
深度学习库: TensorFlow vs PyTorch
在深度学习领域,TensorFlow 和 PyTorch 是目前最主流的两种框架,分别由 Google 和 Facebook(现 Meta)开发。对于初学者而言,选择哪个框架作为入门往往令人困惑。本文将从多个维度对比这两种框架,并提供可执行的代码示例,帮助读者更好地理解和选择。
深度学习库 TensorFlow 与 PyTorch 的比较与入门指南
在深度学习领域,TensorFlow 和 PyTorch 是目前最主流的两种框架,分别由 Google 和 Facebook(现 Meta)开发。对于初学者而言,选择哪个框架作为入门往往令人困惑。本文将从多个维度对比这两种框架,并提供可执行的代码示例,帮助读者更好地理解和选择。
一、TensorFlow 与 PyTorch 的基本特点
TensorFlow
- 简介 :TensorFlow 是 Google 开发的开源机器学习框架,采用静态计算图(在运行前定义好整个计算图结构),具有强大的图形化工具,支持大规模分布式训练和跨平台部署,常用于生产环境中模型的部署和大规模数据训练。
- 特点 :静态计算图使得其执行效率高,适合大规模的模型训练和部署;丰富的工具和预训练模型,方便用户直接使用或微调;多平台支持,可运行在 CPU、GPU、TPU 等多种硬件设备上。
- 应用场景 :图像识别、自然语言处理、视频分析、语音识别等。
PyTorch
- 简介 :PyTorch 是 Facebook 开发的开源深度学习框架,采用动态计算图(在运行过程中动态构建计算图),以灵活、易用著称,常用于研究和开发阶段,特别是在需要频繁修改模型结构的场景。
- 特点 :动态计算图更灵活,可根据数据流自动调整,调试方便,支持 Python 原生的调试工具;强大的自动求导机制,能自动计算张量操作的梯度;丰富的预训练模型和工具库,如 TorchVision、TorchText、TorchAudio 等。
- 应用场景 :自然语言处理、计算机视觉、强化学习等。
二、动态计算图与静态计算图的区别
计算图是深度学习框架中用于表示数学计算或程序执行的图结构,它对框架的性能、调试和开发体验有重要影响。
动态计算图
- 定义 :在运行时动态构建,操作是即时计算的,每次前向传播时,计算图都可以有不同的结构。
- 优点 :更加灵活,可轻松处理可变大小的数据,支持更复杂的控制流操作;调试直观,开发者可以实时查看变量的值和程序的执行流程。
- 缺点 :由于图结构的动态性,优化可能不如静态图彻底,运行时可能会引入额外的开销。
静态计算图
- 定义 :在运行之前就已经定义好,需要先定义图结构,然后编译执行,无论输入数据如何变化,计算图的结构保持不变。
- 优点 :编译器可以在编译时对图进行优化,如图剪枝等,因此运行时更高效;适合大规模部署和跨平台运行。
- 缺点 :编写代码更复杂,特别是涉及到复杂的控制流时;调试不如动态图直观,因为图的结构在运行前就已经固定。
三、PyTorch 的独特功能
- 动态计算图 :如前文所述,这使得 PyTorch 在学术研究和快速原型开发中具有极大的优势,研究人员可以更灵活地调整模型结构和参数。
- 强大的自动求导机制 :PyTorch 的 autograd 模块提供了强大的自动求导功能,能够自动计算张量操作的梯度,且使用起来非常直观。
- 丰富的预训练模型和工具库 :提供了大量与计算机视觉、自然语言处理、音频处理等领域相关的预训练模型和数据处理工具,方便快速上手和应用。
- 分布式训练和混合精度训练 :支持强大的分布式训练功能,可在多台机器、多个 GPU 上进行大规模模型的训练,同时支持混合精度训练,提高训练效率。
四、代码示例
以下是使用 TensorFlow 和 PyTorch 构建并训练一个简单神经网络进行手写数字识别(MNIST 数据集)的代码示例。
TensorFlow 代码示例
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
import matplotlib.pyplot as plt
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理,将像素值归一化到 [0, 1] 范围
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建模型
model = Sequential([
Flatten(input_shape=(28, 28)), # 将 28x28 的图像展平为一维数组
Dense(128, activation='relu'), # 全连接层,128 个神经元,激活函数为 relu
Dense(10, activation='softmax') # 输出层,10 个神经元对应 10 个数字类别,激活函数为 softmax
])
# 编译模型
model.compile(optimizer='adam', # 使用 Adam 优化器
loss='sparse_categorical_crossentropy', # 稀疏分类交叉熵损失函数
metrics=['accuracy']) # 监控准确率指标
# 训练模型
history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
# 绘制训练过程中的准确率变化曲线
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)
运行结果
…
1ms/step - accuracy: 0.9867 - loss: 0.0422 - val_accuracy: 0.9780 - val_loss: 0.0698
313/313 - 0s - 1ms/step - accuracy: 0.9780 - loss: 0.0698
Test accuracy: 0.9779999852180481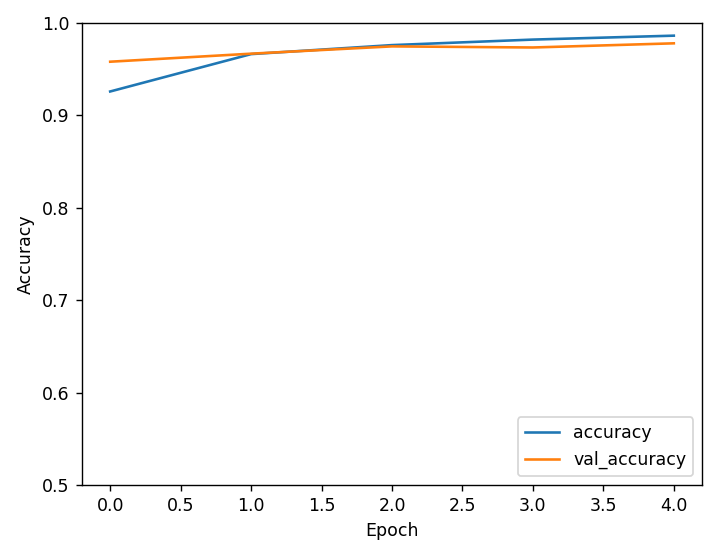
PyTorch 代码示例
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# 设置随机种子以确保结果可重复
torch.manual_seed(42)
# 定义数据预处理方式
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 对图像进行标准化
])
# 加载 MNIST 数据集
train_dataset = datasets.MNIST('../data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('../data', train=False, transform=transform)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=True)
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 输入层到隐藏层的全连接
self.fc2 = nn.Linear(128, 10) # 隐藏层到输出层的全连接
def forward(self, x):
x = x.view(-1, 28 * 28) # 将图像展平为一维数组
x = F.relu(self.fc1(x)) # 隐藏层使用 ReLU 激活函数
x = self.fc2(x)
return F.log_softmax(x, dim=1) # 输出层使用 log_softmax
model = Net()
# 定义损失函数和优化器
optimizer = optim.Adam(model.parameters())
criterion = nn.NLLLoss() # 负对数似然损失函数
# 训练模型
model.train()
for epoch in range(5):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 测试模型
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item() # 累加损失
pred = output.argmax(dim=1, keepdim=True) # 获取预测的类别
correct += pred.eq(target.view_as(pred)).sum().item() # 统计正确的预测数量
test_loss /= len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.0f}%)\n')
运行结果
Test set: Average loss: 0.0001, Accuracy: 9774/10000 (98%)
五、代码解释
- TensorFlow :通过
Sequential模型构建神经网络,使用Flatten将图像展平为一维数组,Dense层作为全连接层。在编译模型时,指定优化器、损失函数和评估指标。使用fit方法进行模型训练,并通过evaluate方法评估模型性能。 - PyTorch :定义一个神经网络类
Net,继承自nn.Module,在__init__方法中定义网络层,在forward方法中定义前向传播过程。使用DataLoader加载数据,定义损失函数和优化器,通过训练循环进行模型训练,并在测试阶段评估模型性能。
六、动态计算图与静态计算图对比表格
| 对比因素 | 动态计算图(PyTorch) | 静态计算图(TensorFlow) |
|---|---|---|
| 构建方式 | 运行时动态构建,操作即时计算,每次前向传播可有不同的结构 | 运行前定义好图结构,编译执行,图结构固定不变 |
| 灵活性 | 高,可轻松处理可变大小数据,支持复杂控制流,调试直观 | 低,图结构固定,调试不如动态图直观 |
| 性能优化 | 优化不如静态图彻底,运行时可能引入额外开销 | 编译时可进行全局优化,运行时更高效 |
| 适用场景 | 模型开发、原型设计、需要频繁修改模型结构的场景 | 大规模部署、跨平台运行、对性能要求较高的应用场景 |
通过本文的介绍和示例,希望能帮助初学者更好地了解 TensorFlow 和 PyTorch 的特点和区别,从而选择适合自己的深度学习框架进行学习和实践。无论是 TensorFlow 的强大部署能力,还是 PyTorch 的灵活开发体验,都为深度学习的应用和发展提供了有力的支持。
更多推荐
 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)