
红外小目标检测论文(DNA-Net)学习(OUC新芽第四周)
” 红外小目标检测也是同理,
本周计划对语义分割任务代码中通用的损失函数,数据集处理与评估指标进行学习,恰好主题中第四篇论文(TIP2022) Dense Nested Atention Network for Infrared Small Target Detection (DNA-Net) 提供的代码是用pytorch完成,同时结构清晰,于是利用DNA-Net的代码部分学习语义分割任务中pytorch代码通用的损失函数,数据集处理与评估指标。有下面几个收获:1.了解了语义分割两个常用的损失函数IoU与Dice。2.了解了图片怎么处理成张量并打包成batch。3.了解了语义分割常见的几个评估指标ROC,PD_FA等。
下周计划:学习DNA-Net论文中的特征提取模块密集嵌套交互模块(DNIM), 特征金字塔融合模块(FPFM),八连通邻域聚类算法。
目录
论文地址:
https://arxiv.org/pdf/2106.00487
代码地址:
https://github.com/YeRen123455/Infrared-Small-Target-Detection
损失函数
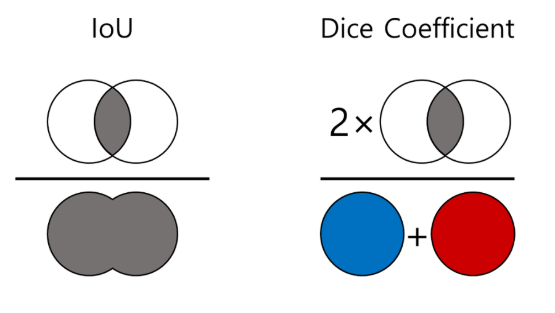
如上图所示,IoU与Dice的计算公式分别为:
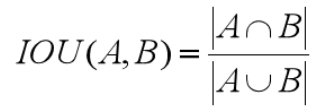
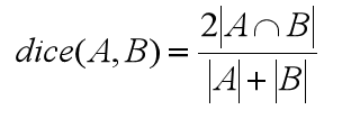
DNA-Net的代码中,计算IoU的代码如下,值得注意的是为了防止分母为0引起错误,在代码中给分子分母都加上了一个常数,这里取1。关于与pred与target的形状,pred与target形状一致,而target由DataLoader类的一个实例产生(在后文数据集处理部分会详细介绍),形状为(4, 1, 256, 256)。
def SoftIoULoss( pred, target):
pred = torch.sigmoid(pred)
smooth = 1
# smooth 是一小的常数,用于防止分母为零。
# 如果预测和真实标签都为空(所有像素都为0),那么分母会是0,导致计算错误。
# smooth 保证了分母和分子至少为1,增加了计算的稳定性。
intersection = pred * target
# target (即 labels) 的值是 0. 或 1。黑色为0,白色为1,观察mask图像可知白色(1)为真实前景,黑色(0)为真实背景
# 当 target 像素为 1(真实前景) 时,intersection = pred 的概率值。(1 x any = any)
# 当 target 像素为 0 (真实背景) 时,intersection = 0。 (0 x any = 0)
# 所以,`intersection` 张量在真实前景区域的值是模型的预测概率,在背景区域是0。
loss = (intersection.sum() + smooth) / (pred.sum() + target.sum() -intersection.sum() + smooth)
loss = 1 - loss.mean()
# IOU是一个度量指标,值越大越好(最大为1)。而损失函数需要越小越好(最小为0)。 最简单的转换方法就是用 `1 - IoU`。
# 如果 IoU 接近 1 (完美匹配),损失 `1 - IoU` 就接近 0。
# 如果 IoU 接近 0 (完全不匹配),损失 `1 - IoU` 就接近 1。
# 这样,通过最小化这个 `loss`,我们就能最大化 Soft IoU,从而让模型的预测结果更接近真实标签。
return lossDice实质上就是图像领域的F1-Score。
分割损失:Dice vs. IoU - BimAnt文中提到 “从定义中,我们注意到 Dice 系数扩大了分母和分子中重叠的权重,基于糖水不等式,如果重叠增加,Dice 损失将以更大的梯度流信息做出响应,从而促进更精确的分割。在医学图像中,如细胞病理学成像,通常细胞本身占据图像的大部分,如果使用 IoU 损失,网络可能会选择将整个图像预测为正,并且仍然产生不错的性能,这将使进一步的学习变得困难。 如果使用 Dice 损失,损失定义中的重叠权重会增加,因此网络将被激励去分割细胞,而不是学习一些像 IoU 损失中的情况那样的启发式方法。” 红外小目标检测也是同理,https://zhuanlan.zhihu.com/p/542645626文中作者在DNA-Net使用Dice作为损失函数替代IoU,结果复现出的结果高于原文的实验结果,也说明了Dice作为损失函数在小目标分割较IoU更加有效。下面为仿照文中IoU损失函数的一个Dice损失函数。
def DiceLoss(pred, target):
"""
Dice Loss 函数。
Args:
pred (torch.Tensor): 模型的预测输出,形状为 (B, 1, H, W)。通常是未经激活的 logits。
target (torch.Tensor): 真实的标签掩码,形状为 (B, 1, H, W)。值为 0.0 或 1.0。
Returns:
torch.Tensor: 计算出的 Dice Loss,一个标量。
"""
# 1. 将模型的原始输出转换为概率
pred = torch.sigmoid(pred)
# 2. 定义平滑系数,防止分母为零
smooth = 1.0
# 3. 计算交集 (Intersection)
# pred * target 会逐元素相乘。因为 target 中背景是0,前景是1,
# 所以这个操作有效地将 pred 中对应背景区域的概率清零,只保留前景区域的概率。
intersection = (pred * target).sum()
# 4. 计算 Dice 系数
# Dice 系数的公式是:(2 * |A ∩ B|) / (|A| + |B|)
# |A| 在这里是 pred.sum(),|B| 是 target.sum()
dice_coeff = (2. * intersection + smooth) / (pred.sum() + target.sum() + smooth)
# 5. 将 Dice 系数转换为损失函数
# Dice 系数是相似度度量,值越大越好(最大为1)。
# 损失函数需要越小越好(最小为0),所以用 1 - dice_coeff。
loss = 1 - dice_coeff
return loss数据集处理
为了能直观看到数据集处理中数据流与张量形状,这里把作者项目中有关代码抽离出到一个ipynb格式的文件进行推演。
# 1.先要能定位到每一对image和mask,已知每一对image和mask名称相同(这样就不用在代码中将每对image和mask联系起来),仅文件路径不同,事先准备了一个TXT文本记录了所有image的名称(对应的mask名称相同)。可以将所有图片对名称封装到一个列表里方便读取def load_dataset (root, dataset, split_method):
train_txt = root + '/' + dataset + '/' + split_method + '/' + 'train.txt'
test_txt = root + '/' + dataset + '/' + split_method + '/' + 'test.txt'
train_img_ids = []
val_img_ids = []
with open(train_txt, "r") as f:
line = f.readline()
while line:
train_img_ids.append(line.split('\n')[0])
line = f.readline()
f.close()
with open(test_txt, "r") as f:
line = f.readline()
while line:
val_img_ids.append(line.split('\n')[0])
line = f.readline()
f.close()
return train_img_ids,val_img_ids,test_txt
train_img_ids, val_img_ids, test_txt = load_dataset("dataset","NUDT-SIRST","50_50")
load_dataset("dataset","NUDT-SIRST","50_50")
#成功得到记录所有图片对的名称,顺便记录一下记录文件路径,这里一个名称实际上表示的一个图片对,如dataset/NUDT-SIRST/images/001137与dataset/NUDT-SIRST/masks/001137
(['001137',
'000345',
'000774',
'000593',
'001002',
'001024',
'001204',
'000683',
'000353'],
'dataset/NUDT-SIRST/50_50/test.txt')
#2.接下来就可以定义dataset了,功能就类似一个加工厂,定义每一项原料的加工流程(上一步已经获取了原料的地址)
from PIL import Image, ImageOps, ImageFilter
import platform, os
from torch.utils.data.dataset import Dataset
import random
import numpy as np
import torch
from torch.nn import init
from datetime import datetime
import argparse
import shutil
from matplotlib import pyplot as plt
from torchvision import transforms
class TrainSetLoader(Dataset):
"""Iceberg Segmentation dataset."""
NUM_CLASS = 1
def __init__(self, dataset_dir, img_id ,base_size=512,crop_size=480,transform=None,suffix='.png'):
super(TrainSetLoader, self).__init__()
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([.485, .456, .406], [.229, .224, .225])])
self._items = img_id
self.masks = dataset_dir+'/'+'masks'
self.images = dataset_dir+'/'+'images'
self.base_size = base_size
self.crop_size = crop_size
self.suffix = suffix
def _sync_transform(self, img, mask):
# random mirror
if random.random() < 0.5:
img = img.transpose(Image.FLIP_LEFT_RIGHT)
mask = mask.transpose(Image.FLIP_LEFT_RIGHT)
crop_size = self.crop_size
# random scale (short edge)
long_size = random.randint(int(self.base_size * 0.5), int(self.base_size * 2.0))
w, h = img.size
if h > w:
oh = long_size
ow = int(1.0 * w * long_size / h + 0.5)
short_size = ow
else:
ow = long_size
oh = int(1.0 * h * long_size / w + 0.5)
short_size = oh
img = img.resize((ow, oh), Image.BILINEAR)
mask = mask.resize((ow, oh), Image.NEAREST)
# pad crop
if short_size < crop_size:
padh = crop_size - oh if oh < crop_size else 0
padw = crop_size - ow if ow < crop_size else 0
img = ImageOps.expand(img, border=(0, 0, padw, padh), fill=0)
mask = ImageOps.expand(mask, border=(0, 0, padw, padh), fill=0)
# random crop crop_size
w, h = img.size
x1 = random.randint(0, w - crop_size)
y1 = random.randint(0, h - crop_size)
img = img.crop((x1, y1, x1 + crop_size, y1 + crop_size))
mask = mask.crop((x1, y1, x1 + crop_size, y1 + crop_size))
# gaussian blur as in PSP
if random.random() < 0.5:
img = img.filter(ImageFilter.GaussianBlur(
radius=random.random()))
# final transform
img, mask = np.array(img), np.array(mask, dtype=np.float32)
return img, mask
def __getitem__(self, idx):
img_id = self._items[idx] # idx:('../SIRST', 'Misc_70') 成对出现,因为我的workers设置为了2
img_path = self.images+'/'+img_id+self.suffix # img_id的数值正好补了self._image_path在上面定义的2个空
label_path = self.masks +'/'+img_id+self.suffix
img = Image.open(img_path).convert('RGB') ##由于输入的三通道、单通道图像都有,所以统一转成RGB的三通道,这也符合Unet等网络的期待尺寸
mask = Image.open(label_path)
# synchronized transform
img, mask = self._sync_transform(img, mask)
# general resize, normalize and toTensor
if self.transform is not None:
img = self.transform(img)
mask = np.expand_dims(mask, axis=0).astype('float32')/ 255.0
return img, torch.from_numpy(mask) #img_id[-1]
def __len__(self):
return len(self._items)
trainset= TrainSetLoader(dataset_dir="dataset/NUDT-SIRST",img_id=train_img_ids,base_size=256,crop_size=256,transform=None,suffix=".png") #256是图片尺寸
trainset
# 加工厂成功建立,原作者把transforms向量化的工序放在外面当参数给工厂,而这里直接在工厂内部定义transforms向量化的工序# 3.有了每个图片对的加工的方法,接下来就可以建立一个实际的可迭代对象实现批量获取原料加工成的成品
DataLoader就是一个高效的“商人+调度系统”。它从Dataset中取数据,然后把它们打包成批次(batch)。
数据流:图片文件夹->Dataset->DataLoader 就是dataloader向Dataset提出订单,Dataset把图片文件夹的数据加工一下给dataloader
dataloader 的优点是可以多线程,打乱,多批次
from torch.utils.data import DataLoader
train_data = DataLoader(dataset=trainset, batch_size=4, shuffle=True, num_workers=0,drop_last=True)
train_data
#DataLoader是一个 Python 的可迭代对象 (iterable)。
<torch.utils.data.dataloader.DataLoader at 0x24c30298790>看看可迭代对象 dataloader的内容
import torch
from torch.utils.data import DataLoader
if __name__ == '__main__':
for batch_idx, batch in enumerate(train_data):
if isinstance(batch, (list, tuple)):
images, labels = batch
# 打印批次索引
print(f"Batch {batch_idx}:")
# 打印images的形状和类型(
print(f"Images shape: {images.shape}")
print(f"Images type: {type(images)}")
print(f"Images data (first few elements): {images[:2]}") # 只打印前2个样本,避免输出太大
# 打印labels的内容
print(f"Labels: {labels}")
print(f"Labels shape: {labels.shape}")
else:
# 如果batch不是元组(例如,如果trainset只返回一个元素)
print(f"Batch {batch_idx}: {batch}")
# 添加一个分隔线,便于阅读
print("-" * 50)

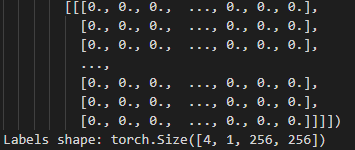
可以看出images张量的大小为(4,3,256,256),label(就是损失函数部分提到的target)张量的大小为(4,1,256,256)。前者将作为输入进入网络,后者将与网络输出计算损失函数。此外,可以通过tbar = tqdm(dataloader)为可迭代对象 dataloader加一个进度条。
评估指标
接下来将用几个语义分割的实例来介绍一下ROC,PD_FA是如何计算的。
ROC
ROC 曲线展示了在不同阈值下,真阳性率 (TPR) 与 假阳性率 (FPR) 之间的关系,是评估二分类模型性能的重要工具。就是在pred中,大于阈值认为模型将像素预测为阳性,小于认为模型将像素预测为阴性。具体定义可以参考:【官方双语】ROC & AUC 详细解释!_哔哩哔哩_bilibili。只看定义不太直观,直接结合作者的代码来推演一个例子:
假设我们有一个 5x5 的图像。模型的目标是分割出图像中的一个物体。
1. 真实标签 (labels)
这是一个 (1, 1, 5, 5) 的张量,代表一个批次中只有一张图。图中有一个 2x2 的正方形物体。1 代表前景(物体),0 代表背景。
[[0, 0, 0, 0, 0],
[0, 1, 1, 0, 0],
[0, 1, 1, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]
真实前景像素数 (total_label): 4
2. 模型预测 (preds)
这是模型输出的 (1, 1, 5, 5) 张量。这是 Sigmoid 后的概率,值越高代表模型越确信是前景。
[[0.1, 0.2, 0.1, 0.0, 0.0],
[0.1, 0.9, 0.8, 0.6, 0.1], <- 注意这里有个假阳性 (0.6)(如果阈值为0.5)
[0.2, 0.8, 0.4, 0.1, 0.0], <- 注意这里有个假阴性 (0.4)(如果阈值为0.5)
[0.1, 0.1, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0]]
class ROCMetric():
"""Computes pixAcc and mIoU metric scores
"""
def __init__(self, nclass, bins): #bin的意义实际上是确定ROC曲线上的threshold取多少个离散值
super(ROCMetric, self).__init__()
self.nclass = nclass
self.bins = bins
self.tp_arr = np.zeros(self.bins+1)
self.pos_arr = np.zeros(self.bins+1)
self.fp_arr = np.zeros(self.bins+1)
self.neg_arr = np.zeros(self.bins+1)
self.class_pos=np.zeros(self.bins+1)
# self.reset()
def update(self, preds, labels):
for iBin in range(self.bins+1):
score_thresh = (iBin + 0.0) / self.bins
# print(iBin, "-th, score_thresh: ", score_thresh)
i_tp, i_pos, i_fp, i_neg,i_class_pos = cal_tp_pos_fp_neg(preds, labels, self.nclass,score_thresh)
self.tp_arr[iBin] += i_tp
self.pos_arr[iBin] += i_pos
self.fp_arr[iBin] += i_fp
self.neg_arr[iBin] += i_neg
self.class_pos[iBin]+=i_class_pos
def get(self):
tp_rates = self.tp_arr / (self.pos_arr + 0.001)
fp_rates = self.fp_arr / (self.neg_arr + 0.001)
recall = self.tp_arr / (self.pos_arr + 0.001)
precision = self.tp_arr / (self.class_pos + 0.001)
return tp_rates, fp_rates, recall, precision第1步: update 方法被调用
roc_metric.update(preds, labels)-
进入大循环:
for iBin in range(self.bins+1):。假设bins=10,这个循环会执行11次,score_thresh会从0.0,0.1, ...,1.0变化。我们看三个阈值。-
Case 1:
score_thresh = 0.3[[0, 0, 0, 0, 0],
[0, 1, 1, 1, 0],
[0, 1, 1, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]predict = (torch.sigmoid(output) > 0.3).float()Binarized Pred(所有 > 0.3 的都为1):- 与
labels对比,计算 TP, FP, TN, FN:- TP (真阳性): 预测=1, 标签=1 -> 3 个
- FP (假阳性): 预测=1, 标签=0 -> 2 个
- FN (假阴性): 预测=0, 标签=1 -> 1 个
- TN (真阴性): 预测=0, 标签=0 -> 19 个
统计结果:self.tp_arr[3] += 3,self.fp_arr[3] += 2, ...
-
Case 2:
score_thresh = 0.7Binarized Pred(所有 > 0.7 的都为1):[[0, 0, 0, 0, 0],
[0, 1, 1, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]- 计算 TP, FP, TN, FN:
- TP: 3 个
- FP: 0 个
- FN: 1 个
- TN: 21 个
统计结果:self.tp_arr[7] += 3,self.fp_arr[7] += 0, ...
-
Case 3:
score_thresh = 0.95Binarized Pred(所有 > 0.9的都为1):全0矩阵- 计算 TP, FP, TN, FN:
- TP: 0 个
- FP: 0 个
- FN: 4 个
- TN: 21 个
统计结果:self.tp_arr[10] += 0,self.fp_arr[10] += 0, ...
-
第2步: get 方法被调用
- 计算 TPR 和 FPR 数组:
tp_rates = self.tp_arr / (self.pos_arr + 0.001)(TPR = TP / (TP+FN))fp_rates = self.fp_arr / (self.neg_arr + 0.001)(FPR = FP / (FP+TN))
- 得到数据点:
- 对于阈值 0.3: TPR = 3/4 = 0.75; FPR = 2/21 ≈ 0.095 -> 点 (0.095, 0.75)
- 对于阈值 0.7: TPR = 3/4 = 0.75; FPR = 0/21 = 0 -> 点 (0, 0.75)
- 对于阈值 0.9: TPR = 0/4 = 0; FPR = 0/21 = 0 -> 点 (0, 0)
PD_FA
- PD (探测概率): 有多少真实的目标被成功检测出来了?
- FA (虚警/误报): 模型检测出了多少不存在的假目标?
PD_FA评估物体级别的检测能力。它不关心像素是否完美对齐,而是关心整个物体是否被找到。
为了更好地展示,我们换一个稍微复杂的实例。
labels: 有两个独立的 1x1 小物体。
[[0, 0, 0, 0, 0],
[0, 1, 0, 0, 0], <- 物体1
[0, 0, 0, 0, 0],
[0, 0, 0, 1, 0], <- 物体2
[0, 0, 0, 0, 0]]
preds (概率): 模型找到了物体1,错过了物体2,并在一个新地方产生了一个假物体。
[[0.1, 0.1, 0.8, 0.7, 0.1], <- 假物体
[0.1, 0.9, 0.1, 0.1, 0.1], <- 找到物体1
[0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.1, 0.1, 0.2, 0.1], <- 错过物体2
[0.1, 0.1, 0.1, 0.1, 0.1]]
第1步: update 方法被调用 (只看 score_thresh = 0.5 这一个循环)
-
二值化:
predits = np.array((preds > 0.5).cpu()).astype('int64')- [[0, 0, 1, 1, 0], <- 假物体
[0, 1, 0, 0, 0], <- 找到的物体
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]
- [[0, 0, 1, 1, 0], <- 假物体
-
寻找连通区域 :
label = measure.label(labelss): 在labels上找到2个独立的物体。coord_label列表里有2个RegionProperties对象。- 真实物体1: 质心
(1, 1) - 真实物体2: 质心
(3, 3)
- 真实物体1: 质心
image = measure.label(predits): 在Binarized Pred上也找到2个独立的物体。coord_image列表里有2个RegionProperties对象。- 预测物体A: 质心
(0, 2.5)(由 (0,2) 和 (0,3) 组成) - 预测物体B: 质心
(1, 1)
- 预测物体A: 质心
-
匹配物体: 循环遍历真实物体,看有没有预测物体的质心离它足够近 (
distance < 3)。- 检查真实物体1 (质心
(1,1)):- 和预测物体A (
(0, 2.5)) 距离 > 3。 - 和预测物体B (
(1,1)) 距离 = 0。匹配成功 self.distance_match列表增加一个元素。- 从
coord_image中删除预测物体B,防止它被重复匹配。
- 和预测物体A (
- 检查真实物体2 (质心
(3,3)):- 和剩下的预测物体A (
(0, 2.5)) 距离 > 3。匹配失败!
- 和剩下的预测物体A (
- 检查真实物体1 (质心
-
计算当前批次的 PD 和 FA:
- PD (探测数):
self.PD[iBin] += len(self.distance_match)->self.PD[5] += 1。 - Target (目标总数):
self.target[iBin] += len(coord_label)->self.target[5] += 2。 - FA (虚警面积):
self.dismatch是那些没有匹配上的预测物体。这里是预测物体A。coord_image[K].area获取它的面积,为2。self.FA[iBin] += np.sum(self.dismatch)->self.FA[5] += 2。
- PD (探测数):
第2步: get 方法被调用
- 计算最终 PD 和 FA:
Final_PD = self.PD / self.target->Final_PD[5] = 1 / 2 = 0.5Final_FA = self.FA / ((256 * 256) * img_num)->Final_FA[5] = 2 / (25 * 1)= 0.08
结论: 在阈值为0.5时,模型的探测概率是50%(找到了2个真实物体中的1个),虚警率是8%(虚警像素占了总面积的8%)。
还注意到作者定义了losses来计算整个epoch的损失。
losses = AverageMeter()class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
更多推荐


 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)