
「日拱一码」062 深度学习——循环神经网络RNNs
深度学习——循环神经网络RNNs
·
目录
循环神经网络(Recurrent Neural Networks, RNNs)是一类专门用于处理序列数据的神经网络,它具有"记忆"能力,能够捕捉数据中的时序依赖关系
特点
- 时序处理能力:可以处理任意长度的序列数据
- 参数共享:在不同时间步共享相同的权重参数
- 记忆机制:通过隐藏状态(hidden state)保留历史信息
- 循环连接:网络中存在反馈连接,形成循环结构
基本结构
RNN的基本单元在每个时间步t执行以下计算:
- 输入:当前时间步的输入xₜ和前一时间步的隐藏状态hₜ₋₁
- 输出:当前时间步的隐藏状态hₜ和可能的预测输出yₜ
数学表达式:
hₜ = σ(Wₕₕ hₜ₋₁ + Wₓₕ xₜ + bₕ)
yₜ = Wₕᵧ hₜ + bᵧ
其中σ是激活函数(如tanh),W表示权重矩阵,b表示偏置项
RNN的常见变体
- 简单RNN(vanilla RNN):基本循环结构
- 长短期记忆网络(LSTM):解决长程依赖问题,引入门控机制
- 门控循环单元(GRU):LSTM的简化版本,计算效率更高
- 双向RNN(Bi-RNN):同时考虑前向和后向的序列信息
代码示例
示例1:简单RNN实现字符级文本生成
# 1. 简单RNN实现字符级文本生成
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, SimpleRNN
from tensorflow.keras.models import Sequential
# 准备数据
text = "hello world" # 示例文本
chars = sorted(list(set(text)))
char_to_idx = {c: i for i, c in enumerate(chars)}
idx_to_char = {i: c for i, c in enumerate(chars)}
# 创建训练样本
maxlen = 5 # 序列长度
step = 1 # 滑动步长
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i:i + maxlen])
next_chars.append(text[i + maxlen])
# 向量化
X = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool_)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool_)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
X[i, t, char_to_idx[char]] = 1
y[i, char_to_idx[next_chars[i]]] = 1
# 构建简单RNN模型
model = Sequential([
SimpleRNN(32, input_shape=(maxlen, len(chars))),
Dense(len(chars), activation='softmax')
])
model.compile(loss='categorical_crossentropy', optimizer='adam')
# 训练模型
model.fit(X, y, batch_size=16, epochs=100, verbose=1)
# 文本生成函数
def generate_text(seed, length=10):
generated = seed
for _ in range(length):
x = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(generated[-maxlen:]):
x[0, t, char_to_idx[char]] = 1
preds = model.predict(x, verbose=0)[0]
next_idx = np.argmax(preds)
next_char = idx_to_char[next_idx]
generated += next_char
return generated
# 测试生成
print(generate_text("hello", 10))
# hello world wor示例2:LSTM实现时间序列预测
# 2. LSTM实现时间序列预测
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 生成正弦波时间序列数据
def generate_time_series(batch_size, n_steps):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, batch_size, 1)
time = np.linspace(0, 1, n_steps)
series = 0.5 * np.sin((time - offsets1) * (freq1 * 10 + 10)) # 波形1
series += 0.2 * np.sin((time - offsets2) * (freq2 * 20 + 20)) # 波形2
series += 0.1 * (np.random.rand(batch_size, n_steps) - 0.5) # 噪声
return series[..., np.newaxis].astype(np.float32)
# 数据参数
n_steps = 50
series = generate_time_series(10000, n_steps + 1)
# 划分训练集和测试集
X_train, y_train = series[:7000, :n_steps], series[:7000, -1]
X_valid, y_valid = series[7000:9000, :n_steps], series[7000:9000, -1]
X_test, y_test = series[9000:, :n_steps], series[9000:, -1]
# 构建LSTM模型
model = Sequential([
LSTM(32, return_sequences=True, input_shape=[None, 1]),
LSTM(32),
Dense(1)
])
model.compile(loss="mse", optimizer="adam")
# 训练模型
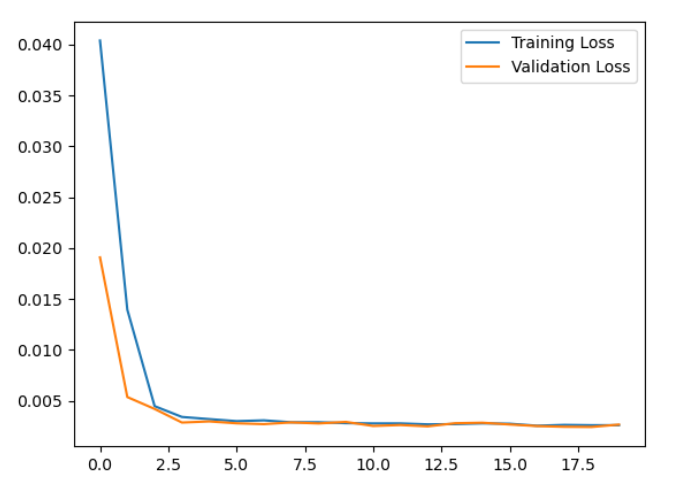
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
# 绘制训练曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
plt.show()
# 预测示例
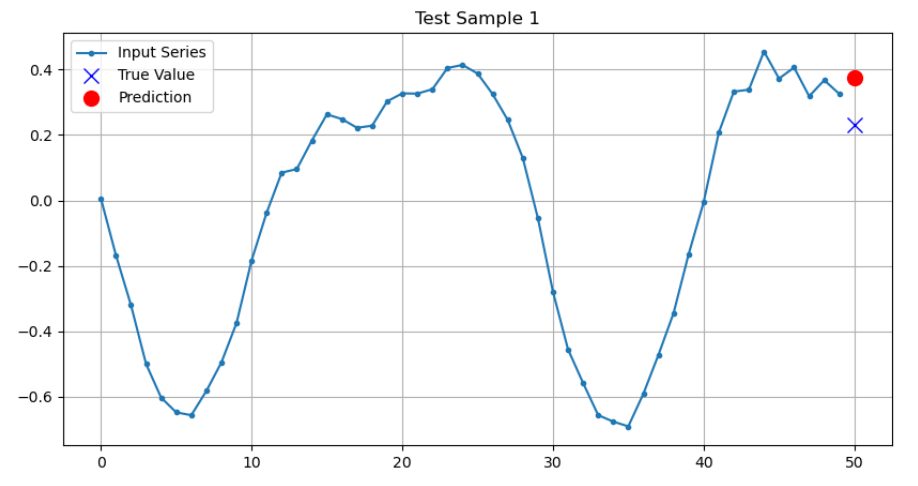
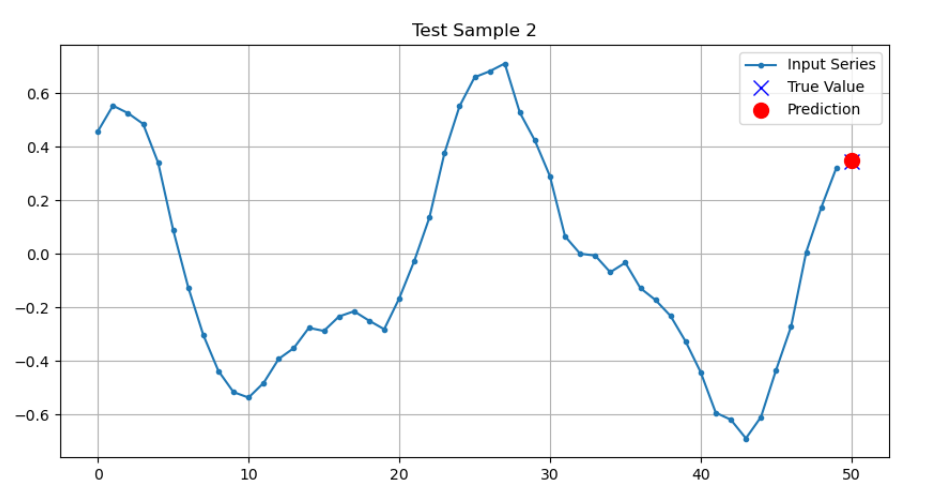
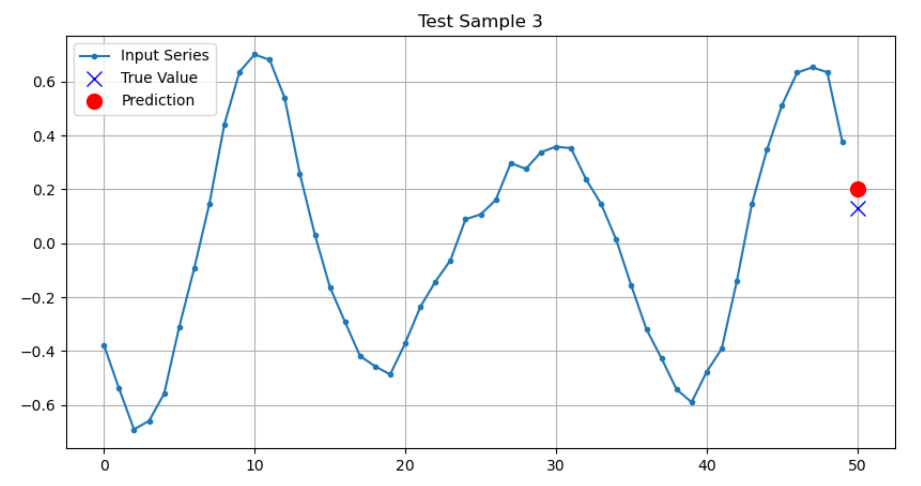
def plot_series(series, y_true, y_pred=None):
plt.plot(series, ".-", label="Input Series")
plt.plot(n_steps, y_true, "bx", markersize=10, label="True Value")
if y_pred is not None:
plt.plot(n_steps, y_pred, "ro", markersize=10, label="Prediction")
plt.grid(True)
plt.legend()
# 测试集预测
y_pred = model.predict(X_test)
# 可视化几个预测结果
for i in range(3):
plt.figure(figsize=(10, 5))
plot_series(X_test[i, :, 0], y_test[i, 0], y_pred[i, 0])
plt.title(f"Test Sample {i+1}")
plt.show()
示例3:双向GRU实现情感分析
# 3. 双向GRU实现情感分析
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.layers import Embedding, Bidirectional, GRU, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.sequence import pad_sequences
import matplotlib.pyplot as plt
import numpy as np
imdb_path = "imdb.npz"
# 加载IMDB电影评论数据集
max_features = 10000 # 词汇表大小
maxlen = 200 # 每条评论保留的单词数
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.imdb.load_data(
path=imdb_path,
num_words=10000
)
# 填充/截断序列
X_train = pad_sequences(X_train, maxlen=maxlen)
X_test = pad_sequences(X_test, maxlen=maxlen)
# 构建双向GRU模型
model = Sequential([
Embedding(max_features, 128),
Bidirectional(GRU(64, dropout=0.2, recurrent_dropout=0.2)),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 训练模型
history = model.fit(X_train, y_train,
batch_size=32,
epochs=5,
validation_data=(X_test, y_test))
# 评估模型
score, acc = model.evaluate(X_test, y_test, batch_size=32)
print(f"测试集准确率: {acc:.4f}")
# 绘制训练曲线
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Loss')
plt.legend()
plt.show()
# 预测示例
word_index = imdb.get_word_index()
reverse_word_index = {v: k for k, v in word_index.items()}
def decode_review(encoded_review):
return ' '.join([reverse_word_index.get(i - 3, '?') for i in encoded_review])
# 随机选择几条评论进行预测
for i in np.random.randint(0, len(X_test), 3):
review = X_test[i:i+1]
pred = model.predict(review)[0][0]
true_label = y_test[i]
print(f"\n评论: {decode_review(review[0])}")
print(f"预测情感: {'正面' if pred > 0.5 else '负面'} ({pred:.4f})")
print(f"真实情感: {'正面' if true_label == 1 else '负面'}")
# 评论: ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? think ? but with a death curse a bunch of ? ? get their hands on a game that takes the life of some one who is playing it supposedly it was made from the skin of a witch during the spanish ? and carries a nasty curse br br okay ? and just sort of watchable tale isn't anything you haven't seen before frankly its a been there and done that story that hits all the right buttons in such away as to have no real surprises far from the worst thing that ? has run but certainly its not the best there are better choices out there but if this is your only choice you won't completely hate it
# 预测情感: 负面 (0.0035)
# 真实情感: 负面
#
# 评论: ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? a notorious big budget flop when released this robert altman inspired comedy has some terrific moments and an occasionally inspired cast although it goes on to long an loses its focus completely there are enough funny moments that will keep a curious viewer watching until the end if you are a fan of character actors and actresses this will be a treat for you you will recognize so many terrific little known performers throughout this movie you may not know their names but you know their faces heck even the kid from a christmas story turns up in a small part rent if from netflix if you read this i bet you will enjoy it
# 预测情感: 正面 (0.9929)
# 真实情感: 正面
#
# 评论: oh boy on the cover of worn out vhs has a picture of sandra ? and her name written on top i think only reason they had chance to sell the movie in nineties was because of sandra ? name ? fans don't have to disappoint sandra is only thing to watch in this movie and her performance is the only you can call acting rest of the ? it's fun to watch in first fifteen minutes because it's bad but after that it's going worse much worse directing is awful acting is awful script is awful dialog is awful action is awful music is quite good actually typical score for eighties action movies this movie is so bad that it goes close to anything andy ? has ever produced it's so bad that there isn't proper word to describe this poor attempt to be a movie but still there was sandra ? and super cool sarcasm jake who tried to be marlon brando br br i think they can now bring the film out on dvd it could be cool and they should write on the cover academy award winner sandra ? in br br 1 out of 10
# 预测情感: 负面 (0.1788)
# 真实情感: 负面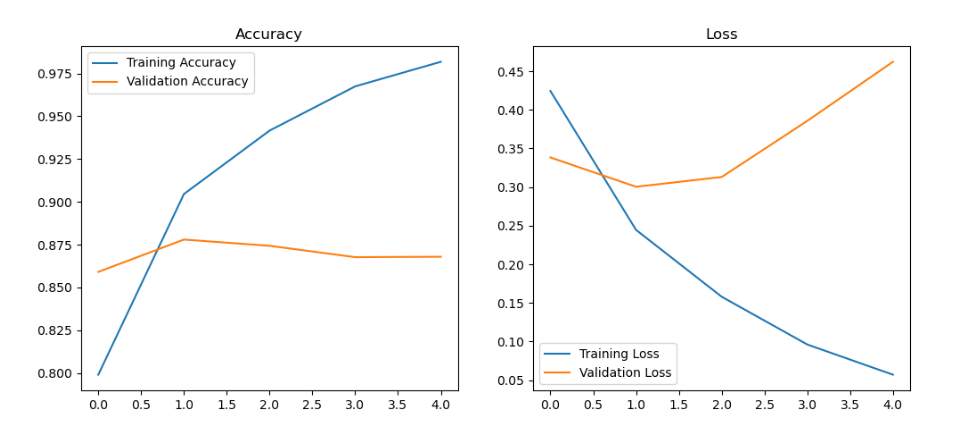
应用场景
-
自然语言处理(NLP):
- 机器翻译
- 文本生成
- 情感分析
- 命名实体识别
-
时间序列分析:
- 股票价格预测
- 天气预测
- 传感器数据分析
-
语音处理:
- 语音识别
- 语音合成
- 语音情感分析
-
其他序列数据:
- 视频分析
- 手写识别
- 基因组序列分析
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)