
【计算机视觉】【语义分割】基于深度学习的道路场景图像语义分割总结!
深度学习(Deep Learning, DL)的概念由Hinton等在2006年提出,其通过多层结构的表征学习方法显著提升了计算机视觉任务的性能。CNN(卷积神经网络)作为处理图像数据的主流深度学习模型,经历了从LeNet-5、AlexNet到ResNet的快速发展。这些网络的出现,为语义分割任务注入了强大的性能支持。
基于深度学习的道路场景图像语义分割总结
深度学习的引入背景
深度学习(Deep Learning, DL)的概念由Hinton等在2006年提出,其通过多层结构的表征学习方法显著提升了计算机视觉任务的性能。CNN(卷积神经网络)作为处理图像数据的主流深度学习模型,经历了从LeNet-5、AlexNet到ResNet的快速发展。这些网络的出现,为语义分割任务注入了强大的性能支持。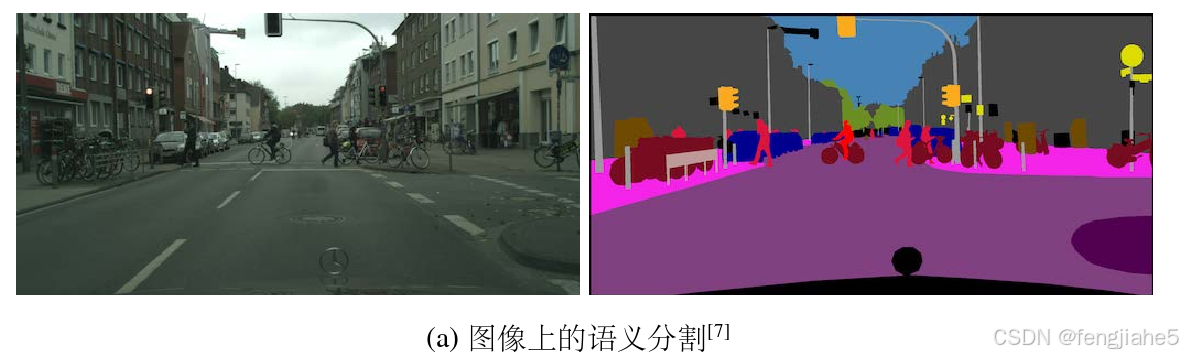
语义分割任务的目标是对每个像素进行分类,并预测其语义类别。在深度学习的推动下,语义分割逐渐摆脱传统方法的限制,实现了高效、准确的端到端训练。
1. 图像语义分割的发展
1.1 全卷积神经网络(FCN)
- 背景:在全卷积神经网络(FCN)出现之前,语义分割依赖复杂的预处理(如超像素、检测建议等),并通过随机场或局部分类器优化。这种方法效率较低,难以扩展。
- 创新点:加州大学伯克利分校的Long等人提出了FCN,实现了任意大小图像的输入与端到端训练。
- 特性:
- 将图像识别网络权重迁移至语义分割网络。
- 融合不同层的特征表示。
- 对整幅图像高效训练和推理。
- 贡献:极大提升了语义分割的性能,并奠定了后续改进的基础。
- 特性:
1.2 编码-解码架构的优化
语义分割可被视为编码与解码的过程:
- 编码器:逐步降低特征分辨率,捕获高层语义特征。
- 解码器:逐步恢复空间信息,推理每个像素的语义类别。
1.2.1 SegNet
- 提出者:剑桥大学。
- 特点:解码器使用编码器池化层计算的索引进行非线性上采样,无需学习上采样。
- 优势:提高计算效率。
1.2.2 UNet
- 提出者:弗赖堡大学。
- 背景:生物医学图像中的训练数据较少。
- 特点:U形结构;解码器在上采样过程中保留较大的特征通道,增强上下文信息传递。
- 应用:少量数据下的训练任务。
1.3 特征分辨率的提升
高分辨率特征对于捕获上下文信息至关重要,但降采样会丢失大量细节信息。
1.3.1 空洞卷积(Atrous Convolution)
- 提出者:Chen等和Yu等。
- 思想:
- 在标准卷积的采样网格中引入空洞,扩大感受野。
- 减少池化层使用,降低细节损失。
- 挑战:多层空洞卷积易引发“网格效应”(Gridding Effect)。
- 改进:
- 图森未来提出了混合扩张卷积,以锯齿波形式分配扩张率。
- 微软亚洲研究院提出可变形卷积(Deformable Convolution),使采样网格位置可学习。
1.4 多尺度与多层级特征的融合
1.4.1 ASPP(空洞空间金字塔池化)
- 提出者:谷歌(DeepLab系列)。
- 特点:通过多扩张率的空洞卷积并行捕获多尺度特征。
1.4.2 金字塔池化模块(Pyramid Pooling Module, PPM)
- 提出者:香港中文大学与商汤科技(PSPNet)。
- 设计:结合全局池化和局部池化,集成全局与局部上下文信息。
1.4.3 Hypercolumn
- 提出者:加州大学伯克利分校。
- 思想:将CNN不同层的特征融合,用于增强语义分割的多层次表现。
2. 实时语义分割方法
自动驾驶等嵌入式平台需要平衡语义分割的精度与速度。
2.1 ERFNet
- 提出者:西班牙阿尔卡拉大学。
- 特点:分解卷积提升实时性,同时保留较高的分割精度。
2.2 ICNet
- 提出者:香港中文大学与商汤科技。
- 特点:基于压缩版PSPNet设计。
- 低分辨率图像:输入高复杂度模型。
- 高分辨率图像:输入低复杂度模型。
- 特征融合:集成高低分辨率特征。
2.3 BiSeNet
- 提出者:旷视科技。
- 特点:
- 设计空间分支(Spatial Path)保留空间信息。
- 上下文分支(Context Path)获取高层语义特征。
- 特征融合模块(Fusion Module)整合两者特性。
3. 挑战与未来方向
目前,基于普通图像(无明显畸变)的语义分割研究相对成熟。主要进展包括:
3.1 高精度方法
- DeepLab 系列:采用空洞卷积和ASPP模块,显著提升了分割精度,在语义分割基准数据集(如Cityscapes)上表现优异。
- PSPNet:通过金字塔池化模块有效融合全局与局部信息,特别适合复杂场景的语义分割任务。
3.2 实时性方法
实时性方法的目标是在有限计算资源下,实现接近高精度方法的分割效果,适配嵌入式平台及资源受限场景。
- ERFNet:利用分解卷积提升计算效率,同时保持良好的分割精度。
- BiSeNet:设计空间分支和上下文分支,兼顾高分辨率特征保留与感受野扩展,适配实时性要求。
3.3 高度畸变图像的挑战
语义分割在高度畸变的图像(如鱼眼图像)中的应用仍面临以下挑战:
- 几何扭曲问题:鱼眼镜头拍摄的图像因光学特性会产生严重的几何畸变,导致标准的卷积操作难以有效提取特征。
- 特征匹配难度:由于畸变的影响,高低分辨率特征融合的精度下降,限制了分割效果。
- 数据稀缺:鱼眼图像数据集相对较少,限制了模型的泛化能力。
- 实时性能不足:鱼眼图像的处理通常需要额外的几何校正或特定模块,增加了计算复杂度。
3.4 未来方向
为应对这些挑战,未来研究应从以下方面展开:
- 几何适配能力提升:
- 引入对畸变具有鲁棒性的卷积操作,例如可变形卷积或基于极坐标的卷积。
- 开发适配畸变特征的空间变换模块。
- 数据增强与生成:
- 利用生成对抗网络(GAN)生成多样化的鱼眼图像。
- 设计特定的数据增强策略以模拟畸变效果,增强模型泛化能力。
- 网络架构优化:
- 设计针对鱼眼图像的轻量化网络,减小计算开销的同时提升分割效果。
- 开发结合物理模型的混合架构,在几何与语义信息间建立更强的联系。
- 场景化应用探索:
- 针对智能驾驶场景中鱼眼摄像头的应用,提升模型在边界检测、道路预测中的表现。
- 扩展鱼眼图像语义分割在工业、医疗、无人机导航等领域的应用。
- 实时性与鲁棒性权衡:
- 集成更加高效的推理模块,降低嵌入式平台上的部署成本。
- 平衡特征分辨率与计算复杂度,确保实时分割的同时维持精度。
4. 深度学习语义分割关键技术总结
4.1 编码器-解码器架构
语义分割中的编码器-解码器架构(Encoder-Decoder)是基础的网络设计框架。通过特征压缩与重建,模型实现了语义信息的提取与恢复。常见的优化方法有:
- 编码器:逐步降低特征的空间分辨率,压缩图像信息,并提取高级语义特征。
- 解码器:通过上采样还原图像的空间分辨率,并恢复详细的语义信息。
优化方式:
- 索引上采样(SegNet):利用最大池化层索引高效上采样,减少计算复杂度。
- U型结构(UNet):采用对称架构,增强高分辨率与低分辨率特征之间的信息流动,提高上下文信息传递能力。
4.2 感受野与特征分辨率
语义分割需要较大的感受野来获取全局上下文信息,但传统的降采样方法往往会丢失细节信息。
空洞卷积
通过调整卷积核的扩张率,可以扩大感受野而不增加参数量。空洞卷积的优点是:
- 优点:扩展感受野,减少细节特征丢失。
- 问题:可能会产生“网格效应”。
- 改进方法:
- 混合扩张卷积:通过非线性调节扩张率,避免重复采样的问题。
- 可变形卷积:卷积核的采样位置变得可学习,增加了灵活性和适应性。
4.3 多尺度特征的融合
语义分割需要同时处理大小不一的目标,这要求模型具备多尺度特征融合的能力。
- ASPP(空洞空间金字塔池化):通过不同扩张率的空洞卷积,增强模型对多尺度特征的捕捉能力。
- PPM(金字塔池化模块):结合全局池化和局部池化,集成了不同尺度的全局和局部信息。
- 特征金字塔网络(FPN):逐层融合不同分辨率的特征图,从而增强对多尺度目标的感知能力。
4.4 实时语义分割优化
随着深度学习模型的复杂度增加,实时性成为嵌入式平台(如自动驾驶、移动设备)应用中的关键需求。如何在计算效率与精度之间找到平衡,成为研究的重点。
代表方法
- ERFNet:采用卷积分解和低秩近似来减少计算量,从而在精度和效率之间达成平衡。
- ICNet:通过将高分辨率和低分辨率图像分别输入到高复杂度与低复杂度模型,最后融合特征,提升整体性能和效率。
- BiSeNet:采用双分支网络架构:
- 空间分支(Spatial Path):保留空间细节,处理高分辨率图像。
- 上下文分支(Context Path):提取上下文信息,处理低分辨率图像。
- 特征融合模块(Fusion Module):将两部分的特征进行融合,以平衡精度与速度。
4.5 新兴网络架构(2018年及以后)
SENet(Squeeze-and-Excitation Networks)
SENet提出了一种新型的 自适应特征重标定机制,通过 Squeeze-and-Excitation (SE) 模块来增强网络的表达能力。其关键创新是:
- Squeeze:通过全局平均池化(GAP)将每个通道的信息压缩为一个全局特征。
- Excitation:通过一个全连接层和激活函数生成每个通道的权重,从而重新调整各通道的权重。
- SE模块:这个模块通过学习通道之间的依赖关系来增强特征的表达,进而提升网络的性能。
SENet被广泛应用于多个任务中,特别是在图像分类和语义分割中,通过动态调整通道权重来增强模型的特征表达能力。
HRNet(High-Resolution Network)
HRNet专注于保持高分辨率的特征图,并通过逐步融合高分辨率和低分辨率的特征图来提高多尺度信息的表达。其核心创新点是:
- 高分辨率特征保持:HRNet不同于传统网络通过下采样获取全局上下文信息,而是通过逐步融合不同分辨率的特征图,保持高分辨率的细节信息。
- 跨分辨率连接:多分辨率特征通过深度可分离卷积进行融合,这使得网络可以同时保持精细的局部信息和全局的上下文信息。
HRNet在多个视觉任务中取得了优异的表现,尤其是在精细任务如人脸识别和姿态估计中具有较高的表现。
DeepLabV3+
DeepLabV3+是基于DeepLabV3的进一步改进版本,在语义分割任务中取得了显著的性能提升。其主要贡献包括:
- ASPP改进:通过引入多尺度空洞卷积(Atrous Spatial Pyramid Pooling),提升模型对不同尺度信息的感知能力。
- 解码器结构:在DeepLabV3的基础上加入了解码器,以更好地恢复高分辨率的细节信息。
- 融合策略:DeepLabV3+使用融合的特征图来结合低级别和高级别特征,从而更好地进行像素级别的分类。
MobilenetV3
MobilenetV3通过使用 深度可分离卷积 和 硬件友好的设计 实现了高效的计算。它结合了优化算法(如NAS、自动化机器学习)和硬件特性,能够在低延迟和高精度之间找到平衡,非常适合嵌入式设备。
- 移动设备优化:MobileNetV3优化了计算量,保持了较高的精度,适用于边缘计算与实时处理任务。
- 硬件优化策略:通过深度可分离卷积等方式,减少了参数量,降低了计算需求。
4.6 未来方向与挑战
- 多模态融合:除了图像数据,语义分割任务可以借助多种模态数据(如深度图、红外图像等)来提高精度,尤其是在复杂环境中的表现。
- 自监督学习:通过自监督学习来挖掘图像中的隐藏特征,减少对标注数据的依赖,这将为大规模数据集的训练提供新方案。
- 实时性与精度平衡:随着深度学习应用向嵌入式设备和自动驾驶领域拓展,如何在保证实时性的同时提升分割精度,仍然是一个巨大的挑战。
5. 应用与未来发展
5.1 常规图像语义分割
语义分割在常规小孔成像的图像中已发展较为成熟:
- 高精度应用:如自动驾驶和高清场景分析。
- 实时性需求:如嵌入式系统和智能设备。
5.2 高畸变图像的挑战
针对鱼眼图像等具有高度畸变的场景,目前的研究尚未完全解决其带来的几何扭曲问题。
- 研究重点:
- 提高模型的几何适配能力。
- 设计针对性的数据增强方法。
- 改进现有网络结构以适配畸变特征。
5.3 跨领域应用
语义分割技术正在拓展至医学影像处理、遥感图像分析等领域,这些场景对分割精度与鲁棒性提出了更高的要求。
6. 总结
语义分割是计算机视觉中的核心问题,深度学习技术的引入极大推动了这一领域的发展。通过编码解码架构、空洞卷积、多尺度特征融合等技术的引入,研究者成功实现了性能与效率的不断突破。
未来方向:
- 针对实时性与精度间的平衡需求,进一步优化网络架构。
- 面对高畸变场景与复杂环境,开发鲁棒性更强的模型。
- 推动语义分割技术在新兴领域的应用与扩展。
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)