
深度学习6——Convolutional Neural Network
目录
一、为什么用CNN处理图像?
假设有一张100x100的彩色图像,那么它一共有100x100x3个维度,如果将该图像作为输入,有3w个输入值,这实在是太多了,那么CNN就是用来将这个过程的模型进行简化的:
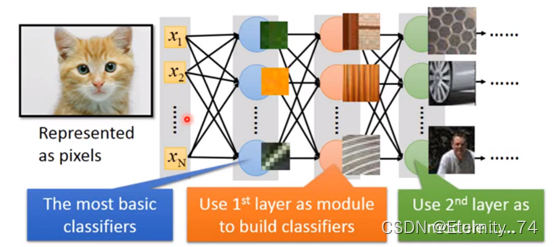
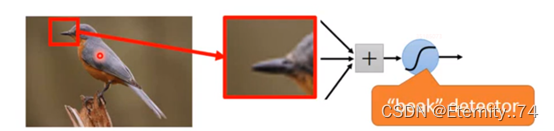
首先,因为有些图案比整个图像小得多,并且神经元不必看到整个图像就能发现形状是什么。假设有一个神经元要检测一张图上是否有鸟嘴,那么它不需要看整张图片,只需要看有鸟嘴的图案即可:
其次,如果有两个相同的形状出现在不同的区域内,那么只需要训练一个神经元,让它们共享同一组参数即可:

最后,我们可以对图像进行二次采样,从而使得它变得更小,这样就可以减少需要用到的参数:

二、CNN完整的架构
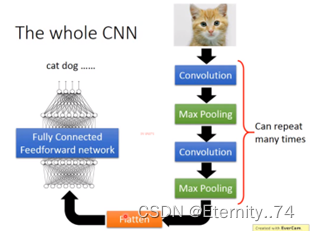
1、Convolution
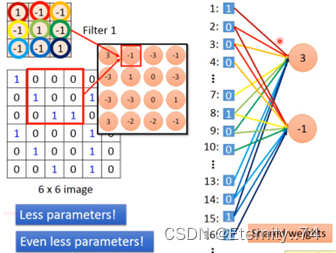
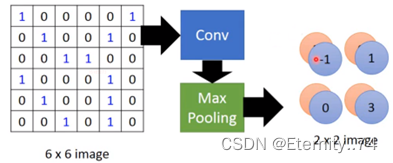
假设现在有一张6x6的图像,并且有一个过滤器(filter):
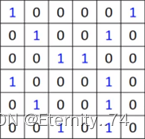
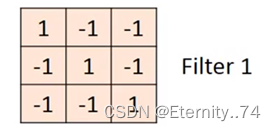
然后用这个过滤器与这张图像的值做内积,先和前三个做内积,再往后移,以此内推:
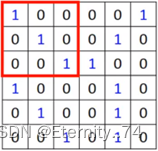
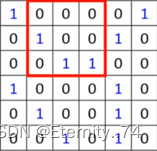
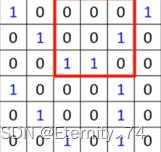
从而得到的内积值为:
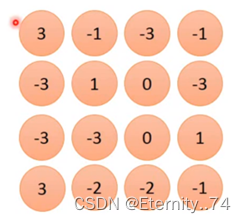
最大值出现在左上角和左下角,因此该过滤器侦测出的值在左上角和左下角。
如果有其它过滤器,那么可以得到新的内积值,称之为特征映射(feature map)。
其实convolution就是fully-connected去掉一些weight的结果:
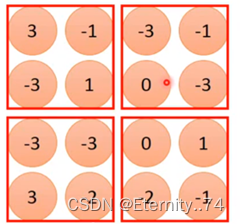
2、Max Pooling
选择特征映射中每四个一组的最大值,使4个值变成1个值:
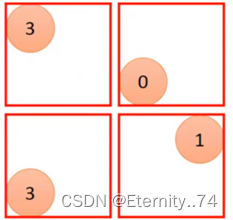
所以一张6x6的图像经过Convolution和Max Polling后变成了一个新的2x2的图像:
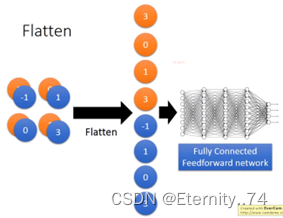
3、Flatten
把特征映射的值拉直后,将其放进Fully-Connected的正反馈网络中即可:
三、CNN学到了什么?
首先列出第K个过滤器的11x11的矩阵输出值:
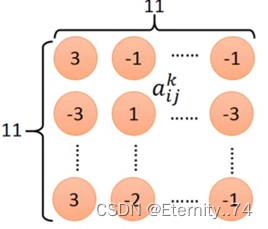
然后计算第K个过滤器的活化程度:
最后寻找一个输入值 ,使得
的值最大,可使用梯度下降法:
四、Deep Dream
如果给机器一张图片,那么机器会添加一些它所看到的东西,比如将一张图片放进CNN,得到一列过滤器的值:
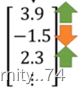
那么机器会夸大这个值,比如将正值变得更大,把负值变得更小。
所以如果当图片里有块石头很像一头熊,那么机器就会将其变成一头熊:


更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)