
多模态大语言模型(MLLMs)如何重塑和变革计算机视觉?
简单来说,多模态大型语言模型(MLLM)是结合了大型语言模型(LLM)(如 GPT-3 [2] 或 LLaMA-3 [3])的推理能力,同时具备接收、理解并输出多种模态信息的能力。图 1 展示了一个医疗领域的多模态 AI 系统 [4]。它接收两个输入:一张医学影像一个文本查询,如:“这张影像中是否存在胸腔积液?该系统输出一个关于该查询的预测答案。在本文中,可能会简化“多模态大型语言模型”这一术语,
本文介绍了多模态大型语言模型(MLLM) 的定义、使用挑战性提示的应用场景,以及正在重塑计算机视觉的顶级模型。

1、什么是多模态大型语言模型(MLLM)?
简单来说,多模态大型语言模型(MLLM)是结合了大型语言模型(LLM)(如 GPT-3 [2] 或 LLaMA-3 [3])的推理能力,同时具备接收、理解并输出多种模态信息的能力。
示例:
图 1 展示了一个医疗领域的多模态 AI 系统 [4]。它接收两个输入:
-
一张医学影像
-
一个文本查询,如:“这张影像中是否存在胸腔积液?”
该系统输出一个关于该查询的预测答案。


在本文中,可能会简化“多模态大型语言模型”这一术语,直接称其为“多模态模型”。
1.1 人工智能中的多模态崛起
近年来,人工智能经历了重大变革,其中Transformer [5] 体系架构的兴起极大推动了语言模型的发展 [6]。这一架构由 Google 于 2017 年提出,并对计算机视觉领域产生了深远影响。
早期的示例包括视觉 Transformer(ViT) [7],它将图像分割为多个补丁,并将其作为独立的视觉 token 进行输入处理。
随着大型语言模型(LLM)的崛起,一种新的生成式模型,即多模态大型语言模型(MLLM),自然地诞生了。
如前面时间线图所示,2023 年,大多数科技巨头都推出了至少一种 MLLM。到了 2024 年,OpenAI 的 GPT-4o 在 5 月发布时成为行业热点。
1.2 MLLMs vs VLMs vs 基础模型
一些人认为 MLLMs 其实就是基础模型(Foundation Models)。例如,Google 的 Vertex AI 将 Claude 3、PaliGemma 和 Gemini 1.5 等多模态大型语言模型归类为基础模型。🤔
另一方面,视觉语言模型(VLMs)[8] 是多模态模型的一个子类别,它们集成了文本和图像输入,并生成文本输出。
MLLMs 和 VLMs 的主要区别在于:
1、 MLLMs 能处理更多模态,而不仅仅是文本和图像(如 VLMs)。
2、 VLMs 的推理能力较弱,而 MLLMs 具有更强的逻辑推理能力。
1.3 体系架构
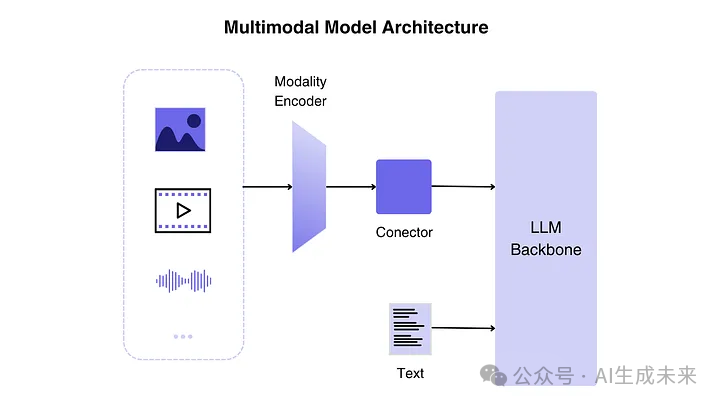
如图 3 所示,MLLM 的架构主要分为三个部分:
1、 模态编码器(Modality Encoder):
该组件将视觉、音频等原始数据转换为紧凑的表示形式。通常使用预训练编码器(如 CLIP)进行迁移学习,以适配不同的模态输入。
2、 LLM 主干(LLM Backbone):
语言模型负责生成文本输出,作为 MLLM 的“核心大脑”。编码器接收图像、音频或视频输入并生成特征,由连接器(模态接口)处理后输入 LLM。
3、 模态接口(Modality Interface):
连接编码器和 LLM,确保 LLM 能够理解不同模态的信息,并进行合理的推理和输出。
2、 多模态模型在计算机视觉中的应用
为了验证这些模型的能力,使用了 GPU 对三个顶级 MLLMs 进行测试,并使用了具有挑战性的查询(不再是猫🐱和狗🐶的简单示例)。
测试的 MLLMs:
-
GPT-4o (OpenAI)
-
LLaVA 7b (开源,基于 LLaMA)
-
Apple Ferret 7b (Apple 开源)
2.1 目标遮挡情况下的物体计数

任务: 计算图像中出现的安全帽数量,并提供其位置(见图 4)。
-
GPT-4o 提供了详尽的场景描述,但给出的坐标有误。
-
LLaVA 仅检测到 3 个安全帽,并且没有正确识别遮挡部分的安全帽。
-
Apple Ferret 成功检测到 4 个安全帽,包括左侧被遮挡的那个!⭐️
2.2 自动驾驶:风险评估与规划

任务: 从自动驾驶汽车的角度评估风险,并检测车辆和行人(见图 5)。
-
LLaVA 未能识别前方的大卡车。
-
GPT-4o 在文本分析方面表现优异,但检测出的目标框位置错误。
-
Apple Ferret 是唯一一个准确检测出大部分物体并给出正确坐标的模型 ✅。
2.3 体育分析:目标检测与场景理解

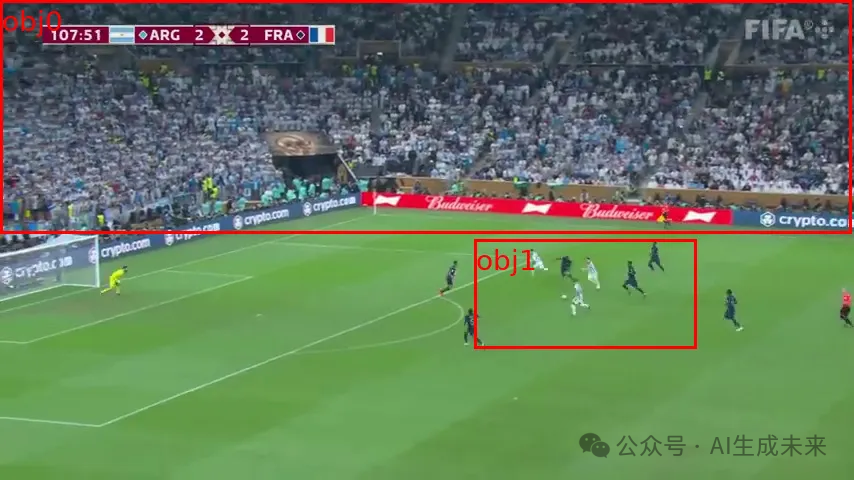
任务: 分析足球比赛场景,包括球员计数、球和守门员位置估计,并预测进球可能性(见图 7)。
结果:
-
所有模型均未能正确检测所有球员,并区分不同球队。
-
相比之下,YOLOv8 这样的单模态检测模型表现更优。
这表明,MLLMs 在一些复杂任务上仍然存在局限性,它们尚未完全取代专门优化的计算机视觉模型。
下一步是否应该对 MLLMs 进行微调?🤔
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!
更多推荐
 10
10 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)