
深度学习在推荐系统中的应用|召回篇
本系列分为两篇:召回和排序。本部分介绍深度学习在推荐系统中的召回应用。出处:https://zhuanlan.zhihu.com/p/201159731「文末阅读原文直达出处」作者:摄影师...
本系列分为两篇:召回和排序。本部分介绍深度学习在推荐系统中的召回应用。
出处:https://zhuanlan.zhihu.com/p/201159731「文末阅读原文直达出处」
作者:摄影师王同学
编辑:搜索与推荐Wiki
说明:重排原文,一起学习
一.整体架构
在现代的推荐系统,由于数据的扩张远远超过算力的增长,外加经济型的考虑,所以架构呈现出分漏斗的多阶段处理,一般整体架构图如下: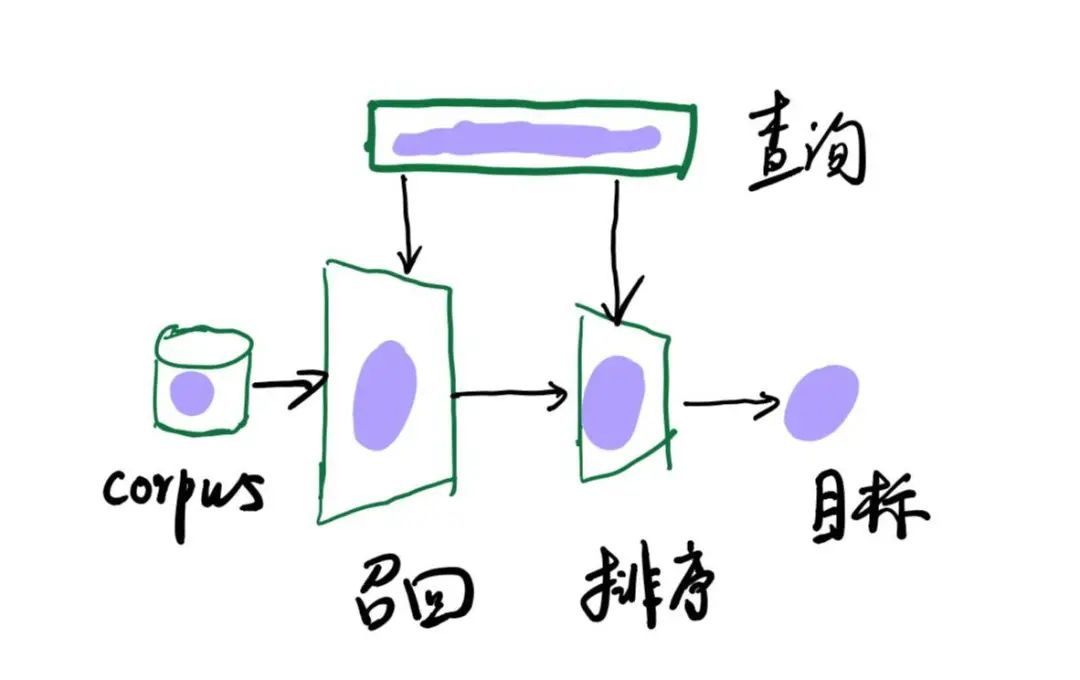
其中召回部分在整套系统起着承上启下的作用,下边会详细介绍
二.召回系统
作用:在海量(100M+)的内容中快速筛选得到目标内容(小于K级别)供上游系统(排序)使用,一般召回系统通常要从算法和工程上两方面配合去实现。
算法:对内容进行潜在特征表示, 不同内容的特征可以进行非常轻量的计算,通过计算的结果可以筛选得到目标内容;
工程:对内容的特征表示结果进行合理的存储,轻量算法的设计和加速,满足在线低延迟大规模的计算和筛选。
所以召回系统由两部分组成:
-
1.离线的候选物品的特征表示,通过设计好的算法对参与召回的物品进行特征表示,并将表示结果用工程化设计存储方案进行存储,方便在线使用。
比如:
传统的搜索引擎,特征是网页中关键词和权重,存储方案是倒排索引;
传统的推荐引擎,协同过滤召回的特征就是相似物品的id和相似度得分,存储为k-v结构
-
2.在线特征匹配计算和目标筛选。
比如:
传统的搜索引擎,在线计算就是匹配query和索引中的关键词,并根据匹配成功的词进行打分排序
传统的推荐引擎,协同过滤召回在线计算只需要根据id查询并根据相似度得分过滤
这次分享主要是深度学习在召回系统的使用,基本在算法篇,工程篇会在后边介绍。
三.深度学习召回匹配的分类
基于实现方法,一般可以分为以下两类:
1.基于表示学习型的
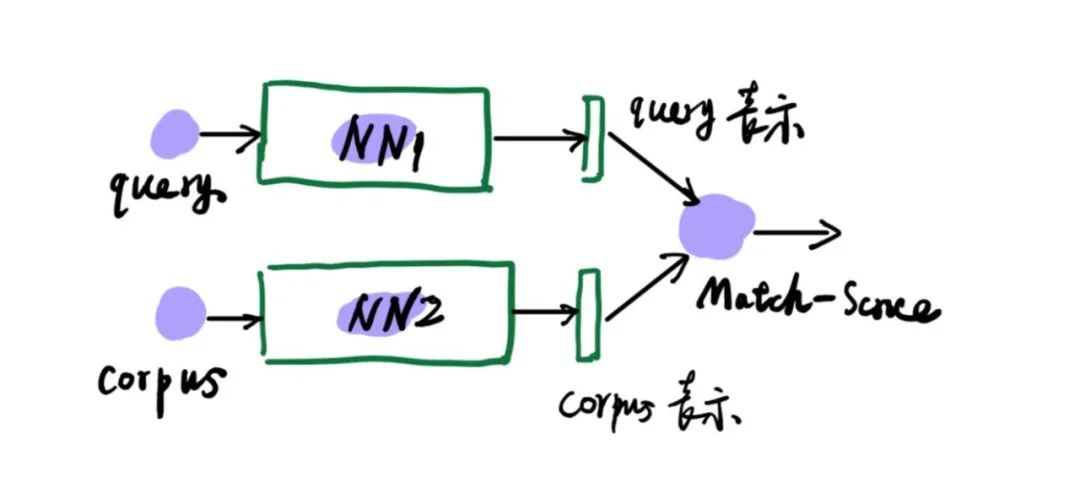
query物品和召回物品通过独立的网络模型各表示成一个向量,两个表示向量通过一个轻量级别匹配分数算法得到匹配得分,最终通过匹配分数筛选的期望结果。其中NN1和NN2可以共享参数(同一个网络),在同构召回中基本都是这种思路;可以部分共享参数,比如共享物品的embedding编码;也可以完全不共享参数。
优点
可以在离线做较多的工作,比如可以离线将所有召回物品预先编码好embedding向量,这个编码网络可以用复杂的模型进行很好的语义表示;
参与召回的query在一些模型也可以离线编码 (若在线编码只运算一个物品,运算量也很小)
在线匹配分数可以做的很简单(cosine或者l2 距离),通过优化可以在有限的时间进行大规模的计算,将候选池最大化。(具体优化在工程这一节会分享)
缺点
1.query物品和召回物品独立的网络训练,缺少交互,无法获取更强的相关信息(如召回物品对不同的query物品,其特征的强弱程度有可能不同,这些的信息无法捕获)
2.在线一般都做轻量级分数计算,无法融入更多的实时的上下文特征(如当前时间)
2.基于匹配分数型
直接将query物品和召回物品一起输入到一个神经网络,这个神经网络最终输入匹配得分,最终通过匹配得分得到期望的输出结果。
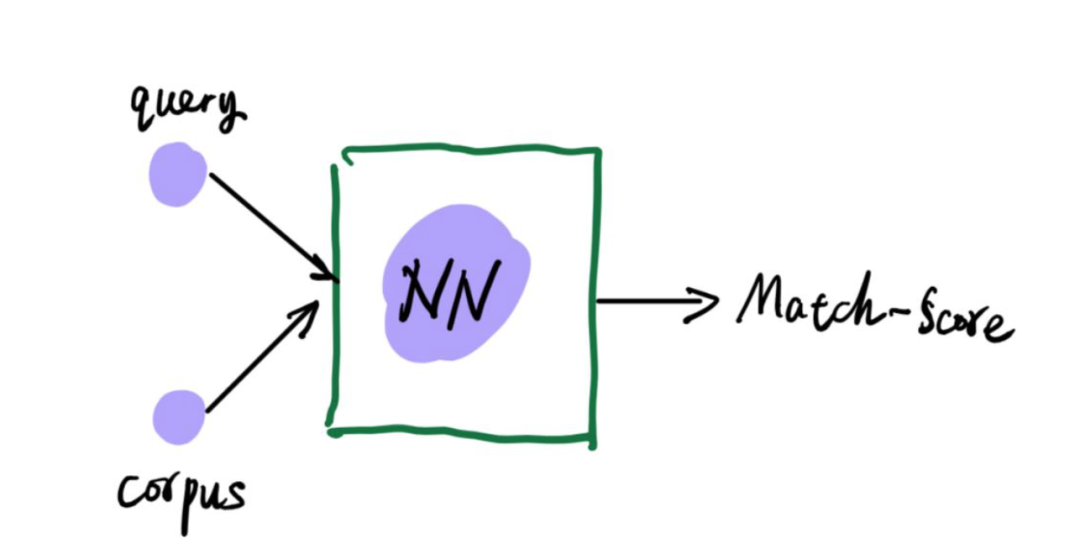
优缺点和基于表示的基本相反。
根据召回实现的功能一般可以分为以下两种。
-
1.同构物品召回。也就是query物品和召回的物品属于同一类,比如query是物品,召回是同一类物品
-
2.异构物品召回。也就是query物品和召回物品不属于同一类,比如query是用户,召回是待推荐的物品
由于基于匹配的算法,效果好的复杂模型因为在线计算量较大,无法进行大规模计算,基本都是做为二次召回(或粗排),这种做法会放到下一节排序中分享,这次分享主要侧重于表示型的深度学习做法。
基于表示学习的核心点是:将query物品和召回物品 表示成同一向量空间的低维度向量,表示的向量可以通过简单的距离计算,根据运算结果经过排序过滤就能得到符合上游业务系统的物品。
为了学习得到这种目的embedding向量表示,一般会有以下三类算法:
-
1.无监督算法。一般就是通过降维的算法将物品表示压缩到低维向量
-
2.弱监督(自监督)的算法。在无标签数据(也就是在什么query下应该召回什么物品)情况下,通过其他信息做为监督信号进行学习得到物品的embedding
-
3.有监督的算法。有了标签数据(标签数据不一定是人工标注,可以是规则生成),通过标注的标签数据进行学习得到物品embedding
下边将对以上三种算法展开介绍。
四. 无监督学习
回想在传统的基于物品的协同过滤中,需要将物品表示成向量,向量通过算相似度找到最“相似”的物品。其中最核心的是物品向量如何表示,做法就是生成维度和用户总数一样的0向量,每个用户占用一维,若这个维度的用户对此物品有正向行为(视频新闻上的播放,购物网站加入购物车,购买等),此维度标记为1,如此办法生成向量。
有了这种向量,我们就可以采用自编码器(Auto-Encoder)对原始向量压缩降维得到一个低纬度的向量,可用此低纬度的向量来表示召回物品,若下图所示:
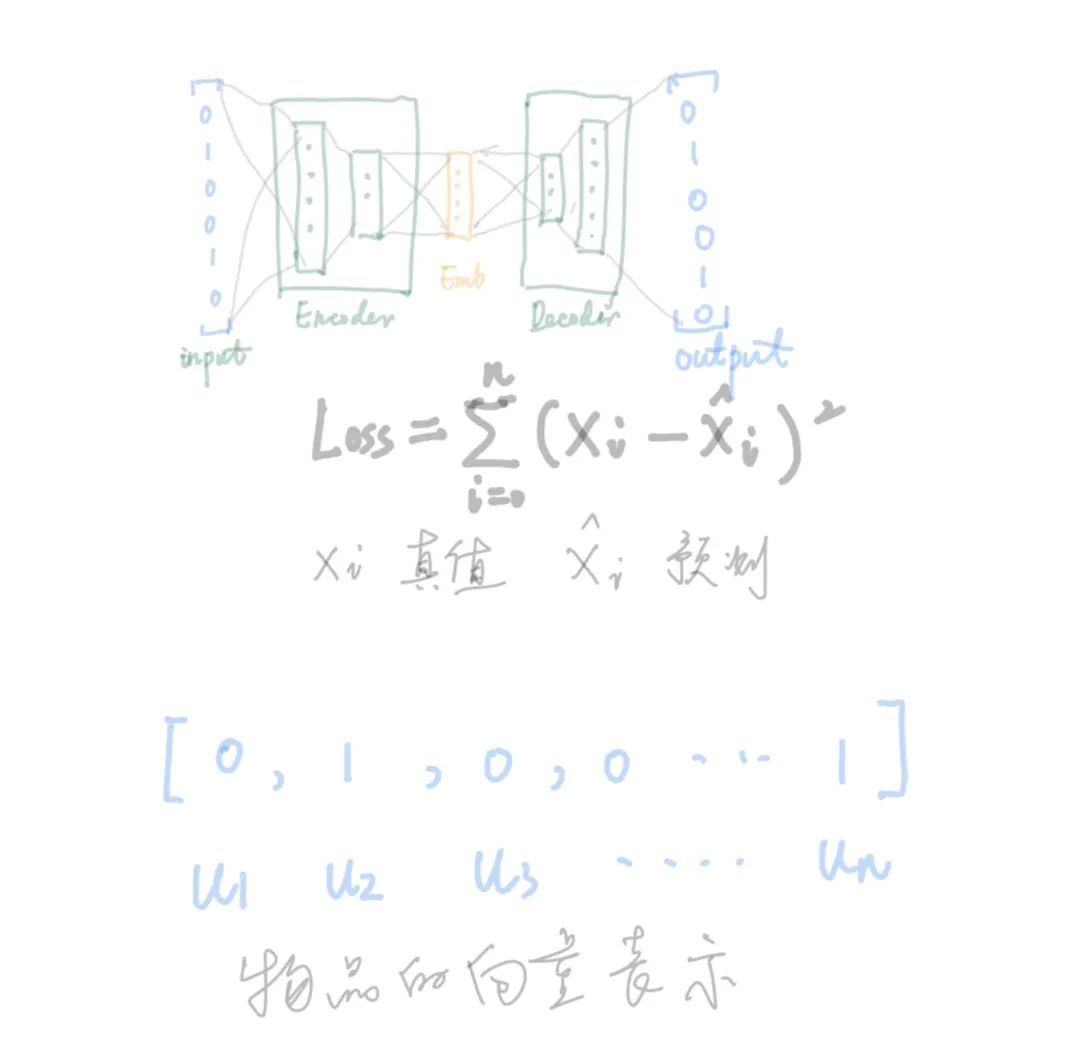
其中上边编码器和解码器的网络可以自由组合,比如除了基本dnn,也可以用cnn。
上边图是展示如何压缩得到物品向量,同样可以得到用户的向量表示,输入端是用户的one-hot表示
AutoEncoder压缩得到的向量只适合做同构物品的召回。
五.弱监督学习
1. item2vec
item2vec的思路来自word2vec,将用户对商品的正向行为在时间维度上转成序列信息(session),在序列信息中划分固定的滑动窗口后,利用自监督信息来进行上下文预测,从而得到item的向量。
item2vec 一般有两种实现方案:cbow (通过两侧预测中间), skip-gram (通过中间预测两边)。一般使用中后者的效果会更好,因为要用一个中间物品的表达出多个相邻物品,语义表达能力更强。
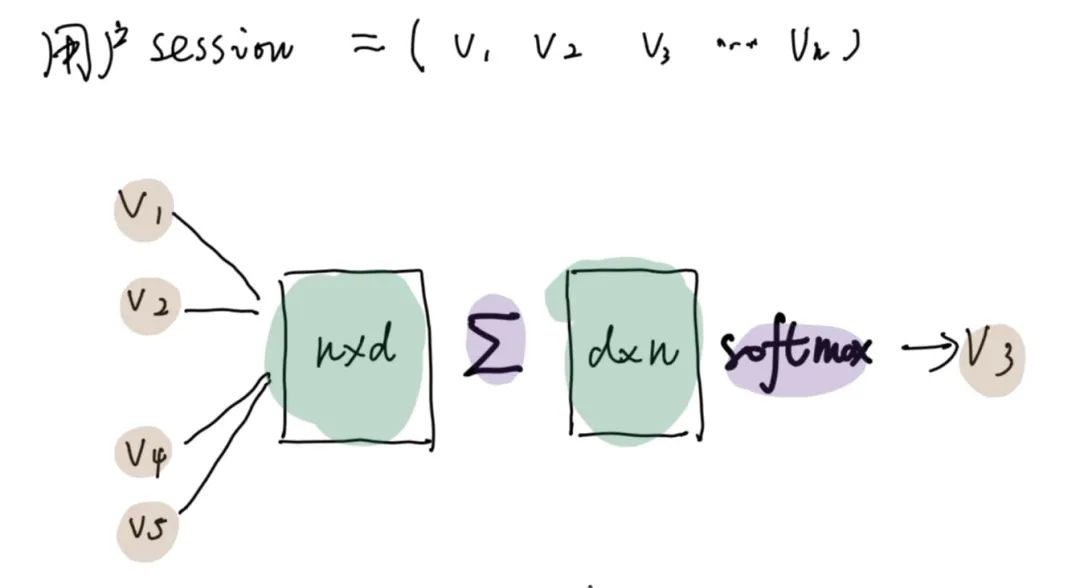
左边的 的参数权重的每一行 既可以被认为是每个item的向量 定义为 ,右边的 可以被认为是学习的权重定义为 。
item2vec 非常核心的一点是 在一个不定的用户行为序列上,如何切分session,以下给一些Airbnb的参考做法:
-
1.用户的行为时间的间隔如果超过30分钟,属于一个新的sessio
-
2.如果用户的行为中产生预定行为(下文中提到book),预定行为之后的属于一个新session
2.Airbnb 的item2vec 改进
skip-gram算法是相当softmax最大化上下文词的概率,由于词表一般比较大,会采用负采样算法来进行优化计算。采用负采样后的skip-gram的损失函数推导如下:
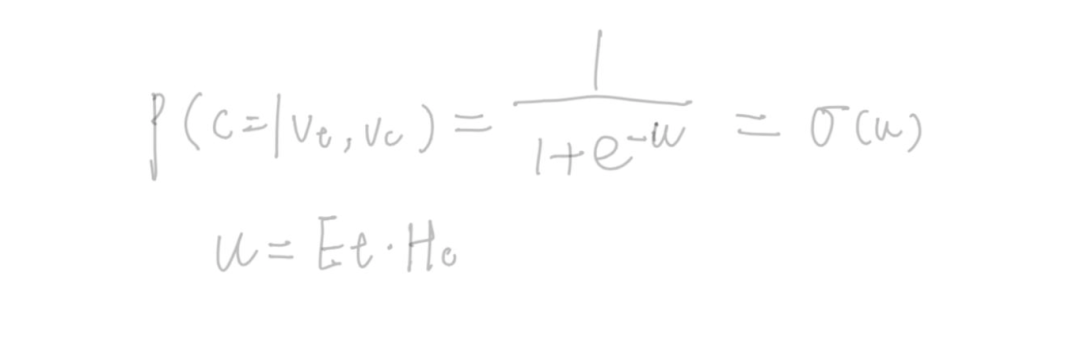
假定
和
是正采样,
是中心词,
是上下文词,希望的
和
的向量足够相近,
变大,所以上述的概率会变大(趋于1);假定
和
是负采样,
是中心词,
是负采样词,希望的
和
的向量足够远,也就是-
变大,
趋于1,所有优化目标变为如下
airbnb基于自己的业务产品形态,在skip-gram上优化了损失函数了,如下: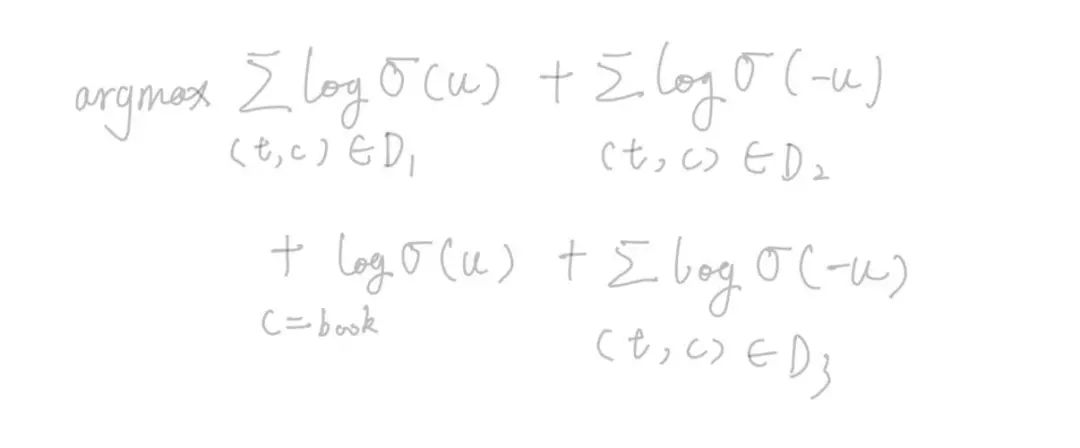
其中前两项是标准的skip-gram的损失函数
第三项是session中预定的房源和中心房源的的pair对,认为预定房源是正样本,和上下文房源同等对待,当然可以加上超参数权重加大对目标函数的贡献。
第四项是根据业务重新构造的一个负样本对,为中心房源和中心房源所在的地域的热门房源组成,出发点很明确,同一区域的热门房源用户没有预定,那么这个房源和中心房源互斥。
思考:在自己的业务场景,用word2vec的损失函数还可以做如何优化?
3.阿里的deepwalk
简单的流程描述如下:
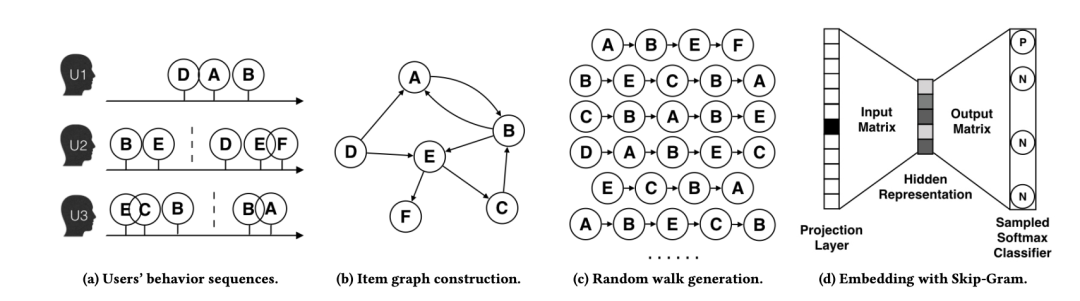
挖掘用户行为序列->构建图→随机游走重新产生序列→word2vec生成向量
最大的改进分两点:
-
1.利用户行为序列构建图时,边的权重可以求和,甚至用一些(如pagerank的)传导算法再次加权
-
2.随机游走生成序列时,转移概率可以指定,权重高的转移概率高,权重低的转移概率低,相当边权重高的节点被采样的概率高,在上游训练的更加充分,得到表示向量也更好。
阿里的论文中随机游走的概率公式如下,一个节点 跳转到另外一个节点B的概率等于:这两个节点AB的边权重除以和 节点相连所有边的权重和。
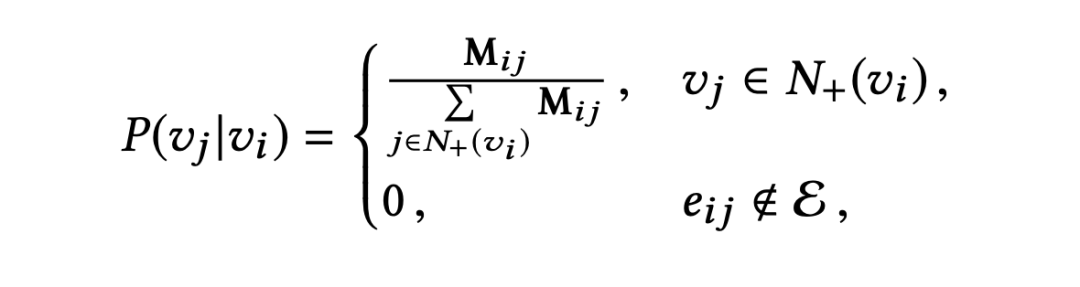
4.图自编码器
和第四节分享的自编码器大体模型一样,只不过输入是用户行为序列构建的图,编码器采用了GCN,编码器得到矩阵 , 节点数目, 向量维度)的每 一行可以表示为一个节点的向量,解码器直接是Z和Z转置相乘并用sigmod激活到0~1之间重建得到新的连接矩阵 。
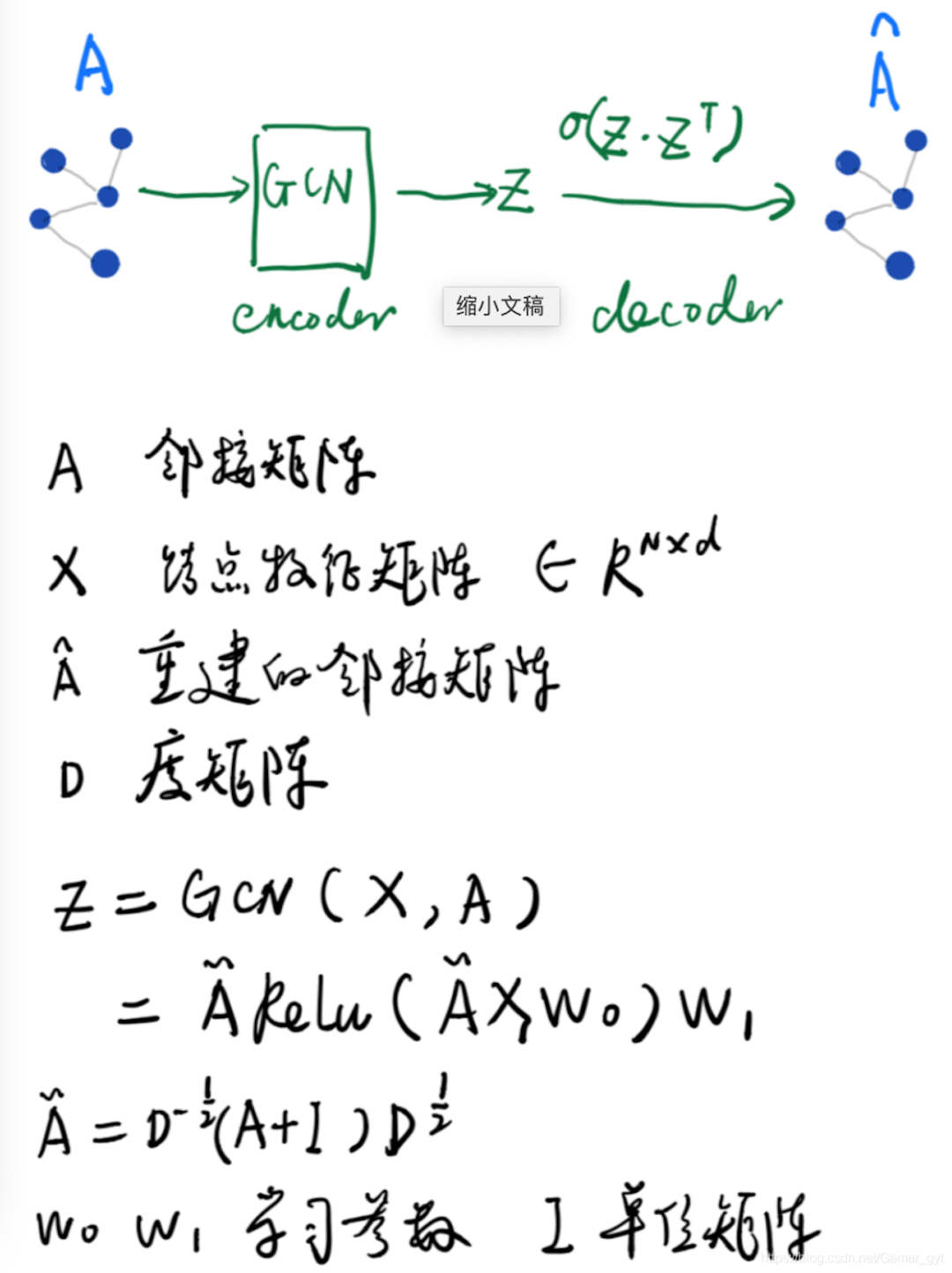
其中优化目标是希望重建后的 和 足够接近,由于这里的邻接矩阵 的都是0,1分布,故可以用softmax做为优化函数。
综上,弱监督表示学习也是用在同构的物品之间,只利用用户的序列行为信息就可以得到一个比较好的物品的embedding表示。
六.有监督同构物品表示学习
这种学习的前提是有标注好的样本(比如两个物品相似的正样本对,两个物品不相似的负样本对)。注意这里的标注不一定要人工专门去标注,可以利用原始用户行为信息+规则去标注,比如在一个视频网站,用户在一定时间内观看的视频两两相似做为正样本,观看的和没有观看的属于不相似作为负样本(具体抽样策略会在后边分享)。有监督的表示学习一般有以下做法
1.双塔模型
双塔模型大体原理图如下:
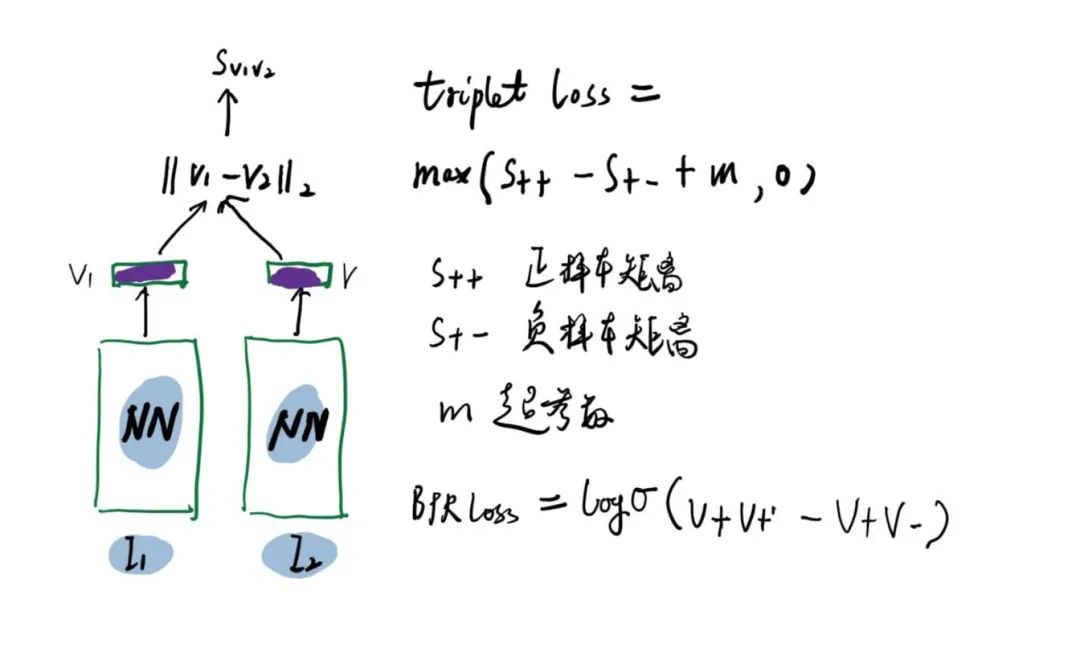
物品经过NN(神经网络)编码后得到输出的向量,采用triplet loss时,希望正正样本之间的 距离足够小,正负样本样本之间 距离足够大 ,并且正负样本的距离差需要超过 。采用贝叶斯优化loss时,希望正正样本向量之间的点积足够大,正负样本向量之间的点积足够小。
这个时候双塔之间的神经网络参数共享,完全一致。
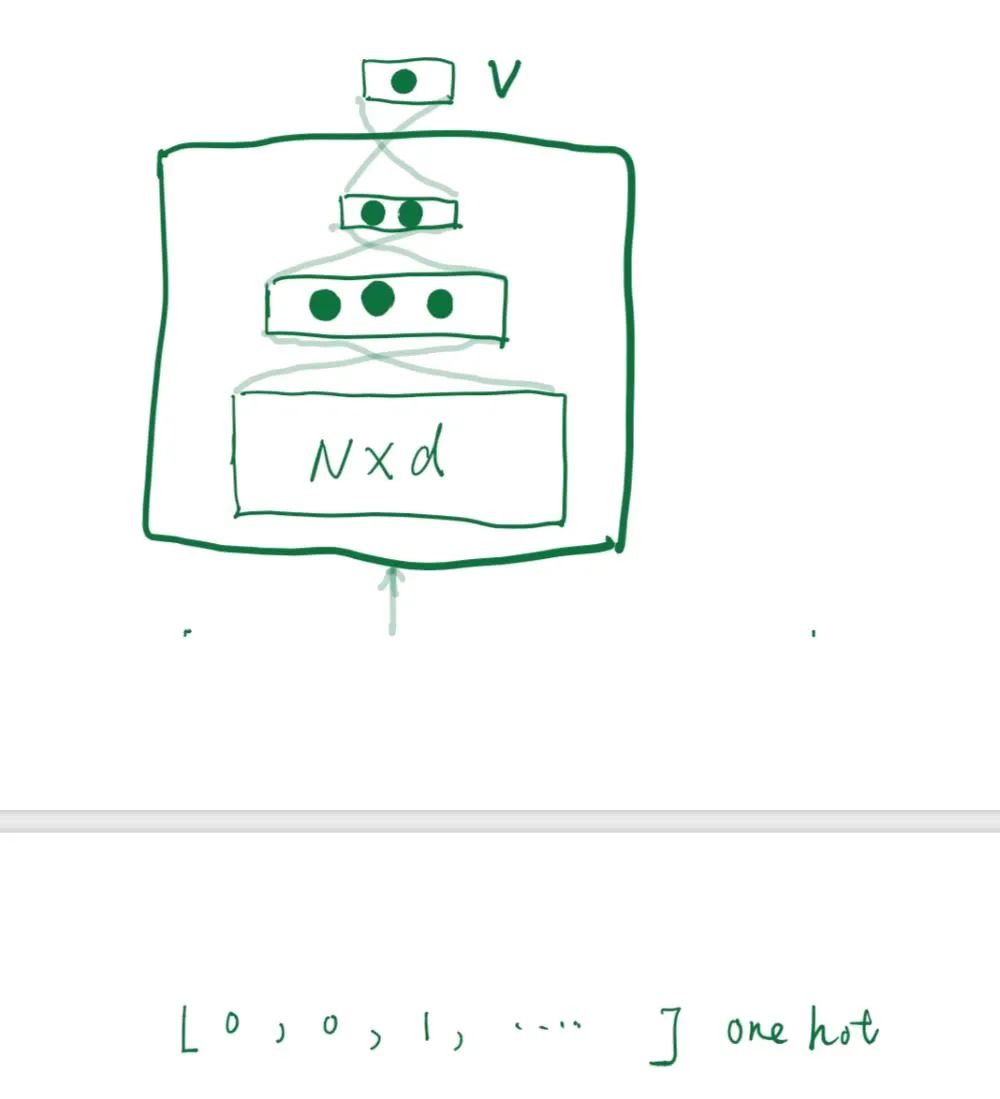
最基本的NN网络,物品采用one-hot表示输入 ,经过Embedding查表得到物品的输入embedding表示,在经过简单DNN 学习,就得到商品的embedding (这里是画了上图的NN部分)
基于这种思路,中间的NN可以进行很多变化比如改成卷积,网络模型中也可以加入更多的特征,如下图,可以加入物品描述NLP的特征(比如用预训练的bert编码物品的描述),如果有图片海报可以加入图片的特征(比如用预训练cnn网络提取图片的特征),甚至可以融入知识库等等。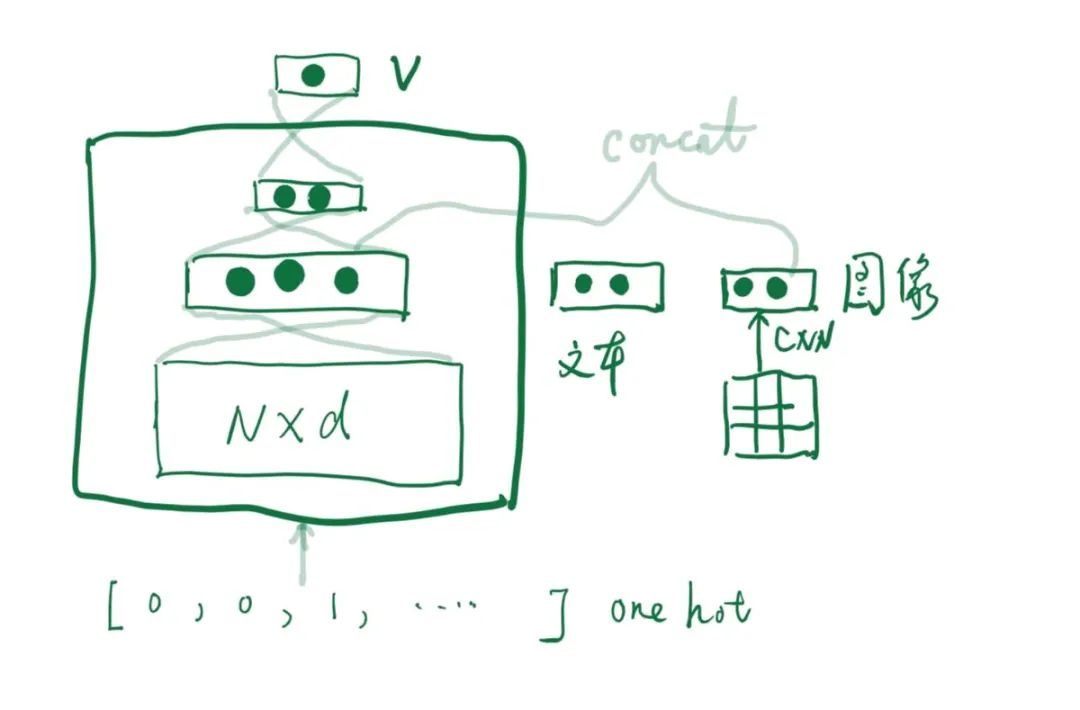
双塔模型在训练完成后,对物品的表示只需要获取 这一层的输出即可,上面的匹配得分可以不要。
2.微软的DSSM
DSSM模型由微软提出,主要是解决搜索引擎中query和document的匹配问题,核心思路是训练过程中采用一正多负的样本pair对(微软是采用一对正样本,四对负样本),最终的优化函数是cosine相似度经过softmax后的交叉熵,模型大体如下(为了画图简单,采用了一正一负的pair对)
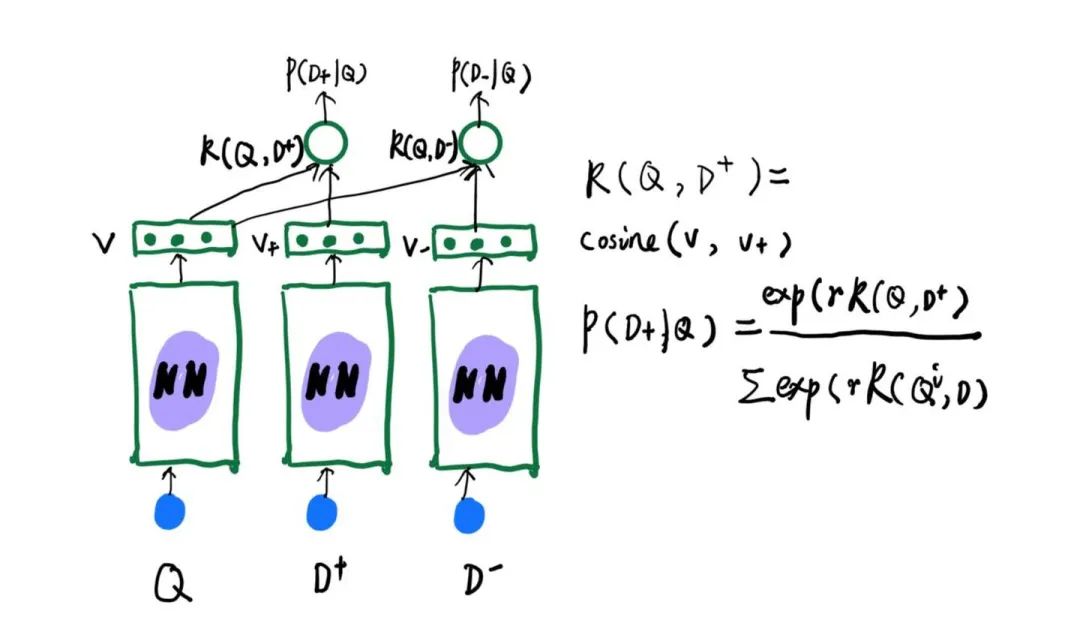
其中 是超参数希望平滑概率,期望 和 的向量尽可能相似, 和 的向量尽可能远。也就是 尽可能大 ,也就得到以下的损失函数,也就是交叉熵(正样本的label=1,负样本的label=0所以省略了)。
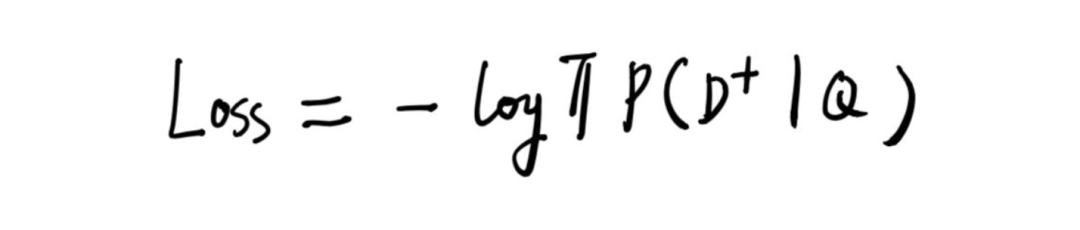
同样的其中的NN神经网络可以魔改,比如CNN-DSSM,LSTM-DSSM,注意几部分的NN神经网络参数共享。
七.有监督的异构物品召回
一般在推荐系统的异构召回下,都是基于人召回物品,这个时候需要将学习出来用户和物品的向量映射到统一维度表示的空间,分别有以下做法:
1.基本的双塔模型
这个和同构物品的基本双塔模型保持一致,用户和商品都采用one-hot输入,经过查表embedding后输入dnn得到表示向量,注意这个时候双塔两个网络是完全独立的,同构召回中两个双塔网络共享参数(可以认为是一个网络)
2.利用用户行为的双塔网络
这个网络最大的特点是用户的输入不是one-hot,而是通过其行为物品的embedding来表示,如下图
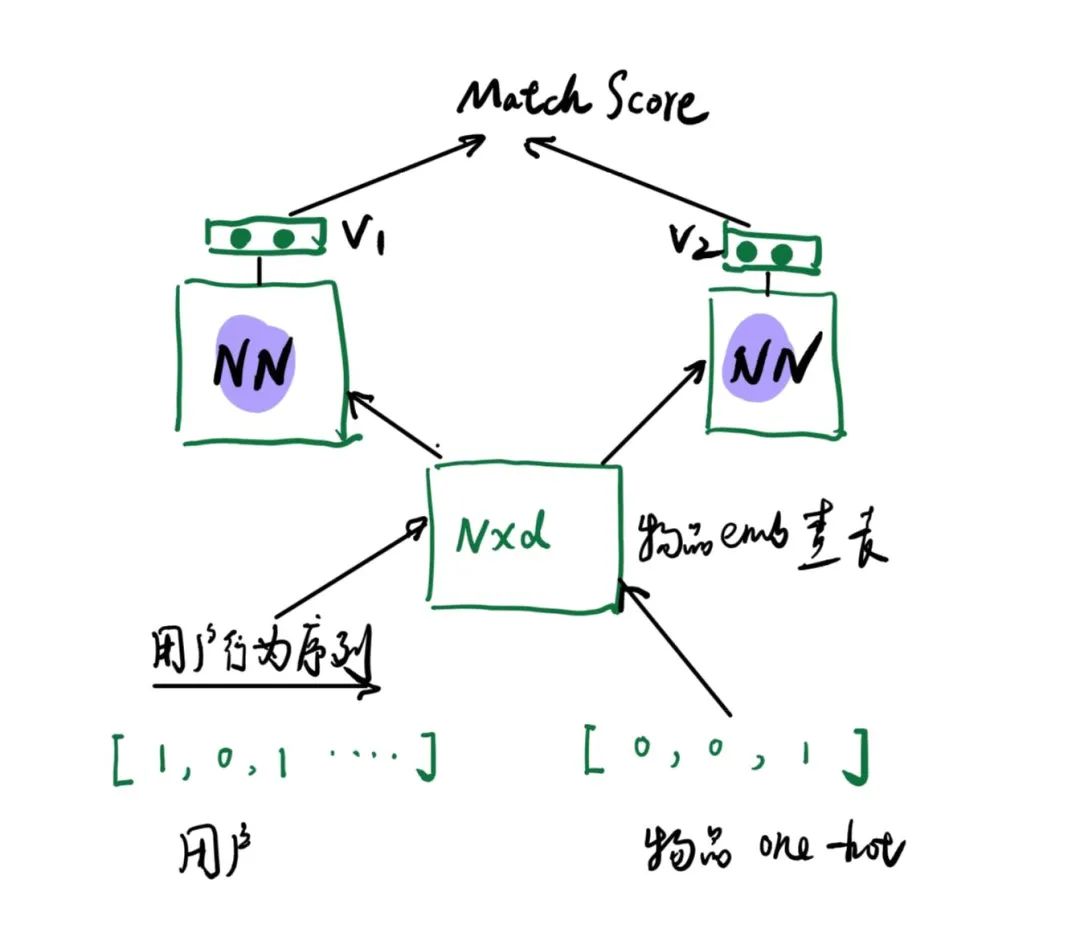
用户输入物品行为序列先通过查表获取物品embedding 得到一个矩阵,这个矩阵输入左边的网络,物品通过查表物品embedding进入右边的网络,最终左右网络分别输出用户和物品的embedding表示。
其中用户查表的物品embedding和物品输入查表的embedding共享, 既可以随机输入通过目标任务一起训练;也可以通过第六节的方法进行预训练,在这里用预训练的结果。
同样这里的NN网络和输入特征可以自由组合,如下:
-
1.物品侧网络可以加入物品的特征,如第6节提到的物品的描述,图像特征
-
2.用户侧网络可以加入用户的特征,比如用户的年龄,性别,所在的地域等等特征
-
3.用户行为是一个时间序列,可以用RNN系列网络来进行序列特征学习
-
4.用户的行为可能误操作带来的噪音(或者兴趣不强烈的),可以通过self-attention机制来加强兴趣物品,和较少噪音物品。
这些知识会在后边继续分享
这种通过行为商品来表示用户的模型有以下优点:
-
1.对用户的描述比较准确
-
2.one-hot的用户输入,新来的用户没有embedding,需要重新训练网络。而这种模型只要用户有了一定历史行为,就可以用训练好的网络直接生成用户自身的embedding
3.DSSM召回
这个和第六节的DSSM原理一样,注意的地方就是人和物的NN神经网络不一样,同样NN的网络可以参考7.2小节做网络变换和加入更多的特征
4.Youbute DNN召回
很多深度学习的排序模型都以此为基础延伸,所以这个模型会在下一节排序中做详细的介绍。
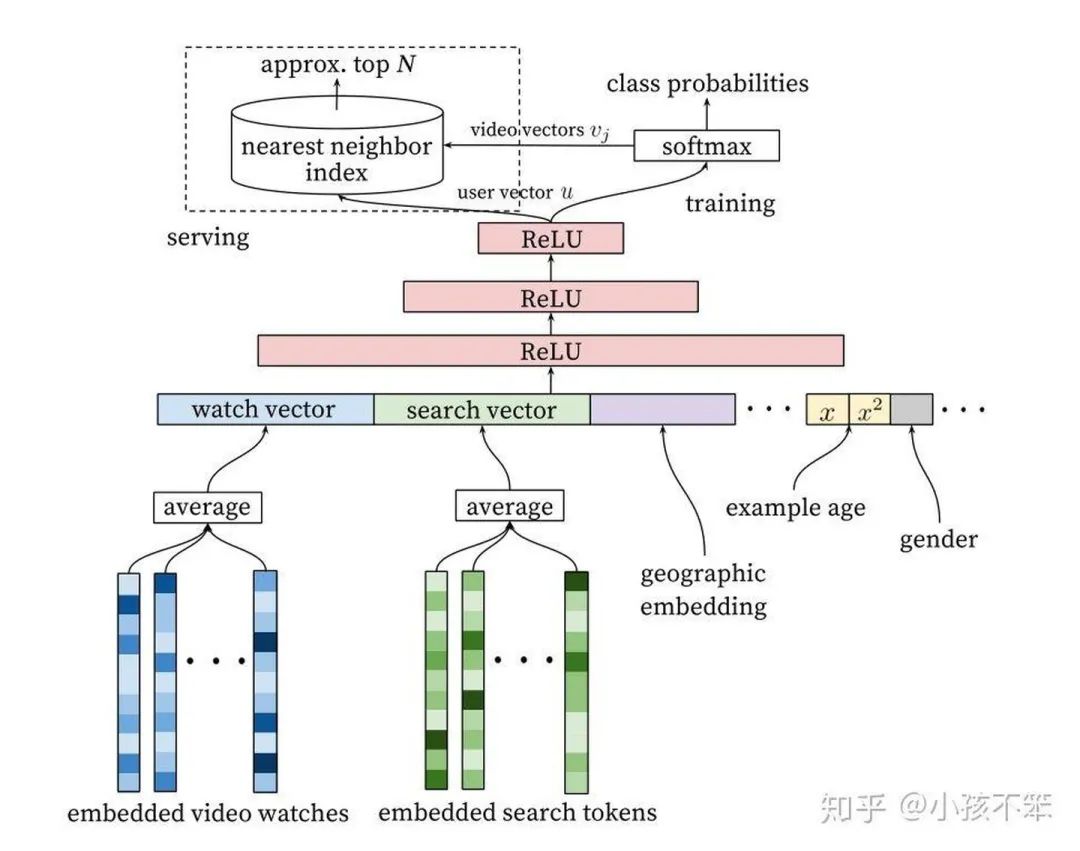
这个模型主要的思想是输入是用户的各种行为和特征,预测的目标转化为一个多分类的任务,类别的数目就是参与学习的视频的总数目,若用户对某个视频有正向行为,就认为这个类别的预测值是1,没有正向行为认为预测值是0(真实训练过程中因为视频数目太大,会采用前边提过的负采样的技巧)。
这个模型认为神经网络的最后一层输出(最后的ReLU输出)就是用户的Embedding表示,参与模型训练的同时会有一个视频embedding表示矩阵D(N*d),N是视频总数,d是视频embedding的维度,d和神经网络最后一层ReLU的输出维度一样(和用户Embedding维度一样)。假如用户u对视频j发生了正向行为(u和vj点击足够大,和负样本视频点击足够小),也就是下边的概率P最大化。
可以采用5.1和5.2提到负采样损失函数来优化目标,网络训练完成后将D每一行作为视频的Embedding表示,将用户的特征输入网络,得到最后一层神经网络的输出做为用户的Embedding。
八.总结
-
1.核心将在线的query和要召回的物品标示成同一空间的低纬向量
-
2.优化目标和损失函数是需要重点考虑的地方
-
3.一样要做尽可能多特征工程,如用户行为如何分隔为session
-
4.有监督的表示模型,同构的召回用同样的神经网络,异构的召回,神经网络不同,注意不要提前发生交互
更多推荐


 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)