) for f in os.listdir(images_dir)]
def __len__(self):
return len(self.image_filenames)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_name = self.image_filenames[idx]
label_name = self.label_filenames[idx]
image = Image.open(img_name).convert("RGB")
with open(label_name, 'r') as f:
labels = []
for line in f.readlines():
label, xmin, ymin, xmax, ymax = line.strip().split()
labels.append([int(label), float(xmin), float(ymin), float(xmax), float(ymax)])
labels = np.array(labels)
if self.transform:
image = self.transform(image)
return image, labels
# 示例转换
transform = transforms.Compose([
transforms.Resize((448, 448)),
transforms.ToTensor(),
])
# 创建数据集实例
train_dataset = InfraredSubstationDataset(
images_dir='path/to/data/train/images/',
labels_dir='path/to/data/train/labels/',
transform=transform
)
valid_dataset = InfraredSubstationDataset(
images_dir='path/to/data/valid/images/',
labels_dir='path/to/data/valid/labels/',
transform=transform
)
test_dataset = InfraredSubstationDataset(
images_dir='path/to/data/test/images/',
labels_dir='path/to/data/test/labels/',
transform=transform
)
# 创建数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
valid_dataloader = DataLoader(valid_dataset, batch_size=4, shuffle=False, num_workers=4)
test_dataloader = DataLoader(test_dataset, batch_size=4, shuffle=False, num_workers=4)模型定义
我们可以使用YOLOv5作为基础模型来进行目标检测:
# 假设YOLOv5已经安装并且可用
from yolov5.models.common import DetectMultiBackend
from yolov5.utils.torch_utils import select_device
device = select_device('')
model = DetectMultiBackend('yolov5s.pt', device=device, dnn=False) # load FP32 model
model.nc = 5 # number of classes
model.names = ['arrester', 'insulator', 'current_transformer', 'bushing', 'voltage_transformer']模型训练
接下来定义训练循环:
from yolov5.train import train
# 调用训练函数
train(
data='path/to/data.yaml',
imgsz=448,
batch_size=4,
epochs=100,
workers=4,
device=device,
project='runs/train',
name='infrared_substation',
exist_ok=True
)模型评估
在训练完成后,我们需要评估模型的性能:
from yolov5.val import val
# 调用评估函数
val(
data='path/to/data.yaml',
weights='path/to/weights/best.pt',
imgsz=448,
batch_size=4,
workers=4,
device=device,
project='runs/val',
name='infrared_substation',
exist_ok=True
)模型预测
下面是一个使用训练好的模型进行预测的Python脚本示例:
from yolov5.detect import detect
# 调用预测函数
detect(
weights='path/to/weights/best.pt',
source='path/to/your/image.jpg',
imgsz=448,
conf_thres=0.5,
iou_thres=0.45,
device=device,
project='runs/detect',
name='infrared_substation',
exist_ok=True
)数据配置文件
创建一个data.yaml文件来指定数据集路径、类别数量等信息:
path: path/to/data/
train: train/images/
val: valid/images/
test: test/images/ # test set
nc: 5 # number of classes
names: ['arrester', 'insulator', 'current_transformer', 'bushing', 'voltage_transformer'] # class names完整的训练和预测流程
-
克隆YOLOv5仓库:
-
preprocess_data.py -
数据集划分:
split_dataset.py -
运行训练脚本:
-
python detect.py --weights path/to/weights/best.pt --source path/to/your/image.jpg --img 448 --conf 0.5 --iou 0.45
注意事项
- 数据集质量:确保数据集的质量,包括清晰度、标注准确性等。
- 模型选择:可以选择更强大的模型版本(如YOLOv5l或YOLOv5x)以提高性能。
- 超参数调整:根据实际情况调整超参数,如批量大小(
--batch)、图像大小(--img)等。 - 监控性能:训练过程中监控损失函数和mAP指标,确保模型收敛。
通过上述步骤,你可以使用YOLOv5来训练一个红外变电站分割数据集,并使用训练好的模型进行预测
更多推荐


 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)