
目标检测从入门到精通-基础原理与项目实战笔记
缺点:1、训练阶段多:步骤繁琐:微调网络+训练SVM+训练边框回归器。2、训练耗时:占用磁盘空间大:5000张图像产生几百G的特征文件。(VOC数据集的检测结果,因为SVM的存在)3、处理速度慢:使用GPU,VGG16模型处理一张图像需要47s。4、图片形状变化:候选区域要经过crop/warp进行固定大小,无法保证图片不变形。
目录
1 项目总体结构
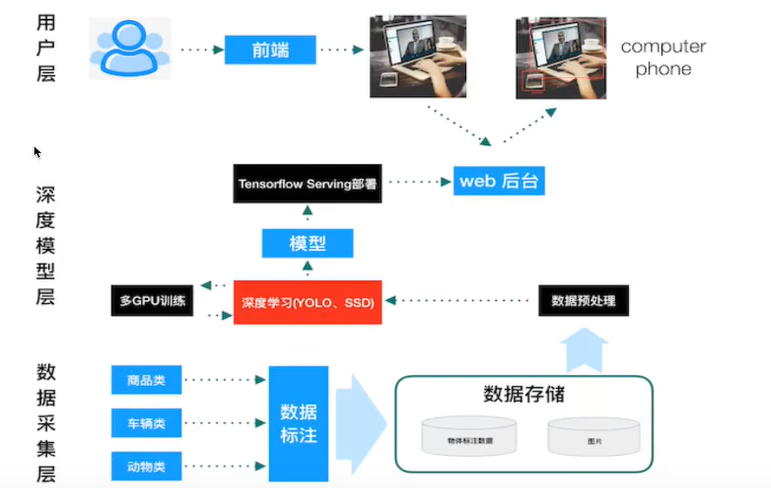
数据采集层:数据收集标注
深度模型层:YOLO,SSD模型,模型导出,Serving部署
用户层:前端交互,(web后台)对模型的部署
2 目标检测
2.1 算法分类
两步走的目标检测:先进行区域推荐,而后进行目标分类
代表:R-CNN、SPP-net、Fast R-CNN、Faster R-CNN
端到端的目标检测:采用一个网络一步到位。
代表:YOLO、SSD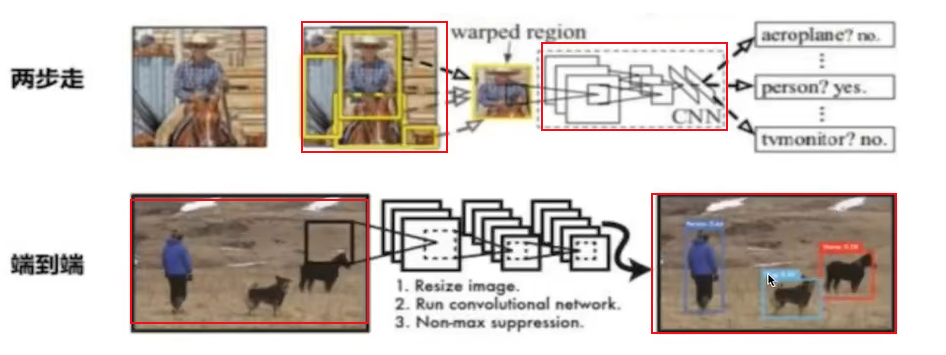
2.2 目标检测的任务
回归下分类的原理,CNN过程输入一张图片,经过其中卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果。
对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息,所以从分类到检测,标记了过程。
分类:
N个类别
输入:图片
输出:类别标签
评估指标:Accuracy准确度
检测:
N个类别
输入:图片
输出:物体类别、物体的位置坐标
评估指标:IOU
其中我们得出来的(x,y,w,h)有一个专业的名词, 叫做bounding box(bbox)
物体位置:
x,y,w,h:x,y物体的中心点位置,以及中心点距离物体两边的长宽。xmin,ymin,xmax,ymax:物体位置的左上角、右下角坐标。
2.3 目标定位的简单思路
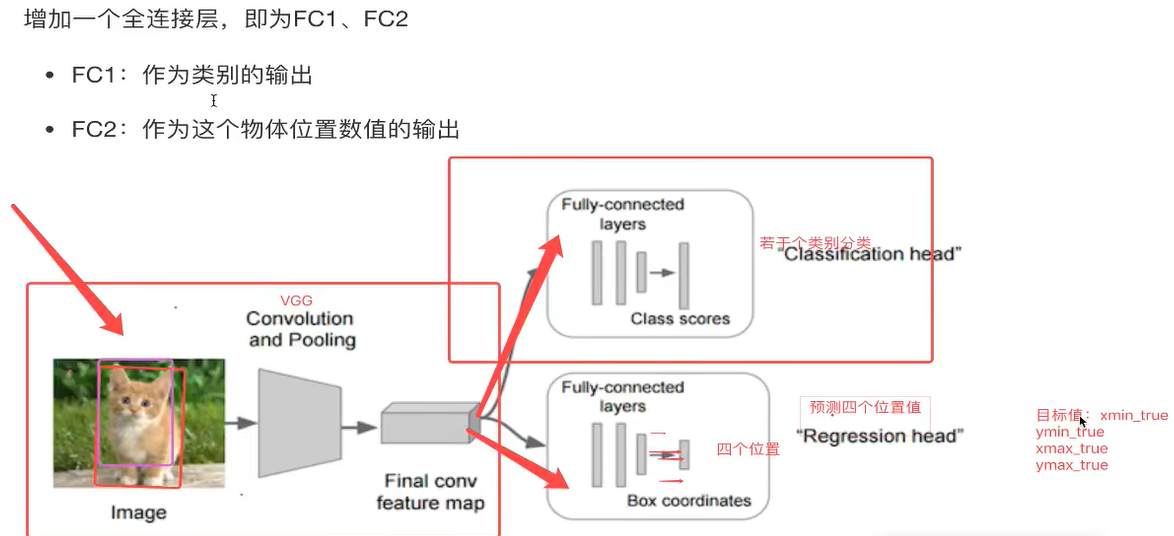
假设有10个类别,输出[p1,p2,p3,……p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失
·对于分类的概率,还是使用交叉熵损失
·位置信息具体的数值,可使用MSE均方误差损失(L2损失)
在目标检测当中,对bbox主要由两种类别。
Ground-truth bounding box:图片当中真实标记的框(GT)
Predicted bounding box:预测的时候标记的框(bbox)
3 R-CNN与SPPNet
对于多个目标检测,不能固定个数输出物体的位置
3.1 目标检测overfeat模型–滑动窗口
目标检测的暴力方法是从左到右、从上到下滑动窗口,利用分类识别目标。为了在不同观察距离处检测不同的目标类型,我们使用不同大小和宽高比的窗口。
注:这样就变成每张子图片输出类别以及位置,变成分类问题。但是滑动窗口需要初始设定一个周定大小的窗口,这就遇到了一个问题,有些物体话应的框不一样。
所以需要提前设定K个窗口,每个窗口滑动提取M个,总共KxM个图片,通常会直接将图像变形转换成固定大小的图像,变形图像块被输入CNN分类器中,提取特征后,我们使用一些分类器识别类别和该边界框的另一个线性回归器。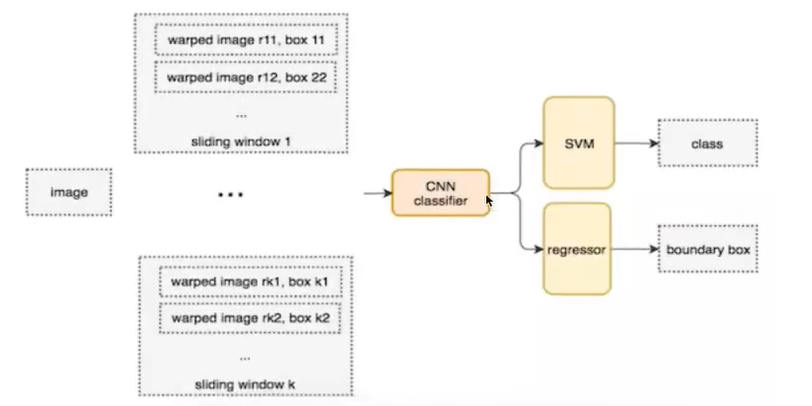
Overfeat方式暴力破解,会消耗大量算力
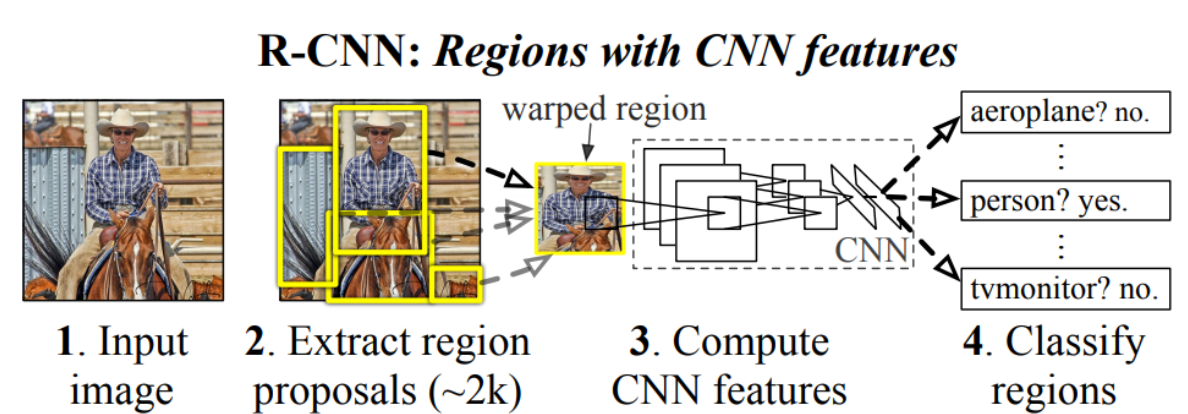
3.2 目标检测R-CNN模型
不使用暴力方法,而是用候选区域方法(region proposal method),创建目标检测的区域改变了图像领域实现物体检测的模型思路,R-CNN是以深度神经网络为基础的物体检测的模型,R-CNN在当时以优异的性能令世人瞩目,以R-CNN为基点,后续的SPPNet、Fast R-CNN、Faster R-CNN模型都是照着这个物体检测思路。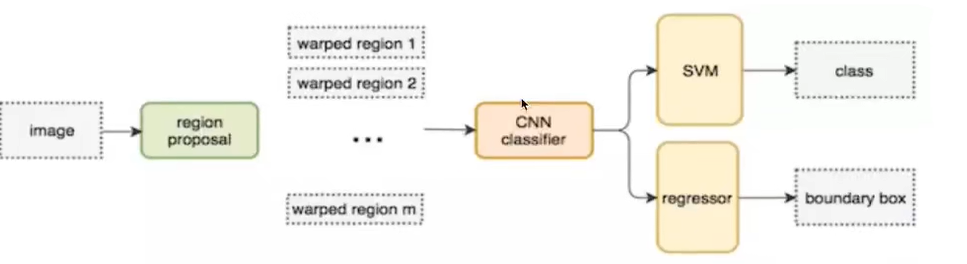
步骤:(以AlexNet网络为基准)
1、找出图片中可能存在目标的侯选区域region proposal
选择性搜索(SelectiveSearch,ss)中,首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。下第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的ROI。
SelectiveSearch在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
2、将候选区域调整为了适应AlexNet网络的输入图像的大小227x227,通过CNN对候选区域提取特征向量,2000个建议框的CNN特征组合成网络AlexNet最终输出:2000×4096维矩阵
在侯选区域的基础上提取出更高级、更抽象的特征,这些高级特征是作为下一步的分类器、回归的输入数据。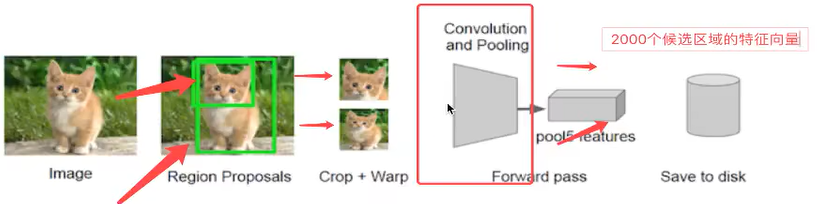
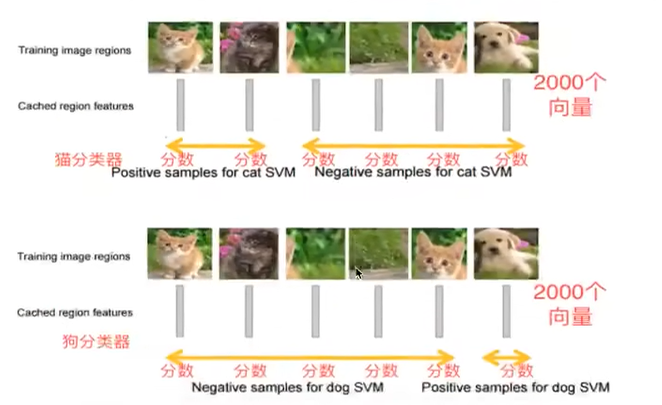
3、将2000×4096维特征经过SVM分类器(20种分类,SVM是二分类器,则有20个SVM),获得2000×20种类别矩阵
①、假设一张图片的2000个侯选区域,那么提取出来的就是2000×4096这样的特征向量(R-CNN当中默认CNN层输出4096特征向量)。
②、R-CNN选用SVM进行二分类。假设检测20个类别,那么会提供20个不同类别的SVM分类器每个分类器都会对2000个候选区域的特征向量分别判断一次,这样得出[2000,20]的得分矩阵,如下图所示
4、分别对2000x20维矩阵中进行非极大值抑制(NMS:non-maximum suppression)剔除重叠建议框,得到与目标物体最高的一些建议框
目的:非极大值抑制(NMS):筛选候选区域,目标是一个物体只保留一个最优的框,来抑制那些冗余的候选框
迭代过程:
1、对于所有的2000个候选区域得分进行概率筛选,0.5
2、剩余的候选框
·假设图片真实物体个数为2(N),筛选之后候选框为5(P),计算N中每个物体位置与所有P的交并比loU计算,得到P中每个候选框对应loU最高的N中一个
· 如下图,A、C候选框对应左边车辆,B、D、E对应右边车辆
假设现在滑动窗口有:A、B、C、D、E5个候选框,
·第一轮:对于右边车辆,假设B是得分最高的,与B的IoU>0.5删除。现在与B计算IoU,DE结果>0.5,剔除DE,B作为一个预测结果
·第二轮:对于左边车辆,AC中,A的得分最高,与A计算IoU,C的结果>0.5,剔除C,A作为一个结果最终结果为在这个5个中检测出了两个目标为A和B
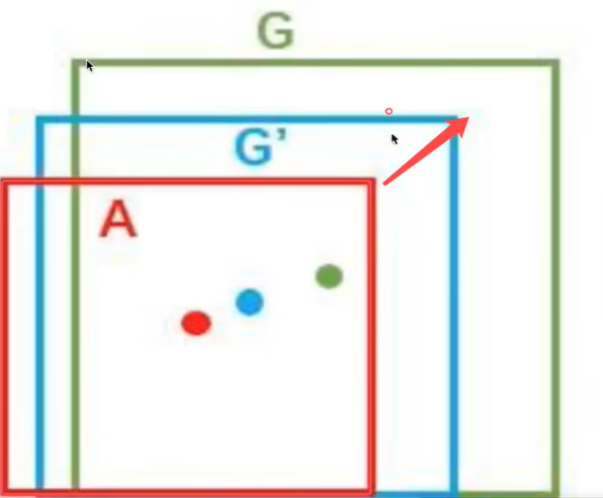
5、修正bbox候选框,对bbox做回归微调
那么通过非最大一直筛选出来的候选框不一定就非常准确怎么办?R-CNN提供了这样的方法,建立一个bbox regressor
回归用于修正筛选后的候选区域,使之回归于ground-truth默认认为这两个框之间是线性关系,因为在最后筛选出来的候选区域和ground-truth很接近了
3.3 检测的评价指标
3.3.1 IOU交并比

另个区域的重叠程度overlap:候选区域和标定区域的IOU值(IOU值在0~1)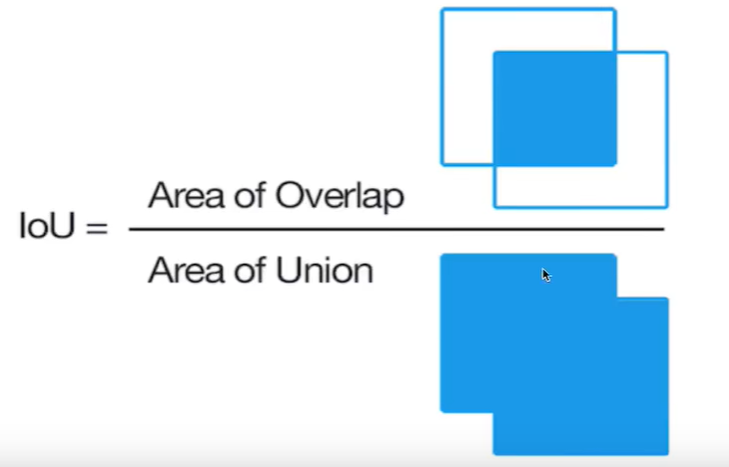
位置考量
3.3.2 平均精确率(mean average precision)map
分类考量
训练样本的标记:候选框(如RCNN2000个)标记
- 每个ground-truth box 有着最高的IOU的anchor标记为正样本
- 剩下的anchor/anchors与任何around truth box的loU大于0.7记为正样本,loU小于0.3,记为负样本
多个分类任务的AP的平均值
mAP=所有类别的AP之和/类别的总和(AP1+AP2+…AP20)/20
主:PR曲线,而就是这个曲线下的面积(ROC与AUC)(average precision)AP
方法步骤:
- 1、对于其中一个类别C,首先将算法输出的所有C类别的预测框,按预测的分数confidence排序·RCNN中就是SVM的输出分数(对于一个类别狗,候选框为狗类别的概率做一个排序,得到一个排序的候选框列表(8))
- 2、设定不同的k值,选择top k个预测框,计算FP和TP,计算Precision和AP(对于狗当中进行计算20个候选框的列表,进行AUC)
- 3、将得到的N个类别的AP取平均,即得到AP;AP是针对单一类别的,mAP是将所有类别的AP求和,再取平均(最终得到20个类别,20个AP相加)
首先回顾精确率与召回率
左边一整个矩形中的数表示ground truth之中为1的(即为正确的)数据
右边一整个矩形中的数表示ground truth之中为0的数据
精度precision的计算是用检测正确的数据个数/总的检测个数
3.4总结
缺点:
1、训练阶段多:步骤繁琐:微调网络+训练SVM+训练边框回归器。
2、训练耗时:占用磁盘空间大:5000张图像产生几百G的特征文件。(VOC数据集的检测结果,因为SVM的存在)
3、处理速度慢:使用GPU,VGG16模型处理一张图像需要47s。
4、图片形状变化:候选区域要经过crop/warp进行固定大小,无法保证图片不变形
3.5 目标检测SPPNet
RCNN速度慢在卷积运算量大,一张图片里面有多个区域卷积运算大。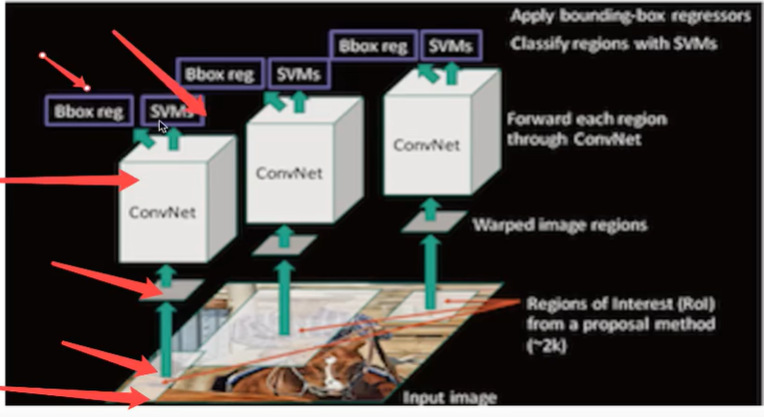
SPPNet主要存在两点改进地方,提出了SPP层
减少卷积运算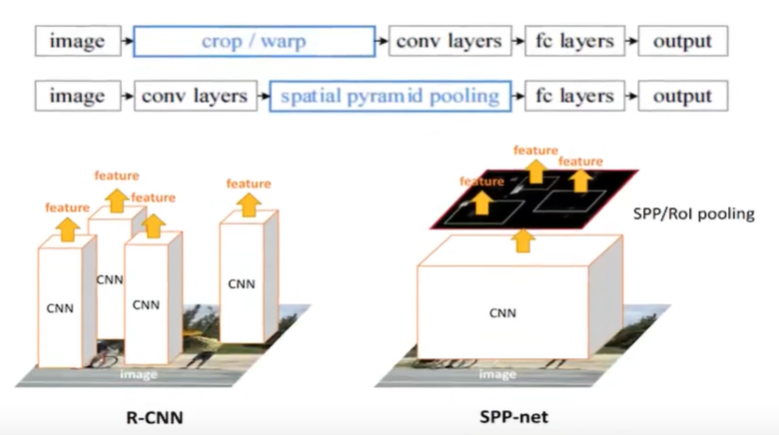

3.5.1 映射
原始图片经过CNN变成了feature map,原始图片通过选择性搜索(SS)得到了候选区域(Region ofInterest),现在需要将基于原始图片的候选区域映射到feature map中的特征向量。映射过程图参考如下: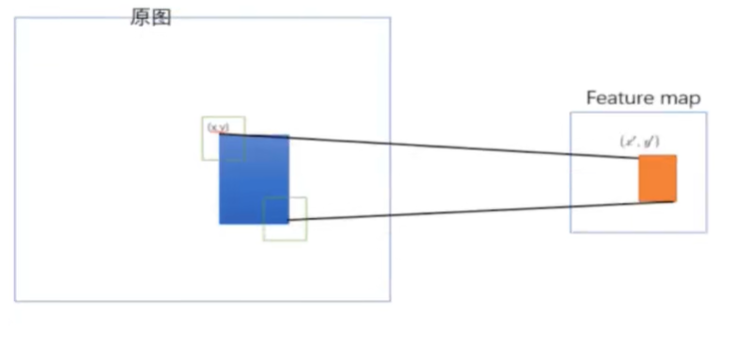
整个映射过程有具体的公式,如下假设(x’,y)(x’,y)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关:(x,y)=(Sx’,Sy’),即
3.5.2 spatial pyramid pooling(空间金字塔池化)
·通过spatial pyramid pooling 将特征图转换成固定大小的特征向量
示例:假设原图输入是224×224,对于conv出来后的输出是13×13×256,其中某个映射的候选区域假设为:12×10×256
·spp layer会将每一个候选区域分成1x1,2x2,4x4三张子图,对每个子图的每个区域作max pooling,得出的特征再连接到一起就是(16+4+1)×256=21×256=5376结果,接着给全连接层做进一步处理,如下图:
·Spatial bins(空间盒个数):1+4+16=21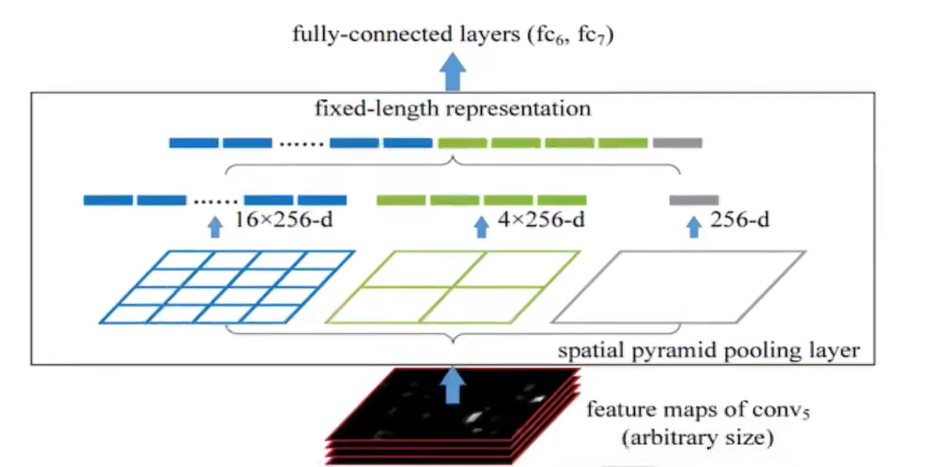
SPPNet结构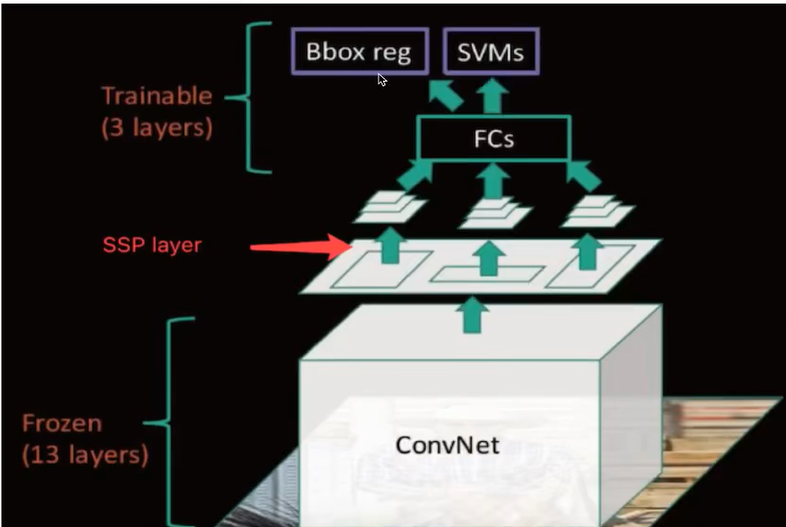
·优点:
SPPNet在R-CNN的基础上提出了改进,通过候选区域和feature map的映射,配合SPP层的使用,从而达到了CNN层的共享计算,减少了运算时间,后面的Fast R-CNN等也是受SPPNet的启发
·缺点:训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)。
分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器,SPPNet反向传播效率低
4 Fast R-CNN
改进的地方:提出一个Rol pooling,然后整合整个模型,把CNN、Rolpooling、分类器、bbox回归几个模块整个一起训练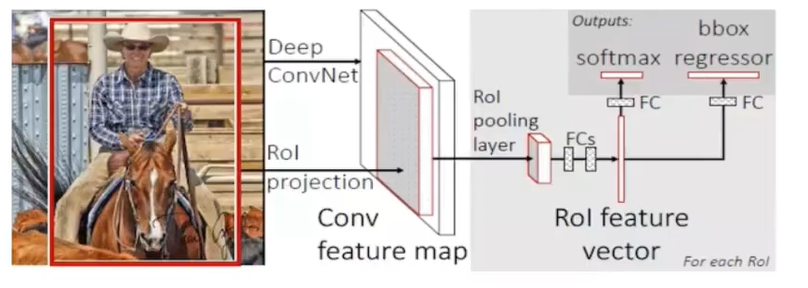
步骤:
1、首先将整个图片输入到一个基础卷积网络,得到整张图的feature map
2、将选择性搜索算法的结果region proposal(Rol)映射到feature map中
3、Rol pooling layer提取一个固定长度的特征向量,每个特征会输入到一系列全连接层,得到一个Rol特征向量(此步骤是对每一个候选区域都会进行同样的操作)
·其中一个是传统softmax层进行分类,输出类别有K个类别加上”背景”类
·另一个是bounding box regressor
4.1 Rol Pooling
首先Rol pooling只是一个简单版本的SPP,目的是为了减少计算时间并且得出固定长度的向量。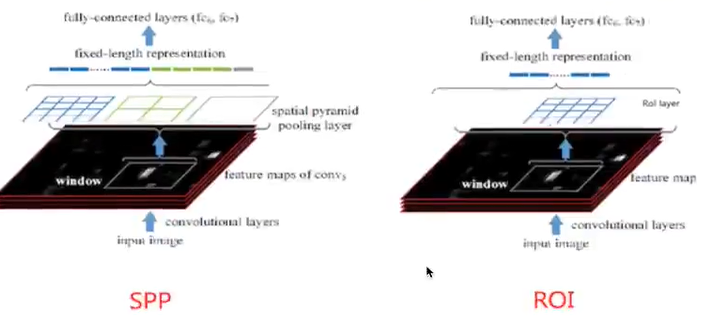
Rol池层使用最大池化将任何有效的Rol区域内的特征转换成具有HxW的固定空间范围的小featuremap,其中H和W是超参数它们独立于任何特定的Rol。
为什么要设计单个尺度呢?这要涉及到single scale与multi scale两者的优缺点
·single scale,直接将image定为某种scale,直接输入网络来训练即可。(Fast R-CNN)
·multi scal,也就是要生成一个金字塔
训练统一,废弃了svm和sppNet,roi pooling layer+softmax
4.2 多任务损失
两个loss,分别是:
·对于分类loss,是一个N+1路的softmax输出,其中的N是类别个数,1是背景,使用交叉熵损失
·对于回归loss,是一个4xN路输出的regressor,也就是说对于每个类别都会训练一个单独的regressor的意思,使用平均绝对误差(MAE)损失即L1损失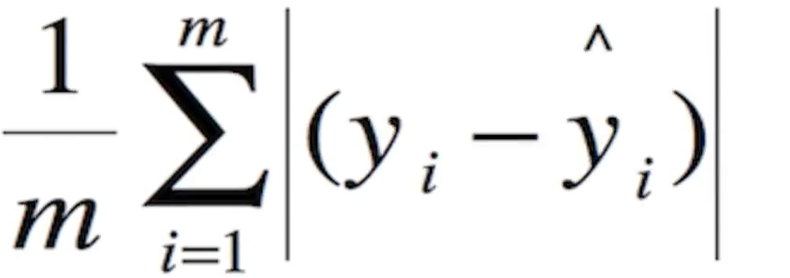
三种模型对比
5 Faster R-CNN
在Faster R-CNN中加入一个提取边缘的神经网络,也就说找候选框的工作也交给神经网络来做了。这样,标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。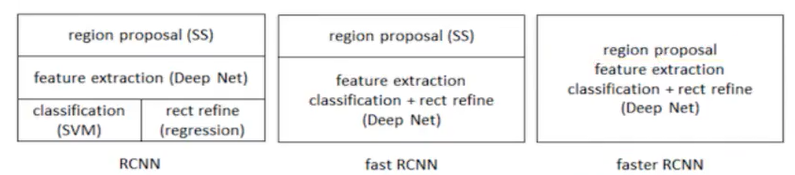
Faster R-CNN可以简单地看成是区域生成网络+Fast R-CNN的模型,用区域生成网络(Region ProposalNetwork,简称RPN)来代替Fast R-CNN中的选择性搜索方法,结构如下: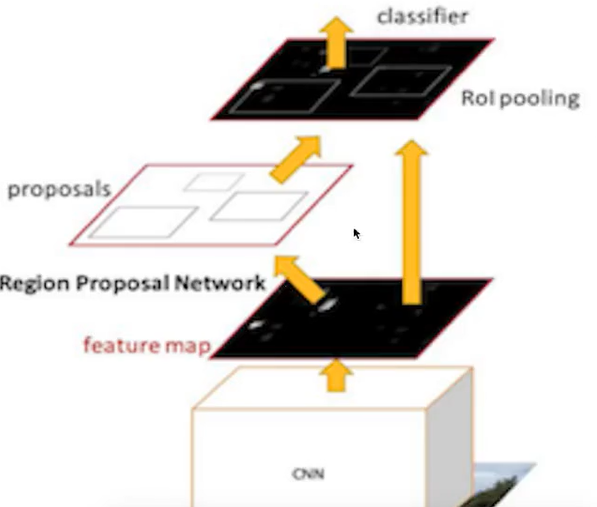
步骤:
1、首先向CNN网络(VGG-16)输入图片,Faster RCNN使用一组基础的conv+relu+pooling层提取featuremap。该feature map被共享用于后续RPN层和全连接层。
2、Region Proposal Networks。RPN网络用于生成region proposals,faster rcnn中称之为anchors。
通过softmax判断anchors属于foreground或者background。
再利用bounding box regression修正anchors获得精确的proposals,输出其Top-N(默认为300)的区域给Rol pooling。
生成anchors -> softmax分类器提取fg anchors->bbox reg回归fg anchors->Proposal Layer生成proposals
3、后续就是Fast RCNN操作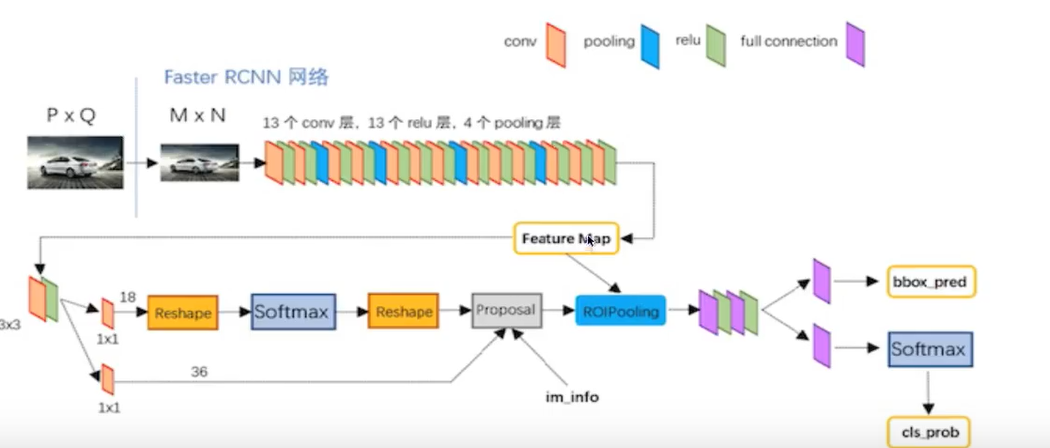
5.1 RPN原理
RPN网络的主要作用是得出比较准确的候选区域。整个过程分为两步
·用n×n(默认3×3=9)的大小窗口去扫描特征图,每个滑窗位置映射到一个低维的向量(默认256维),并为每个滑窗位置考虑k种(在论文设计中k=9)可能的参考窗口(论文中称为anchors)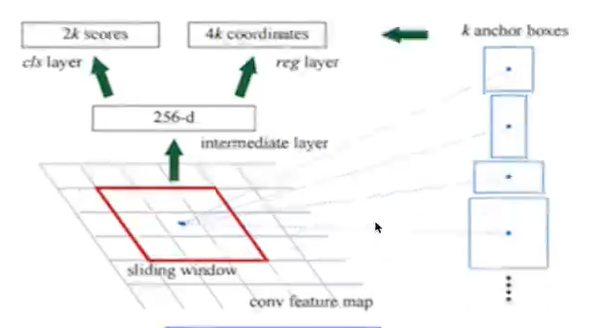
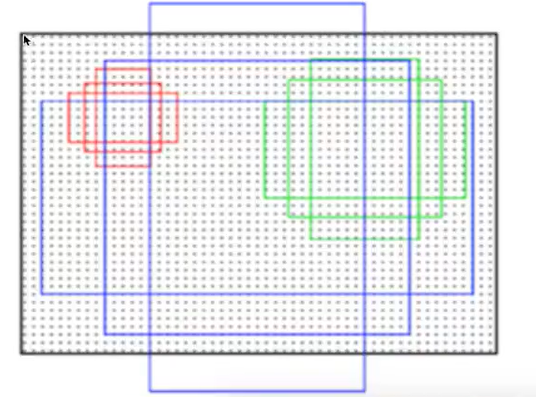
3*3卷积核的中心点对应原图上的位置,将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors,三种尺度{128,256,512},三种长宽比{1:1,1:2,2:1},每个特征图中的像素点有9中框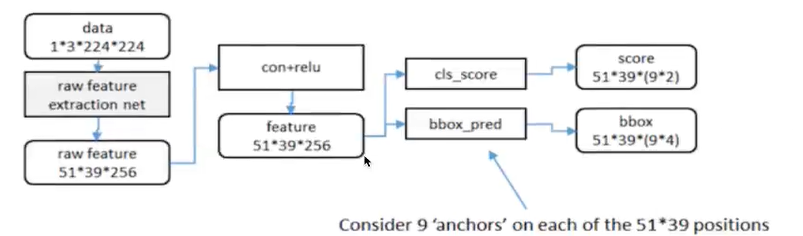
5.2 Faster R-CNN训练
Faster R-CNN的训练分为两部分,即两个网络的训练。
·RPN训练:
目的:从众多的候选区域中提取出score较高的,并且经过regression调整的候选区域
·Fast RCNN部分的训练:
Fast R-CNN classification(over classes):所有类别分类N+1,得到候选区域的每个类别概率。
Fast R-CNN regression(bbox regression):得到更好的位置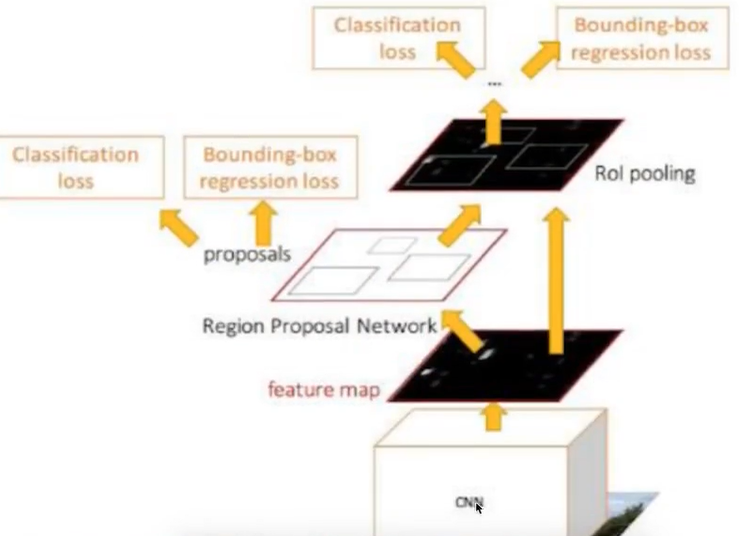
5.3 候选区域训练
训练样本anchor标记。
1.每个ground-truth box有着最高的loU的anchor标记为正样本。
2.剩下的anchor/anchors与任何ground-trup box的loU大于0.7记为正样本,loU小于0.3,记为负样本。
3.剩下的样本全部忽略。
4. 正负样本比例为1:3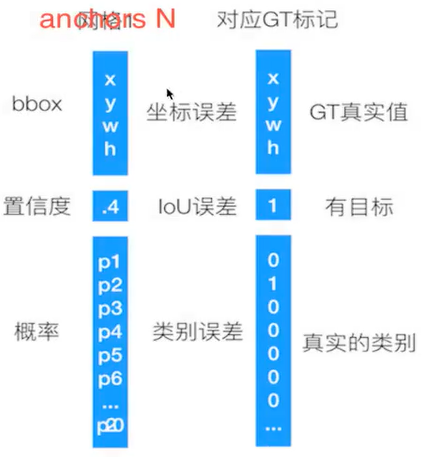

6 YOLO
一个网络搞定一切,GoogleNet +4个卷积+2个全连接层
6.1 预测阶段
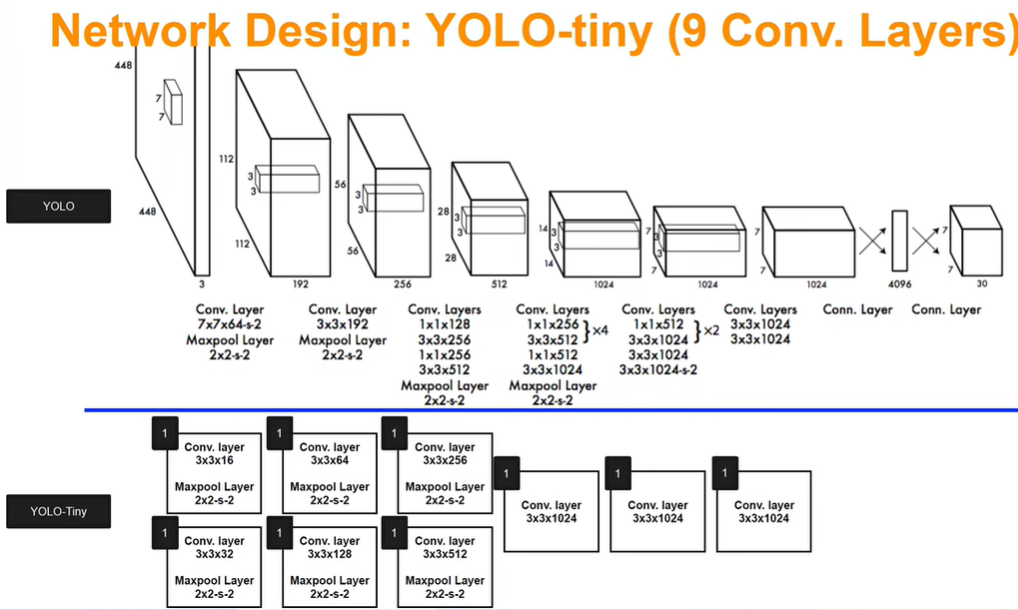
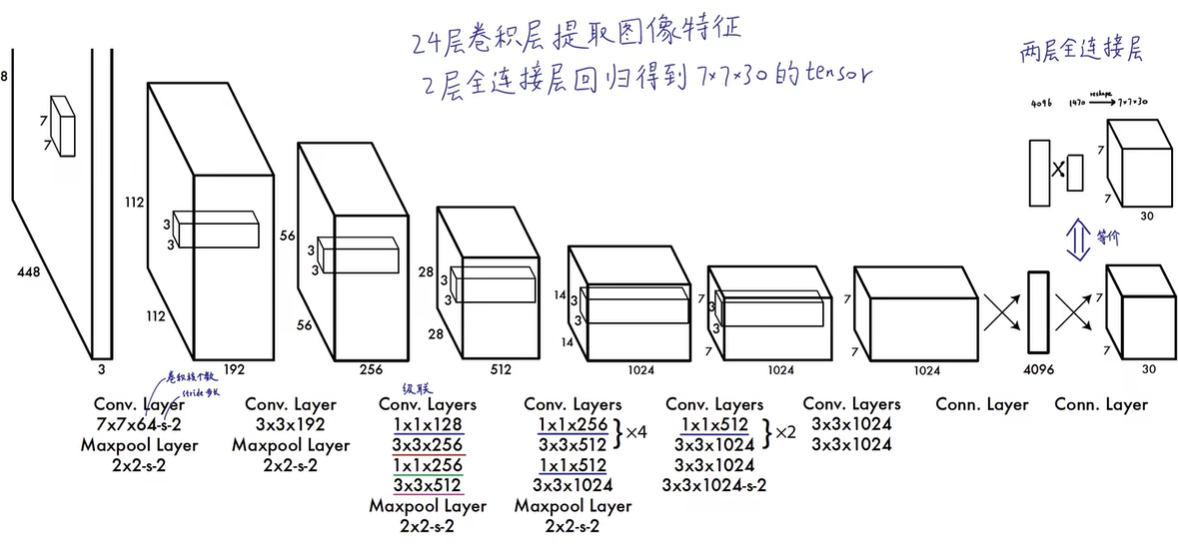
输入图片划分成s×s个网格,yolo v1中 s=7,7×7划分成49个网格,每一个grid cell能预测出B个bounding box,在yolo v1中B=2,只要bounding box的中心点落在grid cell里,说明这个bounding box是由grid cell生成的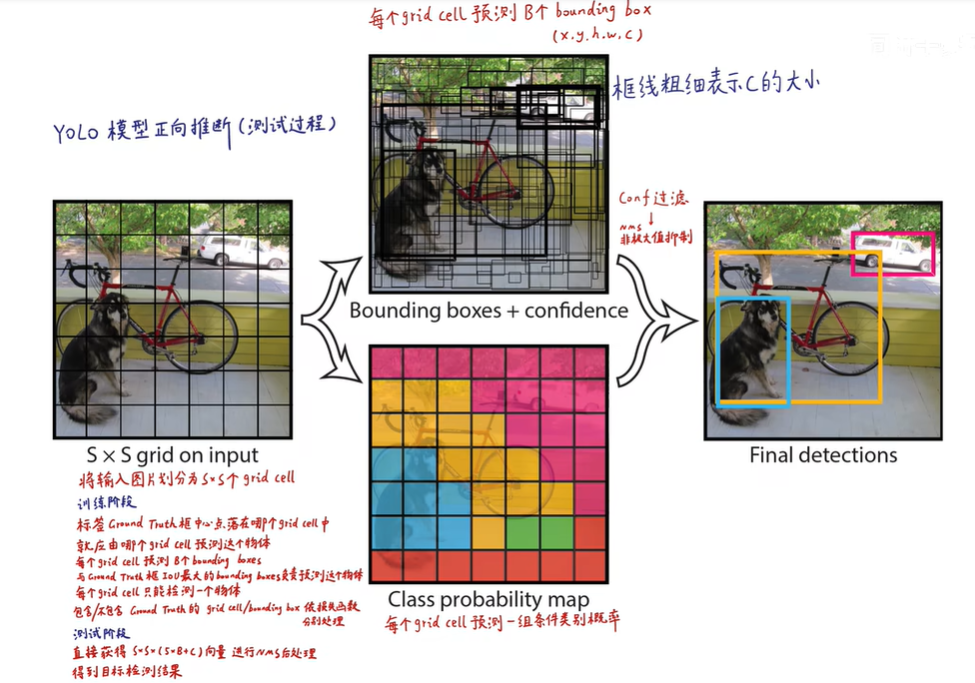
30怎么来的,包含两个预测框,每个预测框包含两个参数(x,y,w,y,1 confidence value)pascal VOC包含20个类别就是5+5+20=30个参数
30维向量就是一个grid cell的信息,总共是7 * 7个gird cell,就是7 * 7 * 30 tensor=1470outputs
输入448×448×3 输出1470个数字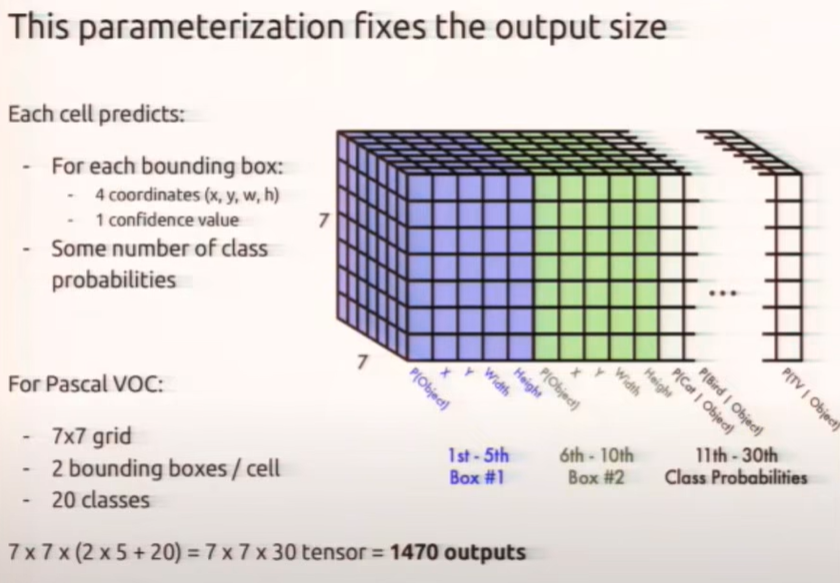
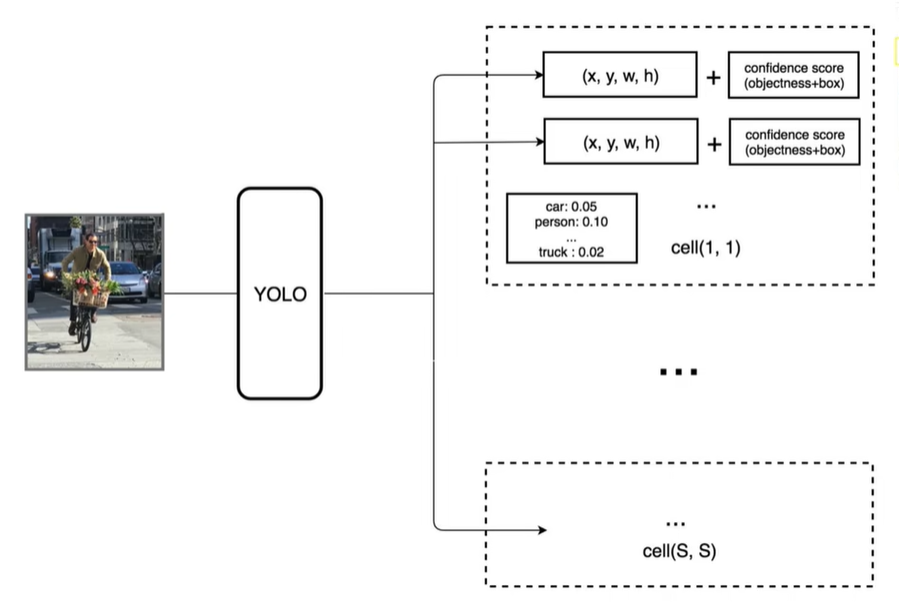
一个网格会预测两个Bbox,在训练时我们只有一个Bbox专门负责预测概率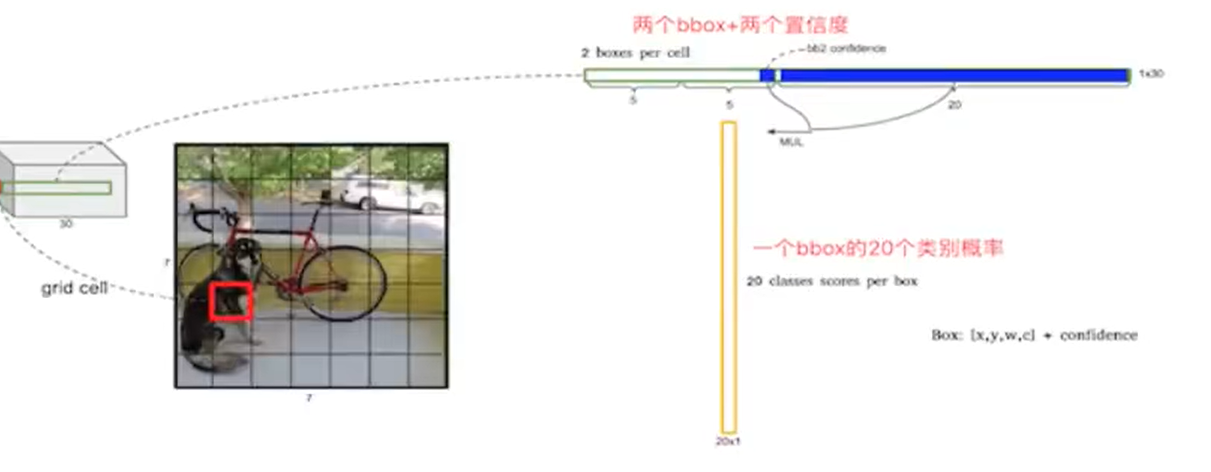
每个bounding box都对应一个confidence score
·如果grid cell里面没有object,confidence就是0
·如果有,则confidence score等于预测的box和ground truth的IOU乘积
6.2 预测阶段后处理NMS非极大值抑制
7×7×30的张量如何变成目标检测结果的,7×7个grid cell中一个grid cell包含30个数字,30个数字由5 5 20 构成,第一个5是由第一个bbox的四个坐标+一个置信度,20个类别的条件概率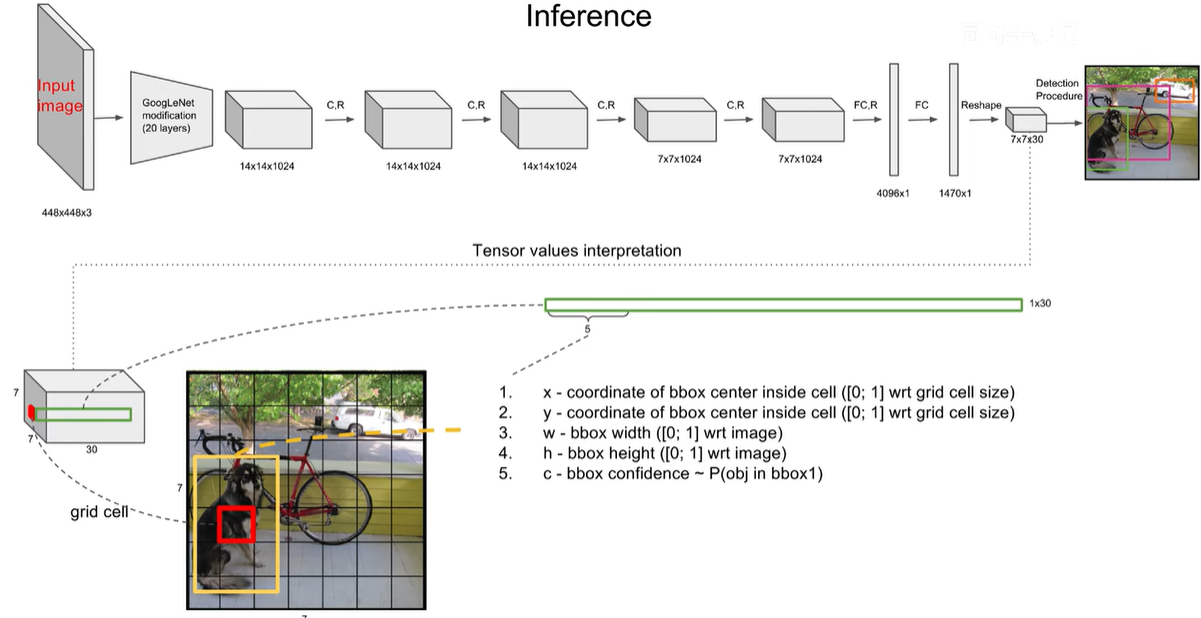
第一个预测框的置信度×它包含物体的条件下各个类别的概率=真正是那个类别的概率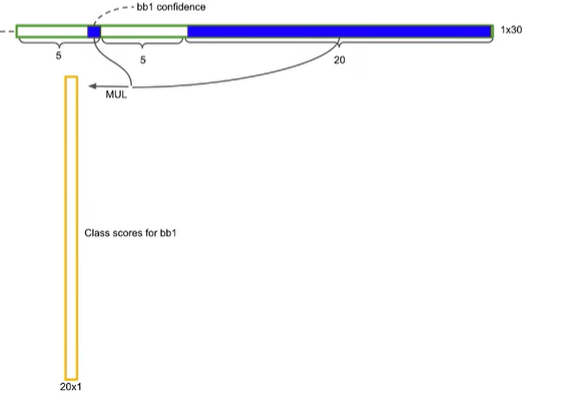
每个grid cell获得两个20维的向量,所以7×7×2=98个bbox,获得98个20维的向量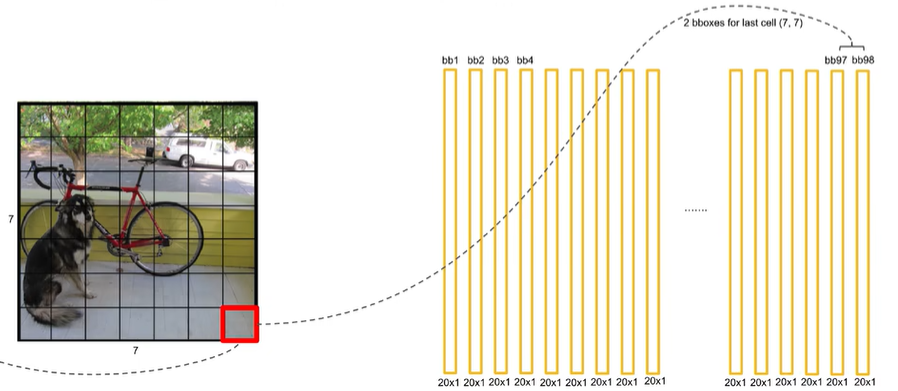
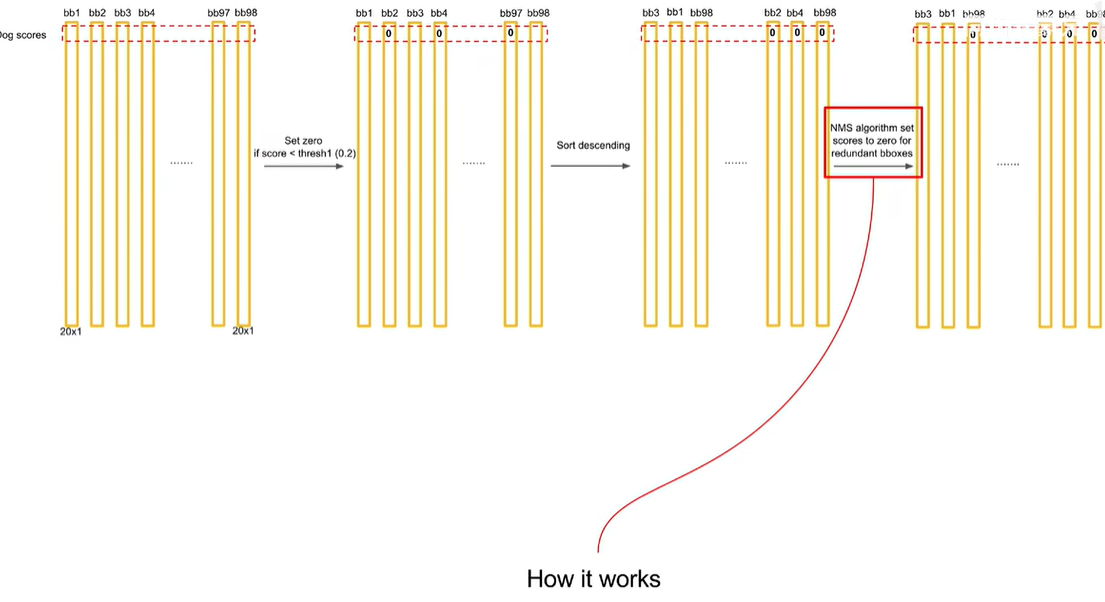
先将最高的拿出来,然后其他的依次跟最高的作比较,如果他俩的iou大于一个阈值,就认为重复识别了一个物体,把置信度低的去掉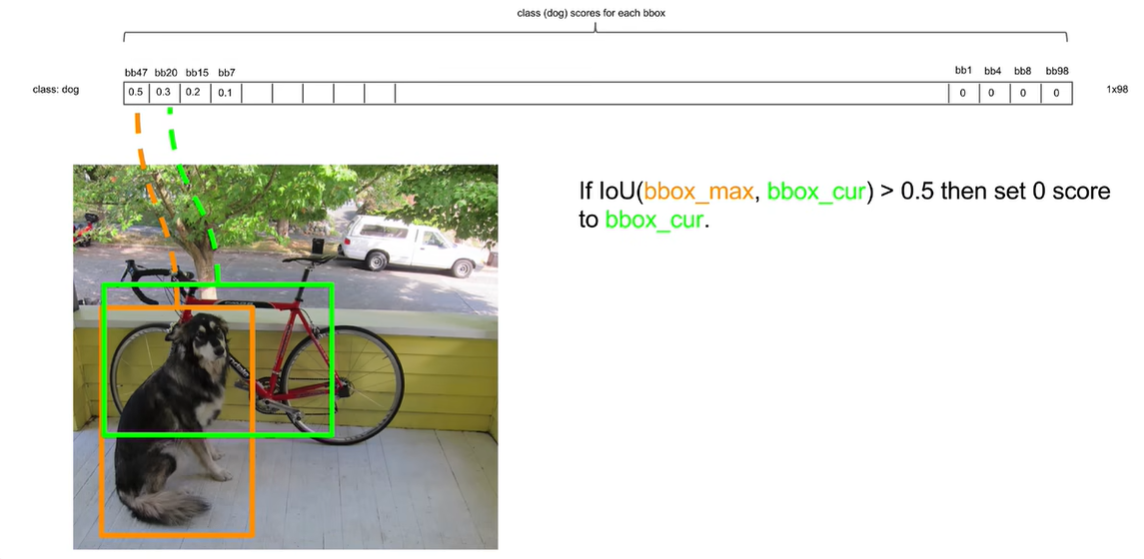
交并比没有超过0.5就保留
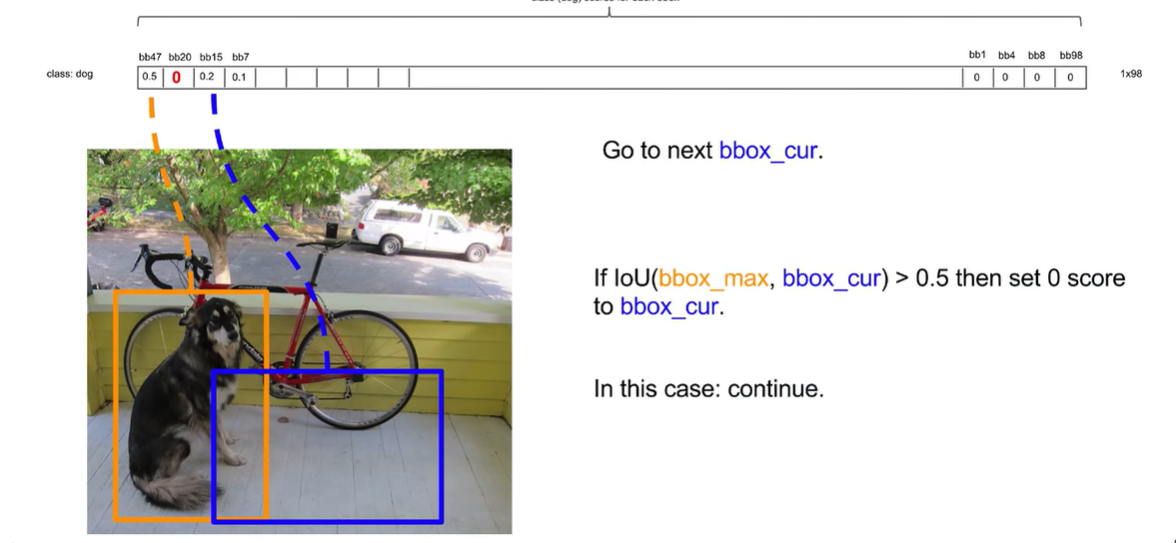
然后将次高的重复上面步骤,发现bb7交并比大于0.5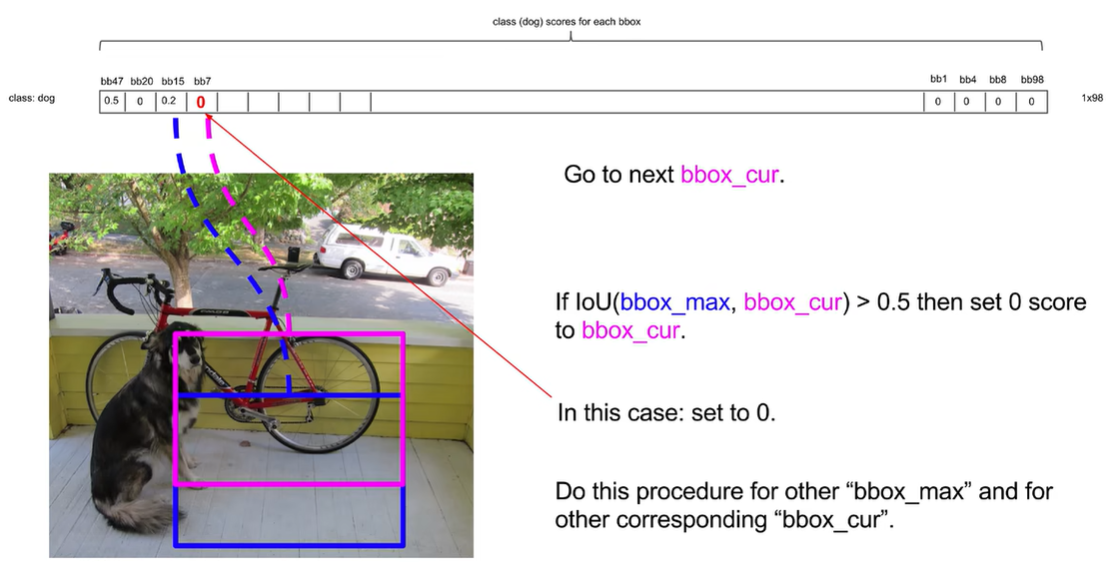
最终获得两个结果
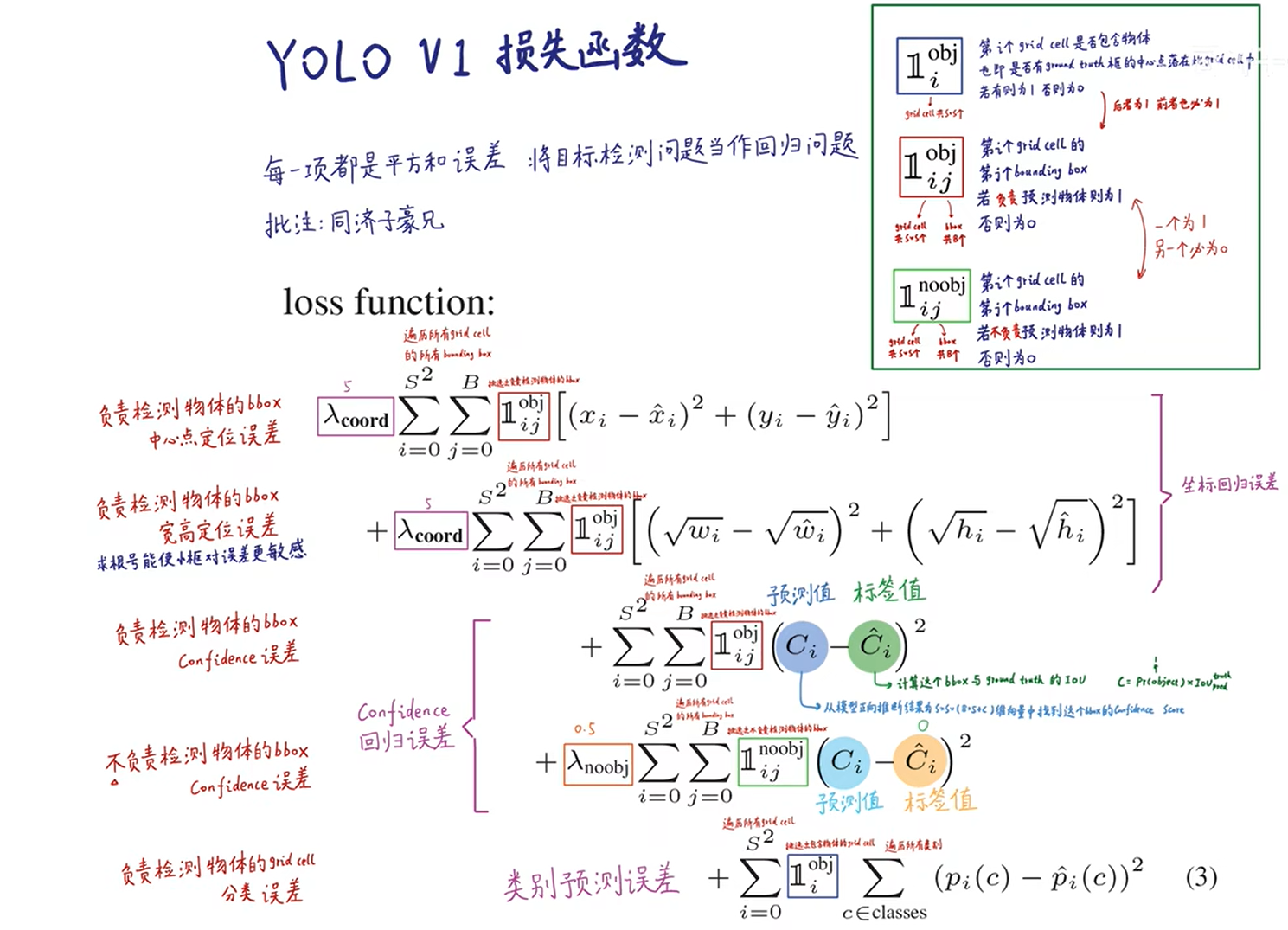
6.3 训练阶段(反向传播)
7 SSD
SSD的特点在于:
·SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用全图各个位置的多尺度区域进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster-RCNN一样比较精准。
·SSD的核心是在不同尺度的特征特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移。
7.1 结构
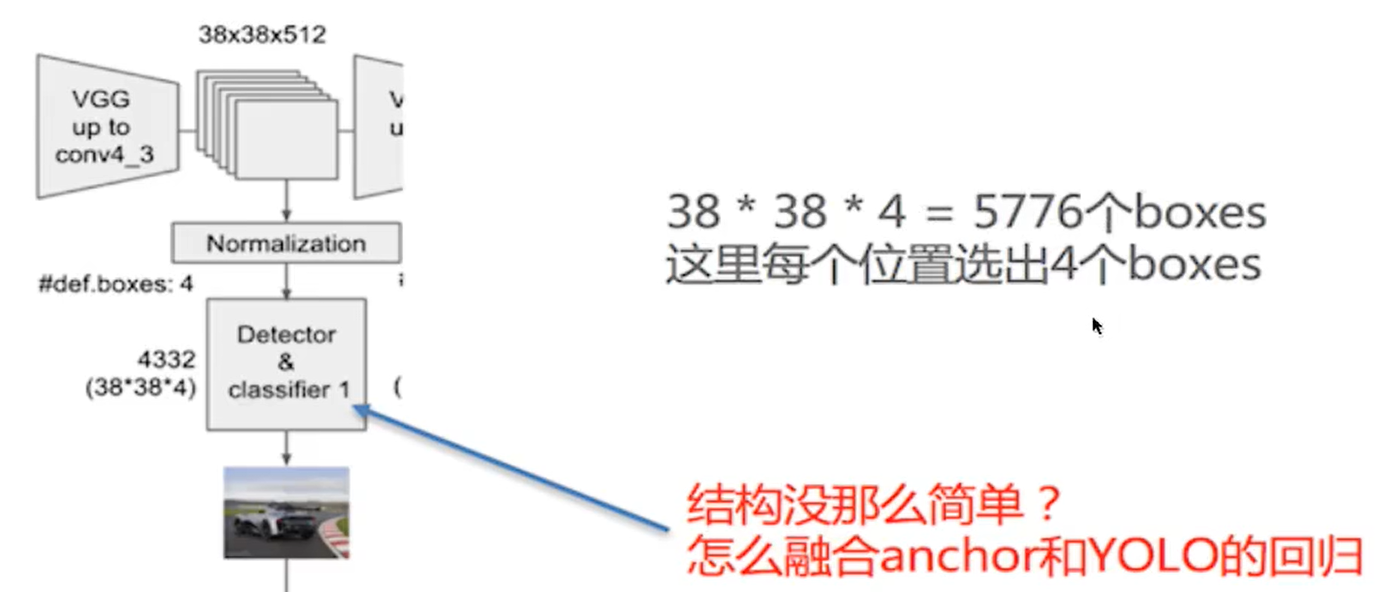
以VGG-16为基础,使用VGG的前五个卷积,后面增加从CONV6开始的5个卷积结构,输入图片要求300*300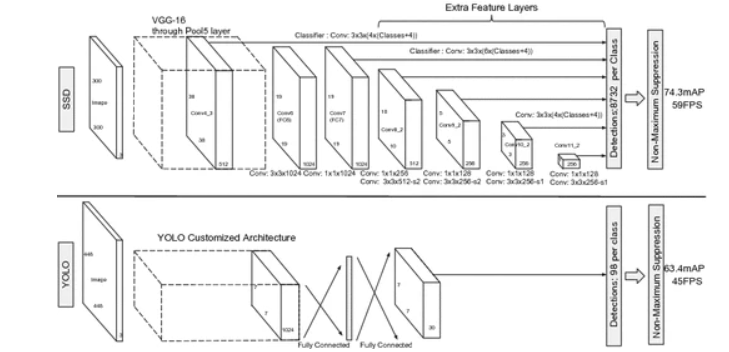
7.2 流程
6层的特征图都需要用到,每一层除了做输入以外,还需要输出特征图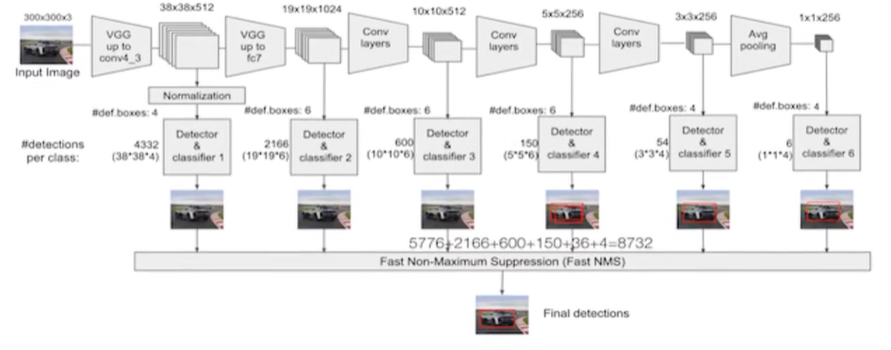
SSD中引入了Defalut Box,实际上与Faster R-CNN的anchor box机制类似,就是预设一些目标预选框,不同的是在不同尺度feature map所有特征点上使用PriorBox层(detector & classify)
7.3 detector classify的结构
1、PriorBox层:生成default boxes,默认候选框
2、Conv3x3:生成localization,4个位置偏移
3、Conv3x3:confidence,21个类别置信度(要区分出背景)
预测三个框,75个候选框,每个候选框有四个位置,5×5×12=300个值,每四个值给一个bounding box ,75个框,每个框要预测21个类别 5×5×63=75×21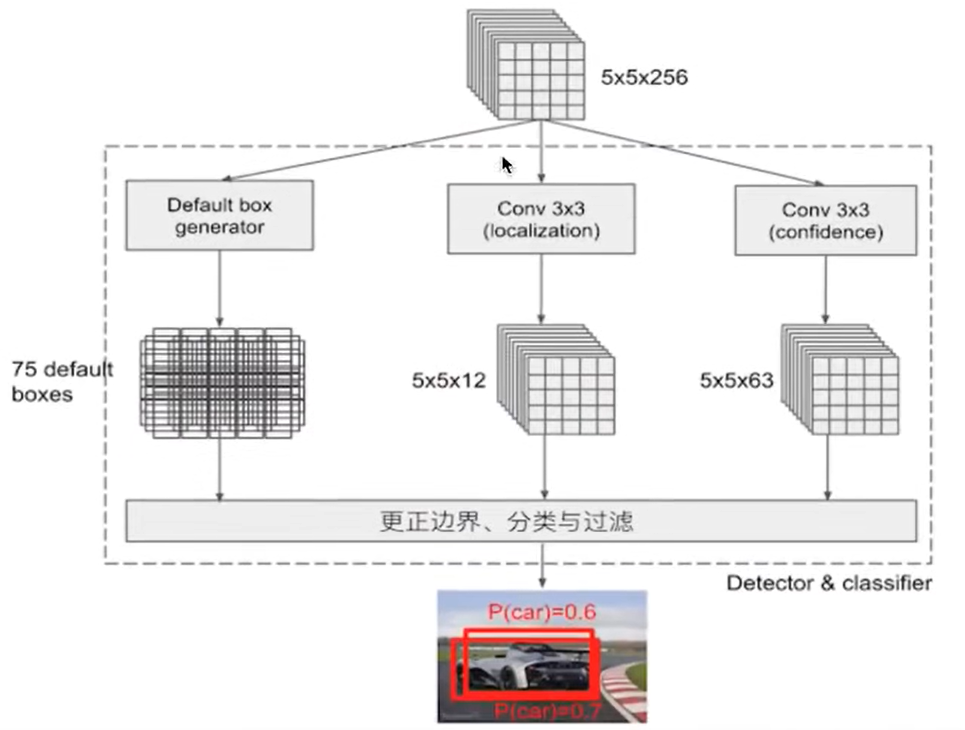
default boxex类似于RPN当中的滑动窗口生成的候选框,SSD中也是对特征图中的每一个像素生成若干个框。
SSD兼顾了速度和准确率
8 RestNet
转载:
https://zhuanlan.zhihu.com/p/1889079285102380738
9 RestNet50
转载:
https://blog.csdn.net/weixin_44791964/article/details/102790260
10 RetinaNet
转载:
https://zhuanlan.zhihu.com/p/143877125
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)